LangChain是什么?
在實際企業開發中,大模型應用往往比簡單的問答要復雜得多。如果只是簡單地向大模型提問并獲取回答,那么大模型的許多強大功能都沒有被充分利用。
要開始使用LangChain,首先需要安裝相關的庫:
pip install langchain
pip install langchain-openai
pip install langchain-community
pip install langgraph,grandalf
與大模型的集成
LangChain支持各種大模型,包括OpenAI的模型、智譜的GLM等,只需更改幾個參數即可切換不同的模型:
llm = ChatOpenAI(model="glm-4-plus",temperature=1.0,openai_api_key="your_api_key",openai_api_base="your_api_base_url"
)
LangChain的核心概念
提示詞模板
在LangChain中,提示詞通常通過模板定義,支持參數化,方便動態生成提示詞。兩個方式的目的都是創建一個提示詞模板,可以根據個人喜好選擇其中一種使用。
提示詞模板有兩種創建方式:
1. from_template方式
使用對象方式定義模板。
from_messages方式(更常用)
json方式定義模板:
prompt = ChatPromptTemplate.from_messages([("system", "請把下面的語句翻譯成{language}"),("user", "{user_text}")
])
LangChain Expression Language (LCEL)
LCEL允許開發者以聲明式的方式鏈接各個組件,使用豎線"|"操作符來連接不同的組件,創建復雜的處理流程,比如某節點循環、重復等。
串行/并行
-
串行執行:節點按順序依次執行,前一個節點的輸出作為后一個節點的輸入。這是最常見的模式,如我們之前示例中的鏈式結構。
-
并行執行:多個節點同時接收相同的輸入,各自處理后再匯總結果。這對于需要從不同角度分析同一數據的場景特別有用。
# 串行執行示例
serial_chain = node1 | node2 | node3# 并行執行示例
parallel_chain = (node1 & node2 & node3) | combine_results
鏈可能會越來越復雜,以下可以可視化鏈
# 可視化鏈結構
chain.get_graph().print_ascii()
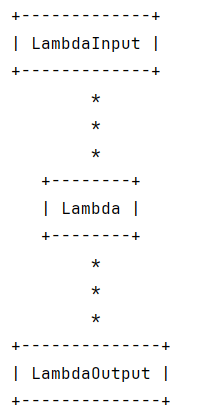
使用串行鏈案例
# 定義大模型
llm = ChatOpenAI(model="glm-4-plus",temperature=1.0,openai_api_key="your_api_key", openai_api_base="your_api_base_url"
)# 創建提示詞模板
prompt = ChatPromptTemplate.from_messages([("system", "請把下面的語句翻譯成{language}"),("history", MessagePlaceholder(variable_name="history")),("user", "{user_text}")
])# 創建鏈
chain = prompt | llm | StrOutputParser()# 調用鏈并傳參
result = chain.invoke({"language": "日文","user_text": "今天天氣怎么樣?"
})
print(result)
RunablePassthrough:靈活的數據處理器
RunablePassthrough是LCEL中處理數據轉換的核心工具,它允許我們以字典方式處理鏈。
使用RunablePassthrough有一個重要前提:它只能處理字典類型的數據。這也符合LangChain中大多數組件的設計理念,使用字典作為標準數據傳遞格式。
下面是一個簡單的示例,展示如何使用RunablePassthrough創建和轉換數據:
# 創建一個將輸入轉換為字典的簡單節點
r1 = lambda x: {"k1": x}# 使用RunablePassthrough添加新的鍵值對
chain = r1 | RunablePassthrough.assign(k2=lambda inputs: inputs["k1"] * 2,k3=lambda inputs: inputs["k1"] + 10
)# 運行鏈
result = chain.invoke(5)
# 輸出: {'k1': 5, 'k2': 10, 'k3': 15}
錯誤處理與后備機制
在生產環境中,錯誤處理是不可避免的挑戰。LCEL提供了優雅的錯誤處理機制,確保應用的穩定性和可靠性。
錯誤處理機制在以下場景中特別有價值:
- 外部API集成:當調用第三方服務時,提供平滑的錯誤處理
- 網絡操作:處理網絡連接問題和服務中斷
- 分布式系統:增強系統在部分組件失敗時的彈性
- 用戶體驗優化:即使在發生錯誤的情況下,也能確保用戶獲得有用的反饋
后備選項:優雅處理錯誤
with_fallbacks方法允許我們為節點指定后備選項,當主要節點報錯時啟用:
from langchain.schema.runnable import RunnableLambda# 定義一個可能失敗的主要節點
def primary_processor(x):if isinstance(x, int):return x + 10else:raise ValueError("Input must be an integer")# 定義后備節點
def backup_processor(x):try:return int(x) + 20 # 嘗試將輸入轉換為整數后加20except:return "Unable to process input"# 創建帶后備的鏈
resilient_chain = (RunnableLambda(primary_processor).with_fallbacks([RunnableLambda(backup_processor)])
)# 測試
result_normal = resilient_chain.invoke(5)
print(result_normal) # 正常情況,返回15
result_fallback = resilient_chain.invoke("2")
print(result_fallback) # 主處理器失敗,使用后備,返回22
在這個例子中,主處理器只接受整數輸入。當收到字符串輸入時,它會失敗并觸發后備處理器,后者會嘗試將輸入轉換為整數并加上20。
多級后備鏈
我們可以設置多個后備選項,系統會按順序嘗試,直到找到一個可成功執行的選項:
multi_fallback_chain = primary_node.with_fallbacks([backup_node1, # 首選后備backup_node2, # 備選后備final_fallback # 最后的保障
])
這種設計特別適合處理不同類型的錯誤或異常情況,確保系統在各種條件下都能提供有意義的響應。
重試機制:處理臨時故障
對于可能由于網絡中斷、服務暫時不可用等臨時問題導致的失敗,LCEL提供了重試機制:
# 創建帶重試的鏈
retry_chain = (network_dependent_node.with_retry(max_attempts=4, # 最多嘗試4次(初始嘗試+3次重試)stop_after_attempt=4, # 4次嘗試后停止wait_exponential_jitter=True # 使用指數退避策略,避免同時重試)
)
生命周期管理
生命周期管理是指監控和控制節點從創建到銷毀整個過程中的各個狀態。在LCEL中,每個節點都有一系列生命周期事件,我們可以為這些事件注冊回調函數,實現精細的控制和監控。
主要的生命周期事件包括:
- 啟動事件(on_start):節點開始執行時觸發
- 結束事件(on_end):節點執行完成時觸發
- 錯誤事件(on_error):節點執行出錯時觸發
LCEL提供了簡潔的API來實現生命周期監聽:
from langchain.schema.runnable import RunnableLambda
import time# 定義一個簡單的處理節點
def text_processor(seconds):# 模擬耗時操作time.sleep(seconds)return seconds * 2# 封裝為節點
node = RunnableLambda(text_processor)# 添加生命周期監聽器
monitored_node = node.with_listeners(on_start=lambda run_obj: print(f"節點啟動時間: {run_obj.start_time}"),on_end=lambda run_obj: print(f"節點結束時間: {run_obj.end_time}")
)# 執行節點
result = monitored_node.invoke(2) # 將休眠2秒,然后返回4
在這個例子中,我們為節點添加了兩個監聽器:一個在節點啟動時記錄時間,另一個在節點結束時記錄時間。這使我們能夠精確了解節點的執行持續時間。
歷史記錄管理
在選擇歷史記錄存儲方案時,有幾種常見選擇:
- 內存存儲:簡單快速,但存在容量限制。隨著用戶數量和并發請求的增加,內存占用會迅速增長。
- 磁盤存儲:更為持久,通常是通過數據庫實現。
對于生產環境,數據庫存儲是推薦的方案。數據可以存儲在本地數據庫(如SQLite)或遠程服務器上,只需更改連接URL即可切換。
以下是一個使用SQLite實現歷史記錄管理的示例:
def get_session_history(session_id: str):"""根據會話ID來讀取和保存歷史記錄Args:session_id: 會話的唯一標識符Returns:一個消息歷史對象"""return SQLMessageHistory(session_id=session_id,connection_string="sqlite:///history.db")result = chain.run_with_message_history({"input": "中國一共有哪些直轄市?"},get_session_history,config={"configurable": {"session_id": "user001"}}
)
這個函數創建并返回一個SQLMessageHistory對象,該對象負責管理與特定會話ID相關的所有對話歷史。
綜合案例
串行鏈:餐廳推薦系統
用戶輸入需求 ↓
需求分析與整理 → [展示整理后的結構化需求]↓
餐廳推薦生成 → [展示3家符合條件的餐廳]核心價值:將用戶非結構化輸入轉化為結構化決策流程,使整個推薦過程透明可見,幫助用戶做出更明智的選擇。
以下是一個餐廳推薦系統的設計,它展示了如何處理多步驟的復雜決策流程:
from langchain.chat_models import init_chat_model
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParserapi_key = "X"
api_base = "https://api.deepseek.com/"llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base=api_base,temperature=0,model_provider="deepseek",
)# 創建處理用戶需求的提示模板
requirement_analysis_prompt = PromptTemplate.from_template("""你是一位專業的需求分析師。請對以下用戶輸入的餐廳選擇要求進行歸納總結,提取關鍵點,并組織成有邏輯性的結構:用戶原始要求:{user_requirements}請輸出整理后的需求描述:"""
)# 創建餐廳推薦的提示模板
restaurant_selection_prompt = PromptTemplate.from_template("""你是一位美食專家。根據以下用戶的需求,推薦3家最符合條件的餐廳:用戶需求:{organized_requirements}請列出3家餐廳的名稱和簡要描述:"""
)# 使用管道操作符直接連接所有節點
restaurant_recommendation_chain = (requirement_analysis_prompt | llm |restaurant_selection_prompt | llm | StrOutputParser()
)# 執行鏈的示例代碼
if __name__ == "__main__":result = restaurant_recommendation_chain.invoke({"user_requirements": "我想找一家餐廳,價格不能太貴,最好有素食選擇,環境要安靜一點,適合和朋友聊天,最好是亞洲菜系,我不太能吃辣。位置最好在市中心附近,因為我們坐公共交通。"})print(result)在這個復雜的推薦系統中,我們看到了幾個重要的設計模式:
- 逐步細化處理:從用戶的原始(可能混亂)需求開始,逐步進行分析、推薦和評估
- 數據傳遞與保留:使用
RunnablePassthrough和Lambda函數確保關鍵數據在鏈中被正確傳遞 - 中間結果可視化:通過定制的處理函數展示每個步驟的輸出,使整個流程透明可見
- 模塊化設計:將復雜流程分解為可管理的組件,每個組件負責特定功能
動態鏈:智能選擇問題模板
核心要點是創建模板不同,根據用戶的輸入信息AI判斷應該屬于什么類。再根據不同類用不同回答
from langchain.chat_models import init_chat_model
from langchain.schema.output_parser import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnableLambda
from langchain_core.output_parsers import JsonOutputParserapi_key = "X"
api_base = "https://api.deepseek.com/"llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base=api_base,temperature=0,model_provider="deepseek",
)# 定義各領域專用提示詞模板
physics_template = PromptTemplate.from_template("你是一位物理學專家。請回答以下物理問題:\n\n{input}"
)math_template = PromptTemplate.from_template("你是一位數學專家。請解答以下數學問題:\n\n{input}"
)history_template = PromptTemplate.from_template("你是一位歷史學家。請回答以下歷史問題:\n\n{input}"
)computer_science_template = PromptTemplate.from_template("你是一位計算機科學家。請回答以下計算機科學問題:\n\n{input}"
)default_template = PromptTemplate.from_template("你輸入的內容無法歸類到特定領域。我將盡力回答:\n\n{input}"
)# 定義各領域處理鏈
physics_chain = physics_template | llm
math_chain = math_template | llm
history_chain = history_template | llm
computer_science_chain = computer_science_template | llm
default_chain = default_template | llm# 創建分類提示詞
classification_prompt = PromptTemplate.from_template("""不要回答下面用戶的問題,只要根據用戶的輸入來判斷分類。一共有物理、數學、歷史、計算機、其他五種分類。用戶的輸入是: {input}輸出格式為JSON,其中類別的key為"type",用戶輸入內容的key為"input"。"""
)# 創建路由函數
def router(input_data):# 根據分類結果選擇合適的處理鏈question_type = input_data["type"]if "物理" in question_type:print("1號路由:物理問題")return physics_chainelif "數學" in question_type:print("2號路由:數學問題")return math_chainelif "歷史" in question_type:print("3號路由:歷史問題")return history_chainelif "計算機" in question_type:print("4號路由:計算機問題")return computer_science_chainelse:print("5號路由:其他問題")return default_chain# 創建路由節點
router_node = RunnableLambda(router)# 構建完整的智能體鏈
agent_chain = (classification_prompt |llm |JsonOutputParser()|router_node|StrOutputParser()
)# 測試智能體
test_questions = ["什么是黑體輻射?","計算1+1的結果","第二次世界大戰是什么時候爆發的?","解釋什么是遞歸算法"
]for input_question in test_questions:result = agent_chain.invoke({"input":input_question})print(f"問題:{input_question}")print(f"回答:{result}\n")


![[250506] Auto-cpufreq 2.6 版本發布:帶來增強的 TUI 監控及多項改進](http://pic.xiahunao.cn/[250506] Auto-cpufreq 2.6 版本發布:帶來增強的 TUI 監控及多項改進)


指針的高級應用匯總)



初識n8n:工作流自動化平臺概述)

 實現 MNIST 手寫數字識別)






)
