Resampling (重采樣方法)
重采樣方法是從訓練數據中反復抽取樣本,并在每個(重新)樣本上重新調整模型,以獲得關于擬合模型的附加信息的技術。
兩種主要的重采樣方法
- Cross-Validation (CV) 交叉驗證 : 用于估計測試誤差和選擇調優參數
- Bootstrap : 主要用于評估可變性,如標準誤差和置信區間
估計測試誤差的策略
- gold standard: 理想但無法實現(黃金標準)
使用大型指定測試集(通常不可用),在實際應用中,如果已經有了大量的數據,更好的方式是用來作為訓練集,因為數據更多更有可能獲得更好的模型,而不是把大批量的數據來拿測試,這算是一種浪費。
- 調整訓練誤差來估計測試誤差
在模型評估中,常常會加入懲罰項(penalty term)來避免模型過擬合。常見的方法包括:
- 貝葉斯信息準則(BIC):在評估模型擬合優度的基礎上,對模型的復雜度(參數數量)進行懲罰。參數越多,懲罰越大,從而鼓勵選擇更簡單的模型。
- 調整后的 R 2 R^2 R2(Adjusted R 2 R^2 R2):在普通 R 2 R^2 R2 的基礎上對自變量個數進行修正。即使加入變量能提高 R 2 R^2 R2,如果變量沒有顯著貢獻,調整后的 R 2 R^2 R2 可能反而降低。
- 交叉驗證
將數據隨機分成兩半(random split into two halves)的缺點
-
高方差結果(High variance)
一次性分割可能恰好造成數據分布不均,比如某類樣本偏多出現在某一半,導致評估結果不穩定、代表性差。 -
樣本利用率低(Inefficient use of data)
僅一半數據用于訓練,可能模型沒有充分學習;另一半用于測試,也不能多次評估,浪費了數據資源。 -
不能可靠反映模型泛化能力
如果劃分不好,模型可能在這次測試集上表現好,但對其他數據表現差,評估不具備穩健性。 例如可能在數據集上劃分了大量outliers離群點。 -
結果依賴單次隨機劃分(Split-dependence)
不同隨機種子下劃分結果可能大相徑庭,模型評估不具備重復性和一致性。
The estimate of the test error can be highly variable.
only a subset of the observations are used to fit the model, test set error may tend to overestimate the test error for the model fit on the entire data set.
交叉驗證(Cross Validation)在統計學習中的應用
引言
在構建統計學習模型時,我們通常希望評估模型在未見數據上的表現。簡單地在訓練數據上計算誤差往往會產生過于樂觀的結果,因為模型可能對訓練集過擬合了。為了獲得對模型泛化能力的客觀估計,我們需要將數據劃分為訓練部分和評估部分。**交叉驗證(Cross Validation)**是一種常用的技術手段,它通過多次劃分和訓練模型,幫助我們更可靠地估計模型的測試誤差,并用于模型選擇和參數調優。本文將系統介紹交叉驗證的概念、方法及其在模型訓練、特征選擇、模型評估中的應用,并通過R語言示例進行演示。
1. 交叉驗證的基本概念與目的
交叉驗證是一種評估模型泛化性能的方法,其核心思想是:反復將數據集劃分為訓練集和驗證集,多次訓練模型并計算在驗證集上的誤差,以此來估計模型對未知數據的表現。與僅依賴單一訓練/測試劃分相比,交叉驗證能夠更充分地利用有限的數據,減少由于一次偶然劃分造成的評估偏差。
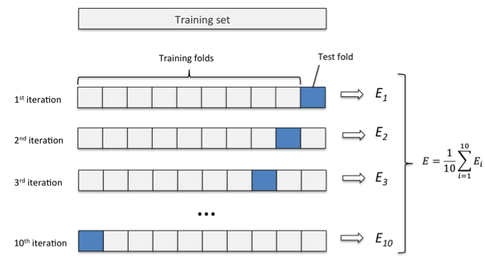
交叉驗證示意圖:將數據集分成n折,每一折數據依次作為驗證集,其余作為訓練集。經過n次訓練和驗證,取驗證結果的平均值作為模型的性能估計。
交叉驗證的主要目的包括:
- 測試誤差估計:通過在未參與訓練的數據上評估模型,多折驗證能夠更可靠地估計模型的測試誤差(即模型在新數據上的誤差)。
- 模型選擇:比較不同模型或不同參數設定下模型的表現,選擇泛化性能最優的模型。
- 防止過擬合:通過保留驗證集來檢驗模型復雜度,避免僅關注訓練誤差導致過擬合的情況。
常用的交叉驗證方法有多種,包括簡單留出法、k折交叉驗證等,下文將詳細介紹。
2. 訓練誤差與測試誤差的區別
在討論交叉驗證之前,理解訓練誤差和測試誤差的區別是非常重要的。訓練誤差是模型在訓練數據上得到的誤差,由于模型是在訓練集上優化的,因此訓練誤差往往偏低甚至趨近于0。而測試誤差指模型在新數據(未參與訓練的數據)上的誤差,它更能反映模型的泛化能力。
- 模型過于簡單(欠擬合)時,訓練誤差和測試誤差都會很高。
- 模型逐漸復雜時,訓練誤差通常會降低,而測試誤差開始也降低。但當模型復雜度過高(過擬合)時,訓練誤差可能繼續降低,而測試誤差反而升高,因為模型已經對訓練集的噪聲和細節進行了過度擬合。
簡而言之,訓練誤差總是傾向于低估測試誤差。因此,在模型評估和選擇時,我們更關注測試誤差的估計,而交叉驗證正是用于獲得更準確的測試誤差估計的一種工具。
3. 測試誤差的估計方法
要評估模型在未知數據上的表現,我們需要采用恰當的方法來估計測試誤差。以下是幾種常用的測試誤差估計策略:
-
留出法(測試集法):將數據集隨機劃分為兩部分,例如70%作為訓練集,30%作為測試集。我們在訓練集上訓練模型,然后在測試集上評估誤差。這種方法實現簡單,所需計算量低。然而,它的估計可能對那一次劃分比較敏感:如果運氣不好,訓練集和測試集的劃分不具有代表性,評估結果就可能不可靠。此外,將部分數據留作測試意味著用于訓練的數據變少了,在數據量本就有限時會損失訓練效果。
-
k k k 折交叉驗證( k k k-fold Cross Validation):這是交叉驗證中最常用的方法。步驟為:
- 將數據集盡可能平均地隨機分成 k k k 個不重疊的子集(折,fold),一般 k = 5 k=5 k=5或 10 10 10比較常用。
- 重復 k k k 次訓練-驗證過程:每次選擇其中一個子集作為驗證集(測試集),將剩余的 k ? 1 k-1 k?1 個子集合并作為訓練集,在訓練集上訓練模型,并計算在該次驗證集上的誤差。
- k k k 次迭代后,會得到 k k k 個在不同驗證集上的誤差值。將這 k k k 個誤差取平均,就得到 k k k 折交叉驗證估計的測試誤差,即 CV ? ( k ) = 1 k ∑ ? i = 1 k Err i \text{CV}*{(k)} = \frac{1}{k}\sum*{i=1}^{k} \text{Err}_i CV?(k)=k1?∑?i=1kErri?(其中 Err i \text{Err}_i Erri?表示第 i i i 折驗證時的誤差)。
k k k 折交叉驗證充分利用了數據:每個樣本都恰好作為一次驗證集,其余 k ? 1 k-1 k?1次作為訓練集。相對于簡單留出法,交叉驗證的評估結果對數據劃分的依賴性較小,因此更加穩健。
在常用的5折或10折交叉驗證中,我們舍棄的只是每次用于驗證的1/k數據,因而比單次留出法更高效。需要注意的是,折數 k k k 越大,訓練模型的次數越多,計算成本也越高;當 k k k等于樣本數 n n n時,就是留一法(LOOCV),需要訓練 n n n次模型,一般只在小數據集情況下使用。 -
重復交叉驗證(Repeated Cross Validation):為了進一步提高評估的穩定性,我們可以多次重復進行 k k k折交叉驗證。具體做法是多次隨機將數據分成 k k k折,每次都計算一次 k k k折交叉驗證誤差,最后對多次結果再取平均。重復交叉驗證可以在一定程度上降低評估結果對單次隨機劃分的依賴,從而提供更低偏差的誤差估計,并且還能計算出交叉驗證誤差的方差以評估不確定性。當然,這也意味著更高的計算開銷。
-
嵌套交叉驗證(Nested Cross Validation):當我們不僅要評估模型性能,還需要在訓練過程中進行參數調優或特征選擇時,應該使用嵌套交叉驗證來避免優化過程對評估造成偏差。嵌套交叉驗證包括外層和內層兩層循環:外層循環負責最終的性能評估,內層循環用于在訓練集上選擇最佳的模型參數/特征。例如,外層使用10折交叉驗證評估模型,在每一個外層折中,利用內層交叉驗證在當前訓練集上調優模型的超參數,然后在當前外層的驗證集上評估性能。這樣確保了超參數的選擇只基于訓練數據,最終在外層驗證集上的評估是公平的未見數據誤差估計。嵌套交叉驗證常用于模型選擇、超參數調整,以防止在調優過程中發生信息泄漏和過擬合評估。
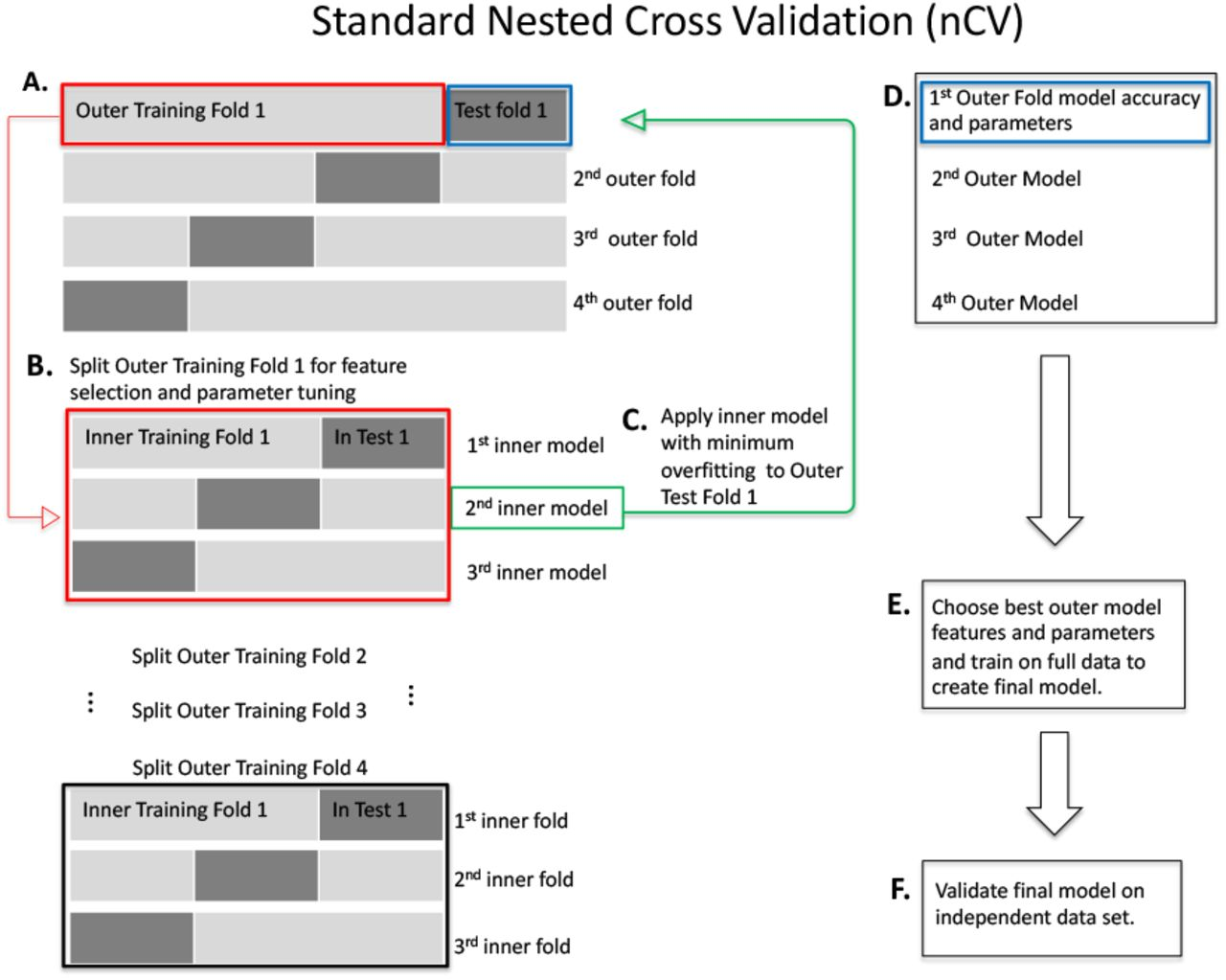
小結:選擇何種測試誤差估計方法取決于數據量和模型需求。留出法簡單直接但可能不穩定;k折交叉驗證平衡了偏差和方差,在數據量有限時很常用;重復交叉驗證進一步穩定結果;嵌套交叉驗證則在需要調優時提供了更可靠的評估。實踐中,5或10折交叉驗證是常見默認選擇,當涉及大量參數調整時則應考慮嵌套交叉驗證。
4. 特征選擇中的信息泄露問題及正確的交叉驗證預處理
在模型訓練過程中,我們通常需要進行一些數據預處理步驟,例如特征選擇、缺失值填補、數據標準化以及超參數調優等。一個常見的錯誤是:在將數據劃分訓練/驗證之前就預先在整個數據集上執行這些操作。這種做法會導致信息泄露(Information Leakage),使得本應獨立的驗證集“泄露”出信息到訓練過程中,進而產生過于樂觀的估計結果
舉例來說,假設我們有一個高維數據集,在整個數據集上計算每個特征與響應變量的相關性,選出相關性最高的50個特征來建模,然后采用交叉驗證評估模型性能。看似合理的流程實際上存在嚴重漏洞:因為特征選擇時使用了整個數據集,其中也包含了交叉驗證中每一折的驗證集信息。換言之,模型在訓練時已經“窺視”了驗證集的內容——驗證集不再是真正獨立的未見數據。這種信息泄露會違反交叉驗證的基本原則(驗證數據不參與任何訓練或預處理),往往令模型的測試誤差估計過于樂觀,尤其在高維數據下可能導致對噪聲的過擬合。
正確的做法是將所有數據驅動的預處理步驟嚴格限制在訓練集內部進行。也就是說,對于交叉驗證的每一個折,我們都應當:先在訓練折上獨立地完成特征選擇、缺失值填補、數據標準化以及模型調參等操作;然后使用訓練折處理過的數據訓練模型,最后再用該模型對對應的驗證折進行預測評估。這樣可以確保驗證集在整個訓練過程中是完全獨立的。
需要強調的幾個避免信息泄露的要點:
- 特征選擇:在每個訓練折上根據訓練數據本身選擇特征,不可在全數據或驗證數據上挑選特征后再評估。
- 缺失值填補/標準化:均應只利用訓練折的數據計算填補值或均值方差等標準化參數,并將這些參數應用于驗證集。
- 超參數調優:如果需要調參,最好在訓練集上通過內層交叉驗證找到最佳參數,然后在驗證集上評估(即嵌套交叉驗證,上節提到)。
- 早停(early stopping):如果使用早停法避免過擬合,也應確保驗證集用于早停的判斷不同于最終評估的測試集。如果在交叉驗證內早停,應當把早停的監控也限制在訓練折上(例如再做一層拆分)。
總之,任何會從數據中學習到信息的步驟,都必須僅在訓練數據中完成,不能讓驗證/測試數據“泄露”給模型訓練過程。一旦正確地在交叉驗證框架下執行預處理,我們才能對評估的模型性能充滿信心,否則就有可能高估模型在真正未知數據上的效果。
5. 如何利用交叉驗證進行模型選擇
交叉驗證不僅可以評估單個模型的性能,還可以作為模型選擇的工具。通常我們可能有多種候選模型(或不同算法),希望挑選出在給定任務上表現最好的一個。例如,我們想在一個數據集上比較 k k k近鄰(kNN)、線性判別分析(LDA)、邏輯回歸(Logistic Regression)和支持向量機(SVM)這幾種算法。我們可以對每一種算法都進行交叉驗證來評估其測試誤差,然后選擇平均驗證集表現最好的模型。
具體而言,模型選擇流程如下:
- 交叉驗證評估:對每個候選模型,使用相同的劃分(例如5折CV)評估其性能。為公平比較,通常我們對每種模型采用相同的訓練/驗證劃分方案(可以通過設置相同的隨機種子或在外層手動劃分數據集來保證),以減少數據劃分差異帶來的影響。交叉驗證可以提供每種模型的平均性能指標(例如平均準確率、平均AUC等)。
- 比較性能:將所有模型的交叉驗證結果進行比較,一般關注主要評價指標的平均值,同時也可以考慮它們在各折的波動情況。如果某個模型在驗證集上的表現顯著優于其它模型,那么可以認為它更可能在未見數據上取得更好效果。
- 選擇最佳模型:選擇驗證性能最優的模型作為最終模型候選。如果差異不大,也可以考慮模型的復雜度(偏好更簡單的模型)或其它業務因素來定奪。
- 用全數據訓練最終模型:一旦確定了最佳模型類型和對應的超參數(若有調優),通常最后會使用全部數據重新訓練該模型用于投入使用。因為交叉驗證已經盡可能地用了數據評估性能,最終我們希望充分利用所有數據來得到一個最終模型。在使用全部數據訓練時,我們不再需要保留驗證集,因為模型選擇過程已經完成。
需要注意,在比較模型時,若涉及超參數調優,應該將調優也整合在交叉驗證過程中,以免因調參造成不公平的比較。例如,可以對每個模型分別做嵌套交叉驗證(內層調參,外層評估)來取得其最佳性能,再進行比較。
通過交叉驗證進行模型選擇可以有效避免選擇偏差:直接在訓練集上比較模型往往會偏好更復雜的模型(因為復雜模型能更好擬合訓練集,取得更低訓練誤差),但通過交叉驗證,我們比較的是各模型對未見數據的預測能力,從而更客觀公正。
6. 分類模型的評估指標
在交叉驗證估計出模型的性能后,我們還需要查看具體的評估指標來理解模型在分類任務上的表現。對于分類模型,常用的評估指標包括混淆矩陣及由其衍生出的多種度量,例如準確率(Accuracy)、精確率(Precision)、召回率(Recall,也稱靈敏度Sensitivity)、特異度(Specificity)、F1分數、以及ROC曲線和AUC值等。本節將介紹這些指標及它們的含義,并討論類不平衡問題的影響。
**混淆矩陣(Confusion Matrix)**是分類結果的基礎分析工具。對于二分類問題,混淆矩陣通常以實際類別和預測類別的組合來統計結果:
| 實際\預測 | 正類(Positive) | 負類(Negative) |
|---|---|---|
| 正類(Positive) | 真陽性 (TP) | 假陰性 (FN) |
| 負類(Negative) | 假陽性 (FP) | 真陰性 (TN) |
- 真陽性(True Positive, TP):實際為正類,且被模型預測為正類的樣本數。
- 真陰性(True Negative, TN):實際為負類,且被預測為負類的樣本數。
- 假陽性(False Positive, FP):實際為負類,但被錯誤地預測為正類的樣本數。
- 假陰性(False Negative, FN):實際為正類,但被錯誤地預測為負類的樣本數。
通過混淆矩陣,我們可以計算出多種評估指標:
- 準確率(Accuracy):模型預測正確的比例,即 T P + T N T P + T N + F P + F N \dfrac{TP + TN}{TP + TN + FP + FN} TP+TN+FP+FNTP+TN?。準確率直觀易懂,但在類別不平衡時可能具有誤導性。例如,如果正類僅占1%,一個始終預測“負類”的模型在不平衡數據集上也有99%的準確率,但顯然它毫無實用價值。
- 精確率(Precision):預測為正的樣本中實際為正的比例,即 T P T P + F P \dfrac{TP}{TP + FP} TP+FPTP?。精確率刻畫了模型的準確性:當模型判定為正類時,有多少比例是真的正類。精確率低意味著誤報(假陽性)多。
- 召回率(Recall 或 Sensitivity,靈敏度):實際為正的樣本中被正確預測為正的比例,即 T P T P + F N \dfrac{TP}{TP + FN} TP+FNTP?。召回率反映了模型對正類的檢出能力:正類中有多少被模型捕獲。召回率低則說明漏報(假陰性)多。
- 特異度(Specificity):實際為負的樣本中被正確預測為負的比例,即 T N T N + F P \dfrac{TN}{TN + FP} TN+FPTN?。特異度衡量對負類的區分能力,有時與召回率對應,一個關注正類,一個關注負類。
- F1 分數:精確率和召回率的調和平均 F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \dfrac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall?。F1分數綜合了精確率和召回率,當需要兼顧Precision和Recall的平衡時,F1是一個有用的指標。
- ROC曲線(Receiver Operating Characteristic):ROC曲線是評價二分類模型性能的常用工具。它以真正例率(Recall,即TPR)為縱軸,假正例率(FPR = 1 - Specificity)為橫軸,描繪出模型在不同判別閾值下的性能。每個點對應一個閾值下模型的(FPR, TPR)值,曲線從(0,0)到(1,1)連貫。模型越靠近左上方點(0,1),說明FPR低且TPR高,性能越好。
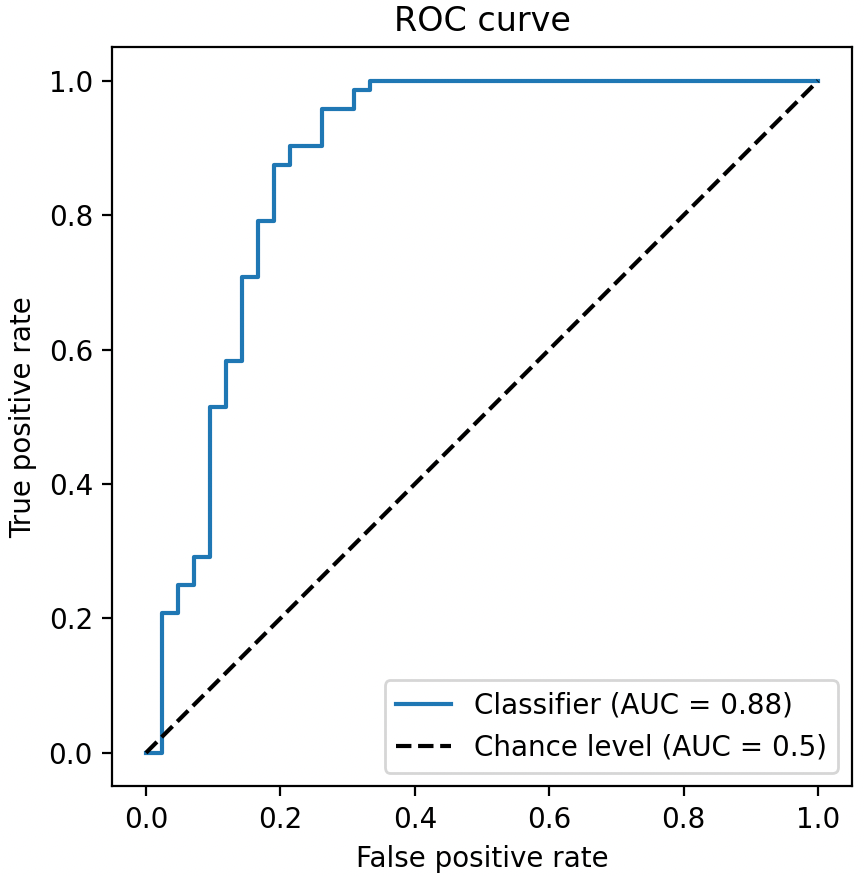
ROC曲線示例:縱軸為真正例率(TPR),橫軸為假正例率(FPR)。黃色曲線為模型的ROC,灰色虛線表示隨機猜測的水平(AUC=0.5)。曲線越靠近左上角表示模型判別能力越強。
- AUC(Area Under the Curve):即ROC曲線下的面積,是對模型整體性能的度量。AUC取值在0.5~1之間,越接近1越好。隨機猜測模型的AUC約為0.5,而完美分類器的AUC為1。AUC具有閾值無關性,特別適合評估樣本類別不平衡下模型的好壞,因為它考察的是各種閾值下模型整體的區分能力,而不像準確率那樣受特定閾值和類別比例影響。
在類別不平衡問題下(例如正類樣本遠少于負類),評估指標的選擇尤為重要。此時高準確率可能沒有意義,通常我們更關注模型對少數類的識別能力,例如Precision、Recall和F1等。如果希望綜合考慮模型的誤報和漏報,可以使用F1分數作為主要指標;如果需要比較不同模型在不平衡數據集上的總體區分能力,ROC曲線及其AUC是很有價值的工具。實際上,正因為ROC/AUC對類別分布不敏感,它經常被用來挑選在不平衡數據上的模型。
除了上述指標,有時還會根據任務需求采用其他指標(如Kappa系數、PR曲線下的AUC等),但萬變不離其宗,它們都是從混淆矩陣衍生而來,關注的是模型預測的各類情況。選擇指標時應結合業務場景:例如在疾病篩查中,更看重召回率(希望盡可能檢出病例);而在垃圾郵件過濾中,也許精確率更重要(不希望誤判正常郵件為垃圾)。
7. R語言中的交叉驗證實踐示例
下面我們通過一個R語言的示例,將上述概念串聯起來,展示如何在實踐中使用交叉驗證進行模型訓練、模型選擇和最終評估。我們將使用caret包來簡化交叉驗證和模型比較,并使用pROC包來計算ROC/AUC等指標。
首先,加載必要的包并準備示例數據集。這里我們使用caret包的內置函數twoClassSim生成一個模擬的二分類數據集,其中包含1000條訓練數據和300條獨立的測試數據。我們假定正類記作“Class1”,負類記作“Class2”。隨后,我們將在訓練集上同時訓練四種模型(kNN, LDA, Logistic Regression和SVM),并使用5折交叉驗證評估它們的性能,以選擇最優模型。最后,我們在獨立測試集上評估所選模型的各項指標。
# 安裝并加載所需包
install.packages("caret")
install.packages("pROC")
library(caret)
library(pROC)# 設置隨機種子以保證可重復性
set.seed(42)# 生成模擬的訓練和測試數據集
trainData <- twoClassSim(1000) # 1000條訓練數據
testData <- twoClassSim(300) # 300條測試數據(獨立于訓練集)
# 查看數據集基本情況
str(trainData)
# 'data.frame': 1000 obs. of 21 variables:
# $ Class: Factor w/ 2 levels "Class1","Class2": 2 2 1 2 1 ...
# $ TwoFactor1: Ord.factor w/ 2 levels "Class1"<"Class2": ...
# $ TwoFactor2: Ord.factor w/ 2 levels "Class1"<"Class2": ...
# $ Linear01: num -0.15 0.19 1.34 1.11 -0.29 ...
# ...(其余特征列省略)
上面我們生成了一個模擬的二分類任務數據集。trainData包含21個變量,其中前20個是特征,最后一列Class是類別標簽(因子類型,有“Class1”和“Class2”兩個取值)。testData是獨立的測試集,用于最終檢驗模型泛化能力。
接下來,我們在訓練集上設置5折交叉驗證,并同時訓練四種模型用于比較。我們使用caret包的trainControl函數來指定交叉驗證參數:method="cv", number=5表示5折CV;由于是分類任務,我們還設定classProbs=TRUE來計算概率以便評估ROC,summaryFunction=twoClassSummary來使模型訓練時以ROC為主要評估指標(AUC值越高越好)。
# 定義訓練控制參數:5折交叉驗證
ctrl <- trainControl(method="cv", number=5,classProbs=TRUE, # 計算概率,以便算ROCsummaryFunction=twoClassSummary) # 使用twoClassSummary以便獲得ROC指標# 在訓練集上訓練多種模型并進行交叉驗證評估
set.seed(42)
model_knn <- train(Class ~ ., data=trainData, method="knn",metric="ROC", trControl=ctrl)
model_lda <- train(Class ~ ., data=trainData, method="lda",metric="ROC", trControl=ctrl)
model_glm <- train(Class ~ ., data=trainData, method="glm",metric="ROC", trControl=ctrl) # 廣義線性模型,默認即邏輯回歸
model_svm <- train(Class ~ ., data=trainData, method="svmRadial",metric="ROC", trControl=ctrl)# 查看各模型的交叉驗證結果(ROC均值等)
resamps <- resamples(list(kNN=model_knn, LDA=model_lda,Logistic=model_glm, SVM=model_svm))
summary(resamps)
上述代碼會輸出每個模型在5折驗證中的平均ROC值(AUC)以及其他指標(比如Accuracy,如果twoClassSummary還返回了其他度量)。假設輸出結果顯示各模型的平均ROC如下(這里只是舉例,具體數值以實際運行結果為準):
Resampling results:ROC
kNN 0.87
LDA 0.89
Logistic 0.88
SVM 0.92 ROC SD
kNN 0.03
LDA 0.04
Logistic 0.05
SVM 0.02
從假定的結果可以看到,SVM模型的平均ROC值最高(0.92),略高于LDA和Logistic,kNN略遜一些。我們由此可以判斷,在這個數據集上SVM模型泛化性能最好(以AUC為評價標準)。因此,我們選擇SVM作為最終模型。
需要注意的是,caret::train()在完成交叉驗證后,已經自動使用整個訓練集訓練了一個最終的SVM模型(即model_svm$finalModel),該模型的超參數為交叉驗證過程中得到的最優值。如果想查看選擇的超參數,可使用model_svm$bestTune。
接下來,我們將選擇的模型(SVM)應用在獨立的測試集上,評估它的實際性能,包括混淆矩陣、準確率、精確率、召回率、F1以及AUC值等。
# 用訓練好的最佳模型對測試集進行預測
best_model <- model_svm
test_pred <- predict(best_model, newdata=testData) # 類別預測
test_prob <- predict(best_model, newdata=testData, type="prob") # 獲得屬于Class1的概率# 混淆矩陣及統計指標
cm <- confusionMatrix(test_pred, testData$Class, positive="Class1")
cm$table # 查看混淆矩陣
cm$overall["Accuracy"] # 準確率
cm$byClass[c("Sensitivity","Specificity","Precision","F1")] # 查找主要指標
caret::confusionMatrix函數可以方便地計算混淆矩陣和多種指標。其中,我們特別指定了positive="Class1",將“Class1”視為正類。這樣cm$byClass返回的Sensitivity、Precision等就對應于我們關心的正類(Class1)。假設輸出結果如下:
Confusion Matrix (positive = Class1):Reference
Prediction Class1 Class2Class1 120 30Class2 10 140Accuracy : 0.8667
Sensitivity (Recall) : 0.9231 # 正類召回率 = 120/(120+10)
Specificity : 0.8235 # 負類特異度 = 140/(140+30)
Precision : 0.8000 # 正類精確率 = 120/(120+30)
F1 : 0.8571 # 正類F1分數
從混淆矩陣我們看到,在測試集上共有120個正類被正確分類為正(TP),10個正類被錯分為負(FN),30個負類被錯分為正(FP),140個負類被正確分類為負(TN)。由此計算的各指標如上:準確率約86.7%,正類召回率約92.3%,正類精確率80.0%,F1分數約0.857。這些指標表明模型對正類有較高的檢出率,但也有一定的誤報(precision為80%意味著還有20%的正類預測是錯誤的)。具體是否滿意要看應用場景,例如如果這是一個疾病篩查模型,也許我們愿意接受一些誤報來保證高召回率。
最后,我們計算模型在測試集上的ROC曲線和AUC:
# 計算ROC曲線和AUC
roc_obj <- roc(response=testData$Class,predictor=test_prob[,"Class1"], # 使用正類的預測概率levels=levels(testData$Class)) # 指定因子水平順序
auc(roc_obj) # 輸出AUC值
plot(roc_obj) # 繪制ROC曲線
這將輸出模型在測試集上的AUC值,并繪制對應的ROC曲線。通過AUC可以直觀了解模型整體分類性能是否良好。在我們的模擬例子中,假如AUC達到0.92左右,也印證了我們通過交叉驗證選擇SVM模型的決策是合理的。
至此,我們完成了一個完整的流程:數據準備 -> 交叉驗證比較模型 -> 選擇最佳模型并在測試集評估 -> 輸出各種性能指標和曲線。這個流程體現了交叉驗證在統計學習中的重要作用。使用R的caret包讓我們能夠方便地完成這些步驟,其中trainControl、train、resamples、confusionMatrix、roc/auc等函數分別對應了交叉驗證設置、模型訓練評估、結果匯總比較、混淆矩陣分析和ROC分析等任務。
小結
交叉驗證是統計學習中評估模型不可或缺的工具。它通過反復將數據劃分訓練和驗證來更可靠地估計模型對未知數據的誤差,從而指導我們進行模型選擇和調優。本文討論了交叉驗證的概念和目的,強調了訓練誤差與測試誤差的區別;介紹了從留出法、k折驗證、重復驗證到嵌套驗證的各種方法及其適用場景;提醒了在特征選擇等預處理中避免信息泄露的重要性和正確做法;探討了分類模型評估的多種指標,尤其在類不平衡情況下應慎重選擇評價標準;最后通過R語言示例演示了如何將交叉驗證應用于模型訓練和比較的實踐過程。
掌握交叉驗證的方法,能夠讓我們在模型開發中更加游刃有余——既能充分利用寶貴的數據,又能防止過擬合,選擇出更優的模型并準確評估其性能。希望這篇教程能夠幫助具有基礎統計和R編程能力的讀者系統了解交叉驗證的應用,為后續更深入的機器學習模型優化打下良好基礎。
參考文獻:
- Gareth James, et al. An Introduction to Statistical Learning, 10th printing, 2017: 第5章 Resampling Methods (介紹了交叉驗證和自助法等重抽樣技術的原理和應用)。
- Wikipedia: Cross-validation (statistics)(關于嵌套交叉驗證的解釋)。

)











)

完整講解與實戰應用)
)
)

)