一、常用數據處理模塊Numpy
Numpy常用于高性能計算,在機器學習常常作為傳遞數據的容器。提供了兩種基本對象:ndarray、ufunc。
ndarray具有矢量算術運算和復雜廣播能力的快速且節省空間的多維數組。
ufunc提供了對數組快速運算的標準數學函數。
ndarry
創建
創建一維和二維數組,顯示其屬性值
import numpy as np
# 創建一維數組和二維數組,顯示其屬性值
a1 = np.array([1,2,3,4,3,5,6,9])
print(a1)
a2 = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(a2)
# 特殊的ndarray
a3 = np.arange(1,100,5)
print('a3:\n', a3)
a4 = np.linspace(1,100,5)
print('a4:\n', a4)
a5 = np.logspace(1,3, 2)
print('a5:\n', a5)
a6 = np.logspace(0, 9, 10, base=2)
print('a6:\n', a6)
a7 = np.zeros((3,4))
print('a7:\n', a7)
a8 = np.eye(5)
print('a8:\n', a8)
a9 = np.ones((2,3))
print('a9:\n', a9)
a10 = np.diag([1,2,3,5])
print('a10:\n', a10)結果

| arange | 等差數列(開始值,終值,步長) |
| linspace | 等差數列(開始值,終值,元素數量) |
| logspace(a,b,c,base=d) | 等比數列(10的a次方到10的b次方共c個,基d默認為10) |
| zeros | 全為0的矩陣 |
| ones | 全為1的矩陣 |
| eye | 單位矩陣(對角線元素為1,其余為0) |
| diag | 對角矩陣(對角線元素為特定值,其余為0) |
索引與切片
import numpy as np
# 一維數組的索引和切片
a1 = np.arange(10)
print('a1:\n', a1)
print(a1[5])
print(a1[3:6])
print(a1[:-1])
print(a1[5:1:-2])# 二維數組的索引和切片
a2 = np.array([[11,12,13,14,15], [21,22,23,24,25], [31,32,33,34,35]])
print('a2:\n', a2)
print(a2[0,3:5])
print(a2[1:,2:])
print(a2[:,2:])設置形狀
import numpy as np
# 設置數組形狀
a = np.arange(12)
print('生成一個一維數組a:\n', a)
a = a.reshape(3,4)
print(a)
a.resize(2,6)
print(a)
a.shape = (4,3)
print(a)展平
import numpy as np
# 展平數組
a = np.arange(12).reshape(3,4)
print('生成一個3*4數組a:\n',a)
b = a.ravel()
print('按行展平a:',b)
c = a.flatten('F')
print('按行展平a:',c)
排序
import numpy as np
a = np.array([[1,12,3,9],[2,4,6,8],[10,11,7,5]])
print(a)
print('調用sort函數')
print(np.sort(a))
print('按列排序:')
print(np.sort(a,axis = 0))# 在sort函數種排序字段
dt = np.dtype([('name','S10'),('age',int)])
ar = np.array([('fang', 26),('jie', 24),('ahao', 25),('ming', 22),('ajie', 28),('quan', 19)],dtype=dt)
print('原數組:\n',ar)
print('按name排序:\n')
print(np.sort(ar, order='name'))
print('按age排序:\n')
print(np.sort(ar, order='age'))搜索
import numpy as np
x = np.arange(9).reshape(3,3)
print(x)
print('大于3的元素的索引:')
y = np.where(x>3)
print(y)
print('使用這些索引搜索滿足要求的元素')
print(x[y])print('返回滿足要求的元素')
condition = np.mod(x,2) == 0
print(np.extract(condition,x))ufunc
算術運算、三角運算、集合運算、比較運算、邏輯運算、統計運算。
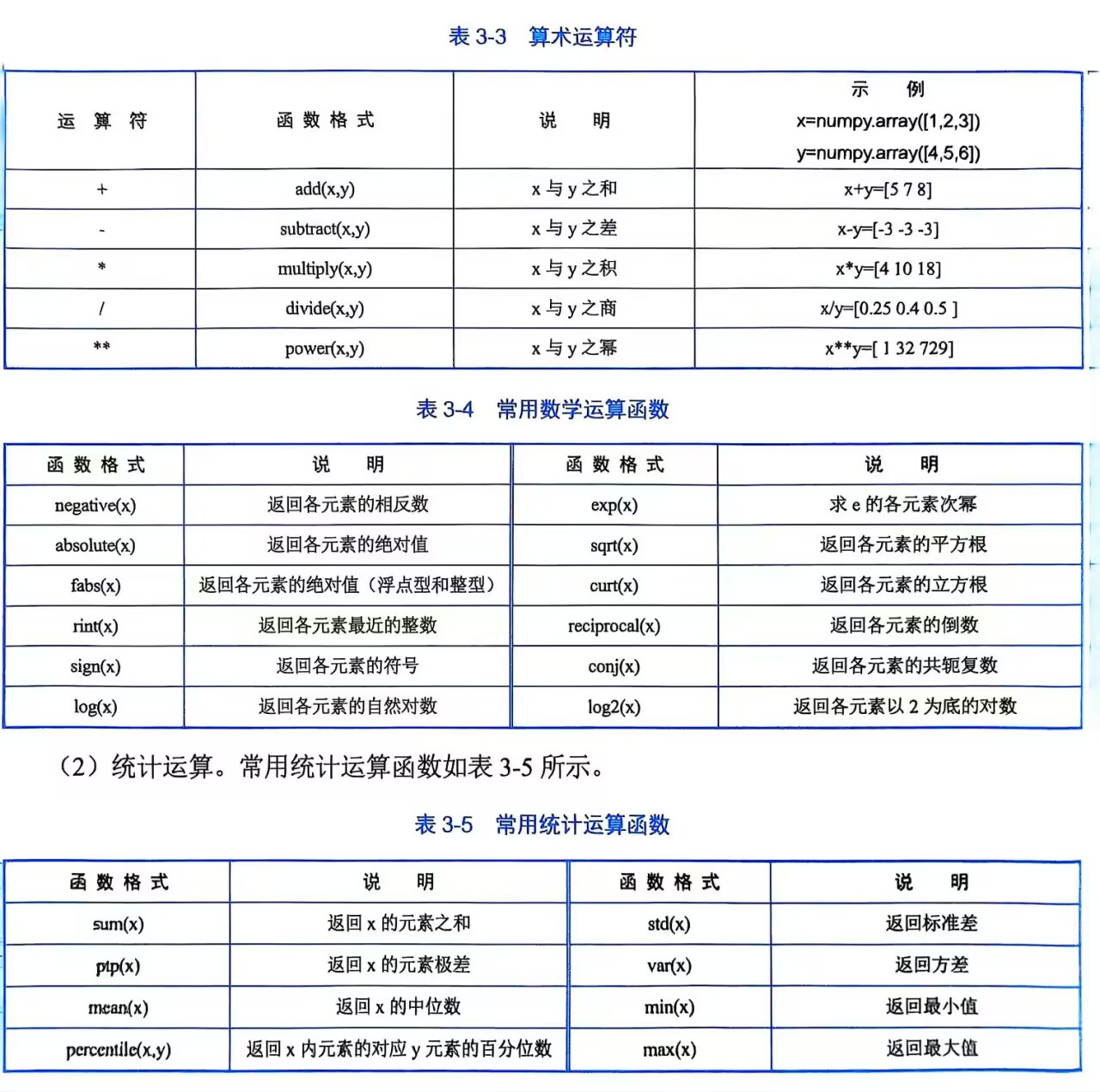
計算矩陣面積
import numpy as np
# 計算矩陣乘積(左上為1*5+2*7=19)
a = [[1,2],[3,4]]
b = [[5,6],[7,8]]
print(np.matmul(a,b))結果:
[[19 22]
?[43 50]]
注:矩陣面積為左邊的行乘右邊的列,詳見線性代數。結果的左上角19 = 1*5+2*7
二、常用數據處理模塊Pandas
Pandas是基于Numpy創建的,為Python提供高性能、易使用的數據結構和數據分析工具。主要有Series和DataFrame
Series:基本數據結構,一維標簽數組,能夠保存任何數據類型
DataFrame:基本數據結構,一般為二維數組
Series
創建
pandas.Series(一維數組,數據索引標簽(默認從0開始),數據類型,名稱)
import numpy as np
import pandas as pd
# 用ndarray創建Series數據對象
print(pd.Series(np.arange(5),index=['a','b','c','d','e']))
# 用dict創建Series數據對象
print(pd.Series({'y':84,'h':94, 'w':96}))
# 用list創建Series數據對象
print(pd.Series([10,20,30],index=['a','b','c']))
數據訪問
import pandas as pd
import numpy as np
data = np.arange(5)
s = pd.Series(data,index=['a','b','c','d','e'])
print(s)
print(s['b'])
s['c'] = 75
print(s)?DataFrame
創建
import numpy as np
import pandas as pd
dict1 = {'col1':[0,1,2,3],'col2':[4,5,6,7]}
print(pd.DataFrame(dict1))
list1 = [[30,45],[65,76],[25,86]]
print(pd.DataFrame(list1, index=['a','b','c'],columns=['A','B']))訪問
import numpy as np
import pandas as pd
dict1 = {'col1':[0,1,2,3],'col2':[4,5,6,7]}
print(pd.DataFrame(dict1))
list1 = [[30,45],[65,76],[25,86]]
print(pd.DataFrame(list1, index=['a','b','c'],columns=['A','B']))增、刪、改
import pandas as pd
dict = {'y':[90,76,82,61,62,72],'a':[75,73,86,85,91,76],'b':[66,64,74,89,85,90]}
d = pd.DataFrame(dict)
print(d)
d['y'] = [80,82,86,92,95,77]
d['g'] = [90,96,85,84,83,93]
print(d)
d.drop(['y','g'],axis=1,inplace=True)
print(d)三、常用數據可視化模塊Matplotlib
一個2D繪圖庫。
matplotlib是最基礎的擴展包,為pandas、seaborn提供基礎繪圖概念與語法。
它雖然不能直接提供繪制折線圖的函數,但可以借助散點函數繪制折線圖。
在我看來,它與MATLAB相比雖然需要手工導入函數,但可以與其他庫配合使用。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
month = ['一月','二月','三月','四月','五月']
sales_amounts = [26, 75, 89, 56, 64]
month_index = range(len(month))
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
ax1.bar(month_index, sales_amounts,align='center',color='darkblue')
ax1.xaxis.set_ticks_position('bottom')
ax1.yaxis.set_ticks_position('left')
plt.xticks(month_index,month,rotation=0,fontsize='small')
plt.xlabel('月份')
plt.ylabel('銷售額')
plt.title('每個月的銷售額')
plt.savefig('matplotlib336.png')四、數據收集、整理與清洗
數據收集
方法:
1.通過現有網絡平臺進行數據抽取而獲得數據。
2.利用設備收集。利用各類傳感器從系統外部收集數據并輸入到系統內部。
3.系統日志采集方法。
4.網絡數據采集方法。
以爬蟲為例介紹如何從網絡獲取數據。
爬蟲通過模擬是計算機對服務器端發起Request請求,接受服務器端的Response回應并解析,提取得到所需信息。
通過Python程序進行網絡爬蟲獲取相關數據主要涉及3個Python庫:Requests、Lxml、BeautifulSoup。
①Requests庫的作用主要是請求網站獲取網頁數據。
import requests
res = requests.get('http://www.baidu.com')
print(res)
print(res.text)②Lxml為XML解析庫,同時很好的支持HTML文檔的解析功能,除了能直接讀取字符串,也能從文件中提取內容。
③BeautifulSoup庫用于解析Requests庫請求的網頁,并把網頁源代碼解析為Soup文檔,以便過濾和提取數據。
例:爬取《天工開物》
from urllib.request import urlopen
url = 'https://www.gutenberg.org//files/25273/25273-0.txt'
text = urlopen(url).read()
text = text.decode('utf-8')
print(len(text))
text1 = text[596:733]
print(text1)
print()import opencc
cc = opencc.OpenCC('t2s')
print(cc.convert(text1))
?例:爬取豆瓣圖書TOP250的信息
from lxml import etree
import requests
import csv
fp = open('D:/pythoncode/aiSelf/P114book.csv','wt',newline="", encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment'))
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0'
}
for url in urls:html = requests.get(url, headers=headers)selector = etree.HTML(html.text)infos = selector.xpath('//tr[@class="item"]')for info in infos:name = info.xpath('td/div/a/@title')[0]url = info.xpath('td/div/a/@href')[0]book_infos = info.xpath('td/p/text()')[0]author = book_infos.split('/')[0]publisher = book_infos.split('/')[-3]date = book_infos.split('/')[-2]price = book_infos.split('/')[-1]rate = info.xpath('td/div/span[2]/text()')[0]comments = info.xpath('td/p/span/text()')comment = comments[0] if len(comments)>0 else '空'writer.writerow((name,url,author,publisher,date,price,rate,comment))
fp.close()
print('ok')

其他必需知識
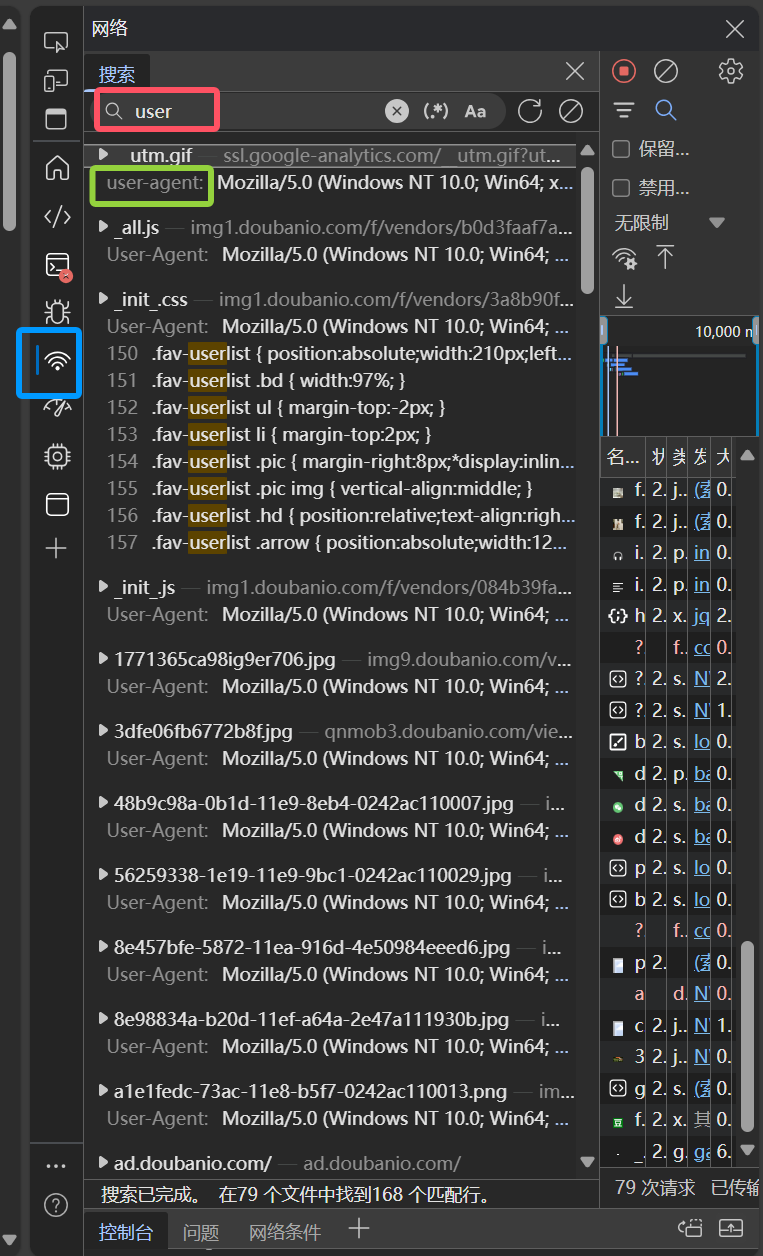
user-agent的獲取
進入目標網頁,按F12或右鍵檢查,進入控制臺,找到網絡(藍色框),刷新網頁后輸入user(紅色框)找到user-agent(綠色框),復制。
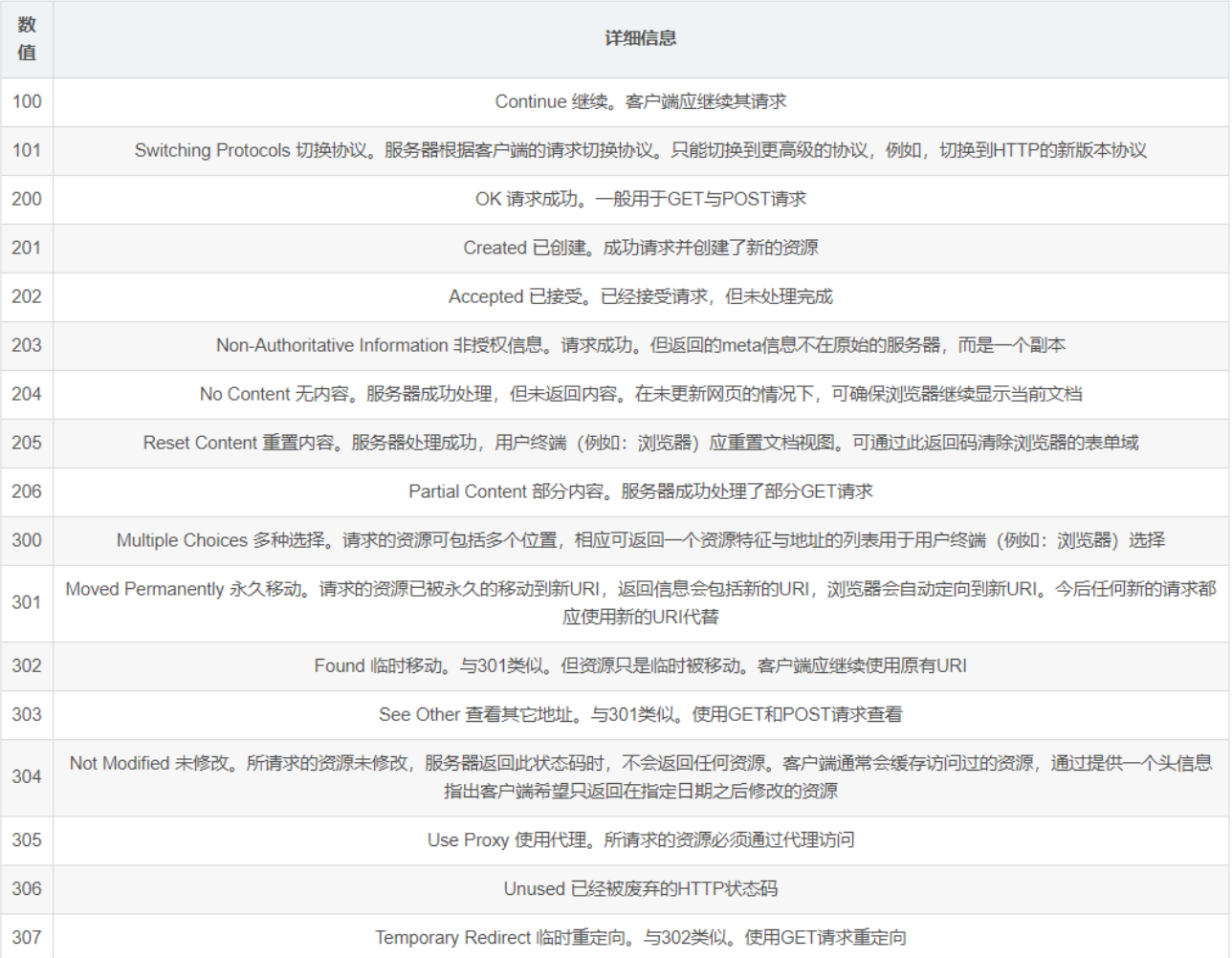
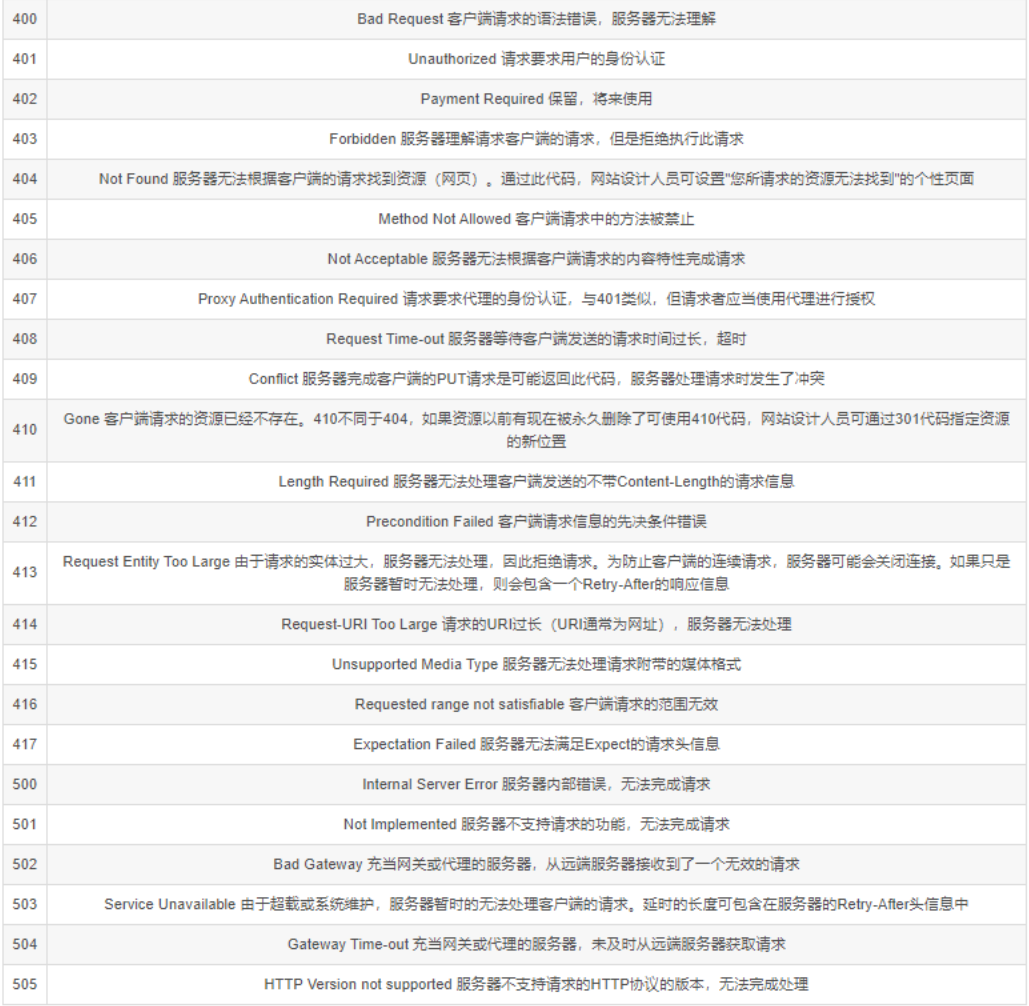
響應狀態碼
| 1xx | 服務器接收客戶端消息,但沒有接受完成,等待一段時間后發送的 |
| 2xx | 成功 |
| 3xx | 重定向 |
| 4xx | 客戶端錯誤 |
| 5xx | 服務器端錯誤 |
?Requests庫的七個主要方法
| 方法 | 說明 | 對應HTTP的 |
| requests.request() | 構造一個請求,支撐以下各個方法的基礎方法 | |
| requests.get() | 獲取HTML網頁的主要方法 | GET |
| requests.head() | 獲取HTML頭信息的方法 | HEAD |
| requests.post() | 向HTML提交POST請求的方法 | POST |
| requests.put() | 向HTML提交PUT請求的方法 | PUT |
| requests.patch() | 向HTML提交局部修改請求 | PATCH |
| requests.delete() | 向HTML提交刪除請求 | DELETE |
Response對象的屬性
| 屬性 | 說明 |
| r.status_code | HTTP請求的返回狀態,200連接成功,404連接失敗 |
| r.text | HTTP相應內容的字符串形式,即url對應的頁面內容 |
| r.encoding | 從HTTP header中猜測的相應內容編碼方式 |
| r.apparent_encoding | 從內容中分析出的相應內容編碼方式(備選編碼方式) |
| r.content | HTTP相應內容的二進制形式 |
Requests庫的異常
| 異常 | 說明 |
| requests.ConnectionError | 網絡連接錯誤異常, 如DNS查詢失敗、拒絕連接等 |
| requests.HTTPError | HTTP錯誤異常 |
| requests.URLRequired | URL缺失異常 |
| requests.TooManyRedirects | 超過最大重定向次數,產生重定向異常 |
| requests.ConnectTimeout | 連接遠程服務器超時異常 |
| requests.Timeout | 請求URL超時,產生超時異常 |
Python讀寫文件模式匯總
基本打開方式
| 模式 | 描述 | 文件存在 | 文件不存在 |
|---|---|---|---|
| r | 只讀 | 打開文件 | 報錯(FileNotFoundError) |
| w | 只寫 | 清空文件 | 創建新文件 |
| a | 追加 | 從末尾寫入 | 創建新文件 |
| x | 排他創建 | 報錯(FileExistsError) | 創建新文件 |
組合模式
| 模式 | 描述 |
|---|---|
| r+ | 讀寫(文件必須存在) |
| w+ | 讀寫(清空文件或創建新文件) |
| a+ | 讀寫(從末尾追加或創建新文件) |
二進制模式
以上模式后加b,如rb,rb+,ab+。表示二進制模式。
:大模型NL2SQL繪制城市之間連線)


詳解與實踐)












—— 使用C操作MySQL)


