一.基本結構
1.目標:處理序列數據(時間序列,文本,語音等),捕捉時間維度上的依賴關系
核心機制:通過隱藏狀態(hidden State)傳遞歷史信息,每個時間步的輸入包含當前數據和前一步的隱藏狀態
前向傳播的公式:
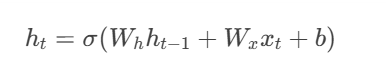
-
ht?:當前時間步的隱藏狀態
-
xtxt?:當前輸入
-
Wh,WxWh?,Wx?:權重矩陣
-
σσ:激活函數(通常為
tanh或ReLU)
2.輸入與輸出形式
單輸入單輸出(如時間序列預測):每個時間步接收一個輸入,最后一步輸出預測結果
多輸入,多輸出(如機器翻譯):?每個時間步接收輸入并生成輸出(如逐詞翻譯)。
Seq2Seq(如文本生成):編碼器-解碼器結構,編碼器處理輸入序列,解碼器生成輸出序列。
二.RNN的變體
1.雙向RNN
-
特點:同時捕捉過去和未來的上下文信息。
-
結構:包含正向和反向兩個隱藏層,最終輸出由兩者拼接而成。
2.深層RNN
-
特點:堆疊多個RNN層,增強模型表達能力。
-
結構:每層的隱藏狀態作為下一層的輸入。
3.LSTM(長短時記憶網絡)
-
核心機制:通過細胞狀態(Cell State)和門控機制(輸入門、遺忘門、輸出門)解決梯度消失問題。
-
門控公式:
-
遺忘門:決定保留多少舊信息
-
輸入門:決定新增多少新信息
-
輸出門:決定當前隱藏狀態輸出
-
4.GRU(門控循環單元)
-
簡化版LSTM:合并細胞狀態和隱藏狀態,參數更少。
-
門控公式:
-
更新門:控制新舊信息的融合比例
-
重置門:決定忽略多少舊信息
-
三.RNN的梯度問題與優化?
梯度消失與爆炸的原因
-
反向傳播:通過時間展開(BPTT)計算梯度時,梯度涉及權重矩陣的連乘。
-
梯度消失:若權重矩陣特征值?∣λ∣<1∣λ∣<1,梯度指數級衰減,深層參數無法更新。
-
梯度爆炸:若?∣λ∣>1∣λ∣>1,梯度指數級增長,導致數值溢出或模型震蕩。
解決方案
-
梯度裁剪(Gradient Clipping):限制梯度最大值,防止爆炸。
-
參數初始化:使用正交初始化(保持矩陣乘法后的范數穩定)。
-
改進結構:LSTM/GRU通過門控機制緩解梯度消失。
-
殘差連接:跨時間步跳躍連接(如?ht=ht?1+f(xt,ht?1)ht?=ht?1?+f(xt?,ht?1?)),直接傳遞梯度。






)








而不用conda)



