結構體
目錄:
1、結構體類型聲明
2、結構體變量的創建和初始化
3、結構體成員訪問操作符
4、結構體內存對齊*****(重要指數五顆星)
5、結構體傳參
6、結構體實現位段
一、結構體類型聲明
其實在指針中我們已經講解了一些結構體內容了,讓我們回顧一下結構體是什么吧~
結構體:是一些值的集合,這些值稱為成員變量,結構體的成員變量可以是不同類型的
1、數組與結構體:
數組:相同數據類型值的集合
結構體:不同數據類型的值的集合
struct tag
{member-list;//成員列表
}variable-list;//變量列表
- 結構體可以更好的描述現實世界的復雜實體:現實世界中的實物都是具有屬性和行為的,這里的屬性就是不同數據類型的成員來描述的,也就是拿什么東西區描述它,而行為就是我們學習面向對象編程的類里的方法(沒學過的可以暫時理解為函數),可以實現各種功能,也就是能拿他來做什么,對應不同的行為。
假設有一本書:它的屬性是書名,作者,編號,價格,這些就是我們可以用結構體的成員列表來描述而他的行為,比如可以賣出去營利多少,這個就可以寫個函數算一下。
//結構體類型:實體書具有的屬性集合
struct Book
{ //成員列表char name[20];//書名char author[10];//作者char id[19];//編號float price;//價格
}b1,b2;//變量列表:這樣創建是編譯器依據數據類型結構體類型創建出來的全局變量
int main()
{
//直接在創建變量的同時對其進行初始化
//位置初始化:必須按照位置來初始化
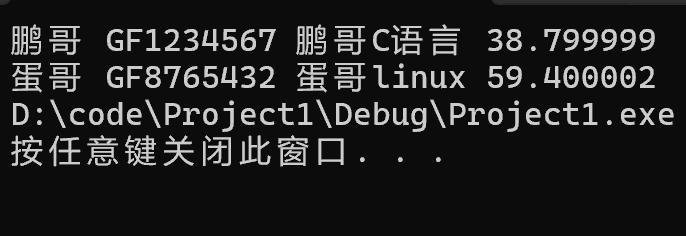
struct Book b3 = {"鵬哥C語言","鵬哥","GF1234567",38.8f};
//關鍵字初始化:由你自己指定參數來初始化值,但是必須注意要訪問到成員變量才可以進行賦值
struct Book b4 = {.author = "蛋哥",.id = "GF8765432",.name = "蛋哥linux",.price = 59.4f};
//打印結構體內容:通過.和->訪問結構體成員
printf("%s %s %s %f\n", b3.author, b3.id, b3.name, b4.price);
p = &b4;
//結構體變量名.結構體成員名 , 結構體指針->結構體成員名
printf("%s %s %s %f", p->author, p->id, p->name, p->price);
return 0;
}
- 結構體類型其實就是一個數據類型的集合,把各種數據類型封裝起來用于描述更為復雜的現實世界的實體
- 那我們要創建出實體書才可以用結構體類型來描述他的屬性呀,這個變量列表就是我們依據這些屬性創建出的實體書,也可以在主函數內部創建并初始化實體書(結構體類型的實體)
打印出的結果:
- 為什么這里的38.8并不是真正的38.8呢?
小數在內存(二進制)中是不一定能夠精確存儲的,
1、比如10.5 -->1010.1(后面的小數位正好是2**-1也就是0.5)剛好保存
10.8: 就是1010.1(是0.5),1010.11(是0.5+0.25),1010.111(是0.5+0.25+0.125)超綱了所以第三位小數要補0,那么接下來就又要用后面的數湊這個0.8,如果湊不齊就要已知湊下去
2、由于內存小數的精度是有限的,float小數最多32bit位,double最多是52個比特位,有沒有可能有一個數字,你就一直往后面湊數就是湊不夠,那是不是就是丟失精度了
- 所以我們在比較浮點數的大小的時候實際上是需要接受他們之間有一定的誤差值的,誤差在多少范圍內我認為他們相等,計算他們之間的浮點數差值絕對值,如果小于某個值就認為他們相等
int main()
{ if (fabs(38.8 - 38.8f) < 0.000001){printf("相等");}else{printf("不相等");}return 0;
}int main()
{float f = 38.8;if (fabs(38.8 - f) < 0.000001){printf("相等");}else{printf("不相等");}return 0;
}打印字符串的時候直接使用printf(“字符串內容”)就可以,因為實際上是將字符串的首地址傳遞給printf了,找到地址就可以直接將內容打印了
1、匿名結構體
1、在創建結構體的時候,可以不定義結構體的名字,但是這種結構體創建變量的時候只能夠創建全局變量,如果沒有對結構體重命名,基本只能使用一次
2、對于這樣的結構體,即使內容一樣,編譯器一樣會把他們當成不同的類型,因為沒有名字
struct
{int a;char b;float c;
}x;
struct
{int a;char b;float c;
}a[20], *p;
*p = &x//不合法的:因為類型不一樣
即使成員變量一樣,但是沒名字,編譯器認為是兩種不同的類型
二、結構體的自引用
結構體內包含有同類型的指針,記錄著下一個結點的位置,以方便找到一下個數據
1、數據結構
數據結構其實就是數據在內存中的組織結構
線性數據結構
- 1、順序表:底層是數組,數據在內存中是連續存儲的,只是在數組的基礎上增加了一些功能,比如增刪查改
- 2、鏈表:數據在內存中不連續存儲,一個節點中同時存放著數據域和指針域,一個結點有能力找到與它自身同類型的下一個結點,是通過下一個結構體的地址(指針域)來找到的
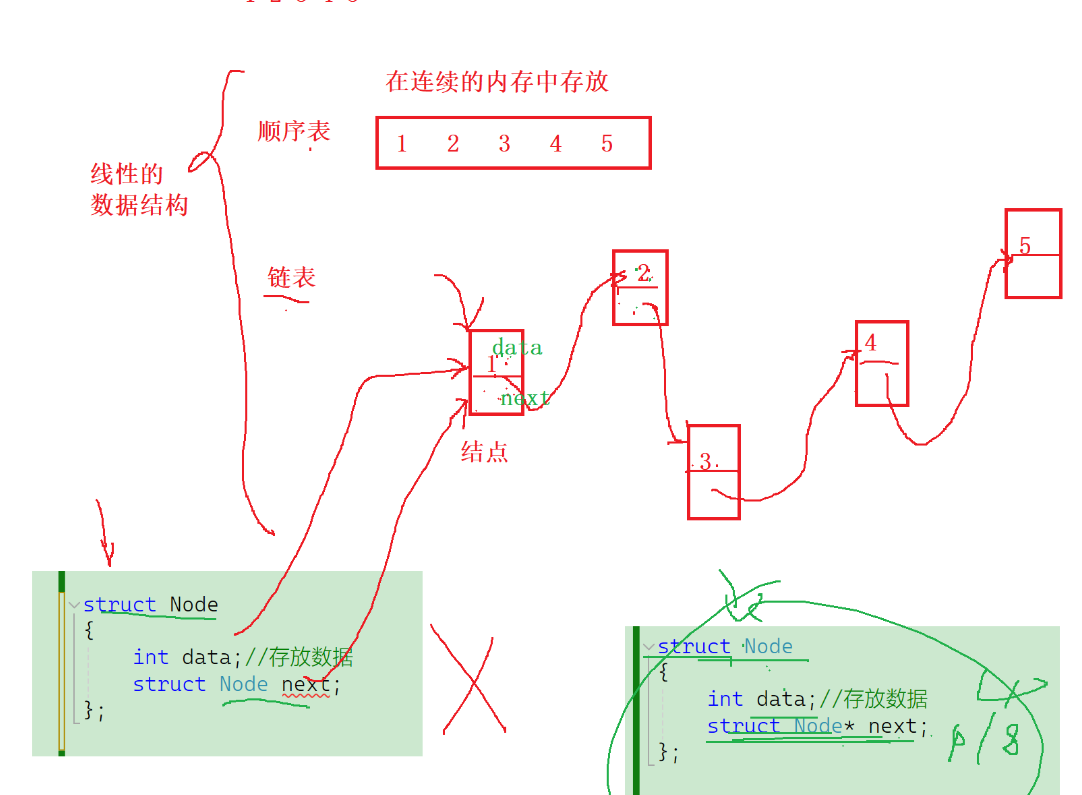
- 注意:這里有可能有的朋友們認為結構體的自引用難道不是直接在結構體的成員變量中引用自己同類型的下一個結構嗎?
- 那么請接收靈魂拷問:這種結構體的大小是多少?
- 自己里面有同時包含數據域還有一個自己,這就很矛盾了呀
- 那如果是結構體中同時包含數據域和指針域,這個結構體的大小就是可算的,數據域在內存中所占的字節數是可算的,指針的大小x86環境32bit是4字節,x64環境64bit是8字節
2、結構體的重命名
如果我們覺得結構體類型名字實在是太長了,想簡寫,就可以使用typedef來重命名,但是請注意順序問題。
typedef struct Node
{int a;//數據域struct Node* next;//指針域
}Node;
將結構體類型由struct Node重定義為Node
1)如果這樣使用結構體自引用看似合理卻隱含順序錯誤:
typedef struct Node
{int a;Node* next;
}Node;我們是先聲明了結構體struct Node,然后再去對其進行重命名的,而不是在創建的時候就可以直接用重命名后的結構體名稱了

四、結構體的內存對齊(筆試常考題,重要程度五顆星)
引言:請朋友們看這里兩段代碼,試著運行一下:
#pragma pack(8) //默認對齊數設置為8,編譯器本身就是8,不知道為什么我的編譯器沒有內存對齊現象,大家可以試試如果輸出結果是6 6 ,那么就需要加上這句話,如果是12 8,就不需要加上
struct S1
{char c1;int a;char c2;
}s1;
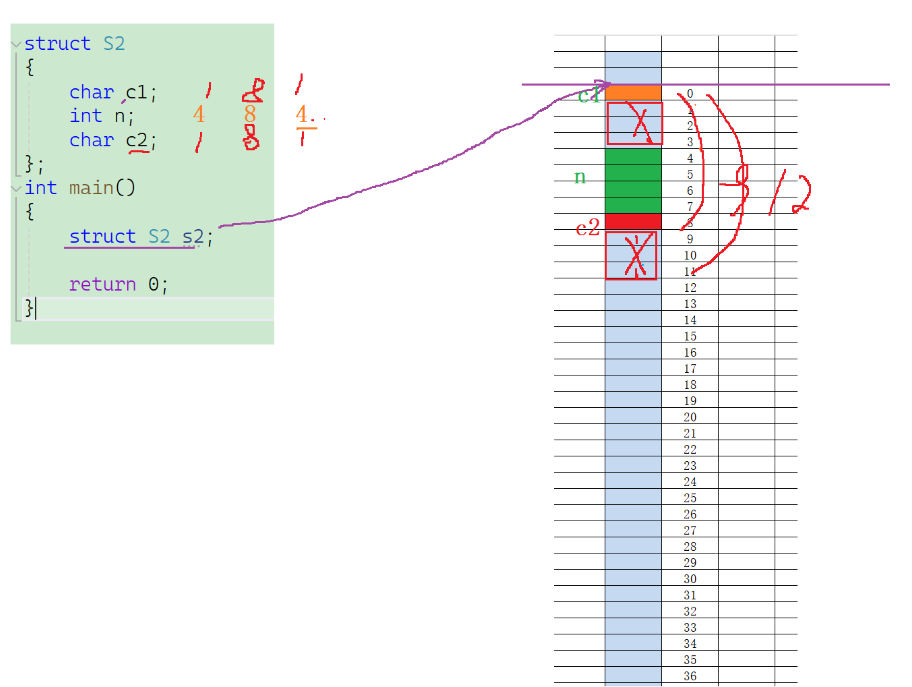
struct S2
{char c1;char c2;int a;
}s2;
int main()
{printf("%d\n", sizeof(s1));//printf("%d\n",sizeof(struct S1));printf("%d\n", sizeof(s2));//printf("%d\n",sizeof(struct S2));return 0;
}
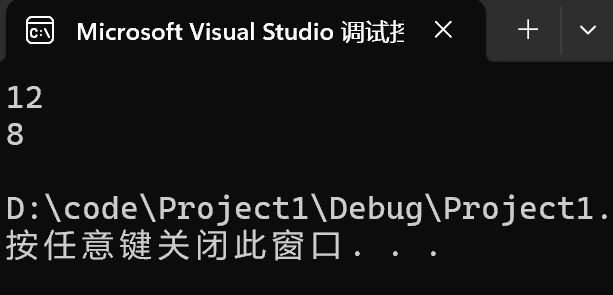
- 從運行結果可以看出,編譯器并不是按照結構體成員變量所占內存的字節數來分配內存空間的,因為結果并不是6
- 那么編譯器到底是如何將結構體變量在內存中分配空間的呢?(其實就是給結構體類型分配空間,結構體內部是成員變量,也就是給結構體類型的各個成員變量分配空間)
1、內存對齊
這個規則就叫做結構體內存對齊:
- 結構體的第?個成員對?到和結構體變量起始位置偏移量為0的地址處
- 其他成員變量要對?到某個數字(對?數)的整數倍的地址處。
對?數 = 編譯器默認的?個對?數 與 該成員變量??的較?值。
- VS 中默認的值為 8
- Linux中 gcc 沒有默認對?數,對?數就是成員??的??
- 結構體總??為最?對?數(結構體中每個成員變量都有?個對?數,所有對?數中最?的)的整數倍。
- 如果嵌套了結構體的情況,嵌套的結構體成員對?到??的成員中最?對?數的整數倍處,結構體的整體??就是所有最?對?數(含嵌套結構體中成員的對?數)的整數倍。
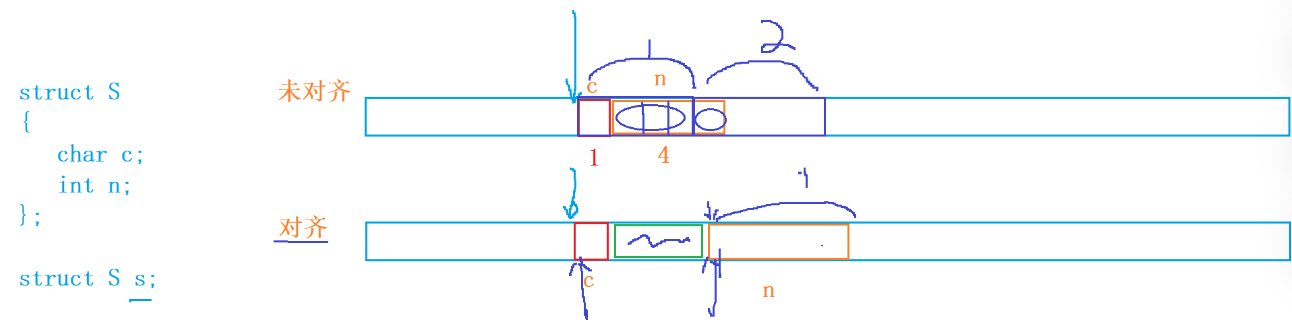
- 偏移量:從結構體變量在內存中開辟的空間的起始位置開始由0開始計數,第一個位置的偏移量是0,第二個位置偏移量為2…一直按照這個規則下去就形成了一段具標有偏移量的內存空間,如圖所示:

- 而結構體第一個成員對齊到偏移量為0的位置,也就是把c1放置在標號為0的位置
- 編譯器默認對齊數:編譯器自己決定的一個性質數,vs中默認是8,linux的gcc編譯器就默認是成員本身,并不存在對齊數,所以就是按照字節數來分配空間,最終的對齊數,等于編譯器默認對齊數和成員變量大小中的較小值,所以從第二個成員變量開始之后,每一個成員變量都是找對齊數,并且對齊到對齊數的整數倍的偏移量上,所以char c2就是對其到偏移量為1那,int n 自身大小是4,默認對齊數是8,最終對齊數是4,所以對齊到4的整數倍上就是偏移量是4那里開始
- 最終將空間分配成這個樣子:那么結構體的大小就是8字節啦占(8個內存空間,每個內存空間占1字節)
*
- 這段代碼的空間分配是這樣的,這里up就不算啦,大家可以按照剛剛講的方法試試呢~
- 第四條規則:關于嵌套結構體大小問題
- 如果嵌套了結構體的情況,嵌套的結構體成員對?到??的成員中最?對?數的整數倍處,這個外部的結構體的整體??就是所有最?對?數(含嵌套結構體中成員的對?數)的整數倍。
int main()
{struct S3{double d;char c;int i;};printf("%d\n", sizeof(struct S3));//練習4-結構體嵌套問題struct S4{char c1;struct S3 s3;double d;};printf("%d\n", sizeof(struct S4));return 0;
}
- 這里的struct S3大小是16字節,可以自己練習練習奧~
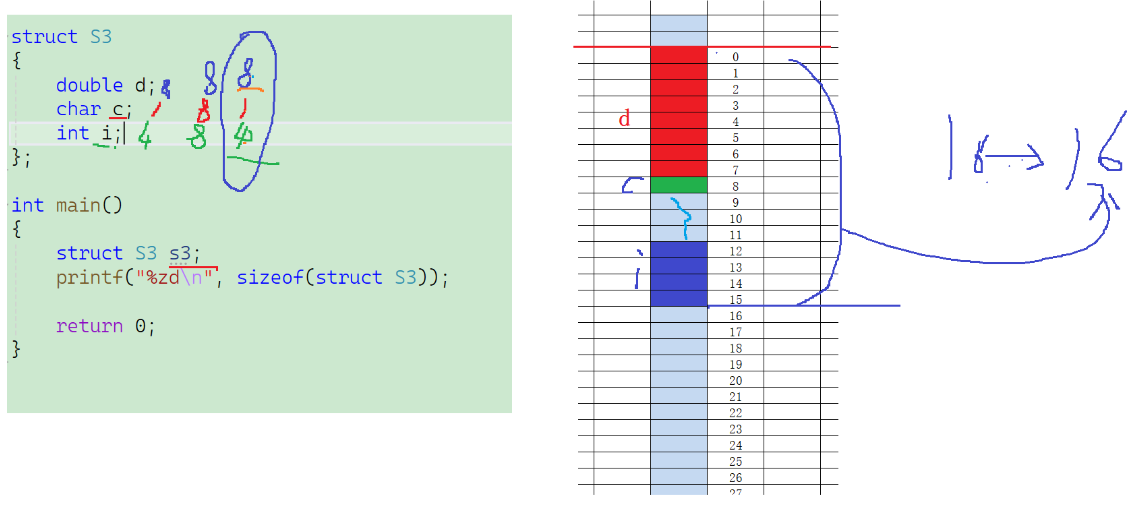
- d占8字節,從偏移量為0開始對其占8字節,到編號為7的位置停止
- c的大小1,默認對齊數8,最終對齊數是1,所以編號為8的偏移量是1的倍數,所以放在8位置
- i的大小是4,默認對齊數8,最終對齊數是4,所以對齊到4的倍數處,9并不是4的倍數,所以不能再9的位置進行對齊,而12是4的倍數,所以從偏移量為12的位置開始對齊占4字節,所以到編號為15的位置,目前大小是16(從0開始占空間數)
- 最終結構體的大小:所有的成員變量的最大對齊數是8,所以16是8的倍數,最終大小是16
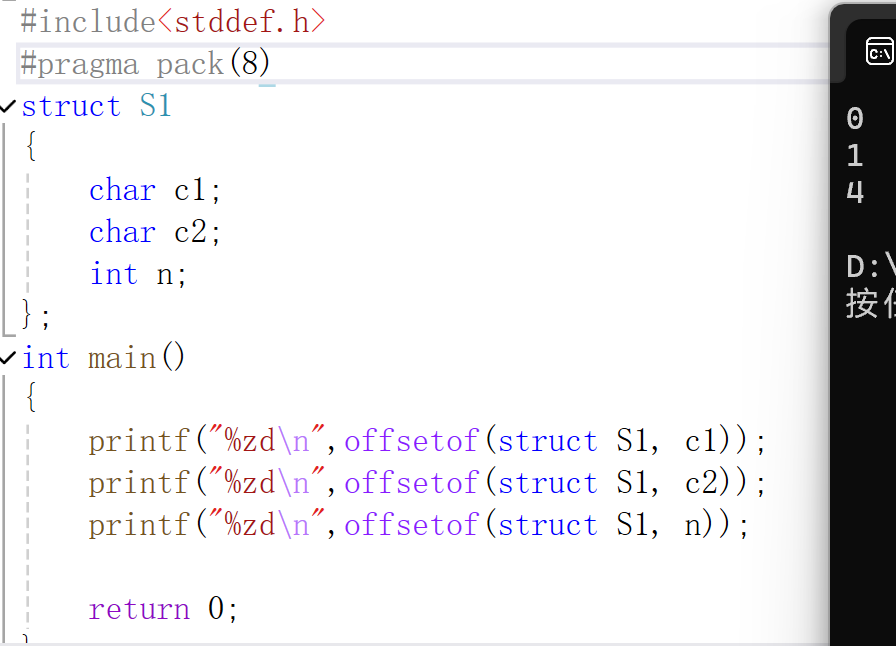
- c1是對齊到結構體起始位置偏移量為0的位置,
- 結構體S3對齊到他的成員變量中最大對齊數那,最大對齊數是8,所以最終從偏移量為8的位置開始對齊,+16,對齊到偏移量為23的位置
- d占8字節,對齊數8,所以從24開始對齊+8一直到編號為31的內存空間那,目前大小是32
- 最終大小是所有成員變量最大對齊數的最大值的倍數,32是8的倍數
2、介紹一個宏:offsetof
可以計算結構體成員或者聯合體相較于結構體變量起始位置或者是聯合體變量起始位置的偏移量,返回的是一個unsigned int也就是一個無符號整形,使用%zd打印
- offsetof(結構體類型,結構體成員變量)
和我們自己推測的在內存中的偏移量的起始位置是一致的:
五、為什么存在內存對齊呢?
?部分的參考資料都是這樣說的:
- 平臺原因 (移植原因):
不是所有的硬件平臺都能訪問任意地址上的任意數據的;某些硬件平臺只能在某些地址處取某些特定類型的數據,否則拋出硬件異常。
2.性能原因:(后面有詳細解釋):
- 數據結構(尤其是棧)應該盡可能地在?然邊界上對?。
- 原因在于,為了訪問未對?的內存,處理器需要作兩次內存訪問;?對?的內存訪問僅需要?次訪問。假設?個處理器總是從內存中取8個字節,則地址必須是8的倍數。
- 如果我們能保證將所有的double類型的數據的地址都對?成8的倍數,那么就可以??個內存操作來讀或者寫值了。否則,我們可能需要執?兩次內存訪問,因為對象可能被分放在兩個8字節內存塊中。
- 總體來說:結構體的內存對?是拿空間來換取時間的做法。
解釋:如果是一個32位機器,那么就有32根地址總線,每一根線都能讀操作或寫操作一個比特的地址,(讀操作,寫操作,以及數據是如何由內存傳入cpu進行處理的,相關知識點請看深入指針1哈)
1、那么就是一次操作4字節,如果不進行內存對齊就會導致你需要兩次訪問才能把n這個整形類型的變量訪問完全
2、如果對齊的,你只需要找到從4這個位置訪問4字節,一次就能完全訪問到n,但是相應的,它也會浪費一定的空間,相當于用空間換時間
1、如何更好的布局結構體呢?
那在設計結構體的時候,我們既要滿?對?,?要節省空間,讓占用空間小的成員盡量的集中在一起,這樣可以很有效的利用本應該被浪費掉的空間。
- 將c1和c2集中在一起,明顯結構體占用空間小了
- 注意:這里并不是說將小的成員變量都放在結構體的前邊的意思,只是說把小的成員都集中在一起!,位置倒是無所謂,可以自己試試n,c1 , c2這個順序,你會發現大小還是8
2、修改默認對齊數
#pragma 這個預處理指令,可以改變編譯器的默認對?數。
#include <stdio.h>
#pragma pack(1)//設置默認對?數為1
struct S
{char c1;int i;char c2;
};
#pragma pack()//取消設置的對?數,還原為默認
int main()
{//輸出的結果是什么?printf("%d\n", sizeof(struct S));return 0;
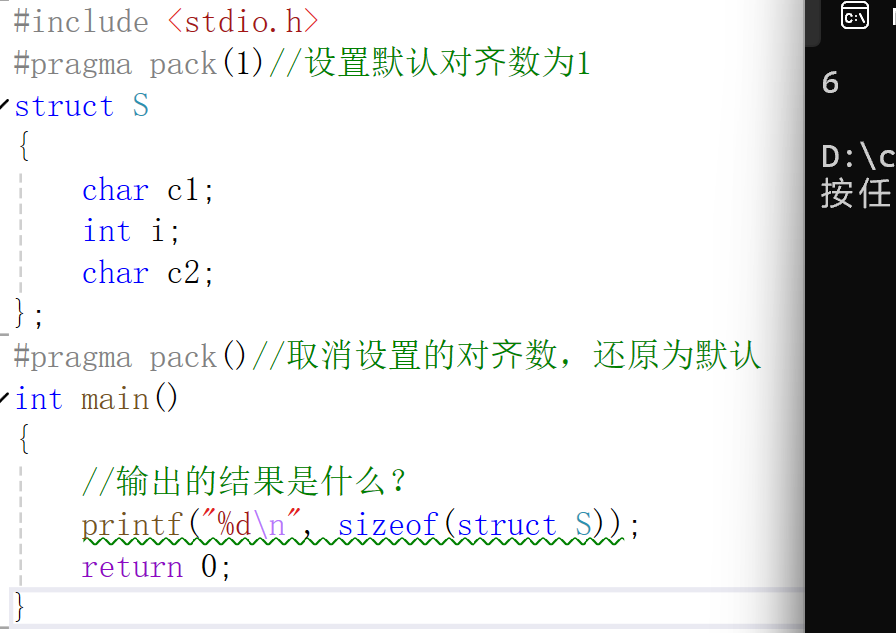
發現是6了,因為我們將對齊數修改為1了,就是緊挨著存放的意思,因為內存編號上的所有的值都是1的倍數嘛。
- 在函數內部的執行順序是這樣的:首先主函數,找到結構體s,從前往后編譯,默認對齊數被修改為1,計算出了大小是6,接著恢復了默認對齊數為8。
- 但是請注意,一般我們的默認對齊數都設置成2的次方數,1,2,4,8,16…等等,而不會設置為3,5,7等等。
3、結構體傳參
1、傳值調用
2、傳址調用
struct S {int a[10];float age;
};
void print1(struct S s1)
{int i = 0;for (i = 0; i < 10; i++){printf("%d ", s1.a[i]);}printf("\n");printf("%f", s1.age);
}
void print2(struct S* p)
{int i = 0;for (i = 0; i < 10; i++){printf("%d ", p->a[i]);}printf("\n");printf("%f", p->age);
}
int main()
{struct S s1 = { {1,2,3,4,5,6,7,8,9,10},20.0};print1(s1);//傳值調用printf("\n");print2(&s1);//傳址調用return 0;
}
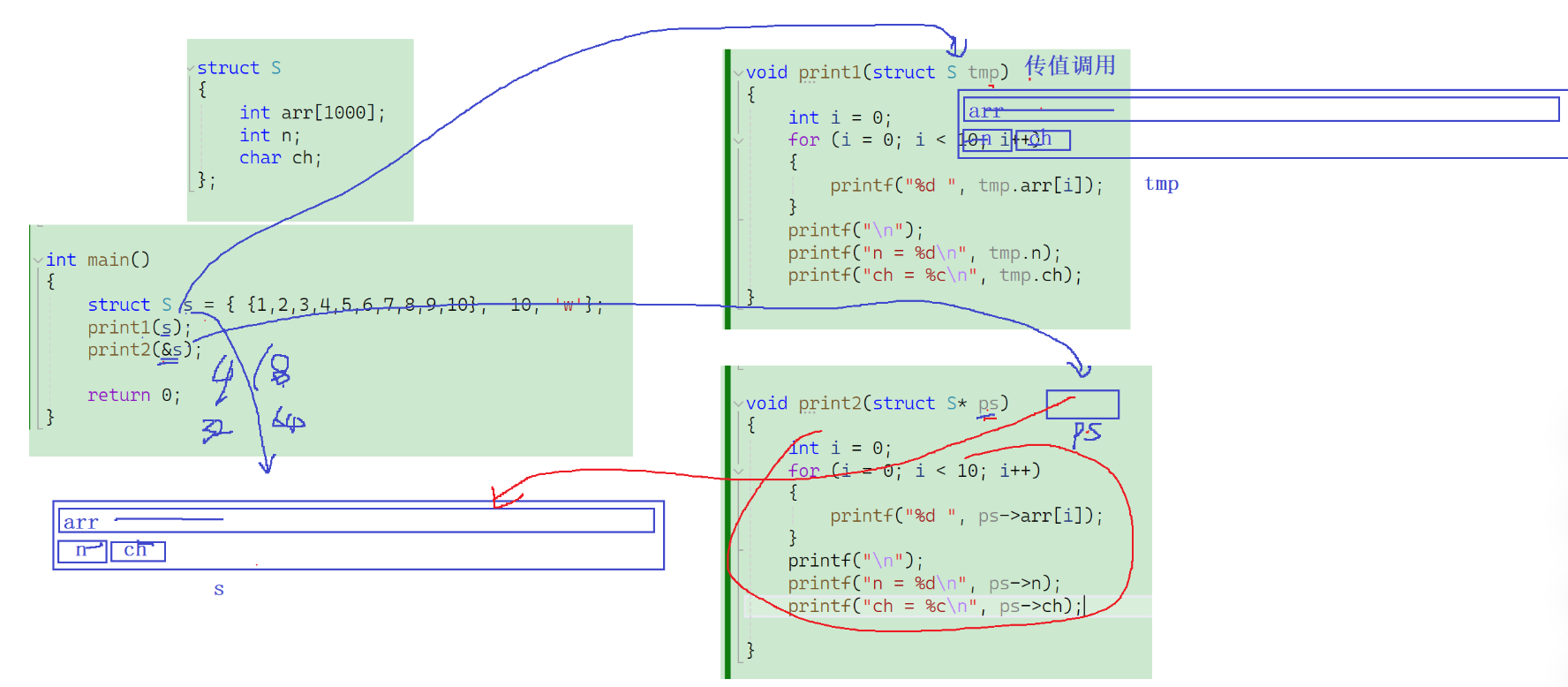
- 傳值調用:直接傳遞結構體名字,形參同樣使用結構體類型變量接收,形參是對實參的一份臨時拷貝,會在內存中開辟一份臨時的與實參等大的空間,在將實參中的數據拷貝出來進行函數處理,訪問通過點操作符,但是涉及到修改的地方是沒辦法在主函數中的原變量上體現的
- 傳址調用:&結構體名,傳遞結構地址,實參使用結構體類型指針接收,這個指針又有能力找到結構體,并且通過->能夠訪問結構體成員,并對其進行實質性的修改,可以實質性的對主函數中的相關變量修改
- 所以其實傳值調用能做的,傳址調用都可以做做到但是傳值調用未必能做傳址調用能做到的(比如在函數內部修改主函數中的值)
- ?選print2函數。
原因:
函數傳參的時候,參數是需要壓棧,會有時間和空間上的系統開銷。
如果傳遞?個結構體對象的時候,結構體過?,參數壓棧的的系統開銷?較?,所以會導致性能的下降。
結論:
結構體傳參的時候,要傳結構體的地址。
六、結構體實現位段
位段的聲明和結構是類似的,有兩個不同:
- 位段的成員必須是 int、unsigned int 或signed int或者char(本質上也是整形) ,在C99中位段成員的類型也可以選擇其他類型。
- 位段的成員名后邊有?個冒號和?個數字。位:指的是二進制位(bit),需要多大bit位空間就寫多少
- 如果是char類型一次給1個字節操作,如果是int類型一次給4字節操作
struct S//結構體本來應該是16字節大小
{int _a;int _b;int _c;int _d;
}
struct A//實現位段之后就是8字節
{int _a:2;int _b:5;int _c:10;int _d:30;
};
int main()
{printf("%zd", sizeof(struct A));return 0;
}
- 結構體中的每一個成員是int,本質上應該開辟4字節=32比特,但是這些bit位我并需要都用上,只需要用到一些,需要多少的比特位就在冒號后面寫多少就可以了
- 那么我們把位段中的位加在一起:47,那不應該是6字節嘛,哈哈別太過分啦,編譯器能壓縮到8字節已經很不錯了,肯定會有一些空間浪費掉了,那么接下來跟我一起看看8字節是如何得來的吧~
1、結構體位段在內存中的分配
讓我們看看這段代碼:
struct A
{char _a : 3;char _b : 4;char _c : 5;char _d : 4;
};
//A就是一個位段
int main()
{printf("%zd", sizeof(struct A));return 0;
}
-
是這樣的編譯器一次性是可以給開辟好空間的,這里我為了方便就一個字節一個字節拿出來給大家演示
-
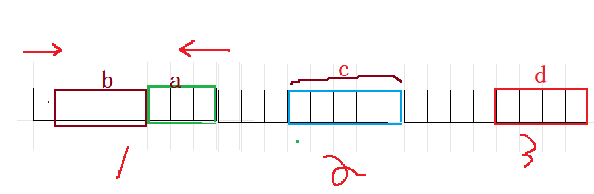
-
位段是有很多不確定性因素存在的:
-
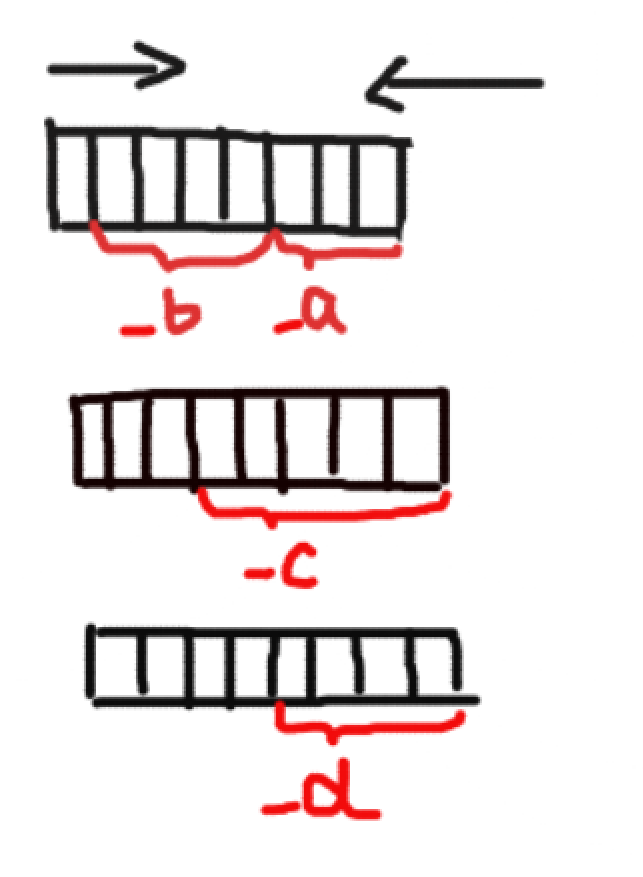
1、取出一個字節之后數據是由左向右還是由右向左,進行放入,是不確定的,取決于編譯器,假設:從右向左
-
2、如果一個字節剩余的比特位不夠放下一個位段成員,是繼續把剩余的比特位展占用,還是直接開辟一個新的字節空間進行使用是不確定的,假設浪費
-
運行結果是3,果然vs編譯器是這樣默認的
那么對其進行賦值是不是我們所說的從右向左賦值呢,并且不夠的位浪費掉呢,我們來驗證一下
struct A
{char _a : 3;char _b : 4;char _c : 5;char _d : 4;
}a1;
int main()
{a1._a = 10;a1._b = 12;a1._c = 3;a1._d = 4;return 0;
}
轉換為二進制位是(因為內存空間是一字節也就是8bit,所以放入數據要轉換為二進制放入,1個二進制位就是1個bit位):
- 10:1010
- 12:1100
- 3:11
- 4:100
推測一波是這樣放的:

- 由于a只開辟了3bit,所以存放的時候去掉最高位,注意這里都是這樣的把超出的位高位去掉,留下符合數目的低位,那么這里留下剩余的三位進行存儲,從右向左,剩余的空間補齊0,其余的以此類推
- 最后由于在內存中存放的值是以十六進制查看的,所以我們將每4個bit位化為一組得到一個16進制數
那我們查看一下內存空間中的值:
2、如何打開內存
按住F11,點擊調試–窗口–內存–窗口幾都行,在輸入&a1,就是找到a1在內存中的位置,好繼續觀察它在內存中存儲的值
繼續按F11,是進行一步一步調試用的,也就是程序一行代碼一行代碼執行,每次執行一行涉及到變量變化的,變量的值(監視窗口:打開方式一樣只是打開的是監視)和內存中的值(內存窗口)都會有所變化。

- 注意:這里采用了4列顯示,大家右上角也有個列,可以自行調整,每一列都是1個字節(2個16進制的數,1個16進制數是4bit,2個16進制數正好是8bit,也就是1個字節),這里我們推測是用了3字節我就拿出了4個字節的空間查看效果,如果是整形的話4字節,大家也可以設為4列來查看整形的值,char的話1字節,大家可以1列查看,當然4列也是可以查看到效果的。
- 大家在調試的過程中,執行完a1_a這句代碼,會顯示02 00 00 00,這是a的值被放入內存空間了,繼續按住F11,執行完a1_b發現,62 00 00 00,這是b的值被放入了…,所以大家看到了確確實實是在一個字節中從右向左賦值的
3、位段成員沒有地址
1、位段的?個成員共有同?個字節,這樣有些成員的起始位置并不是某個字節的起始位置,那么這些位置處是沒有地址的。內存中每個字節分配?個地址,?個字節內部的bit位是沒有地址的。
2、所以不能對位段的成員使?&操作符,這樣就不能使?scanf直接給位段的成員輸?值,只能是先輸?放在?個變量中,然后賦值給位段的成員。
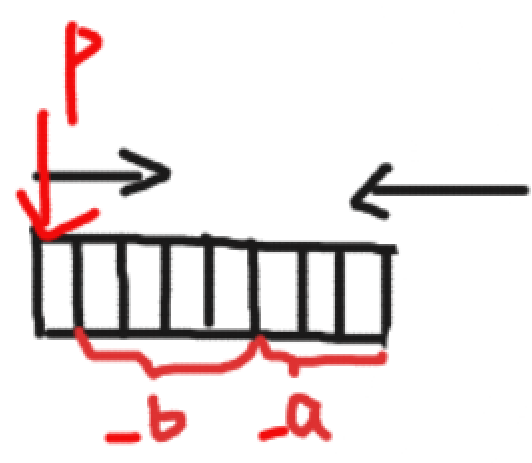
struct A
{char _a : 3;char _b : 4;char _c : 5;char _d : 4;
}a1;
//A就是一個位段
int main()
{int a = 10;scanf("%d",&a);a1._a = a;//正常scanf("%d", &a1._b);//報錯return 0;
}
4、位段的不跨平臺性
因為具有這些不跨平臺性,所以要跨屏平臺時,別使用位段
它既具有了在能實現結構體功能的基礎上再減少空間,又帶來了不跨平臺的風險
- int 位段被當成有符號數還是?符號數是不確定的。
在位段中,如果位段成員是int類型就一次開辟4個字節進行操作,那么這四個字節的第一個bit位是0還是1是不確定的
- 位段中最?位的數?不能確定。(16位機器最?16,32位機器最?32,寫成27,在16位機器會出問題。
在早期的16位機器中,int的大小是2字節,所以位段成員如果是int類型就必須不能超過16個bit,那么
int _d:30;這個代碼在16位機器上就是報錯的,在32位機器上就是正常的
- 位段中的成員在內存中從左向右分配,還是從右向左分配,標準尚未定義。
- 當?個結構包含兩個位段,第?個位段成員?較?,?法容納于第?個位段剩余的位時,是舍棄剩余的位還是利?,這是不確定的。
5、位段的應用
下圖是?絡協議中,IP數據報的格式,我們可以看到其中很多的屬性只需要?個bit位就能描述,這?使?位段,能夠實現想要的效果,也節省了空間,這樣?絡傳輸的數據報??也會較??些,對?絡的暢通是有幫助的。網路好比高速公路,如果都是一些小的數據,那么傳輸效率高,如果封裝的很大,數據也多就會造成擁堵。
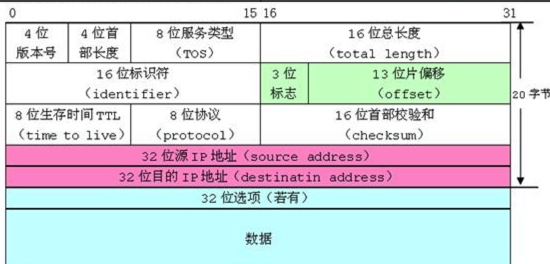
簡易的講解一下意思:計算機pc端1的用戶發送了一條呵呵的短信,他怎么能夠保證發送到你室友那,而不是發送給你的女朋友呢
計算機網絡體系結構有許多層,每一層都有相應的功能,保證著你的數據正確發送,而每一層都有自己的數據格式,那么每一層就需要將要發送的數據進行加工(封裝)上自己這一層的功能與格式之后進行相應處理,在繼續傳送數據,而到了網絡層如果使用IP協議(協議就是使得計算機數據能夠按照規定進行傳輸的約定),我們給它就數據封裝上了數據上面的這些東西
類比一下你想發一個易碎的杯子快遞,就需要層層給快遞封裝上泡沫,膠布,等等,還需要填寫上相應的信息作為格式,如果你只是發一個很小的,那么我拿一個很大的箱子給你封裝上就是浪費了,所以需要多少我就封裝多大就可以了,那么位段同樣也是這個道理,這回再去看開頭的就比較好理解了
)
之 概念名詞)




)





)



 -part7)


