c語言修煉秘籍 - - 禁(進)忌(階)秘(技)術(巧)【第七式】程序的編譯
【心法】
【第零章】c語言概述
【第一章】分支與循環語句
【第二章】函數
【第三章】數組
【第四章】操作符
【第五章】指針
【第六章】結構體
【第七章】const與c語言中一些錯誤代碼
【禁忌秘術】
【第一式】數據的存儲
【第二式】指針
【第三式】字符函數和字符串函數
【第四式】自定義類型詳解(結構體、枚舉、聯合)
【第五式】動態內存管理
【第六式】文件操作
【第七式】程序的編譯
文章目錄
- c語言修煉秘籍 - - 禁(進)忌(階)秘(技)術(巧)【第七式】程序的編譯
- 前言
- 一、程序的翻譯環境和執行環境
- 二、詳解編譯和鏈接
- 1. 翻譯環境
- 2. 編譯本身也分為幾個階段
- 編譯
- 預編譯:
- 編譯:
- 匯編:
- 鏈接
- 3. 運行環境
- 三、預處理詳解
- 1. 預定義符號
- 2. #define
- 2.1 #define 定義標識符
- 2.2 #define 定義宏
- 2.3 #define 替換規則
- 2.4 #和##
- 2.5 帶副作用的宏參數
- 2.6 宏和函數的對比
- 3. #undef
- 4. 命令行定義
- 5. 條件編譯
- 6. 文件包含
- 總結
前言
在本章會對程序的編譯過程,進行詳細的講解,重點包括:
- 程序的翻譯環境
- 程序的執行環境
- c語言程序的編譯+鏈接
- 預定義符號介紹
- 預處理指令#define
- 宏和函數的對比
- 預處理操作符#和##的介紹
- 命令定義
- 預處理指令#include
- 預處理指令#undef
- 條件編譯
一、程序的翻譯環境和執行環境
在ANSI C的任何一種實現中,都存在兩種不同的環境
第1種是翻譯環境,在這個環境中源代碼被轉換為可執行的機器指令;
第2種是執行環境,它用于執行代碼;
下圖簡單的表示了這兩個環境的作用:

二、詳解編譯和鏈接
1. 翻譯環境
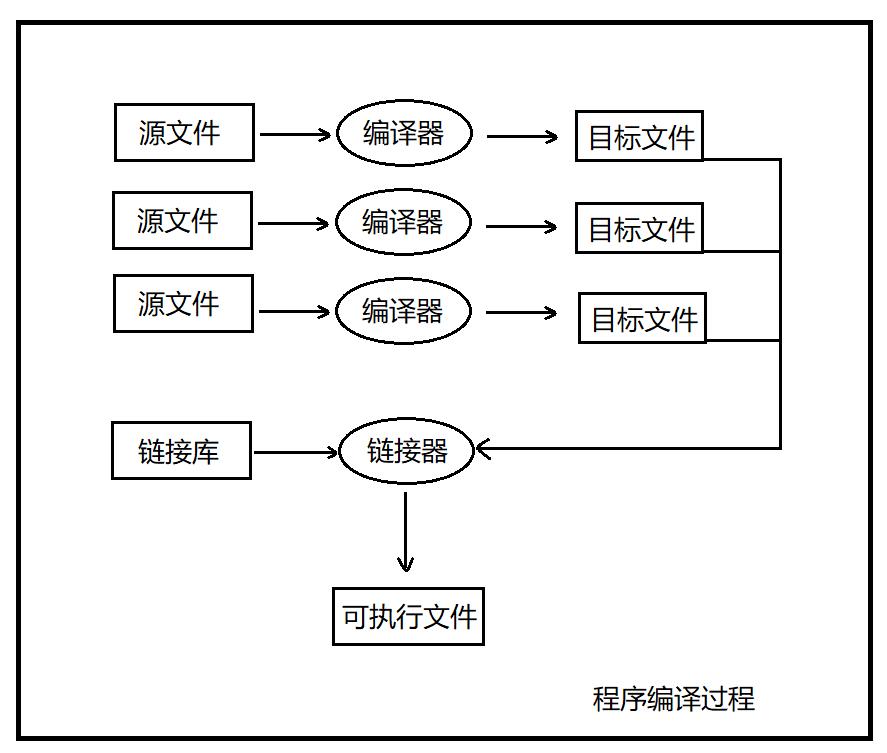
- 組成程序的每個源文件通過編譯過程分別轉換成目標代碼(object code);
- 每個目標文件由鏈接器(linker)捆綁在一起,形成一個單一而完整的可執行程序;
- 鏈接器同時也會引入標準c語言庫中任何被該程序使用到的函數,而且它可以搜索程序員個人的程序庫,將其需要的函數也鏈接到程序中;
以之前寫過的通訊錄程序為例子:
該程序有2個源文件:contact.c、test.c,這兩個源文件在翻譯環境中單獨進行翻譯生成對應的目標文件(后綴為.obj);
即生成contact.obj和test.obj
之后這些生成的目標文件將會一起經過鏈接器,鏈接在一起生成一個可執行程序,在這個過程中,還會將程序會使用到的庫函數一起鏈接進來。
所以翻譯環境中,代碼經歷的過程又可以分為兩步,編譯和鏈接:
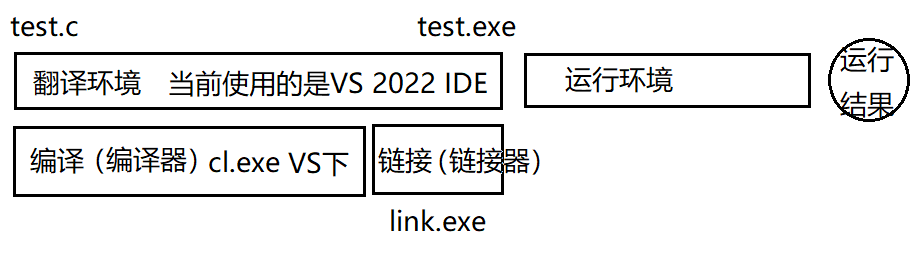
在VS使用的編譯器是cl.exe,使用的鏈接器是link.exe;
2. 編譯本身也分為幾個階段
編譯過程還可以詳細的分為3個步驟:預編譯(預處理),編譯,匯編;
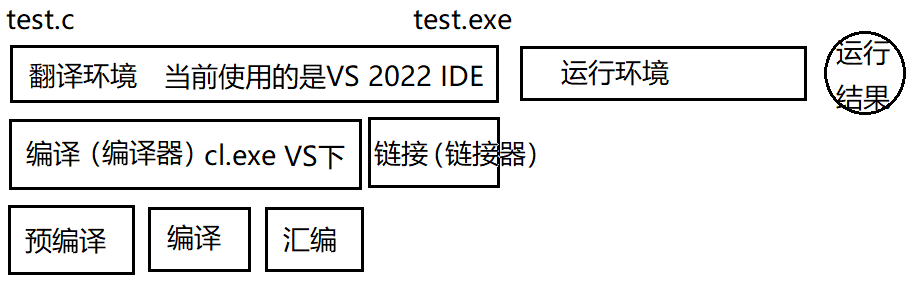
接下來我們會對這三個步驟逐個的詳細討論(在linux環境下進行):
編譯
示例代碼如下:
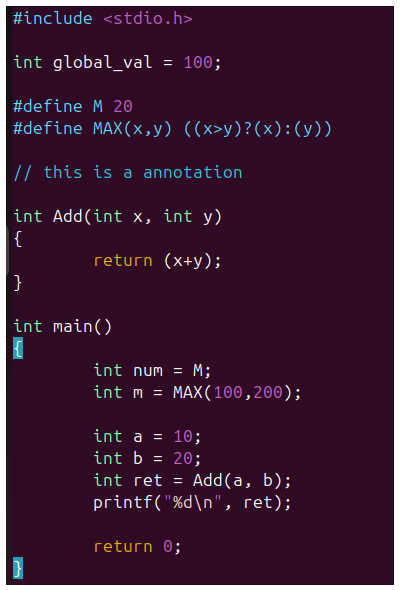
預編譯:
gcc test.c -E 這個命令的作用是讓源文件在預處理之后就停下;這條命令不生成文件,可以使用重定向將命令執行結果輸出到一個文件中;這里使用gcc test.c -E > test.i將該命令等到的信息輸出到test.i這個文件中;后綴為.i的文件是預處理后得到的文件;
打開得到的文件可以看到如下的結果:

在此之前還有很多內容,僅截取部分;可以發現我們并不能看懂這部分的內容;
在它之后的內容我們就能看懂了,這是我們的代碼:

可以看到在我們的代碼之前多出來了一大堆東西,但是少了一條語句 - #include <stdio.h>
在我們的心法篇中介紹了#include包含的頭文件會以替換的形式將頭文件中的內容包含進行源代碼中,所以上面那一大堆代碼其實就是頭文件stdio.h中的內容。
那么我們就來驗證一下,看看上面的內容到底是不是stdio.h中的內容,可以看到stdio.h的地址是/usr/include,我們打開這個文件比較一下,兩者是否相同。

此目錄下確實存在這個文件,接下來看看文件的內容:
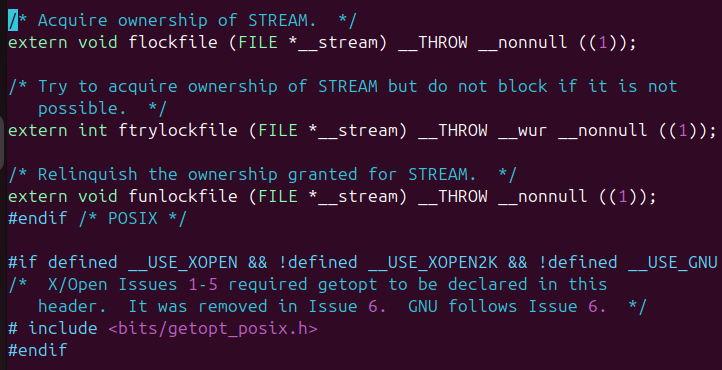
可以看到之前的確實是stdio.h拷貝到test.c中的內容;
接下來我們就來看看,預處理過程究竟做了什么?
從上圖中我們可以看出,預處理
- 完成了頭文件的包含#include;
- 完成了#define定義的符號和宏的替換
- 刪除了所有注釋;
總結一下,預處理過程完成了源文件到目標文件過程中所有的文本操作;
編譯:
gcc test.c -S,此命令的作用是對test.c這個文件進行預處理和編譯;也可以使用gcc test.i -S,這個命令可以得到同樣的結果;命令執行之后會得到一個test.s

大概看一下test.s中有什么內容:
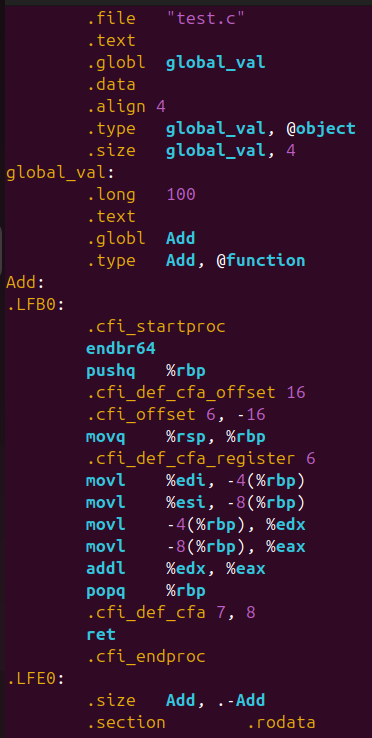
在預處理階段,得到的文件仍是一個c語言代碼,經過編譯之后就得到了像上面一樣的匯編代碼;
這個過程中會進行語法分析、詞法分析、語義分析、符號匯總;這4個步驟分別會做些什么,這里就不詳細介紹,具體內容請自行學習編譯原理;這里僅作簡單介紹;
從上面的圖片中我們得知,編譯的過程就是將c語言代碼轉換成匯編代碼的過程;這個轉換的過程是由計算機來完成的,這也意味著計算機需要能夠“讀懂”c語言代碼;那么要讀懂c語言代碼需要做到什么呢?首先需要知道每個語句表示什么,比如,這個東西是一個變量,那個是一個for循環,這就是語法分析大概要完成的事情;除此之外,還需要對每個語句進行拆分,比如,將一個for循環語句中拆分出for關鍵字,變量名等等;在知道了語法和詞法之后,還需要知道一個語句表示的是什么意思,這就是語法分析要做的事;至于符號匯總,我們放在匯編中再作介紹;
匯編:
使用gcc test.c -c可以將對源文件進行預編譯、編譯和匯編,生成test.o文件,相當于windows系統中的.obj文件,也就是目標文件;

那么我們打開這個test.o文件看看里面保存的是什么;
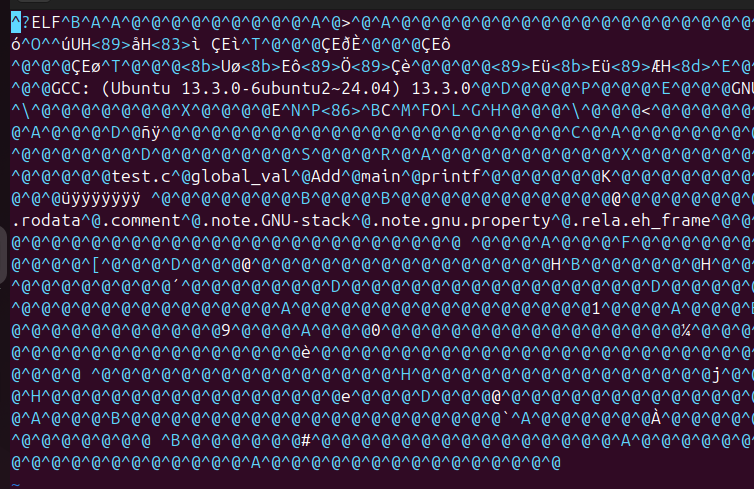
test.o文件打開之后就是一堆亂碼,也就是test.o是一個二進制文件;
所以匯編過程的作用是將匯編代碼轉換成了機器指令(二進制指令);
在這個過程中除了上面我們能看出來的將匯編代碼轉換為機器指令之外,還有一件非常重要的事情:生成符號表;
在這里需要生成的符號表和上一步中的符號匯總有什么聯系呢?
在說明上面的聯系之前,我們要先知道test.o文件的是一種elf類型的文件,這是一種分段的文件,代碼的符號表就保存在這種文件的符號段中,使用readelf test.o --syms就可以獲取到這個目標文件的符號表:
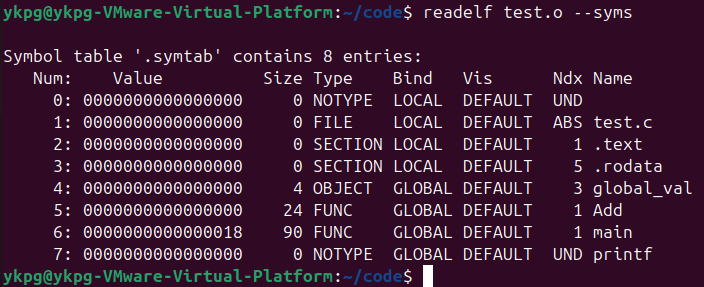
對其進行分析:
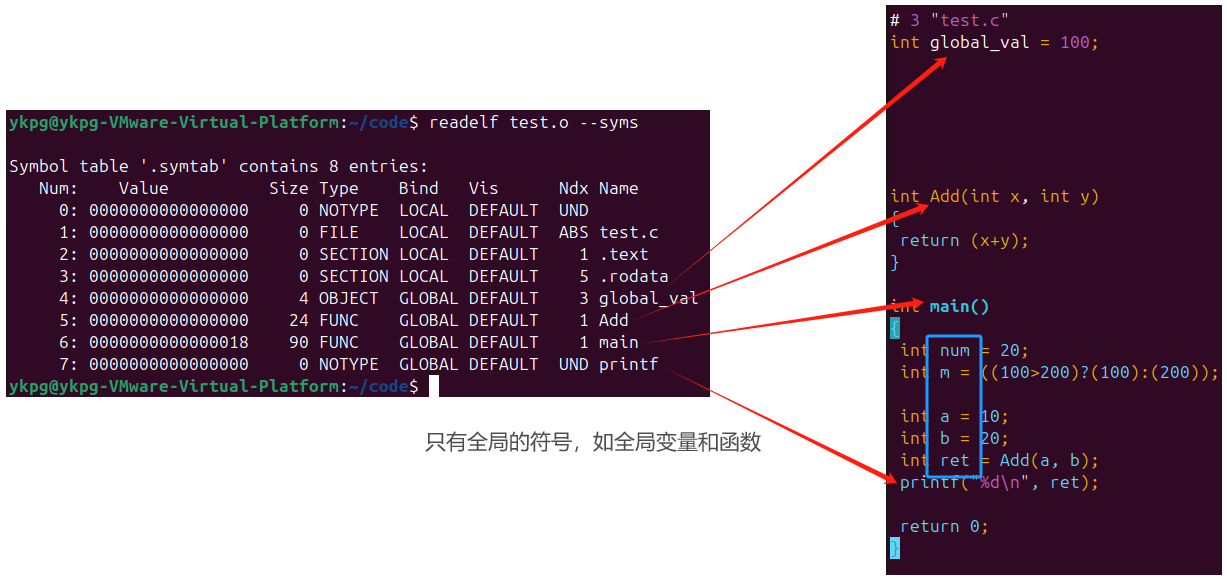
從上圖中可以看到,匯編過程中得到的符號表中僅有一些全局的符號,而這些符號又是在編譯過程的符號匯總中匯聚在一起的,這一步會將整個程序中所有源文件中存在的全局符號全部匯總在一起,之后再進行處理;
為了能更加清楚的展示編譯過程會將符號匯總,在匯編過程中會生成對應的符號表,下面重新在對test.c和add.c進行編譯:
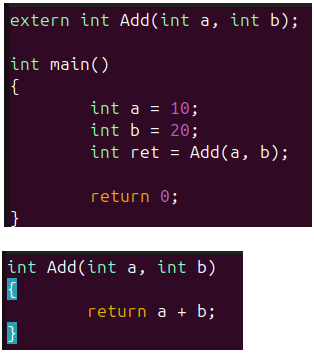
分別對它們進行編譯:
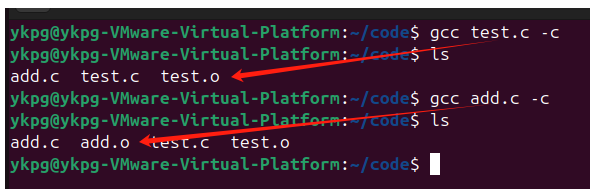
查看它們生成的符號表:
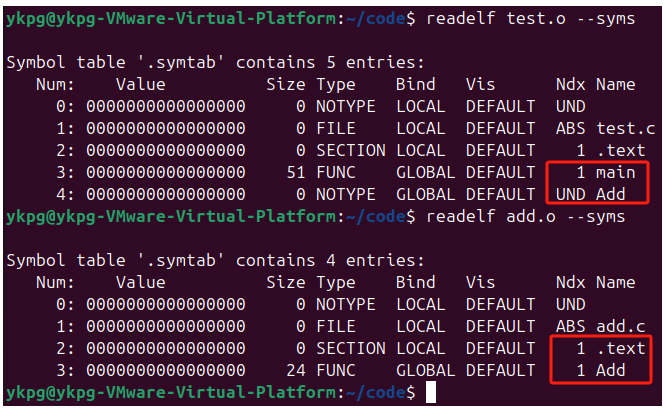
可以看到在test.o的符號表中也有Add這個符號,但是實際上它并知道這個符號的地址是什么,只是給它填充一個沒有意義的地址;
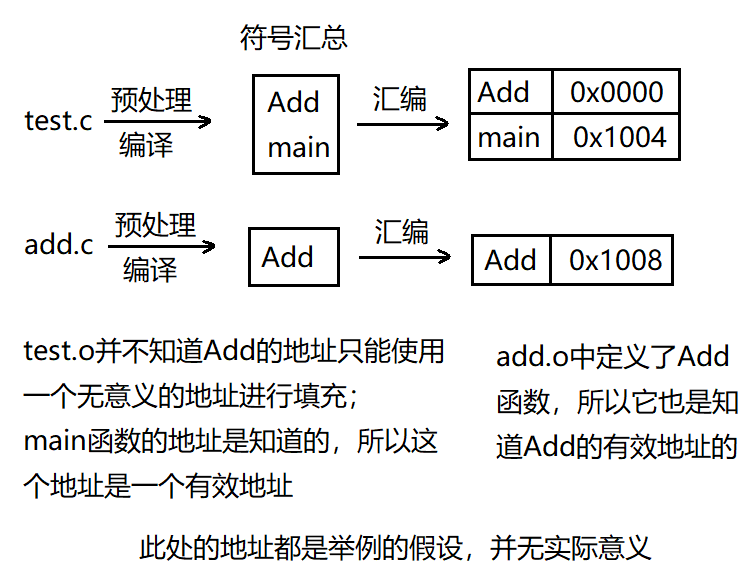
可以看到單獨生成的test.o和add.o中都包含有符號Add,只是一個的地址是有效的,一個是無效的;但是這兩個符號在生成可執行程序時,到底使用哪一個呢?這一步就交到鏈接器來完成;
鏈接
在鏈接階段,鏈接器會將多個目標文件和鏈接庫進行鏈接,生成一個可執行文件;在上面的例子中,僅有兩個目標文件,test.o和add.o,沒有鏈接庫,所以在此程序中,鏈接操作的作用就是將這兩個目標鏈接成一個可執行文件a.out(可以通過參數設置,修改生成的可執行文件的名字),linux系統中;命令:gcc test.o add.o -o test.out生成一個名為test.out可執行文件;(注意,linux系統中并不以后綴名來區分文件是否可執行,而通過文件權限和文件格式(必須是elf格式)來區分,可以看到test.out文件是有執行的權限的X標志);
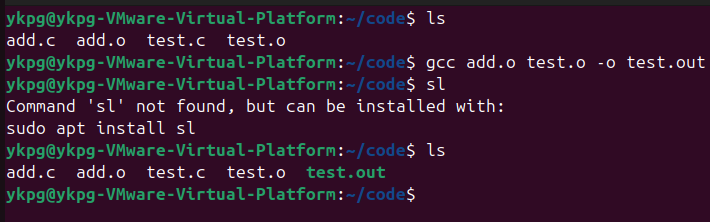
該階段會進行的具體操作可分為:
- 合并段表;
- 符號表的合并和重定位;
因為,可執行文件的格式也是elf,所以在由多個目標文件生成可執行文件過程中,需要將這些文件中相同段中的內容進行合并,這就是合并段表;
而符號表的合并和重定位就更容易理解了,在介紹匯編時,我們提到了test.o和add.o這兩個文件和符號表中都有Add這個符號,在兩個目標文件合并成一個可執行文件的過程中,這兩個Add肯定只能保留一個,也就是保留那個有著有效信息的Add,將另一個無效的Add刪除,并將Add的地址保存為add.o中的地址;簡單來說就是將多個目標文件的符號進行合并,并將有效的符號進行保留;
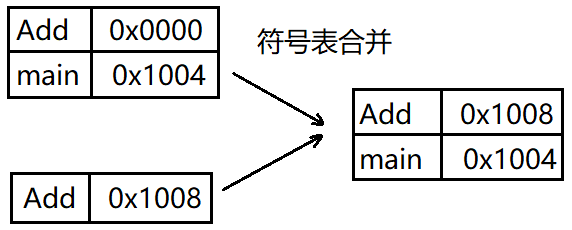
看到這里的同學肯定會疑惑,這個符號表有什么用呢?
這個符號表可以使得程序能夠通過它們找到并使用對應的符號,比如,程序要調用Add函數時,就會到符號表中找Add這個符號的地址,也就是0x1008,之后程序通過這個地址調用了Add函數,完成了功能;
下面我們在VS環境中舉個例子幫助大家更好的理解這點。
將add.c中所有內容注釋掉,此時add.c變成了一個空文件,在匯編之后會生成一個空的符號表,test.c文件仍會生成包含兩個符號的符號表,其中符號Add的地址是無效地址;
此時進行編譯就會出現以下的錯誤:
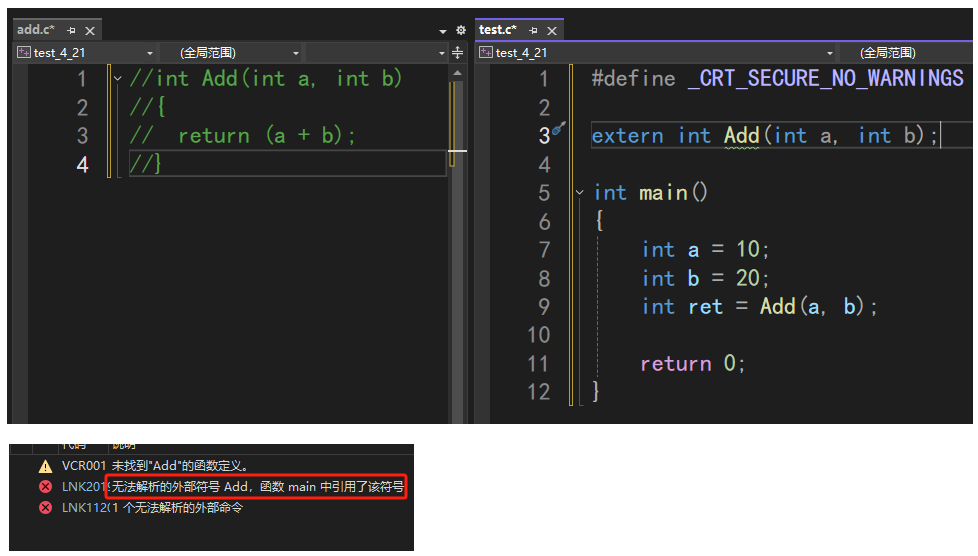
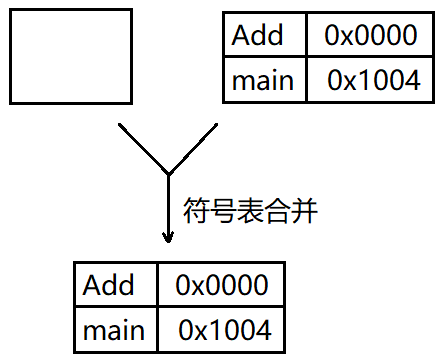
在鏈接時,通過合并的符號表尋找Add函數時,鏈接器去往0x0000這個地址會發現并沒有Add這個函數存在,也就發生了錯誤;
正是因為有了符號表的存在,跨文件的函數調用才得以實現;
總結
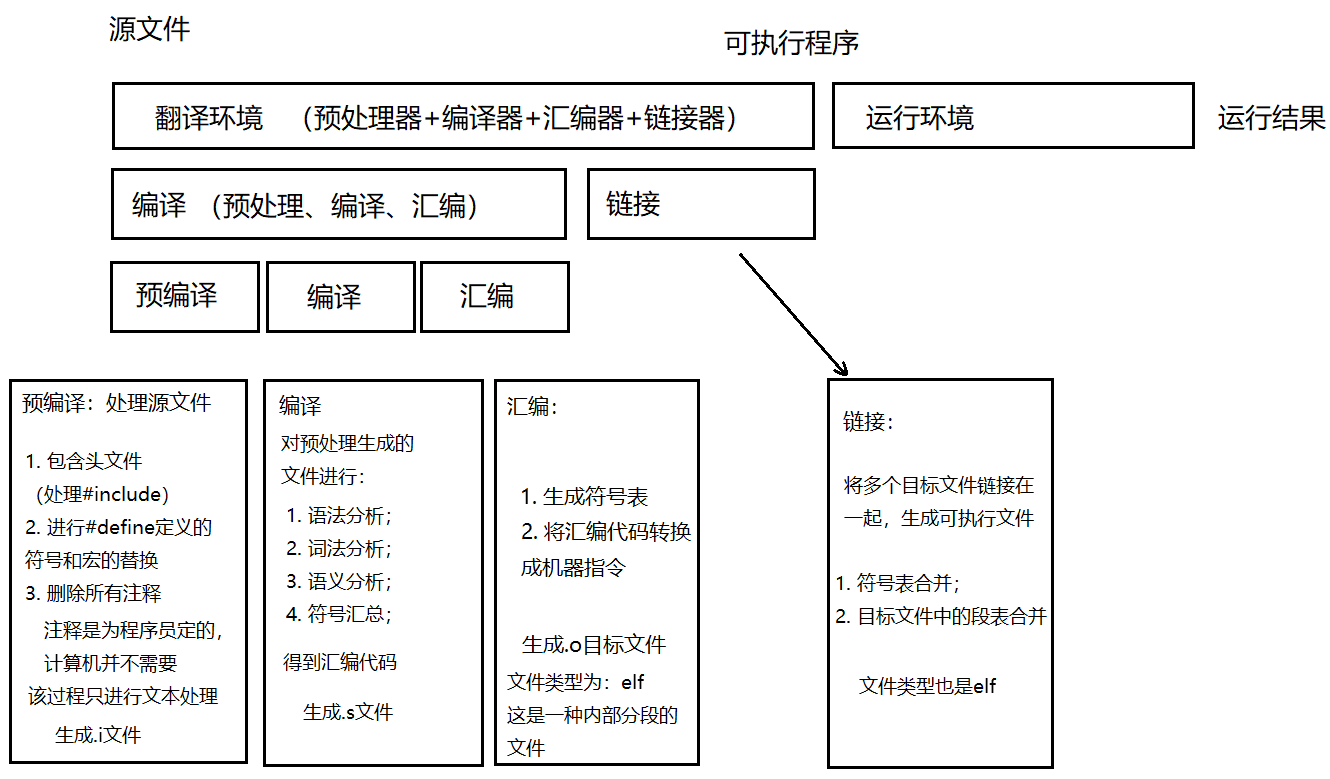
翻譯過程可以分為編譯和鏈接兩個步驟,其中編譯又可以分為,預編譯、編譯、匯編三個步驟;
它們使用的命令分別是:gcc -test.c -E、gcc -test.c -S、gcc -test.c -c;
預編譯過程進行文本操作(test.i),編譯過程將c語言代碼轉換成匯編代碼(test.s),匯編過程將匯編代碼轉換成機器指令(目標文件,test.o);最后由鏈接器將這些目標文件鏈接成一個可執行文件;
一圖流:
3. 運行環境
程序運行的過程:
- 程序必須載入內存中才可以運行;在有操作系統的環境中,該步驟一般由操作系統來完成;在獨立的環境中,程序的載入要么手動操作,要么通過可執行代碼置入只讀內存來實現;
- 程序的執行便開始。接著調用main函數;
- 開始執行程序代碼。此時程序將使用一個運行時堆棧(stack),存儲函數的局部變量和返回地址。程序同時也可以使用靜態內存(static),存儲于靜態內存中的變量在程序執行整個過程中一直保留它們的值;
- 終止程序。正常終止main函數;有時候也可能是意外終止;
關于運行時堆棧,這里僅簡單介紹,想要詳細了解,大家可以去看之前的文章內容,里面有詳細介紹;在心法篇中的函數和秘術篇的動態內存分配里都有介紹;
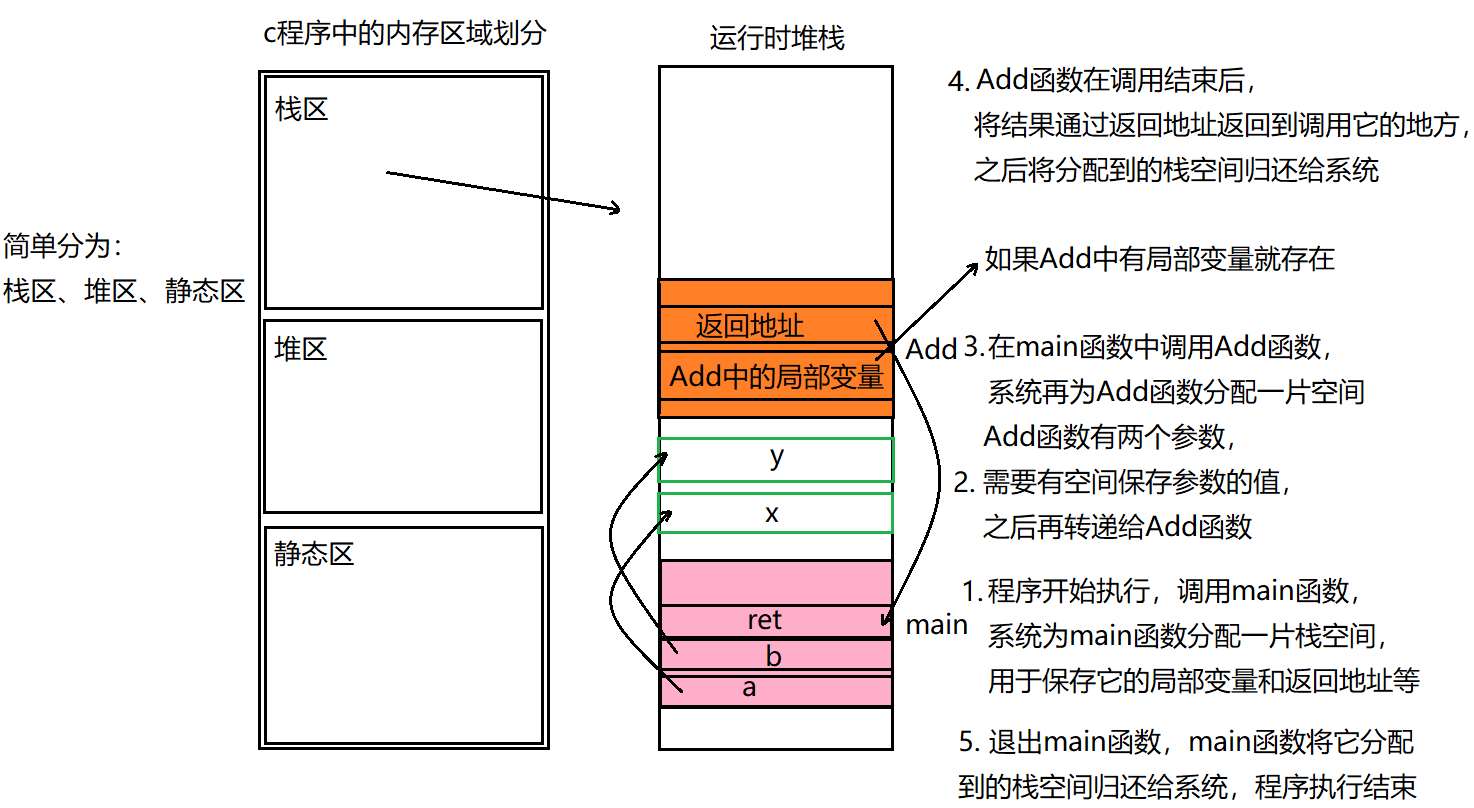
注意:堆棧指的就是棧,并不是堆+棧;
三、預處理詳解
1. 預定義符號
__FILE__ // 進行編譯的源文件
__LINE__ // 文件當前行號
__DATE__ // 文件被編譯的日期
__TIME__ // 文件被編譯的時間
__STDC__ // 如果編譯器遵循ANSI C,其值為1,否則未定義
__FUNCTION__ // 當前函數
這些預定義符號都是語言內置的。
舉個例子:
#include <stdio.h>int main()
{printf("file:%s\n", __FILE__);printf("line:%d\n", __LINE__);printf("date:%s\n", __DATE__);printf("time:%s\n", __TIME__);printf("function:%s\n", __FUNCTION__);// printf("STDC:%s\n", __STDC__); // VS 2022 未定義return 0;
}
運行結果:
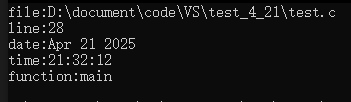
這些內置符號具體有什么用呢?
可以用來寫程序日志,在日志中記錄時間和代碼行號,在出錯時,就可以非常方便的定位錯誤原因;就算是正常運行過程中,寫日志也是一個非常重要的事,它可以讓你可以了解程序當前是運行狀態,檢查可能出現的一些問題;
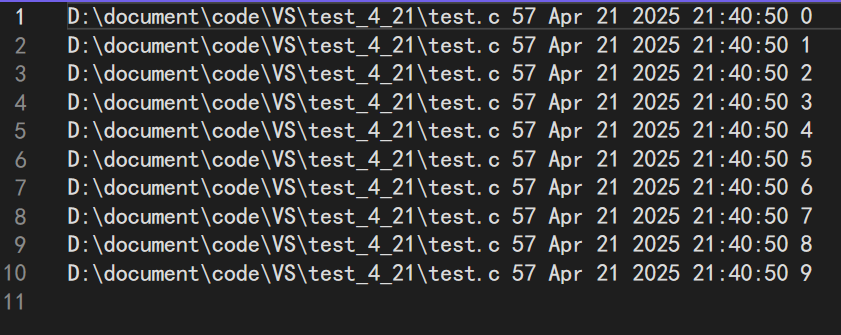
下面我們給出一個記錄日志的例子供大家參考:
#include <stdio.h>int main()
{// 記錄日志,就是在寫文件// 將程序執行的信息輸出到log.txt中FILE* pf = fopen("log.txt", "a");if (pf == NULL){perror(pf);return ;}int i = 0;for (i = 0; i < 10; i++){// 記錄每行的信息fprintf(pf, "%s %d %s %s %d\n", __FILE__, __LINE__, __DATE__, __TIME__, i);}fclose(pf);pf = NULL;return 0;
}
文件內容:
2. #define
2.1 #define 定義標識符
語法:
#define name stuff
示例:
// #define 定義標識符
#define MAX 100 // 定義一個數字
#define uint unsigned int // 有時一個關鍵字較長,可以創建一個更簡短的方式
#define do_forever for(;;) // 用更形象的符號來替換一個種實現,這里實現的是一個死循環
#define CASE break;case // 在寫case語句的時候自動把 break寫上;// 因為有此語言中switch語句不用加break,習慣了這些語言的程序員可能在使用c語言時,// 害怕自己忘記添加break導致程序出錯,就可以使用這種標識符
// 如果定義的stuff過長,可以分成幾行來寫,除了最后一行外,每一行的后面都加上一個反斜杠 \ (續行符)
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n", \__FILE__, __LINE__, \__DATE__, __TIME__)#include <stdio.h>int main()
{uint i = MAX;// do_forever; // 相較于,for(;;);,該語句以一個更清楚的方式,實現了一個死循環int input = 0;scanf("%d", &input);// 代碼1switch (input){case 1:CASE 2:CASE 3:}// 代碼2switch (input){case 1:break;case 2:break;case 3:}// 代碼1和代碼2完全等價DEBUG_PRINT;return 0;
}
大家可能在使用#define定義標識符時,會產生一個疑問,在標識符后面需不需要加上一個分號;呢?
比如:
#define MAX 1000;
#define MAX 1000
這兩種定義方式有什么不同呢?
我們都知道,#define定義的標識符是在預處理階段直接進行文本替換的;
放在代碼中:
int main()
{int a = MAX; // 使用第一種定義方式時,這個代碼會變成 int a = 1000;;// 賦值語句之后還有一個空語句,在這里語法是沒有什么問題的,// 但是換一種情況就會產生問題if(condition)max = MAX; // 在這里一條if語句只能對應一條語句,但是這里有了兩條語句,產生了語法錯誤elsemax = 0;
}
所以我們在使用#define定義標識符時,一般都不會在后面添加;
2.2 #define 定義宏
#define 機制包括了一個規定,允許把參數替換到文本中,這種實現通常稱為宏(macro)或定義宏(define macro);
下面是宏的申明方式:
#define name(parament-list) stuff
// parament-list是一個逗號隔開的符號表,它們可能出現 stuff中
注意,參數列表的左括號必須與name緊鄰;如果兩者之間存在有任何空白存在,參數列表就會被解釋為stuff的一部分,就變成了#define定義的標識符了
使用示例:
// 定義一個宏來計算平方
#define SQUARE(x) ((x) * (x))
// 這個宏接受一個參數,x// 在程序中使用
SQUARE(8);
// 該宏會像#define定義的標識符一樣,直接在預處理階段進行替換
// 即程序中的代碼變成
((8) * (8));
易錯點:
大家初次使用宏可能會疑惑,為什么上面定義的這個宏要有那么多的括號呢?
下面我們就來看看如果沒有括號會發生什么:
#include <stdio.h>
#define SQUARE(x) x * xint main()
{int a = 2;int ret = SQUARE(a + 1);printf("%d\n", ret);return 0;
}
這段代碼會如預期一樣輸出9嗎?

可以看到輸出結果是5;
這是為什么呢?
宏的本質是在文本處理階段直接替換,所以上面的代碼在預處理之后變成了:
#include <stdio.h>int main()
{int a = 2;int ret = a + 1 * a + 1;printf("%d\n", ret);return 0;
}
可以看到,該程序是將a + 1 * a + 1賦值給了ret,也就是 2 + 1 * 2 + 1,結果就是5;
當我們的宏定義成#define SQUARE(x) ((x) * (x))時,上面代碼在替換之后為,((2 + 1) * (2 + 1)),結果與預期相同;
這時有人可能還有疑問,在x外部加上括號不就行了,為什么在計算結果外面也要加上括號呢;
我們再看一個例子:
#define DOUBLE(x) (x) + (x)int main()
{int a = 5;int ret = 10 * DOUBLE(a);printf("%d\n", ret);return 0;
}
這段代碼在替換之后變成了int ret = 10 * (5) + (5)這與預期的結果也是不符的,當宏的結果外面有了括號,此時int ret = 10 * ((5) * (5))才符合預期;
結論:
在使用宏來對數值表達式求值時,宏的定義都應該在參數和總體外面加上括號,這樣就可以避免在使用宏時出現預期之外的錯誤;
2.3 #define 替換規則
在程序中擴展#define定義的符號和宏時,需要涉及以下的幾個步驟:
- 在調用宏時,首先對參數進行檢查,看看是否包含任何由#define定義的符號。如果是,首先替換掉它們;
- 替換文本隨后被插入到程序原來文本的位置。對于宏,宏的參數名被它的值替換;
- 最后,再對結果文件進行掃描,看看是否還有包含任何由#define定義的符號。如果是,就重復上述步驟;
示例:
#include <stdio.h>#define M 20
#define MAX(x, y) (((x) > (y))? (x) : (y))int main()
{int a = 10;printf("%d\n", MAX(a, M));return 0;
}
這段代碼中,MAX這個宏中第二個參數是一個#define定義的符號,所以此時先替換M,變成printf("%d\n", MAX(a, 20));;
之后替換文本,printf("%d\n", (((10) > (20)) ? (10) : (20)));;
注意
- 宏參數和#define定義中可以出現其他#define定義的符號,但對于宏,不能出現遞歸;
- 當預處理器搜索#define定義的符號時,字符串常量的內容并不被搜索;
舉個例子說明第二點:
printf("M = %d\n", M);
這段代碼中的字符串中的M不會被替換;
輸出結果為:M = 20
2.4 #和##
#的作用
如何把參數插入到字符串中?
在介紹這個內容之前,我們先看下面的代碼:
#include <stdio.h>int main()
{printf("hello world\n");printf("hello ""world\n");return 0;
}
這兩個輸出語句,輸出的結果相同嗎?
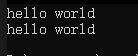
由上圖得知,這兩句代碼效果相同;
在了解了上面的printf函數的使用之后,再來看下面的代碼:
#include <stdio.h>int main()
{int a = 10;// 需要得到 the value of a is 10 這樣的輸出int b = 20;// 需要得到 the value of b is 20 這樣的輸出int c = 30;// 需要得到 the value of c is 30 這樣的輸出return 0;
}
要完成上面的需求,應該怎么解決呢?函數?
試試看:
void print(int x)
{printf("the value of x is %d\n", x);
}
能這樣寫嗎?顯然不行,寫成函數的話,輸出結果就被寫死了,只有值能隨著參數的變化而變化,字符串內容無法改變;只能寫成3個不同的函數來實現;
想到上面提到的printf函數的特性,能寫成一個宏來實現這個功能嗎?
#define PRINT(X) printf("the value of " X "is %d\n", X);
這樣寫正確嗎?預想中,先輸出字符串the value of ,再輸出X,再輸出字符串is %d\n,%d對應X的值;
實際上:

這里需要第一個a變成一個字符串,c語言規定,使用#修飾宏的參數,在預處理階段,該參數會作為字符串進行替換;即,#X會變成"X";
將代碼改成:
#include <stdio.h>#define PRINT(X) printf("the value of " #X " is %d\n", X);int main()
{int a = 10;// 需要得到 the value of a is 10 這樣的輸出PRINT(a);int b = 20;// 需要得到 the value of b is 20 這樣的輸出PRINT(b);int c = 30;// 需要得到 the value of c is 30 這樣的輸出PRINT(c);return 0;
}
運行結果:
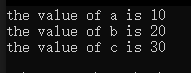
可能有人會想可以用3個引號嗎?也就是寫下面這樣:
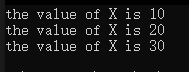
#define PRINT(X) printf("the value of " "X" " is %d\n", X);
很顯然不行,這個與上面提示的預處理器處理時不會替換字符串常量中的符號沖突,此時的輸出變成:
接下來我們再對這個宏進行優化,此時該宏只能處理整型數據,能否讓它可以處理任何類型的變量呢?當然是可以的,要處理什么類型的數據,這個問題使用者是清楚的,所以我們的宏在增加一個參數,接收數據的類型;
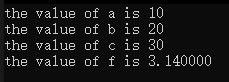
#include <stdio.h>#define PRINT(X, FORMAT) printf("the value of " #X " is " FORMAT "\n", X);int main()
{int a = 10;// 需要得到 the value of a is 10 這樣的輸出PRINT(a, "%d");int b = 20;// 需要得到 the value of b is 20 這樣的輸出PRINT(b, "%d");int c = 30;// 需要得到 the value of c is 30 這樣的輸出PRINT(c, "%d");float f = 3.14f;PRINT(f, "%f");return 0;
}
##的作用
##可以將位于它兩邊的符號連成一個符號;
它允許宏定義以分離的文本片段創建標識符;
示例:
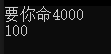
#include <stdio.h>#define STR "要你命"
#define CAT(X, Y) X##Yint main()
{// 達文西現在除了要你命3000之外,還有了許多其他的要你命系列的武器// 現在需要根據提供的型號,產生對應的字符串printf("%s\n", CAT(STR, "4000"));// 譬如此時有一個變量名就是Annihilator3000int Annihilator3000 = 100; // 這里為了演示方便使用int類型,也可以使用其他類型printf("%d\n", CAT(Annihilator, 3000));return 0;
}
運行結果:
注意:
使用##時,除了#define定義的標識符會進行替換之外,符號兩邊是什么,就用什么進行拼接,使用變量時,不會使用變量指代的值,而是直接使用變量名本身;
2.5 帶副作用的宏參數
什么叫做帶副作用的宏參數呢?
副作用就是表達式求值時出現的永久性效果。比如,x+1這個表達式就沒有副作用,x++這個表達式就有副作用,它會永久性的改變x的值;
當宏參數在宏的定義中出現超過一次時,如果參數帶有副作用,那么你在使用這個宏時可能出現不可預測的結果;
示例:
#include <stdio.h>#define MAX(X, Y) ((X) > (Y)? (X) : (Y))int main()
{int a = 5; int b = 8;int c = MAX(a++, b++);// 這里的結果會是什么呢?// 會是6, 9, 9嗎 printf("%d, %d, %d\n", a, b, c);return 0;
}
運行結果:
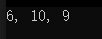
可以看到實際結果與預期不符,這是因為條件表達式在替換之后為int c = ((a++) > (b++)? (a++) : (b++)),兩個參數比較之后,還執行了一次b++;所以b變成了10;
所以在使用宏時,盡量不要使用有副作用的參數;
2.6 宏和函數的對比
比較下面兩種實現哪種更好
// 代碼1
#define Add1(X, Y) ((X) + (Y))// 代碼2
int Add2(int x, int y)
{return (x + y);
}int main()
{int a = 10;int b = 20;int c = Add1(a, b);int d = Add2(a, b);return 0;
}
結論是代碼1更好;
原因如下:
這是宏的匯編代碼,僅有三句;

下面的是函數實現的匯編執行過程:
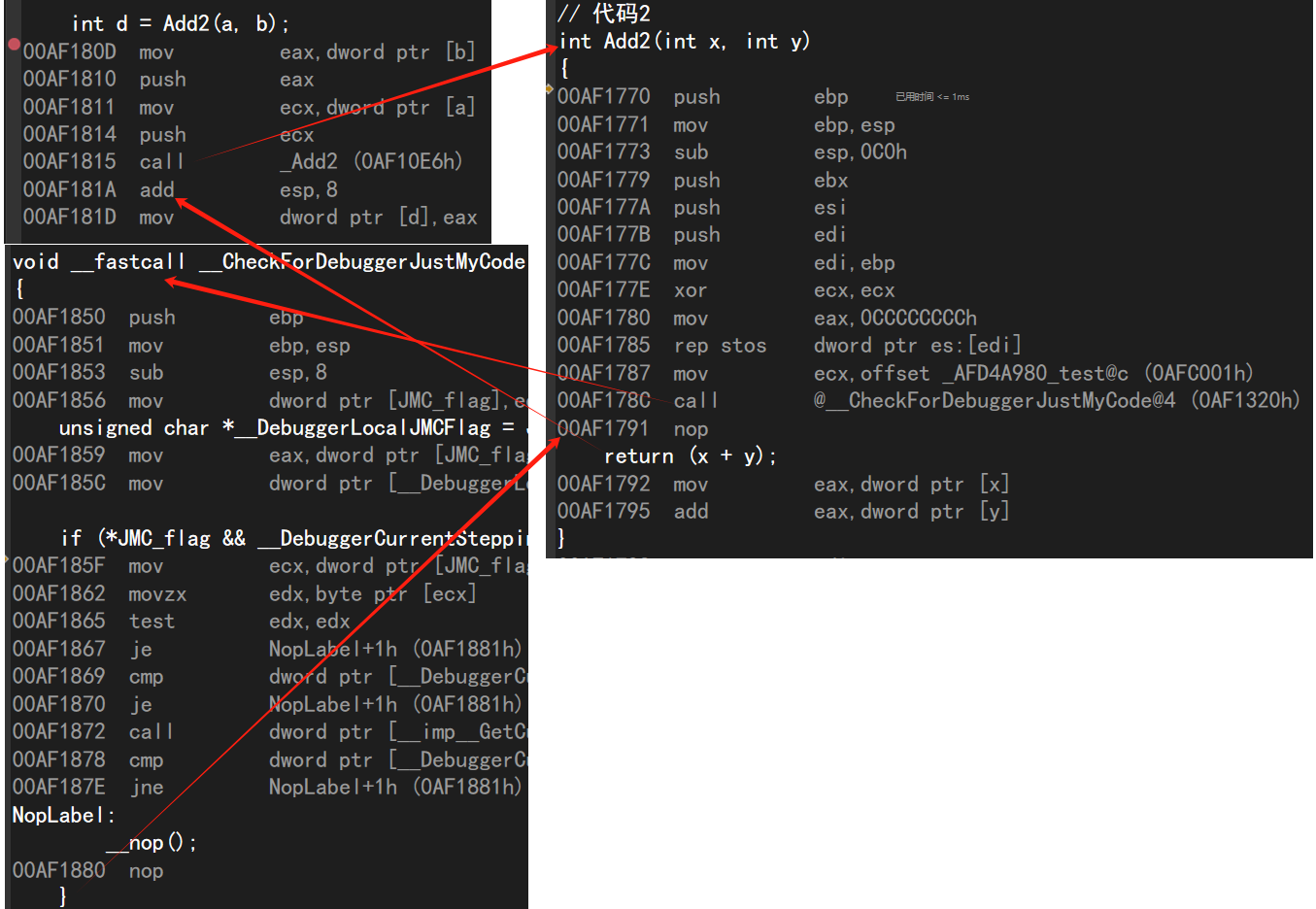
很顯然,函數調用比宏的實現要復雜得多;
所以簡單的運算使用宏是更優的;
原因有二:
- 用于調用函數和從函數返回的代碼可能比實際執行這個小型計算工作所需要的時間更多。所以宏比函數在程序的規模和速度方面更勝一籌;
- 更為重要的是函數的參數必須聲明為特定的類型。所以函數只能在類型合適的表達式上使用。而宏可以適用于整型、長整型、浮點數等可以使用
>進行比較的類型,使用更靈活;宏與類型無關
當然宏與函數相比也存在有劣勢的地方:
- 每次使用宏時,都是通過代碼替換的方式實現的。除非一個宏較短,否則,這會大大增加程序的長度;
- 宏是無法調試的;因為宏的替換是在預處理階段,而調試則是發生在可執行程序運行中;
- 宏與類型無關,既是優點也是缺點,因為沒有類型,所以不夠嚴謹;
- 宏可能存在運算符優先級的問題,導致程序更容易出錯;
宏也能做到一些函數無法做到的事,比如#中的例子,還有宏的參數可以是類型,函數不行;
#include <stdlib.h>#define MALLOC(x, type) \((type*)malloc(sizeof(type) * x))int main()
{// 開辟10個整型的空間int *p = MALLOC(10, int);return 0;
}
| 屬性 | #define定義宏 | 函數 |
|---|---|---|
| 代碼長度 | 每次使用時,宏代碼都會插入程序,程序長度會增加 | 函數代碼只出現一次,每次調用都是使用同一份代碼 |
| 執行速度 | 更快 | 存在函數調用和返回的額外開銷,較慢 |
| 操作符優先級 | 宏參數的求值是在所有周圍上下方環境中,除非加上括號,否則鄰近操作符的優先級可能會對求值產生不可預料的影響 | 函數參數只在傳參時求值一次,將求值結果傳遞給函數,結果更容易預測 |
| 帶副作用的參數 | 參數可能被替換到宏體中的多個位置,所以帶有副作用的參數求值可能會產生不可預期的結果 | 函數參數只在傳參時求值一次,結果更容易控制 |
| 參數類型 | 宏的參數與類型無關,只要對參數的操作是合法的,它就可以使用任何參數 | 函數的參數確定類型的,不同的參數需要不同的函數,即使它們執行的任務相同 |
| 調試 | 宏無法調試 | 函數可以逐語句調試 |
| 遞歸 | 宏不可遞歸 | 函數可以遞歸 |
命名約定
一般來說,函數和宏使用的語法非常相似;所以語言本身無法幫助我們區分它們。
所以平時,我們習慣于將:
宏名全部大寫
函數名不要全部大寫
3. #undef
這條語句用于移除一個宏的定義
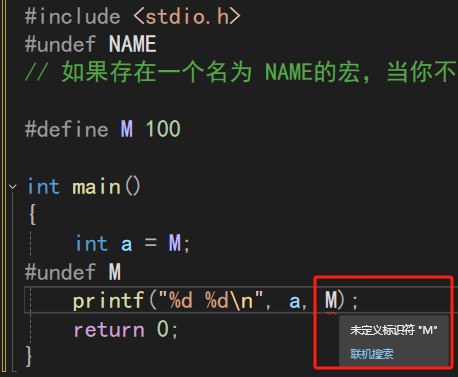
#include <stdio.h>
#undef NAME
// 如果存在一個名為 NAME的宏,當你不再想要它時,可以使用#undef來將它移除#define M 100int main()
{int a = M;
#undef Mprintf("%d %d\n", a, M);return 0;
}
4. 命令行定義
對于許多c語言的編譯器提供了在命令行中定義符號的功能;
假如對于一個可移植的代碼,代碼中有一個數組,有些機器的內存空間有限,所以這個數組的長度就小,對于另一些內存較大的機器,數組的長度就可以更長一點;
此時就可以使用命令行定義:
示例:
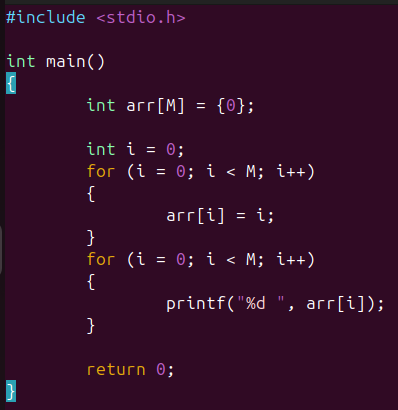
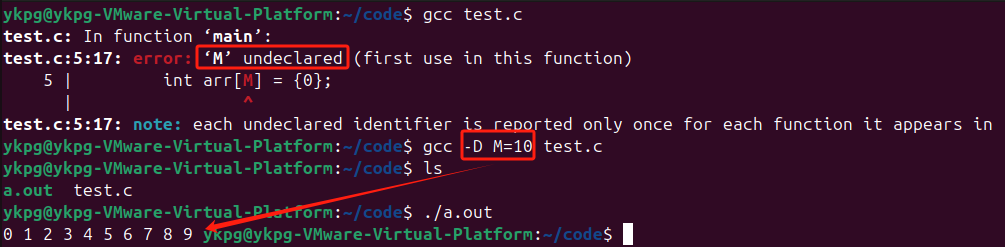
可以看到直接編譯時會出現錯誤,提示M沒有定義;此時可以使用命令行命令定義變量M的值為10,之后再進行編譯就可以通過,并且成功運行;
5. 條件編譯
c語言中語句的編譯可以像條件語句一樣,選擇性的進行編譯;
比如:
#include <stdio.h>
#define __PRINT__int main()
{
// 如果已經定義了__PRINT__,則#ifdef和#endif之間的代碼參與編譯
#ifdef __PRINT__printf("hehe\n");
#endifreturn 0;
}
常見的條件編譯指令:
// 1.
#if 常量表達式// ....
#endif
// 常量表達式為真時,被包括的內容參與編譯;為假則反之
// 常量表達式由預處理器求值// 如:
#define __DEBUG__ 1
#if __DEBUGprintf("hehe");
#endif// 2. 多個分支的條件編譯
#if 常量表達式// ...
#elif 常量表達式// ...
#else// ...
#endif
// 可以看到條件編譯語句和條件分支語句很像// 3. 判斷是否被定義
#if defined(symbol) // ...
#endif
// 寫法1
#ifdef symbol // ...
#endif
// 寫法2
// 這兩種寫法等價,意思是如果symbol已經被定義,就編譯它們包含的內容#if !defined(symbol)// ...
#endif
// 寫法1
#ifndef symbol// ...
#endif
// 寫法2
// 與上面相反,如果symbol已經被定義,它們包含的內容就不編譯// 4. 嵌套指令
#if defined(HELLO)#ifdef HEHEprintf("HEHE\n");#endif#ifdef HAHAprintf("HAHA\n");#elif HEIHEIprintf("HEIHEI\n");#elseprintf("HELLO\n");#endif
#elif WORLDprintf("WORLD\n");
#endif
// 嵌套指令和嵌套使用條件語句一樣
6. 文件包含
我們已經知道,#include指令可以使另一個文件也被編譯進程序。就像直接將它的內容替換到這個地方一樣;
這種替換非常簡單:
預處理器會先刪除這條指令,將用被包含文件的內容來替換;
如果這個文件被包含了10次,那么它的內容就被包含了10次;
因為這個性質在包含頭文件時就會產生問題;
如果一個頭文件在多個文件中都被包含,那么這個頭文件的內容就被重復包含了多次,這使得程序代碼變得冗余臃腫;
比如:
此時有4個源文件,common.c, test1.c, test2.c, test.c
它們都有對應的頭文件,common.h, test1.h, test2.h, test.h
test1.h 包含了common.h, test2.h 也包含了common.h, test.h 包含了test1.h和test2.h
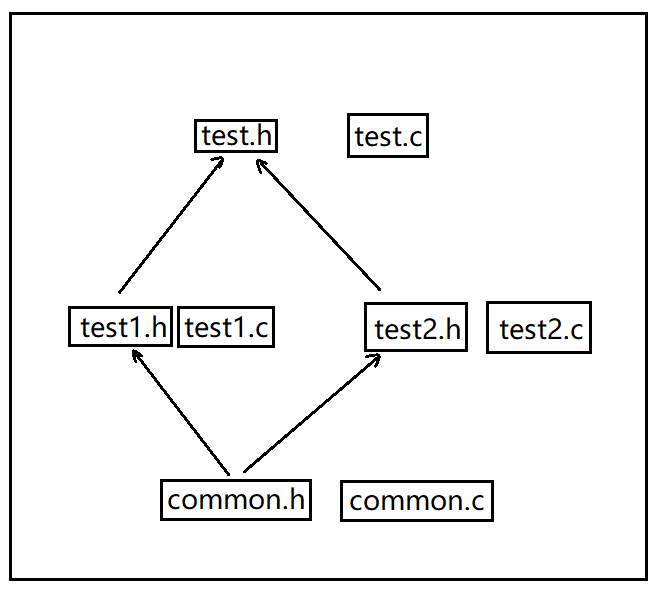
可以看到test.h中包含了兩次的common.h的內容;
為了解決這種問題就可以使用條件編譯語句:
// test1.h
#ifndef COMMON
#define COMMON
#include "common.h"
#endif// test2.h
#ifndef COMMON
#define COMMON
#include "common.h"
#endif// test.h
#ifndef TEST1
#define TEST1
#include "test1.h"
#endif
#ifndef TEST2
#define TEST2
#include "test1.h"
#endif
上面的條件編譯語句只有在目標頭文件沒有被編譯到文件中時才會參與編譯,在編譯之后就設置一個標志,使得之后不會再重復包含這個文件;
或者是使用
#pragma once // 文件內容只會被包含一次
在上面的代碼中,包含頭文件時,使用的是""并不是之前使用過的<>;這兩者有什么區別呢?
- 本地文件包含:
#include "name"
查找策略:先在源文件所在目錄下查找,如果找不到,編譯器就會在標準位置(庫函數頭文件所在位置)查找;此時再找不到就編譯錯誤;
linux系統中的標準位置:/usr/include
VS環境下的標準位置:C:\Program Files (x86)\Windows Kits\10\Include 這個地址以自己的機器為準
- 庫文件包含:
#include <name>
查找頭文件時,直接到標準位置查找,找不到就編譯錯誤;
可能有的同學會有疑問,那么包含庫函數頭文件時,是否可以使用#include "name"來包含呢?
可以,但是不推薦,因為使用這種方法,會先去當前目錄查找,這肯定是找不到的,浪費了系統資源,降低了查找效率;
總結
這是c語言學習的最后一個部分了,此章節介紹了一個c語言程序從源文件變成可執行文件的過程,還詳解了c語言中使用的預處理指令;以及一些宏的使用方法;
希望這系列文章對大家的c語言學習有幫助;










工程優化)

)




)

)