數據倉庫分層是構建高效數據體系的核心方法論。本文系統闡述ODS、DWD、DWS、ADS四層架構的設計原理,結合電商用戶行為分析場景,詳解各層功能及協作流程,并給出分層設計的原則與避坑指南,幫助讀者掌握分層架構的落地方法。
一、為什么需要數據倉庫分層?
在互聯網公司中,原始數據往往存在以下問題:
- 數據冗余:同一份數據被多套系統重復存儲
- 強耦合性:業務直接依賴原始日志表,改動成本高
- 性能瓶頸:復雜查詢直接掃描TB級原始數據
分層架構通過解耦數據處理流程,實現:
- 數據資產結構化沉淀
- 計算資源優化分配
- 業務需求快速響應
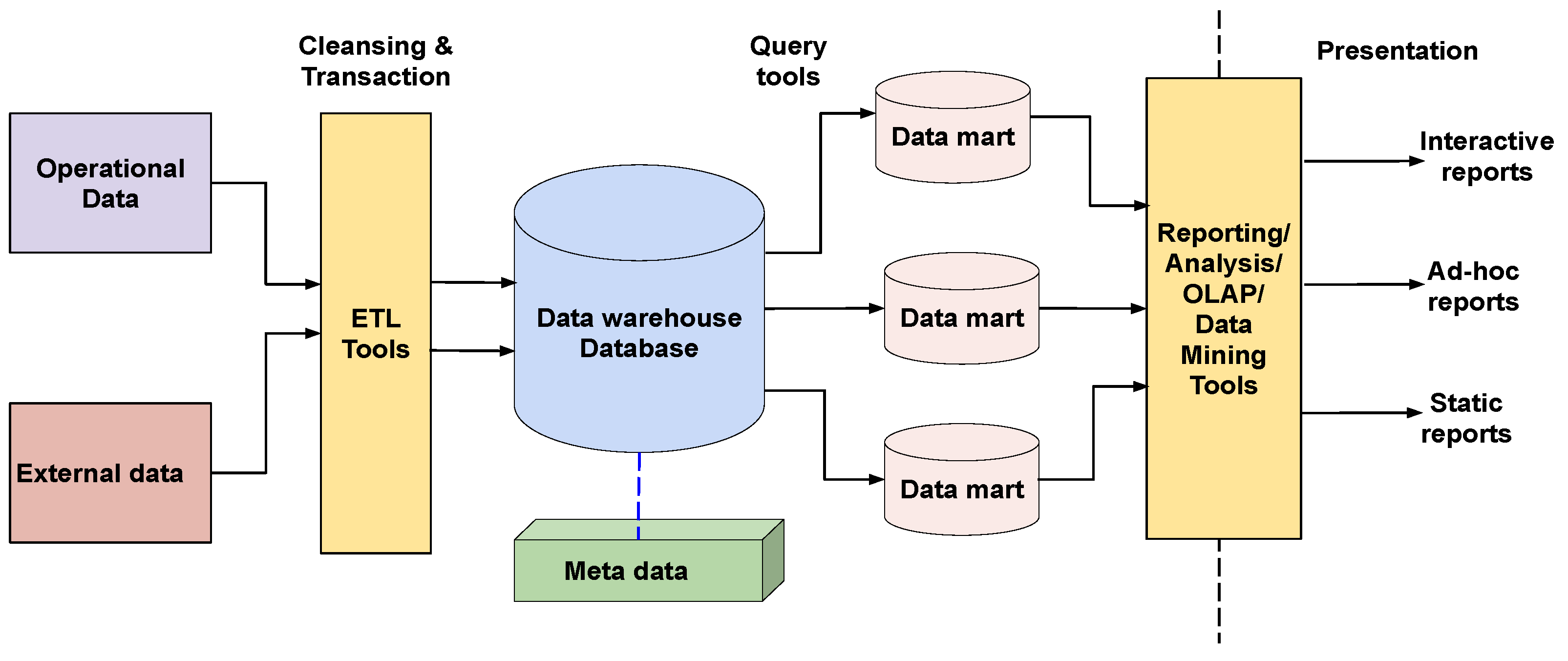
二、分層架構核心模型
1. ODS層(操作數據存儲層)
-
定位:原始數據鏡像
-
功能:保留業務系統原始狀態,完成數據初步清洗
-
場景示例:
-- 電商訂單日志ETL示例 CREATE TABLE ods_order_log (log_id STRING COMMENT '日志唯一標識',user_id BIGINT COMMENT '用戶ID',action_time TIMESTAMP COMMENT '行為時間戳',page_url STRING COMMENT '訪問頁面URL' ) PARTITIONED BY (dt STRING) STORED AS ORC;
2. DWD層(明細數據層)
- 定位:數據清洗后的標準明細模型
- 核心操作:
- 維度建模(星型/雪花模型)
- 數據脫敏(手機號加密)
- 補全維度屬性(商品類目映射)
- 場景示例:
將用戶點擊流數據關聯商品維度表,生成帶商品分類的明細寬表
3. DWS層(匯總數據層)
-
定位:面向主題的聚合數據
-
設計原則:
- 高頻訪問指標優先聚合
- 預計算常用維度組合
-
電商場景:
-- 日粒度用戶行為聚合 CREATE TABLE dws_user_behavior_daily (date DATE,user_id BIGINT,pv_count INT COMMENT '頁面瀏覽量',cart_add INT COMMENT '加購次數' ) PARTITIONED BY (dt STRING) DISTRIBUTED BY HASH(user_id);
4. ADS層(應用數據層)
- 定位:直接支撐BI報表/數據產品
- 設計要點:
- 按業務線垂直切分
- 包含業務過程指標(GMV、轉化率)
- 典型應用:
- 實時大屏:GMV實時統計
- BI報表:用戶留存分析
三、分層架構實戰案例

場景:電商用戶行為分析
- 數據流路徑:
App埋點日志 → Kafka → Flink實時清洗 → ODS → Hive批處理 → DWD → Spark聚合 → DWS → Presto查詢 → ADS - 分層價值體現:
- 開發效率:新需求平均開發時間從3天縮短至6小時
- 成本優化:DWS層緩存高頻指標,集群資源消耗降低40%
- 數據質量:通過DWD層統一數據口徑,消除部門間指標差異
四、分層設計最佳實踐
- 黃金分層數:建議采用4層架構(ODS→DWD→DWS→ADS),避免過度分層
- 數據血緣管理:使用Atlas等工具追蹤字段級血緣
- 灰度發布機制:新分層架構上線時采用新舊版本并行驗證
- 成本監控:對DWS層建立存儲/計算成本預警機制
五、常見誤區與解決方案
| 誤區 | 現象 | 解決方案 |
|---|---|---|
| 過度分層 | 出現5層以上架構 | 合并相似層級,保持扁平化 |
| 層次倒置 | 在DWD層存放匯總數據 | 嚴格遵循"原子粒度→聚合粒度"順序 |
| 忽視數據血緣 | 下游出現臟數據難以溯源 | 強制實施字段級血緣登記 |
總結
數據倉庫分層是數據體系建設的基石,通過ODS到ADS的四層演進,實現了從原始數據到業務價值的轉化。實際應用中需注意:
- 分層設計要與業務發展階段匹配
- DWD層應作為架構優化的重點
- 持續進行元數據治理
掌握分層架構設計,可使數據團隊在應對業務需求時達到"架構彈性"與"執行效率"的平衡,真正釋放數據價值。

——4.1基本算術運算的實現)



![[密碼學基礎]GM/T 0018-2023 密碼設備應用接口規范深度解析:技術革新與開發者實踐](http://pic.xiahunao.cn/[密碼學基礎]GM/T 0018-2023 密碼設備應用接口規范深度解析:技術革新與開發者實踐)
)

)






)
)

)
)