1 簡介
??顯示卡(英語:Display Card)簡稱顯卡,也稱圖形卡(Graphics Card),是個人電腦上以圖形處理器(GPU)為核心的擴展卡,用途是提供中央處理器以外的微處理器幫助計算圖像信息,并將計算機系統所需要的顯示信息進行轉換并提供逐行或隔行掃描信號給顯示設備,是連接顯示器和個人電腦主板的重要組件,是“人機交互”的重要設備之一。顯卡有時被稱為獨立顯卡或專用顯卡,以強調它們與主板上的集成圖形處理器(集成顯卡)或中央處理器 (CPU) 的區別。
??早期顯卡主要用來進行圖像顯示,其主要應用場景為游戲渲染等領域。而自從深度學習開啟21世紀的人工智能熱潮之后,顯卡也被用來進行計算加速。從此之后,顯卡廠商也將顯卡的并行計算能力作為衡量顯卡性能的標準之一。眾多顯卡廠商中,其中Nvidia是其中的佼佼者。
??為了跟上AI熱潮,且我本人對于并行計算也比較感興趣,因此這里總結下Nvidia顯卡架構演進來學習底層硬件結構指導自己。
??Nvidia成立于1993年4月,截止2025年,這30年里其發布了眾多的顯卡型號。每一代顯卡都有各自的新特性和新的側重點,但是總的來說主要分為兩種類型架構:早期架構和統一架構。前者因為時間的流逝逐漸被新的顯卡型號替代,且不具備太大的參考意義。因此本文主要聚焦統一架構,對于早期架構不會詳細描述。
2 早期架構
??早期架構并不是一個正式的架構名稱,而是為了和后續的統一架構區分。
??Nvidia早期架構主要聚焦在提升圖形性能,比如提升紋理的處理能力,引入更多硬件加速來提升渲染性能。從剛開始的NV1到典型其市場地位的GeForce256,Nvidia不斷提升使得3D Video Game成為了現實。這些早期架構雖然比較簡陋,但是正是有這些早期的嘗試才有了現如今的輝煌。
2.1 NV1(發布于1995)
??NV1 是由 NVIDIA 用了兩年研發,于1995年5月發布的顯示芯片[1]。它亦是 NVIDIA 自創立起的首款產品。NVIDIA 亦授權 SGS Thomson Microelectronics 生產,芯片型號為 STG2000X B。當時還沒有像 Direct3D 的多邊形 3D 標準,所以 nVIDIA 使用二次方程紋理貼圖作為立體圖形的實現方式。它不但擁有完整的 2D/3D 核心,還內置聲音處理核心。隨后微軟在 Windows 95 制訂 Direct3D 多邊形立體標準,縱使 NV1 的二次方程紋理貼圖是出色的技術,但始終不兼容 Direct3D,亦不支持當時還很流行的 Glide,導致該顯卡市場上響應不佳。

2.2 RIVA128(發布于1997)
??NVIDIA RIVA 128 (1997) 是 NVIDIA 走向成功的關鍵一步。作為其首款消費級顯卡,RIVA 128 并非完美,但它在當時以合理的價格提供了顯著的性能提升,特別是對 Direct3D 5.0 的支持使其在游戲中表現出色。它采用 128 位顯存接口,在紋理填充率方面表現良好,但缺乏硬件加速的三角形設置引擎是其弱點,在復雜場景中性能會明顯下降。盡管如此,RIVA 128 憑借其性價比和相對出色的性能,成功打入市場,為 NVIDIA 贏得了聲譽,并為后續 RIVA TNT 等更強大的產品奠定了基礎。它標志著 NVIDIA 從一家默默無聞的小公司成長為圖形卡市場的重要參與者。

2.3 RIVA TNT(發布于1998)
??NVIDIA RIVA TNT (1998) 是 RIVA 128 的繼任者,也是 NVIDIA 在圖形卡市場取得更大成功的關鍵。TNT 的核心改進在于其雙紋理引擎 (Twin Texel engine),使其能夠在每個時鐘周期處理兩個紋理單元,從而有效地將紋理填充率翻倍,顯著提升了游戲性能。這使得 RIVA TNT 在當時成為極具競爭力的產品,贏得了眾多游戲玩家的青睞。盡管 RIVA TNT 仍然缺乏硬件加速的三角形設置引擎,這在一定程度上限制了其在復雜 3D 場景中的表現,但憑借其卓越的紋理處理能力和相對較低的價格,它迅速成為市場上的熱門選擇,進一步鞏固了 NVIDIA 在圖形卡領域的地位,并為后續的 GeForce 系列鋪平了道路。

2.4 GeForce256(發布于1999)
??NVIDIA GeForce 256 (1999) 是圖形卡發展史上的一個里程碑,通常被認為是“第一款 GPU”。它首次集成了硬件 T&L (Transform and Lighting) 引擎,將頂點轉換和光照計算從 CPU 轉移到 GPU 處理,極大地提升了 3D 圖形的性能。NVIDIA 也正是用這款產品定義了“GPU”一詞,強調其作為獨立圖形處理器的作用。GeForce 256 支持 DirectX 7,擁有出色的單紋理填充率,并引入了立方體環境貼圖等先進技術。雖然在多邊形處理能力上仍有不足,但 GeForce 256 憑借其革命性的硬件 T&L 設計和卓越的整體性能,迅速成為市場領導者,為現代 GPU 架構奠定了基礎,并開啟了 NVIDIA 在圖形處理器領域的霸主地位。

3 統一架構
??NVIDIA 統一架構(Unified Architecture)是 NVIDIA 在 2006 年發布的 GeForce 8 系列顯卡中引入的革命性設計。它打破了傳統 GPU 中頂點著色器和像素著色器分離的架構,采用統一的著色器單元,可以動態地分配計算資源給任何類型的著色任務。這意味著 GPU 能夠更有效地利用其計算能力,不再受限于特定著色器的性能瓶頸。
??統一架構還引入了 CUDA (Compute Unified Device Architecture),使 GPU 不僅可以用于圖形渲染,還可以用于通用計算。這為 GPU 在科學計算、人工智能等領域開辟了廣闊的應用前景。
??總而言之,NVIDIA 統一架構通過靈活的資源分配和 CUDA 的引入,極大地提高了 GPU 的效率和通用性,是 GPU 發展史上的一個重要轉折點,奠定了現代 GPU 的基礎。
3.1 Tesla(2006-2010)
??Tesla 架構發布于 2006 年。Tesla 架構全新的 CUDA 架構,支持使用 C 語言進行 GPU 編程,可以用于通用數據并行計算。Tesla 架構具有 128 個流處理器,帶寬高達 86GB/s,標志著 GPU 開始從專用圖形處理器轉變為通用數據并行處理器。
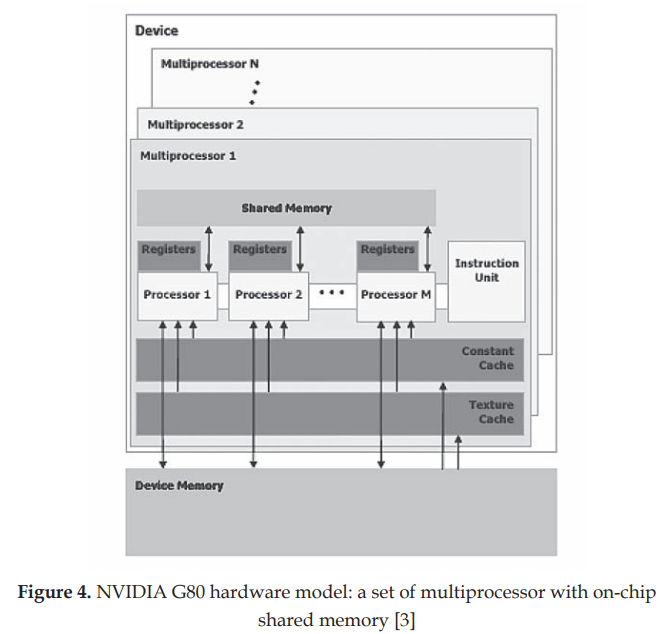
??Tesla架構的第一款產品為Nvidia G80。G80 作為 NVIDIA 首款 Tesla 架構的基礎,具有以下里程碑式的創新:
- C 語言支持: 首次允許開發者使用熟悉的 C 語言進行 GPU 編程,降低了 GPU 編程的門檻(CUDA)。
- 統一架構: 采用單一、統一的處理器取代了獨立的頂點和像素管線,能夠靈活執行各種類型的程序(頂點、幾何、像素和計算程序)。
- 標量線程處理器: 使用標量線程處理器,簡化了編程模型,程序員無需手動管理向量寄存器。
- SIMT 執行模型: 引入單指令多線程 (SIMT) 執行模型,允許多個線程并發執行同一指令,提高了并行效率。
- 線程間通信機制: 提供了共享內存和屏障同步機制,方便線程之間進行數據共享和同步,增強了程序的靈活性。
??CUDA 是一種硬件和軟件架構,它使 NVIDIA GPU 能夠執行使用 C、C++、Fortran、OpenCL、DirectCompute 和其他語言編寫的程序。CUDA 程序調用并行內核。內核在一組并行線程上并行執行。程序員或編譯器將這些線程組織成線程塊和線程塊網格。GPU 在并行線程塊網格上實例化一個內核程序。線程塊中的每個線程執行內核的一個實例,并且在其線程塊中具有線程 ID、程序計數器、寄存器、每個線程的私有內存、輸入和輸出結果。

??這些創新使得 G80 不僅在圖形處理方面表現出色,也為 GPU 在通用計算領域的應用奠定了堅實的基礎,開啟了 GPGPU (General-Purpose computing on Graphics Processing Units) 的時代。同時,其全面支持Direct3D 10和DirectX 10 Shader Model 4.0,憑借其內部128位浮點精度、無限長度著色器以及對多重紋理和渲染目標的支持,實現了卓越的圖形處理能力。同時,它還集成了NVIDIA Lumenex技術和PureVideo HD技術,分別在圖像增強和高清視頻處理方面表現出色,并通過SLI技術支持多GPU并行,為用戶帶來前所未有的視覺體驗。
3.2 Fermi(2010-2012)
??NVIDIA Fermi 架構是 2010 年發布的一款具有里程碑意義的 GPU 微架構,它標志著 NVIDIA 在 GPU 計算領域的重大突破。作為 Tesla 架構的繼任者,Fermi 架構主要應用于 GeForce 400 和 500 系列顯卡,以及 Quadro 和 Tesla 系列專業卡,旨在提供卓越的圖形性能和強大的并行計算能力。
??Fermi 架構的核心在于其對計算的優化。它是 NVIDIA 首個完整的 GPU 計算架構,顯著提升了雙精度浮點性能,滿足了科學計算和工程模擬等領域的需求。它全面兼容 IEEE 754-2008 浮點標準,支持融合乘加運算 (FMA),保證了計算的精度和可靠性。同時,Fermi 架構還引入了 ECC 保護,覆蓋從寄存器到 DRAM 的各個環節,提高了數據完整性。
??在架構設計上,Fermi 采用了統一尋址模型,簡化了內存管理,并實現了所有級別的緩存,提高了數據訪問效率。每個流式多處理器 (SM) 最多包含 32 個 CUDA 核心,這些核心能夠并行執行大量的線程。此外,Fermi 還采用了可配置的 L1 緩存,允許根據不同的應用場景靈活分配共享內存和 L1 緩存的大小。雙 Warp 調度器和雙指令分派單元的設計,使得每個 SM 能夠并發執行兩個 Warp,進一步提升了并行執行效率。
??Fermi 架構還特別針對圖形處理進行了優化。它包含一個專為曲面細分和位移貼圖優化的 PolyMorph 引擎,能夠提供更逼真的游戲畫面。此外,Fermi 也是 NVIDIA 最早支持 Microsoft Direct3D 12 feature_level 11 渲染 API 的微架構,為新一代游戲和圖形應用提供了硬件支持。
??盡管 Fermi 架構采用的是 40nm 工藝制造,擁有高達 30 億個晶體管,但其創新的架構設計和強大的計算能力,為 NVIDIA 在 GPU 領域奠定了堅實的基礎。Fermi 架構不僅是一款成功的游戲顯卡架構,更是一款重要的 GPU 計算平臺,推動了 GPU 在科學研究、人工智能等領域的應用。它以意大利物理學家恩里科·費米的名字命名,也象征著 NVIDIA 在 GPU 技術上的不斷創新和突破
??總結下來,Fermi架構的關鍵特性有:
- 計算 GPU: Fermi 是 NVIDIA 首個完整的 GPU 計算架構。
- 雙精度浮點性能: 在單芯片上提供高水平的雙精度浮點性能。
- IEEE 754-2008 標準: 兼容 IEEE 754-2008 浮點標準,包括融合乘加運算 (FMA)。
- ECC 保護: 提供從寄存器到 DRAM 的 ECC 保護。
- 統一尋址: 具有直接的線性尋址模型,并在所有級別進行緩存。
- CUDA 核心: 每個流式多處理器 (SM) 最多包含 32 個 CUDA 核心。
- 可配置的緩存: 每個 SM 的 L1 緩存可配置為支持共享內存以及本地和全局內存操作的緩存。64 KB 內存可以配置為 48 KB 共享內存 + 16 KB L1 緩存,或 16 KB 共享內存 + 48 KB L1 緩存。
- 雙 Warp 調度器: 每個 SM 具有兩個 Warp 調度器和兩個指令分派單元,允許并發執行兩個 Warp。
- 多線程: 多個線程被分組到最多包含 1,536 個線程的線程塊中。
- PolyMorph 引擎: Fermi 架構包含一個 PolyMorph 引擎,專為曲面細分和位移貼圖優化。
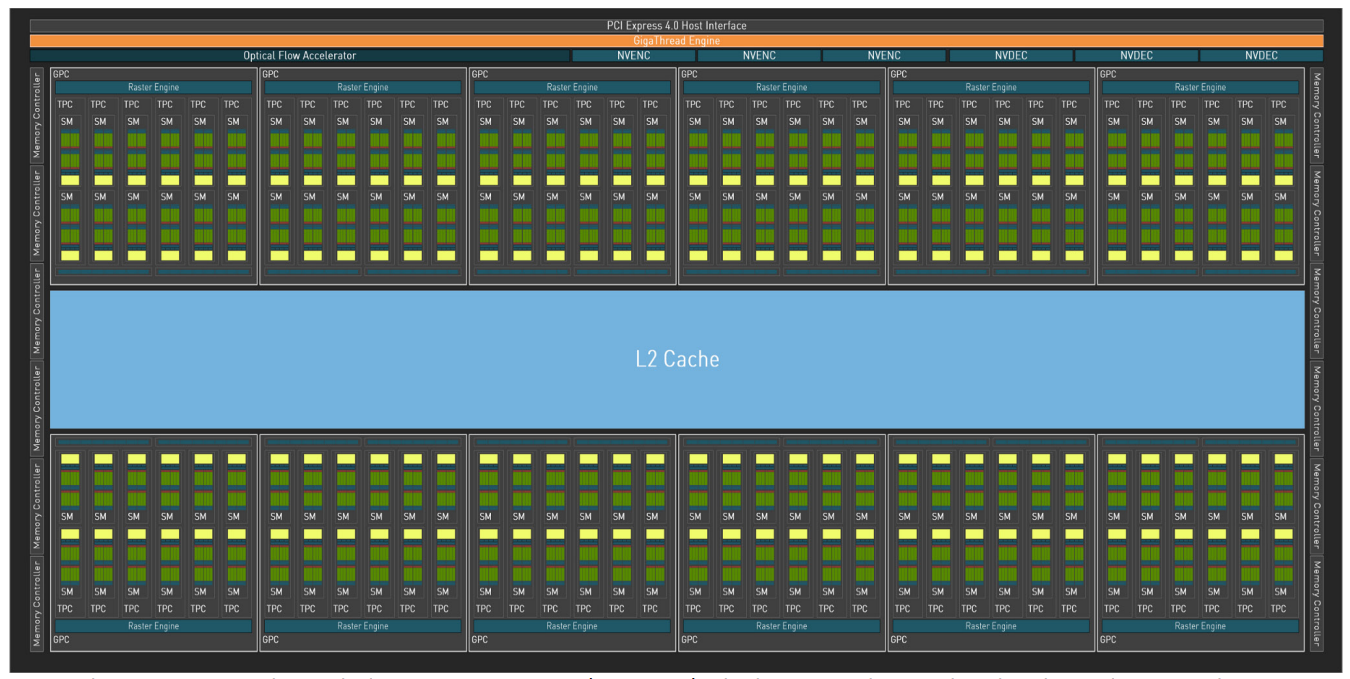
3.2.1 Fermi Architecture Overview
??首款基于 Fermi 的 GPU 擁有高達 512 個 CUDA 核心,由 30 億個晶體管實現。每個 CUDA 核心在一個時鐘周期內為一個線程執行一個浮點或整數指令。這 512 個 CUDA 核心被組織成 16 個 SM(流式多處理器),每個 SM 包含 32 個核心。該 GPU 具有六個 64 位內存分區,構成一個 384 位內存接口,最多支持總計 6 GB 的 GDDR5 DRAM 內存。主機接口通過 PCI-Express 將 GPU 連接到 CPU。GigaThread 全局調度器將線程塊分發到 SM 線程調度器。
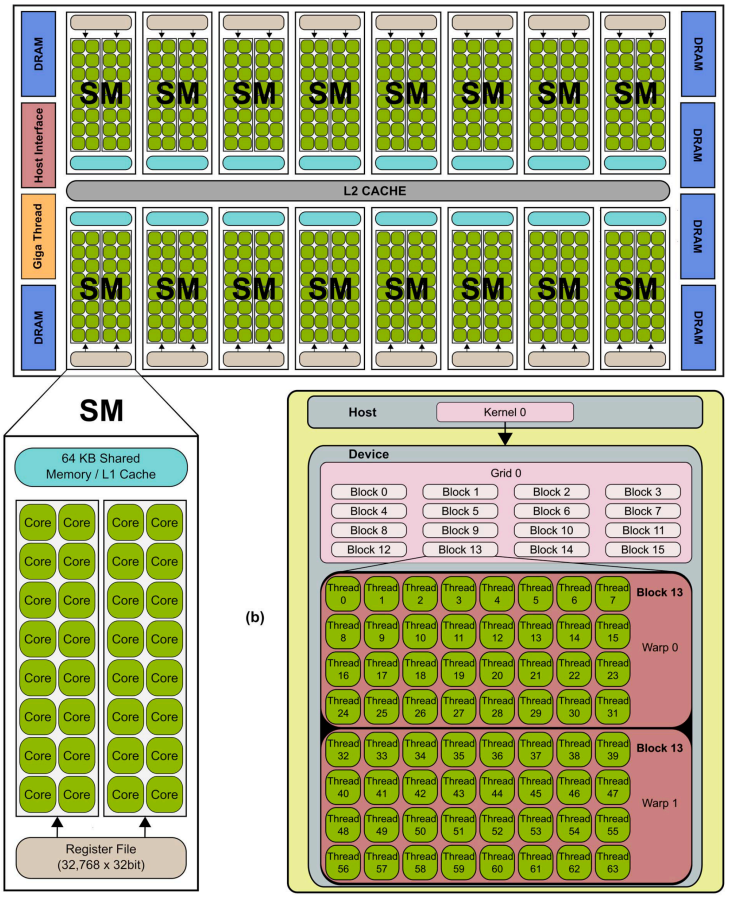
3.2.2 Stream Multiprocessor(SM)
??每個 SM 具有 32 個 CUDA 處理器,比之前的 SM 設計增加了四倍。每個 CUDA 處理器都有一個完全流水線的整數算術邏輯單元 (ALU) 和浮點單元 (FPU)。之前的 GPU 使用 IEEE 754-1985 浮點運算。Fermi 架構實現了新的 IEEE 754-2008 浮點標準,為單精度和雙精度算術運算提供了融合乘加 (FMA) 指令。FMA 通過在單個最終舍入步驟中完成乘法和加法,而不在加法中損失精度,從而改進了乘加 (MAD) 指令。FMA 比單獨執行操作更準確。GT200 實現了雙精度 FMA。
??在 GT200 中,整數 ALU 的乘法運算精度限制為 24 位;因此,整數算術運算需要多指令仿真序列。在 Fermi 中,新設計的整數 ALU 支持所有指令的完整 32 位精度,與標準編程語言要求一致。整數 ALU 也經過優化,可以有效地支持 64 位和擴展精度運算。支持各種指令,包括布爾運算。
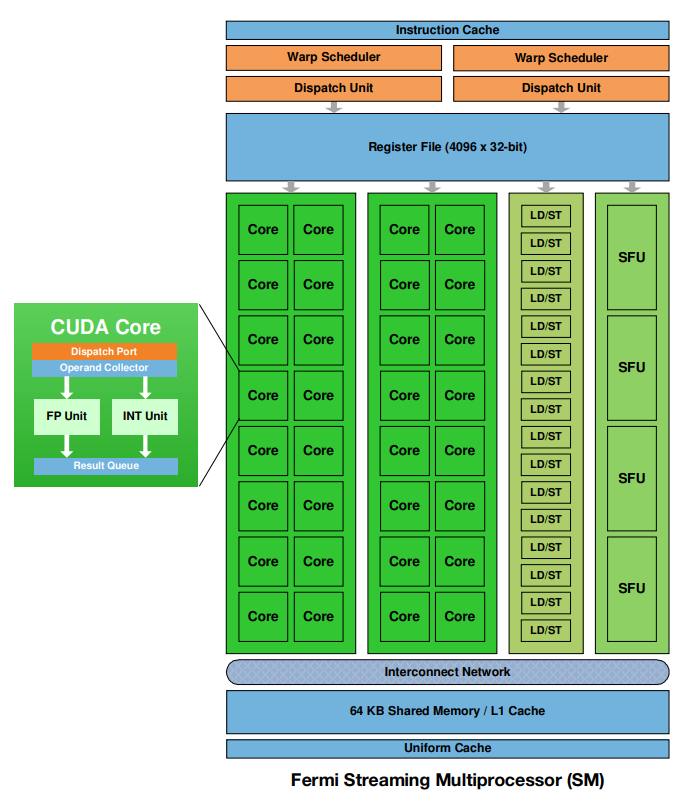
??SM中除了CUDA核心,還有其他負責數據傳輸和特殊運算的單元:
- Warp 調度器(Warp Schedulers): 每個 SM 有兩個 Warp 調度器。每個調度器從其準備就緒的 Warps 中選擇一個 Warp 執行。 雙 Warp 調度器允許每個時鐘周期從兩個不同的 Warps 發出兩條指令。 這種雙重調度能力提高了 SM 的吞吐量,并有助于隱藏延遲。
- 分派單元(Dispatch Units): 與 Warp 調度器配對,每個 SM 有兩個分派單元。 每個分派單元負責將 Warp 調度器選擇的指令分派給 CUDA 核心或其他執行單元。 兩個分派單元允許每個時鐘周期分派兩條指令,從而提高指令吞吐量。
- 寄存器文件(Register File): 用于存儲線程的局部變量和臨時數據。 Fermi 架構具有較大的寄存器文件,為每個 SM 提供更多的寄存器。 增加的寄存器數量減少了對全局內存的訪問,提高了性能。
- 加載/存儲單元(LD/ST Units): 負責從內存加載數據和將數據存儲到內存。 Fermi 架構具有專用的加載/存儲單元,以高效地處理內存訪問操作。 這些單元支持各種內存訪問模式,包括對齊和非對齊的訪問。
- 特殊功能單元(SFU): 用于執行特殊功能指令,如三角函數、指數函數和對數函數。 Fermi 架構具有專用的 SFU,以加速這些計算密集型操作。 SFU 允許 GPU 高效地執行復雜的數學計算,這對于圖形渲染和科學計算至關重要。
3.3 Kepler(2012-2014)
3.3.1 Kepler Overview
??NVIDIA Kepler 架構是繼 Fermi 架構之后,于 2012 年推出的 GPU 微架構。它主要應用于 GeForce 600、700 系列顯卡,以及 Quadro 和 Tesla 系列專業卡。Kepler 架構在能效比和計算能力上都取得了顯著的進步,旨在提供更出色的圖形性能和更強大的并行計算能力。
??Kepler 架構的核心改進在于其對能效的優化。相較于 Fermi,Kepler 采用了更先進的 28nm 工藝制造,降低了功耗和發熱量。它引入了動態超頻技術 GPU Boost,能夠根據負載自動調整 GPU 的頻率,在保證性能的同時降低功耗。此外,Kepler 還采用了更高效的 SMX (Streaming Multiprocessor eXtreme) 設計,取代了 Fermi 架構的 SM。
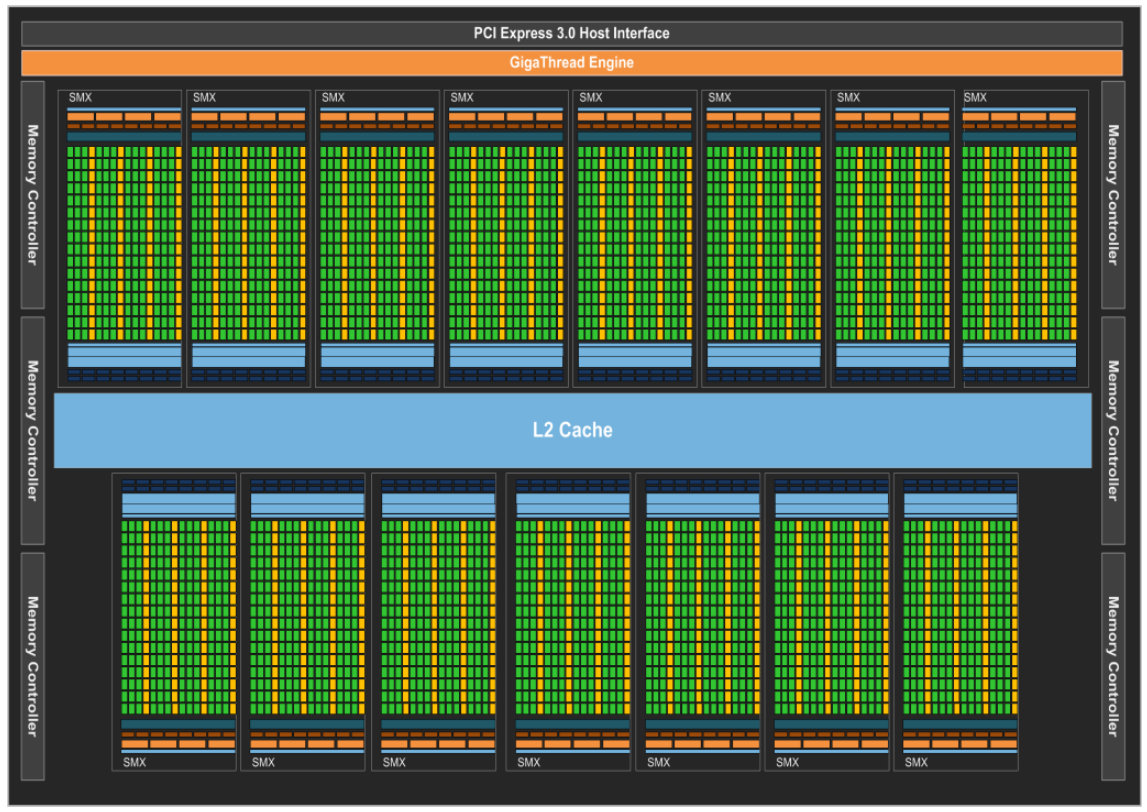
??Kepler 架構還增強了圖形處理能力。它支持 TXAA 抗鋸齒技術,能夠提供更平滑的游戲畫面。此外,Kepler 還支持 NVIDIA 的 NVENC 視頻編碼器,能夠加速視頻編碼過程,提高視頻編輯和流媒體應用的效率。
??在計算方面,Kepler 架構提升了單精度浮點性能,但降低了雙精度浮點性能。這是因為 NVIDIA 將 Kepler 架構定位為主要面向游戲和圖形應用,而這些應用對單精度浮點性能的需求更高。對于需要高雙精度浮點性能的應用,NVIDIA 提供了 Tesla 系列專業卡,這些卡采用了 Kepler 架構的特殊版本,保留了較高的雙精度浮點性能。
??總的來說,Kepler 架構是一款成功的 GPU 微架構,它在能效比、圖形性能和計算能力上都取得了顯著的進步。它為 NVIDIA 在 GPU 領域保持領先地位奠定了堅實的基礎,并推動了 GPU 在游戲、圖形、人工智能等領域的應用。
3.3.2 Streaming Multiprocessor (SMX)
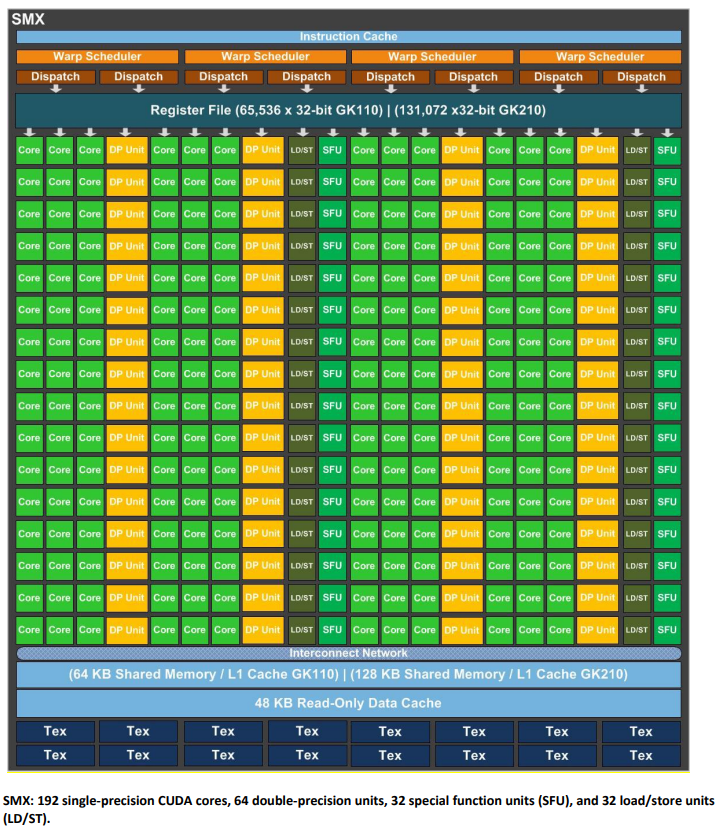
??SMX 單元擁有 192 個單精度 CUDA 核心,每個核心都具備完整的浮點和整數運算單元,并保留了 Fermi 架構引入的 IEEE 754-2008 標準的單精度和雙精度運算,包括 FMA 操作。Kepler 的設計目標之一是顯著提升雙精度性能,這對于高性能計算至關重要。此外,它還保留了用于快速近似超越運算的特殊功能單元 (SFU),數量是 Fermi GF110 SM 的 8 倍。與 GK104 SMX 單元類似,GK110/210 SMX 單元中的核心使用主 GPU 時鐘,而非之前的 2 倍 Shader 時鐘。Kepler 的重點是每瓦性能,因此選擇使用更多的核心以較低的 GPU 時鐘運行,從而優化功耗,即使這意味著增加了一些面積成本。
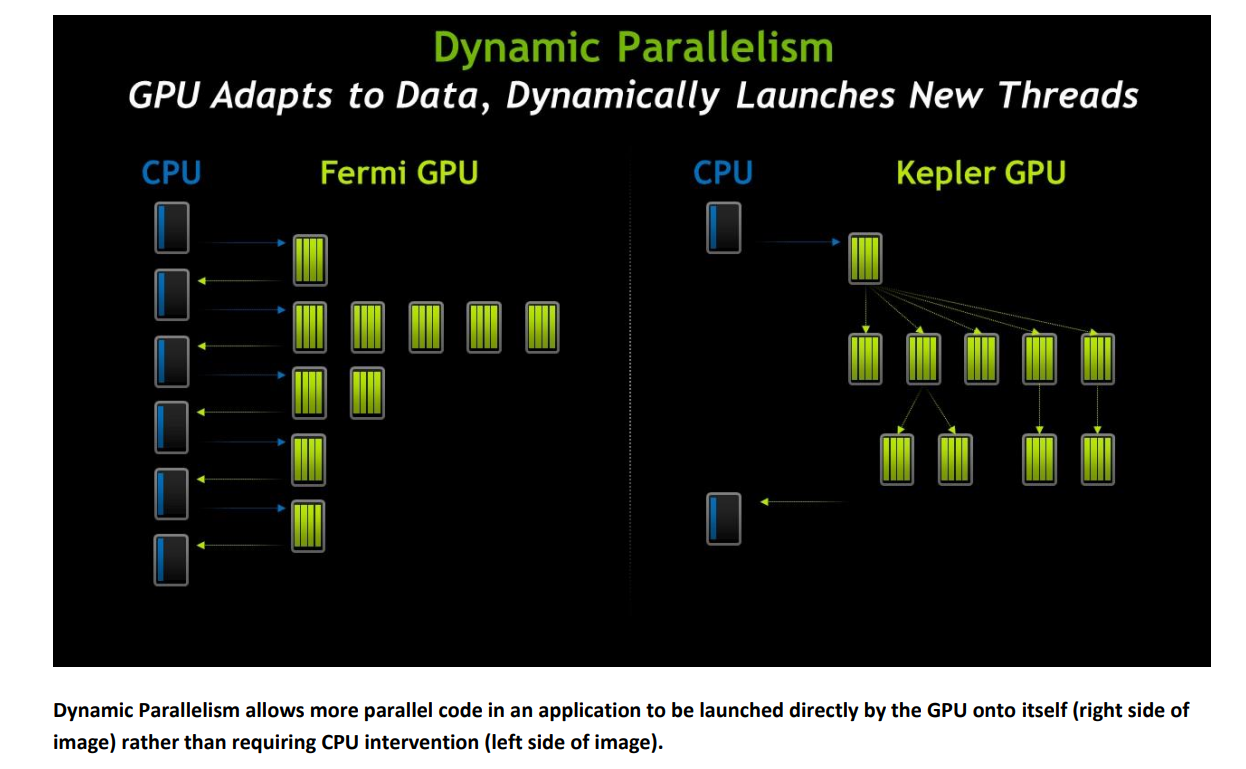
3.3.3 Dynamic Parallelism
??Kepler 架構引入的動態并行(Dynamic Parallelism)是一項重要的創新,它極大地提升了 GPU 的靈活性和效率。在之前的 GPU 架構中,GPU 只能由 CPU 發起 kernel 函數,并且 kernel 函數的執行是靜態的,無法在 GPU 內部動態地啟動新的 kernel 函數。這意味著所有的任務調度和同步都必須由 CPU 來完成,限制了 GPU 的并行能力和效率。
??動態并行的核心思想是允許 GPU 在執行 kernel 函數的過程中,動態地啟動新的 kernel 函數,而無需 CPU 的干預。這意味著 GPU 可以根據實際的計算需求,自主地進行任務調度和同步,從而更好地利用 GPU 的并行計算資源。
3.4 Maxwell(2014-2016)
3.4.1 Maxwell Architecture Overview
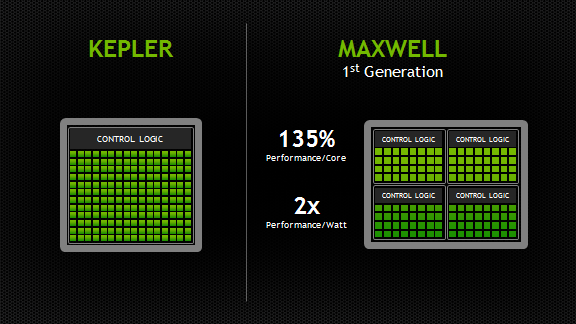
??Maxwell 架構作為 NVIDIA 在 Kepler 之后推出的 GPU 微架構,其核心目標是顯著提升能效比,并在圖形性能和功能上進行優化。與 Kepler 相比,Maxwell 的主要新特性和區別體現在以下幾個方面:
- SM 設計的重大改進: Maxwell 架構重新設計了流式多處理器 (SM),將其劃分為更小的處理單元,每個單元包含更少的 CUDA 核心。這種設計使得 Maxwell 能夠更精細地控制功耗,并更好地利用 GPU 的并行計算資源。具體來說,Maxwell 的 SM 包含 128 個 CUDA 核心,分為 4 個獨立的調度器和 4 個 32 核心的處理塊,而 Kepler 的 SMX 則包含 192 個 CUDA 核心。
- 能效比的顯著提升: 通過對 SM 設計的優化和寄存器文件的改進,Maxwell 架構在能效比上實現了顯著的提升。這意味著在相同功耗下,Maxwell 能夠提供更高的性能。
- 圖形性能和功能的改進: Maxwell 架構支持 NVIDIA 的 VXGI (Voxel Global Illumination) 技術,能夠提供更逼真的光照效果。此外,Maxwell 還支持多幀采樣抗鋸齒 (MFAA) 技術,能夠以較低的性能代價提供高質量的抗鋸齒效果。
- 視頻編碼的改進: Maxwell 架構引入了新的 NVENC 視頻編碼器,能夠提供更高的編碼效率和更好的視頻質量。此外,Maxwell 架構還支持 HDCP 2.2,能夠播放受保護的 4K 內容。
- L2 緩存的改進: 在 Maxwell 架構的 GM20x 版本中,NVIDIA 增加了 L2 緩存的容量,提高了顯存帶寬,從而進一步提升了性能。
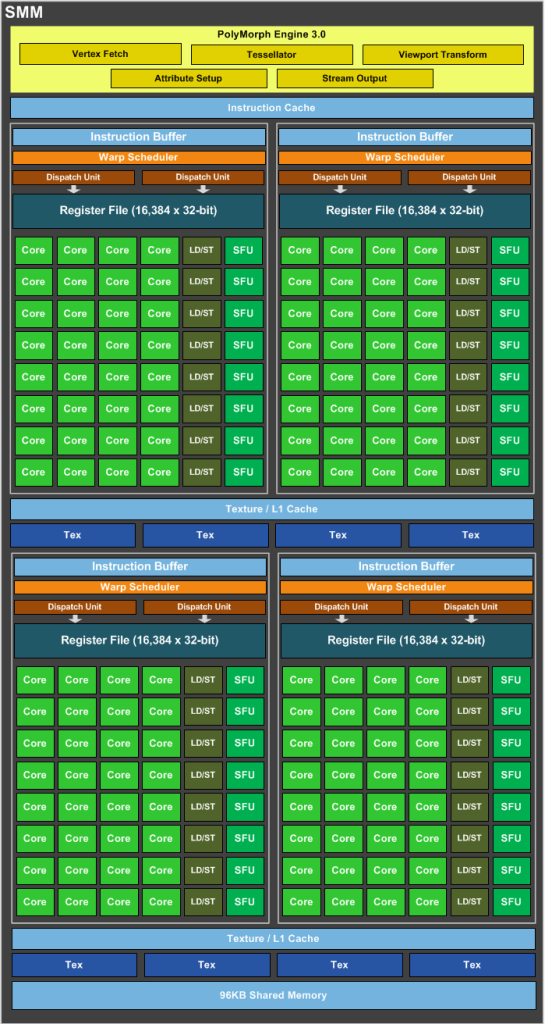
3.4.2 SMM: The Maxwell Multiprocessor
??Maxwell 架構能效表現的核心在于其流式多處理器,即 SMM。Maxwell 的全新數據路徑組織和改進的指令調度器,每個 CUDA 核心提供的性能提升超過 40%,整體效率是 Kepler GK104 的兩倍。新的 SMM 包含了第一代 Maxwell 的所有架構優勢,包括控制邏輯分區、工作負載平衡、時鐘門控粒度、指令調度、每個時鐘周期發出的指令數量等方面的改進。SMM 采用基于象限的設計,包含四個 32 核處理塊,每個塊都有一個專用的 warp 調度器,能夠每個時鐘周期分派兩條指令。每個 SMM 提供八個紋理單元、一個多形引擎(用于圖形的幾何處理),以及專用的寄存器文件和共享內存。
3.5 Pascal (2016-2017)
3.5.1 Pascal Architecture Overview
??Pascal 架構是 NVIDIA 在 Maxwell 之后推出的 GPU 微架構,主要應用于 GeForce 10 系列和 Tesla P100 等顯卡。Pascal 架構在性能、能效和功能方面都實現了顯著的提升。以下是 Pascal 架構的一些新特性:
- 16nm FinFET 工藝: Pascal 架構采用了 16nm FinFET 制造工藝,相比 Maxwell 的 28nm 工藝,晶體管密度更高,功耗更低,從而提高了性能和能效。
- SM 設計的改進: Pascal 架構的 SM 包含 64-128 個 CUDA 核心 (取決于 GP100 還是 GP104 芯片),改進了 SM 的調度器和指令分派機制,提高了 SM 的效率。引入了并發指令調度技術,允許 SM 同時執行多個獨立的指令,從而進一步提高了性能。
- HBM2 和 GDDR5X 顯存: Pascal 架構采用了 HBM2 和 GDDR5X 兩種顯存技術。HBM2 具有更高的帶寬和更低的功耗,主要應用于 Tesla P100 等高性能計算卡。GDDR5X 則具有更高的頻率和更大的容量,主要應用于 GeForce 10 系列顯卡。
- NVLink 互聯技術: Pascal 架構引入了 NVLink 技術,能夠提供更高的帶寬和更低的延遲,主要應用于 Tesla P100 等高性能計算卡,用于連接多個 GPU 和 CPU。
- FP16 計算支持: Pascal 架構支持 FP16 (半精度浮點數) 計算,能夠加速深度學習的訓練和推理。
- CUDA 8.0: Pascal 架構支持 CUDA 8.0,提供了更豐富的 API 和工具,方便開發者進行 GPU 編程.
- 統一內存 (Unified Memory): CPU 和 GPU 可以訪問主系統內存和顯卡上的內存,這要歸功于一種稱為“頁面遷移引擎”的技術。
- 動態負載平衡調度系統: 允許調度程序動態調整分配給多個任務的 GPU 數量,確保 GPU 保持工作飽和狀態,除非沒有更多可以安全地分配以進行分配的工作。
??總的來說,Pascal 架構在制造工藝、SM 設計、顯存技術、互聯技術和計算能力等方面都進行了重大改進,為深度學習、高性能計算和游戲等領域帶來了革命性的變革。(下圖是GP100的架構圖,其他類型的架構類似區別是不同的CUDA核心和SM數量)

3.5.2 Stream Multiprocessor
??Pascal 架構的 SM (Streaming Multiprocessor) 相比于前代 Maxwell 架構的 SM,主要區別體現在以下幾個方面:
- CUDA 核心數量: Pascal 架構的 SM 中 CUDA 核心的數量取決于具體的芯片型號。在 GP100 芯片中,每個 SM 包含 64 個 CUDA 核心,而在 GP104 芯片中,每個 SM 包含 128 個 CUDA 核心。相比之下,Maxwell 架構的 GM204 芯片中,每個 SM 包含 128 個 CUDA 核心。
- 調度器和指令分派機制的改進: Pascal 架構改進了 SM 的調度器和指令分派機制,提高了 SM 的效率。Pascal 架構引入了并發指令調度 (Concurrent Instruction Scheduling) 技術,允許 SM 同時執行多個獨立的指令,從而進一步提高了性能。
- FP16 計算支持: Pascal 架構的 SM 支持 FP16 (半精度浮點數) 計算,能夠加速深度學習的訓練和推理。Maxwell 架構的 SM 則不支持 FP16 計算。
- 統一內存 (Unified Memory): CPU 和 GPU 可以訪問主系統內存和顯卡上的內存,這要歸功于一種稱為“頁面遷移引擎”的技術。
- 動態負載平衡調度系統: 允許調度程序動態調整分配給多個任務的 GPU 數量,確保 GPU 保持工作飽和狀態,除非沒有更多可以安全地分配以進行分配的工作。
??總的來說,Pascal 架構的 SM 在調度器和指令分派機制、FP16 計算支持和 CUDA 8.0 支持等方面都進行了改進,從而提高了性能和效率。
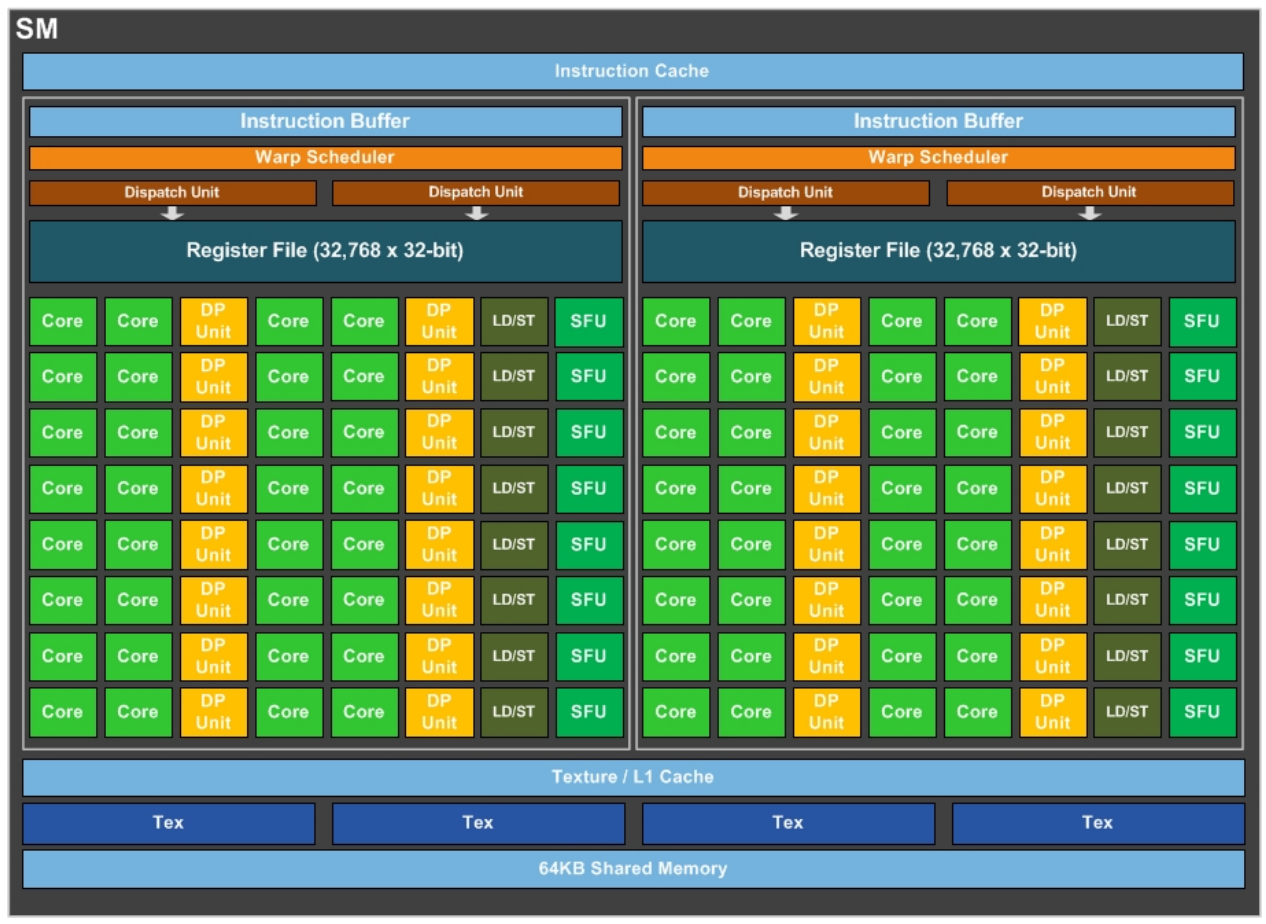
圖上的黃色部分DPUnit為雙精度運算單元。
3.6 Volta (2017-2018)
3.6.1 Volta Architecture Overview
??
??Volta 架構是 NVIDIA 在 Pascal 架構之后推出的 GPU 微架構,主要應用于 Tesla V100 等高性能計算卡。Volta 架構在深度學習性能方面實現了顯著的提升,為人工智能領域帶來了新的突破。 Volta 架構的核心目標是加速深度學習的訓練和推理。為了實現這一目標,Volta 架構在 SM (Streaming Multiprocessor) 設計、顯存技術、互聯技術和計算能力等方面都進行了重大改進。
??Volta 架構的 SM 包含 640 個 CUDA 核心和 80 個 Tensor 核心。Tensor 核心是 Volta 架構中新增的專門用于加速深度學習計算的硬件單元。每個 Tensor 核心能夠執行混合精度浮點運算 (FP16 和 FP32),從而加速深度學習模型的訓練和推理。
??在顯存技術方面,Volta 架構采用了 HBM2 (High Bandwidth Memory 2) 顯存,能夠提供更高的帶寬和更低的功耗。
??在互聯技術方面,Volta 架構引入了 NVLink 2.0 技術,能夠提供更高的帶寬和更低的延遲。NVLink 2.0 技術主要應用于 Tesla V100 等高性能計算卡,用于連接多個 GPU 和 CPU。
??在計算能力方面,Volta 架構支持 CUDA 9.0,提供了更豐富的 API 和工具,方便開發者進行 GPU 編程。此外,Volta 架構還支持獨立線程調度 (Independent Thread Scheduling),能夠提高 GPU 的利用率。
??Volta 架構的主要特點包括:
- Tensor 核心: Volta 架構中新增的專門用于加速深度學習計算的硬件單元,能夠執行混合精度浮點運算 (FP16 和 FP32)。
- HBM2 顯存: 能夠提供更高的帶寬和更低的功耗。
- NVLink 2.0 技術: 能夠提供更高的帶寬和更低的延遲。
- CUDA 9.0: 提供了更豐富的 API 和工具,方便開發者進行 GPU 編程。
- 獨立線程調度: 能夠提高 GPU 的利用率。

3.6.2 Volta Streaming Multiprocessor
??Volta 架構的 SM (Streaming Multiprocessor) 單元的組成是其核心創新之一,尤其是在深度學習性能方面。與之前的 Pascal 架構相比,Volta 的 SM 單元進行了重大改進。以下是 Volta SM 單元的主要組成部分:
- CUDA 核心 (CUDA Cores): Volta 架構的 SM 包含 640 個 CUDA 核心。這些核心用于執行傳統的浮點和整數運算,是 GPU 通用計算的基礎。
- Tensor 核心 (Tensor Cores): 這是 Volta 架構中最顯著的創新。每個 SM 包含 8 個 Tensor 核心。 Tensor 核心專門設計用于加速深度學習中的矩陣乘法運算,尤其是在訓練神經網絡時。 Tensor 核心能夠高效地執行混合精度浮點運算 (FP16 乘法和 FP32 累加),從而顯著提高深度學習模型的訓練速度。
- L1 Cache 和共享內存 (Shared Memory): Volta 架構的 SM 共享一個統一的 128KB L1 Cache 和共享內存。 這個統一的內存池可以靈活地配置為 L1 Cache 或共享內存,以適應不同的工作負載。 L1 Cache 用于緩存常用的數據,減少對全局內存的訪問,提高性能。 共享內存允許 SM 中的線程共享數據,實現高效的線程間通信。
- 紋理單元 (Texture Units): Volta 架構的 SM 仍然包含紋理單元,用于執行紋理過濾等操作。 雖然 Volta 架構主要關注深度學習,但它仍然保留了對傳統圖形應用的支持。
- 調度器 (Schedulers) 和分派單元 (Dispatch Units): Volta 架構的 SM 包含多個調度器和分派單元,用于管理和分配線程的執行。 這些調度器和分派單元能夠高效地利用 SM 中的各個單元,實現高吞吐量。

3.7 Turing (2018-2020)
3.7.1 Turing Architecture Overview
??圖靈 (Turing) 架構是 NVIDIA 在 Volta 架構之后推出的 GPU 微架構。 它主要應用于 GeForce RTX 20 系列和 Quadro RTX 系列顯卡。 圖靈架構在游戲和專業可視化領域引入了多項創新技術,例如光線追蹤和深度學習超采樣 (DLSS)。
??圖靈架構的核心目標是實現實時光線追蹤和 AI 增強圖形。 為了實現這些目標,圖靈架構在 SM (Streaming Multiprocessor) 設計、顯存技術、光線追蹤單元和 AI 核心等方面都進行了重大改進。
??圖靈架構的 SM 包含 CUDA 核心、Tensor 核心和 RT 核心 (光線追蹤核心)。 CUDA 核心用于執行傳統的浮點和整數運算。 Tensor 核心用于加速深度學習計算。 RT 核心則專門用于加速光線追蹤計算。
??在顯存技術方面,圖靈架構采用了 GDDR6 顯存,能夠提供更高的帶寬和更低的功耗。
圖靈架構的主要特點包括:
- RT 核心 (Ray Tracing Cores): 圖靈架構中新增的專門用于加速光線追蹤計算的硬件單元。 RT 核心能夠加速光線與三角形的相交測試,從而實現實時光線追蹤。
- Tensor 核心 (Tensor Cores): 圖靈架構的 Tensor 核心經過改進,能夠更高效地執行深度學習計算。 Tensor 核心主要用于加速 DLSS (Deep Learning Super-Sampling) 等 AI 增強圖形技術。
- GDDR6 顯存: 能夠提供更高的帶寬和更低的功耗。
- Mesh Shading: 一種新的幾何處理技術,能夠提高復雜場景的渲染效率。
- 可變速率著色 (Variable Rate Shading, VRS): 一種新的著色技術,能夠根據圖像內容調整著色速率,從而提高性能。
- NVIDIA NGX: 一種新的神經網絡圖形框架,能夠簡化 AI 增強圖形技術的開發。
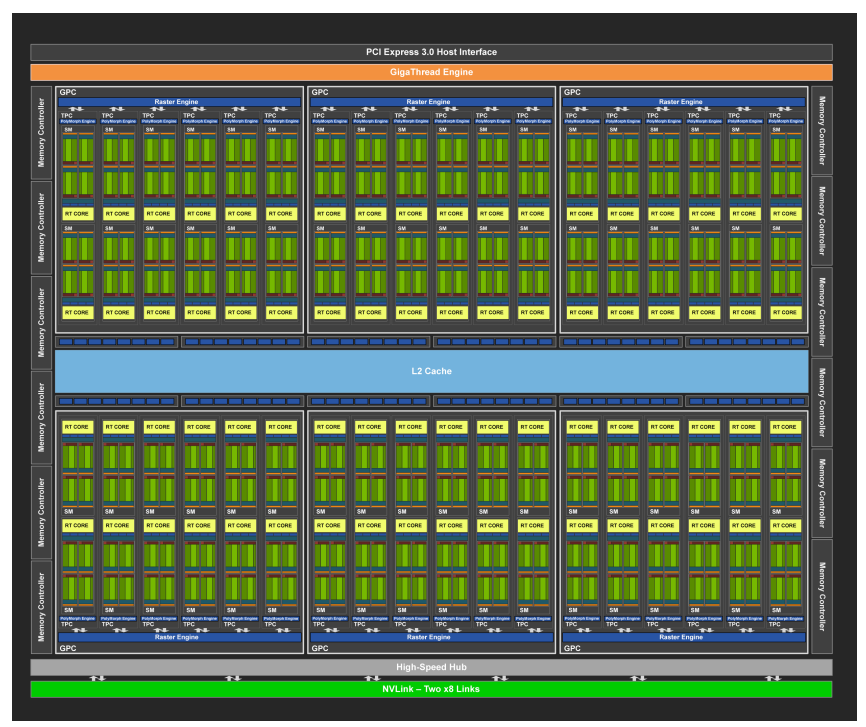
3.7.2 Turing Streaming Multiprocessor
??圖靈 (Turing) 架構的 SM (Streaming Multiprocessor) 單元在設計上借鑒了 Volta GV100 架構的許多特性,并進行了改進。主要特點:
- 數量和組成: 每個 TPC (Texture Processing Cluster) 包含兩個 SM。 每個 SM 包含 64 個 FP32 核心 (用于浮點運算) 和 64 個 INT32 核心 (用于整數運算)。 相比之下,Pascal GP10x GPU 每個 TPC 只有一個 SM,每個 SM 有 128 個 FP32 核心。
- 并行執行: 圖靈 SM 支持 FP32 和 INT32 操作的并行執行,以及類似于 Volta GV100 GPU 的獨立線程調度。
- 專用核心: 每個圖靈 SM 還包含 8 個混合精度圖靈 Tensor 核心 (用于加速深度學習) 和 1 個 RT 核心 (用于加速光線追蹤)。
- 處理塊: 圖靈 SM 被劃分為四個處理塊,每個塊包含 16 個 FP32 核心、16 個 INT32 核心、2 個 Tensor 核心、1 個 warp 調度器和 1 個分派單元。
- 緩存: 每個處理塊包含一個新的 L0 指令緩存和一個 64 KB 寄存器文件。 四個處理塊共享一個組合的 96 KB L1 數據緩存/共享內存。
- 內存分配: 對于傳統的圖形工作負載,96 KB L1/共享內存被劃分為 64 KB 的專用圖形著色器 RAM 和 32 KB 的紋理緩存和寄存器文件溢出區域。 對于計算工作負載,可以將 96 KB 劃分為 32 KB 共享內存和 64 KB L1 緩存,或 64 KB 共享內存和 32 KB L1 緩存。
- 執行數據路徑: 圖靈架構對核心執行數據路徑進行了重大改進。 它在每個 CUDA 核心旁邊增加了一個并行的執行單元,用于并行執行整數運算等非浮點運算指令,從而提高了效率
3.8 Ampere (2020-2022)
3.8.1 Ampere Architecture Overview
??Ampere 架構是 NVIDIA 在 Turing 架構之后推出的 GPU 微架構。 它主要應用于 GeForce RTX 30 系列顯卡和 NVIDIA A100 等數據中心 GPU。 Ampere 架構在游戲、專業可視化和數據中心等領域都實現了顯著的性能提升。
??Ampere 架構的核心目標是提高 GPU 的計算效率和性能,尤其是在人工智能和高性能計算方面。 為了實現這些目標,Ampere 架構在 SM (Streaming Multiprocessor) 設計、顯存技術、Tensor 核心和互聯技術等方面都進行了重大改進。
??Ampere 架構的 SM 在 Turing 架構的基礎上進行了重新設計,提高了 FP32 和 INT32 的吞吐量。 Ampere 架構的 SM 包含更多的 CUDA 核心,能夠提供更高的計算性能。
??在顯存技術方面,Ampere 架構采用了 GDDR6X 顯存 (在 GeForce RTX 3080 和 RTX 3090 上) 和 HBM2e 顯存 (在 NVIDIA A100 上),能夠提供更高的帶寬和更低的功耗。
??Ampere 架構的主要特點包括:
- 第二代 RT 核心 (2nd Generation Ray Tracing Cores): Ampere 架構的 RT 核心在第一代的基礎上進行了改進,能夠提供更高的光線追蹤性能。
- 第三代 Tensor 核心 (3rd Generation Tensor Cores): Ampere 架構的 Tensor 核心在第二代的基礎上進行了改進,能夠更高效地執行深度學習計算。 Ampere 架構的 Tensor 核心支持稀疏性 (sparsity),能夠進一步提高深度學習模型的訓練和推理速度。
- GDDR6X 顯存: 能夠提供更高的帶寬和更低的功耗 (僅限部分型號)。
- HBM2e 顯存: 能夠提供更高的帶寬和更低的功耗 (僅限部分型號)。
- PCIe 4.0: 支持 PCIe 4.0,能夠提供更高的帶寬。
- NVLink 3.0: Ampere 架構引入了 NVLink 3.0 技術,能夠提供更高的帶寬和更低的延遲 (僅限部分型號)。
- 多實例 GPU (Multi-Instance GPU, MIG): Ampere 架構支持 MIG 技術,可以將一個 GPU 劃分為多個獨立的 GPU 實例,從而提高 GPU 的利用率 (僅限部分型號)。
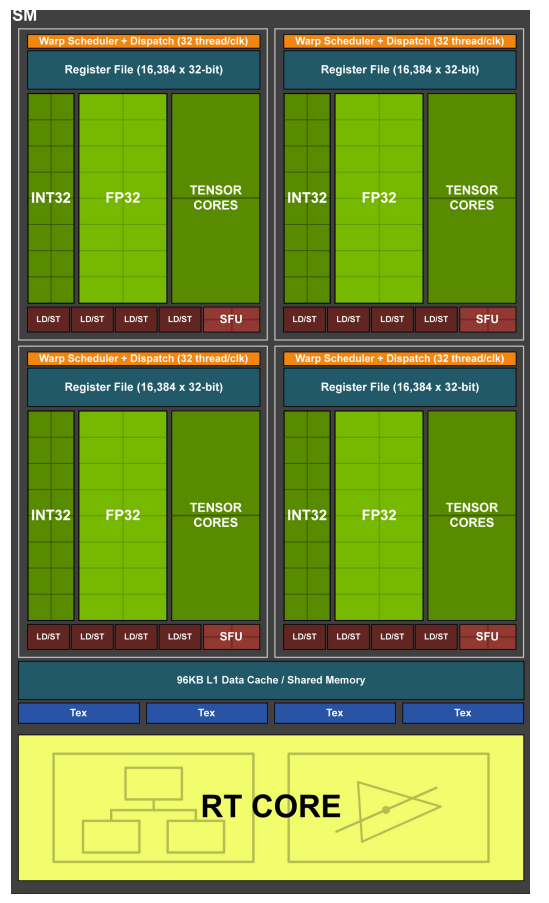
3.8.2 Ampere Streaming Multiprocessor
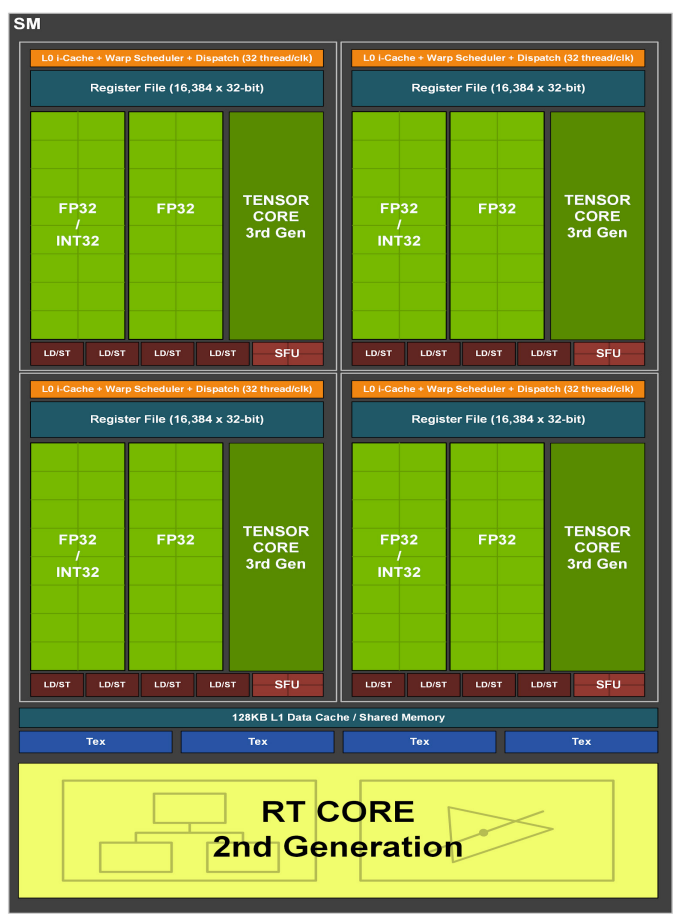
??Ampere 架構對 SM 進行了重大改進,使其在性能和效率方面都得到了提升。與 Turing 架構相比,Ampere SM 的主要變化包括:
- 更高的 FP32 吞吐量:
- 在 Turing 架構中,SM 包含獨立的 FP32 (浮點) 和 INT32 (整數) 單元。Ampere 架構將 FP32 的吞吐量翻倍。
- Ampere SM 中的每個分區都包含 16 個 FP32 CUDA 核心,這些核心可以并行執行 FP32 運算。這意味著 Ampere 架構在處理圖形和計算任務時,可以更快地完成浮點運算。
- 獨立的 FP32 和 INT32 數據路徑:與 Turing 架構類似,Ampere 架構也保留了獨立的 FP32 和 INT32 數據路徑,允許并行執行浮點和整數運算。這對于現代著色器和計算工作負載非常重要,因為它們通常需要混合使用浮點和整數運算。
- 改進的 Tensor 核心:
- Ampere 架構配備了第三代 Tensor 核心,與 Turing 架構的第二代 Tensor 核心相比,性能得到了顯著提升。
- 第三代 Tensor 核心支持稀疏性 (Sparsity),這是一種利用神經網絡中零值數據的技術,可以進一步提高深度學習模型的訓練和推理速度。
- 更大的 L1 緩存:Ampere 架構的 L1 緩存容量更大,可以減少對全局內存的訪問,提高性能。
- 統一的共享內存和 L1 緩存: 與 Turing 架構類似,Ampere 架構也采用了統一的共享內存和 L1 緩存,可以靈活地配置以適應不同的工作負載。
3.9 Ada Lovelace (2022-至今)
3.9.1 Ada Lovelace Architecture Overview
??Ada Lovelace 架構是 NVIDIA 在 Ampere 架構之后推出的最新一代 GPU 微架構。 它主要應用于 GeForce RTX 40 系列顯卡。 Ada Lovelace 架構在游戲、專業可視化和人工智能等領域都帶來了顯著的性能提升和創新技術。
??Ada Lovelace 架構的核心目標是實現更高的性能和效率,并提供更逼真的圖形效果。 為了實現這些目標,Ada Lovelace 架構在 SM (Streaming Multiprocessor) 設計、顯存技術、光線追蹤單元和 AI 核心等方面都進行了重大改進。
??Ada Lovelace 架構的主要特點包括:
- 第三代 RT 核心 (3rd Generation Ray Tracing Cores): Ada Lovelace 架構的 RT 核心在第二代的基礎上進行了改進,能夠提供更高的光線追蹤性能。 新的 RT 核心引入了 Displaced Micro-Meshes 和 Opacity Micromaps 等技術,可以更高效地處理復雜的光線追蹤場景。
- 第四代 Tensor 核心 (4th Generation Tensor Cores): Ada Lovelace 架構的 Tensor 核心在第三代的基礎上進行了改進,能夠更高效地執行深度學習計算。 新的 Tensor 核心支持 FP8 數據類型,可以進一步提高深度學習模型的訓練和推理速度。
- DLSS 3 (Deep Learning Super Sampling 3): Ada Lovelace 架構引入了 DLSS 3 技術,它利用 AI 生成額外的幀,從而顯著提高游戲性能。 DLSS 3 結合了 DLSS Super Resolution、DLSS Frame Generation 和 NVIDIA Reflex 等技術,可以提供更流暢、更逼真的游戲體驗。
- Shader Execution Reordering (SER): Ada Lovelace 架構引入了 SER 技術,可以動態地重新排序著色器工作負載,從而提高 GPU 的利用率和性能。
- AV1 編碼器: Ada Lovelace 架構集成了 AV1 編碼器,可以提供更高的視頻編碼效率。
3.9.2 Ada Lovelace Streaming Multiprocessor
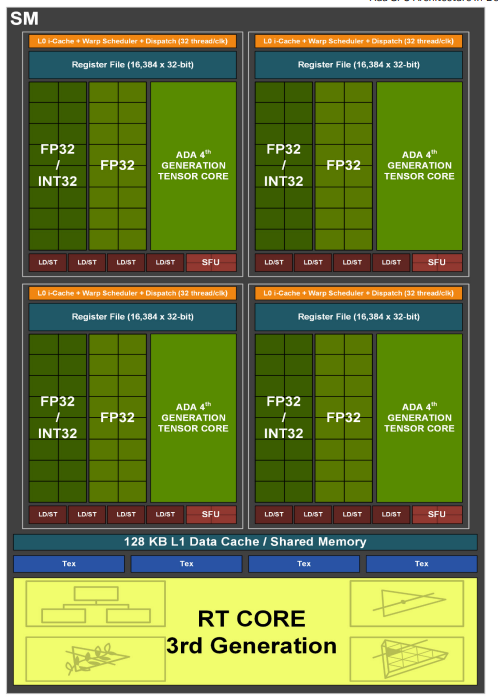
??Ada Lovelace 架構的 SM 在 Ampere 架構的基礎上進行了顯著的改進,旨在提高性能、效率和光線追蹤能力。
??主要改進和特點:
- 更高的時鐘頻率和效率: Ada Lovelace 架構的 SM 旨在以更高的時鐘頻率運行,從而提高整體性能。此外,架構改進旨在提高每個時鐘周期的指令吞吐量,從而提高效率。
- 第三代 RT Cores: Ada Lovelace 架構包含第三代 RT Cores,與之前的架構相比,光線追蹤性能得到了顯著提升。這些 RT Cores 包含新的硬件單元,可以加速光線三角形相交測試和光線追蹤計算。
- 第四代 Tensor Cores: Ada Lovelace 架構包含第四代 Tensor Cores,與之前的架構相比,AI 性能得到了顯著提升。這些 Tensor Cores 支持新的數據類型和技術,例如 FP8,可以加速深度學習訓練和推理。
- Shader Execution Reordering (SER): SER 是一種新的技術,可以動態地重新排序著色器工作負載,從而提高 GPU 的利用率和性能。SER 可以通過減少著色器核心的停頓時間來提高效率。
- Displaced Micro-Meshes: Ada Lovelace 架構引入了 Displaced Micro-Meshes,這是一種新的幾何圖形表示方法,可以更有效地表示復雜場景中的細節。Displaced Micro-Meshes 可以與光線追蹤技術結合使用,以實現更逼真的渲染效果。
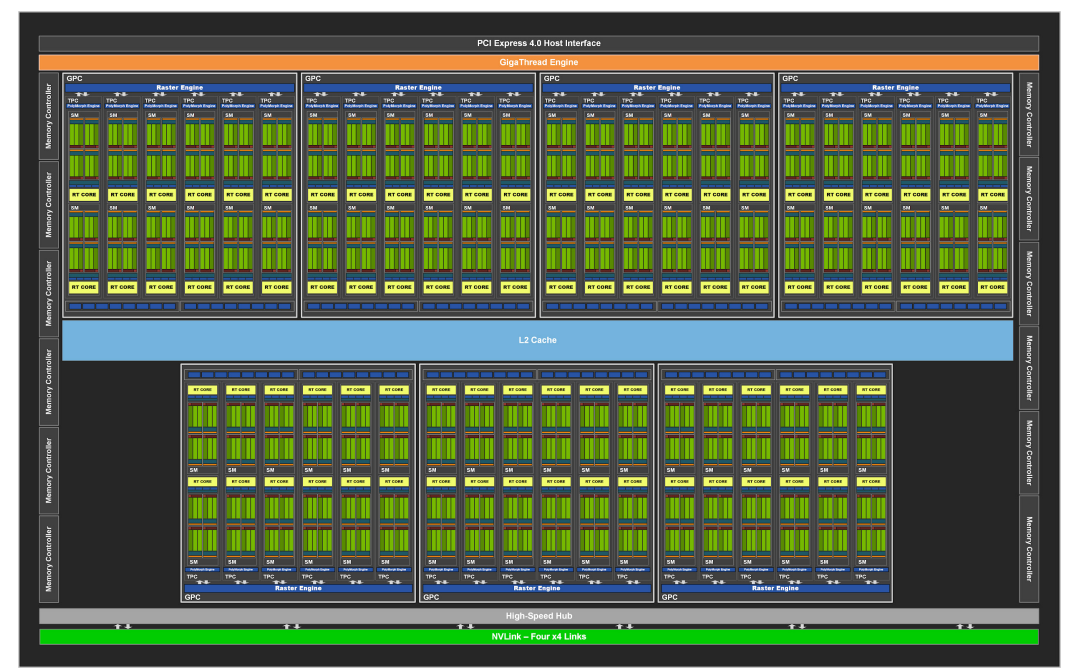
3.10 Blackwell (2024-)
3.10.1 Blackwell Architecture Overview
??NVIDIA Blackwell 架構是 NVIDIA 最新發布的 GPU 架構,旨在為加速計算、人工智能和數據分析提供前所未有的性能。 它被認為是 NVIDIA 有史以來最強大的芯片,并有望在各個行業帶來革命性的變化。
??主要特點和創新:
- 雙芯片設計: Blackwell 架構采用雙芯片設計,將兩個獨立的 GPU 芯片互連為一個統一的 GPU。 這種設計可以有效地提高 GPU 的計算能力和內存帶寬。
- 下一代 Tensor Cores: Blackwell 架構配備了下一代 Tensor Cores,與之前的架構相比,AI 性能得到了顯著提升。 新的 Tensor Cores 支持 FP4 和 FP6 等新的數據類型,可以進一步提高深度學習模型的訓練和推理速度。
- Transformer Engine: Blackwell 架構引入了 Transformer Engine,專門用于加速 Transformer 模型的訓練和推理。 Transformer 模型是自然語言處理領域最流行的模型之一,Transformer Engine 可以顯著提高這些模型的性能。
- NVLink 5: Blackwell 架構支持 NVLink 5 互連技術,可以提供更高的帶寬和更低的延遲。 NVLink 5 可以將多個 Blackwell GPU 連接在一起,以構建更大規模的計算系統。
- 保密計算: Blackwell 架構支持保密計算,可以在保護數據隱私的同時進行計算。 保密計算對于金融、醫療保健等敏感數據處理領域非常重要。
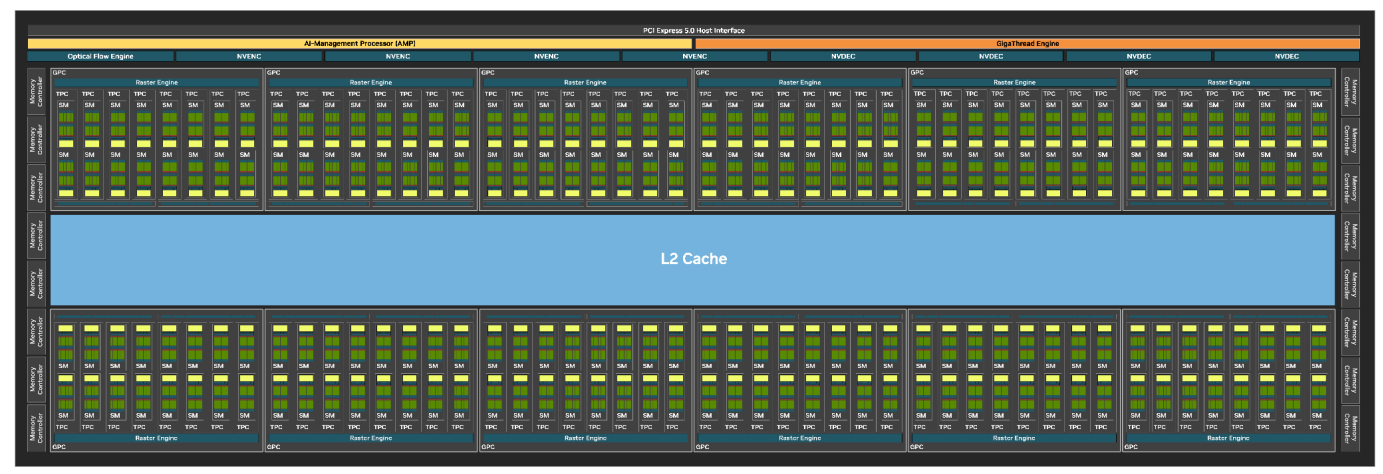
3.10.2 Blackwell Streaming Architecture

??Blackwell 架構 SM 的主要特點:
- SM 數量: 每個完整的 GB202 芯片包含 192 個 SM。
- CUDA 核心: 每個 SM 包含 128 個 CUDA 核心。
- RT 核心: 每個 SM 包含 1 個 Blackwell 第四代 RT 核心。
- Tensor 核心: 每個 SM 包含 4 個 Blackwell 第五代 Tensor 核心。
- 紋理單元: 每個 SM 包含 4 個紋理單元。
- 寄存器文件: 每個 SM 包含 256 KB 的寄存器文件。
- L1/共享內存: 每個 SM 包含 128 KB 的 L1/共享內存,可以根據圖形和計算工作負載的需求配置不同的內存大小。
- INT32 整數運算: Blackwell 架構中的 INT32 整數運算數量是 Ada 架構的兩倍,通過將它們與 FP32 核心完全統一來實現。 但是,在任何給定的時鐘周期內,統一的核心只能作為 FP32 或 INT32 核心運行。
4 參考文獻
- Nvidia-NV1
- Nvidai-GeForce256
- Nvidia-架構
- Nvidia GPU架構梳理
- NVIDIA GPU 核心與架構演進史
- Impact analysis of conditional and loop statements for the NVIDIA G80 architecture
- GPU Architecture: the Fermi’s example
- Whitepaper NVIDIA’s Next Generation CUDATM Compute Architecture: Fermi
- List of Fermi series GeForce GPUs
- Whitepaper NVIDIA’s Next Generation CUDATM Compute Architecture: Kepler TM GK110/210
- Maxwell: The Most Advanced CUDA GPU Ever Made
- Whitepaper NVIDIA Tesla P100 The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World’s Fastest GPU
- NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD’S MOST ADVANCED DATA CENTER GPU
- NVIDIA TURING GPU ARCHITECTURE Graphics Reinvented
- NVIDIA TURING GPU ARCHITECTURE
- NVIDIA AMPERE GA102 GPU ARCHITECTURE Second-Generation RTX
- NVIDIA ADA GPU ARCHITECTURE Designed to deliver outstanding gaming and creating, professional graphics, AI, and compute performance.
- NVIDIA RTX BLACKWELL GPU ARCHITECTURE Built for Neural Rendering




)







![[圖論]生成樹 引言](http://pic.xiahunao.cn/[圖論]生成樹 引言)





:在商品對象創建系統中的應用)
