1.MySQL的基礎架構是什么?
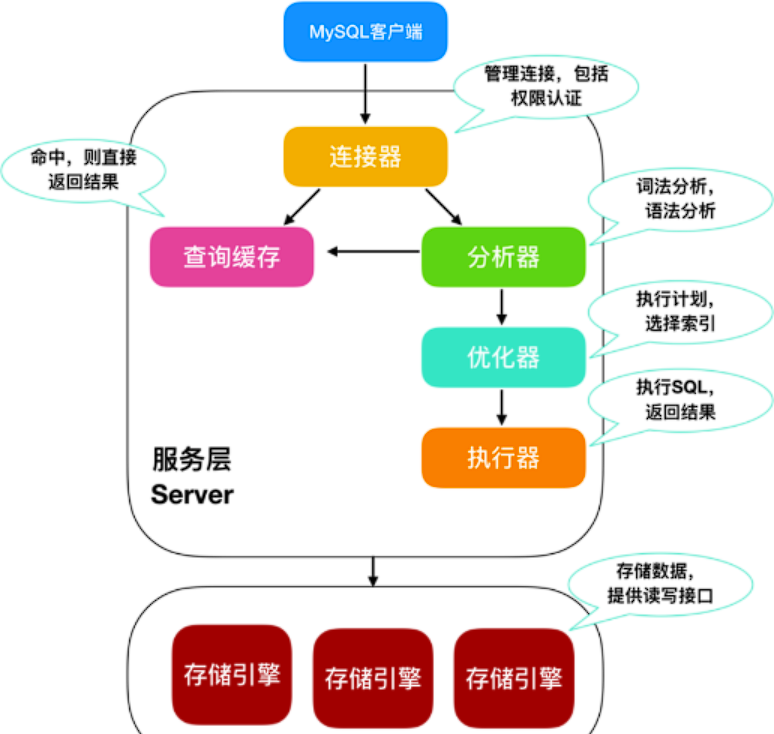
MySQL由連接器、分析器、優化器、執行器和存儲引擎這五部分構成。
一條SQL的執行流程:
- 通過
連接器連接數據庫,檢查用戶名和密碼,以及權限校驗,是否有增刪改查的權限。 - 在MySQL8.0之前,連接完數據庫后會先判斷緩存是否有數據,如果執行過這個SQL語句,直接返回。8.0之后沒有了緩存,直接進入
分析器,進行詞法分析判斷執行的什么操作,語法分析檢查語句是否存在問題。 - 進入
優化器,選擇合適的索引以及查詢的順序,由優化器指定執行計劃。 - 進入
執行器之前先進行權限校驗,權限信息是從連接器中取出來的,權限沒問題就開始執行。 - 最后由存儲引擎負責讀寫數據,MySQL默認的存儲引擎是
InnoDB,采用Buffer Pool來減少對磁盤的直接I/O,并通過redo log和undo log來保證事務的持久性和原子性。
SQL語句的執行順序是From子句返回初始結果集,WHERE子句排除不滿足條件的行,GROUP BY子句進行分組,HAVING子句排除不滿足條件的組,最后經過ORDER BY子句對結果集進行排序。
2.MySQL中有哪些存儲引擎?
MySQL中的存儲引擎是插件式的,可以為不同的數據庫表設置不同的存儲引擎。主要有四種存儲引擎,InnoDB、MyISAM、Memory和Archive。
- InnoDB是支持
事務完整的ACID特性的,MyISAM、Memory和Archive都不支持事務。 - InnoDB和Archive采用的是
行級鎖,而MyISAM和Memory采用的是表級鎖。 - InnoDB支持
外鍵,保證數據的完整性,而其它的存儲引擎都不支持外鍵。 - InnoDB通過
redo log和undo log來實現崩潰后的自動恢復,其他幾種存儲引擎不支持崩潰后的自動恢復。 - InnoDB的
存儲方式是數據與索引一體,MyISAM是數據與索引分離。Memory存儲在內存,Archive進行壓縮存儲。 - InnoDB主要用于高并發的場景下,MyISAM適合靜態讀,Memory適合存放臨時數據,Archive存放歸檔數據。
3.什么是MySQL索引?
創建索引的目的就是加快檢索速度,但是維護索引需要耗費性能。
- MySQL索引默認采用的數據結構是
B+樹,B+樹的數據全部存放在葉子節點上,這樣就可以組織更寬的樹,樹高就會降低,減少磁盤I/O。 - B+樹采用
雙向鏈表,非常適合范圍查詢和排序。
4.什么是二級索引(非聚簇索引)?
非聚簇索引就是非主鍵做為索引,可以有多個,葉子節點存放的是主鍵值。
5.什么是聚簇索引?
聚簇索引就是將主鍵做為索引,只能有一個,葉子節點存放的是整行數據。如果表中沒有主鍵,默認使用唯一字段做為索引,如果沒有唯一字段就采用隱藏字段rowid做為索引。
6.什么是回表查詢?
回表查詢就是通過非聚簇索引找到主鍵值,再通過聚簇索引找到對應的數據。非聚簇索引不一定回表查詢,比如查詢用戶名,用戶名正好建立了索引,直接返回就可以。
7.什么是覆蓋索引?
覆蓋索引就是查詢使用了索引,返回的字段必須在索引中全部找到。覆蓋索引查詢就是一次性查詢,不需要回表查詢。如果我們使用主鍵進行查詢,那么就會采用聚簇索引返回所有字段的數據,這就是覆蓋索引查詢。
8.什么是聯合索引?
聯合索引就是多個字段創建的索引,相比于單列索引,每個索引對應一顆B+樹,而聯合索引只需要一顆B+樹。最左匹配原則就是在使用聯合索引時,MySQL會按照字段的順序,從左到右依次查詢字段。需要注意的是,如果查詢條件中存在范圍查詢,從這個范圍列開始就不會繼續向后匹配索引了。我們在使用聯合索引的時候,將區分度最高的字段放到左邊,這樣可以過濾更多的數據。
9.如何選擇合適的字段創建索引?
- 選擇
不為NULL的字段 - 選擇
查詢頻繁的字段 - 選擇做為
查詢條件的字段 - 選擇頻繁排隊的字段
10.什么情況下索引會失效?
- 組合索引未遵循
最左匹配原則 - 索引上進行
計算、類型轉換等操作 - 使用%開頭的LIKE模糊查詢
- 查詢條件
使用OR但是有一列沒有索引



第五期)










)




