第一章 PyTorch簡介和安裝
PyTorch是一個很強大的深度學習庫,在學術中使用占比很大。
我這里是Mac系統的安裝,相比起教程中的win/linux安裝感覺還是簡單不少(之前就已經安好啦),有需要指導的小伙伴可以評論。
第二章 基礎知識
這里劃重點!
- 張量的創建/隨機初始化
a = torch.tensor(1.0, dtype=torch.float)
d = torch.FloatTensor(2,3)
f = torch.IntTensor([1,2,3,4])
k = torch.rand(2, 3)
l = torch.ones(2, 3)
m = torch.zeros(2, 3)
n = torch.arange(0, 10, 2) #arrange用于創造等差數列 interval is 2
-
查看/修改維度
.shape or .size()
.view(row,column)
.unsqeeze(1)#加一維度
.squeeze(1) -
tensor&numpy.array
1.array->tensor
h = torch.tensor(g) #g = np.array([[1,2,3],[4,5,6]])
i = torch.from_numpy(g)2.tensor->array
j = h.numpy()
共享內存的情況
torch.from_numpy()和torch.as_tensor()從numpy array創建得到的張量和原數據是共享內存的,張量對應的變量不是獨立變量,修改numpy array會導致對應tensor的改變。
如代碼例中所示,修改g改變i
- tensor運算
o = torch.add(k,l)#o=k+l
#broadcast is two different size of tensors adding.
print(p + q)
- 靈活運用索引 [:]
- 自動求導
x1 = torch.tensor(1.0, requires_grad=True)
x1.grad.data是在有requires_grad=True即要求求導數的該數字的結果。
y.backward()反向傳播于梯度,不清0會累積。
x1.grad #可嘗試查看導數
第三章 組成模塊
-
設計及解決學習任務
步驟如下:
1.數據預處理(格式統一、數據變換、劃分訓練集/測試集的)
2.選擇模型,損失函數,優化函數,超參(常用:batch_size,learning rate ,max_epochs,configuration of gpu)
3.訓練并計算得到表現-深度學習&機器學習 1.深度學習樣本多,有批batch訓練。 2.層多,需要按順序逐層搭建。 3.損失函數,優化器使得其更靈活 -
gpu配置:略
-
數據讀入:Dataset+DataLoader
Dataset定義數據格式和變換形式,DataLoader用iterative的方式不斷讀入批次數據
自定義Dataset類需要繼承PyTorch自身的Dataset類。- 主要包含三個函數:
init: 用于向類中傳入外部參數,同時定義樣本集
getitem: 用于逐個讀取樣本集合中的元素,可以進行一定的變換,并將返回訓練/驗證所需的數據
len: 用于返回數據集的樣本數 - 涉及到的API
1.PyTorch自帶的ImageFolder類的用于讀取按一定結構存儲的圖片數據(path對應圖片存放的目錄,目錄下包含若干子目錄,每個子目錄對應屬于同一個類的圖片),其中“data_transform”可以對圖像進行一定的變換,如翻轉、裁剪等操作,可自己定義。
- 主要包含三個函數:
-
用cifar10數據集(識別普適物體的小型數據集)構建Dataset類實例:圖片存放在一個文件夾,另外有一個csv文件給出了圖片名稱對應的標簽。這種情況下需要自己來定義Dataset類
利用ImageFolder,
train_data = datasets.ImageFolder(root, transform=None, target_transform=None, loader=default_loader)- 關于ImageFolder,展開如下:(細節部分轉自https://blog.csdn.net/weixin_40123108/article/details/85099449,有改動)
root:在root指定的路徑下尋找圖片
transform:對PIL Image進行的轉換操作,transform的輸入是使用loader讀取圖片的返回對象
target_transform:對label的轉換
loader:給定路徑后如何讀取圖片,默認讀取為RGB格式的PIL Image對象 - label是按照文件夾名順序排序后存成字典,即{類名:類序號(從0開始)},一般來說最好直接將文件夾命名為從0開始的數字,這樣會和ImageFolder實際的label一致,如果不是這種命名規范,建議看看self.class_to_idx屬性以了解label和文件夾名的映射關系。

- 關于ImageFolder,展開如下:(細節部分轉自https://blog.csdn.net/weixin_40123108/article/details/85099449,有改動)
from torchvision import transforms as T
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
# cat文件夾的圖片對應label 0,dog對應1
print(dataset.class_to_idx)
# 所有圖片的路徑和對應的label
print(dataset.imgs)
print(dataset[0][1])# 第一維是第幾張圖,第二維為1返回label
print(dataset[0][0]) # 為0返回圖片數據
#transform配置
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([T.RandomResizedCrop(224),#即先隨機采集,然后對裁剪得到的圖像縮放為同一大小T.RandomHorizontalFlip(),#水平翻轉T.ToTensor(),normalize,
])
dataset = ImageFolder('data1/dogcat_2/', transform=transform)
# 深度學習中圖片數據一般保存成CxHxW,即通道數x圖片高x圖片寬
#print(dataset[0][0].size())
to_img = T.ToPILImage()
- 另一種讀入方式,自定義構建數據集
class MyDataset(Dataset):#to build dataset we needdef __init__(self, data_dir, info_csv, image_list, transform=None):"""Args:data_dir: path to image directory.info_csv: path to the csv file containing image indexeswith corresponding labels.image_list: path to the txt file contains image names to training/validation settransform: optional transform to be applied on a sample."""label_info = pd.read_csv(info_csv)image_file = open(image_list).readlines()#distinguish among read()/readline()/readlines()#link:https://zhuanlan.zhihu.com/p/26573496self.data_dir = data_dirself.image_file = image_file #custom/user-definedself.label_info = label_infoself.transform = transformdef __getitem__(self, index):#return image and label."""Args:index: the index of itemReturns:image and its labels"""image_name = self.image_file[index].strip('\n')#只要頭尾包含有指定字符序列中的字符就刪除,中間的刪不掉,若'12'則字符串中的'21'也能刪掉 raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name]#顯示索引:.loc,第一個參數為 index切片,第二個為 columns列名label = raw_label.iloc[:,0]#隱式索引:.iloc(integer_location), 只能傳入整數。image_name = os.path.join(self.data_dir, image_name)#path.join拼接規則https://www.jianshu.com/p/3090f7875f9bimage = Image.open(image_name).convert('RGB')if self.transform is not None:image = self.transform(image)return image, labeldef __len__(self):return len(self.image_file)
#Finishing dataset,we can use DataLoader to load batch data.
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
#batch_size:樣本是按“批”讀入的,batch_size就是每次讀入的樣本數
#num_workers:有多少個進程用于讀取數據
#shuffle:是否將讀入的數據打亂
#drop_last:對于樣本最后一部分沒有達到批次數的樣本,使其不再參與訓練
#PyTorch中的DataLoader的讀取可以使用next和iter來完成,next(iterable[, default])
#next() 返回迭代器的下一個項目。next() 函數要和生成迭代器的iter() 函數一起使用。
#iter()函數獲取這些可迭代對象的迭代器。對獲取到的迭代器不斷使?next()函數來獲取下?條數據,調?了可迭代對象的 iter ?法.
#iterable – 可迭代對象,default – 可選,用于設置在沒有下一個元素時返回該默認值,如果不設置,又沒有下一個元素則會觸發 StopIteration 異常。images, labels = next(iter(val_loader))
print(images.shape)
plt.imshow(images[0].transpose(1,2,0))
plt.show()
- 模型構建
基于 Module 類的模型來完成,Module 類是 nn 模塊里提供的一個模型構造類,是所有神經?網絡模塊的基類,我們可以繼承它來定義我們想要的模型。 Module 類它的子類既可以是?個層(如PyTorch提供的 Linear 類),?可以是一個模型(如這里定義的 MLP 類),或者是模型的?個部分。- 繼承 Module 類構造多層感知機。代碼中定義的 MLP (Multilayer Perceptron)類重載了 Module 類的 init 函數和 forward 函數。它們分別用于創建模型參數和定義前向計算。前向計算也即正向傳播。

- 繼承 Module 類構造多層感知機。代碼中定義的 MLP (Multilayer Perceptron)類重載了 Module 類的 init 函數和 forward 函數。它們分別用于創建模型參數和定義前向計算。前向計算也即正向傳播。
import torch
from torch import nnclass MLP(nn.Module):# 聲明帶有模型參數的層,這里聲明了兩個全連接層def __init__(self, **kwargs):# 調用MLP父類Block的構造函數來進行必要的初始化。這樣在構造實例時還可以指定其他函數super(MLP, self).__init__(**kwargs)self.hidden = nn.Linear(784, 256)#set fully connected layer#[in_features,out_features]#從輸入輸出的張量的shape角度來理解,相當于一個輸入為[batch_size, in_features]的張量變換成了[batch_size, out_features]的輸出張量。self.act = nn.ReLU()self.output = nn.Linear(256,10)# 定義模型的前向計算,即如何根據輸入x計算返回所需要的模型輸出def forward(self, x):o = self.act(self.hidden(x))return self.output(o) #實例化
X = torch.rand(2,784)
net = MLP()
print(net)
net(X)
以上的 MLP 類中?須定義反向傳播函數。系統將通過?動求梯度?自動?成反向傳播所需的 backward 函數。
我們可以實例化 MLP 類得到模型變量 net 。下?的代碼初始化 net 并傳入輸?數據 X 做一次前向計算。其中, net(X) 會調用 MLP 繼承?自 Module 類的 call 函數,這個函數將調?用 MLP 類定義的forward 函數來完成前向計算。
#Parameter 類其實是 Tensor 的子類,如果一 個 Tensor 是 Parameter ,那么它會?動被添加到模型的參數列表里。所以在?定義含模型參數的層時,我們應該將參數定義成 Parameter ,除了直接定義成 Parameter 類外,還可以使? ParameterList 和 ParameterDict 分別定義參數的列表和字典。#torch.mul()對應位相乘
#torch.mm()矩陣乘法
class MyListDense(nn.Module):def __init__(self):super(MyListDense, self).__init__()self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])self.params.append(nn.Parameter(torch.randn(4, 1)))def forward(self, x):for i in range(len(self.params)):x = torch.mm(x, self.params[i])return x
net = MyListDense()
print(net)class MyDictDense(nn.Module):def __init__(self):super(MyDictDense, self).__init__()self.params = nn.ParameterDict({'linear1': nn.Parameter(torch.randn(4, 4)),'linear2': nn.Parameter(torch.randn(4, 1))})self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增def forward(self, x, choice='linear1'):return torch.mm(x, self.params[choice])net = MyDictDense()
print(net)
- 卷積層

#卷積運算(二維互相關)
def corr2d(X, K): h, w = K.shapeX, K = X.float(), K.float()Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i: i + h, j: j + w] * K).sum()return Y
#Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
# 二維卷積層
class Conv2D(nn.Module):def __init__(self, kernel_size):super(Conv2D, self).__init__()self.weight = nn.Parameter(torch.randn(kernel_size))self.bias = nn.Parameter(torch.randn(1))def forward(self, x):return corr2d(x, self.weight) + self.bias #corr2d 上面的二維卷積運算
#padding
X = X.view((1, 1) + X.shape)#原shape前加兩個維度
# 在?和寬兩側的填充數分別為2和1,將每次滑動的行數和列數稱為步幅(stride)
conv2d = nn.Conv2d(..., padding=(2, 1), stride=(3, 4))
#pooling最大池化或平均池化if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max()elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
#一個nn.Module包含各個層和一個forward(input)方法,該方法返回output
#instance:
#前饋神經網絡 (feed-forward network)(LeNet)
#步驟:
#定義包含一些可學習參數(或者叫權重)的神經網絡
#在輸入數據集上迭代
#通過網絡處理輸入
#計算 loss (輸出和正確答案的距離)
#將梯度反向傳播給網絡的參數
#更新網絡的權重,一般使用一個簡單的規則:weight = weight - learning_rate * gradient
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
#n包則依賴于autograd包來定義模型并對它們求導。一個nn.Module包含各個層和一個forward(input)方法,該方法返回output。
#backward函數會在使用autograd時自動定義,backward函數用來計算導數。def __init__(self):super(Net, self).__init__()#Net找其父類,將父類init東西給self# 輸入圖像channel:1;輸出channel:6;5x5卷積核self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# 2x2 Max poolingx = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# 如果是方陣,則可以只使用一個數字進行定義x = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, self.num_flat_features(x))#把特征拍扁x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):#計算特征數用于拍扁size = x.size()[1:] # 除去批處理維度的其他所有維度num_features = 1for s in size:num_features *= sreturn num_features
net = Net()
print(net)#print the net's structure.#返回可學習參數
print(net.parameters())
params = list(net.parameters())
#print(params)
print(len(params))
print(params[0].size()) # conv1的權重#to use my model
#注意:這個網絡 (LeNet)的期待輸入是 32x32 的張量。如果使用 MNIST 數據集來訓練這個網絡,要把圖片大小重新調整到 32x32。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
net.zero_grad()#梯度清零
out.backward(torch.randn(1, 10))#隨機梯度的反向傳播
#torch.nn supports mini-batches rather than only one sample.
#nn.Conv2d 接受一個4維的張量,即nSamples x nChannels x Height x Width,如果是一個單獨的樣本,只需要使用input.unsqueeze(0) 來添加一個“假的”批大小維度。
-
涉及到的模塊總結
- torch.Tensor - 一個多維數組,支持諸如backward()等的自動求導操作,同時也保存了張量的梯度。
- nn.Module- 神經網絡模塊。是一種方便封裝參數的方式,具有將參數移動到GPU、導出、加載等功能。
- nn.Parameter- 張量的一種,當它作為一個屬性分配給一個Module時,它會被自動注冊為一個參數。
- autograd.Function - 實現了自動求導前向和反向傳播的定義,每個Tensor至少創建一個Function節點,該節點連接到創建Tensor的函數并對其歷史進行編碼。
-
AlexNet

5個卷積層和3個全連接層組成的,深度總共8層。
class AlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()self.conv = nn.Sequential(#convolution layersnn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, paddingnn.ReLU(),nn.MaxPool2d(3, 2), # kernel_size, stride# 減小卷積窗口,使用填充為2來使得輸入與輸出的高和寬一致,且增大輸出通道數nn.Conv2d(96, 256, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(3, 2),# 連續3個卷積層,且使用更小的卷積窗口。除了最后的卷積層外,進一步增大了輸出通道數。# 前兩個卷積層后不使用池化層來減小輸入的高和寬nn.Conv2d(256, 384, 3, 1, 1),nn.ReLU(),nn.Conv2d(384, 384, 3, 1, 1),nn.ReLU(),nn.Conv2d(384, 256, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(3, 2))# 這里全連接層的輸出個數比LeNet中的大數倍。使用丟棄層來緩解過擬合self.fc = nn.Sequential(#fully connected layersnn.Linear(256*5*5, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),# 輸出層。由于這里使用Fashion-MNIST,所以用類別數為10,而非論文中的1000nn.Linear(4096, 10),)def forward(self, img):feature = self.conv(img)output = self.fc(feature.view(img.shape[0], -1))return output

- 損失函數
#二分類交叉熵損失函數Cross Entropy
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
#在二分類中,label是{0,1}。對于進入交叉熵函數的input為概率分布的形式。一般來說,input為sigmoid激活層的輸出,或者softmax的輸出。
#size_average:數據為bool,為True時,返回的loss為平均值;為False時,返回的各樣本的loss之和。
#reduce:數據類型為bool,為True時,loss的返回是標量。
#(2) 默認情況下 nn.BCELoss(),reduce = True,size_average = True。
#(3) 如果reduce為False,size_average不起作用,返回向量形式的loss。
#(4) 如果reduce為True,size_average為True,返回loss的均值,即loss.mean()。
#(5) 如果reduce為True,size_average為False,返回loss的和,即loss.sum()。m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)
output.backward()#交叉熵損失函數
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
#ignore_index:忽略某個類的損失函數。
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()#L1損失函數:計算輸出y和真實標簽target之間的差值的絕對值。
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
#reduction參數決定了計算模式。有三種計算模式可選:none:逐個元素計算。 sum:所有元素求和,返回標量。 mean:加權平均,返回標量。 如果選擇none,那么返回的結果是和輸入元素相同尺寸的。默認計算方式是求平均。
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()#MSE損失函數:計算輸出y和真實標簽target之差的平方。
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()#平滑L1 (Smooth L1)損失函數:L1的平滑輸出,其功能是減輕離群點帶來的影響
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
#過程同理,略#可視化:平滑l1與l1對比
import matplotlib.pyplot as plt
inputs = torch.linspace(-10, 10, steps=5000)
target = torch.zeros_like(inputs)loss_f_smooth = nn.SmoothL1Loss(reduction='none')
loss_smooth = loss_f_smooth(inputs, target)
loss_f_l1 = nn.L1Loss(reduction='none')
loss_l1 = loss_f_l1(inputs,target)plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss')#畫圖
plt.plot(inputs.numpy(), loss_l1, label='L1 loss')
plt.xlabel('x_i - y_i')
plt.ylabel('loss value')
plt.legend()#圖例
plt.grid()#網格線
plt.show()#目標泊松分布的負對數似然損失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
#log_input:輸入是否為對數形式,決定計算公式。如果log_input=False:輸入數據還不是對數形式,計算中還需要對input取對數,取對數時有可能遇到input=0,這樣就無法正常進行取對數運算,因此在input后加入修正項eps。其中修正項很小,它的加入并不會影響到對input對數數值的,即便有影響也可忽略不計。
#full:計算所有 loss,默認為 False。
#eps:修正項,避免 input 為 0 時,log(input) 為 nan 的情況。
Smooth L1:
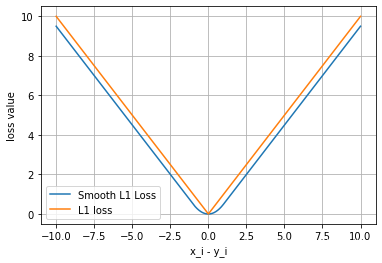
由圖可見,smoothL1處x=0尖端更平滑
PoissonNLLLoss:
當參數log_input=True: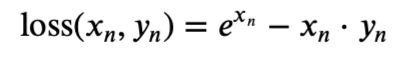
當參數log_input=False:
KLDivLoss

#kl散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
#功能:計算KL散度,也就是計算相對熵。用于連續分布的距離度量,并且對離散采用的連續輸出空間分布進行回歸通常很有用。
#reduction:計算模式,可為 none/sum/mean/batchmean。
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]])
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss = nn.KLDivLoss()
output = loss(inputs,target)#排序損失函數MarginRankingLoss
#計算兩個向量之間的相似度,用于排序任務。該方法用于計算兩組數據之間的差異。
torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
#margin:邊界值,x1 and x2之間的差異值
loss = nn.MarginRankingLoss()
input1 = torch.randn(3, requires_grad=True)
input2 = torch.randn(3, requires_grad=True)
target = torch.randn(3).sign()
output = loss(input1, input2, target)
output.backward()
MarginRankingLoss:

)







地鐵票價信息生成系統)










