UniV2X
- 一、文章基本信息
- 二、文章背景
- 三、UniV2X框架
- 1. 車路協同自動駕駛問題定義
- 2. 稀疏-密集混合形態數據
- 3. 交叉視圖數據融合(智能體融合)
- 4. 交叉視圖數據融合(車道融合)
- 5. 交叉視圖數據融合(占用融合)
- 6. 規劃輸出 Planning Output
- 四、實驗
- 1. 實驗設置
- 2. DAIR-V2X上的實驗結果
- 3. 關于可靠性的消融實驗
- 五、總結
一、文章基本信息
| 標題 | End-to-end autonomous driving through V2X cooperation |
|---|---|
| 會議 | AAAI(Association for the Advancement of Artificial Intelligence) |
| 作者 | Haibao Yu;Wenxian Yang;Jiaru Zhong;Zhenwei Yang;Siqi Fan;Ping Luo;Zaiqing Nie |
| 主要單位 | The University of Hong Kong;AI Industry research (AIR), Tsinghua University |
| 日期 | v1:2024年3月31日;v3:2024年12月24日 |
| 論文鏈接 | https://arxiv.org/abs/2404.00717 |
| 代碼鏈接 | https://github.com/AIR-THU/UniV2X |
摘要: 通過車聯網通信來利用自車和路側傳感器的數據已經成為高階自動駕駛的前景方法。然而,目前的研究主要聚焦于提高單一模塊,而不是采用端到端的學習來優化最終規劃性能,導致數據潛力未能充分利用。在這篇文章中,作者引入了一個UniV2X的先進協同自動駕駛框架,將不同視角下的所有關鍵的駕駛模塊無縫地融合到一個統一的框架下。作者提出了一個稀疏-密集混合的數據傳輸和融合機制來促進車輛和基礎設施的協同,主要有三個優點: |
文章框架:

二、文章背景
盡管自動駕駛通過深度學習的融合取得了巨大的發展,但由于感知距離受限、感知信息不充分,單車自動駕駛仍面臨著巨大的挑戰,尤其是對于依賴經濟的攝像頭作為傳感器的車輛。通過車聯網通信來利用具有更廣闊視野的路側傳感器,在提高高階自動駕駛方面展示了巨大的潛力。現有的利用額外感知數據來輔助提升感知精度的方法,在目標檢測、目標追蹤、語義分割、定位等單獨的任務上表現較好,但忽視了最終的規劃增強。最大的難點在于:單獨的任務目標與最終軌跡規劃的目標不一致。因此,利用車載和路側傳感器數據直接優化最終規劃輸出的方法變得必要。在本文中,作者聚焦于車輛基礎設施協同自動駕駛(vehicle-infrastructure cooperative autonomous driving, VICAD)。
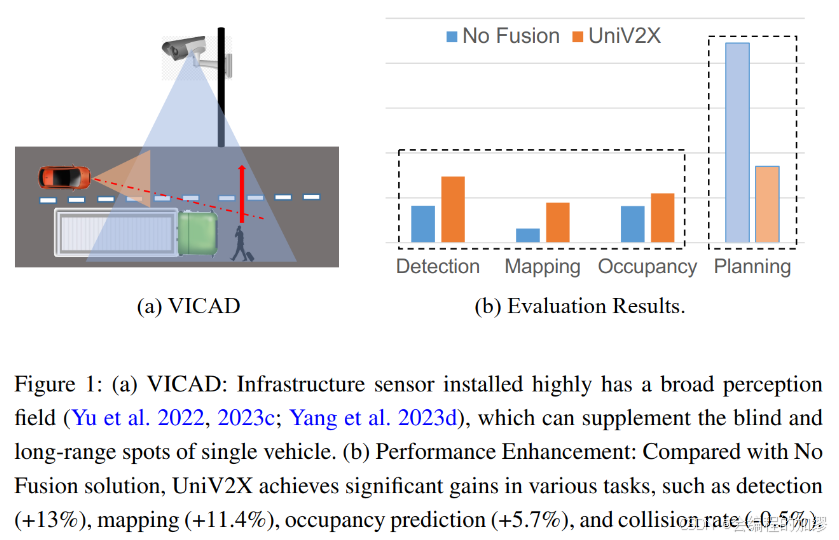
車輛基礎設施協同自動駕駛問題可以定義為:在帶寬限制條件下,采用多視圖傳感器輸入的以規劃為主的優化問題。與單車自動駕駛相比,車輛基礎設施協同自動駕駛在處理端到端學習時,面臨著額外的挑戰:
- 傳輸的基礎設施數據必須是有效的。它應既能增強關鍵模塊的性能,又能提升自動駕駛的最終規劃性能。
- 數據必須是傳輸友好型的。受實時性要求和有限通信條件的驅動,最小化傳輸成文對于降低通信帶寬消耗和減少延遲直觀重要。
- 傳輸數據必須是可靠的。車輛需要可解釋的信息來有效地避免通信攻擊和數據損壞帶來的安全問題。
作者對比了一些現有的協同感知方法,并得出了以下判斷:這些現有解決方案依賴于一種普通的方法,利用簡單的網絡來優化規劃和控制輸出。這種模式缺乏明確的模塊,損害了安全保障和可解釋性。尤其是在復雜的城市環境中,這種方法在確保駕駛系統的可靠性方面存在不足。
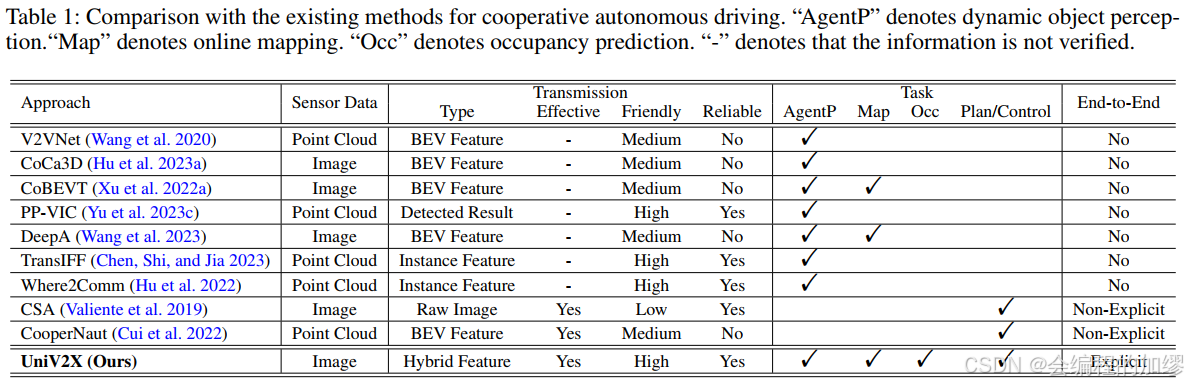
所以,作者受UniAD的設計理念啟發,采用一種模塊化的端端自動駕駛范式。除了最終的軌跡規劃結果,還能對比和處理以下三個常見的任務:
- 智能體感知(agent perception): 包括動態障礙物的3D目標檢測、追蹤及運動預測
- 語義地圖分割(online map):用于在線地圖繪制的道路元素檢測(尤其是車道)
- 網格占用預測(grid-occupancy prediction):用于通用障礙物感知的網格占用預測
在傳輸和跨視圖交互中,我們將智能體感知和道路元素檢測歸類為實例級表示,將占用預測歸類為場景級表示。本文傳輸智能體查詢和車道查詢,以進行跨視圖智能體感知交互和在線地圖繪制交互。本文傳輸占用概率圖,考慮到其在場景級占用中的密集特性,用于跨視圖占用交互。這種傳輸方式稱為稀疏 - 密集混合傳輸,分別在空間和特征維度上平衡了稀疏性和密集性。
本文的主要貢獻如下:
- 開發了首個用于車輛與基礎設施協同自動駕駛的模塊化端到端框架
- 設計了一種稀疏 - 密集混合傳輸和跨視圖數據交互方法
- 復現了多種協同方法作為baseline,并用DAIR-V2X呈現了UniV2X
三、UniV2X框架
本部分展示了UniV2X的整體框架:
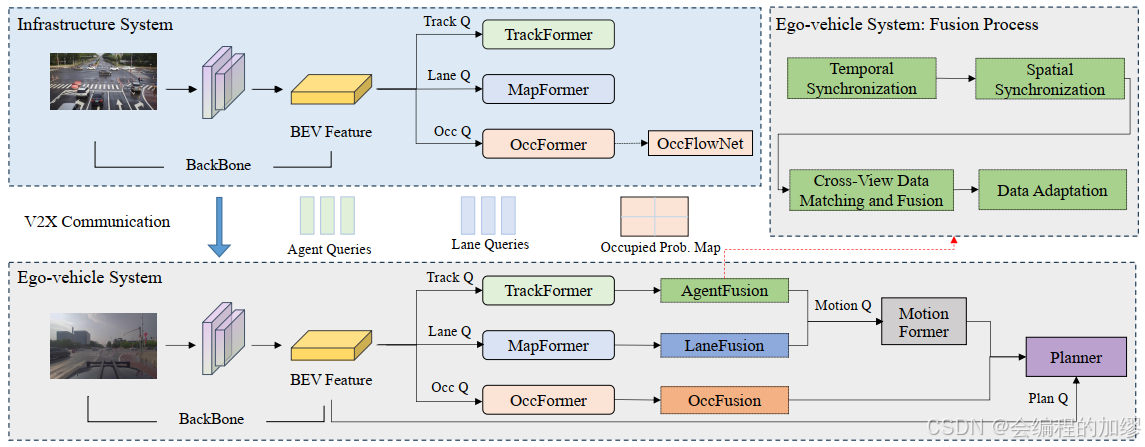
自車系統沿用了2023CVPR best paper: UniAD的架構1:包括TrackFormer, Mapformer和OccFormer幾個主要的模塊。
與UniAD最主要的區別應該是在于如何將路端和車端對齊,為此,作者提出了三個主要的東西分別是:
- 稀疏密集混合數據: 將agent queries和lane queries作為稀疏數據,將occupied probability map作為密集數據,來進行混合數據傳輸,降低通信成本
- 時間同步:采用特征流的概念
- 空間同步:時間同步采用BEV+坐標變換
- 自車消除:路側占用預測中消除自車模塊
1. 車路協同自動駕駛問題定義
1.1 系統輸入輸出
- 輸入:純視覺輸入,包括自車圖像 I v ( t ) ∣ t ≤ t v {I_{v}(t)|t\le t_{v}} Iv?(t)∣t≤tv?和車輛在 t v t_{v} tv?時刻的位姿 M v ( t v ) M_{v}(t_{v}) Mv?(tv?);路側基礎設施圖像 I i ( t ) ∣ t ≤ t i {I_{i}(t)|t\le t_{i}} Ii?(t)∣t≤ti?和基礎設施在 t i t_{i} ti?時刻的位姿 M i ( t i ) M_{i}(t_{i}) Mi?(ti?),實踐中,時間 t i t_i ti?應該比 t v t_v tv?更早。
- 輸出:預測自車在未來時間步 t = t v + 1 , … , t p r e d t=t_{v}+1,\dots,t_{pred} t=tv?+1,…,tpred?的坐標
1.2 評價指標
L2誤差 (L2 error):用于評估規劃的車輛未來軌跡與實際行駛軌跡之間的偏差程度。計算方法是對預測軌跡點和實際軌跡點對應坐標差值的平方和求平方根,其值越小,代表規劃軌跡越接近實際軌跡,規劃性能越好。
碰撞率 (collision rate):指在一定的測試或行駛場景下,車輛發生碰撞的次數與總行駛次數(或總行駛時間、總行駛里程等相關指標)的比例。該指標反映了車輛在行駛過程中發生碰撞的可能性,碰撞率越低,說明自動駕駛系統在避免碰撞方面的性能越出色.
道路偏離率(off-road rate):表示車輛偏離正常行駛道路區域的頻率或比例。通過統計車輛離開可行駛區域(如超出車道范圍、駛入禁止區域等)的次數,并與總行駛次數(或總行駛時間等)相除得到。道路偏離率低意味著車輛能較好地保持在規定的行駛區域內,規劃路徑能有效引導車輛遵守交通規則和維持在安全行駛區域。
每秒傳輸的比特數量(Bytes Per Second, BPS): 用于量化從基礎設施每秒傳輸到自動駕駛車輛的數據量,它考慮了傳輸頻率
1.3 面臨的挑戰
- 受實際通信條件的限制,應向車輛傳輸更少的基礎設施數據,以最小化帶寬使用并減少延遲。
- 無線通信會導致延遲,這可能會在數據融合時造成時間上的不一致。
- 在的通信攻擊和數據損壞可能會使傳輸的數據不可信。
2. 稀疏-密集混合形態數據
這部分說明了如何在基礎設施系統中生成用于傳輸的稀疏-密集混合數據。作者主要關注車道線和人行橫道元素。在傳輸過程中,我們使用分類解碼器生成的邊界框過濾掉得分較低的查詢,僅傳輸 N l i n f N_{l}^{inf} Nlinf??個有效的車道查詢 { Q L i n f } \{Q_{L}^{inf}\} {QLinf?},其特征維度為 256,以及它們相應的參考點。
UniAD中的原始 OccFormer 僅考慮與智能體查詢相關的實例級占用情況,并進行多步預測。然而,占用情況是一般障礙物檢測中目標感知的補充因素,傳輸多個概率圖會產生巨大的傳輸成本。為了解決這些挑戰,我們保留通過像素級注意力獲得的大小為 (200, 200, 256) 的密集特征。
首先,使用多層感知器(MLP)將密集特征轉換為大小為 (200, 200) 的 BEV 占用概率圖,記為 p i n f p^{inf} pinf。
隨后,采用特征流預測方法,利用一個額外的概率流模塊通過線性運算來表示 T 步的概率圖,公式為:
P f u t u r e ( t ) = P 0 + t ? P 1 P_{future}(t)=P_{0}+t*P_{1} Pfuture?(t)=P0?+t?P1?
其中, P 0 P_{0} P0?表示當前的 BEV 概率圖, P 1 P_{1} P1?表示相應的 BEV 概率流。傳輸 T 步的占用概率圖需要 T × 200 × 200 T×200×200 T×200×200個浮點數,而 UniV2X 僅需要 2 × 200 × 200 2×200×200 2×200×200個浮點數。
圖片來自于原文作者在深藍學院的課程:鏈接
3. 交叉視圖數據融合(智能體融合)
在車載系統中,首先從車載傳感器捕獲的圖像中提取鳥瞰圖(BEV)特征 B v e h B_{veh} Bveh?。我們還采用TrackFormer、MapFormer和OccFormer來生成相應的智能體查詢 Q A v e h {Q_{A}^{veh}} QAveh?、車道查詢 Q L v e h {Q_{L}^{veh}} QLveh?以及占用概率圖 P v e h P_{veh} Pveh?。這些模塊的網絡結構與基礎設施系統中的對應模塊一致。在本節中,我們將描述如何實現跨視圖智能體融合。跨視圖智能體融合主要包括
- 用于補償延遲的時間同步
- 統一跨視圖坐標的空間同步
- 數據匹配與融合
- 針對規劃和中間輸出的數據適配。
3.1 基于流預測的時間同步
基于流預測的時間同步在無線通信中,由于 t i t_{i} ti?早于 t v t_{v} tv?,傳輸延遲在復雜交通系統中十分顯著,在繁忙的十字路口場景中更是如此。由于動態物體的移動,在融合不同來源的數據時會出現時間上的不一致。為了解決這個問題,本文根據特征流預測方法,將特征預測融入到基礎設施智能體查詢中以減少延遲。具體來說,我們將智能體查詢 Q A i n f Q_{A}^{inf} QAinf?和前一幀相關的查詢輸入到QueryFlowNet(一個三層的多層感知器)中,生成智能體查詢流 Q A F l o w i n f Q_{AFlow}^{inf} QAFlowinf?。智能體查詢流的維度與智能體查詢的維度相匹配。隨后,通過線性運算預測未來特征,以此減少 t v ? t i t_{v}-t_{i} tv??ti?的延遲,公式表示為:
Q A i n f ( t v ) = Q A i n f ( t i ) + ( t v ? t i ) ? Q A F l o w i n f Q_{A}^{inf}(t_{v}) = Q_{A}^{inf}(t_{i}) + (t_{v}-t_{i}) * Q_{AFlow}^{inf} QAinf?(tv?)=QAinf?(ti?)+(tv??ti?)?QAFlowinf?
值得注意的是,在UniV2X中,流預測模塊的QueryFlowNet并非以端到端的方式進行訓練。我們采用了提出的自監督學習方法。
3.2 基于旋轉注意查詢轉換的空間同步(本質是坐標系的轉換)
文首先利用基礎設施系統和車載系統之間的相對位姿 [ R , T ] [R, T] [R,T],將基礎設施智能體查詢 Q A i n f Q_{A}^{inf} QAinf?的參考點從基礎設施坐標系轉換到車載坐標系。
這里的相對位姿是由兩個系統的全局相對位姿生成的,其中 R R R代表旋轉矩陣, T T T表示平移。然而,每個物體本身都具有關于其位置、大小和旋轉的三維信息。
在表示三維物體的查詢情境中,位置由參考點明確表示,而旋轉則隱含地編碼在查詢的特征中,如圖3所示。為了解決這個問題,我們提出了一種稱為旋轉感知查詢變換的解決方案來實現空間同步。這需要將基礎設施查詢及其相對位姿中的旋轉 R R R輸入到一個三層的多層感知器(MLP)中,以使特征具備旋轉感知能力,從而實現顯式的空間同步,公式如下: s p a t i a l _ u p d a t e ( Q A i n f ) = M L P ( [ Q A i n f , R ] ) spatial\_update \left(Q_{A}^{inf}\right)=MLP\left(\left[Q_{A}^{inf}, R\right]\right) spatial_update(QAinf?)=MLP([QAinf?,R]) 其中旋轉矩陣 R R R被重塑為9維。最后,我們將基礎設施智能體查詢數據轉換到車載坐標系中。

3.3 不同視圖查詢的匹配融合
跨視圖查詢匹配與融合。在這一階段,跨視圖的智能體查詢已在時間和空間上完成同步。為了匹配來自不同視角的對應查詢,我們計算它們參考點的歐氏距離,并采用匈牙利算法進行匹配:
-
對于匹配上的查詢對 Q A i n f Q_{A}^{inf} QAinf?和 Q A v e h Q_{A}^{veh} QAveh? ,將它們輸入到一個三層的多層感知器中,生成協作查詢 Q A Q_{A} QA?,用于更新車載智能體查詢 Q A v e h Q_{A}^{veh} QAveh?。
-
對于基礎設施中未匹配上的查詢,則將其添加到車載查詢中。
-
最后,我們分配跟蹤ID,并過濾掉檢測置信度較低的跨視圖融合查詢,從而得到最終的智能體查詢結果。
3.4 消除自車誤檢問題
該模塊用于消除自車區域的誤檢測問題。從基礎設施的視角來看,在智能體感知中,自車可能會被視作一個明顯的障礙物,在占用預測中則可能被視為占用區域的一部分。經過跨視圖數據融合后,有可能在自車所在區域生成障礙物查詢,從而將自車區域標記為被占用。這種情況會嚴重干擾決策過程,最終影響決策性能。為緩解這一問題,我們將自車區域定義為一個矩形,過濾該區域內的查詢,并將此區域指定為未被占用。然而,由于定位和校準不準確,導致基礎設施與自車之間存在相對位置誤差,這種簡單直接的解決方案可能無法始終達到最佳效果。為推動協同自動駕駛發展,進一步探索和優化至關重要。

圖片來自于原文作者在深藍學院的課程:鏈接
3.5 用于中間輸出的解碼器輸入增強
通過最終融合的智能體查詢與車載TrackFormer中編碼器的輸出之間的交叉注意力機制,我們可以獲得智能體的中間輸出,如3D檢測輸出,以增強UniV2X的可解釋性。然而,編碼器的輸出全部由車載傳感器數據信息生成,這使得來自基礎設施的查詢無法產生相應的智能體輸出。為了解決這個問題,我們使用同步的基礎設施查詢來增強編碼器的輸出,即車載BEV特征,公式如下:
u p d a t e ( B v e h ) = B v e h + M L P ( s y n c h r o n i z e d ( Q A i n f ) ) update (B^{veh})=B^{veh}+MLP(synchronized (Q_{A}^{inf})) update(Bveh)=Bveh+MLP(synchronized(QAinf?))
4. 交叉視圖數據融合(車道融合)
車道融合(LaneFusion)模塊用于融合來自不同視角的車道查詢信息。在此過程中,我們在車道融合時省略了時間同步,因為道路車道元素不受延遲影響,保持穩定。與智能體融合(AgentFusion)類似,車道融合通過旋轉感知查詢變換實現空間同步。這個過程將包含參考點和查詢特征的基礎設施車道查詢轉換到車載坐標系中。然后,我們像在智能體融合中那樣,對同步后的基礎設施車道查詢和車載車道查詢進行匹配與融合。為加快訓練速度,我們還選擇直接將同步后的查詢與車載車道查詢連接起來。同步后的查詢也用于解碼器輸入增強。
5. 交叉視圖數據融合(占用融合)
我們首先通過線性運算生成多步的基礎設施占用概率圖,并將其與車載多步占用預測進行對齊。利用密集概率圖中明確表示的旋轉信息,我們使用相對位姿將基礎設施占用概率圖直接轉換到車載系統。
隨后,我們使用簡單的取最大值運算,將同步后的占用概率圖與車載占用概率圖進行融合,生成融合概率圖 P ^ \hat{P} P^。概率超過特定閾值的網格會被標記為已占用。
6. 規劃輸出 Planning Output
利用融合后的智能體查詢、車道查詢和占用特征,我們首先復用UniAD中的方法生成粗略的未來路徑點。MotionFormer用于生成一組預測時長為 t p r e d t_{pred} tpred?的 N a N_{a} Na?個運動查詢。這些查詢通過捕捉智能體、車道和目標之間的交互生成。值得注意的是,這些智能體查詢包含了自車查詢,這使得MotionFormer能夠生成具有多模態意圖的自車查詢。
鳥瞰圖(BEV)占用概率圖 P ^ \hat{P} P^用于創建二進制占用圖 o ^ \hat{o} o^。在規劃階段,從MotionFormer獲得的自車查詢與指令嵌入相結合,形成一個 “規劃查詢”。這些指令包括左轉、右轉和前進。
這個規劃查詢與BEV特征一起輸入到解碼器中,以生成未來的路徑點。
最終的規劃軌跡由以下方式確定:
1)調整道路上的未來路徑點,確保遵守交通規則,并利用生成的車道和其他道路元素使車輛保持在駕駛區域內;
2)最小化成本函數,以避免與被占用的網格 o ^ \hat{o} o^發生碰撞。
四、實驗
1. 實驗設置
實驗數據集—DAIR-V2X
DAIR-V2X2數據集包含約100個場景,這些場景拍攝于28個復雜的交通路口,由基礎設施傳感器和車輛傳感器共同記錄。每個場景時長在10到25秒之間,以10Hz的頻率采集數據,并配備了高清地圖。該數據集涵蓋了多種駕駛行為,包括前進、左轉和右轉等動作。為了與nuScenes數據集保持一致,我們將目標類別分為四類:汽車、自行車、行人和交通錐。
實施細節
實施過程。我們將自車的關注范圍設定為[-50, 50, -50, 50]米。自車的鳥瞰圖(BEV)范圍與之相同,也是[-50, 50, -50, 50]米,每個網格大小為0.25米×0.25米。基礎設施的BEV范圍設置為[0, 100, -50, 50]米,這考慮到了攝像頭的前向感知范圍,有助于更有效地利用基礎設施數據。實驗使用8塊NVIDIA A100 GPU進行。附錄中提供了更多實施細節。
基準算法設置
- 無融合(No Fusion):方案僅使用自車圖像作為傳感器數據輸入,不輸入任何基礎設施數據。
- 普通方法(Vanilla approach):我們使用簡單的卷積神經網絡(CNN)融合基礎設施和自車的鳥瞰圖(BEV)特征。融合后的BEV特征被重塑為一維,隨后輸入到多層感知器(MLP)中以生成規劃路徑。
- 在BEV特征融合BEV Feature Fusion)方法:我們使用CNN將兩側的BEV特征融合為新的自車BEV特征,并將這個新特征輸入到UniAD中。
- CooperNaut:最初利用點云的稀疏特性,采用點變換器(Point Transformer)來聚合跨視圖特征。
鑒于自車狀態(如自車速度)在開環端到端自動駕駛中起著重要作用(Li等人,2024),為了進行公平比較,我們在所有基線設置中都去除了自車速度嵌入。此外,我們在附錄中探究了自車速度對UniV2X的作用。
2. DAIR-V2X上的實驗結果
端到端自動駕駛最終規劃結果,作者認為L2 Error指標似乎不太合理,因此一直討論的是碰撞率,車道偏離率與傳輸成本。但我感覺這里的BPS對比好像設置的不是很合理,因為沒有和一些專注于提升通信效率的算法相比,而只是證明了通過稀疏-密集混合傳輸使得傳輸的數據量減少了。
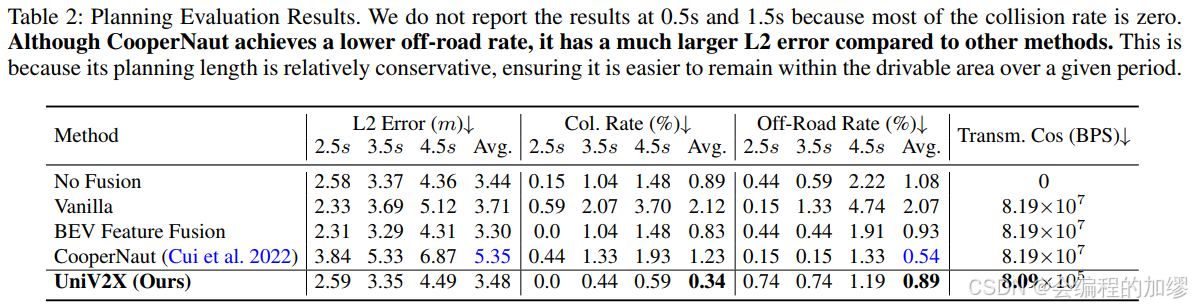
感知結果:
主要對比了mAP和AMOTA兩個指標。
- mAP: 平均精度是對目標檢測模型在不同類別上的精度進行平均得到的指標,它綜合考慮了模型檢測出的目標的準確率和召回率。
- AMOTA:AMOTA 是多目標追蹤領域中用于評估模型性能的指標,它綜合考慮了目標的檢測準確性和軌跡的匹配準確性。
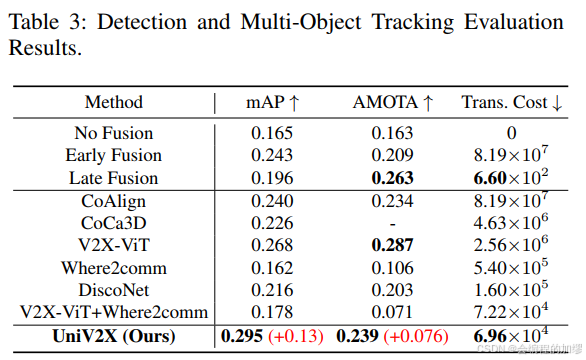
在線地圖結果:
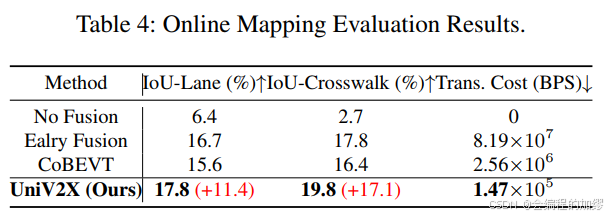
占用預測結果:

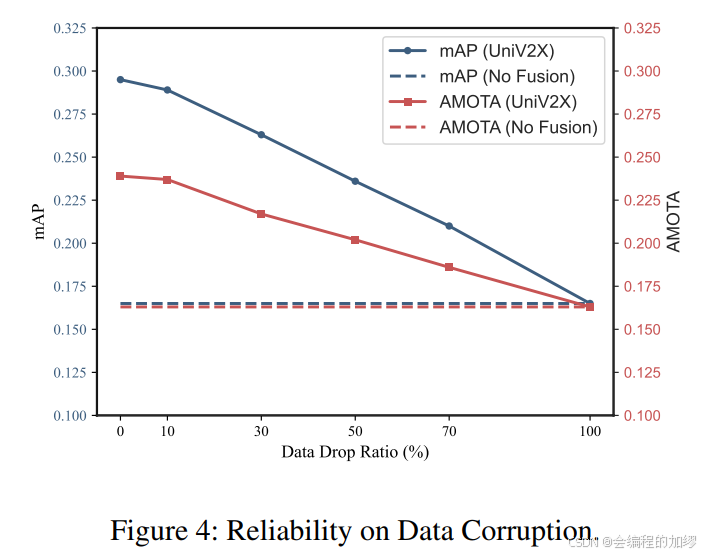
3. 關于可靠性的消融實驗
在評估 UniV2X 時,我們的第一步是在傳輸過程中隨機丟棄 10%、30%、50%、70% 和 100% 的基礎設施智能體查詢,以此來模擬數據損壞的情況。(這一塊感覺論文中也沒有詳細說明,UniAD中說的是模塊化的端到端讓該模型變得更加可解釋…可能是基于此)
五、總結
文章總結: 本文提出了UniV2X,這是一種新穎的端到端框架,它將來自不同視角的關鍵任務集成到單個網絡中。該框架采用以規劃為導向的方法,在利用原始傳感器數據的同時,確保網絡在協同自動駕駛中的可解釋性。此外,還設計了一種稀疏 - 密集混合數據傳輸策略,以利用跨視圖數據并提高整體規劃性能。這種傳輸方法既便于通信又可靠,符合車聯網(V2X)通信的要求。在DAIR-V2X數據集上的實證結果驗證了我們所提方法的有效性。 |
補充:
開環評估和閉環實驗是自動駕駛研究中評估系統性能的兩種不同方式。
-
開環評估:在自動駕駛中,開環評估指系統依據輸入數據(像傳感器數據和地圖信息)生成決策或規劃,但不考慮這些決策實際執行后的反饋。比如在模擬場景里,系統根據當前感知信息規劃行駛路徑,卻不依據車輛實際行駛軌跡來調整后續規劃,類似單向操作,不形成回路,能簡單快速地評估系統在特定輸入下的規劃能力。
-
閉環實驗:閉環實驗則不同,系統會把決策執行后的反饋納入考量。車輛實際行駛過程中,系統持續接收傳感器數據,判斷規劃路徑是否合適。若出現偏差,如與預期軌跡不符,就會據此調整后續決策。這就像人開車,時刻根據實際路況調整駕駛行為,形成了感知 - 決策 - 執行 - 反饋的循環。
CVPR2023-best paper-UniAD-Planning-oriented Autonomous Driving ??
CVPR2022-DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection ??



















