對話整數智能聯創和前IDEA研究員:構建高質量數據集與智能數據工程平臺 - AI Odyssey | 小宇宙 - 聽播客,上小宇宙
人工智能技術的日益深遠發展,對人工智能的性能提升與技術迭代提出了新的要求。在大模型訓練中,已有的研究和實踐表明,增大數據量或者增大模型都能帶來性能上的提升,但是單一地擴大數據規模或增加大模型規模,都不免面臨性能提升的瓶頸。在實踐領域,在經過模型迭代的發展階段后,數據的提升成為了推動人工智能領域發展的重要引擎和增長點,在這個過程中,數據質量的提升尤為重要。本期播客中,來自整數智能的算法工程師劉明皓和來自 Brandeis 計算機科學的博士研究生楊子敖與主持人深入探討了如何為大模型訓練和推理構建高質量的數據集,以及如何搭建智能數據工程平臺。
大模型訓練的Scaling Laws
關于大模型訓練的Scaling Laws,各個研究團隊都在基于自己的實驗慢慢完善這個領域的研究,同時數據混合、去重策略和不同的訓練場景(如Continual Pre-Training)等差異對Loss的影響也比較大,現在希望利用scaling law從而很準確的預測training performance仍然是有挑戰且耗時的。整數智能參與搭建的開源大模型 MAP-Neo,在測試中體現出了優秀的性能表現,高質量的數據使得大模型在一些場景中的表現甚至超越目前市面上流通的先進的商用閉源模型,我們也提出了自己的NEO Scaling Law,在我們的實驗中Loss下降的要比Chinchilla Law更快,這說明我們的語料更豐富且更高質量,所以額外添加了正則化項log(D),雖然在D極大時會有影響,但是對于我們的場景來說NEO Scaling Law擬合得更好。
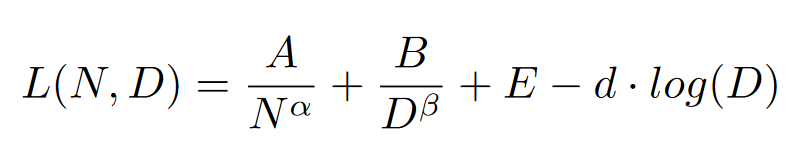
NEO Scaling Law
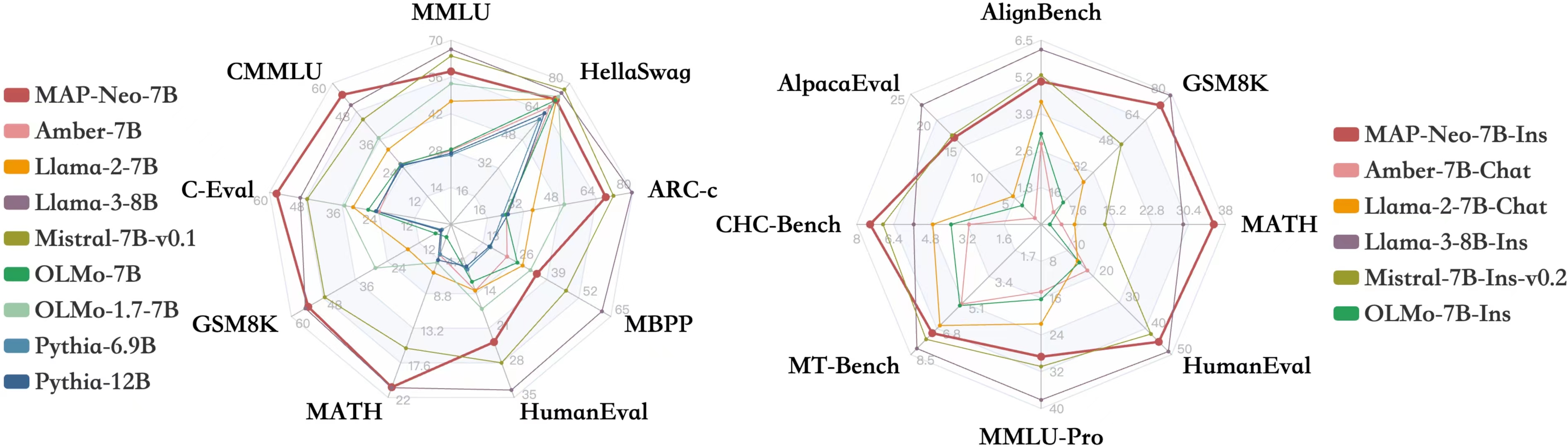
MAP-Neo-7B在不同測試中的表現
整數智能作為專業的數據標注與管理企業,面對不同的用戶,會根據不同用戶所提供的不同業務場景需求,提出數據配比的建議,平衡productivity與entertainment。作為人工智能大模型產業鏈中的一環,整數智能Release了Matrix與PIN等等Datasets,也會依據客戶具體的需求,充分調動既往經驗和專業素養,站在用戶需求這一主觀視角,結合客觀事實依據,為用戶提供大模型建構的有效建議。
高質量的大模型訓練數據
就什么是高質量數據,高質量的訓練數據是如何在具體應用中影響大模型表現,整數智能通過近期發布的開源大模型MAP-Neo給出了現階段的見解與看法。MAP-Neo是基于4.7T的中英文代碼數據集訓練而成,這一數據集是基于近PB的龐大原始數據規模清洗而成。對于MAP-Neo訓練數據集的清洗,MAP團隊采用了最經典的啟發性過濾、內容抽取和低質量數據過濾,而就低質量數據過濾,團隊綜合應用了多種范式,從啟發式的規則、數據去重,再到對數據進行規范性的要求,以及基于黑名單對于數據中可能具有敏感信息的部分進行敏感性的評價。在這一機制下,數據的淘汰率非常高,基于高質量數據的嚴格清洗和篩選流程,使得MAP-Neo大模型能夠有一個超高質量的訓練數據集。而模型的性能的顯著提升在已有的測試中已經得到了多方驗證。

MAP-Neo模型簡介
安全和有用在一些情況下是互斥的,會產生“HARMFUL”和“HELPFUL”之間的矛盾,相似的,高維度的數據清洗同樣會帶來數據質量與之間是具有矛盾的,這就要求開發者在二者之間進行平衡與取舍。而針對不同來源的數據和文本語料的質量評判,不同的模型和場景也有不同的判斷標準,例如來自WIKI的數據篩選流程可能并適用于論壇。針對不同數據來源逐一定制相關模型和規則進行相應的微調訓練,也是當下耗費成本較高的挑戰。
數據質量具體怎么影響模型的訓練效果,學術界和工業界有著不盡相同的判斷標準。楊子敖在播客中提到,學術界對于模型評判有一個明確的指標,依據特定的Valid Dataset為訓練數據時的標準,新的訓練數據訓練出的模型性能是有所提高還是有所損傷,來判斷數據質量對模型訓練效果的影響。在這里,學術研究中提出了一種把數據集中的每一個點移除后重新評估模型表現,觀察模型表現會有什么變化,進而評估該數據集對于這一模型的訓練效果的方法,同時子敖組的最新工作《On the Inflation of KNN-Shapley Value》與《Revisit, Extend, and Enhance Hessian-Free Influence Functions》分別從Shapley Value和Influence Function兩個不同的角度來進行數據估值和篩選。
在工業界,模型性能的評判會隨著具體應用場景的切換而相應地發生變化。當現有研究和技術足以支撐優質的基礎模型,在此基礎上進行相應的調整,就可以使模型在不同的垂類中具備行業的相關知識。大多數時候,用戶端眼中模型的好壞,是非常具有主觀性質的,對模型的調整需要從用戶推理和思考的維度出發,充分理解用戶的需求,甚至在用戶需求尚未明確的時候能夠精準提煉出用戶的需求。在具體應用場景中,我們希望訓練出的大模型能夠幫助甚至代替該行業中業務最好的專業人員思考。因此在實際商業應用中,依據行業場景進行數據集建構并非一個短期工作,數據集建構團隊需要充分了解用戶的需求,并調研該行業最佳業務人員的相關使用方法和思考習慣,磨合的時間越長,收集的數據越貼近現實場景,訓練出來的大模型越能更好地理解指令并執行,從而成為該特定業務場景下的優質模型。
但在醫療、法律等涉及到數據隱私的行業,數據標注的過程會更加困難,無論是數據的采集、還是SFT數據的構造,都會面臨數據安全帶來的挑戰,需要有一個足夠可信的第三方來對整個數據處理流程做相應的監管。
在實際應用中,跨行業的數據集構建很難抽象為一個產品,整數智能基于不同用于的對樣需求,提供一對一的對接和服務,將不同用戶的需求整理成專屬的標注文檔,并在核驗指標上進行量化,將數據標注質量轉化為可以量化的數據標準,將復雜的人與人之間的溝通理解對齊為可以量化的數據標準,從而高效觸達用戶理想的數據集構想。
在當前的商用領域,數據壁壘在每一個垂類領域都是存在并將長期存在的現象。在這一環境中,用戶數據和不斷實時更新的數據都是非常寶貴的財富。即便如此,業界也在不斷探索人工智能領域的民主化進程。整數智能參與開發的開源大語言模型MAP-NEO就是推動高質量大語言模型開源、促進大模型與人工智能技術民主化、助力科研領域發展的重要探索與成功實踐。
智駕探索
在數據采集的過程中,最為復雜的環節是資質和標定,這關系到各個傳感器的布局、互聯,以及標定精度上的取舍。對采集數據的標定也有不同的策略選擇,需要標注方通過方案對數據標定策略進行約束和統一,判斷哪些數據在當前應用場景下具有最高的標注價值。在下半年即將發布的開源大模型的訓練數據集的選擇和建構過程中,整數智能將會提取采集數據的主干特征,這些特征在采集數據中會表現為一些向量。在對數據的采集和分析過程中,整數智能的處理方式是先對這些向量進行聚類,并以簇的方式對數據進行大規模的采樣。以這樣的方式采集到的數據,一簇中的大部分數據只需要標注3-5幀,模型就會有很好地表現。通過對具有代表性的幀進行預標注的方式進行數據生產,在智駕模型的訓練過程中,只需要對已經審核過的數據進行調整,即可適用于大部分的智駕場景。在數據集構建的過程中,整數智能團隊也注意到了上述流程可能帶來的場景局限,如果有現有數據無法很好應對的案例,則需要在剩下尚未被標注的采集數據中進行Data Mining,或者進一步判斷是否要對特定場景下的數據進行采集,這時候就可以為數據采集設計一個trigger, 只有達到滿足這一特殊場景需求的閾值,才對該場景下的數據進行采集。如此,數據集既能涵蓋高效低成本地進行絕大部分常見自駕場景,又能囊括駕駛過程中可能出現的特殊情況。
整數智能在基于主觀性的、多元化的多種行業垂類中致力于更加專業的定制化服務,同時不斷將生產和服務經驗復用到人工智能技術探索的過程中,不斷加深、拓寬高質量數據集,并用創新性、綜合性的思路進行多方嘗試,不斷為業界發展提供更具實用性的高效產品與專業服務。
整數智能信息技術(杭州)有限責任公司,起源自浙江大學計算機創新技術研究院,致力于成為AI行業的數據領航員。整數智能也是中國人工智能產業發展聯盟、ASAM協會、浙江省人工智能產業技術聯盟成員,其提供的智能數據工程平臺(MooreData Platform)與數據集構建服務(ACE Service),滿足了智能駕駛、AIGC等數十個人工智能應用場景對于先進的智能標注工具以及高質量數據的需求。

目前公司已合作海內外頂級科技公司與科研機構客戶1000余家,擁有知識產權數十項,通過ISO 9001、ISO 27001等國際認證,也多次參與人工智能領域的標準與白皮書撰寫,也受到《CCTV財經頻道》《新銳杭商》《浙江衛視》《蘇州衛視》等多家新聞媒體報道。
)








)









