doi: 10.3778/j.issn.1002-8331.2210-0153
深度強化學習求解車輛路徑問題的研究綜述 (ceaj.org)
組合最優化問題( combinatorial optimization problem, COP )
日常生活中常見的 COP 問題有旅行商問題(traveling salesman problem , TSP )、車輛路徑問題
( vehicle routing problem , VRP )、車間作業調度問題 (job shop scheduling , JSP )、最小頂點覆蓋問題( minimum vertex cover, MVC )、施泰納樹問題( Steiner tree problem,STP 施泰納最小樹問題_百度百科 (baidu.com) )以及裝箱問題(bin packing , BP) 裝箱問題_百度百科 (baidu.com) 等。
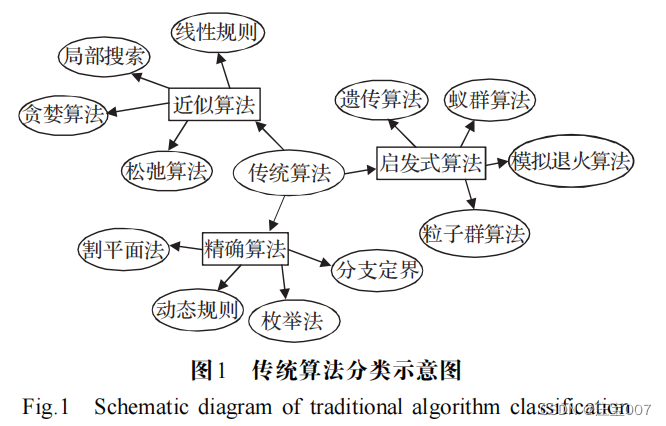
? ? ? VRP 在離散決策空間進行決策變量的最優選擇與RL 序貫決策的功能具有天然的相似性,且 DRL “離線訓練”“在線決策”的特征使VRP在線實時求解成為了可能。
? ? ? NN 解決 VRP 問題是 Vinyals 等人 將問題類比為機器翻譯過程,提出了指針網絡(pointer network , PN )模型,使用長短期記憶網絡(long-short term memory , LSTM)作為編碼器,注意力機制( attention mechanism , AM)作為解碼器,從城市坐標中提取特征。但是 PN采用監督學習(supervise learning , SL )方式訓練網絡,需要構造大量高質量的標簽,因此大多數研究利用DRL 求解 VRP 問題。除 PN 模型外,隨著圖神經網絡(graph?neural network,GNN)技術的興起,Scarselli等人利用GNN對每個節點特征進行學習,從而進行節點預測,主要求解思路是利用 GNN 對節點特征進行學習,由編碼器對問題的輸入序列進行編碼,再利用解碼器結合注意力計算方法,以自回歸的方式逐步構造解,根據學習到的特征進行后續的節點預測。
進一步地,Ma 等人把PN 與 GNN 相結合提出圖指針網絡(graph pointer network,GPN),利用 GNN 提取計算節點特征,再用 PN 進行解的構造,提升了大規模TSP問題的泛化能力。與大多數經典啟發式算法相比,基于 RL 訓練的模型對問題變化具有魯棒性,當問題輸入發生變化時,RL可以自動適應問題變化輸出較優的解。
受Transformer架構的啟發,Kool 等人借用Transformer提出新框架,其主要求解思路是利用AM 對模型進行改進,提出將輸入元素分為靜動態兩種表示, 利用嵌入的方式替代循環神經網絡(recurrent neural network,RNN)的編碼過程對靜動態元素進行向量表示,解碼階段將靜態向量表示輸入到解碼 RNN 中獲得隱含層向量與動態向量結合,通過AM獲得下一個決策點的概率分布,超越了先前解決路徑問題的優化性能。 后續的研究工作大部分是基于 Kool 等人的AM模型開展的,經過不斷調整編碼器、解碼器的結構以及RL訓練方法,進一步提升VRP的優化性能。
下面介紹 RL 相關原理和將 VRP 轉化為序列決策問題的馬爾可夫決策過程(Markov decision process , MDP ),以及經典的RL算法。
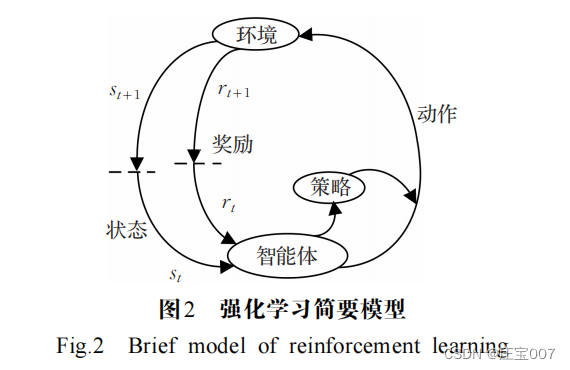
RL 是智能體在與環境的交互過程中,通過學習策 略以最大化提高獎勵或實現特定目標的模型。RL 可以建模為 MDP , MDP 實際就是一個多元組 [ S,A, P ,R,γ ] 。其中,初始狀態空間 S ( s t ∈ S ) 是起點城市或是部分解; A 為動作空間 ( a t ∈ A ) ,動作是對部分解的添加或者對完整解進行改變; P 為狀態轉移概率矩陣; R 是獎勵函數,表明在特定狀態下選擇的動作對解決方案造成的影響。 γ ∈ ( 0 , 1 ) 是折扣因子,調控智能體考慮短期回報。
以 TSP 問題為例,初始環境 s t 為已訪問的城市或起始城市節點,新狀態 s t + 1 是實時更新的解決
方案,動作 a t 是下一個將要訪問的城市,獎勵信號 r t 在訪問完節點時(以負的路徑長度)激勵智能體做出下一步決策。
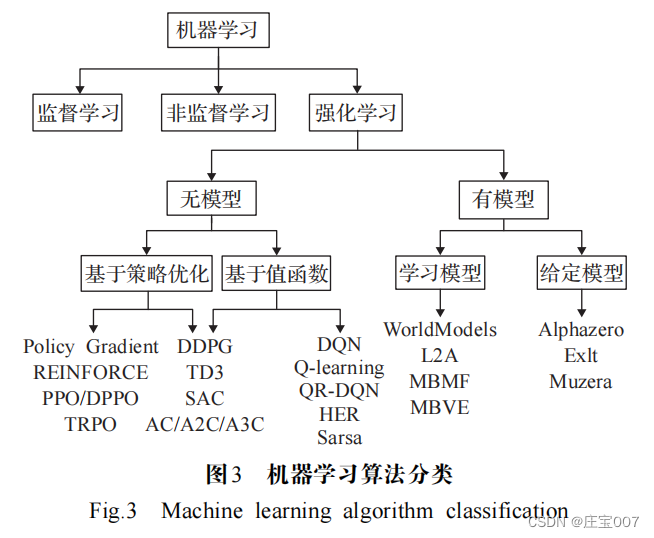
? ? ? ?有模型學習對環境有提前的認知,可以提前感知優化;無模型學習在訓練速度上遜于前者,但更易實現,在真實場景下可以快速調整到較優的狀態。利用RL 解決 VRP 的方法主要分為:基于值函數的方法和基于策略優化的方法。
1.DRL求解車輛路徑問題的思路
1.1車輛路徑問題的簡單概述
? ? ? ?如何提高解的精度,加快搜索速度,減少時間復雜度、 增強模型泛化能力 等是求解VRP 最關注的問題。在實際場景中, VRP 會超出普通路徑問題的限制,例如,帶有時間窗口的 旅行商問題(traveling salesman problem with time windowsz,TSPTW) 將時間窗口約束添加到 TSP 中的節點,即節點只能在固定的時間間隔內訪問;帶容量的車輛路徑問題(capacity vehicle routing problem,CVRP),旨在為訪問一組客戶(即城市)的車隊(即多個銷售人員)找到最佳路線,每輛車都具有最大承載容量的限制。VRP根據不同的應用場景和現實條件需要考慮更多的約束(車
載容量、配送中心數量、車輛行駛里程、時間限制等),因此衍生出許多變體,例如: 帶時間窗的車輛路徑問題 (vehicle routing problem with time windows,VRPTW) ?、 無人機和卡車協同配送的無人機車輛路徑問題(vehicle routing problem with drones, VRPD )、多車型車輛路徑問題(heterogeneous fleet vehicle routing problem , HFVRP)等。
1.2 基于深度強化學習求解路徑問題的步驟
? ? ? ?利用 DRL 求解 VRP 的思路是將城市的原始坐標作為輸入,利用 PN , GNN 或 Transformer 結合經典圖搜索算法建設性地構建近似解 。
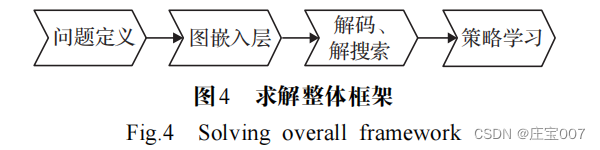
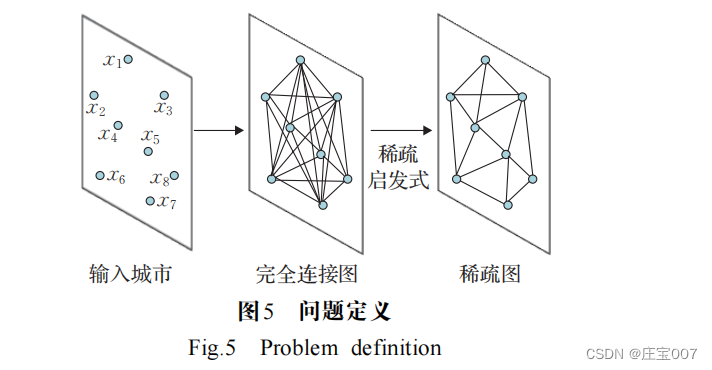
步驟 1 將問題轉化為圖結構信息, VRP 問題是一 個全連接圖,圖的節點對應于城市節點,邊對應兩城市 之間的道路,如圖5 所示。圖通過啟發式算法進行稀疏化,使模型能夠擴展到所有節點的成對計算來解決難以處理的大型實例,或者通過減少搜索空間來更快地學習策略。
步驟 2 獲取圖中節點和邊的初始嵌入,如圖 6 所示。嵌入是GNN 或 Transformer 編碼器將 TSP圖中的每個節點或邊作為輸入,來計算高維空間表示或嵌入特征。在編碼的每一層,節點從其鄰居節點收集特征,通過遞歸傳遞表示局部圖結構。堆疊 L 層后,網絡能夠從每個節點的 L 層鄰域中構建節點的特征。Transformer中基于 AM 的 GNN 已成為編碼路徑問題的默認選擇,AM 作用在于根據對現在節點的相對重要性來權衡鄰居節點。
步驟 3 圖的節點或邊被編碼為高維空間表示,解碼為離散的TSP ,如圖 7 所示。首先,將概率分配給每個節點或每條邊,通過分配的概率將節點或邊添加到解集中;然后通過經典圖搜索技術(例如由概率預測引導的 貪心搜索或波束搜索 )將預測概率轉換為離散決策。

步驟 4 模型訓練。整個編碼器 -解碼器模型以端到端的方式進行訓練,一般情況下,通過模仿最優求解器來訓練模型以產生接近最優的解。由于 TSP 問題通常需要順序決策以最小化特定于問題的成本函數,可以天然地利用 RL 框架訓練智能體最大化獎勵函數。對于未充分研究的問題以及缺乏標準解決方案的情況下,RL是一種最優的替代方案。
2.基于DRL求解VRP的方法
? ? ? ?近年來出現的大量研究,旨在使用 DRL 方法開發新的學習算法來自動解決路徑問題,以實現動態高效的求解。 DRL求解VRP的方法主要分為PN、GNN、Transformer 以及混合模型四類模型。 以上通用的路徑問題求解框架,可以適用于求解 VRP 的變體問題,運行速度和精度相比傳統算法有較大優勢。表1 和表 2 對近幾年求解 TSP 及其變體問題和 VRP 及其變體問題的模型進行分析與總結。下面對以上四類模型方法進行介紹,對各類方法的代表性模型、優化性能進行對比和分析。
2.1 基于PN求解VRP
2.1.1 求解模型
2015 年 Vinyals 等人 首次提出將 PN 與 VRP 結合, 使得模型架構不受輸入輸出維度的限制,采用 SL 方式進行離線訓練,以預測訪問城市的序列,解決了小規模的TSP問題,為PN求解VRP開辟了新的道路。PN模型原理是將 VRP問題編碼成向量,使其在隱層輸出、解碼時通過激活函數對向量進行處理,輸出問題實例中較大的概率向量。例如 PN 求解 TSP 的步驟為:首先將每個城市的坐標轉化為高維節點特征向量,由編碼器讀入城市坐標,編碼為對應的存儲輸入序列信息的向量,然后
解碼器對向量進行解碼,在解碼過程中,利用 AM 和隱層狀態計算選擇各個城市的概率 


在解碼時使用  作為指向向量選擇輸入序列中的元素。
作為指向向量選擇輸入序列中的元素。
? ? ? ? Vinyals 等人 以 SL 方式訓練模型,需要大量 TSP 示例及其最優解作為訓練集,標簽不易獲得。為了擺脫對高質量標簽的依賴,Bello 等人 [25] 采用了 RL 中的行動者- 評論家( actor-critic , AC )算法訓練網絡參數,提出神經組合優化(neural combinatorial optimization , NCO ) 模型,以PN 為基礎構建策略網絡,訓練過程中模型輸出的序列值可以通過深度神經網絡(deep neural network, DNN)訓練估值網絡參數,再通過獎勵機制微調,不斷改進策略網絡,擴大了 TSP 的求解規模,但該框架不適用于隨時間變化的更復雜的 VRP 問題。在此基礎上,Nazari等人 [40] 提出了一種可以系統處理靜態和動態元素的訓練方法,模型對輸入序列保持不變,因此改變任何兩個輸入的順序不會影響模型狀態。在 VRP 問題中輸入是無序的客戶位置及客戶需求,輸入順序對問題求解影響較小,因此模型未采用RNN 編碼器,而通過簡單的節點嵌入替換了 PN 的 LSTM 編碼器,進而縮短了訓練時間,且不會降低模型的訓練效率。
? ? ? ? 面對多目標優化問題( multi-objective optimization problems, MOPs )時, Li 等人 [26] 提出了一種使用 DRL 解決 MOP 的端到端框架,模型將多目標問題分解為一系列子問題,再通過 PN 來解決多目標旅行商問題( multi-objective traveling salesman problem, MOTSP )。該模型探索了使用 DRL 以端到端的方式求解 MOTSP 的可能性,即給定 n 個城市作為輸入,可以通過訓練網絡的前向傳播直接獲得最優解。
2.1.2 模型總結
以上模型依賴梯度信息指導搜索,基于搜索的求解VRP方法通常由啟發式方法指導,在各種條件和情況下調整啟發式方法通常非常耗時。為此 Chen 等人 [41] 使用雙向 LSTM 嵌入路徑,提出 NeuRewriter 模型,模型學習一種策略來選擇啟發式方法并重寫當前解決方案的局部組件,以迭代方式改進直到收斂。實驗果表明模型可求出CVRP20 的最優解, CVRP100 的優化性能優于求解
器 OR-Tools 。
2.2 基于Transformer求解VRP
2.2.1 求解模型
? ? ? ?RNN 參數在序列的所有元素之間共享,當模型獲取最后一個時間步的輸出時,它可能會“忘記”序列中先前元素的信息。而 AM 通過保留編碼器對輸入序列的隱層向量序列,在解碼階段對獲得的向量序列加權求和得到上下文向量 c t ,由于在輸出過程中注意力的權重不同,因此權重參數 α i t 越大,在 t 時刻輸出第 i 個向量的概率越大。進一步,Google 團隊 [16] 提出了由 AM 和多層感知機組成的網絡結構“Transformer ”, Transformer 的MHA可以注意到子空間的信息,從不同角度、不同維度提取到問題的深層特征,允許節點通過不同的通道傳遞相關信息,實現并行計算。因此來自編碼的節點嵌入可以學習圖的上下文中關于節點的信息。Kool等人 提出了一種有效的模型和訓練方法,以改進上述基于學習的啟發式求解路徑問題。通過用AM層代替遞歸網絡來減少節點輸入順序的影響,應用RL算法訓練模型。與 Bello 等人 不同,此模型引入貪婪策略得到的解作為基線,提高了模型的收斂速度。 Joshi等人 基于 Kool 等人 的實驗設置,結合 SL 和 RL訓練100 個節點的 TSP ,提升了模型的準確率。
? ? ? ?在 Kool 等模型中,節點特征通過嵌入方式進行編碼,該嵌入隨時間推移而固定。而問題實例的狀態應根據模型在不同的構造步驟所做的決定而改變,節點特征應該相應地更新。因此,Peng等人提出了一種具有動態編碼器-解碼器結構的動態注意力模型,該模型能夠動態地探索節點特征,并在不同的構造步驟中有效利用隱藏的結構信息。與Kool等人相比,該模型在圖的上下文中動態地刻畫每個節點,這可以在不同的構造步驟中有效地探索和利用隱藏的結構信息。
? ? ? ? 受 Transformer 在 NLP 中的啟發, Bresson 等人 將 Transformer 用 于 求 解 TSP ,編 碼 器 與 Kool 等 人 [17] 和 Deudon 等人 [28] 相同,通過 RL 訓練模型,使用帶有 MHA 模塊的部分解來構建查詢,添加一個不存在的城市,該城市通過自注意力模塊查詢所有城市,并在最佳位置使
用波束搜索解碼。結果表明, TSP50 的最優間隙為0.004%, TSP100 的最優間隙為 0.39% 。
雖然 DRL 方法可以直接輸出問題的解,但是其優化效果與專業求解器相比仍有一定差距。由于局部搜索是求解組合優化問題的經典方法,學者們開始研究利用 DRL 方法來自動學習局部搜索算法的啟發式規則,從而比人工設計的搜索規則具有更好的搜索能力。相比之下,Wu等人[29] 利用 DRL來自動發現更好的改進策略,提出了一個 DRL 框架來改進啟發式算法解決路徑問題。模型首先提出一種用于改進啟發式算法的RL公式,其中策略網絡由兩部分組成,分別學習節點嵌入和節點對選擇,用來指導下一個解決方案的選擇;并利用AC 算法訓練策略網絡,然后通過鄰域搜索來改進初始解,不斷地提高解的質量,最后利用基于自注意力的框架參數化策略。將模型應用于求解 TSP 和 CVRP 的實驗結果表明,模型明顯優于現有的基于線性規劃的求解TSP 和 CVRP 方法,在改進啟發式算法過程中,學習到的策略確實比傳統的手工規則更有效,并且可以通過簡單的集成策略進一步增強。
? ? ? ?基于 Transformer 還有更多的改進, Falkner 等 采用修復和破壞算子,通過局部搜索過程和維護少量候選 解 來 進 一 步 擴 展 大 鄰 域 搜 索(large neighborhood search, LNS )。 LNS 是神經修復算子與局部搜索過程、啟發式破壞算子和部分解的選擇過程相結合,以獲得高效的求解方法,LNS 主要思想是利用學習的模型來重構部分被破壞的解,并通過破壞啟發式(或隨機策略本身)引入隨機性來有效地探索大鄰域。文獻[49] 啟發式方法針對解決方案的不同部分,將銷毀分為兩種不同的操作:創建部分路線、刪除完整的路線。與文獻[49] 每次考慮一個節點的構造啟發式相反,Hottung 和 Tierney 直接學習神經修復算子,以重新組合由CVRP 的隨機分裂產生的路徑片段。
? ? ? ?基于 Falkner , Ma 等人 ? 提出雙方面協作Transformer( dual-aspect collaborative transformer , DACT)神經領域搜索模型,使用雙向編碼器分別學習節點和位置特征的嵌入,利用循環格雷碼鄰接相似、首尾相似的特性設計高維空間連續的循環位置編碼(cyclic positional encoding,CPE),訓練過程中使用課程學習獲得更高效的采樣速率,以及更快的收斂速度和更小的方差,提高求解VRP的泛化性能。應用DACT求解TSP和CVRP的結果表明,DACT優于現有的鄰域搜索求解器,并且具有更優的泛化性能。
2.2.2 模型總結
現實生活中 VRP 問題涉及車輛容量、時間窗口等約束,雖然近年來已經開發了 RL 模型來比優化啟發式更快地解決基本的 VRP 問題,但很少考慮復雜的約束。啟發式算法高效的鄰域搜索功能是求解 VRP 問題的關鍵組成部分,Ma 等人 [52] 針對取貨和送貨問題( pickup and delivery problem, PDP )問題設計基于并改進 DACT 的神經鄰域搜索方法 N2S , N2S 將 DACT-Attention 改進為高效的 Synth-Attention ,允許最基本的自我注意機制合成關于解決方案的各種特征,同時利用兩個自定義解碼器自動學習執行取貨和送貨節點對的移除和重新插入,以解決優先級約束。模型甚至在更多約束的PDP 變體上超過了人工設計的LKH3 求解器。
2.3 基于GNN模型求解VRP
2.3.1 求解模型
? ? ? ? 近年來,研究人員設計了用于處理圖數據的神經網絡結構 GNN ,其核心思想是根據每個節點的原始信息(如城市坐標) 和各個節點之間的關系(城市之間的距離),計算得到各個節點的特征向量,依據節點特征向量進行節點預測、邊預測等任務。GNN 與圖嵌入密切相關,圖嵌入旨在通過保留圖的拓撲結構和節點內容信息,將圖中頂點表示為低維向量,以便使用RL 算法進行處理。Scarselli 等人[14] 利用GNN模型處理圖上的數據表示問題,實現了函數  將圖中的節點映射到多維歐幾里德空間,適用于以圖及其節點為中心的應用。
將圖中的節點映射到多維歐幾里德空間,適用于以圖及其節點為中心的應用。
將圖中的節點映射到多維歐幾里德空間,適用于以圖及其節點為中心的應用。 ? ? ? ?GNN 通過低維的向量信息來表征圖的節點及拓撲結構,有效的提取圖中關鍵節點信息。Nowak 等人 [53] 以SL的方式訓練 GNN ,直接輸出一個環游作為鄰接矩陣, 結合波束搜索將其轉換為可行的路徑方案。該方法被提出之后,structure2vec ( S2V )、GCN[54] 、圖注意力網絡
( graph attention network , GAT )等模型相繼被提出, 用于解決VRP 。
? ? ? ? 在許多實例中,相似的路徑問題通常保持相似的問題結構,但數據不同,這為學習啟發式算法提供了契機。 Khalil等人 [30] 指出上述網絡架構不能有效反映 TSP 的圖結構,并提出了一種將 RL 與圖嵌入神經網絡相結合的框架,以增量方式構造 TSP 和其他 VRP 問題的解決方案,引入基于 S2V 的圖嵌入網絡,以捕獲解決方案的當前狀態和圖的結構,然后使用 Q-learning 來學習貪婪策略,該策略決定將哪個頂點插入部分游覽,可求解大范圍的TSP問題。
GPN擴展了傳統的PN,增加了一層圖嵌入,這種轉換實現了對大規模問題的更好推廣。Kool 等人[17] 將GNN 和 PN 進行結合求解 CVRP,加入 MHA 以及自注意力機制,AM能有效地捕捉深層節點信息,采用AM計算每一步的節點選擇概率,以自回歸的方式逐步構造得到完整解,且模型通過設計超參數展示了在合理大小的多個 VRP問題上的靈活性。為學習更好的啟發式方法解決廣泛的VRP問題提供思路。
? ? ? ?Joshi 等人 [31] 基于 Kool 等人 [17] 的實驗設置,在 PN 基礎上用圖卷積神經網絡(graph convolutional networks ,GCN)編碼代替 Transformer 架構編碼,結合 SL 和 RL 訓練100 個節點的 TSP ,提升了模型的準確率,利用 SL 訓練 GNN ,以預測邊出現在 TSP 中的概率,通過波束搜索 生成可行的回路。為 TSP20/50/100 訓練基于自回歸的GAT模型,并評估從 TSP20 到 TSP500 的實例,通過 REINFORCE訓練 RL 模型和貪婪算法推出基線,以最大限度地減少模型在每一步的預測和最優目標。
? ? ? ?GCN [54] 是許多復雜 GNN 模型的基礎,其核心思想是學習一個函數映射,通過映射圖中的節點,聚合節點與其鄰居節點的特征來生成節點的新表示。Groshev 等人[55] 和 Joshi 等人 [56] 通過 SL 訓練 GCN 來解決 TSP 。 Joshi等人[56] 在 TSP20/50/100 的優化效果略微超越了 Kool 等人[17] 的方法,接近 LKH3 、 Concorde 等求解器得到的最優解,但是該方法的求解時間慢于 LKH3 、 Concorde 等方法,在泛化能力上該方法也不及 Kool 等人 [17] 的方法。Groshev 等人 [55] 使用經過訓練的 GCN 來指導啟發式算法輸出解決方案,利用這些解決方案作為標簽重新訓練大規模 TSP 的 GCN ,進一步, Prates 等人 [57] 使用 SL來訓練GNN ,將邊緣權重視為每個實例的特征,模型輸出的解決方案與最優解的偏差可以小于2% 。
? ? ? ?以上工作都是利用人工智能的泛化能力來探索滿足問題的車輛路徑,仍受到城市規模、大型交通網絡帶來的計算復雜度的困擾。James 等人 [58] 提出一種基于DRL的 NCO 策略,將在線 VRP 問題轉換為車輛游覽生成問題,并提出一種圖嵌入式 PN 結構來迭代開發游覽。由于構造NN 所需的 SL 數據具有高計算復雜度,利用具有無監督輔助網絡的 DRL 機制來訓練模型參數,同時設計多采樣方案,以進一步提高模型性能。
2.3.2 模型總結
? ? ? ?GNN 和 GCN 用來提取圖的特征并部署記憶增強NN 和 RNN 傳遞順序信息, GAT 是一種基于空間的GCN 網絡。 GAT 是通過 AM 傳播節點信息,對圖拓撲具有強大的表示能力。因此,Gao 等人 [42] 在 GAT 基礎上改進提出 EGATE 模型(element-wise GAT with edge-embedding,EGATE),模型的編碼器是將節點嵌入和邊嵌入集成修改的GAT,以及一個基于GRU的解碼器,模型通過 AC 訓練,實驗結果表明,在中等規模的數據集上,該模型優于傳統啟發式算法和NCO模型,能夠處理大規模數據集。由于 VRP 問題的高復雜性,難以擴展且大多受到問題模型容量的限制。因此,學者提出利用混合方法來求解VRP及其變體問題。
2.4 混合模型求解VRP
2.4.1 RL結合傳統算法求解VRP
? ? ? ? 在求解 CVRP 問題時, LKH3 等經典算法求解效率低,難以擴展到更大的問題。基于 DRL 的方法求解效率高,但是 DRL 解的質量與傳統經典方法求得解的質量仍存在相當大的差距,為此 Lu 等人 [59] 提出一種在解決方案中迭代搜索,通過不斷地改善解,直到滿足某個終止條件的框架。模型將啟發式算子分為改進算子和擾動算子,即給定一個問題實例,算法首先生成一個可行解,然后用改進算子或擾動算子迭代地更新解,在一定次數的步驟之后,模型將在所有訪問的解決方案中選
擇最好的一個。
經典算法除了求解效率不高,求解 VRP 問題還面臨著狀態 空間爆炸問題,可行解的數量隨著問題規模的大小呈指數級增長,使得解決大規模 VRP 變得棘手。 Cappart 等人[32] 提出一種基于 DRL 和約束規劃(constraint programming,CP)混合模型求解TSPTW,模型核心是將TSPTW通過動態規劃(dynamic programing,DP)建模,模型架構分為三個部分:學習階段、求解階段和統一表示,其中智能體的動作銜接學習和求解兩個階段,學習階段是通過 RL 訓練問題實例,求解階段利用 CP評估問題實例。通過實驗證明,該模型的性能優于獨立的RL和CP解決方案,與求解器OR-Tools效果擔當。
? ? ? ?為進一步提高模型的泛化能力, Fu 等人 [33] 提出一個在固定大小的圖上預訓練的網絡,通過對子圖進行采樣,推斷和合并結果以解決更大規模的問題。在此基礎上,Xin 等人 [60] 提出將 DL 與傳統啟發式 LKH 相結合的算法NeuroLKH 解決 TSP 。該模型訓練了一個稀疏圖網絡(sparse graph network , SGN ),分別通過 SL 和無監督學習訓練邊緣分數、節點懲罰,以此提高 LKH 的性能,
基于 SGN 的輸出, NeuroLKH 創建邊緣候選集并轉換邊緣距離以指導 LKH 的搜索過程。文獻 [60] 實驗結果顯示,NeuroLKH 顯著優于 LKH ,并且模型可以很好地推廣到CVRP 、 PDP 。
? ? ? ?DRL 方法通常缺少在解空間內搜索的能力。為克服以上問題,王原等人[61] 提出了深度智慧型蟻群優化算法(deep intelligent ant colony optimization , DIACO ),采用 DRL 方法提取問題特征,并形成對應的特征矩陣,蟻群算法基于特征矩陣進行搜索求解,蟻群算法的加入提高了 DRL 解空間搜索性能,同時 DRL 提升了蟻群算法的計算能力,該方法能夠有效求解不同規模的 TSP。
? ? ? ?一些求解 VRP 的模型可以通過 Q-learning 很好地訓練,但不能通過Sarsa 訓練,降低了模型的性能。因此,Zheng等人 [62] 提出一種基于 RL 的啟發式算法 VSR-LKH ,該算法顯著提升了著名的 LKH 算法,它將 Q-learning 、Sarsa 和 MCT 三種算法相結合,取代 LKH 的遍歷操作, 是一種可變策略。可變策略的思想是受可變鄰域搜索的啟發,定義一個 Q 值來代替 α 值,通過結合城市距離和 α 值來進行候選城市的選擇和排序,并且通過迭代搜索過程中產生的可行解的信息自適應地調整Q 值,以進一步提高模型泛化性能。
2.4.2 RL與神經網絡相結合的混合模型
? ? ? ? 由于 RL 學習方法大多直接學習端到端的解決方案,以及 VRP 問題的高復雜性,難以擴展且受到 RL 模型容量的限制,為克服上述問題,Wang 等人 [63] 設計了一 個雙層框架求解器,上層學習框架來優化圖(例如,添加、刪除或修改圖中的邊),下層啟發式算法在優化的圖上求解,這樣的雙層網絡簡化了對原始問題的學習,并且可以有效地減輕對模型容量的需求。
? ? ? ?面對更復雜或者大范圍的路徑問題時,經典的DRL算法仍然得不到好的優化效果,訓練好的模型泛化到大范圍時解的質量會下降。于是研究者提出了分層強化學習(hierarchical reinforcement learning , HRL )模型,HRL在面對高維度問題時不會出現維度災難,將一個復雜的問題分解為簡單的子問題,從而來解決大規模的TSP。 Ma 等人 [15] 使用 RL 訓練分層 GPN ,在約束條件下學習分層策略尋找最優解,該模型在小范圍TSP 訓練且泛化到大范圍TSP 也具有更快的計算速度和最短距離。
? ? ? ?而對于問題 TSP-D , Bogyrbayeva 等人 [34] 提出了一種AM-LSTM 混合模型,用于考慮車輛和無人機之間交互作用的高效路徑,該模型由一個基于AM 的編碼器和一個基于 LSTM 的解碼器組成, AM 對高度連通的圖形進行編碼,LSTM 存儲所有車輛的歷史路徑。數值結果所示,這種混合模型在解決方案質量和計算效率方面都優于基于 AM 機制的模型,以及模型泛化到對最小 - 最大容量約束車輛路徑問題的實驗也證實了混合模型比基于注意的模型更適合于多車輛協調的路徑問題。
? ? ? ? 與啟發式方法相比,經典的 DP 算法保證了最優解, 但隨著問題規模的增大使得泛化性很差。為此 Kool 等人[64] 提出深度策略動態規劃( deep policy dynamic programming, DPDP ),將神經啟發式的優勢與 DP 算法的優勢相結合。DPDP 使用來自 DNN 的策略對 DP 狀態空間進行優先級排序和限制,以及使用 GNN 對部分解進行評估,對DP 算法進行“神經增強”。實驗結果表明,神經策略有效地提高了 DP 算法的性能,對于具有 TSP100 ,該方法產生與高度優化的 LKH 求解器相接近的結果,在TSPTW100上,DPDP的求解速度顯著快于LKH。
? ? ? ? 面對 CVRP ,王揚等人 [43] 提出動態圖 Transformer (dynamic graph transformer model , DGTM )混合模型, 使用動態位置編碼技術,用于循環編碼動態序列,使得節點坐標在嵌入過程滿足平移不變性,其次將 GNN 的聚合操作處理應用于 Transformer 解碼架構中,最后通過雙重損失的 REINFORECE 算法訓練 DGTM ,有效調節不同節點間的差異分布程度,防止過早收斂。DGTM在處理 CVRP 問題上優化結果得到顯著提高且具有較好的泛化性能。
2.4.3 模型總結
? ? ? ?之前關于求解車輛路徑的工作主要集中在自回歸模型,但當與任何形式的搜索方法相結合時,需要為每個部分解來評估模型,導致模型的計算成本很高。而Kool等人 [64] 提出的模型每個實例只需要對 NN 進行一次評估,因此可以進行更大范圍的搜索。
3 DRL求解VRP的分析
3.1 求解方法局限性
? ? ? ? 利用 RL 求解 VRP 需要不斷調整參數,改進策略網絡,在訓練過程中難免會出現模型不穩定、泛化能力差或過于依賴標簽等情況,都會對模型的最終性能造成影響。下面分別對基于 PN 、基于 GNN 、基于 Transformer和混合模型求解VRP 的相關模型進行局限性分析。
? ? ?? 基于 PN 模型局限性分析: PN 結構簡單,無法處理動態信息;網絡層數少,不利于充分提取問題的特征信息;在處理動態信息過程中,信息本身的不穩定性、節點信息稀疏性都會限制模型的優化效果影響解的輸出。
? ? ? ?基于 Transformer 模型局限性分析:網絡層數多、結構復雜,模型參數變多且不易訓練。
? ? ? ?基于 GNN 模型局限性分析:模型需借助驗證集早停提升模型性能;訓練是整個批次進行的,難以擴展到大規模網絡,且收斂較慢;網絡層數太深時,模型參數不能得到有效的訓練;圖的拓撲性質會導致巨大的解空間在搜索過程也是困難的,從而限制模型的優化效果。
? ? ? ?混合模型求解 VRP 局限性分析:使用傳統算法搜索導致訓練時間較長,優化性能無法保證,可能出現解碼錯誤等情況。 因此無論是基于圖結構模型、還是基于 DRL 結合傳統算法模型求解 VRP ,都有一定的局限性,表 3 對求解VRP 的經典模型進行局限性分析。
3.2 RL求解VRP問題的優勢及實驗對比
? ? ? ?VRP 有很多變體涉及動態不確定因素,利用傳統方法求解問題難度很大,且不會有很大的突破 。 RL 與傳統算法的結合求得的結果優于只使用傳統算法的結果,例如 Alipour 等人 [69] 面對多約束條件的路徑問題,使用 RL 算法使問題描述更加全面,解的質量也很高。VRP變體都是在經典的TSP上衍生的,具有相似的優化結構,傳統算法在問題描述發生輕微變化時,就要重新設計算法,面對 VRP眾多變體,設計很多算法將消耗大量人力,因此,單獨地使用傳統算法是不可行的。
? ? ? ?在面對具有多個約束條件的問題時,輸入輸出是隨機的、動態的,且前一步的結果可能會對下一步求解有影響。一些傳統算法難以考慮隨機和動態因素,導致模型泛化能力弱,不能在各個變體中通用或者得到解的質量很差。而 NN 中的嵌入方式可以根據問題的情況做靜態嵌入和動態嵌入,充分保證了原始問題的真實性。Li等人 [36] 提出 DRL 方法求解覆蓋旅行商問題( covering salesman problem, CSP ),模型基于 PN 加入動態嵌入模型處理動態信息,計算速度比傳統啟發式快近 20 倍。利用RL 求解 VRP 與傳統方法相比, RL 有優質的表現和泛化能力,加入動態嵌入可以更好地處理動態信息,深層次的網絡更有利于提取深層次潛在的隱含信息。
? ? ? ?總的來說, RL 求解 VRP 相比傳統算法的優勢如下:(1 )求解速度快。 DNN 模型對問題特征進行全方位的表示,減少了解空間的搜索寬度和深度;硬件設施 CPU 更高、更快、更強和GPU 在 ML 領域的優異表現,使得 VRP問題在最短的計算時間內得到顯著的優化效果;模型一旦訓練完成,以 O ( n ) 的復雜度輸出解。( 2 )泛化能力的提高。面對具有相似結構的問題,只需調用參數通過遷移學習傳遞給相應的策略函數,就能輸出合適的解,減少對數據標簽的依賴性,節省大量資源和計算時間。通過 DRL 學出來的策略有希望比人工設計出來的更高效,不需要重新設計算法。(3 )解決了多維度問題。面對多維度問題,可以使用不同嵌入方式結合AM使問題的描述更加詳細,挖掘更深層次的關系,從而輸出高質量的解。DRL有望能夠求解一些復雜約束條件下的NP難問題。 
? ? ? ? 本文對端到端的 DRL 方法作了詳細的介紹,為保持實驗數據公平性,所有實驗均基于 Pytorch-1.9.0 深度學習平臺,在 Windows11 操作系統環境下使用單張Nvidia RTX 3050 GPU 和 i5-11300H CPU 運行 VRP模型,這里總結了常用的基于 DRL 的方法和啟發式算法的最新實驗結果,表 4 是針對 CVRPlib 數據集實例上具有代表性模型的優化效果的對比。實驗結果顯示, DACT 模型的優化性能超越了目前基于 DRL 的模型和專業求解器。
4.總結及未來發展方向
? ? ? ? 最近,許多研究人員回顧了基于 RL 求解 VRP ,每篇綜述都有各自的優點和不足,本文對最近發表的綜述進行整理分析:Mazyavkina 等人 [70] 總結了一些常用的基于策略和基于價值的強化學習算法,沒有比較模型間的差距,沒有數據對比;Kotary 等人 [71] 對 ML 學習方法進行分類,側重于端到端的學習范式,籠統地介紹了 GNN ;Cappart等人 [72] 對 GNN 在各種推理任務中的應用進行了高級概述沒有描述學習在 CO 推理中的具體作用和過程;Bengio 等人 [73] 對 COP 的 ML 算法進行概述,為 ML 應用到COP 提供理論基礎,但未對 ML 求解 COP 的建模過程進行詳細介紹。
? ? ? ?DRL 將 VRP 問題與 DNN 結合起來,將 VRP 的特殊 性和 DRL 的優勢結合起來,克服了單獨使用傳統算法求解效果不理想的局限性,是目前解決 VRP 及其變體最流行的方法。本文對 RL 的相關算法以及 DRL 模型的構建過程進行了詳細的介紹,并梳理了先前模型的創新點和不足之處,重點分析了 DRL 模型架構的主要作用和特性。VRP是多變體多維度的,且現實數據與訓練數據會有差距,導致模型在應用到實例會出現效果不好、最優間隙差等情況,由這些模型的不足可以看到,將 
來使用 DRL 解決 VRP 及其變體問題仍存在挑戰性。
( 1 )現有基于學習的方法僅僅訓練特定的路徑問題,對特定路徑問題的范圍進行泛化求解。未來可以考慮將訓練完成的路徑策略通過遷移學習技術,在不同實例上進行泛化求解,會節省大量的計算資源,提高模型的利用率。進一步深入探求不同參數之間的內在聯系, 建立 VRP 問題變體之間的源域到目標域的映射關系是未來值得研究的問題。
( 2 )現有 RL 模型求解 VRP 屬于端到端的方法,求解過程類似于黑箱優化,缺乏相應的理論保證。未來工作中,尋找一種通用的體系結構,有效地保證 DRL 求解方法的可行性,還需要進一步評估和檢驗。未來工作中可以考慮將 DRL 及其網絡架構遷移至運籌優化算法中,以增強求解的可靠性。因此繼續深入探求 DRL的求解過程和增強模型的可解釋性是未來值得研究的問題。
( 3 )大多數網絡使用均勻分布或者隨機生成數據來訓練策略網絡,訓練好的模型可以泛化到不同的問題上,但是模型泛化能力的好壞或許與訓練數據有關,若節點位置分布不知或不遵循任何分布,此時構建一個穩定的模型具有很大挑戰。如何為 VRP及其變體問題構建魯棒性的訓練模型是未來工作中的關鍵研究點。未來考慮通過 知識蒸餾的方法提升 DRL模型在不同數據分布下的泛化能力。
( 4 ) RL 含有大量手工設計的超參數,不同的參數往往對模型的性能影響較大。為減少超參數對實驗結果的影響,考慮將自動 RL 參數調整技術引入到模型訓練中。自動調整學習率和衰減率對模型收斂性的控制是未來一個重要的研究方向。

![[數據結構] 基于選擇的排序 選擇排序堆排序](http://pic.xiahunao.cn/[數據結構] 基于選擇的排序 選擇排序堆排序)
:分代假說與垃圾回收算法)









)






