系列文章目錄
一、Hive基礎架構(重點)
二、Hive數據庫,表操作(重點)
三、Hadoop架構詳解(hdfs)(補充)
四、Hive環境準備(操作)(補充)
文章目錄
- 系列文章目錄
- 前言
- 一、Hive基礎架構
- 1、Hive和MapReduce的關系
- 2、Hive架構(熟悉)
- 3、MetaStore元數據管理服務
- 4、數據倉庫和數據庫(熟悉)
- 4.1 數據倉庫和數據庫的區別
- 4.2 數據倉庫基礎三層架構
- 4.3 ETL和ELT
- 二、Hive數據庫操作
- 1、基本操作(掌握)
- 2、其他操作(了解)
- 三、Hive官網介紹(了解)
- 四、Hive表操作(掌握)
- 1、建表語法
- 2、數據類型
- 3、表分類
- 4、默認分隔符
- 5、內部表
- 6、外部表
- 7、查看和修改表
- 8、快速映射表
- 五、Hadoop(補充)
- 1、分布式和集群
- 2、Hadoop框架
- 2.1 概述
- 2.2 版本更新
- 2.3 Hadoop架構詳解(掌握)
- 2.4 官方示例(體驗下)
- 2.4.1 圓周率練習
- 2.4.2 詞頻統計
- 3、Hadoop的HDFS(掌握)
- 3.1 特點
- 3.2 架構
- 3.3 副本
- 3.4 shell命令
- 六、Hive環境準備(操作)
- 1、shell腳本執行方式
- 2、配置Hive環境變量
- 3、啟動和停止Hive服務
- 4、連接Hive服務
- 5、DataGrip連接Hive服務
- 5.1 創建DataGrip項目
- 5.2 連接Hive
- 5.3 配置驅動jar包
- 6、DataGrip連接MySQL
前言
本文主要詳解
一、Hive基礎架構(重點)
二、Hive數據庫,表操作(重點)
三、Hadoop架構詳解(hdfs)(補充)
四、Hive環境準備(操作)(補充)
一、Hive基礎架構
1、Hive和MapReduce的關系

1- 用戶在Hive上編寫數據分析的SQL語句,然后再通過Hive將SQL語句翻譯成MapReduce程序代碼,最后提交到Yarn集群上進行運行
2- 大家可以將Hive理解成有道詞典,幫助你翻譯英文
2、Hive架構(熟悉)
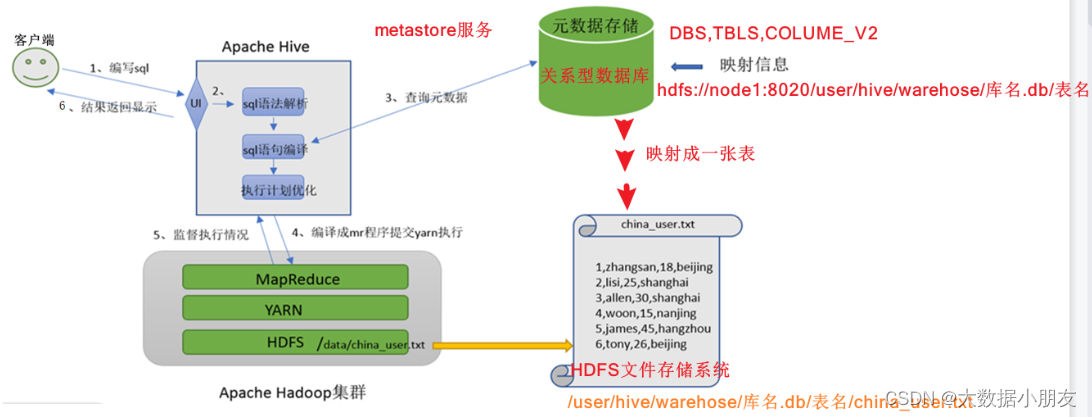
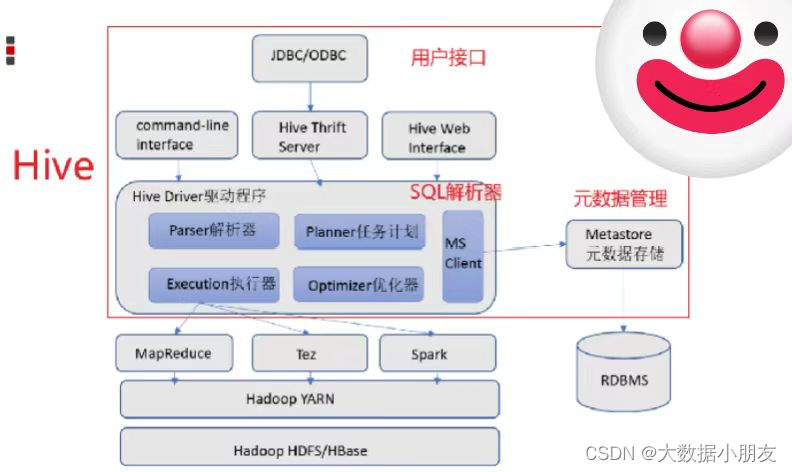
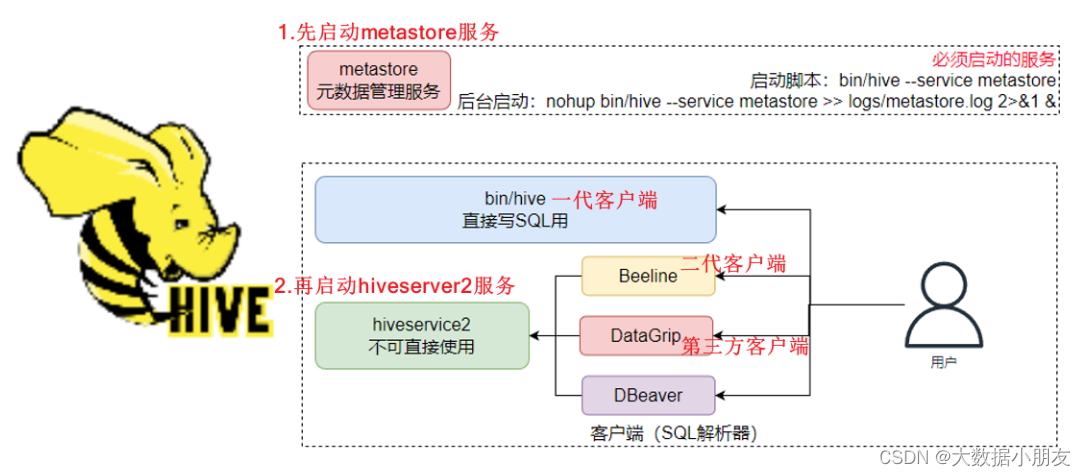
用戶接口: 包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)為shell命令行;Hive中的Thrift服務器允許外部客戶端通過網絡與Hive進行交互,類似于JDBC或ODBC協議。WebGUI是通過瀏覽器訪問Hive。Hive提供了 Hive Shell、 ThriftServer等服務進程向用戶提供操作接口Hiveserver2(Driver): 包括了語法、詞法檢查、計劃編譯器、優化器、執行器。核心作用是完成對HiveSQL(HQL)語句從詞法、語法檢查,并且進行編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在HDFS中,并在隨后由MapReduce進行執行。
注意: 這部分內容不是具體的進程,而是封裝在Hive所依賴的jar中通過Java代碼實現。元數據信息: 包含用Hive創建的Database、table,以及表里面的字段等詳細信息
元數據存儲: 存儲在關系型數據庫(RDBMS relation database manager system)中。例如:Hive中有一個默認的關系型數據庫是Derby,但是一般會改成MySQL。Metastore: 是一個進程(服務),用來管理元數據信息。
作用: 客戶端連接到Metastore中,Metastore再去關系型數據庫中查找具體的元數據信息,然后將結果返回給客戶端。
特點: 有了Metastore服務以后,就可以有多個客戶端(工作中一般使用的就是DataGrip)同時連接。而且這些客戶端都不需要知道元數據存儲在什么地方,你只需要連接到Metastore服務里面就行。
3、MetaStore元數據管理服務
metastore服務配置有3種模式: 內嵌模式、本地模式、遠程模式
推薦使用: 遠程模式
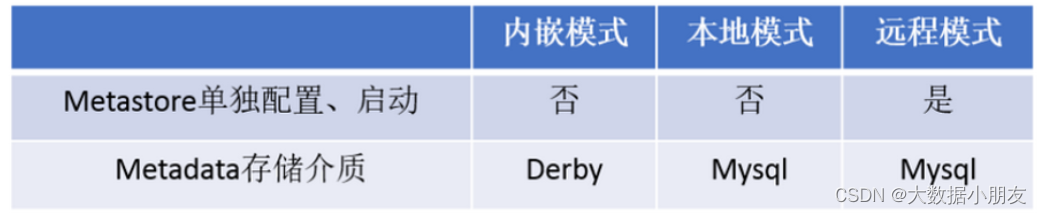
內嵌模式:優點: 解壓hive安裝包 bin/hive 啟動即可使用缺點: 不適用于生產環境,derby和Metastore服務都嵌入在主Hive Server進程中,一個服務只能被一個客戶端連接(如果用兩個客戶端以上就非常浪費資源),且元數據不能共享本地模式: 優點: 可以單獨使用外部數據庫(一般是MySQL)進行元數據的管理缺點: 相對浪費資源。指的是Metastore每次啟動一次的時候都需要對應的啟動Hiveserver2服務。也就是本地模式他們兩個是成對出現的。這3個服務的啟動順序,MySQL->metastore->Hiveserver2遠程模式: 優點: 可以單獨使用外部數據庫(一般是MySQL)進行元數據的管理。Hiveserver2、metastore、MySQL這3個可以單獨配置、啟動、運行缺點:1- 這3個服務的啟動順序,MySQL->metastore->Hiveserver22- 這3個服務可能是分布在不同機器上運行的,可能會導致不同服務間進行數據交換速度比較慢工作中推薦使用遠程模式
4、數據倉庫和數據庫(熟悉)
4.1 數據倉庫和數據庫的區別
數據庫與數據倉庫的區別:實際講的是OLTP與OLAP的區別
OLTP(On-Line Transaction Processin): 聯機事務處理。數據庫中可以進行數據的【增刪改查】操作OLAP(On-Line Analytical Processing): 聯機分析處理。數據倉庫中主要是對數據進行【查詢】操作數據倉庫主要特征:數據倉庫的出現,并不是要取代數據庫,主要區別如下:1- 數據庫是面向事務的設計,數據倉庫是面向主題設計的。2- 數據庫是為捕獲(指的是能夠對數據進行增刪改操作)數據而設計,數據倉庫是為分析數據而設計3- 數據庫一般存儲業務數據(由于用戶的各種操作行為產生的數據,例如:下單、商品瀏覽等),數據倉庫存儲的一般是歷史數據。4- 數據庫設計是盡量避免冗余,一般針對某一業務應用進行設計,比如一張簡單的User表,記錄用戶名、密碼等簡單數據即可,符合業務應用,但是不符合分析。5- 數據倉庫在設計是有意引入冗余,依照分析需求,分析維度、分析指標進行設計。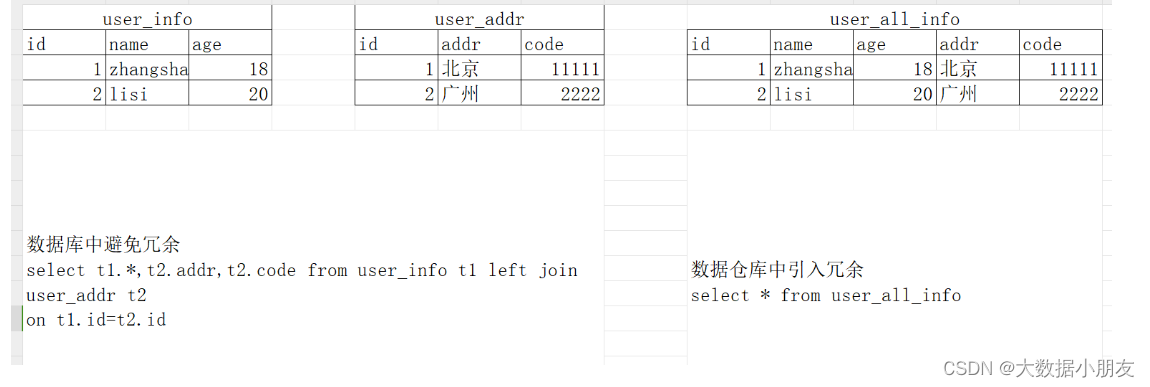
4.2 數據倉庫基礎三層架構
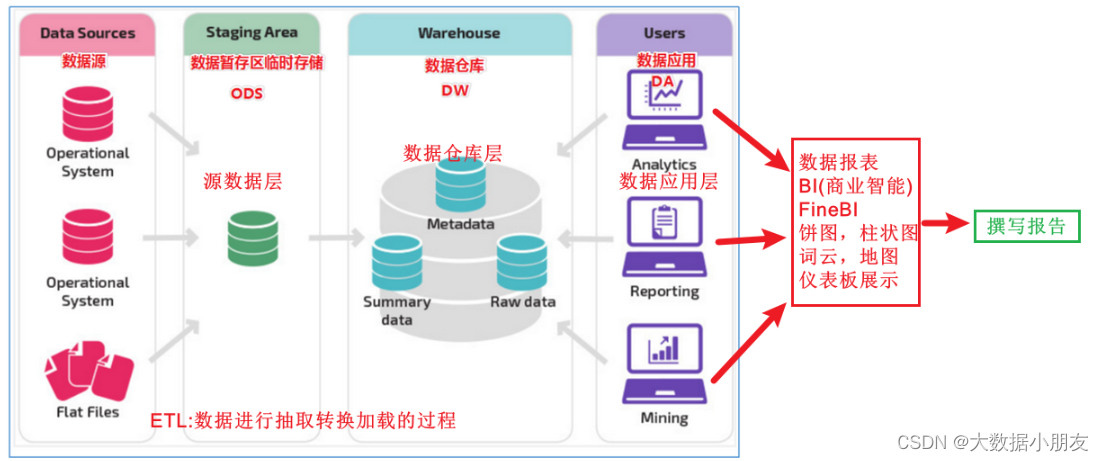
源數據層(ODS): 該層數據幾乎不做任何處理操作。直接使用外部系統中的數據結構(數據庫名稱、表名稱、表結構)。為大數據數倉中后續的其他處理提供數據支撐數據倉庫層(DW): 也稱之為細節層。DW層的數據應該做到一致、準確、干凈。也就是對ODS層中的數據進行ETL以及數據指標分析數據應用層(DA或APP): 前端頁面直接讀取該層的數據,進行前端可視化(以看得見的圖表、曲線圖、柱狀圖、餅圖)的展示大數據前端產品示例:https://tongji.baidu.com/main/overview/demo/overview/index
4.3 ETL和ELT
廣義上ETL:數據倉庫從各數據源獲取數據及在數據倉庫內的數據轉換和流動都可以認為是ETL(抽取Extract, 轉化Transform , 裝載Load)的過程。但是在實際操作中將數據加載到倉庫卻產生了兩種不同做法:ETL和ELT。狹義上ETL: 先將數據從業務系統(可以理解為例如京東的訂單數據)中抽取到數據倉庫的ODS層中,然后執行轉換操作,將數據結構化并且轉換層適合后續容易處理的表結構ELT: 將數據從業務系統中抽取并且直接加載到數據倉庫的DW層的表里面。加載完以后,再根據業務需求對數據進行清洗以及指標的計算分析
二、Hive數據庫操作
1、基本操作(掌握)
知識點:
創建數據庫: create database [if not exists] 庫名 [location '路徑'];使用數據庫: use 庫名;注意: location路徑默認是:刪除數據庫: drop database 數據庫名 [cascade];
示例:
-- Hive的數據庫核心操作(掌握)
-- 創建Hive數據庫
-- if not exists:如果不存在,就創建;如果存在,不會有任何的變化
-- 數據庫默認放在/user/hive/warehouse HDFS目錄中
create database if not exists hive1;create database test;-- 創建數據庫的時候可以手動指定數據庫存放的路徑(不推薦使用,了解)
-- location指定的是HDFS路徑
create database test1 location '/test1';-- 在數據庫中創建表
-- 需要先指定數據庫
use hive1;-- 建表
-- 建表實際上就是在HDFS的數據庫目錄下創建一個與表名同名的文件夾
create table stu(id int,name varchar(100));-- 通過 數據庫名稱.表名稱 也可以創建表
create table test1.stu(id int,name varchar(100));-- 刪除數據庫
drop database test1;-- 強制刪除非空的數據庫
-- 刪除數據庫的時候,同時會將HDFS上面的數據庫目錄刪除
drop database test1 cascade;-- 查看建庫的語句
show create database hive1;-- 查看所有數據庫
show databases;-- 查看目前正在使用的數據庫
select current_database();-- 查看指定數據庫的基本信息。desc是describe單詞縮寫
desc database hive1;
刪除數據庫可能遇到的錯誤:
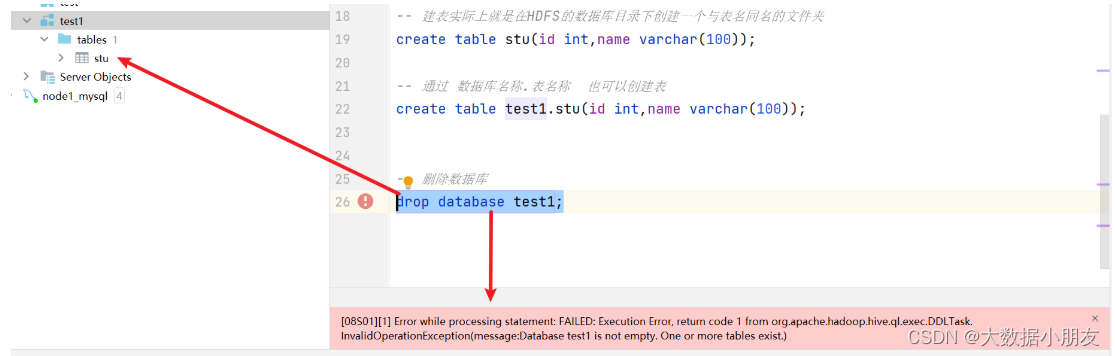
原因: 在Hive中刪除數據庫的時候,需要確保數據庫下面沒有其他的內容,否則會報錯
解決辦法: 1- (不推薦)先手工刪除數據庫中的內容,然后再刪除2- 使用cascade進行強制刪除
2、其他操作(了解)
知識點:
創建數據庫: create database [if not exists] 庫名 [comment '注釋'] [location '路徑'] [with dbproperties ('k'='v')];修改數據庫路徑: alter database 庫名 set location 'hdfs://node1.itcast.cn:8020/路徑'
修改數據庫屬性: alter database 庫名 set dbproperties ('k'='v');查看所有的數據庫: show databases;
查看某庫建庫語句: show create database 庫名;
查看指定數據庫信息: desc database 庫名;
查看指定數據庫擴展信息: desc database extended 庫名;
查看當前使用的數據庫: select current_database();
示例:
-- Hive數據庫的其他操作(了解)
-- 1- 創建數據庫database,也可以使用schema進行創建數據庫
create schema demo1;-- 2- 創建數據庫指定其他的信息。推薦大家將數據庫默認就放在/user/hive/warehouse路徑
create database demo2comment "這是一個數據庫"location "/user/hive/warehouse/demo2.db"with dbproperties ('name'='my name is demo2');create database demo3comment "it is database"location "/user/hive/warehouse/demo3.db"with dbproperties ('name'='my name is demo3');-- 3- 查看建庫的語句
show create database demo3;-- 4- 查看所有數據庫
show databases;-- 5- 查看目前正在使用的數據庫
select current_database();-- 6- 查看指定數據庫的基本信息。desc是describe單詞縮寫
desc database demo3;
-- describe database demo3;-- 7- 查看指定數據庫的擴展信息
desc database extended demo3;-- 8- 修改數據庫中數據存放的路徑
-- 注意:location中的路徑必須要寫HDFS完整路徑
-- 注意:如果修改了數據庫的路徑,那么只有在數據庫下面創建表的時候,它才會給你創建數據庫目錄
-- 注釋的快捷鍵:ctrl+/
-- 復制的快捷鍵:ctrl+D
-- alter database demo3 set location '/dir/demo3';
alter database demo3 set location 'hdfs://node1:8020/dir/demo3';
-- 注意:如果修改了數據庫的路徑,那么只有在數據庫下面創建表的時候,它才會給你創建數據庫目錄
create table demo3.stu(id int,name varchar(100));alter database demo3 set dbproperties ('name'='my name is demo33333');desc database extended demo3;
修改數據庫的location可能遇到的錯誤:
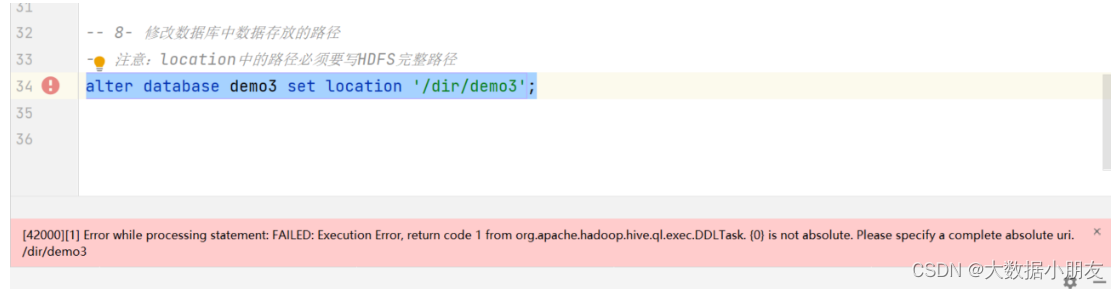
原因: location中的路徑必須要寫HDFS完整路徑
三、Hive官網介紹(了解)
-
地址https://hive.apache.org/
-
文檔
-
數據庫操作
-
其他文檔
四、Hive表操作(掌握)
1、建表語法
create [external] table [if not exists] 表名(字段名 字段類型 , 字段名 字段類型 , ... )
[partitioned by (分區字段名 分區字段類型)] # 分區表固定格式
[clustered by (分桶字段名) into 桶個數 buckets] # 分桶表固定格式 注意: 可以排序[sorted by (排序字段名 asc|desc)]
[row format delimited fields terminated by '字段分隔符'] # 自定義字段分隔符固定格式
[stored as textfile] # 默認即可
[location 'hdfs://node1.itcast.cn:8020/user/hive/warehouse/庫名.db/表名'] # 默認即可
; # 注意: 最后一定加分號結尾注意: 1- 關鍵字順序是從上到下從左到右,否則報錯2- 關鍵字不區分大小寫。也就是例如create可以大寫也可以小寫
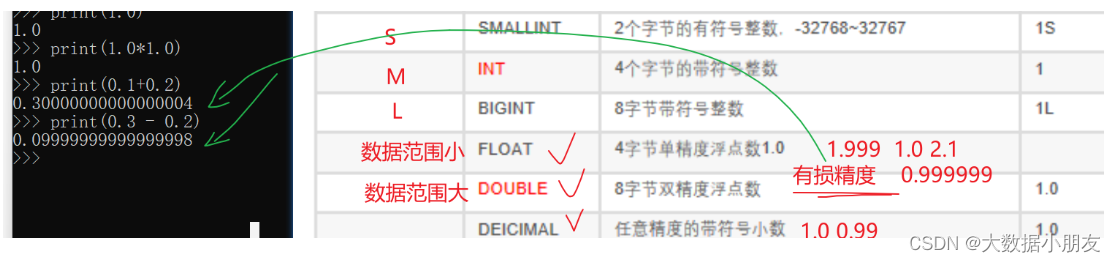
2、數據類型
1、基本數據類型整數: int 小數: float double 字符串: string varchar(長度) 日期: date timestamp補充: timestamp時間戳,指的是從1970-01-01 00:00:00 到現在的時間的差值。2、復雜數據類型集合: array 映射: map 結構體: struct 聯合體: union
3、表分類
Hive中可以創建的表有好幾種類型, 分別是:
內部表(管理表): MANAGED_TABLE分區表分桶表外部表(非管理表): EXTERNAL_TABLE分區表分桶表default默認庫存儲路徑: hdfs://node1:8020/user/hive/warehouse
自定義庫在HDFS的默認存儲路徑: hdfs://node1:8020/user/hive/warehouse/數據庫名稱.db
自定義表在HDFS的默認存儲路徑: hdfs://node1:8020/user/hive/warehouse/數據庫名稱.db/表名稱
業務數據文件在HDFS的默認存儲路徑: hdfs://node1:8020/user/hive/warehouse/數據庫名稱.db/表名稱/業務數據文件內部表和外部表區別?
內部表: 創建的時候沒有external關鍵字,默認創建的就是內部表,也稱之為普通表/管理表/托管表
刪除內部表: 同時會刪除MySQL中的元數據信息,還會刪除HDFS上的業務數據外部表: 創建的時候有external關鍵字,創建的就是外部表,也稱之為非托管表/非管理表/關聯表
刪除外部表: 只會刪除MySQL中的元數據信息,不會刪除HDFS上的業務數據面試題: 你在數倉中使用的是什么類型的Hive表?
說法一: 我在項目中使用的是內部表,因為這些表的數據是完全由我自己負責的,因此我對這些表以及表數據有絕對的控制權限,我能夠對表進行增刪改查的操作,因此用的就是內部表
說法二: 我在項目中使用的是外部表,因為這些表的數據是由其他人負責導入進來,而我沒有絕對的控制權限,我只能對數據進行查詢,因此使用的就是外部表
-- 創建內部表
-- 注意事項:
use hive1;create table stu1(id int,name string
);create table stu2(id int,name string
);-- 創建外部表
create external table stu3(id int,name string
);-- 查看表結構
desc stu1;
desc stu3;-- 查看表格式化的信息
desc formatted stu1;
desc formatted stu3;-- 添加數據到表里面
insert into stu1 values(1,'zhangsan');
insert into stu3 values(1,'zhangsan');-- 刪除表
drop table stu1; -- 內部表
drop table stu3; -- 外部表
刪除內部表和外部表前后元數據信息的變化
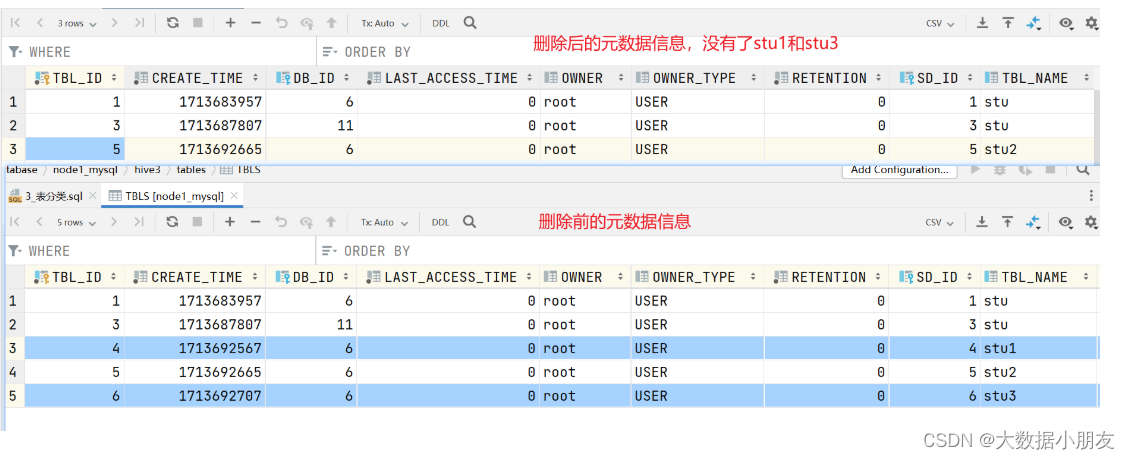
內部表信息:
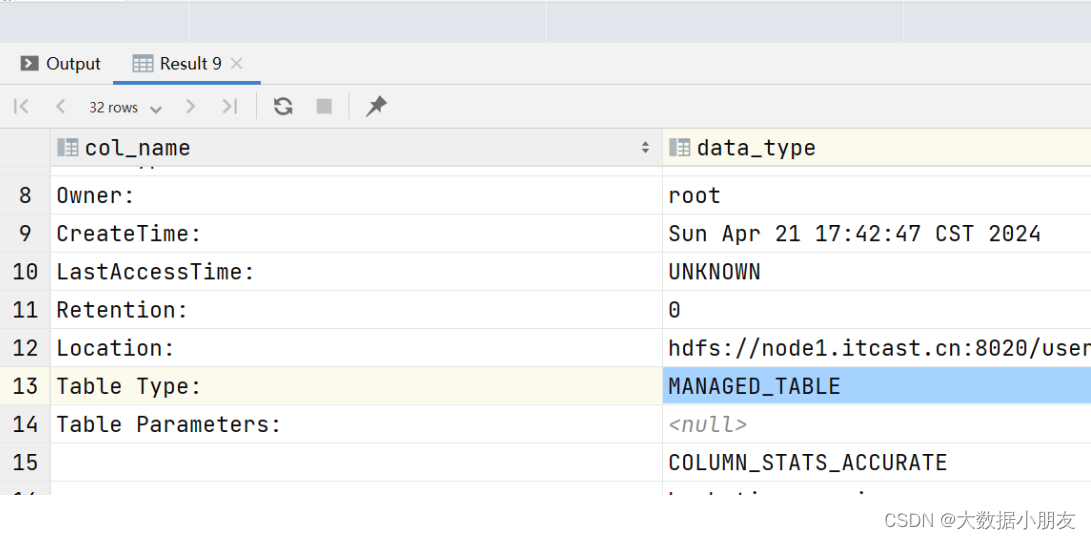
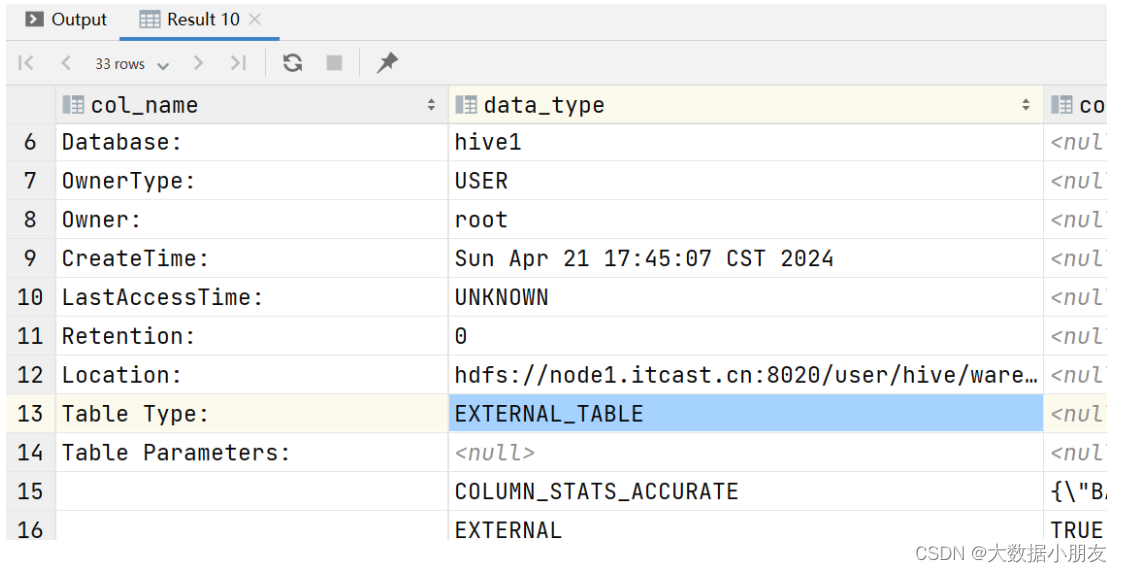
外部表信息:
Hive建表的時候可能遇到的錯誤:
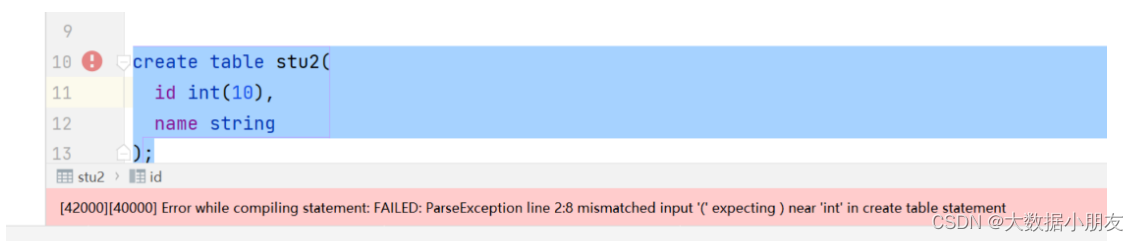
原因: 在Hive中int數據類型,不能指定長度
4、默認分隔符
知識點:
創建表的時候,如果不指定分隔符,以后表只能識別默認的分隔符,鍵盤不好打印,展示形式一般為:\0001,SOH,^A,□
Hive表的默認分隔符\001
示例:
-- 默認分隔符: 創建表的時候不指定就代表使用默認分隔符
-- 1.創建表
create table stu(id int,name string
);
-- insert方式插入數據,會自動使用默認分隔符把數據連接起來
-- 2.插入數據
insert into stu values(1,'zhangsan');
-- 3.驗證數據
select * from stu;
-- 當然也可以通過在hdfs中查看,默認分隔符是\0001,其他工具中也會展示為SOH,^A,□

5、內部表
知識點:
創建普通內部表: create table [if not exists] 表名(字段名 字段類型 , 字段名 字段類型...) [row format delimited fields terminated by '指定分隔符'];刪除內部表: drop table 內部表名; 注意: 刪除mysql中元數據同時也會刪除hdfs中存儲數據修改表名: alter table 舊表名 rename to 新表名;
修改表字段名稱和類型: alter table 表名 change 舊字段名 新字段名 新字段類型;
修改表之添加字段(列): alter table 表名 add columns (字段名 字段類型);
修改表之替換字段(列):alter table 表名 replace columns (字段名 字段類型);查看所有表: show tables;
查看指定表基本信息: desc 表名;
查看指定表擴展信息: desc extended 表名;
查看指定表格式信息: desc formatted 表名;
查看指定表建表語句: show create table 表名;
示例:
-- 內部表的操作-- 創建和使用數據庫
create database myhive;
use myhive;-- 創建內部表
create table if not exists stu(id int,name string
);-- 插入數據
insert into stu values(1,'張三');-- 查詢表數據
-- 下面語句被Hive進行了優化,不會變成MapReduce
select * from stu;
-- 這個會變成MapReduce
select name,count(1) from stu group by name;-- 建表的時候指定字段間的分隔符
create table if not exists stu1(id int,name string
) row format delimited fields terminated by ',';insert into stu1 values(1,'張三');-- 創建表的其他方式
-- 創建stu2表的時候,復制stu1的表結構,并且將select的查詢結果插入到stu2的表的里面去
-- 注意不會復制原表的分隔符,新表用的還是默認
create table stu2 as select * from stu1;select * from stu2;-- 該方式只會復制stu1表的結構,沒有數據。
create table stu3 like stu1;select * from stu3;-- 查詢表信息
-- 查看當前數據庫中的所有表
show tables;-- 查詢表的基本信息
desc stu3;-- 查看表的擴展信息
desc extended stu3;desc formatted stu3;-- 查看指定表的建表語句
show create table stu3;-- 刪除表
drop table stu;-- 清空表數據。需要保留表結構,但是不想要數據
select * from stu1;
truncate table stu1;
select * from stu1;
6、外部表
知識點:
創建外部表: create external table [if not exists] 外部表名(字段名 字段類型 , 字段名 字段類型 , ... )[row format delimited fields terminated by '字段分隔符'] ;復制表: 方式1: like方式復制表結構 注意: as方式不可以使用刪除外部表: drop table 外部表名;注意: 刪除外部表效果是mysql中元數據被刪除,但是存儲在hdfs中的業務數據本身被保留查看表格式化信息: desc formatted 表名; -- 外部表類型: EXTERNAL_TABLE注意: 外部表不能使用truncate清空數據本身
示例:
-- 二.外部表的創建和刪除
-- 1.外部的表創建
-- 建表方式1
create external table outer_stu1(id int,name string
);
-- 插入數據
insert into outer_stu1 values(1,'張三');-- 建表方式2
create external table outer_stu2 like outer_stu1;
-- 插入數據
insert into outer_stu2 values(1,'張三');-- 注意: 外部表不能使用create ... as 方式復制表
create external table outer_stu3 asselect * from outer_stu1; -- 報錯-- 2.演示查看外部表結構詳細信息
-- 外部表類型: EXTERNAL_TABLE
desc formatted outer_stu1;
desc formatted outer_stu2;-- 3.演示外部表的刪除
-- 刪除表
drop table outer_stu2;
-- 注意: 外部表不能使用truncate關鍵字清空數據
truncate table outer_stu1; -- 報錯
-- 注意: delete和update不能使用
delete from outer_stu1; -- 報錯
update outer_stu1 set name = '李四'; -- 報錯
7、查看和修改表
知識點:
查看所有表: show tables;
查看建表語句: show create table 表名;
查看表信息: desc 表名;
查看表結構信息: desc 表名;
查看表格式化信息: desc formatted 表名; 注意: formatted能夠展示詳細信息修改表名: alter table 舊表名 rename to 新表名
字段的添加: alter table 表名 add columns (字段名 字段類型);
字段的替換: alter table 表名 replace columns (字段名 字段類型 , ...);
字段名和字段類型同時修改: alter table 表名 change 舊字段名 新字段名 新字段類型;注意: 字符串類型不能直接改數值類型修改表路徑: alter table 表名 set location 'hdfs中存儲路徑'; 注意: 建議使用默認路徑
location: 建表的時候不寫有默認路徑/user/hive/warehouse/庫名.db/表名,當然建表的時候也可以直接指定路徑修改表屬性: alter table 表名 set tblproperties ('屬性名'='屬性值'); 注意: 經常用于內外部表切換
內外部表類型切換: 外部表屬性: 'EXTERNAL'='TRUE' 內部表屬性: 'EXTERNAL'='FALSE'
示例:
-- 三.表的查看/修改操作
-- 驗證之前的內外部表是否存在以及是否有數據,如果沒有自己創建,如果有直接使用
select * from inner_stu1 limit 1;
select * from outer_stu1 limit 1;
-- 1.表的查看操作
-- 查看所有的表
show tables;
-- 查看建表語句
show create table inner_stu1;
show create table outer_stu1;
-- 查看表基本機構
desc inner_stu1;
desc outer_stu1;
-- 查看表格式化詳細信息
desc formatted inner_stu1;
desc formatted outer_stu1;-- 2.表的修改操作
-- 修改表名
-- 注意: 外部表只會修改元數據表名,hdfs中表目錄名不會改變
alter table inner_stu1 rename to inner_stu;
alter table outer_stu1 rename to outer_stu;
-- 修改表中字段
-- 添加字段
alter table inner_stu add columns(age int);
alter table outer_stu add columns(age int);
-- 替換字段
alter table inner_stu replace columns(id int,name string);
alter table outer_stu replace columns(id int,name string);
-- 修改字段
alter table inner_stu change name sname varchar(100);
alter table outer_stu change name sname varchar(100);-- 修改表路徑(實際不建議修改)
-- 注意: 修改完路徑后,如果該路徑不存在,不會立刻創建,以后插入數據的時候自動生成目錄
alter table inner_stu set location '/inner_stu';
alter table outer_stu set location '/outer_stu';-- 修改表屬性
-- 先查看類型
desc formatted inner_stu; -- MANAGED_TABLE
desc formatted outer_stu; -- EXTERNAL_TABLE
-- 內部表改為外部表
alter table inner_stu set tblproperties ('EXTERNAL'='TRUE');
-- 外部表改為內部表
alter table outer_stu set tblproperties ('EXTERNAL'='FALSE');
-- 最后再查看類型
desc formatted inner_stu; -- EXTERNAL_TABLE
desc formatted outer_stu; -- MANAGED_TABLE
8、快速映射表
知識點:
創建表的時候指定分隔符: create [external] table 表名(字段名 字段類型)row format delimited fields terminated by 符號;加載數據: load data [local] inpath '結構化數據文件' into table 表名;
示例:
-- 創建表
create table products(id int,name string,price double,cid string
)row format delimited
fields terminated by ',';
-- 加載數據
-- 注意: 如果從hdfs中加載文件,本質就是移動文件到對應表路徑下
load data inpath '/source/products.txt' into table products;
-- 驗證數據
select * from products limit 1;
五、Hadoop(補充)
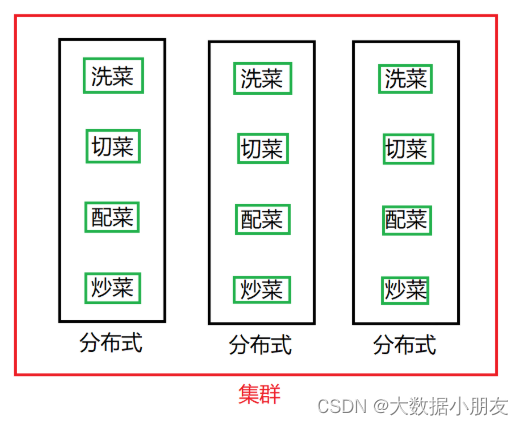
1、分布式和集群
分布式: 分布式的主要工作是分解任務,將職能拆解,多個人在一起做不同的事
集群: 集群主要是將同一個業務,部署在多個服務器上 ,多個人在一起做同樣的事
2、Hadoop框架
2.1 概述
Hadoop簡介:是Apache旗下的一個用Java語言實現開源軟件框架,是一個存儲和計算大規模數據的軟件平臺。
Hadoop起源: Doug Cutting 創建的,最早起源一個Nutch項目。
三駕馬車: 谷歌的三遍論文加速了hadoop的研發
Hadoop框架意義: 作為大數據解決方案,越來越多的企業將Hadoop 技術作為進入大數據領域的必備技術。狹義上來說:Hadoop指Apache這款開源框架,它的核心組件有:HDFS,MR,YANR
廣義上來說:Hadoop通常是指一個更廣泛的概念——Hadoop生態圈Hadoop發行版本: 分為開源社區版和商業版。
開源社區版:指由Apache軟件基金會維護的版本,是官方維護的版本體系,版本豐富,兼容性稍差。
商業版:指由第三方商業公司在社區版Hadoop基礎上進行了一些修改、整合以及各個服務組件兼容性測試而發行的版本,如: cloudera的CDH等。
2.2 版本更新
1.x版本系列: hadoop的第二代開源版本,該版本基本已被淘汰
hadoop組成: HDFS(存儲)和MapReduce(計算和資源調度)2.x版本系列: 架構產生重大變化,引入了Yarn平臺等許多新特性
hadoop組成: HDFS(存儲)和MapReduce(計算)和YARN(資源調度)3.x版本系列: 因為2版本的jdk1.7不更新,基于jdk1.8升級產生3版本
hadoop組成: HDFS(存儲)和MapReduce(計算)和YARN(資源調度)
2.3 Hadoop架構詳解(掌握)
簡單聊下hadoop架構?當前版本hadoop組成: HDFS , MapReduce ,YARNHDFS: 分布式文件存儲系統,Hadoop Distributed File System,負責海量數據存儲元數據: 描述數據的數據。你的簡歷就是元數據,你的人就是具體的數據NameNode: HDFS中的主節點(Master),主要負責管理集群中眾多的從節點以及元數據,不負責真正數據的存儲SecondaryNameNode: 主要負責輔助NameNode進行元數據的存儲。如果NameNode是CEO,那么SecondaryNameNode就是秘書。DataNode: 主要負責真正數據的存儲YARN: 作業調度和集群資源管理的組件。負責資源調度工作ResourceManager: 接收用戶的計算任務,并且負責給任務進行資源分配NodeManager: 負責執行主節點分配的任務,也就是給MapReduce計算程序提供資源現實生活例子: ResourceManager對應醫生,NodeManager拿藥的護士MapReduce: 分布式計算框架,負責對海量數據進行處理如何計算: 核心思想是分而治之,Map階段負責任務的拆解,Reduce階段負責數據的合并計算MR(MapReduce)程序: 可以使用Java/Python去調用方法/函數來實現具體的海量數據分析功能MapReduce計算需要的數據和產生的結果需要HDFS來進行存儲
MapReduce的運行需要由Yarn集群來提供資源調度。
2.4 官方示例(體驗下)
在Hadoop的安裝包中,官方提供了MapReduce程序的示例examples,以便快速上手體驗MapReduce。該示例是使用java語言編寫的,被打包成為了一個jar文件。官方示例jar路徑: /export/server/hadoop-3.3.0/share/hadoop/mapreduce
2.4.1 圓周率練習
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi x y
第一個參數pi:表示MapReduce程序執行圓周率計算;
第二個參數x:用于指定map階段運行的任務次數,并發度,舉例:x=10
第三個參數y:用于指定每個map任務取樣的個數,舉例: y=50
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50
...
Job Finished in 29.04 seconds
Estimated value of Pi is 3.16000000000000000000
2.4.2 詞頻統計
需求:
WordCount算是大數據統計分析領域的經典需求了,相當于編程語言的HelloWorld。統計文本數據中,
相同單詞出現的總次數。用SQL的角度來理解的話,相當于根據單詞進行group by分組,相同的單詞
分為一組,然后每個組內進行count聚合統計。
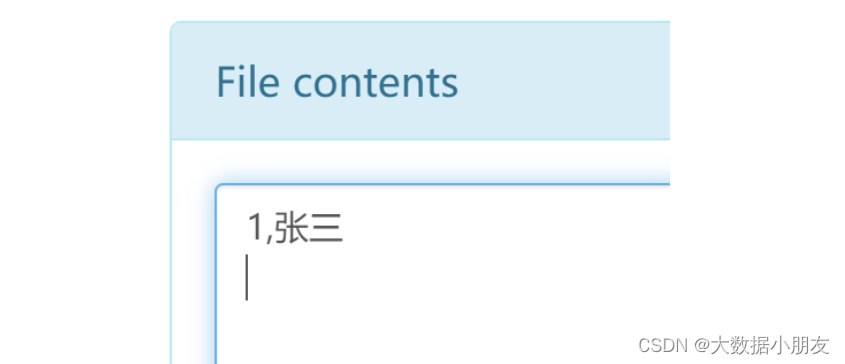
已知hdfs中word.txt文件內容如下,計算每個單詞出現的次數
步驟:
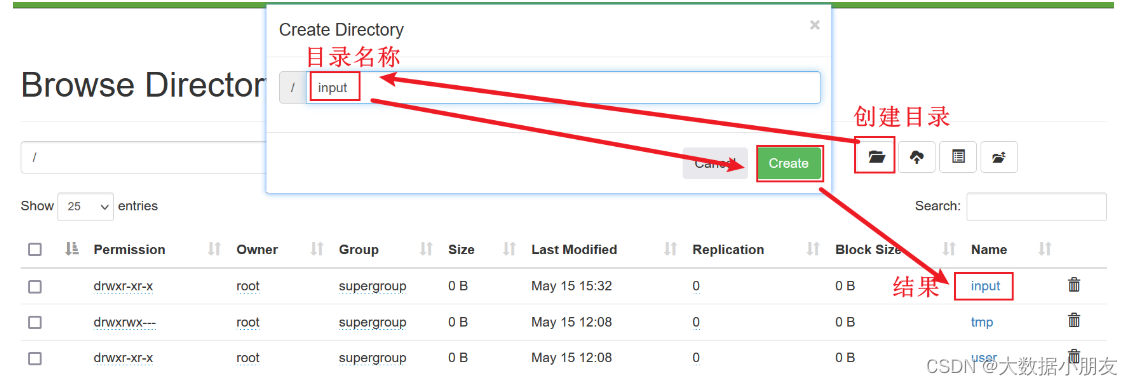
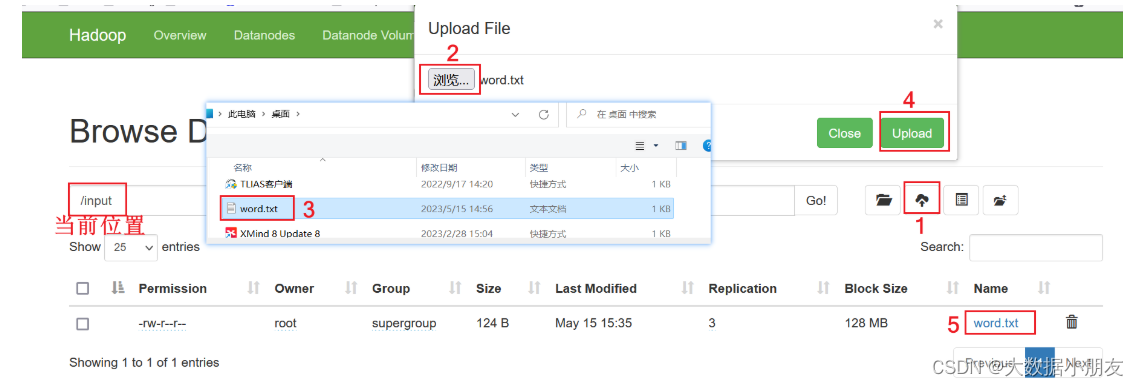
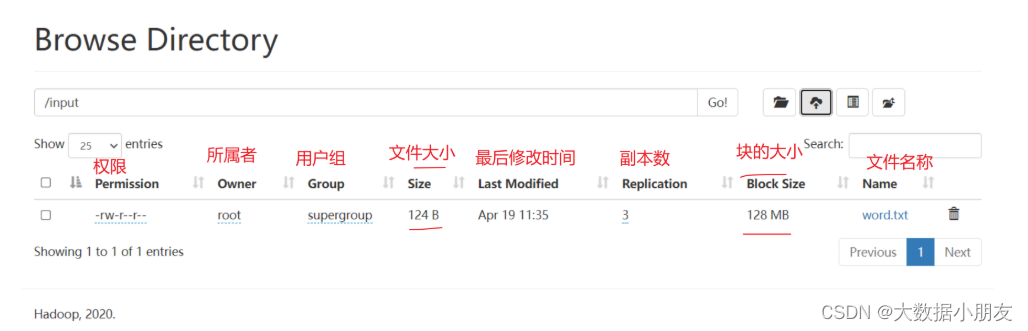
- 1.HDFS根目錄中創建input目錄,存儲word.txt文件
可以在window本地提前創建word.txt文件存儲,內容如下:
zhangsan lisi wangwu zhangsan
zhaoliu lisi wangwu zhaoliu
xiaohong xiaoming hanmeimei lilei
zhaoliu lilei hanmeimei lilei
- 2.在shell命令行中執行如下命令
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output注意: /input 和 /output間有空格
- 3.去HDFS中查看是否生成output目錄
注意: output輸出目錄,在執行第2步命令后會自動生成,如果提前手動創建或者已經存在,就會報以下錯誤:
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://node1.itcast.cn:8020/output already exists
- 4.進入output目錄查看part-r-00000文件,結果如下:
hanmeimei 2
lilei 3
lisi 2
wangwu 2
xiaohong 1
xiaoming 1
zhangsan 2
zhaoliu 3
3、Hadoop的HDFS(掌握)
3.1 特點
HDFS文件系統可存儲超大文件,時效性稍差。
HDFS具有硬件故障檢測和自動快速恢復功能。
HDFS為數據存儲提供很強的擴展能力。
HDFS存儲一般為一次寫入,多次讀取,只支持追加寫入,不支持隨機修改。
HDFS可在普通廉價的機器上運行。
文件存儲到HDFS上面可能會被進行切分,一個塊的大小最大是128MB。一個塊的副本數是3
3.2 架構
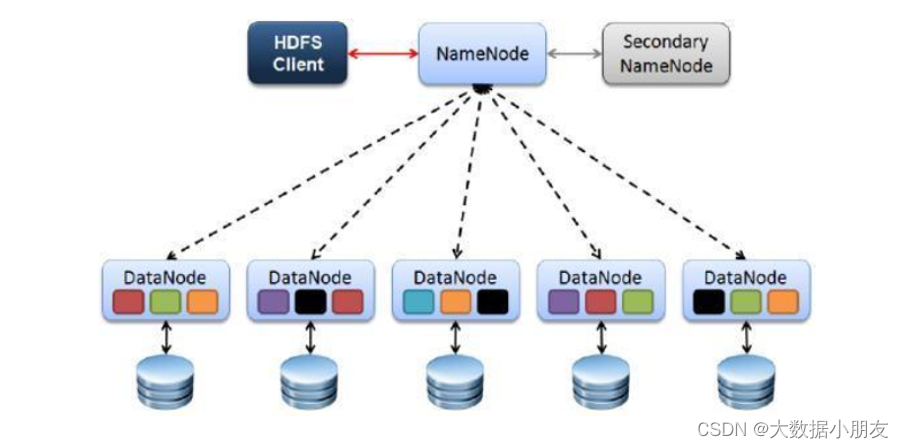
1- Client: 客戶端文件的上傳和下載是由客戶端發送請求給到NameNode還要負責文件的切分;文件上傳到HDFS的時候,客戶端需要將文件分成一個一個的block,然后進行存儲另外還提供了一些HDFS操作命令,用來操作和訪問HDFS2- NameNode就是Master主角色。它是一個管理者的角色處理客戶端發送過來的文件的上傳/下載請求管理HDFS元數據(文件路徑、文件大小、文件的名稱、文件的操作權限、文件被切分之后的block信息...)配置3副本的策略3- DataNode就是Slave從角色。NameNode下達命令,DataNode執行具體的實際的操作。是真正干活的存儲實際的數據塊block負責文件的讀寫請求定時向NameNode匯報block信息,心跳機制4- SecondaryNameNode并非 NameNode 的熱備。當NameNode 掛掉的時候,它并不能馬上替換 NameNode 并提供服務。輔助 NameNode,分擔其工作量。在緊急情況下,可輔助恢復 NameNode。
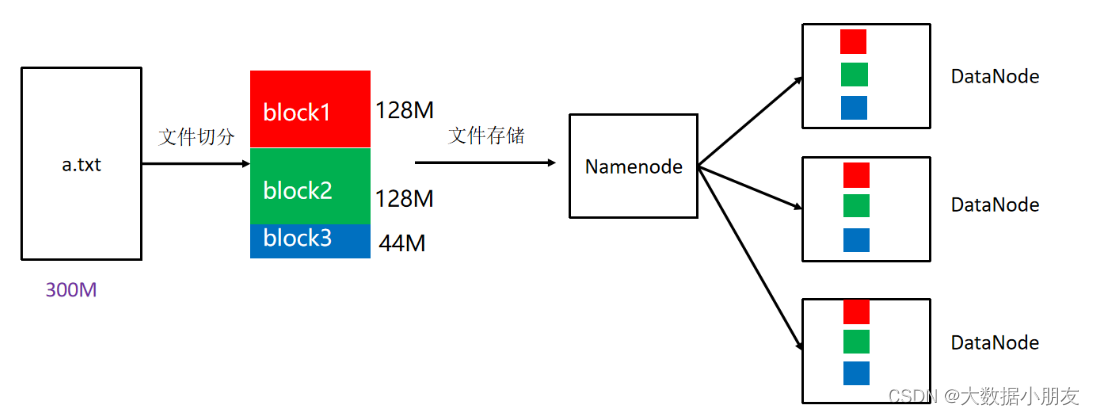
3.3 副本
block: HDFS被設計成能夠在一個大集群中跨機器可靠地存儲超大文件。它將每個文件存儲成一系列的數據塊,這個數據塊被稱為block,除了最后一個,所有的數據塊都是同樣大小的。block: 默認是128MB。副本數是3hdfs默認文件: https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml注意: 1- HDFS的相關配置,在企業中一般使用默認2- 但是這些參數也是可以調整。會根據數據的重要程度進行調整。如果數據的價值太低,可以調低副本數;如果數據的價值高,可以調高副本數
3.4 shell命令
***注意: 可以輸入hdfs dfs查看HDFS支持的shell命令有那些hdfs的shell命令概念: 安裝好hadoop環境之后,可以執行類似于Linux的shell命令對文件的操作,如ls、mkdir、rm等,對hdfs文件系統進行操作查看,創建,刪除等。hdfs的shell命令格式1: hadoop fs -命令 參數
hdfs的shell命令格式2: hdfs dfs -命令 參數hdfs的家目錄默認: /user/root 如果在使用命令操作的時候沒有加根目錄/,默認訪問的是此家目錄/user/root查看目錄下內容: hdfs dfs -ls 目錄的絕對路徑。注意沒有-l -a選項
創建目錄: hdfs dfs -mkdir 目錄的絕對路徑
創建文件: hdfs dfs -touch 文件的絕對路徑
移動目錄/文件: hdfs dfs -mv 要移動的目錄或者文件的絕對路徑 目標位置絕對路徑
復制目錄/文件: hdfs dfs -cp 要復制的目錄或者文件的絕對路徑 目標位置絕對路徑
刪除目錄/文件: hdfs dfs -rm [-r] 要刪除的目錄或者文件的絕對路徑
查看文件的內容: hdfs dfs -cat 要查看的文件的絕對路徑 注意: 除了cat還有head,tail也能查看
查看hdfs其他shell命令幫助: hdfs dfs --help
注意: hdfs有相對路徑,如果操作目錄或者文件的時候沒有以根目錄/開頭,就是相對路徑,默認操作的是/user/root把本地文件內容追加到hdfs指定文件中: hdfs dfs -appendToFile 本地文件路徑 hdfs文件絕對路徑注意: window中使用頁面可以完成window本地和hdfs的上傳下載,當然linux中使用命令也可以完成文件的上傳和下載
linux本地上傳文件到hdfs中: hdfs dfs -put linux本地要上傳的目錄或者文件路徑 hdfs中目標位置絕對路徑
hdfs中下載文件到liunx本地: hdfs dfs -get hdfs中要下載的目錄或者文件的絕對路徑 linux本地目標位置路徑
六、Hive環境準備(操作)
1、shell腳本執行方式
方式1: sh 腳本 注意: 需要進入腳本所在目錄,但腳本有沒有執行權限不影響執行
方式2: ./腳本 注意: 需要進入腳本所在目錄,且腳本必須有執行權限
方式3: /絕對路徑/腳本 注意: 不需要進入腳本所在目錄,但必須有執行權限
方式4: 腳本 注意: 需要配置環境變量(大白話就是把腳本所在路徑共享,任意位置都能直接訪問)
2、配置Hive環境變量
步驟:
注意:下面的步驟,全部在node1上面操作
- vim編輯/etc/profile文件
[root@node1 /]# vim /etc/profile
- 輸入i進入編輯模式,在/etc/profile文件末尾添加如下內容
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
export PATH= P A T H : PATH: PATH:HIVE_HOME/bin:$HIVE_HOME/sbin
vim小技巧:G快速定位到最后
- 保存退出,讓配置生效
[root@node1 /]# source /etc/profile
- 最后建議關機拍攝下快照
3、啟動和停止Hive服務
知識點:
后臺啟動metastore服務: nohup hive --service metastore &
后臺啟動hiveserver2服務: nohup hive --service hiveserver2 &
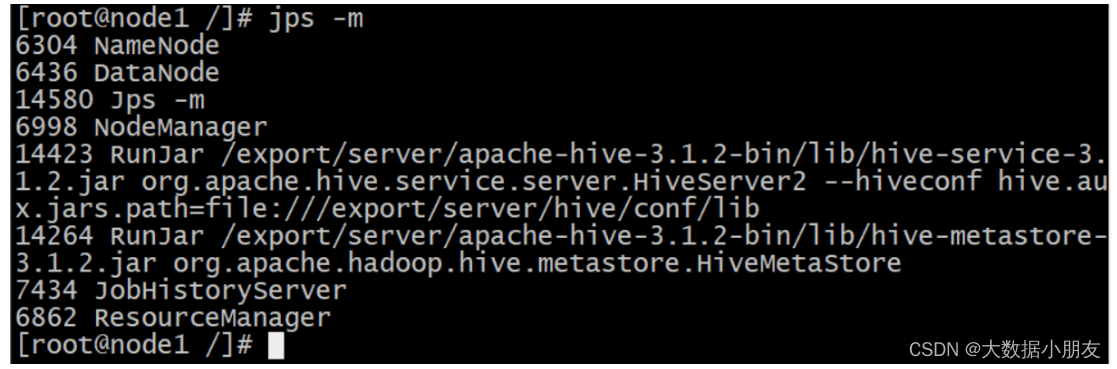
解釋:1- nohup: 程序運行的時候,不輸出日志到控制臺2- &: 讓程序后臺運行查看metastore和hiveserver2進程是否啟動: jps -m hiveserver2服務啟動需要一定時間可以使用lsof查看: lsof -i:10000
注意: hiveserver2服務可能需要幾十秒或者1分鐘左右才能夠成功啟動停止Hive服務: kill -9 進程ID
示例:
[root@node1 bin]# nohup hive --service metastore &
[1] 13490
nohup: 忽略輸入并把輸出追加到"nohup.out"
回車[root@node1 bin]# nohup hive --service hiveserver2 &
[2] 13632
nohup: 忽略輸入并把輸出追加到"nohup.out"
回車[root@node1 bin]# jps
...
13490 RunJar
13632 RunJar[root@node1 bin]#
# 注意:10000端口號一般需要等待3分鐘左右才會查詢到
[root@node1 bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 14423 root 522u IPv6 225303 0t0 TCP *:ndmp (LISTEN)
# 此處代表hive啟動成功,今日內容完成

4、連接Hive服務
知識點:
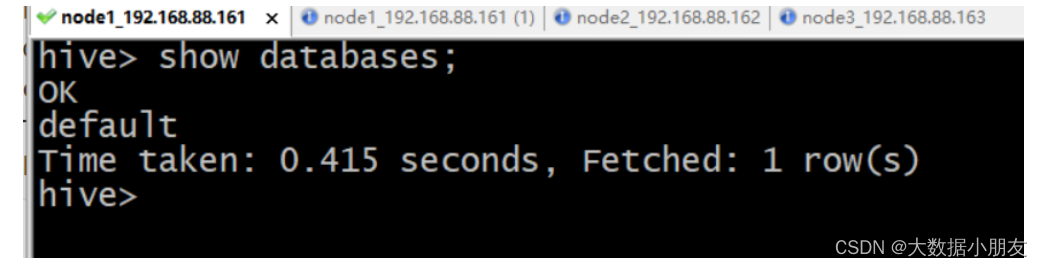
一代客戶端連接命令: hive
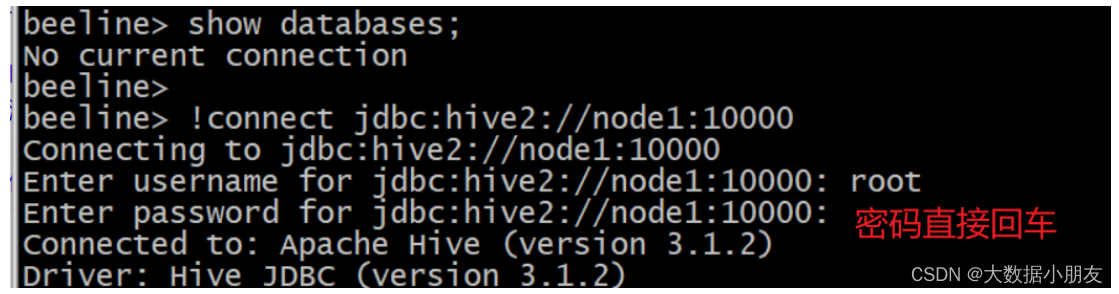
注意: hive直接連接成功,直接可以編寫sql語句二代客戶端連接命令: beeline
二代客戶端遠程連接命令:
注意:
一代客戶端示例:
[root@node1 /]# hive
...
hive> show databases;
OK
default
Time taken: 0.5 seconds, Fetched: 1 row(s)
hive> exit;
二代客戶端示例:
[root@node1 /]# beeline# 先輸入!connect jdbc:hive2://node1:10000連接
beeline> !connect jdbc:hive2://node1:10000# 再輸入用戶名root,密碼不用輸入直接回車即可
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:# 輸入show databases;查看表
0: jdbc:hive2://node1:10000> show databases;
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.2 seconds)
5、DataGrip連接Hive服務
5.1 創建DataGrip項目
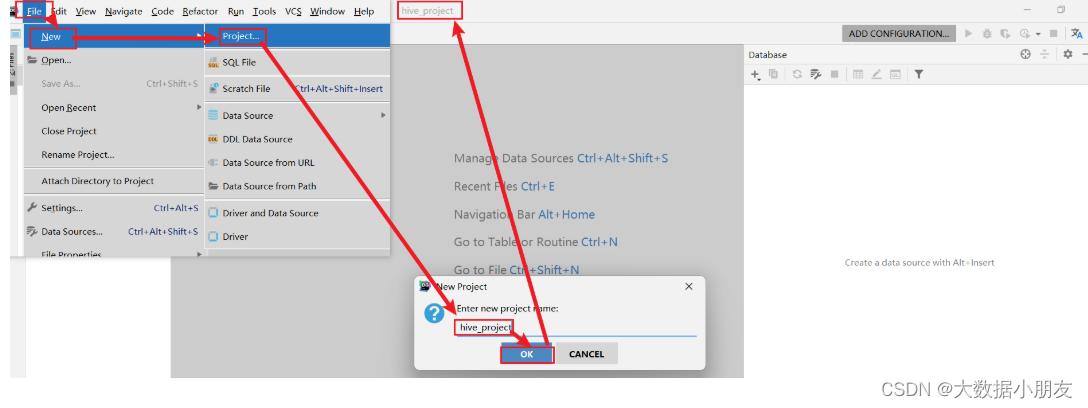
5.2 連接Hive
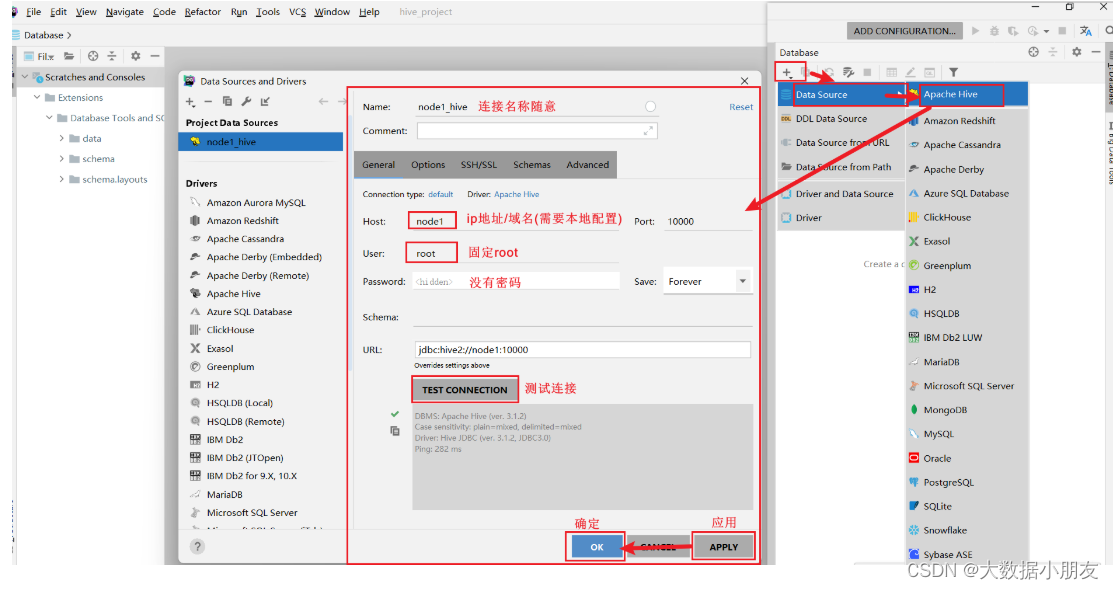
5.3 配置驅動jar包
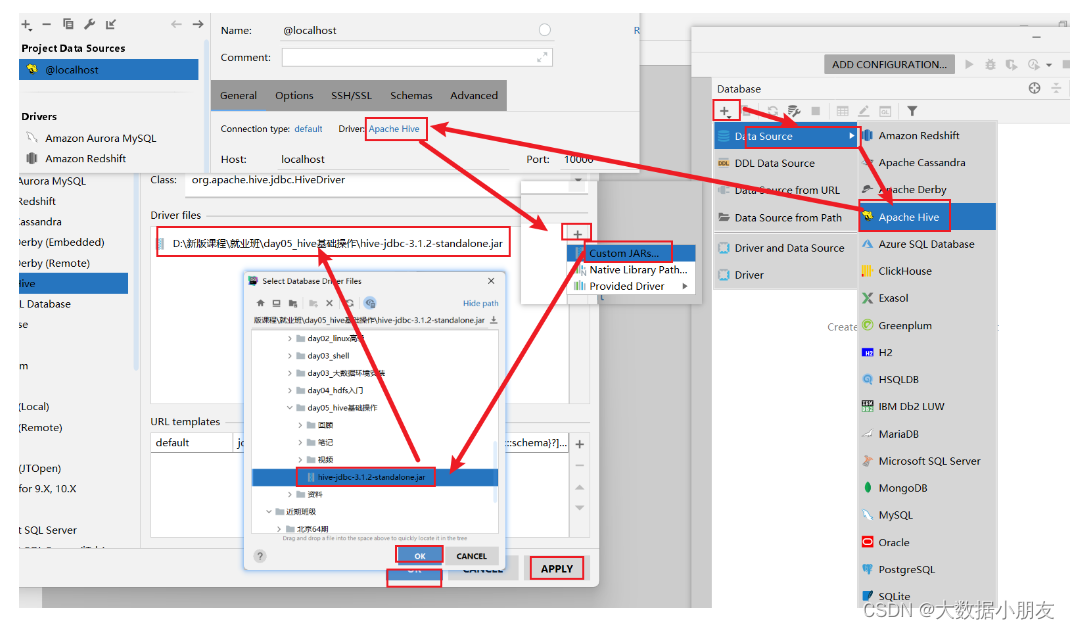
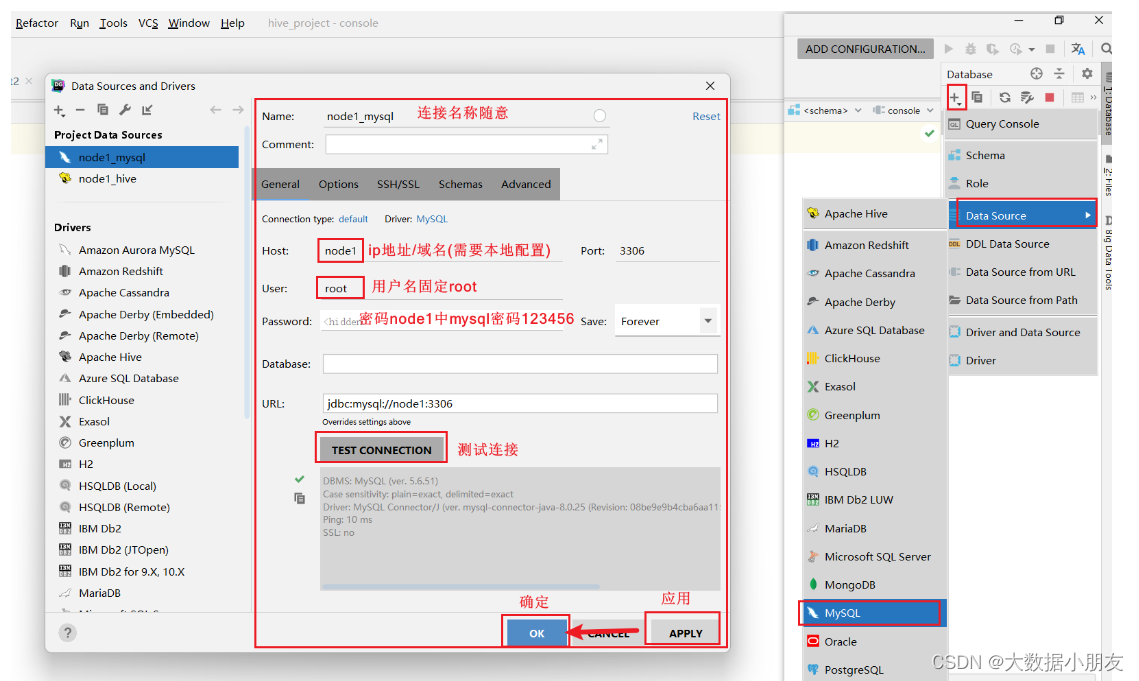
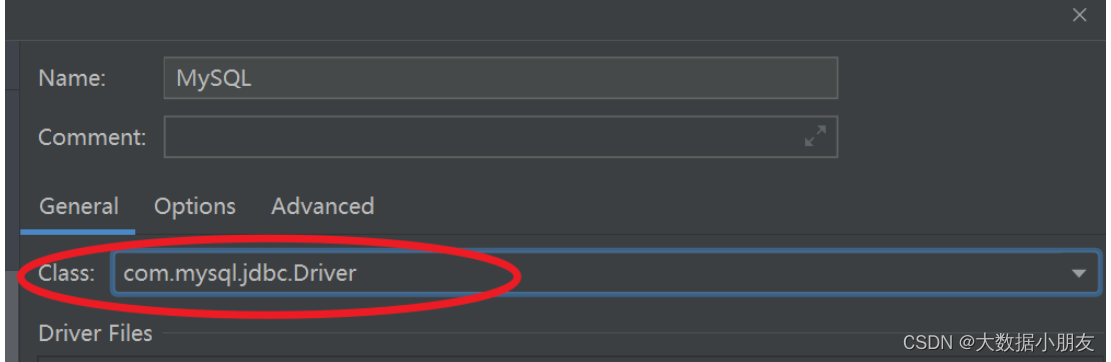
6、DataGrip連接MySQL
寫作不易,覺得可以的支持一下友友們,有建議的也多多指點一下





)








)

、鍵(k_proj)和值(v_proj)投影具體含義)


—— Linux常用命令)
