GraphRAG
最近幾天,微軟團隊開源了GraphRAG,這是一種基于圖(Graph)的檢索增強生成方法。
先說說RAG吧,檢索增強生成,相當于是從一個給定好的知識庫中進行檢索,接入LLM模型,讓模型生成準確且符合上下文的答案,減少幻覺,根據特定的知識庫進行符合知識庫內容的回答。如果和模型微調進行比較,通俗點來說,RAG是給模型一本《答案全解》讓它自己查,微調是給模型開輔導班補習。不過,傳統RAG有一些待解決的問題,比如推理能力不足,答案不完整,準確性不足等。
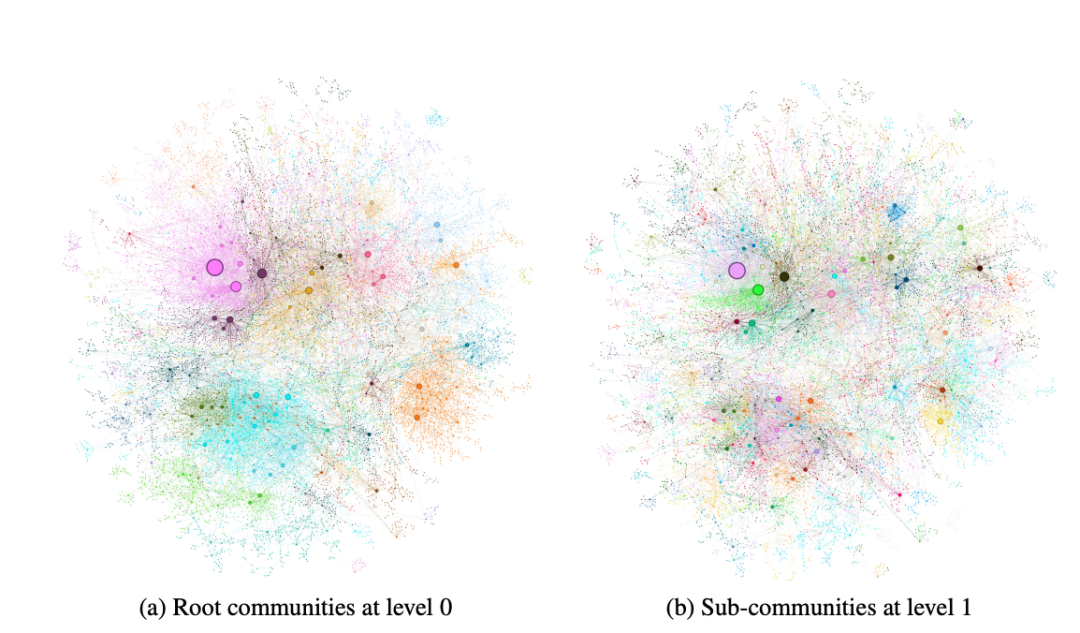
知識圖譜可視化示例
而 GraphRAG 的實現流程大致如下,首先將輸入文本轉化為文本塊,讓 LLM 提取知識圖譜,將知識圖譜聚類,基于關鍵詞實現子圖遍歷。
我們直接來看看 GraphRAG 的實戰測試吧。測試基于俄烏雙方關于暴力事件的上千份新聞報道,文件內容比較多,而且內容之間關系復雜,無法直接放入LLM的上下文中,RAG方法是此時的最優解。團隊首先測試了第一個問題:Novorossiya 是什么?

可以看到無論是 Baseline RAG 還是 GraphRAG 表現都很好,因為這種查詢確實是基線RAG擅長的部分,查就完了。
但如果把問題換成:Novorossiya 做了什么?

Baseline RAG 根本沒法給出答案,它的源文件中沒有任何東西提到這個關鍵詞。而 GraphRAG 讓 LLM 建立了知識圖譜,分析實體之間的關系,生成了很不錯的答案。GraphRAG 極大的提升了 RAG 的檢索能力,在捕獲上下文的這個過程中可以填充更多具有相關性的內容,從而讓生成的答案更具準確性。
不過有一個無法避免的問題:所有的性能改進技術,都會導致 token 的使用和推理的時間增加。但這并不影響 GraphRAG 的優秀,讓我們一起期待一下GraphRAG的進一步發展吧!
項目地址:
https://github.com/microsoft/graphrag
??——EOF——
福利:
后臺回復【酒店】可免費領取酒店管理系統源碼
視圖變換 正交投影 透視投影)
)









)


)
)
多線程)
)
)
