目錄
一. 前言
二. 被廣泛使用
三.?UUID 的結構
3.1.?必須了解的
3.2. 十六進制數字字符(hexDigit)
3.3.?UUID 基本結構
3.4.?類型(變體)和保留位
3.5.?版本(子類型)
3.6.?時間戳
3.7.?時鐘序列
3.8.?節點標志符
3.9. 小結
四.?UUID 的生成
4.1. V4
4.2. V1
4.3.?V3 和 V5
五.?獲取 UUID V4
5.1.?正則 + Math.random
5.2.?crypto.randomUUID
5.3.?URL.createObjectURL
六.?后起之秀 NanoID
一. 前言
? ? UUID(Universally Unique IDentifier)通用唯一識別碼 ,也稱為 GUID(Globally Unique IDentifier)全球唯一標識符。
? ? UUID 是一個長度為128位的標志符,能夠在時間和空間上確保其唯一性。UUID 最初應用于Apollo 網絡計算系統,隨后在 Open Software Foundation(OSF)的分布式計算環境(DCE)中得到應用。可以讓分布式系統可以不借助中心節點,就可以生成唯一標識, 比如唯一的 ID 進行日志記錄。
二. 被廣泛使用
被微軟 Windows 平臺采用。Windows 舉例2個使用場景:
1.?COM 組件通過 GUID 來定義類標識符(CLSID)、接口標識符(IID)以及其他重要的標識,確保在整個系統中不會發生命名沖突。
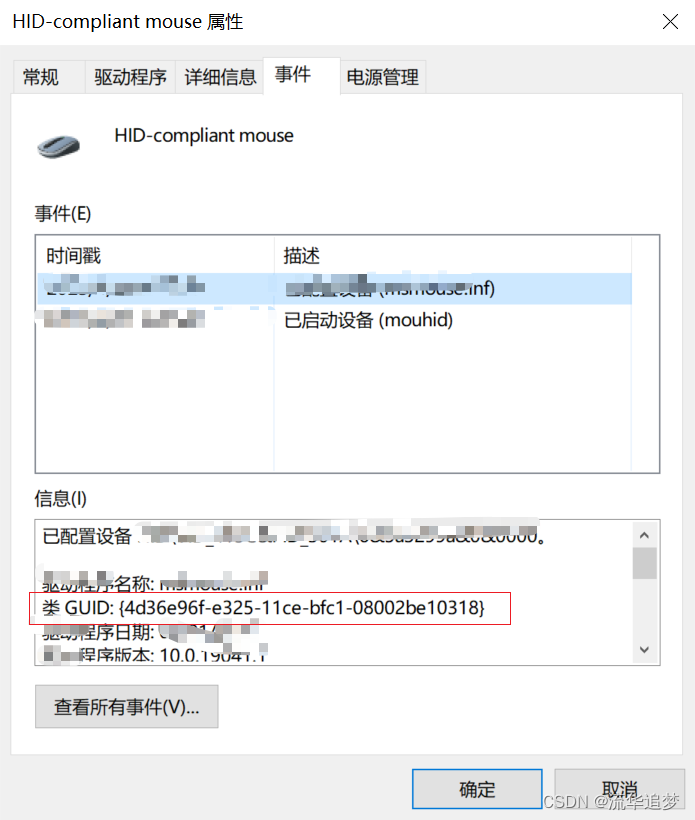
2.?Windows 注冊表中很多項都使用 GUID 作為子鍵名,以便為特定程序或功能提供一個全球唯一的注冊表路徑。

? ? UUID 之所以被廣泛采用,主要原因之一是它們的分配不需要中心管理機構介入。其具有唯一性和持久性,它們非常適合用作統一資源名稱(URN)。UUID 能夠無需注冊過程就能生成新的標識符的獨特優點,使得 UUID 成為創建成本最低的 URN 類型之一。
? ? 那么 UUID 會重復嘛,由于 UUID 具有固定的大小并包含時間字段,在特定算法下,隨著時間推移,理論上在大約公元3400年左右會出現值的循環,所以問題不大。
? ? 由于 UUID 是一個128位的長的標志符,為了便于閱讀和顯示,通常會將這個大整數轉換成32(不包含連接符)個十六進制字符組成的字符串形式。如下:
crypto.randomUUID()
// 4d93f326-3f48-4a43-929d-b6489f4754b5`${crypto.randomUUID()}`.length
// 長度:36`${crypto.randomUUID()}`.replace(/-/g, '').length
// 去掉連接符:32這128位的組成,以及是怎么變成32位的十六進制字符的,請繼續往下看。
三.?UUID 的結構
UUID 看似雜亂無章,其實內有乾坤。
3.1.?必須了解的
- 比特(bit):二進制數字系統中的基本單位。一個比特可以代表二進制中的一個0或1。
- 位(通常情況下與比特同義):二進制數系統中的一位,同樣表示0或1。
- 字節(Byte):字節是計算機中更常用的單位,用于衡量數據存儲容量和傳輸速率。1字節等于8個比特。
總結起來就是:
- 1 字節 = 8 位。
- 1 位 = 1 比特。
? ? 128位轉為32個十六進制字符, 這個十六進制字符是什么呢,其專業名字為hexDigit,是 UUID中我們肉眼可見的最小單元。
3.2. 十六進制數字字符(hexDigit)
? ? hexDigit , 十六進制數字字符,是一個長度為4比特,可以表示0(0b000)到15(0b1111)之間數值。其能轉為16進制的相對應符號,其取值范圍為 0-9、a-f、A-F,即0123456789abcdefABCDEF 中的某一個值。
? ? 所以, hexDigit 可以粗暴的理解為 0123456789abcdefABCDEF 中的某一個值。
(0b1000).toString(16) // 8(0b1111).toString(16) // F此外,還有一個 hexOctet, 兩個連續 hexDigit 組成的序列, 占8個比特,即一個字節。
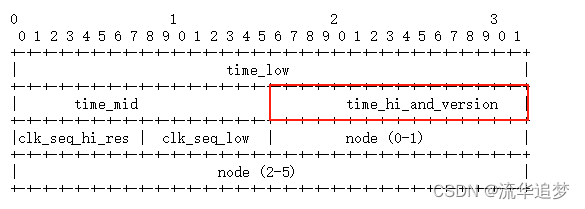
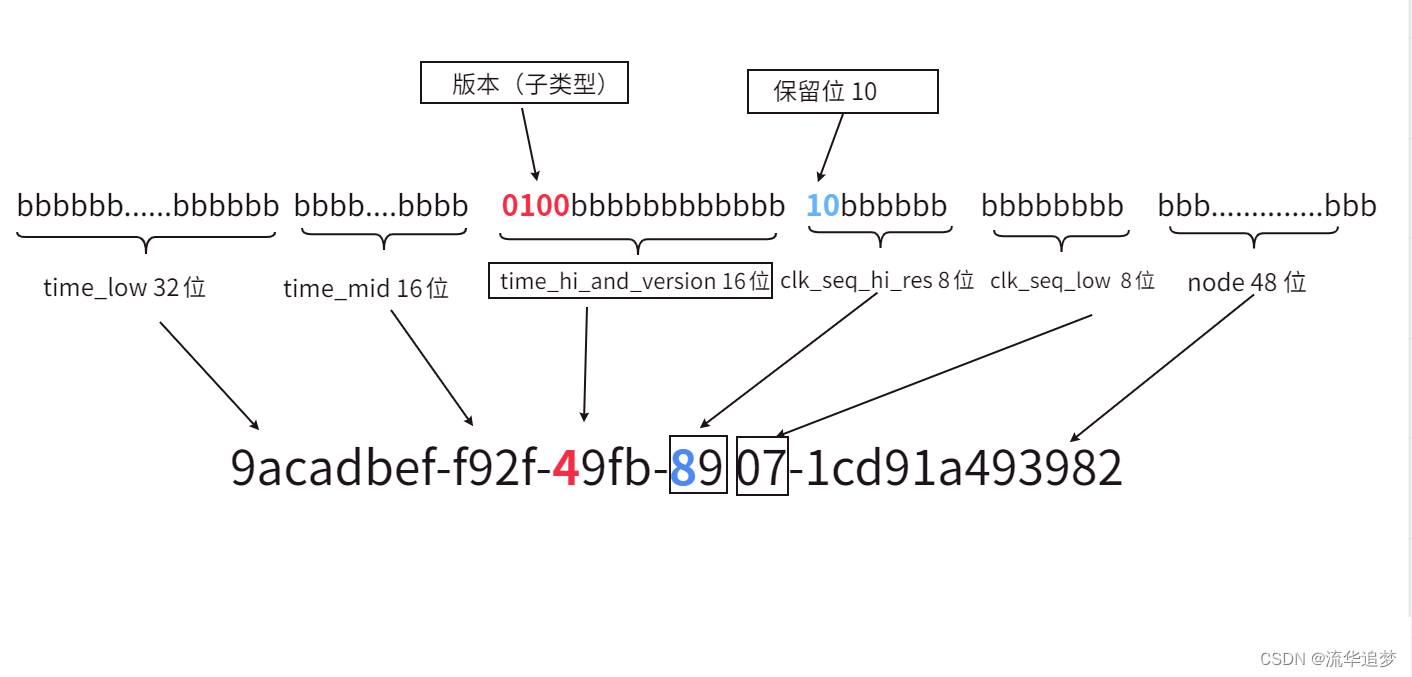
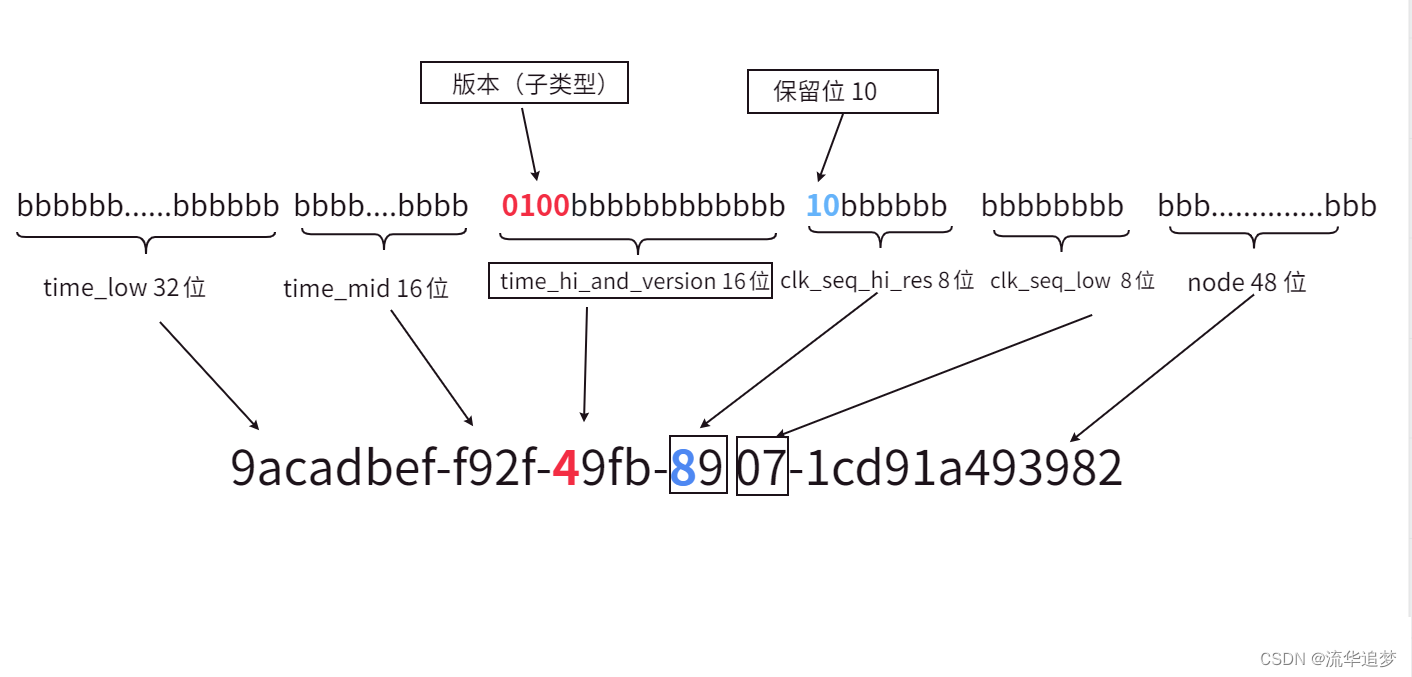
3.3.?UUID 基本結構
UUID 結構圖:
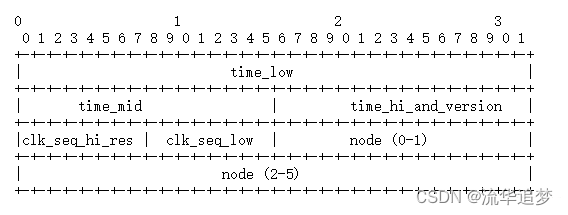
? ? 這個圖最上面的 0、1、2、3 不是表示位數,就是簡單的表示10位數的值,9 之后就是 10、 11、12等等。
? ? 如果不太好理解,換一張手工畫的圖(UUID 10類型的 V4 版本):
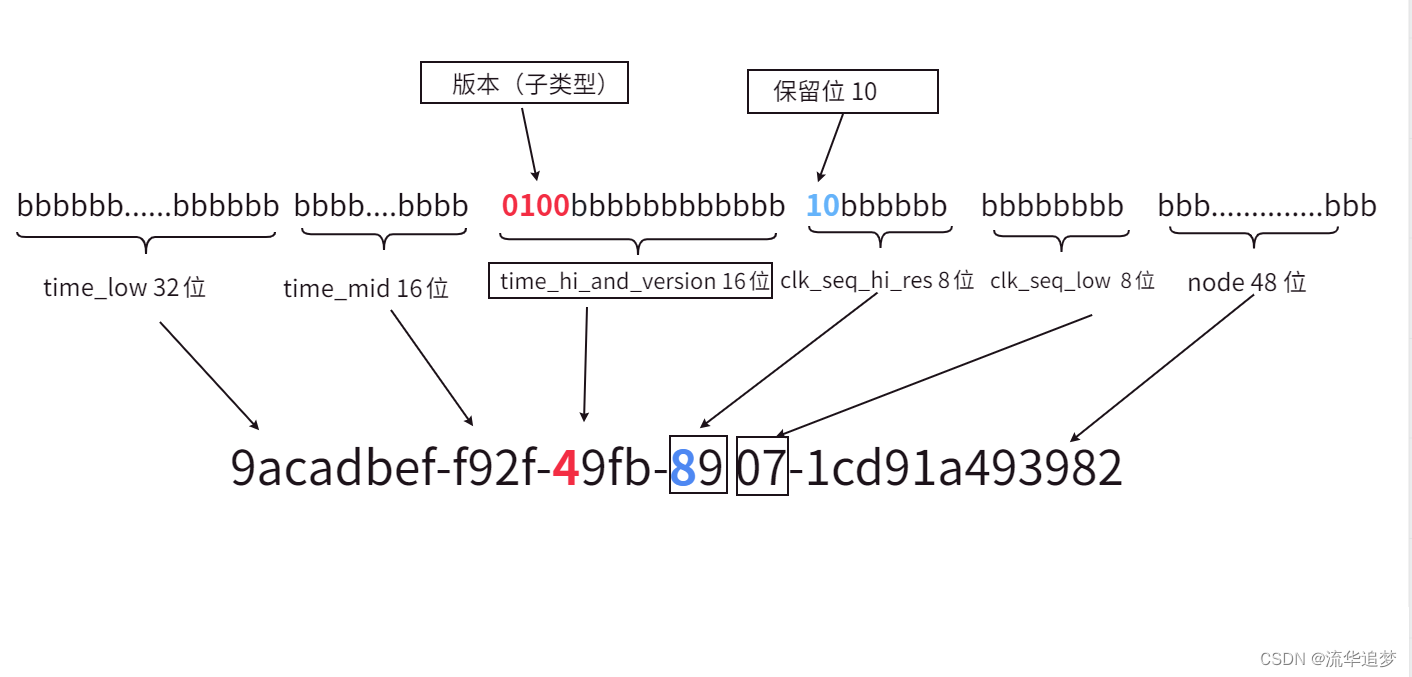
128 比特,16個字節即?16 hexOctet,就被如下瓜分了:
| 字段 | hexOctet(字節) | 位置 | 備注 |
|---|---|---|---|
| time_low | 4 | 0-3 | 時間戳?的低位部分 |
| time_mid | 2 | 4-5 | 時間戳的中間部分 |
| time_hi_and_version | 2 | 6-7 | 時間戳高位部分與?版本?字段,其中12位代表時間戳的高12位,4位則用來標識UUID的版本號 |
| clock_seq_hi_and_reserved | 1 | 8 | 時鐘序列?高位與?保留位 |
| clock_seq_low | 1 | 9 | 時鐘序列低位 |
| node | 6 | 10-15 | 節點標識符,提供空間唯一性,通常基于MAC地址或隨機數生成,以確保全局范圍內的唯一性 |
? ? 要想完整理解這個 6 部分組成,必然要理解備注中被加粗的幾個概念。保留位,版本, 時間戳, 時鐘序列 ,節點標志符。
3.4.?類型(變體)和保留位
? ? UUID 可以分為四種類型(變體),怎么識別是哪種類型(變體)呢,UUID 有對應的 Variant 字段去標記,可以參見協議的?4.1.1. Variant?部分。
? ? Variant 字段位于 UUID 的第8個字節即?clock_seq_hi_and_reserved?部分的第6-7位。
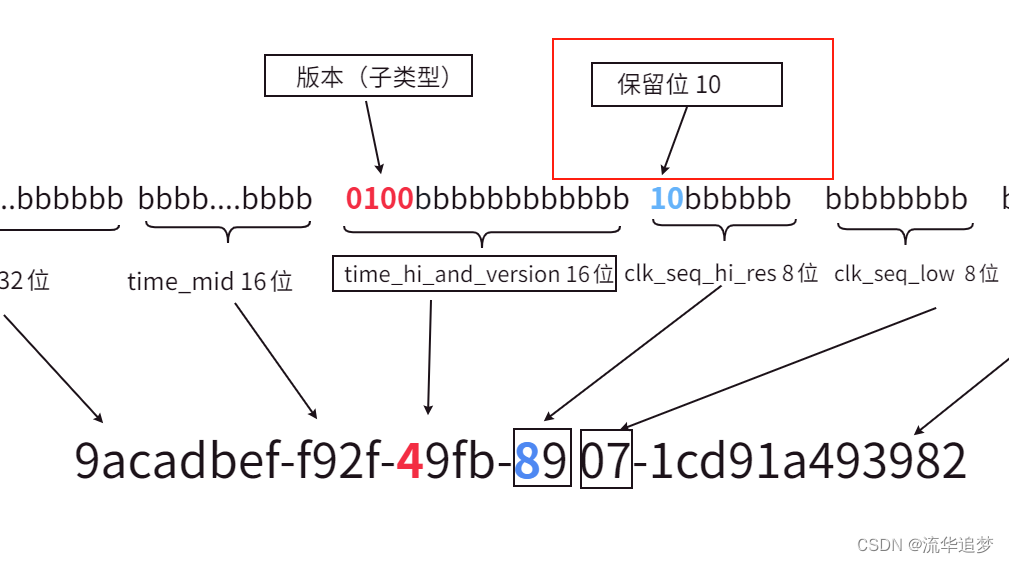
? ? 以外所有其他位的含義都是依據 Variant 字段中的比特位設置來解讀的。從這個意義上講,Variant 字段更準確地說可以被稱作類型字段;然而為了與歷史文檔兼容,仍沿用“Variant”這一術語。
下表列出了 Variant 字段可能的內容,其中字母“x”表示無關緊要或不關心的值:
- Msb0(最高有效位0):此為最高位。
- Msb1:次高位。
- Msb2:第三高位。
| Msb0 | Msb1 | Msb2 | 描述 |
|---|---|---|---|
| 0 | x | x | 保留,用于NCS(Network Computing System)向后兼容 |
| 1 | 0 | x | 此文檔中指定的variant變體 |
| 1 | 1 | 0 | 保留,用于微軟公司系統的向后兼容 |
| 1 | 1 | 1 | 保留供未來定義 |
? ? 類型(變體)的標志符可以是 2 位也可是 3 位,本文圍繞的的是?RFC4122: A Universally Unique IDentifier (UUID) URN Namespace?類型(變體), 即上面表格的第二行,其第三高位 為?x,表示該值并無意義,所以該版本只需要?10?即可。
? ? 10 開頭的 hexDigit 十六進制數字字符,其只有四個值:
0b1000 => 8
0b1001 => 9
0b1010 => a
0b1011 => b? ? 用簡單的圖示表示,就是 下面 y 的部分只會是這四個值 8、9、a、b 其中的某個值。xxxxxxxx-xxxx-xxxx-yxxx-xxxxxxxxxxxx。簡單測一測:
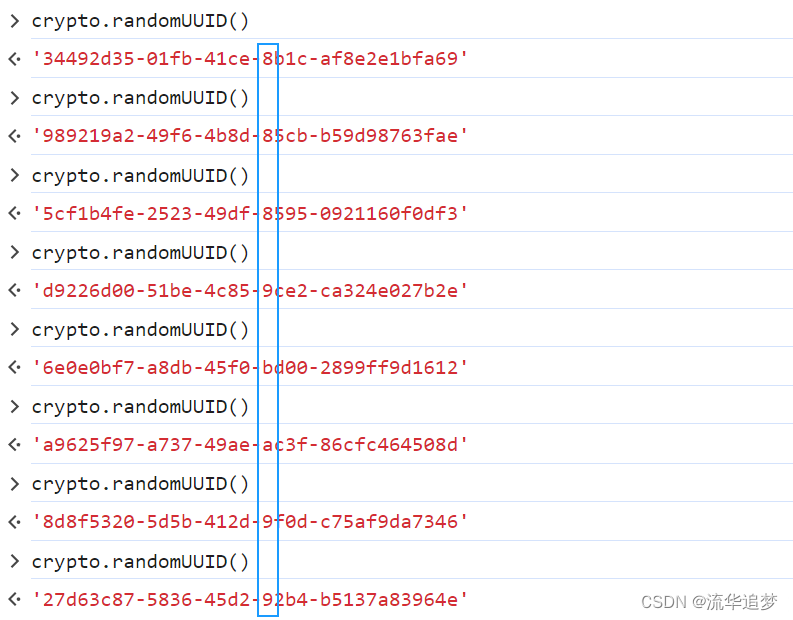
所以,一個?RFC4122?版本的 UUID 正宗不正宗,這么驗證也是一種手段。
3.5.?版本(子類型)
? ? 上面提到了 UUID 的類型(變體), 而這里版本,可以理解為某個類型(變體)下的不同子類型。 當然本文討論的是 變體10?即?RFC4122?下的版本(子類型)。 UUID 的類型(變體)有字段標記,當然這里的版本也有。即版本號 time_hi_and_version 的第12至15位:
V4 版本如下:

一共有5個版本:
| Msb0 | Msb1 | Msb2 | Msb3 | 版本號 | 描述 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 時間基版本。由時間戳、時鐘序列、節點標識符以及版本號和變體字段組成。 |
| 0 | 0 | 1 | 0 | 2 | 類似于版本1,但使用DCE安全標識代替MAC地址。 |
| 0 | 0 | 1 | 1 | 3 | 基于命名空間名稱和名字的MD5散列結果,加上版本號和變體字段。 |
| 0 | 1 | 0 | 0 | 4 | 完全基于隨機或偽隨機數據生成,不依賴于時間戳和硬件地址。 |
| 0 | 1 | 0 | 1 | 5 | 與版本3類似,但使用SHA-1算法替換MD5進行散列計算。 |
? ? 用簡單的圖示表示,就是下面 V 的部分只會是這五個值 1、2、3、4、5 其中的某個值。xxxxxxxx-xxxx-Vxxx-yxxx-xxxxxxxxxxxx。借用 uuid 庫演示一下:
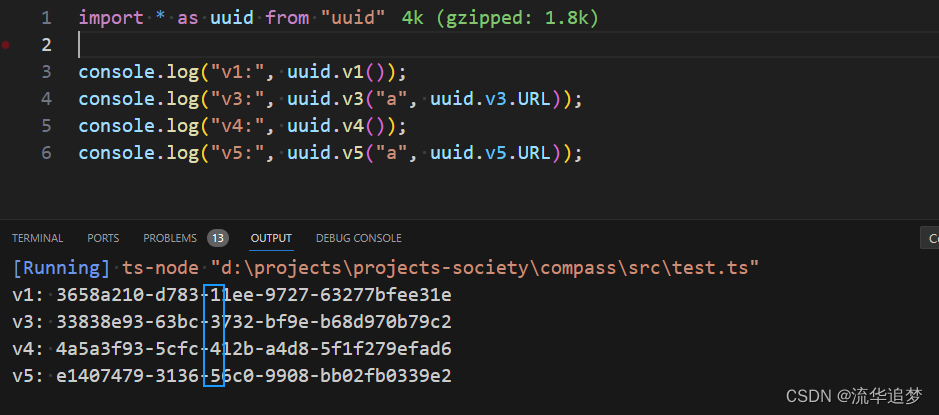
3.6.?時間戳
先回顧一下兩張圖:
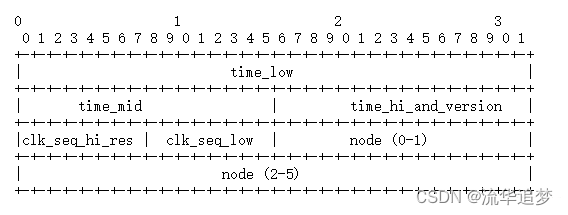

? ? 第一張是 UUID 各部分的組成,time_low ,time_mid, time_hi_and_version 包含了時間戳的不同部分。
? ? 第二張是 UUID 的五個版本,但是只有 V1 和 V2 提到了時間戳,也確實是這樣,除了 V1 和 V2版本真正用了時間戳,其余版本通過不同手段生成了數據填充了 time_low ,time_mid, time_hi_and_version 這三個部分。
? ? 那這個時間戳是開發者們常用的 Date.now() 這個時間戳嗎, 答案當然不是。
? ? 這里的時間戳是一個60位長度的數值。對于 UUID 版本1和2,它通過協調世界時(UTC)表示,即從1582年10月15日0點0分0秒開始算起的100納秒間隔計數。
? ? 比如 2024年1月1日0時0分0秒,這個值時間戳怎么算呢:
const startOfUuidEpoch = new Date('1582-10-15T00:00:00.000Z');
const uuidTimestampFromDate = (date) => {// 直接計算給定日期距離UUID紀元開始的毫秒數const msSinceUuidEpoch = date.getTime() - startOfUuidEpoch.getTime();// 將毫秒轉換為100納秒的整數倍, 1 毫秒=1000000 納秒const uuidTimestampIn100Ns = Math.floor(msSinceUuidEpoch * 10000); // 每毫秒乘以10,000得到100納秒return uuidTimestampIn100Ns;
};// 計算2024年1月1日對應的UUID V1版本時間戳
const targetDate = new Date('2024-01-01T00:00:00.000Z');
const uuidV1Timestamp = uuidTimestampFromDate(targetDate);
// 139233600000000000要保存為60位, 并劃分高位(12),中間(16),低位三部分(32)
uuidV1Timestamp.toString(2).padStart(60,'0')
// 000111101110101010000011100010110100110011001000000000000000time-high time-mid time-low
000111101110 1010100000111000 10110100110011001000000000000000? ? 在不具備 UTC 功能但擁有本地時間的系統中,只要在整個系統內保持一致,也可以使用本地時間替代 UTC。然而,這種方法并不推薦,因為僅需要一個時區偏移量即可從本地時間生成 UTC 時間。
? ? 對于 UUID 版本3或5,時間戳是一個根據?4.3 Algorithm for Creating a Name-Based UUID,由名稱構建的60位值,V3 和 V5 區別是在算法上。
? ? 而對于 UUID 版本4,時間戳則是一個隨機或偽隨機生成的60位值,具體細節參見第4.4 Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers
小結:
- 時間戳是即從1582年10月15日0點0分0秒開始算起的100納秒間隔計數,是一個60位值,被分為 高位,中間,低位三部分填充到UUID中。
- 只有 V1 和 V2? 真正意義上用了時間戳
- V3 和 V5 由名字構建而成的60位值
- V4 隨機或偽隨機生成的60位值。
3.7.?時鐘序列
? ? 時鐘序列(clock sequence)用于幫助避免因系統時間被設置回溯或節點 ID 發生變化時可能出現的重復標識符。
? ? 舉個實例,手動把系統的時間設置為一個過去的時間,那么就可能導致生成重復的 UUID。
? ? 協議考慮到了這點,就增加了時鐘序列,增加一個變數,讓結果不一樣,當然如果序列也是不變的,那么還是可能重復,所以這個時鐘序列也是會變化的。
? ? 如果系統時鐘被設置為向前的時間點之前,或者可能已經回溯(例如,在系統關機期間),并且UUID 生成器無法確定在此期間沒有生成時間戳更大的 UUID,則需要更改時鐘序列。若已知先前時鐘序列的值,可以直接遞增;否則應將其設置為一個隨機或高質量的偽隨機值。
? ? 同樣,當節點 ID 發生變化(比如因為網絡適配器在不同機器間移動),將時鐘序列設置為隨機數可以最大限度地降低由于各機器之間微小時間設置差異導致重復 UUID 的可能性。盡管理論上知道與變更后的節點 ID 關聯的時鐘序列值后可以直接遞增,但這種情況在實際操作中往往難以實現。
? ? 時鐘序列必須在其生命周期內首次初始化為隨機數,以減少跨系統間的關聯性。這提供了最大程度的保護,防止可能會快速在系統間遷移或切換的節點標識符產生問題。初始值不應與節點標識符相關聯。
? ? 同樣的,這個時間序列只在 V1 和 V2 是真的按照上面的規則或者約定來執行的。
? ? 對于 UUID 版本3或5,時鐘序列是一個由第?4.3 Algorithm for Creating a Name-Based UUID?節描述的名稱構建的14位值。
? ? 而對于 UUID 版本4,時鐘序列則是一個如第4.4 Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers?節所述隨機或偽隨機生成的14位值。
3.8.?節點標志符
? ? 空間唯一節點標識符,用來確保即便在同一時間生成的 UUID 也能在特定網絡或物理位置上保持唯一性。
? ? 對于 UUID V1,這個節點標識符通常基于網絡適配器的 MAC 地址或者在沒有硬件 MAC 地址可用時由系統自動生成一個偽隨機數。它的目的是反映生成 UUID 的設備在網絡或物理空間中的唯一性,即使在相同的時序和時鐘序列條件下,不同的設備也會因為其獨特的節點標識符而產生不同的UUID。
? ? 在 UUID V2 中,雖然不常用,但節點標識符的概念同樣適用,用于標識系統的唯一性,只不過這里的“空間”更多地指向組織結構或其他邏輯意義上的空間劃分。
? ? 總之,空間唯一節點標識符是為了保證在分布式系統環境下,即使時間戳相同的情況下也能生成唯一的 UUID,以區分不同物理節點上的事件或資源。
? ? 對于 UUID 版本3或5: 節點字段(48位)是根據第4.3節描述的方法,從一個名稱構造而來。
? ? 對于 UUID 版本4: 節點字段(同樣是48位)是一個隨機或偽隨機生成的值。
3.9. 小結
從 V1 和 V2 版本來看, UUID 最后是想通過時間和空間上兩層手段保證其唯一性:
- 時間: 時間戳 + 時鐘時序。
- 空間: 節點標志符(比如 MAC 地址)。
同時考慮了類型(變體)和版本(子類型),即下面這些組信息組成了 UUID:
- 時間戳
- 時鐘序列
- 節點標志符
- 保留位:即類型(變體)信息
- 版本:V1 到 V5。
? ? 因為保留位和版本信息本身是固定的,是可以從最后的32位16進制字符是可以直接或者間接看到的。再回顧這張圖,是不是比較清晰了:
四.?UUID 的生成
協議中有具體描述 V1、V3 和 V5 以及 V4 的基本流程或者約束。
4.1. V4
? ? 瀏覽器和 nodejs 內置的了 V4 的生成函數, 而且其生成規則相對簡單。對應著協議?4.4. Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers。
? ? 版本4的 UUID 旨在通過真正的隨機數或偽隨機數生成 UUID。其生成算法相對簡單,主要依賴于隨機性。
生成算法步驟如下:
- 在 UUID 結構中的 clock_seq_hi_and_reserved 部分,將最高兩位有效位(即第6位和第7位)分別設置為0和1。
- 在 UUID 結構中的 time_hi_and_version 字段,將最高四位有效位(即第12位至第15位)設置為來自第 4.1.3節 的4位版本號,對于版本4 UUID,這個版本號是固定的0100。
- 將除了以上已設定的位之外的所有其他位設置為隨機(或偽隨機)選取的值。
不好理解,就看這張圖:
? ? 關于隨機性安全要求, 引用了?BCP 106?標準文檔,即?RFC 4086。RFC 4086 是一份由 IETF 制定的最佳當前實踐(Best Current Practice, BCP)文檔,其標題為“Security Requirements for Randomness”,該文檔詳細闡述了在實現安全協議與系統時所需的隨機數生成器的要求和特性,確保生成的隨機數具有足夠的不可預測性和熵,能滿足各類安全應用,包括但不限于密碼學應用中的隨機性需求。
? ? 總之,生成版本4 UUID的過程中,首先對特定字段的幾位進行固定設置以標明版本和時鐘序列特征,然后其余所有位均通過隨機或偽隨機過程填充數值,以此確保生成的 UUID 具備全球唯一性和較強的隨機性。
4.2. V1
對應這協議?4.2.2. Generation Details,按照以下步驟生成的:
- 確定時間戳和時鐘序列:遵循第 4.2.1 節描述的方法,獲取基于 UTC 的時間戳以及用于 UUID 的時鐘序列。
- 處理時間戳和時鐘序列:將時間戳視為一個 60 位無符號整數,時鐘序列視為一個 14 位無符號整數,并按順序編號每個字段中的位,最低有效位從0開始計數。
- 設置時間低位字段(time_low field):將其設置為時間戳的最低有效 32 位(位 0 到 31),保持相同的位權重順序。
- 設置時間中間字段(time_mid field):將其設置為時間戳中的位 32 到 47,同樣保持位權重順序一致。
- 設置時間高位及版本字段(time_hi_and_version field)的低 12 位(位 0 到 11):將其設置為時間戳的位 48 到 59,保持位權重順序一致。
- 設置時間高位及版本字段的高 4 位:將這 4 位(位 12 到 15)設置為對應于所創建 UUID 版本的 4 位版本號。
- 設置時鐘序列低位字段(clock_seq_low field):將其設置為時鐘序列的最低有效 8 位(位 0 到 7),同樣保持位權重順序一致。
- 設置時鐘序列高位及保留字段的低 6 位(clock_seq_hi_and_reserved field 的位 0 到 5):將其設置為時鐘序列的最高有效 6 位(位 8 到 13),保持相同位權重順序。
- 設置時鐘序列高位及保留字段的高 2 位:將這 2 位(位 6 和 7)分別設置為 0 和 1,以滿足版本 1 UUID 的標準格式要求。
- 設置節點字段(node field):將其設置為 48 位的 IEEE MAC 地址,地址中的每一位都保持原有的位權重順序。
4.3.?V3 和 V5
? ? 對應協議的?4.3. Algorithm for Creating a Name-Based UUID。
? ? 版本3或5的 UUID 設計用于從特定命名空間(name space)內的且在該命名空間內唯一的名字(names)生成UUID。這里的名字(names)和命名空間(name space)的概念應該廣泛理解,不僅限于文本名稱。例如,一些命名空間包括域名系統(DNS)、統一資源定位符(URLs)、ISO 對象標識符(OIDs)、X.500區別名(DNs)以及編程語言中的保留字等。在這些命名空間內分配名稱和確保其唯一性的具體機制或規則不在本規范的討論范圍內。
對于這類 UUID 的要求如下:
- 在同一命名空間內,使用相同名稱在不同時間生成的 UUID 必須完全相同。
- 在同一命名空間內,使用兩個不同名稱生成的 UUID 應當是不同的(概率極高)。
- 在兩個不同命名空間內,使用相同名稱生成的 UUID 也應當是不同的(概率極高)。
- 如果兩個由名稱生成的 UUID 相同,則它們幾乎肯定是由同一命名空間內的相同名稱生成的。
生成基于名稱和命名空間的 UUID 的具體算法步驟如下:
- 為給定命名空間內所有由名稱生成的UUID分配一個作為“命名空間ID”的UUID;參見附錄C中預定義的一些值。
- 選擇MD5 [4] 或SHA-1 [8] 其中的一種哈希算法;如果不考慮向后兼容性,建議優先使用SHA-1。
- 將名稱轉換為其命名空間規定的標準化字節序列形式,并將命名空間ID以網絡字節序排列。
- 計算命名空間ID與名稱連接后的哈希值。
- 將哈希值的前四個八位組(octets 0-3)賦給時間低位字段(time_low field)的前四個八位組。
- 將哈希值的第五和第六個八位組賦給時間中間字段(time_mid field)的前兩個八位組。
- 將哈希值的第七和第八個八位組賦給時間高位及版本字段(time_hi_and_version field)的前兩個八位組。
- 將時間高位及版本字段的四位最顯著位(bit 12 至 15)設置為第4.1.3節中指定的相應4位版本號。
- 將哈希值的第八個八位組賦給時鐘序列高位及保留字段(clock_seq_hi_and_reserved field)。
- 將時鐘序列高位及保留字段的兩位最顯著位(bit 6 和 7)分別設置為0和1。
- 將哈希值的第九個八位組賦給時鐘序列低位字段(clock_seq_low field)。
- 將哈希值的第十至第十五個八位組賦給節點字段(node field)的前六個八位組。
- 最后,將生成的UUID轉換成本地字節序。
五.?獲取 UUID V4
? ? 這里只介紹 V4 版本,因為 V4 是基于隨機或者偽隨機來實現的,只要保證保留位和版本號的固定,其他的隨機生成就好。
5.1.?正則 + Math.random
利用 Math.random() 方法生成隨機數。
function uuidv4() {return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {var r = (Math.random() * 16 | 0), v = c == 'x' ? r : (r & 0b0011 | 0b1000);return v.toString(16);});
}? ? 先固定好格式,執行 replace,整體代碼不難,唯一需要提一下的是 (r & 0b0011 | 0b1000) 操作,這里的作用就是設置保留位的值10。
r & 0b0011 // 高位,即2,3位 變為 00
r & 0b0011 | 0b1000 // 高位,即2,3位 變為 10? ? 舉個例子, 用9為例,其二進制 0b1001 &
0b1001 & 0b0011 => 0b0011
0b0011 | 0b1000 => 0b10115.2.?crypto.randomUUID
? ? 現代瀏覽器也內置?Crypto: randomUUID() method?, nodejs 15.6.0 版本以上就內置了crypto.randomUUID([options])
crypto.randomUUID()
// 4d93f326-3f48-4a43-929d-b6489f4754b55.3.?URL.createObjectURL
function uuid() { const url = URL.createObjectURL(new Blob([])); // const uuid = url.split("/").pop(); const uid = url.substring(url.lastIndexOf('/')+ 1); URL.revokeObjectURL(url); return uid;
}uuid()
// blob:http://localhost:3000/ff46f828-1570-4cc9-87af-3d600db71304上面方式產生的都是 v4 版本,如果 v4 版本滿足需求,就沒有必要去引入第三方庫了。
六.?后起之秀 NanoID
? ? Nano ID 是一個精巧高效的 JavaScript 庫,用于生成短小、唯一且適合放在 URL 中的標識符字符串。這個工具提供了幾個關鍵特性:
- 體積小巧:Nano ID 的最小化和壓縮版本非常緊湊,大小僅為 116 字節。
- 安全性:該庫使用硬件隨機數生成器來確保生成的 ID 具有高安全性,可以在集群環境中安全使用。
- 短小 ID:相較于 UUID(通常包含 A-Z、a-z、0-9 以及 - 符號,共 36 個字符),Nano ID 使用了更大的字符集(包括 A-Za-z0-9_-),從而將 ID 的長度從 36 個符號減少到了 21 個,更便于在有限空間中使用。
- 可移植性:Nano ID 已被移植到超過 20 種編程語言中,具有良好的跨平臺適用性。
Nano ID 和 UUID(Universally Unique Identifier)都是用于生成唯一標識符的機制,但它們之間存在一些關鍵差異:
-
長度與格式:
- UUID:標準 UUID 由32個十六進制數字組成,分為5組,每組之間用短橫線
-分隔,例如?xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx,總長度為36個字符(包括連字符)。 - Nano ID:Nano ID 可配置長度,但默認生成的是較短的字符串,通常包含21個字符,并且可以自定義字符集(默認為?
A-Za-z0-9_-)。
- UUID:標準 UUID 由32個十六進制數字組成,分為5組,每組之間用短橫線
-
唯一性保證:
- UUID:基于時間戳、MAC 地址(對于v1 UUID)、隨機數(對于v4 UUID)等多種因素生成,理論上全球范圍內幾乎不可能重復。
- Nano ID:雖然也致力于生成唯一的 ID,但由于其較短的長度,在沒有額外存儲或算法保證的情況下,唯一性風險相對較大。不過,通過增大字符集和適當增加 ID 長度,Nano ID 也能實現很高的唯一性概率。
-
應用場景:
- UUID:廣泛應用于數據庫鍵、資源標識符、網絡協議等需要全局唯一性的場景,尤其在網絡間不同系統間的交互中常見。
- Nano ID:更適合于對 ID 長度要求嚴格的場合,如 URL 友好、前端顯示或者存儲空間有限的情況。
-
性能與存儲成本:
- UUID:由于較長的字符串長度,存儲和傳輸時可能會占用更多空間。
- Nano ID:因其短小,Nano ID 在存儲和帶寬消耗上更有優勢。
-
安全性:
- UUID v4 是基于強隨機性生成的,因此安全性較高,不易被預測。
- Nano ID 也可以使用安全的隨機源生成,同樣能夠達到較高的安全性,但在默認設置下,考慮到生成長度和字符集的選擇,如果不在生成邏輯上做特殊處理以增加熵,其安全性可能不及 UUID。
? ? 綜上所述,選擇 Nano ID 還是 UUID 取決于具體的應用需求,如果重視存儲效率和簡潔性,同時能接受合理的唯一性保證策略,則 Nano ID 可能更為合適;而在需要絕對唯一性和不考慮存儲效率的場景下,UUID 往往是更好的選擇。

![[激光原理與應用-101]:南京科耐激光-激光焊接-焊中檢測-智能制程監測系統IPM介紹 - 5 - 3C行業應用 - 電子布局類型](http://pic.xiahunao.cn/[激光原理與應用-101]:南京科耐激光-激光焊接-焊中檢測-智能制程監測系統IPM介紹 - 5 - 3C行業應用 - 電子布局類型)

















