文章目錄
- 藝術地掌控人物形象
- 好易智算
- 原因分析
- 為什么在使用Stable Diffusion生成全身圖像時,臉部細節往往不夠精細?
- 解決策略
- 局部重繪
- 采樣器
- 總結
藝術地掌控人物形象
在運用Stable Diffusion這一功能強大的AI繪圖工具時,我們往往會發現自己對提示詞的使用還不夠充分。在這種情形下,我們應當如何調整自己的策略,以便更加精確、全面地塑造出理想的人物形象呢?
舉例來說,假設我們輸入的是:
a girl in dress walks down a country road,vision,front view,audience oriented,

圖片效果總是不盡人意

我們批量四個之后,除去背對的圖片,我們可以看到其余三個的面部非常的奇怪

該如何快速處理呢?
好易智算
首先,我們可以通過好易智算平臺迅速啟動。在好易智算的平臺上,它整合了多個AI應用程序——應用即達,AI輕啟。這樣的便捷性使得訪問和使用這些先進技術變得前所未有地簡單快捷。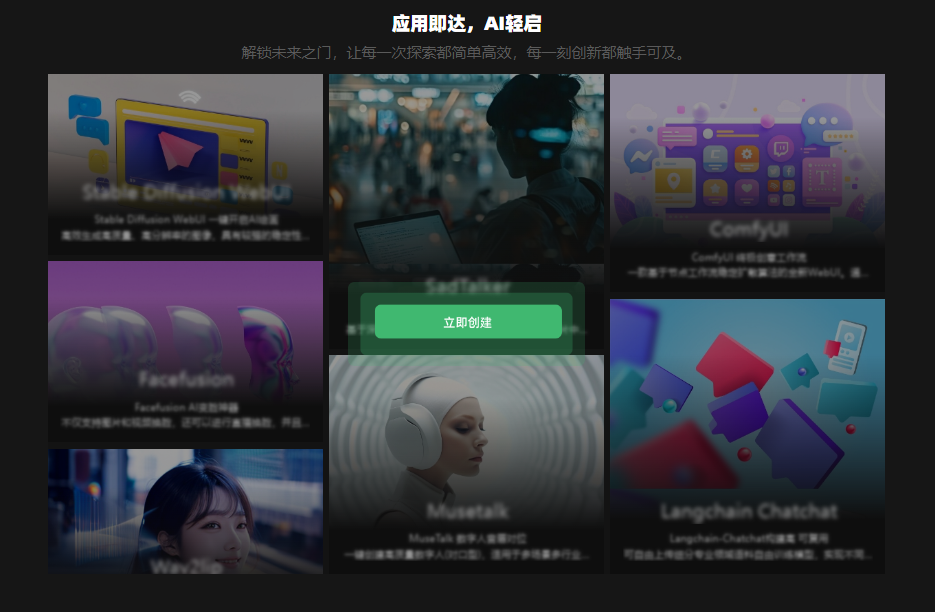
我們這里選擇Stable Diffusion
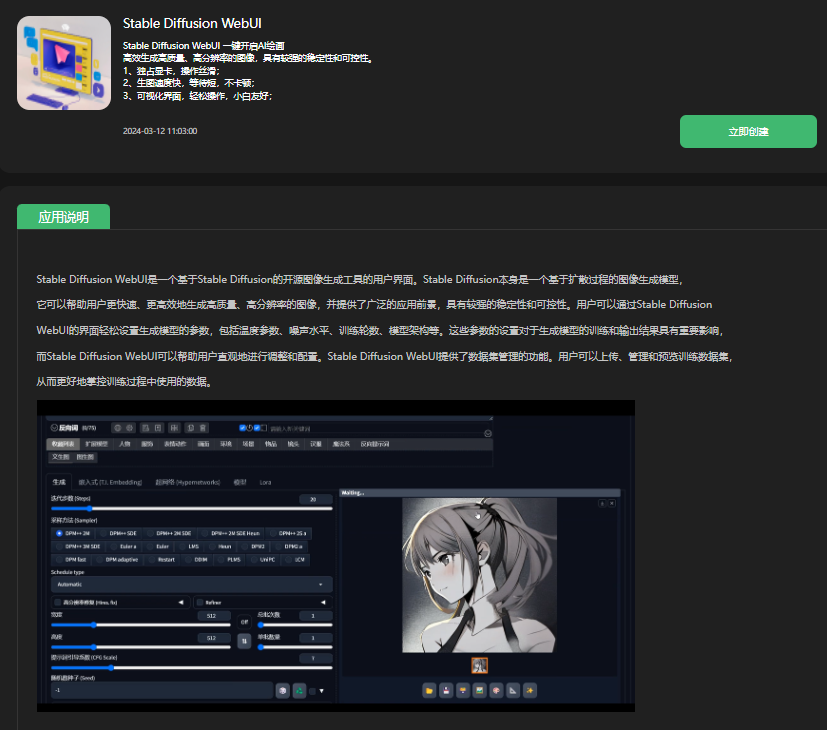
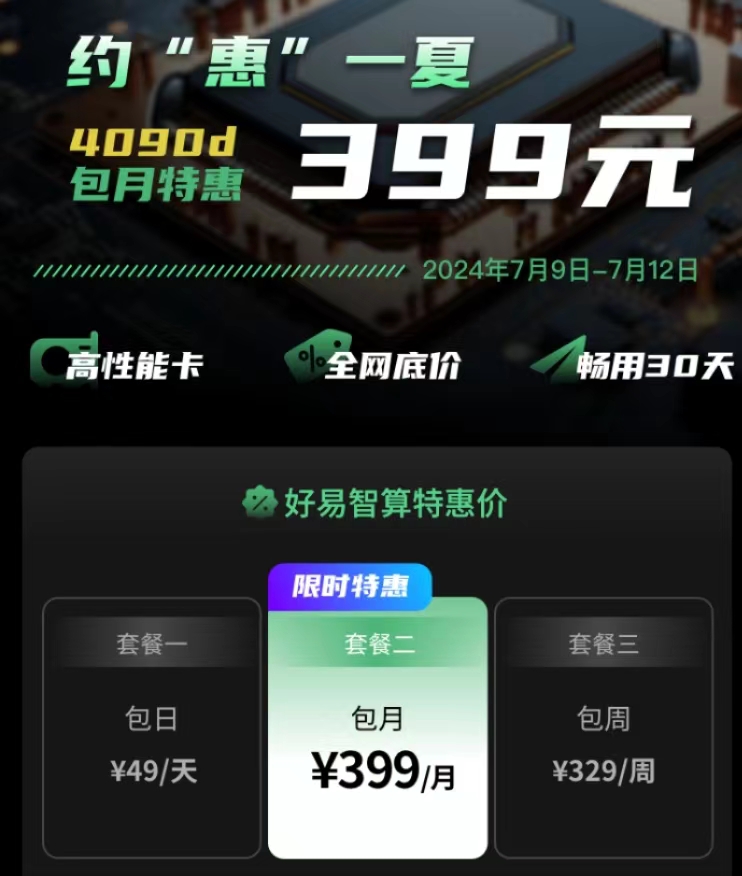
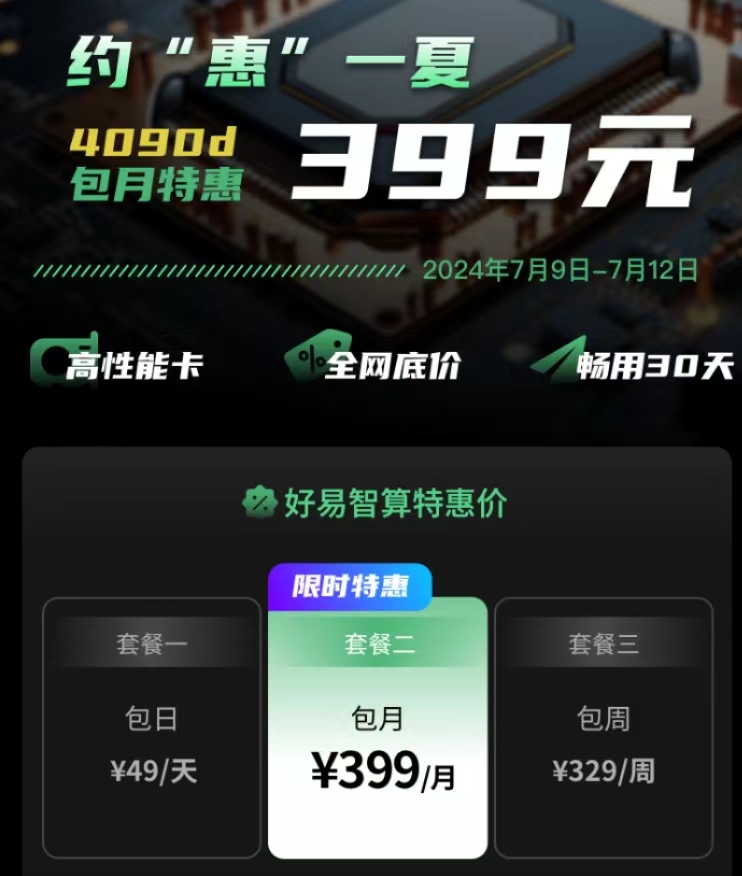
近期,好易智算平臺7月9日上線推出了399包月,用戶可在算力市場中自由選擇心儀的算力資源,享受到前所未有的價格優惠。
原因分析
首先我們要了解臉部崩壞的原因
為什么在使用Stable Diffusion生成全身圖像時,臉部細節往往不夠精細?
- 問題一:圖像分辨率和細節處理
在生成全身圖像的過程中,模型會將計算資源集中于整個身體的描繪,包括服裝、姿勢和背景等要素。臉部通常僅占整個圖像的一小部分,相對地,分配給臉部細節處理的資源就顯得有限。這導致在最終生成的全身圖像中,臉部的細節可能不如半身圖像那樣清晰。 - 問題二:訓練數據的偏差效應
如果您的數據集中包含了大量高清的半身像而非全身像,Stable Diffusion模型可能會傾向于專注于處理這些半身像。由于全身像包含更多的圖像元素和更高的維度,模型在繪制時需要投入更多的計算能力。因此,它在半身像的處理上可能會更有優勢。 - 問題三:生成算法的局限性
當前的生成算法在處理尺寸不同的對象時,可能存在一些限制。例如,臉部區域是一個復雜且細節豐富的部分,而當算法處理全身圖像時,可能難以保持對臉部細節質量的關注。 - 問題四:計算資源的限制
要生成一個特定尺寸的圖像(如320x240像素),模型需要進行一系列運算,包括模板提取、特征表示、搜索和匹配等。這些都需要計算資源,并且在有限的資源下,對圖像不同部分的優化可能會增加計算成本。因此,對于全身圖像,可能對臉部細節質量有所優化,或者簡化了處理流程。
解決策略
-
利用更高分辨率圖像進行訓練
通過使用更高分辨率的圖像來進行訓練,模型可以學習更多細節,這對提升生成照片中臉部的細節是有益的。
但是更高的分辨率會導致人物拉長畸形,大大降低了質量 -
使用更高的算力
提升GPU算力是提高計算機在圖形處理、科學計算、深度學習等高性能計算任務中性能的關鍵。GPU,即圖形處理單元,是一種高度并行的處理器,專門設計用來快速處理和渲染圖像。
在今天的數字時代,我們可以通過一個簡單快捷、功能強大的平臺來迅速啟動我們的服務。這個平臺就是“好易智算”。在這個集成了無數AI應用程序的平臺上,只需選擇想要的應用,無需部署便會被輕松啟用。這種前所未有地便捷體驗極大地降低了訪問這些前沿技術的門檻,讓用戶能夠輕松而高效地利用這些技術,從而極大提升了工作效率和生活質量。并且提供了極高的資源選擇

- 在生成全身圖像時采用引導技術
在生成全身圖像時,嘗試應用引導技術(如注意力機制),這樣可以讓模型更加專注于臉部區域,從而提高對臉部細節的關注。
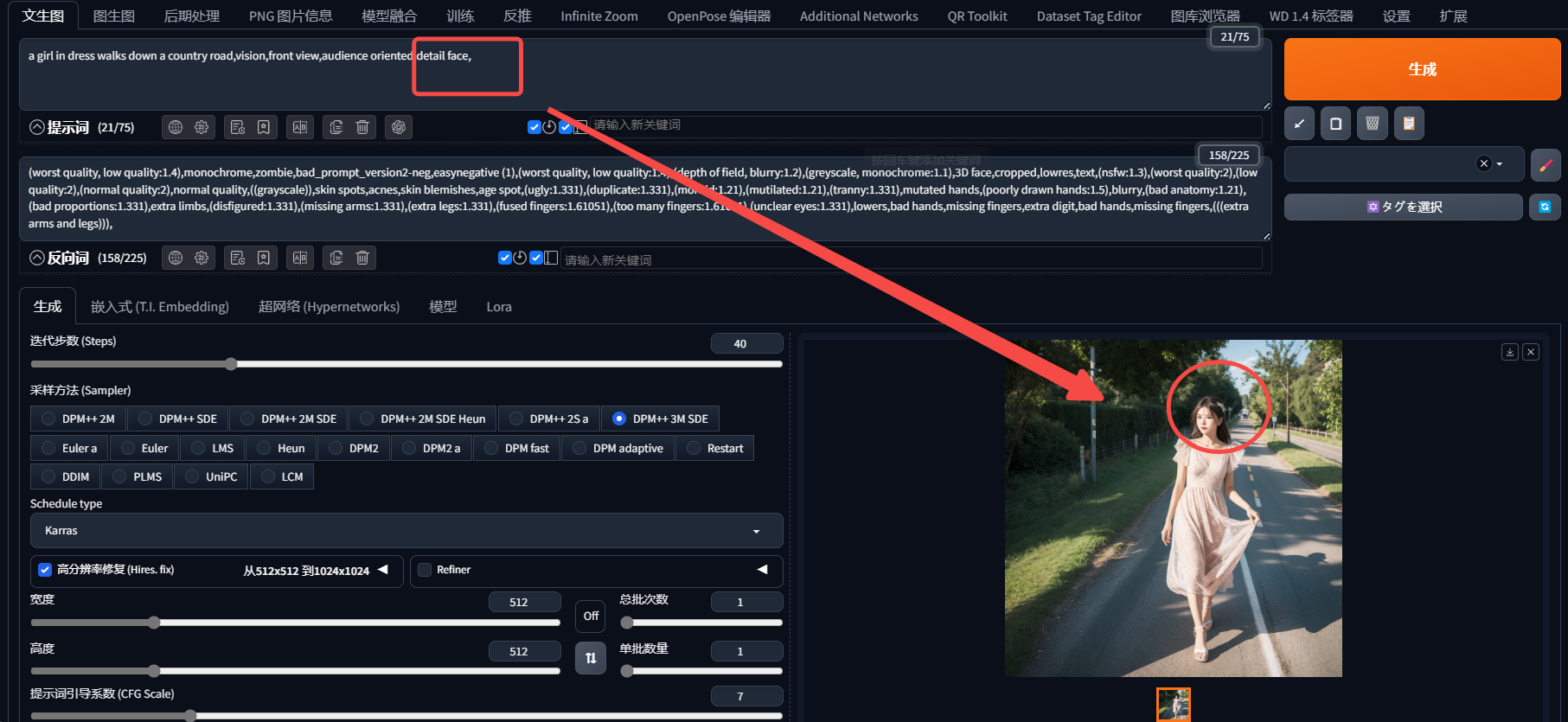
我們可以看到即使使用了prompt之后,Stable Diffusion似乎聽不懂一樣只是對面部加了一個渲染,但并沒有達到預期的效果

局部重繪
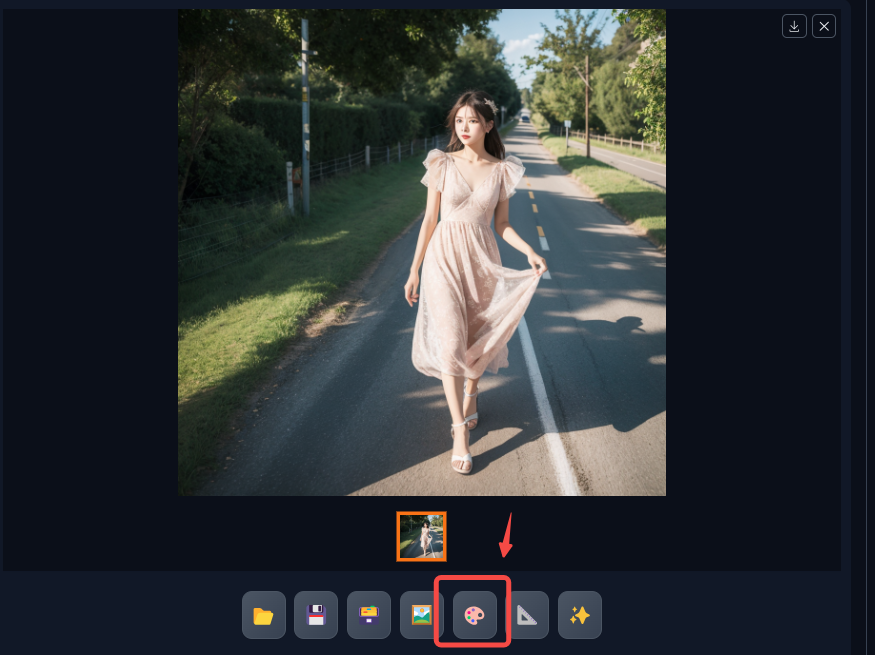
我們可以直接點擊這里到局部重繪,在選擇重繪內容之后,如下:
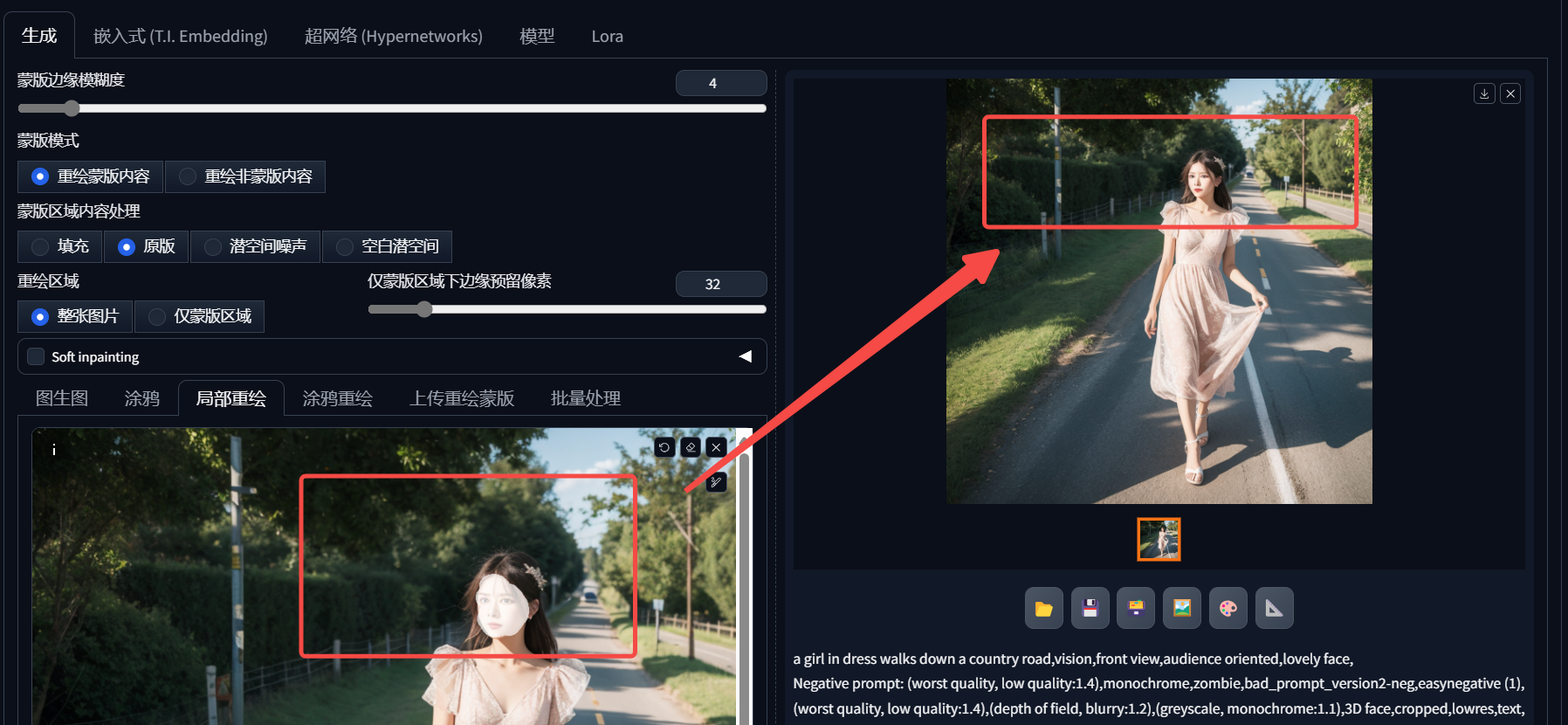
提示詞都不用變化,只需要把負面詞加上即可
(worst quality, low quality:1.4),monochrome,zombie,bad_prompt_version2-neg,easynegative (1),(worst quality, low quality:1.4),(depth of field, blurry:1.2),(greyscale, monochrome:1.1),3D face,cropped,lowres,text,(nsfw:1.3),(worst quality:2),(low quality:2),(normal quality:2),normal quality,((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))),
- 調整參數設置
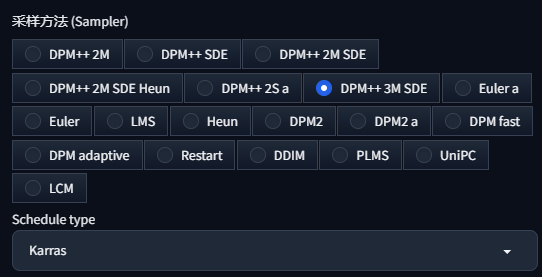
通過增加迭代次數或采用不同的采樣方法,可以提高生成圖像的質量,其中包括臉部細節。
我們借助一個簡便快捷且功能完備的平臺,迅速開啟我們的各項服務。這便是“好易智算”平臺。在這個集合了眾多AI應用的平臺,這些應用中還集成了豐富的采樣器和采樣方法,極大提升了生成高質量圖片的能力。這種前所未有的便捷體驗大幅降低了接觸這些尖端技術的難度,使得用戶能夠輕而易舉、高效地運用這些技術,進而顯著提高了工作效率和生活品質。
這款產品提供即時可用的云計算服務,無需配置,無需等待,隨時啟動,即刻享受預設配置,真正實現即開即用的便捷體驗。
采樣器
在探討Stable Diffusion的核心技術中,采樣器扮演著至關重要的角色。本文將深入分析幾種主要的采樣器,以及它們各自的特點和應用場景,為讀者提供更全面的了解。
首先,我們來看Euler采樣器。這是一個基礎而簡潔的工具,它采用歐拉方法來進行迭代操作。歐拉方法本質上是一種高效的數值積分技術,專門用于求解非線性常微分方程。當應用于圖像生成時,Euler采樣器通過迭代去噪,可以有效地去除圖像中的噪聲。盡管速度快,Euler采樣器也可能導致一些圖像細節受損,因為過度的去噪可能會丟失一些微妙的邊緣信息。
接下來是Euler a采樣器,作為Euler的改進版,它增加了額外的參數用于控制去噪過程。這些參數的引入使得用戶能夠在去噪過程中擁有更多的自主權,從而有望獲得更高的圖像質量。這種改進帶來了一系列潛在的優勢:如更平滑的采樣體驗、更精細的噪聲控制以及更優的整體圖像效果。
轉向Heun采樣器,它的設計理念源自Heun方法,這是一種結合了Euler和Midpoint方法的創新技術。Heun方法同樣基于數值積分原理,專注于求解常微分方程,并在Stable Diffusion中用于迭代去噪過程。相較于Euler,Heun采樣器展現出更加平滑細膩的采樣過程,同時提供更為卓越的圖像質量。

DPM2采樣器則是一種基于物理模型的工具。它采用了“去噪擴散概率模型”(DPM)技術,這一模型能夠在去噪過程中優化控制噪聲水平,進而生成更高質量的圖像。DPM2的強大之處在于它可以精確調整噪聲水平,避免了傳統去噪方法中常見的“過噪”問題。
DPM2 a是DPM2采樣器的又一次重大升級,它繼承了Euler a的特性,并引入了更多的參數來進一步控制去噪流程。這些新參數允許用戶對去噪過程進行精細的控制,有助于提升最終圖像的質量。
DPM fast是DPM系列的另一快速響應選項。它通過降低去噪迭代次數并簡化過程的方式,犧牲了一定的圖像質量以換取生成速度的提升。盡管如此,DPM fast仍然保留了許多吸引人的特點,包括快速的生成效率和更短的處理時間。
DPM adaptive是DPM2采樣器的自適應變體。它具備動態調整采樣策略的能力,能夠根據圖像的復雜度實時調整采樣參數。這樣做的目的是為了平衡高生成速度和高質量輸出之間的關系,確保生成的圖像既快又好。
Restart采樣器是一種利用重啟技術的新型采樣器。當圖像質量開始出現下降趨勢時,Restart采樣器會重新開始整個去噪過程,以恢復圖像的原有質量,防止其進一步惡化。

DDIM采樣器基于迭代去噪技術,使用“去噪擴散迭代模型”(DDIM)。這項技術能夠生成非常高質量的圖像,但由于它的迭代特性,生成速度相對較慢。
PLMS采樣器是DDIM采樣器的改良版,它采用了“預條件的Legendre多項式去噪”(PLMS)技術。這種方法不僅能提供更好的圖像質量,還能在生成速度上略勝一籌,與DDIM形成鮮明對比。
UniPC采樣器基于統一概率耦合,采用“統一概率耦合”技術實現高質量圖像輸出。UniPC雖然在圖像質量方面表現出色,但其復雜性和迭代特性導致了較慢的生成速度。
LCM采樣器則基于拉普拉斯耦合模型,運用“拉普拉斯耦合模型”技術。LCM同樣能夠產出非常高品質的圖像,但由于其結構的復雜性及迭代特性,生成速度也相應受到影響。
DPM++ 2M采樣器是DPM2的進一步改進版,它引入了許多額外的去噪步驟和參數,旨在提升圖像質量。特別值得一提的是,DPM++ 2M在去噪概率模型方面做出了重要的更新。
DPM++ SDE采樣器是DPM2的基于隨機微分方程(SDE)的改進版本。SDE技術的引入為圖像生成提供了更加穩定和高質的結果。
DPM++ 2M SDE采樣器是DPM++ 2M與DPM++ SDE結合的產物。它融合了兩種技術的優勢,為用戶帶來了更佳的圖像質量。
DPM++ 2M SDE Heun采樣器是DPM++ 2M SDE的進一步升級,它使用Heun方法進行迭代,結合了去噪擴散概率模型和Heun方法的共同優點。
DPM++ 2S a采樣器是DPM++ 2M的最新版本,它增加了額外參數來精細控制去噪過程。這些新增的控制參數允許用戶在去噪過程中擁有更多選擇,有望獲得更加精細和高質量的圖像。
最后,我們來看看DPM++ 3M SDE采樣器。它是DPM++ 2M SDE采樣器的第三代進化版,引入了更多的去噪步驟和參數以追求更高的圖像質量。DPM++ 3M SDE的目標是在保持前兩代產品優點的同時,進一步提升性能和圖像質量,為用戶提供更加流暢和精細的圖像生成過程。

總結
在當今這個視覺至上的時代,無論是藝術創作、廣告宣傳還是社交媒體分享,高質量的圖像都是吸引觀眾、傳遞信息的關鍵。通過上述介紹的解決策略和技術改進方法,我們不僅能夠藝術地掌控人物形象,還能更好地運用Stable Diffusion采樣器,這是圖像生成領域的一大進步。
藝術地掌控人物形象,不僅需要我們有獨到的審美眼光,還需要我們掌握相關的技術手段。從化妝造型、服飾搭配到光影效果、后期處理,每一個環節都至關重要。通過上述介紹,我們了解到如何通過細節的調整,讓人物形象更加立體、生動。

而Stable Diffusion采樣器的運用,則是圖像生成技術的又一次飛躍。它通過算法模擬出自然、逼真的圖像效果,大大提高了圖像生成的質量和效率。通過上述介紹,我們了解到如何通過調整參數、優化算法,讓Stable Diffusion采樣器更好地為我們服務。

然而,無論是藝術地掌控人物形象,還是運用Stable Diffusion采樣器,都離不開強大的算力支持。**好易智算平臺**作為一個優秀的算力資源提供者,為我們的圖像生成提供了強有力的保障。它不僅提供了高效的計算資源,還提供了便捷的操作界面和專業的技術支持,讓我們的圖像生成工作更加輕松、高效。
總的來說,通過上述介紹的解決策略和技術改進方法,我們不僅能夠藝術地掌控人物形象,還能更好地運用Stable Diffusion采樣器,讓我們的圖像生成工作更加高效、高質量。同時,好易智算平臺此次399包月活動為用戶帶來了極大的實惠,7月9日上線讓更多用戶能夠以優惠的價格輕松獲取所需的算力資源,助力他們在各自領域取得更好的成果。


)
)

--迭代器)







】為什么在設計遷移后,無法在Nios II BSP 編輯器中找到 DDR3 作為內存區域)

)
)



