計算機操作系統
文章目錄
- 計算機操作系統
- 引言 操作系統基本概念
- 第一章 引論
- 目標和作用
- 操作系統發展歷程
- 單道批處理系統
- 多道批處理系統
- 分時系統
- 實時系統
- 基本特征
- 并發
- 共享
- 虛擬
- 異步性(不確定性)
- 操作系統主要功能
- 處理機管理
- 內存管理
- 設備管理
- 文件管理
- 第二章
- 進程
- 進程和程序的區別
- 線程
- 多線程模型
- 用戶級線程
- 內核支持線程
- 創建進程
- 撤銷進程
- PV操作
- 第三章 處理機調度與死鎖
- 調度
- 進程調度算法
- 處理機調度算法的共同目標
- 批處理系統的調度目標
- 準則
- 先來先服務調度算法 (FCFS)
- 短作業(中級調度)/進程(低級調度)優先調度算法
- 高響應比優先調度算法(HRRN)
- 時間片輪轉(RR)調度算法
- 優先權調度算法
- 多級反饋隊列調度算法
- 死鎖
- 概述
- 處理死鎖的四種方法
- 1. 預防(防范程度最高,往下依次遞減)
- 2. 避免(銀行家算法)
- 3. 檢測
- 4. 解除
- 描述死鎖
- 資源分配圖
- 第四章 存儲器管理
- 存儲其管理的主要功能
- 基本概念
- 連續分配存儲管理方式
- 基于動態搜索的動態分區分配算法
- 首次適應算法(FF)
- 循環首次適應算法(NF)—— 鄰近適應
- 最佳適應算法(BF)
- 最壞適應算法(WF)
- 可重定位分區分配方式
- 內存擴充:覆蓋與交換(了解)
- 基本分頁存儲管理方式
- 基本分段存儲管理方式
- 虛擬存儲器的基本概念
- 請求分頁存儲管理方式
- 頁面置換算法
- 地址
- 地址重定位
- 裝入和鏈接(概念性 了解即可)
- 分頁存儲管理
- 一些計算
- 兩級和多級頁表
- 第五章 虛擬存儲器
- 概述
- 請求分頁系統存儲管理
- 頁面置換算法
- 最佳置換算法
- 先進先出FIFO置換算法
- 最近最久未使用LRU置換算法
- Clock置換算法(最近未用NRU置換) 可能會考哦
- 改進型Clock算法
- ”抖動“與工作集(not important Learn by self)
- 請求分段式存儲管理方式 (不如分頁重點)
- 第六章 輸入輸出系統
- I/O系統的基本功能
- I/O系統的層次結構和模型
- I/O系統接口
- I/O設備
- 設備控制器
- I/O通道
- 中斷
- 基本簡介
- 中斷處理程序
- 設備驅動程序
- 對IO設備的控制方式
- 與設備無關的IO軟件
- 基本概念
- 軟件
- 設備分配
- 邏輯設備名到物理設備名
- 用戶層的IO軟件
- 系統調用和庫函數(dll)
- 假脫機系統(spooling)
- 緩沖區管理
- 基本概念
- 緩存
- 緩沖池
- 磁盤存儲器的性能和調度
- 磁盤性能簡述
- 磁盤調度算法
- 第七章 文件管理
- 文件和文件系統
- 文件的邏輯結構
- 文件目錄
- 文件共享
- 文件保護
- 第八章 磁盤存儲器的管理
- 外存的組織方式
- 連續組織方式
- 鏈接分配
- FAT技術
- 索引分配
- 文件存儲空間的管理
- 空閑表法和空閑鏈表法
- 位示圖法
- 成組鏈接法

核心大題梳理
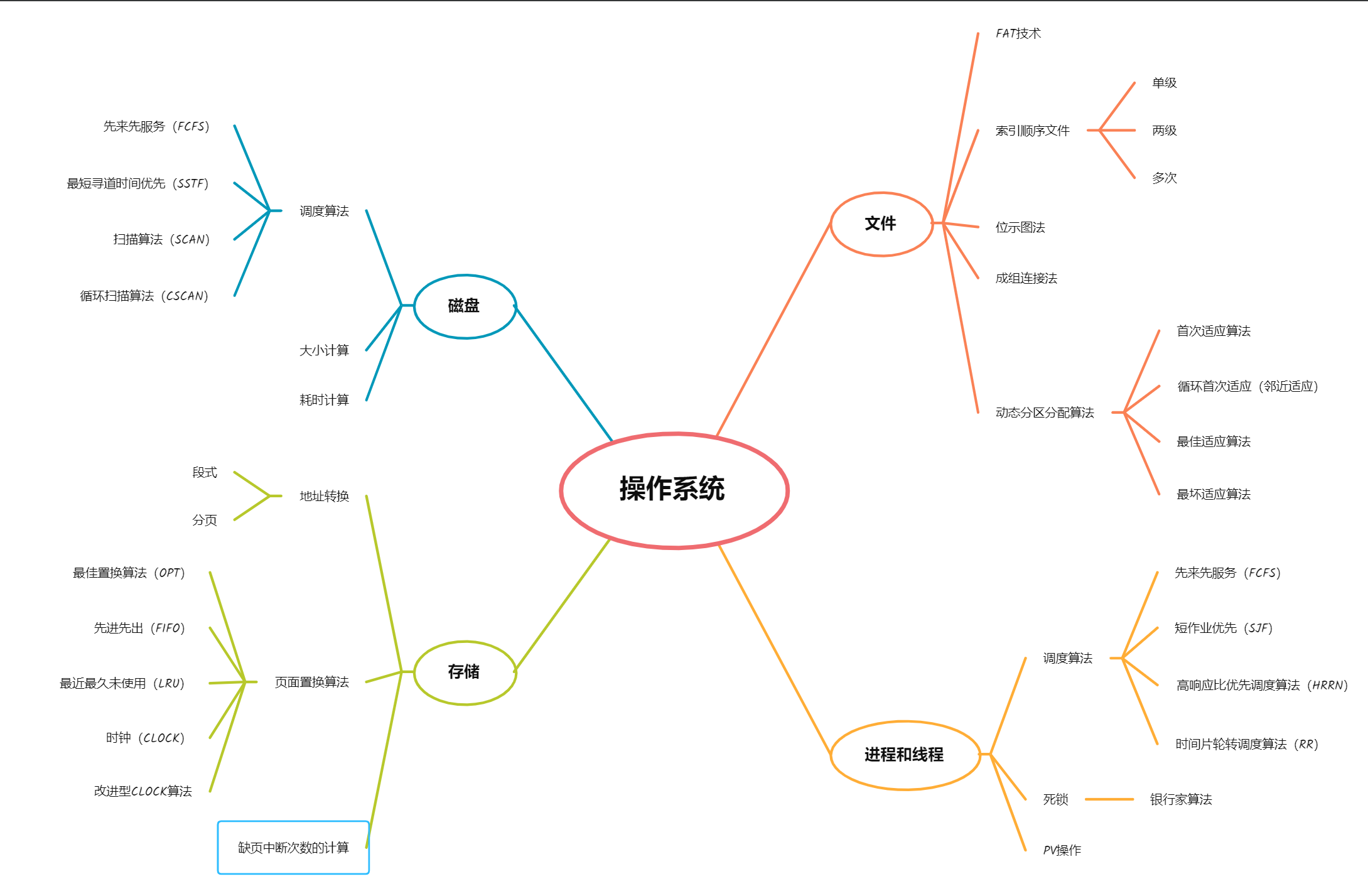
引言 操作系統基本概念
老師畫重點:
操作系統的定義:
計算機系統的組成:
操作系統的作用:
沙漏模型:向上提供類似虛擬機環境 向下提供
抽象:
組成:Windows、MacOS、Linux
操作系統在計算機中的位置
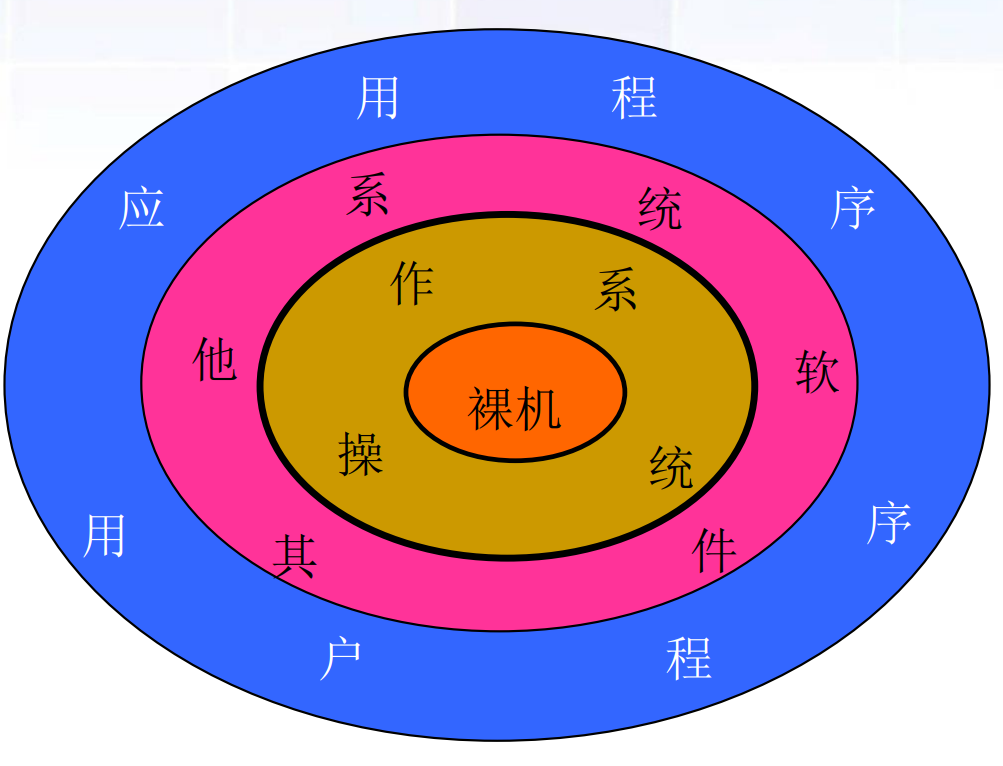
- OS與各層之間的關系
- 與硬件的關系:
- 控制CPU的工作
- 訪問存儲器
- 設備驅動、中斷處理
- 與用戶及應用程序的關系
- 提供便捷的用戶界面
- 提供優質的服務
- 各層對操作系統的制約
- 下層硬件環境
- 提供OS運行基礎
- 限制OS的功能實現
- 上層軟件
- 對OS提出要求
- 良好的用戶界面
第一章 引論
目標和作用
目標:
- 方便性
- 有效性
- 可擴充性
- 開放性
作用:
- OS作為用戶與計算機硬件系統之間的接口
- OS作為計算機系統資源的管理者
- OS實現了對計算機資源的抽象
操作系統發展歷程
單道批處理系統
缺點:
- 資源利用率低下
- 程序難以調試、除錯
存在問題:
內存中只有一個作業在運行,作業本身串行執行,這就導致CPU必須等待IO操作(如 讀數據)完成,才能進行下一步計算。
補一張示例圖:
多道批處理系統
解決上述現象
即可以多個作業同時駐留在內存中,這樣就保證在某個作業等待IO操作完成時CPU仍然在執行其他作業
宏觀上同時運行:都處在運行狀態,但是都未運行完畢
微觀上交替運行:各作業交替使用CPU
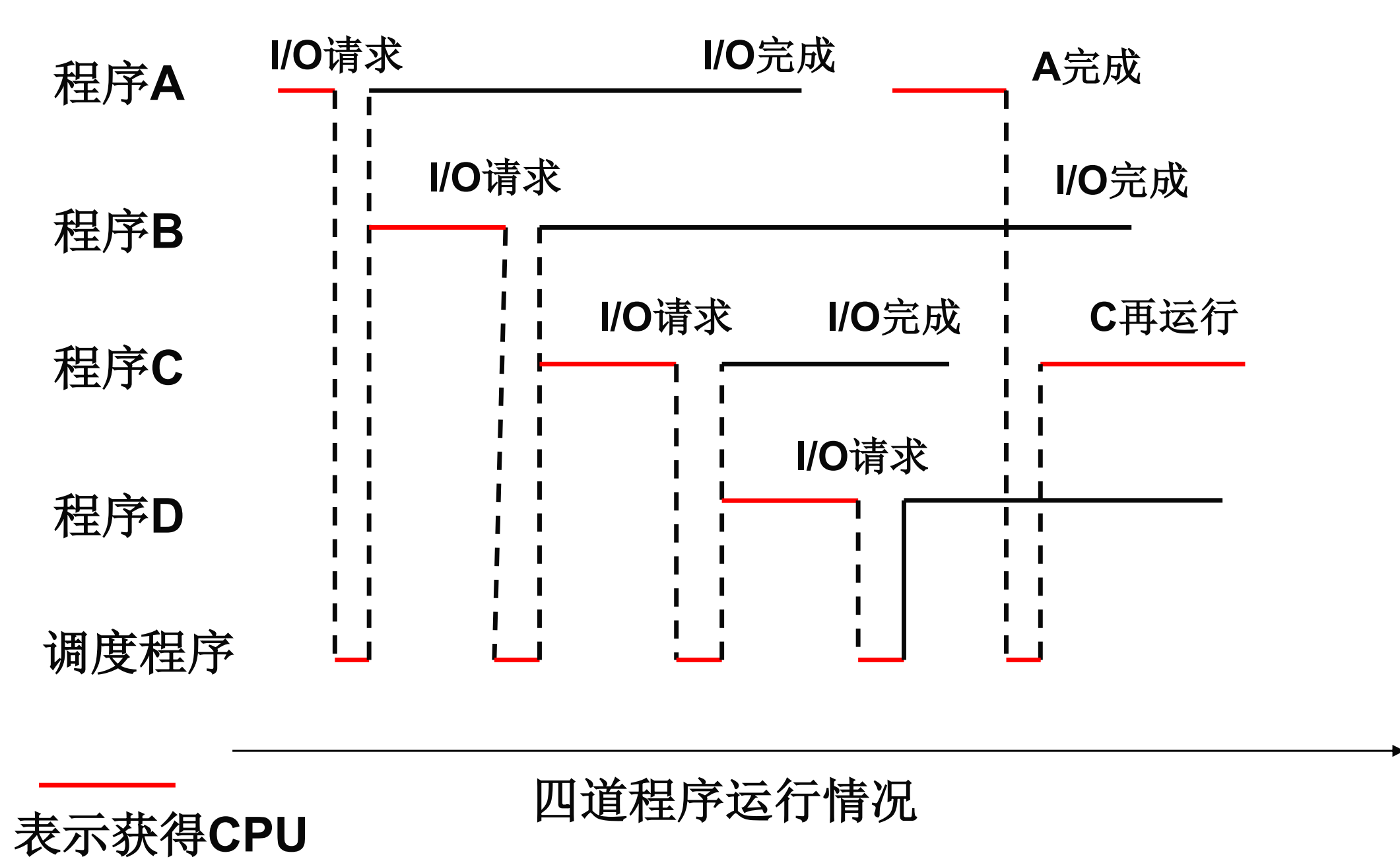
通過這個圖我們可以發現,在不同作業調度之間也是需要占用一小部分CPU的
該系統的優點:
- 提高CPU利用率
- 提高內存和IO設備利用率
- 提高系統吞吐量
缺點:
- 平均周轉時間長
特征:
- 多道性
- 調度性:作業調度、進程調度
分時系統
區別于批處理系統,分時系統指一臺主機上連接多個帶有顯示器和鍵盤的終端,同時允許多個用戶共享主機的資源,每個用戶都可以通過自己的終端以交互方式使用計算機
思想:
- 采用時間片輪轉法,為許多終端用戶服務,對每個用戶能保證足夠快的響應時間,并提供交互會話的功能
- 時間片:將CPU的時間劃分為若干片段,稱為時間片,操作系統以時間片為單位,輪流為每個終端用戶服務
特點:
- 多路性
- 獨立性
- 及時性 : 用戶請求能在很短時間內獲得響應
- 交互性
實時系統
特點在于對時間有更嚴格的控制,如銀行、訂票系統之類,對系統的響應時間提出更高的要求
所有任務都在規定時間內完成的操作系統,滿足時序可預測性
類型:
-
任務執行
- 周期性
- 非周期性
-
截止時間要求
- 硬實時任務(嚴格)
- 軟實時任務(不嚴格)
基本特征
并發
區分:
- 并行:兩個或多個事件在同一時刻發生
- 并發:兩個或多個事件在同一時間間隔內發送
- 在多道程序環境下,并發性指宏觀上一段時間內有多道程序在同時運行
- 在單處理機系統,微觀上這些程序在交替執行
- 進程:能獨立運行并作為資源分配的基本單位
- 線程:獨立運行和獨立調度的基本單位
共享
含義:系統中資源可供內存中多個并發執行的進程共同使用,此外共享以程序的并發為條件
具體:
- 互斥共享:一段時間只允許一個進程訪問該資源 => 臨界資源
- 同時訪問:宏觀上同時訪問,微觀上仍互斥交替訪問
虛擬
通過某種技術把一個物理實體變為若干個邏輯上的對應物。前者是實際存在的,而后者是虛構的
時分復用技術:虛擬處理機、虛擬設備
空分復用技術:虛擬磁盤、存儲器管理
異步性(不確定性)
操作系統主要功能
處理機管理
-
主要任務:
- 對處理機進行分配
- 對處理機運行進行有效的控制和管理
- 上面兩個以進程為基本單位,因此對處理機的管理可歸結為對進程的管理
-
主要功能:
- 進程控制(進程管理)
為作業創建進程,撤銷已結束進程,控制進程在運行過程中的狀態轉換。
-
進程同步
為多個進程(含線程)的運行進行協調
- 信號量
-
進程通信
用來實現在相互合作的進程之間的信息交換
- 直接通信
- 間接通信
-
處理機調度
- 作業調度
- 進程調度
- 作業調度
- 進程調度
- 調度算法
內存管理
- 內存分配和回收
- 內存保護:每道用戶程序都只在自己的內存空間運行,彼此互不干擾
- 地址映射:將地址空間的邏輯地址轉化為內存空間與對應的物理地址
- 內存擴充(虛擬存儲技術):用于實現請求調用功能,置換功能等
設備管理
主要功能:
- 緩沖管理
- 設備分配
- 設別處理
- 虛擬設備
主要任務:
完成用戶提出的IO請求,為用戶分配IO設備,提高CPU和IO設備的利用率,提高IO速度以及方便用戶使用IO設備
文件管理
主要功能:
- 文件存儲空間的管理
- 目錄管理
- 文件的讀寫管理和保護
主要任務:
管理用戶文件和系統文件,方便用戶使用,保證文件安全性
第二章
進程
進程和程序的區別
進程是分配資源的基本單位,而線程則是系統調度的基本單位
- 調度性
? 線程作為調度和分派的基本單位,而進程只作為資源擁有的基本單位
- 并發性
? 進程可以并發執行,一個進程的多個線程也可并發執行
- 擁有資源
? 進程始終是擁有資源的基本單位,線程只擁有 運行時必不可少的資源,本身基本不擁有系統資源,但可以訪問隸屬進程的資源
- 系統開銷
? 進程顯著大于線程
線程
多線程模型
多對一模型、一對一模型和多對多模型。
? 多對一模型的主要缺點在于,如果一個線程在訪問內核時發生阻塞,則整個進程都會被阻塞;此外,在任一時刻,只有一個線程能夠訪問內核,多個線程不能同時在多個處理機上運行。
用戶級線程
僅存在于用戶空間中的線程,無須內核支持。這種線程的創建、撤銷、線程間的同步與通信等功能,都無需利用系統調用實現。用戶級線程的切換通常發生在一個應用進程的諸多線程之間,同樣無需內核支持。
實現方法:
用戶級線程是在用戶空間中的實現的,運行在“運行時系統”與“內核控制線程”的中間系統上。運行時系統用于管理和控制線程的函數的集合。內核控制線程或輕型進程LWP可通過系統調用獲得內核提供服務,利用LWP進程作為中間系統。
內核支持線程
在內核支持下運行的線程。無論是用戶進程中的線程,還是系統線程中的線程,其創建、撤銷和切換等都是依靠內核,在內核空間中實現的。
在內核空間里還為每個內核支持線程設置了線程控制塊,內核根據該控制塊感知某線程的存在并實施控制。
實現方法:
系統在創建新進程時,分配一個任務數據區PTDA,其中包括若干個線程控制塊TCB空間。創建一個線程分配一個TCB,有關信息寫入TCB,為之分配必要的資源。
當PTDA中的TCB用完,而進程又有新線程時,只要所創建的線程數目未超過系統允許值,系統可在為之分配新的TCB;在撤銷一個線程時,也應回收線程的所有資源和TCB。
創建進程
- OS發現請求創建進程事件后,調用進程創建原語Create()
- 申請空白PCB
- 為新進程分配資源
- 初始化進程控制塊
- 將新進程插入就緒隊列
撤銷進程
- 根據被終止進程標識符,從PCB集中檢索出進程PCB,讀出該進程狀態
- 若被終止進程處于執行狀態,立即終止該進程的執行,置調度標志 為真,指示該進程被終止后重新調度
- 若該進程還有子進程,應將所有子孫進程終止,以防成為不可控進程
- 將被終止進程擁有的全部資源,歸還給父進程,或歸還給系統
- 將終止進程PCB從所在隊列或列表移出,等待其他程序搜集信息
PV操作
2.3課后練習:

semaphore mutexX = 1; //設置信號量 后面數值表示可用資源量為1
int x;void P1(){int y, z;P(mutexX); //即將要使用x變量 則聲明 然后鎖住 其他進程無法訪問xx = 1;y = 0;if(x >= 1){y = y + 1;}V(mutexX);z = y;
}
void P2(){int t, u;P(mutex);x = 0;t = 0;if(x < 1){t = t + 2;}V(mutex);u = t;
}

#include <iostream>
using namespace std;semaphore semBuffer = 9; //資源數 九個進程共享緩沖區
semaphore semProduct = 0; //當前產品的數量 初始為0
semaphore mutexBuffer = 1; //緩沖區互斥訪問
semaphore mutexProducerTriAccess = 1; //控制一次性寫入3個void producer(){do{//限定一次性寫入三個緩沖區P(mutexProducerTriAccess);P(semBuffer); //獲取一個資源單位P(semBuffer);P(semBuffer);V(mutexProducerTriAccess);P(mutexBuffer); // 開始訪問... //寫入V(mutexBuffer); //訪問結束//釋放一次性寫入的三個緩沖區V(semBuffer);V(semBuffer);V(semBuffer);}while(TRUE); //不斷執行
}void consumer(){do{P(semBuffer); //訪問緩沖區 獲取一個資源單位P(mutexBuffer);... //開始執行V(mutexBuffer);V(semBuffer);}while(TRUE);
}

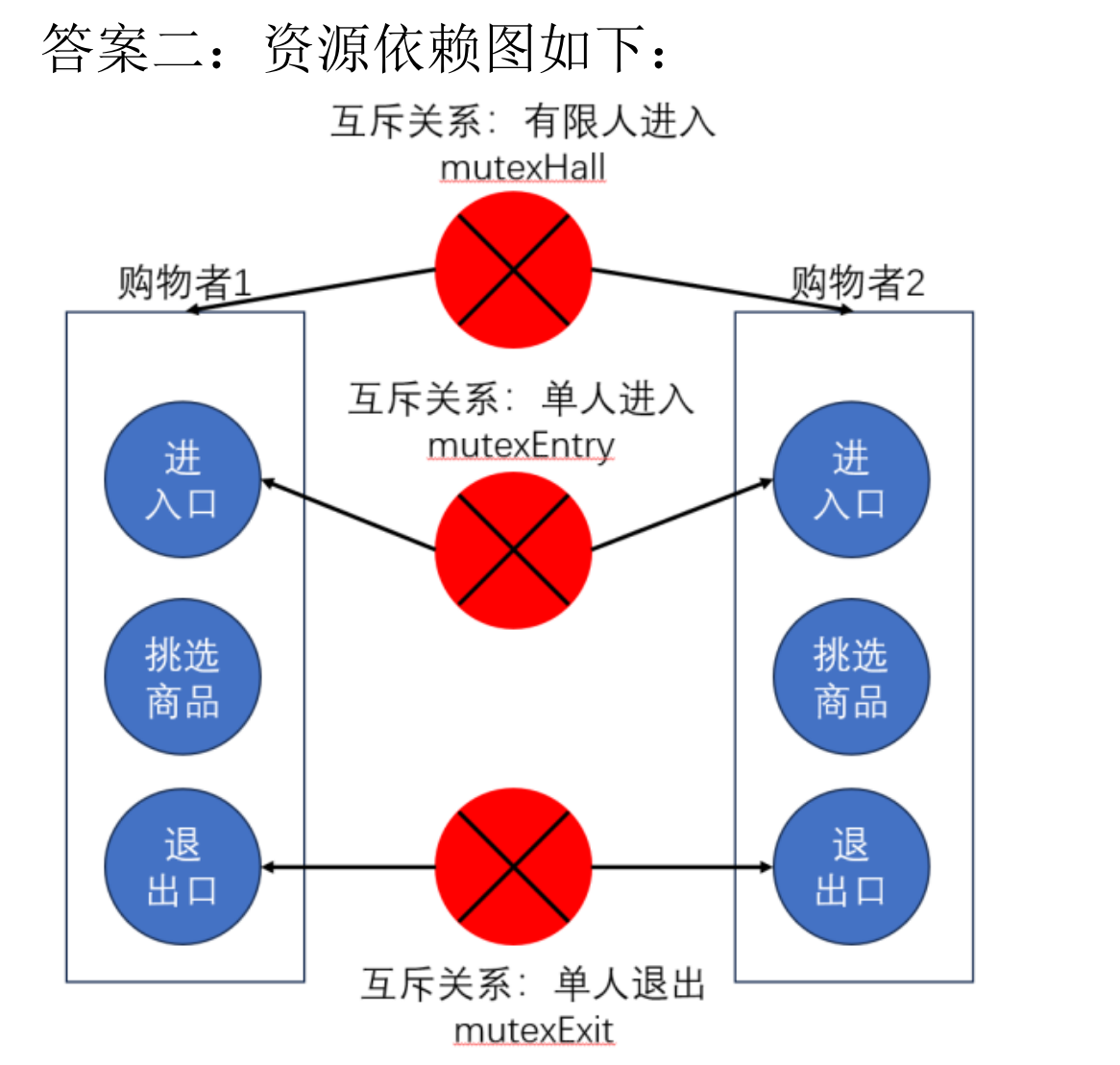
semaphore mutexHall = 50; //最大資源量為50 超時可容納50人
//下面這兩個信號量都是只能單人操作
semaphore mutexEntry = 1;
semaphore mutexExit = 1; void shopping(){do{P(mutexHall);P(mutexEntry); //這不是執行 只是預告 所以鎖住之后 其他代碼會執行對應操作... //進入商場V(mutexEntry);... //shoppingP(mutexExit);... //退出V(mutexExit);V(mutexHall);}while(TRUE);
}
原題練習:

Semaphore empty = 1000 //容量1000人
Semaphore mutex_In = 1 //進口資源控制
Semaphore mutex_Out = 1 //出口資源控制
cobegin參觀者進程i;{P(empty) //先聲明總數 加括號表示是個函數P(mutex_In) //請求入進門;V(mutex_In) //進完了參觀;P(mutex_Out)出門;V(mutex_Out)}coend

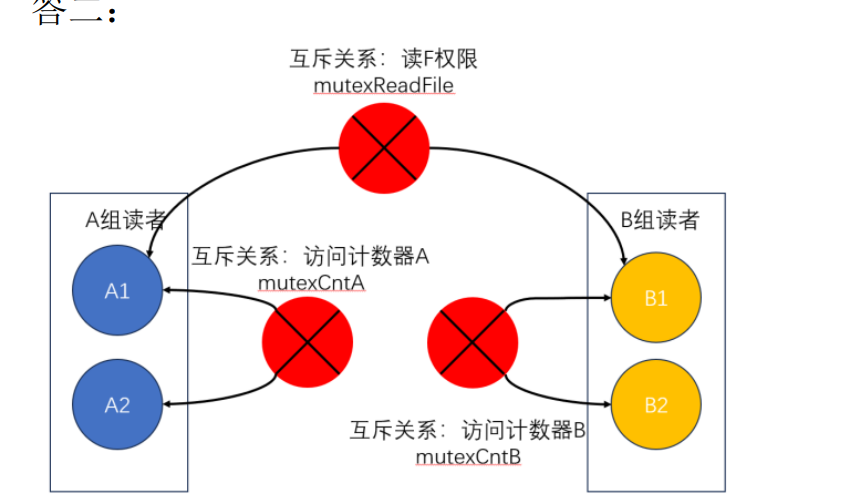
類似這個關系,在互斥中,我們對兩邊的隊頭設置互斥就好了 這個是用mutex 而對內部也需要設置互斥訪問,也就是下面的mutexA 和 mutexB
Semaphore mutex = 1; //獨木橋同一邊方向有人 資源量為1個方向 互斥
Semaphore mutexA = 1; //對countA互斥訪問 只能一個
Semaphore mutexB = 1; //對countB互斥訪問
int countA = 0, countB = 0;PA(){P(mutexA); //countA沒被訪問 同一組進程 對countA計數器的寫操作做保護if(countA == 0){ //A方向沒人 此時如果b有人呢 如果B有人 下面的P就申請不到唄 這里之所以寫==0 作用就是判斷是不是隊首 只有隊首需要去互斥 相當于簡化了 P(mutex); //開始占用獨木橋方向}countA ++; //A向放人V(mutexA);過橋;P(mutexA); //再次需要對countA操作countA --; if(countA == 0){ //如果沒人了 結束占用V(mutex); //釋放A方向對獨木橋的占用}V(mutexA);
}PB(){P(mutexB)if(countB == 0){P(mutex)}countB ++;V(mutexB);過橋;P(mutexB)countB--;//回到隊首了if(countB == 0){V(mutex)}V(mutexB);
}
類似題:

和上面那個邏輯一模一樣
semaphore mutexA = 1; //對隊內部
semaphore mutexB = 1; //對隊內部
semaphore mutex = 1; //對兩個隊
int countA = 0, countB = 0;void PA(){do{P(mutexA);if(countA == 0){P(mutex);}countA++;V(mutexA);//訪問P(mutexA);countA--; //按照邏輯思考 讀完先減一個if(countA == 0){V(mutex);}V(mutexA);}while(TRUE);
}void PB(){do{P(mutexB);if(countB == 0){P(mutex);}countB++;V(mutexB);//訪問P(mutexB);countB--; //按照邏輯思考 讀完先減一個if(countB == 0){V(mutex);}V(mutexB);}while(TRUE);
}
例:


考前練習:
P Q R共享一個緩沖區 P為生產者 Q為消費者 R即為生產者又為消費者 若緩沖區為空 可以寫入 若緩沖區不空可以讀出,實現同步
semaphore mutex = 1; //互斥使用緩沖區semaphore empty = 1; //緩沖區空位數 如果為1 表示為空 為0 表示非空
semaphore full = 0; //緩沖區產品數P(){//寫個死循環放著do{P(empty);P(mutex);...Product oneV(mutex);V(full); //釋放 加1的功效 }while(1);
}Q(){do{P(full);P(mutex);...Consume oneV(mutex);V(empty); //給empty+1 為1 表示空 因為消耗了一個產品}while(1);
}
Summary:
仔細了解下這個信號量怎么使用設置,直到P和V放置的地方,看下上面這幾個題目,PV操作還是比較清晰的!
第三章 處理機調度與死鎖
調度
類型:
- 按OS的類型分類
- 批處理調度
- 分時調度
- 實時調度
- 多處理機調度
- 按調度的層次劃分
- 高級調度
- 中級調度
- 低級調度
一個作業從提交開始,往往要經歷三級調度
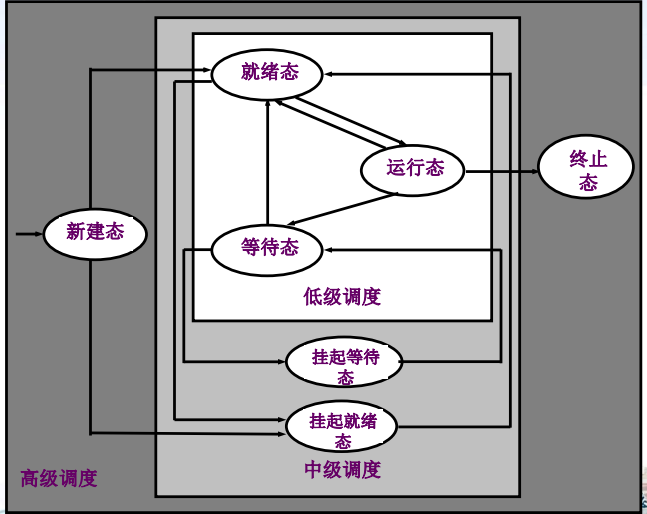
- 高級調度
主要任務:決定把外存上處于后備隊列中的哪些作業調入內存,創建進程 分配資源,排在就緒隊列上。
即允許多少作業同時在內存中運行
而將哪些作業從外存調入內存,將取決于調度算法,先來先服務、短作業優先等
- 低級調度
主要功能:
- 保存處理機的現場信息
- 按某種算法選取進程
- 把處理機分配給進程
從就緒隊列中選擇一個進程來執行并分配處理機
是OS中最基本的調度
常采用非搶占方式和搶占方式兩種
- 非搶占方式:
一旦把處理機分配給某進程后,該進程一直執行,直到進程完成或因某事件阻塞
- 搶占方式:
允許調度程序根據某種原則(時間片、優先權、短進程優先)停止當前正在執行的進程
- 中級調度
內存和外存對換區之間按照給定的原則和策略選擇進程對換
引入中級調度的主要目的:為了提高內存利用率和系統吞吐量,使那些暫時不能運行的進程不再占用內存資源,將他們調至外存等待,把進程狀態改為就緒駐外存狀態或掛起狀態。
進程調度算法
處理機調度算法的共同目標
資源利用率、公平性、平衡性、策略強制執行
批處理系統的調度目標
平均周轉時間短、系統吞吐量高、處理機利用率高
準則
面向用戶:
- 周轉時間短
- 響應時間快
- 截止時間的保證
- 優先權準則
面向系統:
- 系統吞吐量
- 處理機利用率好
- 各類資源平衡利用
最優準則:
- 最大的CPU利用率
- 最大的吞吐量
- 最短的周轉時間
- 最短的等待時間
- 最短的響應時間
計算:
CPU利用率 = CPU有效運行時間 /(運行時間+空閑時間)
響應時間:交互式進程從提交一個請求到系統響應之間的時間間隔
吞吐量:單位時間內處理的作業··數
周轉時間 = 作業等待時間 + 作業運行時間 即從作業提交給系統開始,到作業完成為止的時間間隔
平均周轉時間 = 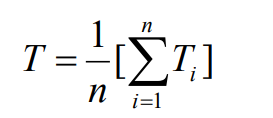
其中Ti 為 服務結束時間 - 到達時間
帶權周轉時間 = 周轉時間 / 進程要求運行時間
平均帶權周轉時間 = 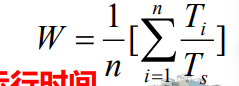
Ti 為 服務結束時間 - 到達時間
Ts 為 需要服務時間
平均等待時間:(開始服務時間 - 到達時間)和 / 個數
需要考慮的因素:
- 系統利用率:充分使用系統中的各類資源 盡可能使多個設備并行工作
- 調度開銷:調度算法不能太復雜 因為調度本身需要很大開銷
先來先服務調度算法 (FCFS)
按照進程進入隊列的先后次序分配處理機
一般采用非剝奪的調度方式
使用甘特圖
考慮周轉時間(結束時間-達到時間)
平均周轉時間:加起來 / 個數 會考喔!
等待時間:開始時間 - 達到時間 一句話給你點透什么是等待時間:就是從到了開始,只要不在執行那就是等待時間,加起來就完事,顧名思義!
平均等待時間:加起來 / 個數
平均帶權周轉時間:基于周轉時間 / 需要服務時間 求和除個數 (帶小數 保留兩位小數即可)
短作業(中級調度)/進程(低級調度)優先調度算法
短作業SJF
- 用于作業調度
- 從后背隊列中選擇一個或若干個估計運行時間最短的作業,調到內存
短進程SPF
- 用于進程調度
- 把CPU進行分配
- 繼續分類
- 可剝奪(搶占)
- 不可剝奪
Summary:
都是在后備隊列中選擇時間短的進行優先處理
應對論述題:
優點:
- 有效降低作業的平均等待時間
- 提高吞吐量
- 有效縮短進程的周轉時間
缺點:
- 對長作業不利
- 不考慮作業的緊迫程度
- 作業執行時間、剩余時間僅為估計時間
區分疑惑(作業調度和進程調度的區別):
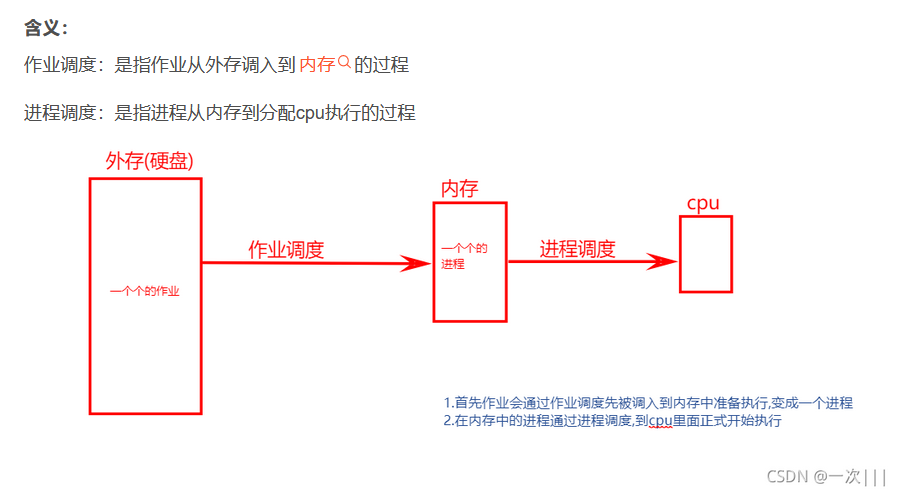
概述:
對于作業調度
對于進程調度(注意 只有進程調度才會涉及到搶占式和非搶占式)
參考文章:https://blog.csdn.net/qq_51694696/article/details/118270795


高響應比優先調度算法(HRRN)
綜合考慮進程等待時間和執行時間
(等待時間+服務時間) / 服務時間
對作業進行調度 不存在搶占或者非搶占 都是非搶占
解釋一下引出這個算法的原因:
- FCFS算法只考慮作業:只考慮作業等候時間而忽視了作業的計算時間
- SJF算法只考慮用戶估計的作業時間計算而忽視了作業的等待時間
所以產生了這么一個既考慮作業等待時間,又考慮作業運行時間的 根據這兩個計算出每一個進程的優先權

直接上例題
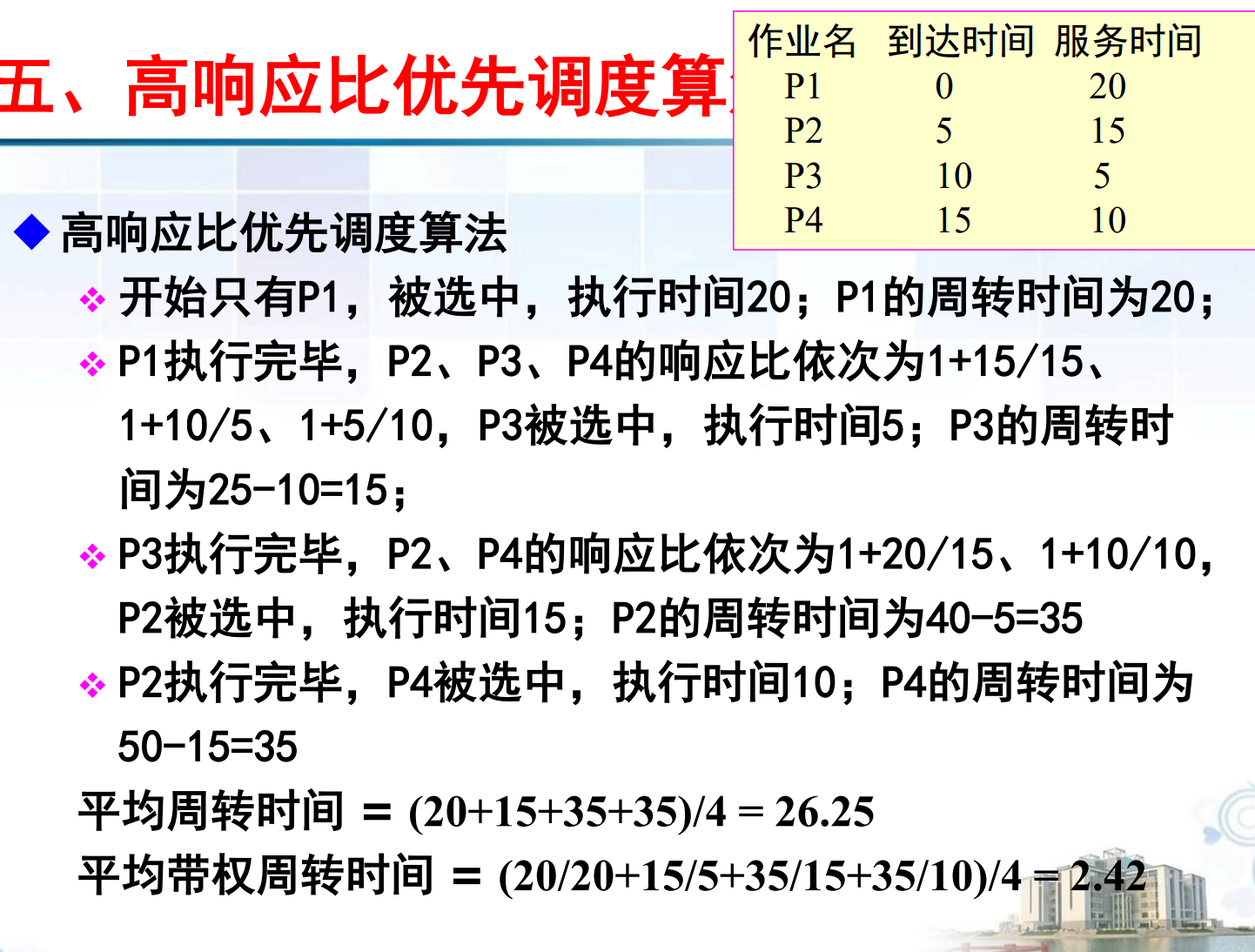
注意:上面的可以寫成 1 + 等待/要求 計算的結果是該作業的響應比 所以越高的越優先
上面是一個組合 從兩個不完美到一個合并 下面這個也一樣 從兩個結合發展到一個
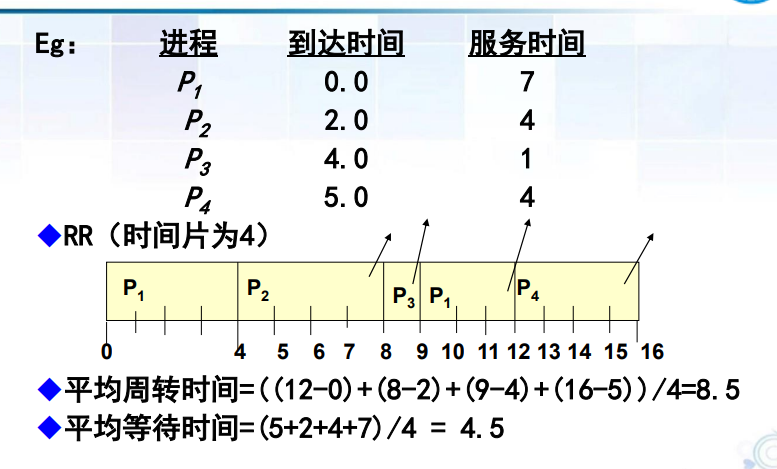
時間片輪轉(RR)調度算法
個人理解引入:
? 基于時間片輪轉,簡單來說就是雨露均沾,根據FCFS的調度原則,先對所有已經到達的進入的進程進行排列,然后從隊首開始,分配一個時間片, 如果進程的執行時間少于時間片,則自愿釋放CPU,對下一個分配。如果一個時間片用完之后該進程還沒有結束,則調度程序將該進程插入到就緒隊列末尾,將CPU分配給新的隊首進程,同時讓它執行一個時間片
來個例題:
優先權調度算法
一般數字越小,優先權越高,看題目
分為搶占式和非搶占式
同時關于優先權也有分類:
- 靜態優先權:優先權在創建進程時確定,在程序的整個運行期間保持不變,一般用一個整數表示,越小優先級越高
- 動態優先權:在創建進程時確定,但在進程的運行期間發送改變
- 根據進程占有CPU時間決定
- 根據進程等待CPU時間決定
多級反饋隊列調度算法
結合了上面的時間片輪轉算法和優先級調度算法的綜合發展,動態調整進程優先級和時間片大小,目前較不錯的進程調度算法
特點:
- 長短作業兼顧,又較好的響應時間
- 短一次完成
- 中作業周轉時間不長
- 大作業不會長期不處理
- 向短時間作業,I/O繁忙和交互式進程傾斜
- 具有**“運行時間越長,則等待時間越長”**特點
解釋執行流程:
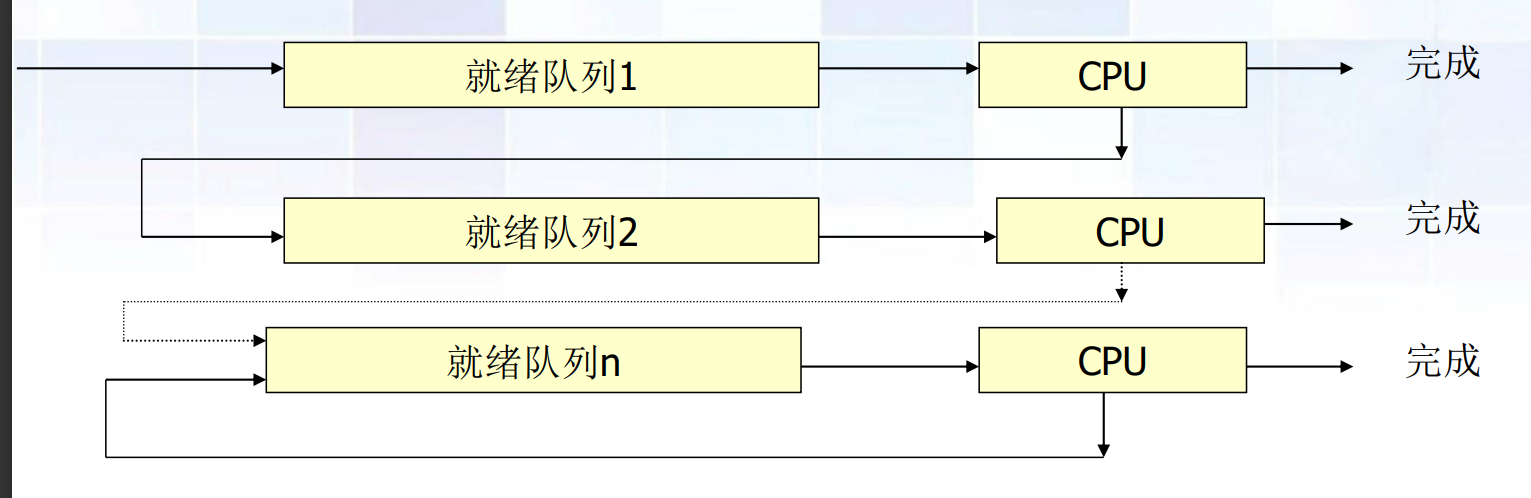
- 設置多個就緒隊列,每個隊列的優先級不同,其中隊列1優先級最高,優先執行,且優先級高的隊列中的進程,獲得CPU的時間片越短
- 當新進程進入系統,放到隊列1的末尾,按照FCFS等待調度。如果進程執行完成,則撤離系統,否則轉移到下一個程序的尾部,依次類推,如果到最后還沒完成,在就緒隊列n中執行RR時間片輪轉算法,直到執行完成
- 上一隊列為空才能下一隊列中的進程才能開始運行。
- 搶占方式:當新進程到比當前優先級高的隊列,則被搶占,原進程轉移到其所在隊列的尾部
綜合例題練習:
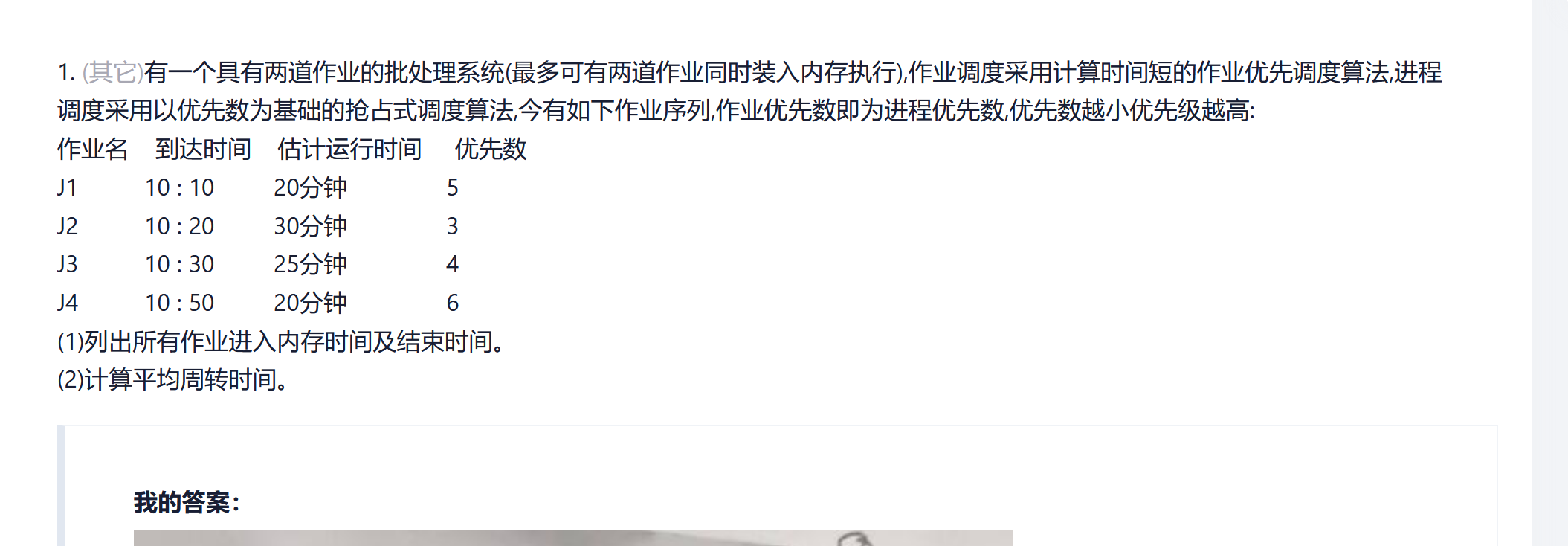
講解:非常脆爽 https://blog.csdn.net/scarificed/article/details/115215962
首先要理解:該題其實要分兩個階段:
- 一個是作業到內存中,這是作業調度,采用短時間優先調度
- 另一個是內存請求CPU進行執行,這是進程調度,采用優先權調度算法
邏輯:
10:10 J1進入, 此時內存中只有J1 開始執行J1
10:20 J2進入, 因為內存可以裝兩個,所以J2進入內存, 同時因為2的優先數為3 搶占 開始執行J2
10:30 J3進入, 因為此時內存有兩個,J3等待進入內存,待會如果內存有空位,則等待中的短時間的優先進入
10:50 J4進入, 此時內存有兩個,J4去等待進入內存
死鎖
概述
P:Process
R:Resource
資源指向進程:資源已經分配給進程
進程指向資源:進程請求該資源
注意:
- 至少兩個進程,每個進程需要多個資源才會有可能產生死鎖
- 參與死鎖的所有進程均等待資源
- 參與死鎖的進程至少有兩個占有資源
定義:多個進程在運行過程中因搶奪資源而造成的一種僵局,如果沒有外力作用,所有進程都無法向前推進
資源分類:
根據資源性質本身:
- 可剝奪資源:CPU、主存
- 不可:驅動器、打印機
根據資源使用期限:
- 永久
- 臨時
而競爭的資源就是上面所說的非剝奪性資源、臨時性資源
產生死鎖的原因:
- 進程推進順序不當
產生死鎖的必要條件:
- 互斥條件(資源獨占條件)
- 請求和保持條件(部分分配條件) 占一部分資源 但是需要新的資源得不到 這時占的資源也不釋放
- 不剝奪條件(不可搶占) 優先級高的剝奪優先級低的可以避免死鎖
- 循環等待條件(環路條件):P1等待P2的資源 … Pn等待P1的資源
處理死鎖的四種方法
1. 預防(防范程度最高,往下依次遞減)
通過設置某些限制條件,去破壞產生死鎖的四個必要條件中的一個或多個
常針對條件2、3、4
- 針對2:
預先靜態分配方法,即要求在進程運行之前一次申請它所需要的全部資源,在資源未滿足前,不投入使用。人話就是要么全占,要么一點別占。
雖然簡單安全,但是降低了資源利用率,同時必須預知進程所需要的全部資源
- 針對3:
一個已經獲得某些資源的進程,若又請求新的資源不能滿足,必須釋放出占有的資源,以后重新申請
- 針對4:
采用有序資源分配法,所有資源都按照類型賦予一個編號,要求每一個進程均嚴格按照編號遞增的次序請求資源,同類資源一次申請完。
好處是一定不會產生死鎖
壞處:
加重了進程負擔
因使用資源順序與申請順序不同而造成資源浪費
2. 避免(銀行家算法)
在資源的動態分配過程中,用某種方法去防止系統進入不安全狀態
如果分配給你,系統仍然處于安全狀態,則分配 一定不會產生死鎖
什么是安全狀態:
系統
銀行家算法:必考
一圖打通:

該算法之所以叫銀行家算法,顧名思義就是模仿銀行與客戶之間進行貸款的流程,所以不要把他想的太復雜,就是一個簡單的貸款還款再貸款的問題,在Claim中 相當于有四個客戶 P1-4 每個客戶都有ABC三個工程去貸款 只有這三個工程都有資金,客戶才能啟動整個項目
例題理解:

分析:
:happy: 資源總數量:上圖中的Resource 銀行可分配給貸款方的錢
:happy: 分配矩陣:Allocation 銀行已經分配給貸款方的錢
:happy: 最大需求矩陣:Claim 貸款方總共需要的錢的情況
系統是否安全就看能否形成一個均滿足的貸款順序 該順序稱為安全序列,但是注意安全序列不是唯一的,只要存在安全序列,則系統處于安全狀態
這個檢測的順序,一般從當前往下循環,比如第一個選中了D 下面我要檢測E 而不是從頭檢測A 測完E再循環到頭部
考點計算:
:happy: 資源總數 = Allocation + Available
:happy: New Available = Allocation + Available
翻譯成人話,每次Need(最大需求-已分配)只是用來判斷的,只要滿足可以選中,則直接回收已分配的資源就好!
答題:
依據上表演示流程,存在一個安全序列P1 … 所以系統是安全的
若P1申請資源(1, 0, 2),是否可以分配
系統按銀行家算法進行檢查:
- Request(1,0,2) <= Need(1,2,2) 相當于提前做一個預估 不能超過Need
- Request(1,0,2) <= Available(3,3,2)
- 先假定為P1分配資源,并修改Available,Allocation,Need向量 進行推演
3. 檢測
允許系統在運行過程中發生死鎖,但可設置檢測機構及時檢測死鎖的發生,并采取適當措施加以清楚
4. 解除
描述死鎖
資源分配圖
參考:https://blog.csdn.net/qq_39328436/article/details/111123779
死鎖定理:
如果分配圖不可完全簡化,說明發生了死鎖
當且僅當該狀態的資源分配圖是不可完全簡化的(死鎖的充分條件)


例題:以一個簡單的分配圖進行學習
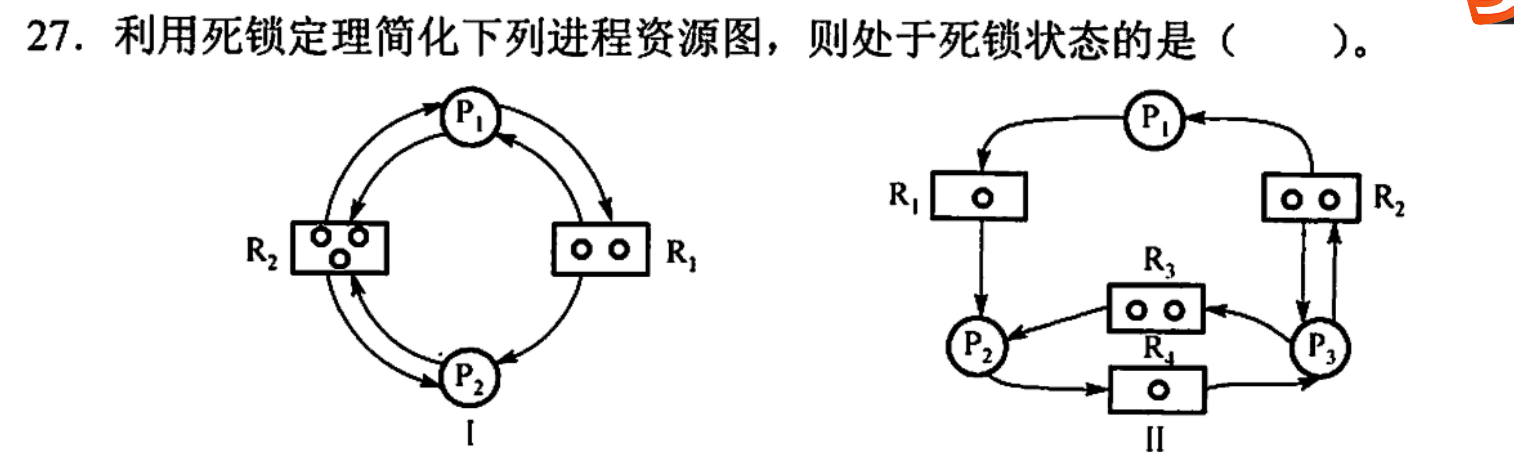
只針對I進行簡化
對圖進行解釋:
P1和P2代表進程
R1和R2代表資源
其中R中的小圓圈代表資源總量,已分配的也包括
從R指向P的箭頭代表已經分配出去的資源
從P指向R的箭頭代表進程請求的資源,還需要
針對P1
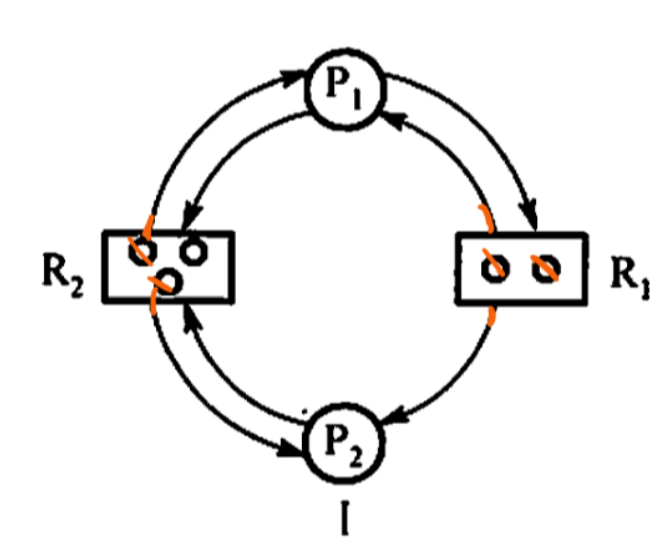
可以發現R2只剩一個資源 R1沒有資源 所以P1無法請求 不能消邊
針對P2
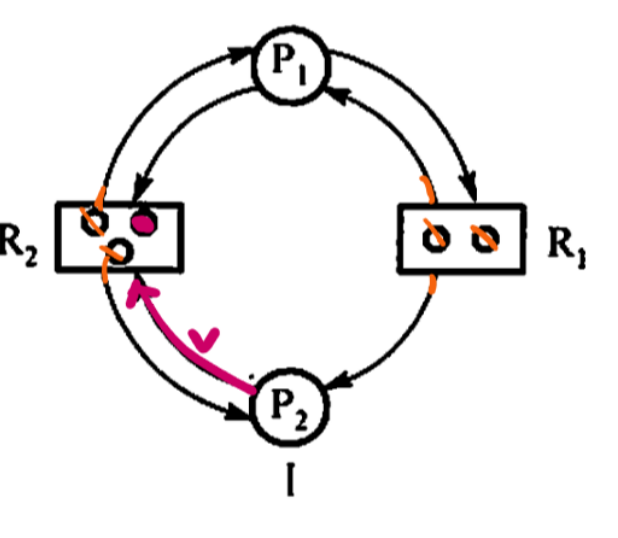
正好請求一個R2的資源 請求成功 然后釋放P2
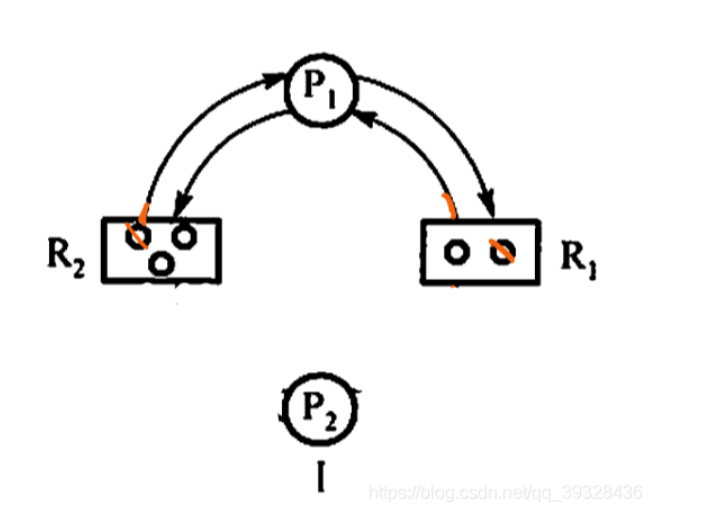
此時P1也可以請求成功
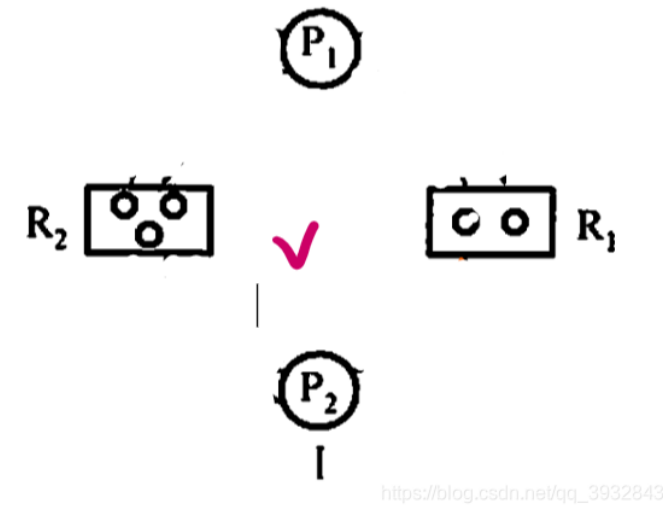
到此結束 不會發生死鎖!
題目練習:
第四章 存儲器管理
存儲其管理的主要功能
- 內存的分配和回收
- 地址變換
- 內存擴充
- 內存共享
- 存儲保護
基本概念
主存儲器:簡稱內存或主存,用于保存進程運行時的程序和數據
寄存器:在CPU內部,具有與處理機相同的速度
硬盤:就是我們電腦里面的C盤 D盤之類
高速緩存:介于寄存器和存儲器之間的存儲器,主要備份主存中較常用的數據,減少處理機隊主存儲器的訪問次數
關系如下:
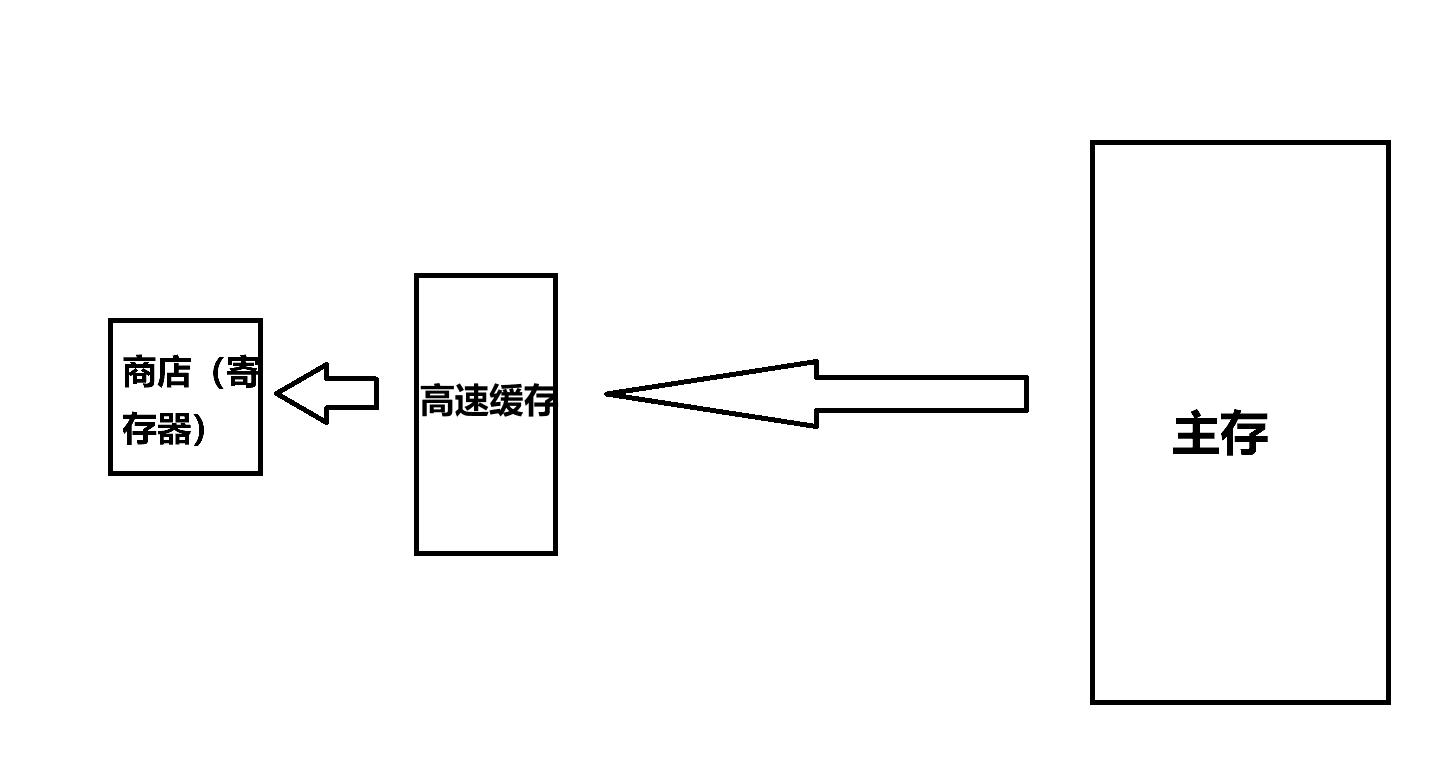
存儲單元:
- 存儲最小單位:“二進制位“,包含信息0或1
- 最小編址單位:字節,一個字節包含八個二進制位
連續分配存儲管理方式
- 固定分區分配
- 可變分區
基于動態搜索的動態分區分配算法
基于順序搜索:首次適應算法、循環首次適應、最佳適應算法、最壞適應算法
基于索引搜索:快速適應算法 伙伴系統 哈希算法
首次適應算法(FF)
低地址優先分配
算法思想:
空閑分區按地址遞增次序鏈接
從鏈首開始查找,直到找到一個大小能滿足的空閑分區為止,下一次分配從頭開始遍歷
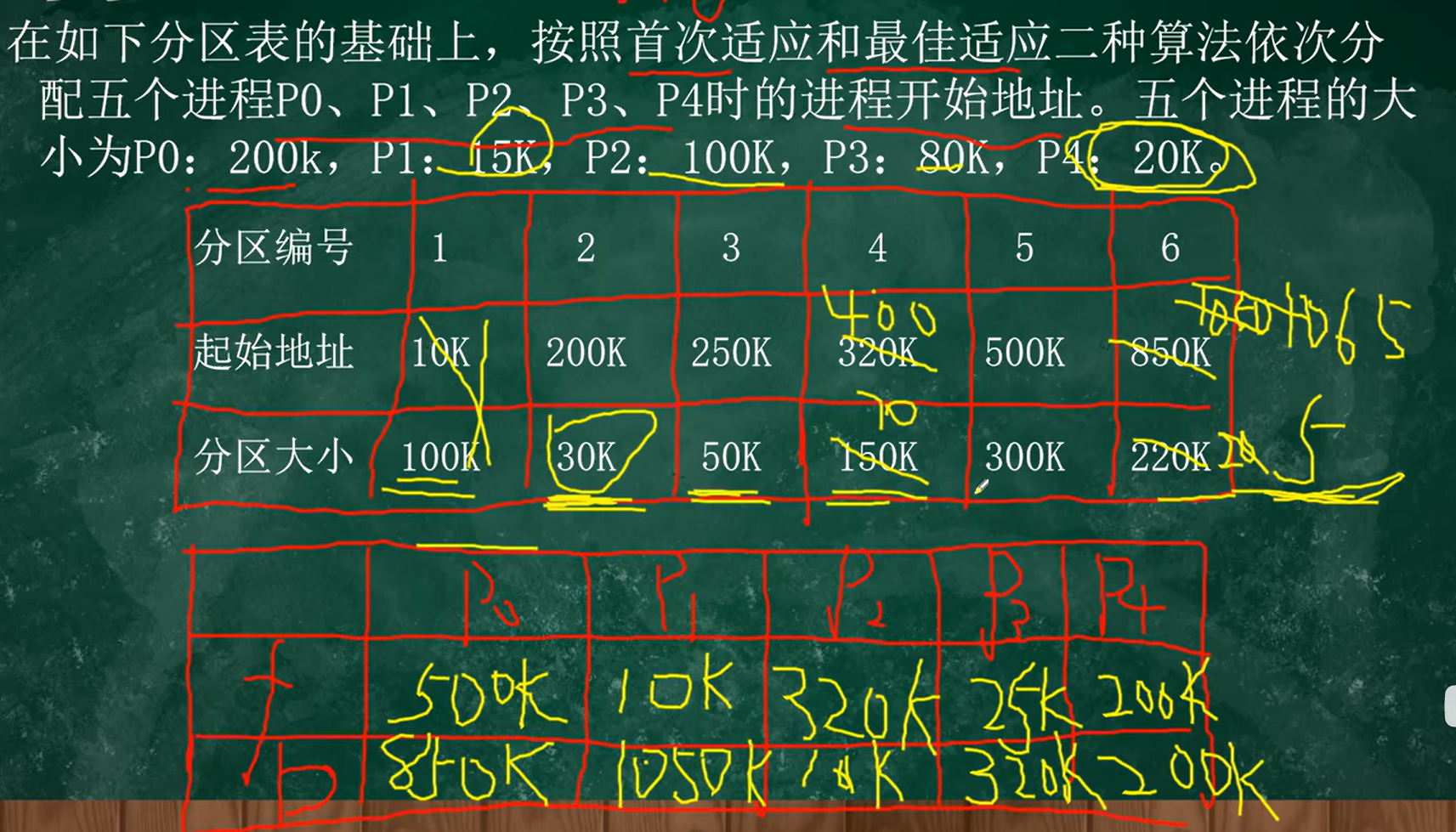
注意要不斷更新喔
循環首次適應算法(NF)—— 鄰近適應
算法思想:
從FF演變而來
按地址遞增次序,下一次分配不是從頭開始,而是從上一次分配的地方開始
最佳適應算法(BF)
最容易產生內存碎片
算法思想:
空閑分區按容量遞增排列
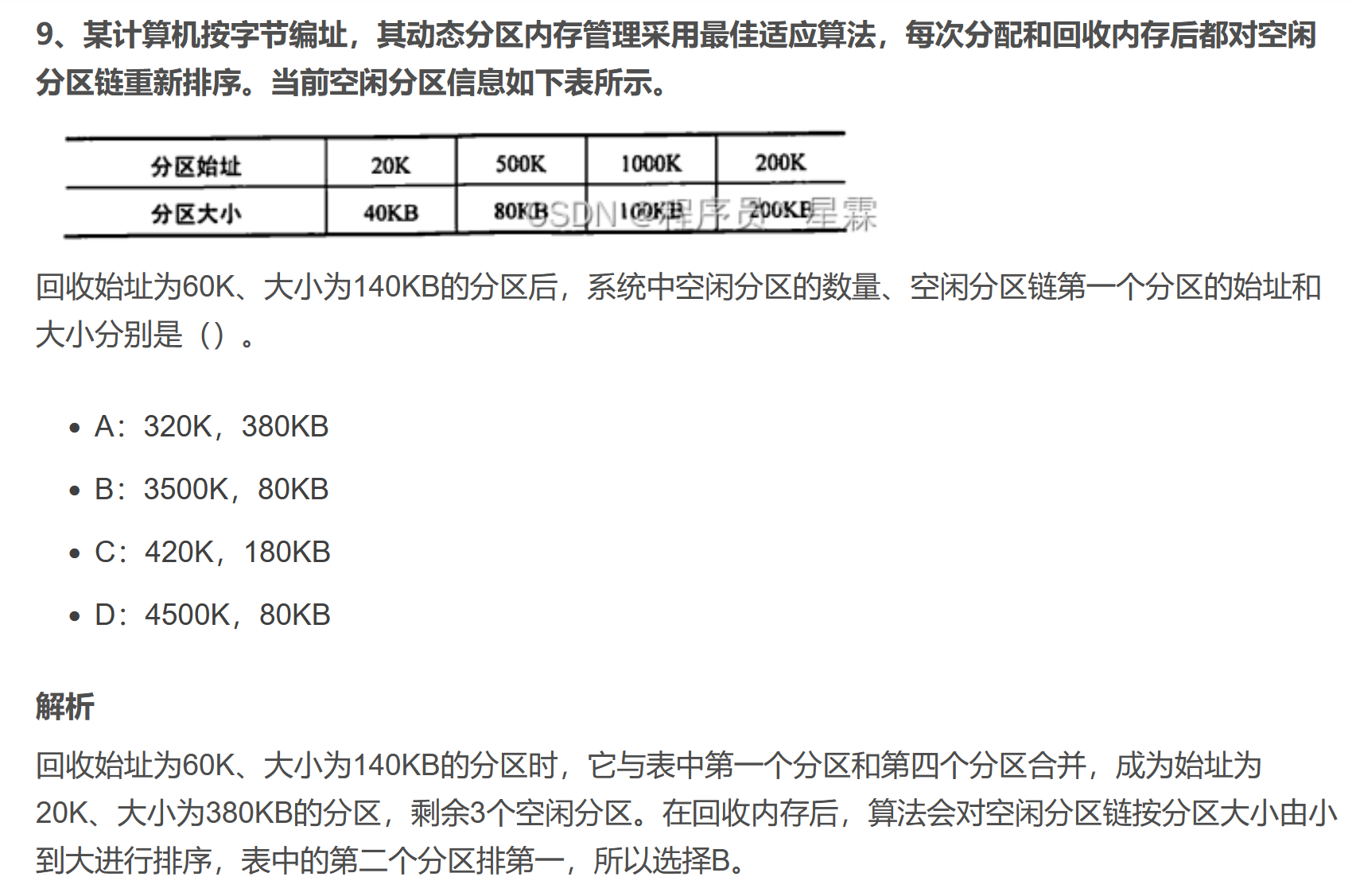
等待分配時,空閑區間從小到大排序

最壞適應算法(WF)
算法思想:空閑分區按容量遞減排列
從鏈首開始查找,找到第一個符合要求的空閑分區
時間上比BF快一點
但是在空間上較差,容易產生一些碎片
例題:
可重定位分區分配方式
-
內部碎片:指分配給程序的存儲空間中未被利用的部分
-
外部碎片:程序外 不同程序之間的碎片
內存擴充:覆蓋與交換(了解)
- 覆蓋技術:解決大程序 小內存矛盾
基本分頁存儲管理方式
什么是頁表?
頁表是分頁式存儲管理使用的數據結構。一個進程分為多少頁,它的頁表就有多少行。每一行記錄進程的一頁和它存放的物理塊的頁號、塊號對應關系。頁表用于進行地址變換。
作用:實現頁號到物理塊號的地址映射
基本分段存儲管理方式
虛擬存儲器的基本概念
請求分頁存儲管理方式
頁面置換算法
地址
邏輯地址:
因為用戶程序和非 常駐的系統程序隨機且動態進入系統,編譯和鏈接程序無法預先確定內存存儲位置,所以采用邏輯地址。編譯時程序中各個地址總是以“0”作為起始地址
相對地址,虛地址
采用相對地址,其首地址為0,其余 指令中的地址相對于首地址而編址
不能用邏輯地址在內存中讀取信息
**物理地址:**絕對地址,實地址
!!高頻考點!!
地址重定位
原因:
-
地址空間的邏輯地址往往與分配到存儲空間的物理地址不一致
-
處理機必須使用物理地址 就像發快遞
方法:
邏輯地址轉為物理地址的方法:
首先,計算該邏輯地址所在的頁號和頁內偏移
? 頁號 = 邏輯地址 / 頁面大小(取整)
? 頁內偏移 = 邏輯地址 % 頁面大小
其次,在確定該邏輯地址合法的情況下,查頁表,根據頁號得到對應的物理塊號
最后,物理地址 = 快號 x 頁面大小 + 頁內偏移
上面這是計算公式,下面看一個真實的例題

當頁面大小為1K 即2的10次方 所以需要10位表示頁內地址 也就是說每頁大小是2的10次方B
區分:
MB
Mb
大寫是Byte 小寫是bit
裝入和鏈接(概念性 了解即可)
裝入:
- 絕對裝入
在編譯時,實現知道用戶程序的絕對地址,直接訪問即可
該裝入方式,僅適用于單道程序(但是效率太低,幾乎沒有了)
- 可重定位
實現不知道用戶程序在內存的駐留位置,而是在裝入時根據內存的實際情況把相對地址(邏輯地址)轉換為絕對地址,在裝入時進行地址轉換
在裝入時一次定位 后面不再修改 稱為靜態可重定位
特點:
- 每個程序分配一個連續的存儲區
- 不能移動
- 動態運行時
加載到內存時原樣裝入,在運行時送入重定位寄存器
鏈接:
- 靜態鏈接 => 絕對裝入
編譯器編譯完成后進行鏈接,多個obj文件鏈接形成可執行exe文件
-
裝入時動態鏈接
-
運行時動態鏈接
分頁存儲管理
思考問題:
- 頁表給誰用 物理器件
- 頁表內容
- 頁表誰來維護
- 邏輯地址與物理地址之間的轉化圖
一些計算
單位:

例題:

根據給定的邏輯地址結構,可以看出:
- 偏移量占用 12 位:這意味著每個頁內的偏移量大小為 2^12=4096 字節。
- 頁號占用 20 位:這表示邏輯地址空間中有 2^20 B基本單位 個頁 = 1MB
因此,頁的大小為 4096 字節 = 4KB。
對于一級頁表的分頁存儲管理,每個頁表項大小為 4 字節,而邏輯地址中的頁號占用 20 位,因此最大頁表項數為 2^20 個。 N頁表項數 * S頁表項大小
所以,頁表的最大占用空間為 2^20×4字節,即 4 MB。
兩級和多級頁表
頁表是可以離散的,但是物理地址必須連續
為什么物理地址是連續的?
硬件得到 頁表的基地址 如果不連續 則頁表的索引號找到的物理地址可能不存在 導致出錯
例題:
邏輯地址空間64頁 每頁1024B 內存共有32個存儲塊
2^6 2^10 => 邏輯地址16位
塊大小和頁大小一定相同 都是1KB
內存空間為 32 * 1KB = 32KB
段頁式存儲管理
需要訪問內存3次
libc.so 在物理內存中 主存 也就可以實現共享
第五章 虛擬存儲器
概述
局部性原理
- 時間局部性
指令或者數據在訪問過后的不久可能再次被訪問 (如存在循環)
- 空間局部性
數組 開辟相鄰的空間
常規存儲器:
- 一次性:程序運行時作業一次性全部裝入內存
- 駐留性:直到程序結束才會在內存中退出
虛擬存儲器定義
虛擬存儲器,是一個內存管理技術,強調軟件系統。具有請求調入和置換功能,能從邏輯上對內存容量進行擴充的一種存儲器管理機制。將程序可以使用的內存與物理內存解耦
- 物理內存大小由誰決定?
內存條設置多少就是多少
- 邏輯地址空間大小由誰決定?
CPU的地址位寬決定
- 邏輯地址與物理地址的映射關系?
頁表決定
頁表給硬件使用,軟件操作系統來維護
通常是動態更新
邏輯地址區間 可以大于 物理內存大小 從而成為虛擬擴充 類比從北京到上海不斷換兩塊鐵軌 更新
每個程序可以使用同樣大小的邏輯地址空間
如果指向同一個頁框數據段,了解沙箱逃逸

- 邏輯地址與物理地址不再是1對1關系
虛擬內存三個主要特征:
- 多次性*:無需在作業運行時一次性全部裝入到內存,而是允許被分成多次調入內存
- 對換性*:在作業運行時無需一直常駐內存,可以將作業換入換出
- 虛擬性:從邏輯上擴充內存容量,真實物理內存不變,使用戶看到的內存容量遠大于實際的容量
不裝入內存:
不是什么都不做,而是給他設置頁表,但不分配物理內存來處理代碼
好處:
- 提高內存利用率
實現方法
分頁請求系統
基于分頁系統,增加請求調頁功能和頁面置換功能,從而形成頁式虛擬存儲系統
置換時以頁面為單位
請求分段系統
基于分段系統,增加請求調段和分段置換功能,從而形成段式虛擬存儲系統
置換時以段為單位
請求分頁系統存儲管理
該系統建立在基本分頁基礎上,增加了請求調頁功能和頁面置換功能
每次調入和換出的基本單位都是長度固定的頁面
-
請求分頁中的硬件支持
- 請求頁表機制
作用:用戶地址空間的邏輯地址 – > 內存空間的物理地址
頁表項:
頁號 物理塊號 狀態位P 訪問字段A 修改位M 外存地址 指示該頁是否已調入內存 記錄本頁在一段時間內被訪問的次數或最近未被訪問的時間=>用來置換用 表示該頁在調入內存后是否被修改過,如果修改過,換出時需要重寫至外存 - 缺頁中斷機構
在請求分頁系統中,當所要訪問的頁面不在內存時,產生缺頁中斷,請求OS將所缺頁調入內存
與一般中斷有兩個方面的明顯區別:
- 缺頁中斷在指令執行期間產生和處理中斷信號
- 一條指令在執行期間可能產生多次缺頁中斷
-
地址變換機構
如何從邏輯地址變為物理地址:
? 首先檢索快表
例題:邏輯地址轉物理地址
信息提取:
每頁1KB => 1024 B =>2^10 B => 頁內地址10位
32個頁面 => 2^5 =>頁號5位
主存16KB => 2^4 => 4個框
物理塊分配策略
- 內存分配策略
- 固定分配局部置換
- 可變分配全局置換
- 置換策略
- 全局置換
- 局部置換
物理塊的分配算法(固定分配時):
補充:請求分段存儲管理
請求段頁式存儲管理
頁面置換算法
最佳置換算法
置換永不使用或未來最長時間內不會被訪問的頁面
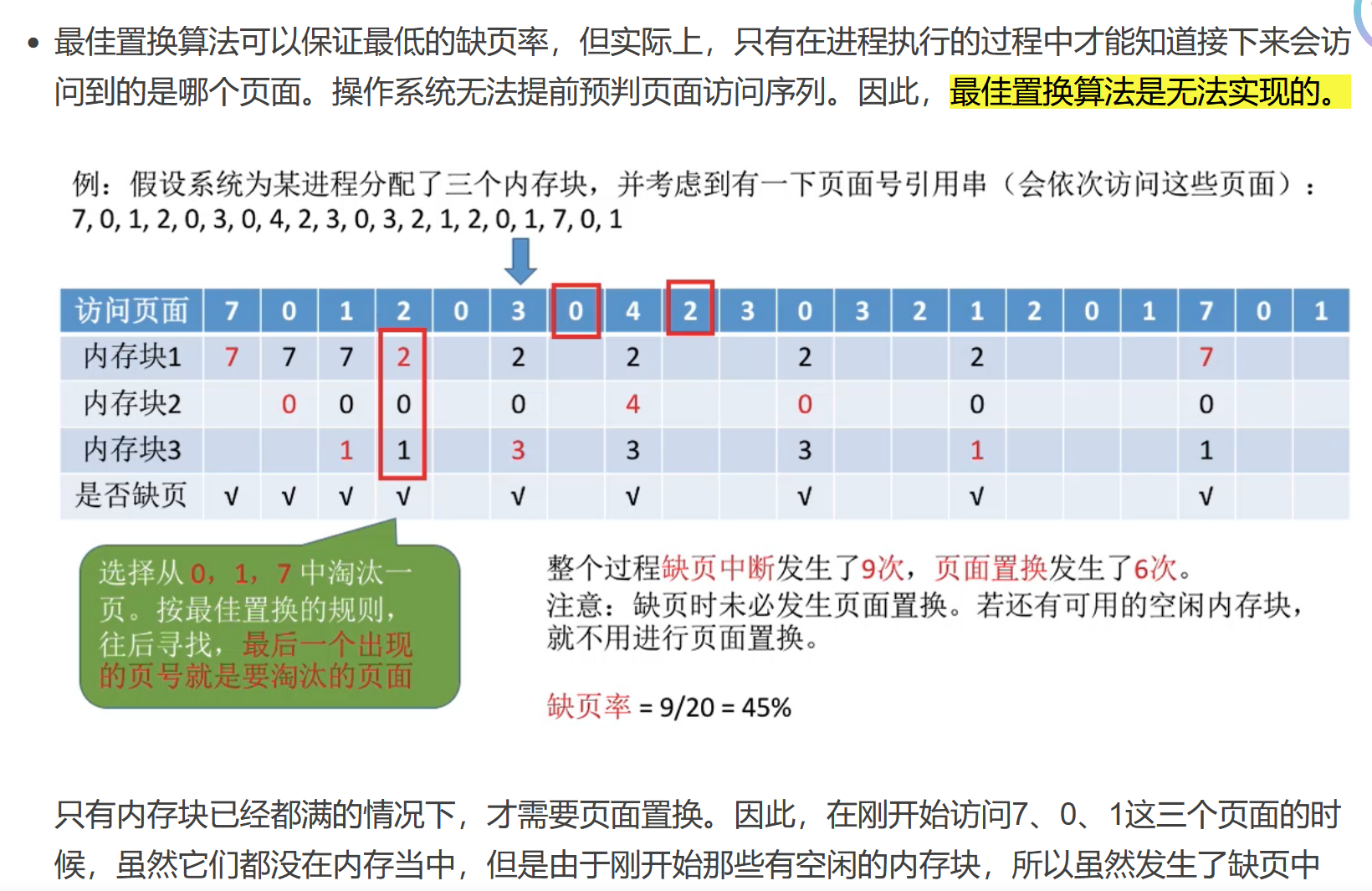
參考:https://blog.csdn.net/weixin_45990326/article/details/120031133
只有缺頁才會做替換 所以最后一個出現的頁號是 7 然后是1 0 4 3
先進先出FIFO置換算法
原則:淘汰最先進入內存的頁面,即選擇在內存中駐留時間最久的頁面予以淘汰
最近最久未使用LRU置換算法
選擇到當前時間為止,訪問次數最少的頁面淘汰,給每個頁面設置訪問計數器,每當頁面被訪問,訪問計數器加1。當發生缺頁中斷時,淘汰計數值最小的頁面,同時一定要注意,將所有計數器清零。
Clock置換算法(最近未用NRU置換) 可能會考哦
改進型Clock算法
相比于Clock算法,添加了修改位
| A \ M | 0 | 1 |
|---|---|---|
| 0 | 00(1)最佳淘汰頁 后面的序號表示優先級 | 01(2) |
| 1 | 10(3) | 11(4) |
10相比01更可能發生缺頁
”抖動“與工作集(not important Learn by self)
請求分段式存儲管理方式 (不如分頁重點)
- 請求分段中的硬件支持
- 段表機制
- 缺段中斷機構
- 地址變換機構
- 分段共享與保護
- 共享段表
- 共享段的分配與回收
| 段名 | 段長 | 段的基址 | 存取方式 | 訪問字段A | 修改位M | 存在位P | 增補位 | 外存地址 |
|---|---|---|---|---|---|---|---|---|
缺段中斷機構
第六章 輸入輸出系統
I/O系統的基本功能
- 隱藏物理設備的細節
- 與設備的無關性
- 提高處理機和I/O設備的利用率
- 對I/O設備進行控制
- 確保對設備的正確共享
- 錯誤處理
I/O系統的層次結構和模型
- 層次結構
| 用戶層軟件 | 用于實現用戶與I/0設備交互 |
|---|---|
| 設備獨立性軟件 | 用于實現用戶程序與設備驅動器的統一接口、設備命令、設備保護,以及設備分配與釋放等。 |
| 設備驅動程序 | 與硬件直接有關,用來具體實現系統對設備發出的操作指令,驅動I/0設備工作 |
| 中斷處理程序 | 用于保存被中斷進程的CPU環境,轉入相應的中斷處理程序進行處理,處理完后恢復現場,并返回到被中斷的進程 |
小知識點:
舉例設備驅動程序完成的內容:
- 向設備寄存器寫命令
- 檢查用戶是否有權使用設備 IO請求的合法性
- 解釋用戶的IO請求,并將請求轉化為具體的IO操作
- 及時響應由控制器或通道發來的中斷請求
- 了解IO設備的狀態,傳送有關參數,設置設備的工作方式
不是的舉例為:
- 將二進制整數轉化為ASCII碼以便打印
- 控制IO設備的IO操作
設備的獨立性:指用戶不指定特定的設備,而指定邏輯設備,使得用戶作業和物理設備獨立
I/O系統接口
- 塊設備接口
- 塊設備
- 隱藏了磁盤的二維結構
- 將抽象命令映射為低層操作
- 流設備接口
- 字符設備
- get和put操作
- in-control指令
- 網絡通信接口
I/O設備
類型:
-
按使用特性分類
存儲設備(外存、輔存) 其中磁盤適合作為共享設備 I/O設備(輸入設備,輸出設備,交互式設備) -
按傳輸速率分類
低速設備 中速設備 高速設備
設備與控制器之間的接口
設備不是直接與CPU進行通信,而是與設備控制器通信,所以設備與設備控制器之間存在接口
設備獨立性軟件,也稱設備無關軟件。
為了提高0S的可適應性和可擴展性,在現代0S中都毫無例外地實現了設備獨立性,也稱設備無關性。
基本含義:應用程序獨立于具體使用的物理設備。為了實現設備獨立性而引入了邏輯設備和物理設備兩概念。在應用程序中,使用邏輯設備名稱來請求使用某類設備;而系統在實際執行時,還必須使用物理設備名稱。
優點:
-
設備分配時的靈活性
- 易于實現I/0重定向(用于I/0操作的設備可以更換(即重定向),而不必改變應用程序。
設備控制器
功能:控制一個或多個I/O設備,以實現I/O設備和計算機之間的數據交換
工作流程:接收CPU發來的命令,去控制I/O設備工作,使處理機能夠從繁雜的設備控制事務中解脫出來。
分類:
- 用于控制字符設備的控制器
- 用于控制塊設備的控制器
基本功能:
- 接受和識別命令
- 數據交換
- 標識和報告設備的狀態
- 地址識別
- 數據緩沖區
- 差錯控制
組成:
- 設備控制器與處理機的接口
- 設備控制器和設備的接口
- I/O邏輯
I/O通道
背景:CPU和I/O設備之間增加設備控制器后,大大減少CPU對I/O的干擾,當主機所配置的外設很多,CPU仍然負擔很重,所以在CPU和設備控制器之間又增設了I/O通道
目的:建立獨立的I/O操作,不僅使數據的傳送獨立于CPU,而且希望對I/O操作的組織、管理及其結束處理盡量獨立,保證CPU有更多時間去進行數據處理,總結來說就是替CPU分擔繁雜的I/O任務
特點:IO通道本質是一種特殊的處理機
- 指令類型單一
- 通道沒有自己的內存,與CPU共享內存
類型:
- 字節多路通道
- 數組選擇通道
- 數組多路通道
瓶頸:通道價格昂貴, 致使機器所設置的通道數量有限,進而造成系統吞吐量下降
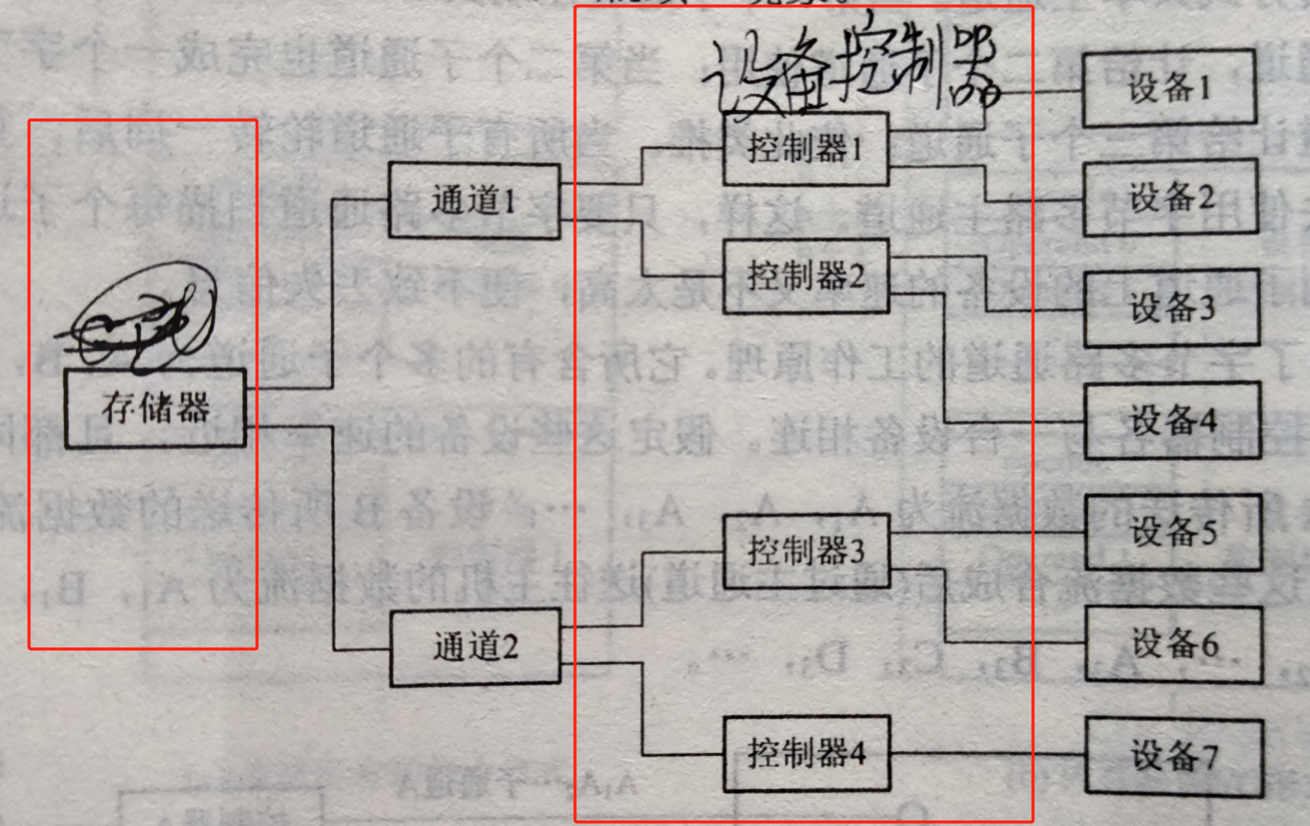
如上圖所示,當設備1和設備3都請求通道1的時候就會出現沖突
但是我們的目標不是增加通道
所以瓶頸的解決方案為:增加通路 而不增加通道
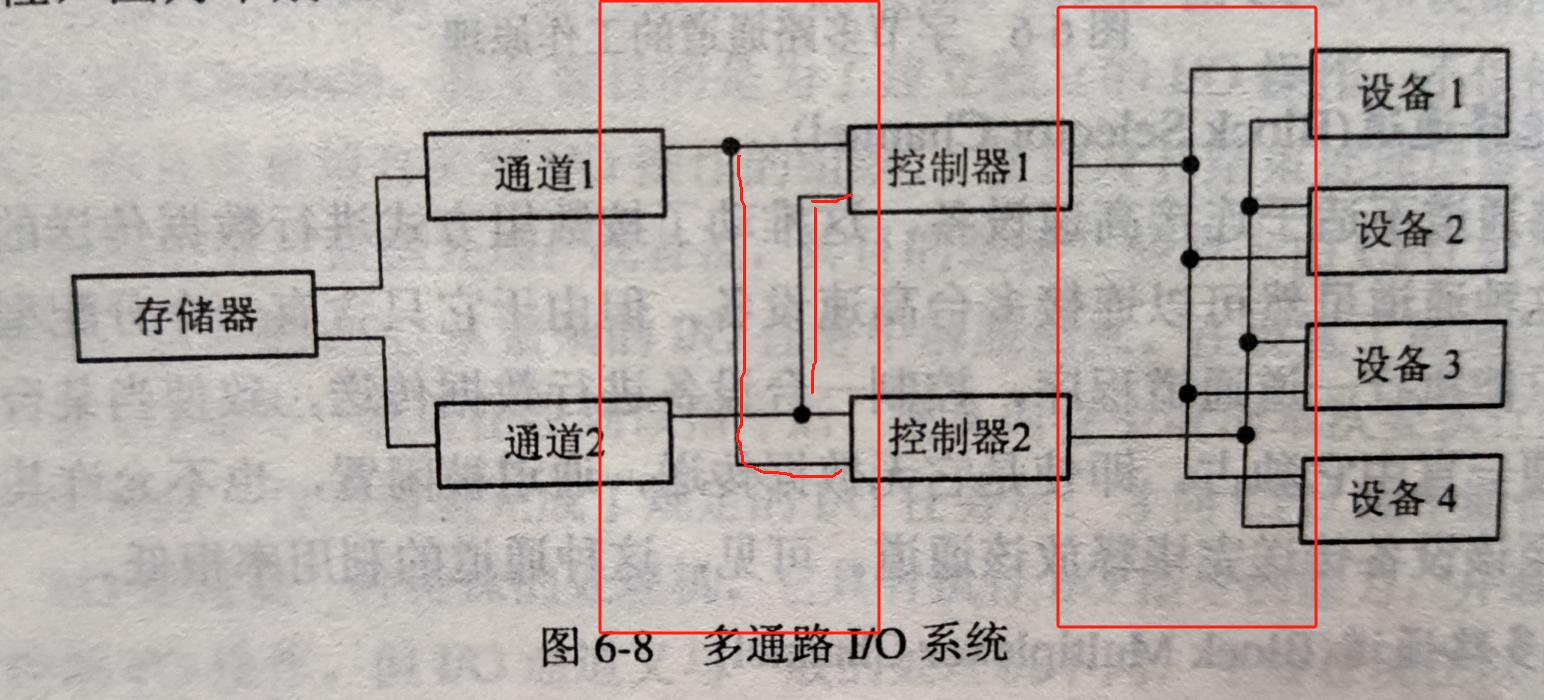
增加控制器與通道之間的通路 也增加設備與控制器之間的通路
小知識點:利用通道實現了內存和外設之間數據的快速傳輸
中斷
基本簡介
中斷:CPU對IO設備發來的中斷信號的一種相應,CPU暫停正在執行的程序,保留CPU環境后,自動地轉去執行該IO設備的中斷處理程序,執行完后,再回到端點,繼續執行原來的程序。中斷是由外部設備引起的,故又稱外中斷 CPU只有在處于中斷允許狀態時,才能響應外部設備的中斷請求
陷入:CPU內部事件引起的中斷,這類中斷稱為內中斷或陷入(trap)
中斷向量表:每種設備配以相應的中斷處理程序,并把該程序的入口地址放在中斷向量表的一個表項中,當IO設備發來中斷請求信號,中斷控制器確定該請求的的中斷號,根據設備終端號去查找中斷向量表,從中取得該設備中斷處理程序的入口地址,轉入中斷處理程序執行
中斷優先級:對設備發出的中斷信號源定級
對多中斷源的處理方式:
- 屏蔽(禁止)中斷
- 嵌套中斷
中斷處理程序
步驟:
- 測定是否有未響應的中斷信號
- 保護被中斷進程的CPU環境
- 轉入相應的設備處理程序
- 中斷處理
- 恢復CPU的現場并退出中斷
小知識點:
硬件采用了中斷和通道技術,使得CPU與外設能并行工作
首先獲得鍵盤輸入信息的程序是中斷處理程序
需要外存的支持:輸入井和輸出井就是在磁盤(外存)開辟的存儲空間
需要多道程序設計技術的支持:實現IO的輸入輸出控制
需要注意:設備與輸入輸出井之間的數據傳送是系統控制的不是用戶作業控制設備控制的
設備驅動程序
對IO設備的控制方式
與設備無關的IO軟件
基本概念
軟件
設備分配
邏輯設備名到物理設備名
背景:用戶程序請求使用IO設備 應當用邏輯設備名,而操作系統內部設備管理設備使用的是物理設備名,因此需要再系統中配置一張邏輯設備表,用于將邏輯設備名映射為物理設備名
用戶層的IO軟件
系統調用和庫函數(dll)
假脫機系統(spooling)
直觀類比感受:
多道程序技術:將一臺物理CPU虛擬為多臺邏輯CPU,允許多個用戶共享一臺主機
假脫機技術:將一臺物理IO設備虛擬為多臺邏輯IO設備,允許多個用戶共享一臺物理IO設備
目的:提高獨占設備的利用率
脫機就是指和CPU分離
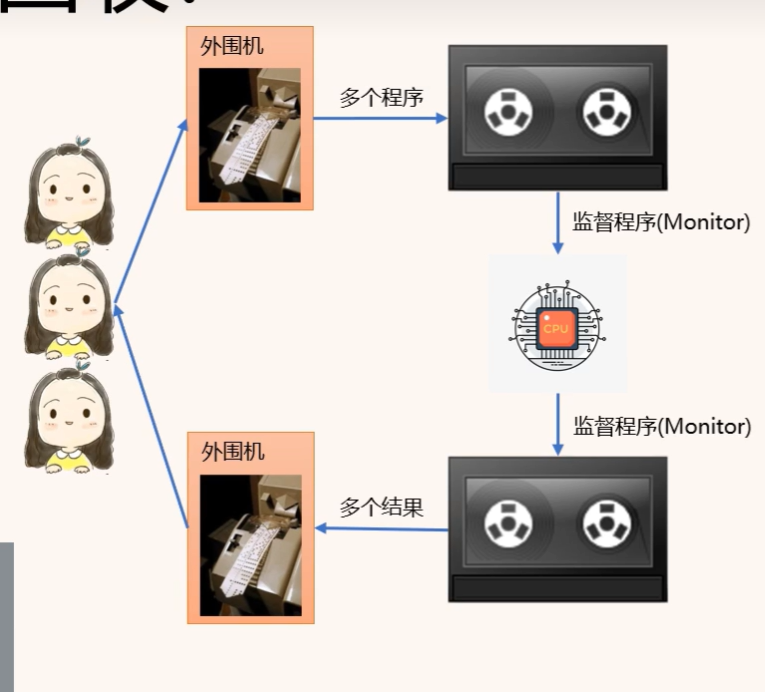
比如這種 屬于真脫機,程序員與CPU之間放了一個外圍機來處理輸入輸出操作
假脫機顧名思義就是指不真正脫離
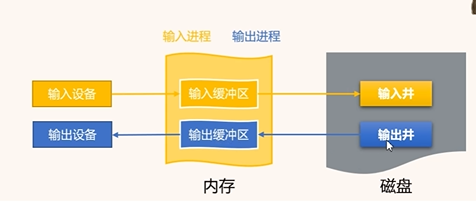
輸入設備速度過慢,CPU處理快,所以建立了井,其作用就是攢數據,不用CPU在那一直等著輸入,而是到達一定數據量后一并操作,提高處理效率
組成:
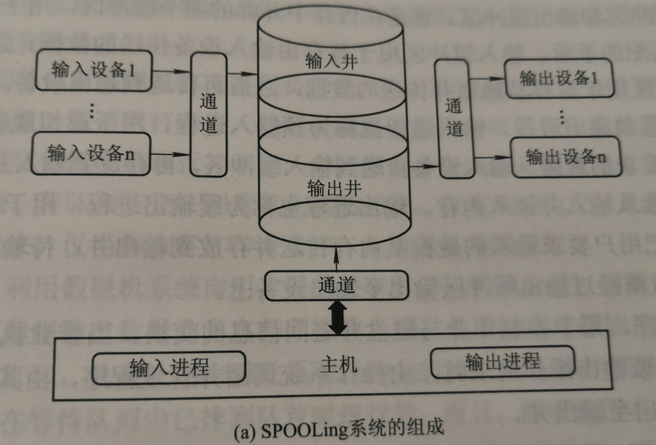
工作原理:
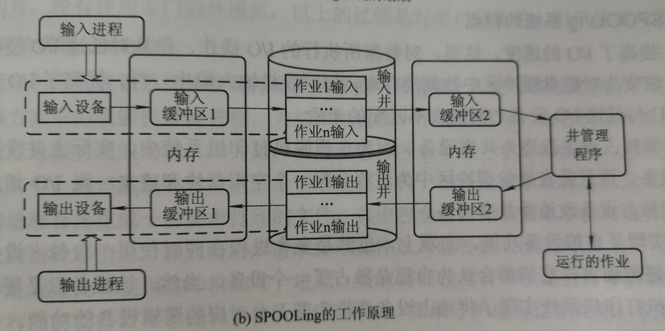
小知識點:
在假脫機IO技術中,對打印機的操作實際上是用對磁盤存儲的訪問,用以代替打印機的部分通常稱作虛擬設備
SPOOLing技術將獨占設備改造為共享設備,實現虛擬設備功能,提高獨占設備的利用率
緩沖區管理
基本概念
引入緩沖的原因:
- 緩解CPU和IO設備間速度不匹配的矛盾
- 減少對CPU的中斷頻率,放寬對中斷響應時間的限制
- 提高CPU和IO設備之間的并行性
緩存
單緩沖區
雙緩沖區
環形緩沖區
緩沖池
便于使得多個進程能有效地同時處理輸入和輸出
磁盤存儲器的性能和調度
磁盤性能簡述
- 數據的組織和格式
磁盤設備的特點:
- 傳輸速率較高,以數據塊為傳輸單位
- IO控制方式常采用DMA方式
- 可以尋址,隨機地讀寫任意數據塊
系統將數據讀到內存的過程順序:
- 初始化DMA控制器并啟動磁盤
- 從磁盤傳輸一塊數據到內存緩沖區
- DMA控制器發出中斷請求
- 執行“DMA結束”中斷服務程序
DMA:用來提供在外設和存儲器之間或者存儲器和存儲器之間的高速數據傳輸,無須CPU干預,節省CPU的資源來做其他操作
-
磁盤的類型
-
磁盤訪問時間
讀取扇區時間例題:

磁盤轉速為3000轉每分鐘,那么轉1圈耗時60 / 3000 = 0.02s = 20ms
盤片劃分10個扇區 則讀取一個為20ms / 10 = 2ms
P338 例題16
磁盤調度算法
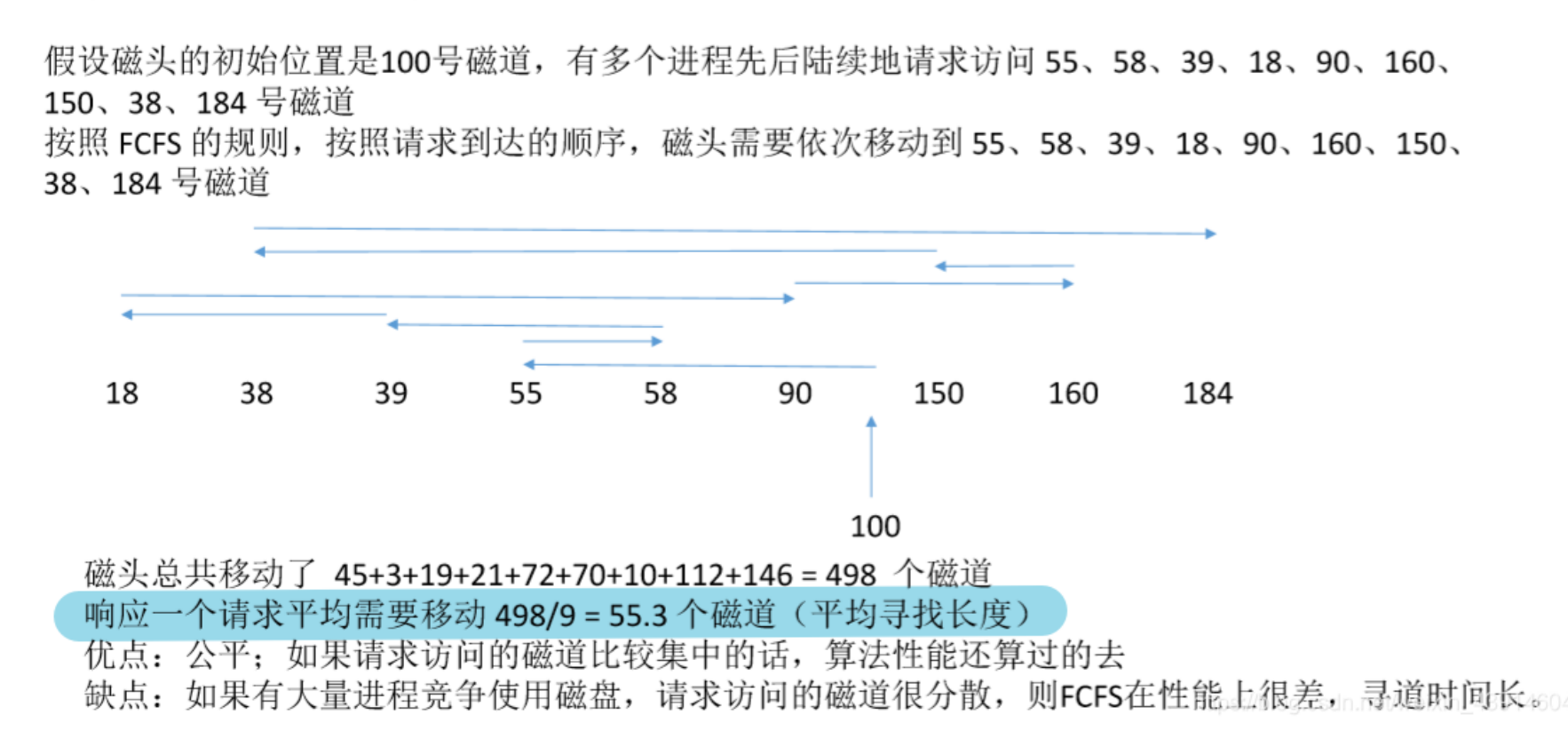
- 早期
- 先來先服務FCFS
按照給出的順序逐個計算
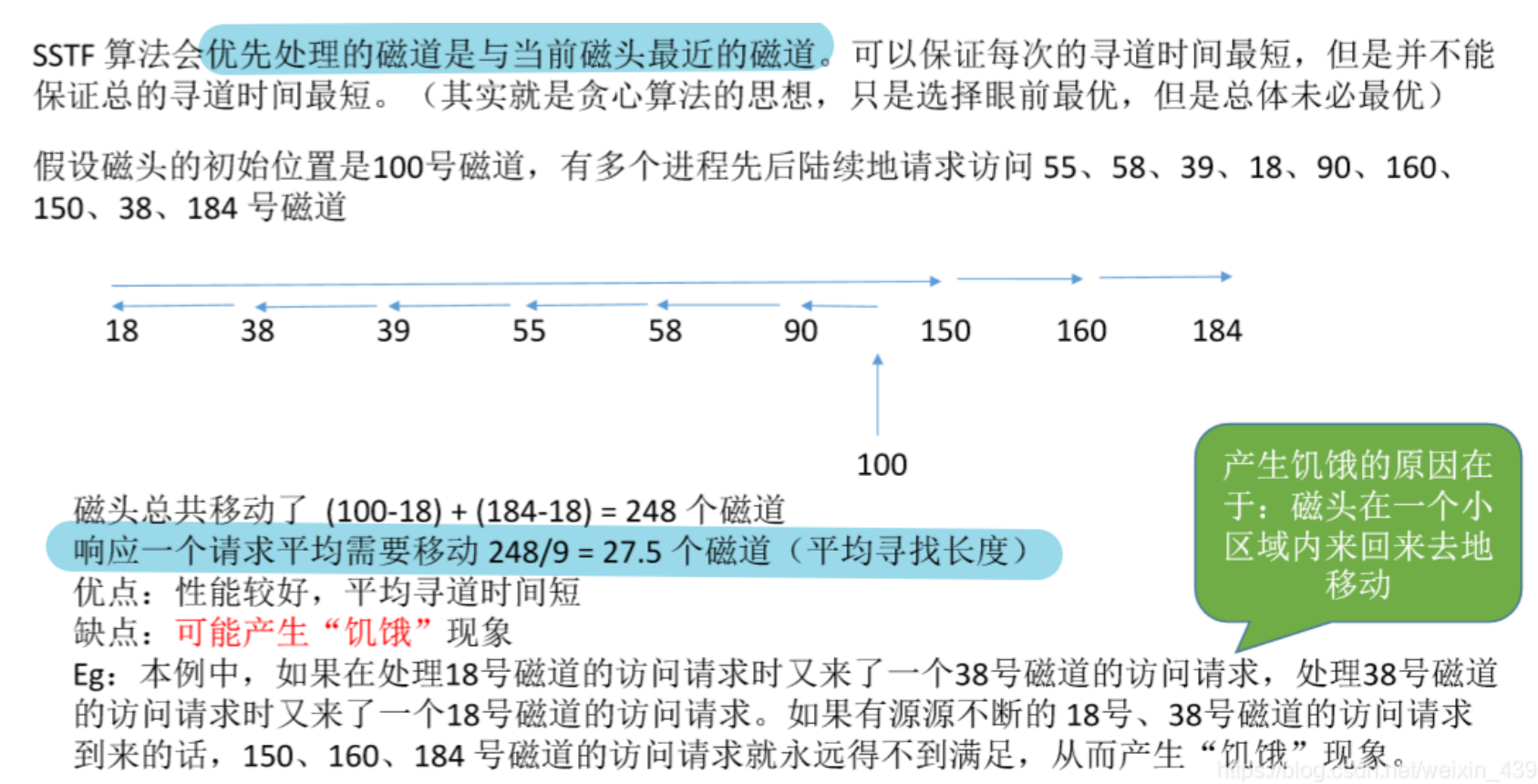
- 最短尋到時間優先SSTF
不斷尋找最近的 保證眼前最優
- 基于掃描
- 掃描(SCAN)算法
從開始位置往大增 直到增到最大后往回縮 類似電梯喔 注意這個方向是提前規定的
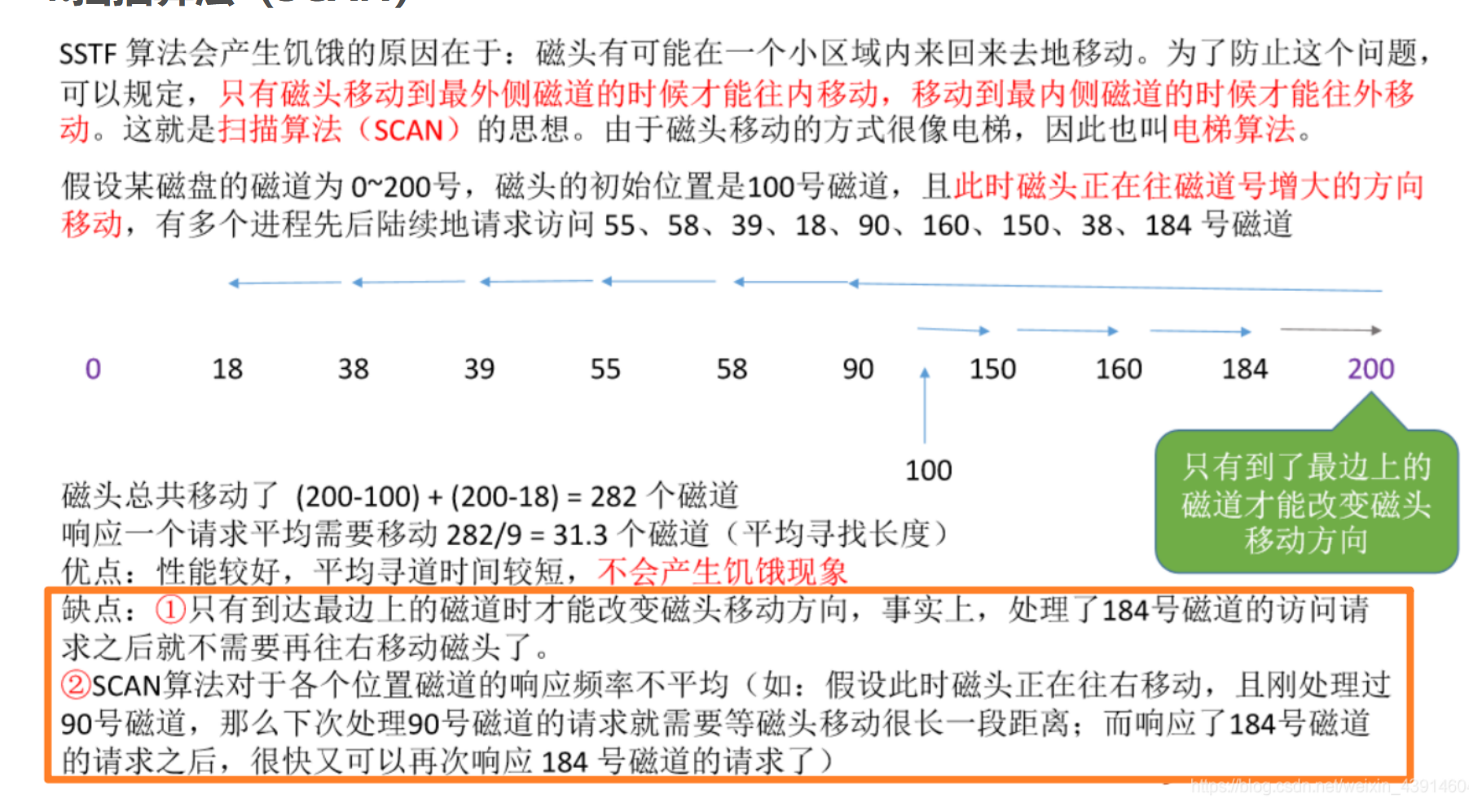
小技巧:
判斷磁頭的移動方向

題目中提示到,完成了1250然后到3500 所以方向是先向大號方向
- 循環掃描(CSCAN)算法
注意看方向
始終同方向
- NStepSCAN算法
小知識點:
磁臂黏著:磁臂停留在某處不動,如有一個或幾個進程對某一磁道有較高的訪問頻率,即這個進程反復請求對某一磁道的IO操作,從而壟斷整個磁盤設備。該情況在SSTF、SCAN、CSCAN幾種調度算法中都可能出現
- FSCAN算法
第七章 文件管理
文件和文件系統
管理功能:將管理的程序和數據通過組織為一系列文件的方式實現
文件:具有文件名的若干相關元素的集合
元素:通常是記錄
記錄:一組有意義的數據項的集合
綜上 數據組成可以分為數據項、記錄、文件三級
下面展開詳細解釋
- 數據項
最低級的數據組織形式
分類:
(1) 基本數據項
描述一個對象的某種屬性的字符集,是數據組織中可以命名的最小邏輯數據單位 如:描述一個學生的基本數據項:學號、姓名、年齡
(2) 組合數據項
若干個基本數據項組成,簡稱組項
- 記錄
一組相關數據項的集合,用于描述一個對象在某方面的屬性。關鍵字是唯一能標識一個記錄的數據項。
- 文件
由創建者所定義的、具有文件名的一組相關元素的集合,可以分為有結構文件和無結構文件。
- 有結構的文件中:文件由若干個相關記錄組成
- 無結構文件中:被看成是一個字符流
文件是文件系統中一個最大的數據單位
文件屬性包括:
- 文件類型
- 文件長度
- 文件的物理位置
- 文件的建立時間
文件類型分類:
- 按用途分裂:
- 系統文件
- 用戶文件
- 庫文件
- 按文件中數據的形式分類:
- 源文件
- 目標文件
- 可執行文件
- 按存取控制屬性分類
- 可執行文件
- 只讀文件
- 讀寫文件
- 按組織形式和處理方式分類
- 普通文件
- 目錄文件
- 特殊文件
文件系統的層次結構
| 用戶(程序) 自上而下 | |
|---|---|
| 文件系統接口 | 兩種類型:命令接口和程序接口 |
| 對對象操縱和管理的軟件集合 | 文件管理系統的核心部分 |
| 對象及其屬性 | 管理的對象有:文件、目錄、磁盤(磁帶)存儲空間 |
文件的邏輯結構
用戶看到的文件成為邏輯文件,在系統中所有文件存在以下兩種大類:
- 文件的邏輯結構:文件由一系列的邏輯記錄組成的,是用戶可以直接處理的數據及其結構,獨立于文件的物理特性,又稱為文件組織
- 文件的物理結構:又稱文件的存儲結構,指系統將文件存儲在外存上所形成的一種存儲組織形式,是用戶不能看見的。
對文件的邏輯結構進行分類:
-
有結構文件,指由一個以上的記錄構成的文件,又稱為記錄式文件
- 定長記錄
- 變長記錄
如大量的信息管理系統和數據庫系統中,廣泛采用了有結構的文件形式
-
無結構文件,指由字符流構成的文件,又稱流式文件
? 如在系統中運行的大量的源程序、可執行文件、庫函數等
按文件的組織方式分類:
- 順序文件
排列方式:
- 串結構
- 順序結構
優點:對文件中的記錄進行批量存取
缺點:增加或者刪除一個記錄比較困難
訪問 => 記錄尋址
為了訪問順序文件中的一條記錄,首先應找到該記錄的地址,有兩種方法:
-
隱式尋址方法
-
顯示尋址方法
-
索引文件
-
按關鍵字建立索引
-
具有多個索引表的索引文件
- 索引順序文件
-
索引順序文件的特征
-
一級索引順序文件
-
二級索引順序文件
文件目錄
對于目錄管理的要求如下:
-
實現”按名存取“
-
提高對目錄的檢索速度
-
文件共享
-
允許文件重名
文件控制塊FCB(File Control Block)
小tips:
在一個文件被用戶進程首次打開的過程中,操作系統需做的是將文件控制塊讀到內存中
文件系統中,文件訪問控制信息存儲的合理位置是文件控制塊
通常含有三類信息:
-
基本信息類
-
存取控制信息類
-
使用信息類
索引節點
-
索引結點的引入
-
磁盤索引結點
-
內存索引結點
簡單的文件目錄
-
單擊文件目錄
-
兩級文件目錄
小tips:
- 采用多級目錄結構后,不同用戶文件的文件名相同或不同均可
樹形結構目錄(Tree-Structured Directory)
目錄查詢技術
-
線性檢索法
-
Hash方法
文件共享
兩種大方式實現共享
- 基于有向無循環圖實現文件共享
-
有向無循環圖DAG
-
利用索引結點
小tips:
基于索引結點的共享會在文件主刪除其共享文件后留下懸空指針
- 利用符號鏈接實現文件共享
小tips:
若多個進程共享同一個文件F,在系統打開的文件表中僅有一個表項包含F的屬性
文件保護
保護域(Protection Domain)
-
訪問權
-
保護域
-
進程和域間的靜態聯系
-
進程和域間的動態聯系方式
訪問矩陣
利用矩陣描述系統的訪問控制,并把該矩陣成為訪問矩陣(Access Matrix)
切換
修改
所有權
控制權
實現:
-
訪問控制表
-
訪問權限(Capabilities)表
分類:
大類上:
- 文本文件 記事本打開后是printable
- 二進制文件 記事本打開后是亂碼
結構上:
- 無結構:如txt(不可執行) js、bat(可執行)
- 有結構:如xml 、 ini、obj(不可執行) dll、exe、so(可執行)
索引文件:
兩部分組成:
- 索引表:存放元數據
- 主文件
第八章 磁盤存儲器的管理
外存的組織方式
連續組織方式
鏈接分配
FAT技術
索引分配
-
單級索引
-
多級索引
文件存儲空間的管理
空閑表法和空閑鏈表法
位示圖法
利用二進制的一位來表示磁盤中一個盤塊的使用情況,用0和1表示兩種狀態空閑和已分配,所有盤塊對應的位構成一個集合,稱為位示圖。本質就是一個二維數組map[m, n]
如
盤塊的分配:
三步走
- 順序掃描位示圖
先按順序找到一個表示空閑的二進制位,當0表示空閑時,就先找到第一個0
- 轉化
將找到的一個或一組二進制位轉換成預支對應的盤塊號,其實說白了就是根據行列號轉化成它在這個二維數組中的第幾個,對應公式如下:
b = n(i - 1) + j 其中i和j是當前行列號 注意是從1開始的 n代表每行的個數
- 修改位示圖
令map[i, j] = 1










、重載的理解)



)




