文章目錄
- 1. 寫在前面
- 2. 特征分析
- 3. 接口分析
- 3. 補JS環境
- 4. 補后綴參數
【🏠作者主頁】:吳秋霖
【💼作者介紹】:擅長爬蟲與JS加密逆向分析!Python領域優質創作者、CSDN博客專家、阿里云博客專家、華為云享專家。一路走來長期堅守并致力于Python與爬蟲領域研究與開發工作!
【🌟作者推薦】:對爬蟲領域以及JS逆向分析感興趣的朋友可以關注《爬蟲JS逆向實戰》《深耕爬蟲領域》
未來作者會持續更新所用到、學到、看到的技術知識!包括但不限于:各類驗證碼突防、爬蟲APP與JS逆向分析、RPA自動化、分布式爬蟲、Python領域等相關文章
作者聲明:文章僅供學習交流與參考!嚴禁用于任何商業與非法用途!否則由此產生的一切后果均與作者無關!如有侵權,請聯系作者本人進行刪除!
1. 寫在前面
??瑞數相關的教程在網上可以說是層出不窮,各種技術方案均有!開源社區上多款針對瑞數定制的補環境框架,現在的過瑞數難度相比較于以前難度已經大大降低了!人均瑞數的成就人均可達成,本次我們使用補環境框架來過一下瑞數
2. 特征分析
在分析網站之前,我們需要去了解瑞數防護的一些特征。首先就是開局的無限debugger,然后4代的話請求是兩次,一次的話是一個202狀態碼!在返回HTMl內容中包含動態加載的meta標簽包含content跟script標簽,如下圖所示:
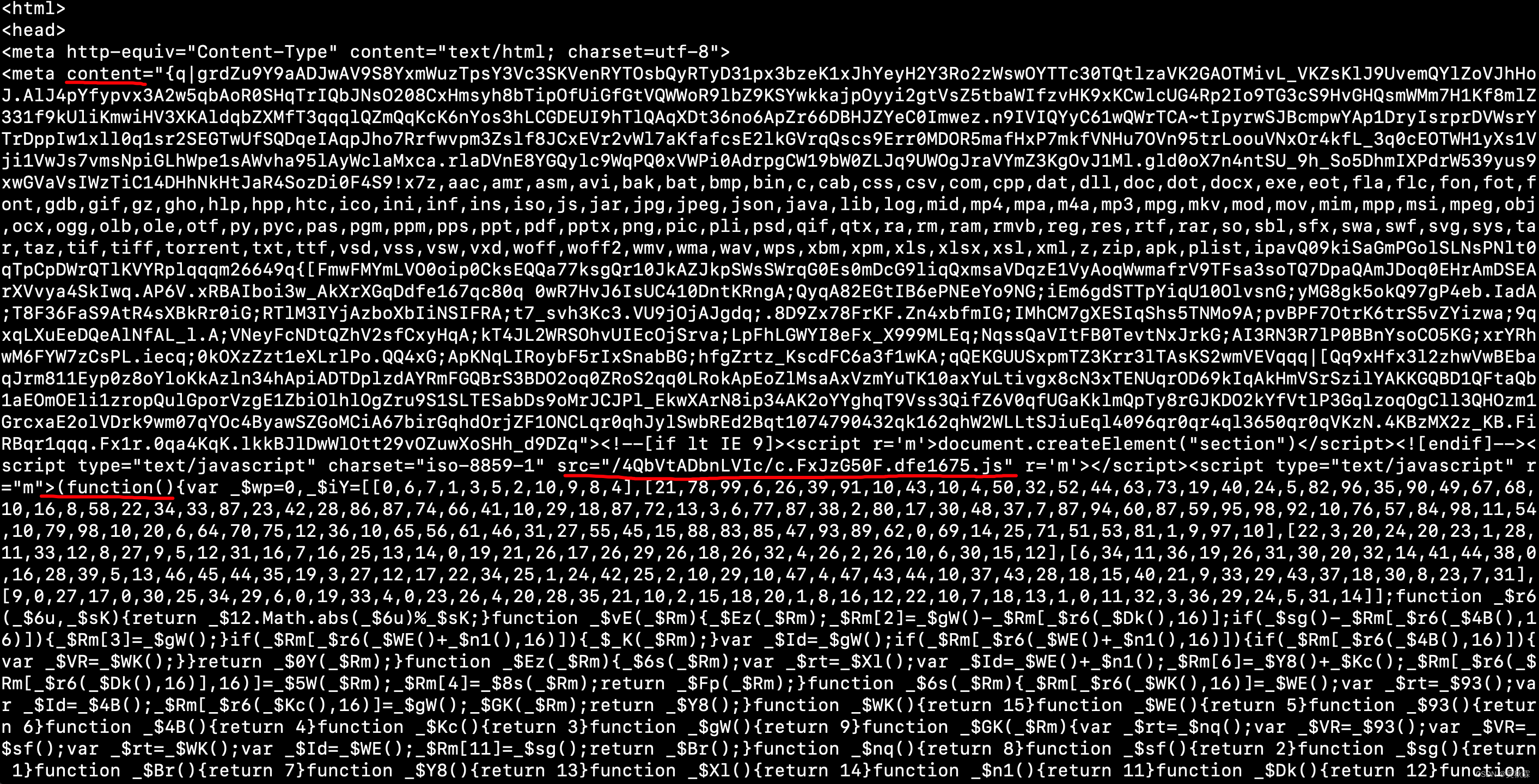
可以看到有一個外鏈的JS地址,_ts=window[…]可以直接請求獲取JS代碼,如下所示:

3. 接口分析
第一次請求頁面我們可以監測一下,FSSBB…就是JS代碼生成的Cookie,開頭的數字表示它是瑞數幾,如下所示:

這里我們可以直接在瀏覽器Curl請求出來,進行一下重放請求驗證。如下所示:
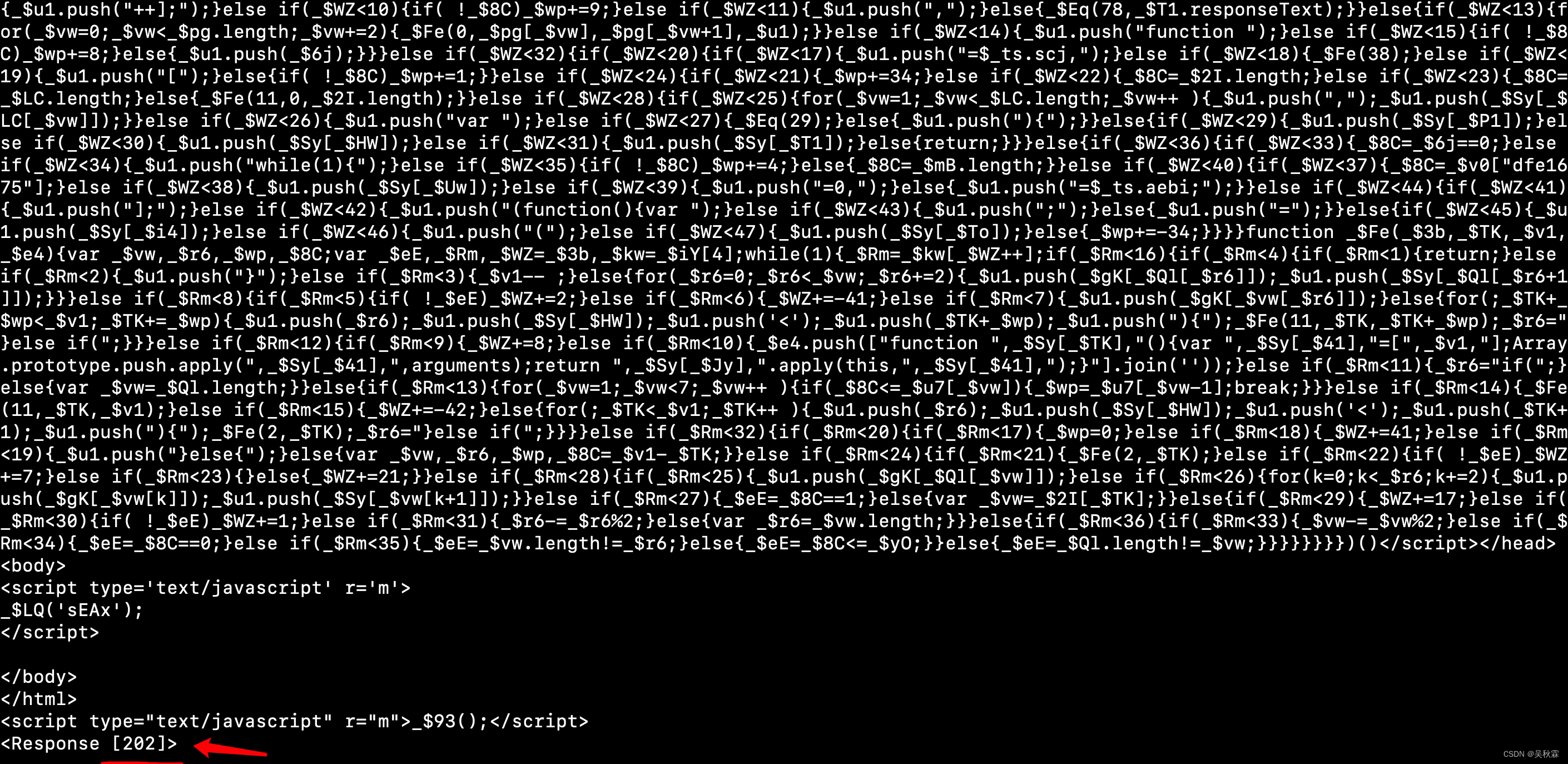
標準的202,其實到這一步我們現在需要解決的一個問題就是過瑞數的反爬蟲防護,讓我們的請求能夠正常的拿到頁面的響應信息
3. 補JS環境
既然是使用補環境的框架(開源的rs框架很多,大家可以自行去查找測試),環境相關的東西基本都是借助Proxy模式讓它自吐出來!
有時候使用框架并頁不一定就好使,可能拿到的結果會跟你瀏覽器的不一樣,這個時候就需要再回過頭去分析JS,將框架監測到的環境盡可能跟瀏覽的一致!
這個地方還會有很多的細節坑,也是很多初學者或者rs新手經常補不出來的一個原因!JS的檢測點很多,多次補的結果都跟瀏覽器的不一樣,那就需要繼續去分析,肯定是JS中沒有補到或者監測到的環境
這里的補環境的JS源碼很長。文章內作者不對其進行貼出,有需要的小伙伴可以找作者獲取學習
這里我們直接運行補環境的框架,檢測對象并進行自動代理。然后打印可以看到所有對象的屬性信息,如下所示:

這里我們先使用Python來構造請求,將開始分析得到的content跟自執行JS提取出來(需要放到補出來的JS中執行調用),代碼實現如下:
import requests
import re
import logginglogger = logging.getLogger(__name__)class WebScraper:def __init__(self, head_url, headers):self.head_url = ""self.headers = headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "no-cache","Connection": "keep-alive","Pragma": "no-cache","Upgrade-Insecure-Requests": "1","User-Agent": "" # 自行獲取}def fetch_page(self):response = requests.get(self.head_url, headers=self.headers, verify=False)logger.info(f"請求響應狀態: {response.status_code}")meta_content_match = re.search(r'<meta content="(.*?)">', response.text)js_code_match = re.search(r'r="m">(.*?)</s', response.text)if not meta_content_match or not js_code_match:logger.error("未能找到所需的meta內容或JavaScript代碼")return Nonemeta_content = meta_content_match.group(1)js_code = js_code_match.group(1)logger.info(f"獲取meta_content: {meta_content}")logger.info(f"獲取自執行JS: {js_code}")
運行上面的程序,在第一次請求響應失敗時,提取信息,運行效果如下所示:

將第一次請求提取到的信息塞到補環境的JS中,全局導出后可直接拿最到新的Cookie信息,如下所示:

拿到生成的Cookie信息攜帶發送新的請求,可以看到上圖已成功過了瑞數反爬。請求狀態碼已是200,成功拿到了頁面信息
4. 補后綴參數
繞過瑞數反爬蟲后,我們需要處理的另一個問題則是后綴!拿接口數據,參數是有加密的,也就是后綴的那個MmEwMD,如下所示:

這個參數的還原其實有多種方案,第一個就是分析JS對其進行算法還原。有一定的難度!第二個則比較簡單,直接在補環境的基礎之上,對XMLHttpRequest對象的open方法進行修改并對其進行攔截,以此獲取到完整的URL(含后綴)
重寫open方法的這種方案目前看是比較常見的,針對部分瑞數的反爬蟲場景,至少作者在開源社區看到了多種此類的方案
(function() {// 保存原始的open方法var originalOpen = XMLHttpRequest.prototype.open;// 創建一個變量來保存URLvar lastURL;// 重寫open方法XMLHttpRequest.prototype.open = function(method, url, async, user, password) {// 記錄URLlastURL = url;// 調用原始的open方法return originalOpen.apply(this, arguments);};// 提供一個函數來獲取記錄的URLwindow.getLastRequestURL = function() {return lastURL;};
})();
作者給出了一個示例,通過這個例子我們可以攔截到XMLHttpRequest對象的open方法,以此來記錄傳入的URL,并通過getLastRequestURL拿到完整的URL,使用示例如下所示:
// 創建一個XMLHttpRequest對象并調用open方法
var xhr = new XMLHttpRequest();
xhr.open("GET", "http://www.xxx.com.cn/service/xxx/xxx.actionId", true);// 獲取最后一次請求的URL
console.log(getLastRequestURL());
最終作者對整個網站的請求進行了一個封裝,測試了一下完整的流程,如下所示:

成功拿到后綴參數并提交接口獲取到結構化數據,我們可以在此框架的基礎去拓展,讓其可以適用與所有瑞數的環境場景






)






)

顯卡驅動,黑屏|雙屏無法使用問題解決方法)
)


