概述
論文地址:https://arxiv.org/pdf/2403.10517
本研究引入了一個新穎的基于代理的系統,名為 VideoAgent。該系統以大規模語言模型為核心,負責識別關鍵信息以回答問題和編輯視頻。VideoAgent 在具有挑戰性的 EgoSchema 和 NExT-QA 基準上進行了評估,平均幀數分別為 8.4 幀和 8.2 幀,零鏡頭準確率分別達到 54.1% 和 71.3%。的零鏡頭準確率。
介紹
理解長視頻需要能夠處理各種信息并有效推理長序列的模型。現有的嘗試發現,要建立能滿足所有這些要求的模型非常困難。目前的大規模語言模型適合處理長語境,但不足以處理視覺信息。另一方面,視覺語言模型被認為難以處理長視覺輸入。我們的系統模仿了視頻理解過程,側重于推理能力而不是處理長視覺輸入;VideoAgent 比現有方法更有效、更高效,是長視頻理解領域的一大進步。
相關研究
傳統方法包括對視頻進行選擇性或壓縮性處理。壓縮稀疏性方法試圖將視頻壓縮為有意義的嵌入或表示。選擇性壓縮方法則試圖根據輸入的問題或文本對視頻進行子采樣。代理是做出決策和執行行動的實體。大規模語言建模(LLM)技術的進步促使越來越多的研究將 LLM 作為代理來使用。這種方法已成功應用于多種場景,如在線搜索和紙牌游戲。受人類理解視頻方式的啟發,本研究將視頻理解重新表述為一個決策過程。
建議方法
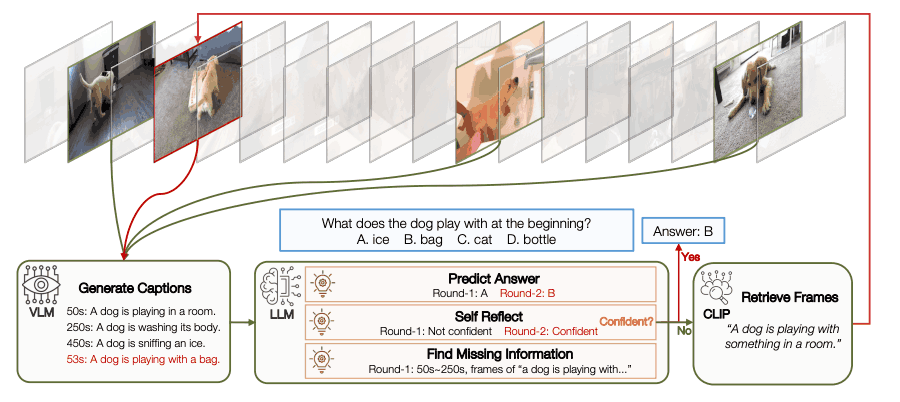
- 初始狀態檢索:.
首先,向 LLM 展示視頻中的均勻采樣幀,使其熟悉視頻上下文。視覺語言模型(VLM)用于將視覺信息轉化為語言描述。這種初始狀態記錄了視頻內容和含義的概況。
- 決定下一步行動:。
考慮到當前情況,LLM 決定下一步行動;有兩種可能的選擇。一個是回答問題,另一個是搜索新信息;LLM 會考慮問題和現有信息,進行反思,并根據置信度選擇行動。
- 收集新的觀察結果:。
需要新信息時,LLM 使用工具來檢索。有些信息是在分段級別收集的,以增強時間推理功能。獲取的信息可作為更新當前狀態的觀測信息。
- 最新現狀:.
考慮到新的觀察結果,VLM 用于為每一幀生成標題,然后請求 LLM 生成下一輪的預測。
與傳統方法相比,這種方法具有若干優勢。特別是,收集信息的適應性選擇策略可以找到相關信息,并將回答不同難度問題所需的成本降至最低。
試驗
數據集和衡量標準
EgoSchema 包含一個以自我為中心的視頻,包含 5000 個問題;NExT-QA 包含一個以物體互動為特色的自然視頻,包含 48000 個問題。自然視頻,包含 48,000 個問題。
實施細節。
所有視頻都以 1 幀/秒的速度解碼,并根據視覺描述和幀特征之間的余弦相似度檢索出最相關的幀。在實驗中,我們將 LaViLa 用于 EgoSchema,將 CogAgent 用于 NExT-QA。GPT-4 也被用作 LLM。
與最先進技術的比較
VideoAgent 在 EgoSchema 和 NExT-QA 數據集上取得了 SOTA 結果,明顯優于之前的方法。例如,它在完整的 EgoSchema 數據集上取得了 54.1% 的準確率,在 500 個問題的子集上取得了 60.2% 的準確率。
迭代幀選擇分析。
VideoAgent 的關鍵組件之一是迭代幀選擇。這一過程會動態檢索和匯總信息,直到收集到足夠的信息來回答問題。為了更好地理解這一過程,我們進行了全面的分析和消融研究。
基本模型的消融
LLM(大型語言模型):對不同的 LLM 進行了比較,發現 GPT-4 的性能優于其他模型;GPT-4 在結構化預測方面尤為突出,在生成準確的 JSON 格式方面表現出色。
VLM(視覺語言模型):對三種最先進的 VLM 進行了研究,結果發現 CogAgent 和 LaViLa 的性能相近,而 BLIP-2 的性能較差。
CLIP(對比語言圖像模型):對不同版本的 CLIP 進行了評估,結果表明,所有版本的 CLIP 性能相當;CLIP 在檢索任務方面更勝一籌,而且效率更高,因為它不需要重新計算圖像嵌入。
案例研究
我們以解析 NExT-QA 實例為例,說明視頻代理如何識別缺失信息、確定所需的附加信息并使用 CLIP 檢索詳細信息。
演示了 VideoAgent 如何正確解析 YouTube 上一小時的視頻。演示者強調,在這種情況下,GPT-4V 可以提供已識別的幀來正確回答問題。
結論
本研究介紹了一個視頻理解系統,該系統利用一個名為 VideoAgent 的大規模語言模型,通過多輪迭代過程有效地檢索和聚合信息,展示了其在理解長視頻方面的卓越效果和效率。今后的工作將集中在改進和整合模型、將其擴展到實時應用、將其應用到各種應用領域以及改進用戶界面等方面,這將進一步推進和拓寬 VideoAgent 的應用。
人形機器人行走舉例)


)







 線程信息 - 線程控制)







