一、Transformer
Transformer,是由編碼塊和解碼塊兩部分組成,其中編碼塊由多個編碼器組成,解碼塊同樣也是由多個解碼塊組成。
編碼器:自注意力 + 全連接
- 多頭自注意力:Q、K、V?
- 公式:??
解碼塊:自注意力 + 編碼 - 解碼自注意力 +全連接
- 多頭自注意力:?
- 編碼—解碼自注意力:Q上個解碼器的輸出
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? K、V最后一個編碼器輸出
二、BERT
- bert,是由Transformer的多個編碼器組成。
- Base :12層編碼器,每個編碼器有12個多頭,隱藏維度為768。
- Large: 24層編碼器,每個編碼器16個頭,隱層維度為1024??
- bert結構 :
? ? ? ? ? ? ? ? ? ? ?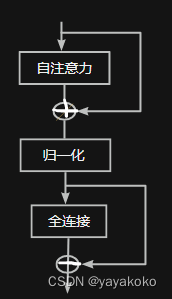 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
import torch
class MultiHeadAttention(nn.Module):def__init__(self,hidden_size,head_num):super().__init__()self.head_size = hidden_size / head_numself.query = nn.Linear(hidden_size, hidden_size)self.key = nn.Linear(hidden_size, hidden_size)self.value = nn.Linear(hidden_size, hidden_size)def transpose_dim(self,x):x_new_shape = x.size()[:-1]+(self.head_num, head_size)x = x.view(*x_new_shape)return x.permute(0,2,1,3)def forward(self,x,attention_mask):Quary_layer = self.query(x)Key_layer = self.key(x)Value_layer = self.value(x)'''B = Quary_layer.shape[0]N = Quary_layer.shape[1]multi_quary = Quary_layer.view(B,N,self.head_num,self.head_size).transpose(1,2)'''multi_quary =self.transpose_dim(Quary_layer)multi_key =self.transpose_dim(Key_layer)multi_value =self.transpose_dim(Value_layer)attention_scores = torch.matmul(multi_quary, multi_key.transpose(-1,-2))attention_scores = attention_scores / math.sqrt(self.head_size)attention_probs = nn.Softmax(dim=-1)(attention_scores) context_layer = torch.matmul(attention_probs,values_layer)context_layer = context_layer.permute(0,2,1,3).contiguous()context_layer_shape = context_layer.size()[:-2]+(self.hidden_size)context_layer = cotext_layer.view(*context_layer_shape return context_layer










)







》)