損失函數
1、邊界框損失函數/回歸損失函數bbox_loss
2、分類損失函數cls_loss
3、置信度損失函數obj_loss
YOLOv8損失函數
1、概述
通過YOLOv8-訓練流程-正負樣本分配的介紹,我們可以知道,經過預處理與篩選的過程得到最終的訓練數據:
a. 網絡輸出值:pred_scores[bx8400xcls_num]、pred_bboxes[bx8400x4]
b. 訓練標簽值:
target_scoresbx8400xcls_num,在計算損失時與預測結果pred_scores[bx8400xcls_num],計算交叉熵損失,該損失是對每個類別計算BCE Loss,因為類別預測采用的sigmoid分類器。
target_bboxesbx8400x4,在計算損失時,分別與預測的pred_bboxes計算Ciou Loss, 同時與pred_regs(預測的anchors中心點到各邊的距離)計算回歸DFL Loss。
c. 訓練mask值:fg_mask [bx8400],對8400個anchor進行正負樣本標記,計算損失過程中通過fg_mask篩選正負樣本。
2、損失函數
1、類別分類損失cls_loss
在yolov8中,類別損失最終采用的是交叉熵損失,該方法是我們非常熟知的,不再贅述。
代碼如下:
self.bce = nn.BCEWithLogitsLoss(reduction='none')
loss[1] = self.bce(pred_scores,target_scores).sum()/target_scores_sum
其中預測pred_scores: b x 8400 x cls_num; target_scores: b x 8400 x cls_num, 相當于對于每個box,其cls_num個分類都視為二分類,并進行交叉熵運算。
2、邊界框回歸損失bbox_loss
邊框回歸,采用的是DFL Loss + CIOU Loss
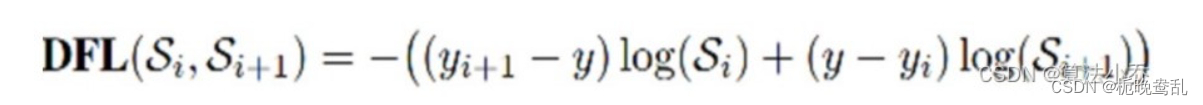
target_bboxes /= self.stride_scales
loss[0],loss[2] = self.bbox_loss(pred_regs,pred_bboxes,self.anc_points,target_bboxes,target_scores,target_scores_sum,fg_mask)
DFL loss:
weight = torch.masked_select(target_scores.sum(-1), fg_mask).unsqueeze(-1)
# DFL loss
if self.use_dfl:target_ltrb = self.bbox2reg(anchor_points, target_bboxes, self.reg_max)loss_dfl = self._df_loss(pred_regs[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
FasterRCNN損失函數
1、由于frcnn的網絡結構主要是兩個網絡組成,損失函數分為四個部分。
RPN分類損失:anchor是否為gt
RPN位置回歸損失:anchor位置微調
ROI分類損失:ROI所屬類別
ROI位置回歸損失:繼續對ROI位置微調
四個損失相加就是最后的損失,反向傳播,更新參數。
2、RPN損失
1、分類損失:cross_entropy
2、回歸損失:smooth L1 loss
3、ROI損失(與RPN類似)
1、分類損失
2、回歸損失
在Faster R-CNN模型中,有兩個主要的組件:區域提議網絡(Region Proposal Network, RPN) 和 Fast R-CNN檢測器。這兩個組件分別負責生成候選區域(region proposals)和最終的目標檢測,它們各自計算并優化不同的損失函數。
RPN的損失
RPN的目標是生成高質量的候選區域,它同時執行分類和回歸任務:
分類損失:RPN需要判斷每個錨框(anchor)是否包含目標物體,通常使用二元分類(前景vs背景)。損失函數通常采用交叉熵損失(Cross-Entropy Loss),有時也稱為Log Loss。對于每個錨框,如果它與任一GT框的重疊超過閾值,則認為它是正樣本(前景),否則為負樣本(背景)。
回歸損失:對于每個前景錨框,RPN需要預測邊界框的偏移量,以便更準確地定位目標。回歸損失通常采用Smooth L1損失(也稱為Huber損失),因為它對大的殘差(預測誤差)更為穩健。
ROI的損失(Fast R-CNN部分的損失)
Fast R-CNN檢測器接收RPN生成的候選區域,然后進行更詳細的分類和邊界框回歸:
分類損失:對于每個候選區域(Region of Interest, ROI),Fast R-CNN需要預測物體的類別。這同樣采用交叉熵損失,但是這次是多分類損失,因為它需要區分多個不同的物體類別。
回歸損失:類似于RPN的回歸損失,Fast R-CNN也需要優化邊界框的位置。然而,這里的邊界框回歸是針對每個類別進行的,因為不同類別的物體可能有不同的形狀和比例。這也通常使用Smooth L1損失。
總體損失
在訓練過程中,RPN的損失和Fast R-CNN部分的損失會被加權求和,形成總損失函數。這是因為兩個部分的目標是相關的,但又各自負責不同的任務。優化整個模型的總損失有助于同時改善區域提議的質量和最終的檢測精度。
損失函數的細節
RPN的分類損失通常使用Sigmoid函數進行二元分類,而Fast R-CNN的分類損失使用Softmax函數進行多分類。
RPN的回歸損失和Fast R-CNN的回歸損失都采用Smooth L1損失,但Fast R-CNN的回歸損失可能在每個類別上都有一個獨立的分支,這意味著它實際上是多個Smooth L1損失的組合。
通過這種方式,Faster R-CNN模型能夠在訓練過程中同時優化區域提議和最終的檢測結果,從而實現高效且準確的目標檢測。
YOLOv8和RT-DETR(Real-Time DETR)是兩種不同的目標檢測框架,它們在設計哲學和損失函數的選擇上存在一些關鍵的區別。下面我將概述這兩種模型的損失函數及其差異。
YOLOv8的損失函數
YOLOv8是YOLO系列的一個最新版本,它采用了以下幾種損失函數:
-
VFL Loss (Variational Focal Loss):用于分類損失,它結合了交叉熵損失和focal loss的優點,以解決類別不平衡問題,尤其是當小目標數量較少時。
-
CIOU Loss (Complete Intersection over Union Loss):用于邊界框回歸,CIOU Loss不僅考慮了IoU(交并比),還考慮了中心點的距離和長寬比,提供了更全面的邊界框回歸度量。
-
DFL Loss (Distribution Focal Loss):用于邊界框坐標預測的細化,通過預測邊界框坐標的分布來進一步優化回歸。
RT-DETR的損失函數
RT-DETR是基于Transformer架構的實時目標檢測模型,它借鑒了DETR的設計,但進行了優化以實現更快的速度。其損失函數包括:
-
分類損失:通常使用交叉熵損失,用于預測每個檢測框的類別。
-
邊界框回歸損失:RT-DETR可能使用L1損失或GIoU(Generalized IoU)損失等,用于優化檢測框的位置。
-
匈牙利匹配算法:這是DETR及其衍生模型的核心特點之一,用于在沒有先驗假設的情況下匹配預測框和真實框,從而確定哪些預測框應該被哪些真實框監督。
區別
-
匹配機制:YOLOv8采用Task-Aligned匹配策略,而RT-DETR則依賴于匈牙利算法進行預測框與真實框的匹配。Task-Aligned匹配考慮了任務的特性來優化匹配過程,而匈牙利算法則是一種全局最優的匹配策略。
-
損失函數:YOLOv8使用了更復雜的損失函數組合,如VFL和CIOU Loss,旨在提高小目標檢測的性能和邊界框回歸的準確性。RT-DETR的損失函數相對簡單,更側重于速度和效率。
-
架構差異:YOLOv8繼承了YOLO的一貫風格,使用卷積神經網絡(CNN)進行特征提取和預測,而RT-DETR基于Transformer架構,這在模型結構和計算流程上有本質的不同。
這些區別反映了YOLOv8和RT-DETR在設計上的不同取向,YOLOv8追求在各種場景下的高性能,而RT-DETR則強調實時性和計算效率,兩者在特定的應用場景下各有優勢。




)

![[C++][CMake][CMake基礎]詳細講解](http://pic.xiahunao.cn/[C++][CMake][CMake基礎]詳細講解)












在排序數組中查找元素的首尾位置)