一、簡介
“Attention Is All You Need” 是一篇由Ashish Vaswani等人在2017年發表的論文,它在自然語言處理領域引入了一種新的架構——Transformer。這個架構現在被廣泛應用于各種任務,如機器翻譯、文本摘要、問答系統等。Transformer模型的核心是“自注意力”(self-attention)機制,這一機制能夠有效捕捉文本序列中的長距離依賴關系。
在這篇論文中,作者們提出了一個基于自注意力機制的模型,該模型完全摒棄了傳統的循環神經網絡(RNN)和卷積神經網絡(CNN)中常用的序列順序處理方式,而是通過自注意力機制來直接計算序列中任意兩個位置之間的關聯性。這種機制使得模型在處理長文本時能夠更加高效,因為它可以同時考慮序列中的所有單詞,而不是像RNN那樣逐個處理。
Transformer模型由編碼器(Encoder)和解碼器(Decoder)組成,每個編碼器和解碼器又是由多層“自注意力層”和“前饋網絡層”堆疊而成。自注意力層可以讓模型在生成每個單詞的時候考慮到序列中其他所有單詞的影響,而前饋網絡層則對每個位置的表示進行進一步的非線性變換。
論文還引入了“多頭注意力”(Multi-Head Attention)機制,它通過將輸入序列分割成多個“頭”來同時進行自注意力計算,這樣可以讓模型在不同的表示子空間中學習到信息,增強了模型的表達能力。
此外,作者還提出了一種位置編碼(Positional Encoding)方法,用來給模型提供關于單詞在序列中位置的信息,這是因為Transformer模型本身并不具有捕捉序列順序的能力。
“Attention Is All You Need” 論文的貢獻在于證明了僅使用注意力機制,而不依賴RNN或CNN,也可以構建出高效、強大的模型。這一架構在許多NLP任務上都取得了突破性的成果,并且為后續的模型發展如BERT、GPT系列等提供了基礎。
這篇論文的解讀需要對深度學習、自然語言處理以及注意力機制有一定的理解。如果您需要更詳細的技術性解讀或對論文中的某一部分有具體的問題,請告知我,我將盡力提供幫助。
二、詳解
根據提供的原論文內容,我們來完善每個章節的解讀:
0. 摘要
摘要部分提供了對論文《Attention Is All You Need》的高層次概述,主要包括以下幾個要點:
-
新模型架構: 提出了一種名為Transformer的新型神經網絡架構,這種架構完全基于注意力機制,不再依賴于傳統的遞歸神經網絡(RNN)或卷積神經網絡(CNN)。
-
簡化與效率: Transformer模型摒棄了序列處理中的遞歸和卷積操作,從而簡化了模型結構,并提高了并行化處理的能力。
-
機器翻譯任務: 在兩個機器翻譯任務上進行了實驗,分別是英語到德語和英語到法語的翻譯,結果顯示Transformer模型在質量上具有優勢。
-
性能提升: 在WMT 2014 English-to-German翻譯任務上,Transformer模型達到了28.4 BLEU分數,超過了之前所有模型,包括集成模型。在English-to-French翻譯任務上,模型在訓練3.5天后,取得了41.8 BLEU分數的新單模型最佳成績。
-
訓練時間: 強調了Transformer模型所需的訓練時間顯著少于之前的最佳模型,這意味著訓練成本更低。
-
泛化能力: 展示了Transformer模型不僅在機器翻譯任務上表現出色,還能夠成功地應用到英語成分句法分析任務上,無論是使用大量訓練數據還是有限數據。
-
開源代碼: 提供了用于訓練和評估模型的代碼鏈接,供其他研究者使用和參考。
摘要是對整篇論文的精煉總結,突出了Transformer模型的核心貢獻和實驗結果。
1. 引言 (Introduction)
在引言 (Introduction) 部分,論文主要討論了以下幾個方面:
-
現有模型的局限性:
論文開始時提到,盡管循環神經網絡(RNN)特別是長短期記憶網絡(LSTM)和門控循環單元(GRU)在序列建模和機器翻譯等任務中表現出色,但它們存在一些固有的局限性。例如,RNN的序列計算特性限制了模型在訓練樣本內的并行化能力,這在處理長序列時尤為關鍵。 -
注意力機制的重要性:
作者強調注意力機制已成為各種序列建模和轉換模型的核心部分,它允許模型不考慮輸入或輸出序列中的距離來建立依賴關系。 -
Transformer模型的創新點:
論文提出了Transformer模型,這是一種全新的模型架構,它完全基于注意力機制,不使用遞歸神經網絡。這種架構允許更多的并行化,并且在訓練時間上大大減少。 -
性能表現:
作者指出Transformer模型在翻譯質量上達到了新的最佳狀態,并且在訓練效率上也有顯著提升。例如,在八塊P100 GPU上僅訓練12小時就能達到新的最佳翻譯質量。 -
模型架構的優勢:
論文討論了Transformer模型相對于現有模型的優勢,包括簡化的模型結構、提高的并行處理能力以及在不同任務上的泛化能力。 -
未來工作:
論文最后指出了Transformer模型的潛力,并展望了未來的研究方向,包括將其應用于其他任務和探索局部、受限的注意力機制,以有效處理大型輸入和輸出,如圖像、音頻和視頻。
引言部分為讀者提供了Transformer模型的背景、動機和預期貢獻的概述,為理解全文內容奠定了基礎。
2. 背景 (Background)
在背景 (Background) 部分,論文主要討論了以下內容:
-
減少序列計算的目標:論文介紹了減少序列計算的重要性,這是Transformer模型設計的核心目標之一。減少序列計算有助于提高模型的并行處理能力,從而加快訓練速度。
-
現有模型的問題:討論了現有模型,如基于卷積神經網絡的Extended Neural GPU、ByteNet和ConvS2S,它們使用卷積作為基本構建塊,盡管這些模型可以并行計算隱藏表示,但它們在處理長距離依賴時存在局限性。
-
長距離依賴的挑戰:論文指出,在各種序列轉換任務中,學習長距離依賴是一個關鍵挑戰。長距離依賴的學習能力受到網絡中前向和后向信號必須穿越的路徑長度的影響。
-
Transformer模型的優勢:論文提出,Transformer模型通過使用自注意力機制,將任意兩個輸入或輸出位置之間的關系的計算復雜度降低到恒定數量的操作,這與基于卷積的模型形成對比,后者隨著位置間距離的增加而增加計算復雜度。
-
自注意力機制:自注意力(Self-attention)有時也稱為內部注意力(intra-attention),它關聯單個序列的不同位置,以計算序列的表示。自注意力已成功應用于多種任務,包括閱讀理解、摘要生成、文本蘊含和學習任務獨立的句子表示。
-
端到端記憶網絡:論文還提到了基于循環注意力機制的端到端記憶網絡,這些網絡在簡單語言問答和語言建模任務上表現良好。
-
Transformer模型的創新性:論文強調,據作者所知,Transformer是第一個完全依靠自注意力來計算輸入和輸出表示的轉換模型,它不使用序列對齊的RNN或卷積。
背景部分為讀者提供了Transformer模型的理論基礎和研究背景,解釋了為什么需要一種新的模型架構,以及Transformer模型是如何在這樣的背景下應運而生的。
3. 模型架構 (Model Architecture)
- Transformer模型遵循編碼器-解碼器結構,其中編碼器將輸入序列映射到連續表示,解碼器則基于此生成輸出序列。
- 編碼器和解碼器都由多層相同的堆疊層組成,每層包括多頭自注意力機制和逐位置的全連接前饋網絡。
- 模型中使用了殘差連接和層歸一化來提高訓練穩定性。
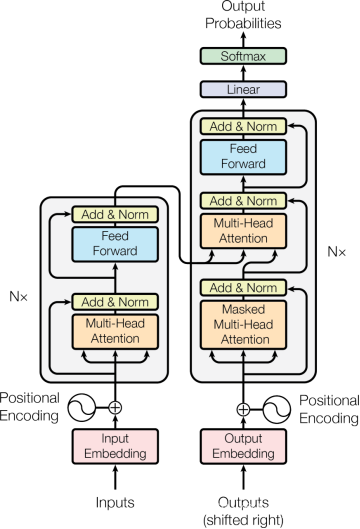
3.1 編碼器和解碼器堆棧 (Encoder and Decoder Stacks)
- 編碼器結構:由N個相同的層組成,每個層包括多頭自注意力機制和前饋網絡。文中N=6,每層的輸出通過殘差連接和層歸一化處理。
- 解碼器結構:同樣由N個相同的層組成,但每層除了自注意力和前饋網絡外,還增加了一個針對編碼器輸出的多頭注意力層。解碼器的自注意力層經過修改,以防止在未來位置的標記上產生依賴,保持解碼順序的自回歸特性。
3.2 注意力機制 (Attention)
-
查詢、鍵、值 (Q, K, V):注意力機制通過查詢與鍵的匹配來計算值的加權和。
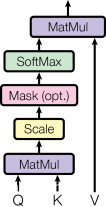
-
縮放點積注意力 (Scaled Dot-Product Attention):使用點積計算查詢和鍵之間的相似度,然后通過softmax函數進行歸一化,得到權重。
-
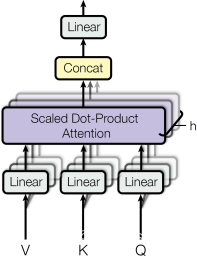
多頭注意力 (Multi-Head Attention):將輸入的Q、K、V通過不同的線性變換映射到多個頭,每個頭獨立計算注意力,然后將結果合并,允許模型在不同位置關注不同表示子空間的信息。
3.2.1 縮放點積注意力 (Scaled Dot-Product Attention)
- 介紹了縮放點積注意力的計算方法,包括點積后的縮放因子 1 / d k 1/\sqrt{d_k} 1/dk??,目的是防止softmax函數進入梯度極小的區域。
3.2.2 多頭注意力 (Multi-Head Attention)
- 解釋了多頭注意力的工作原理,包括如何使用不同的線性變換來處理Q、K、V,以及如何并行處理多個頭的輸出。
3.2.3 注意力在模型中的應用
- 編碼器-解碼器注意力:解碼器層的查詢使用前一層的輸出,而鍵和值來自編碼器的輸出。
- 編碼器自注意力:所有Q、K、V來自編碼器前一層的輸出。
- 解碼器自注意力:允許解碼器的每個位置關注到該位置之前的所有位置。
3.3 逐位置前饋網絡 (Position-wise Feed-Forward Networks)
- 描述了前饋網絡的結構,包括兩個線性變換和一個ReLU激活函數,這些操作對每個位置分別獨立應用。
3.4 嵌入和Softmax (Embeddings and Softmax)
- 討論了輸入和輸出嵌入層的使用,以及如何通過共享權重矩陣將嵌入層與預Softmax線性變換聯系起來。
3.5 位置編碼 (Positional Encoding)
- 由于模型中沒有遞歸或卷積來捕捉序列順序,因此引入位置編碼來提供序列中每個標記的位置信息。
- 位置編碼使用不同頻率的正弦和余弦函數,允許模型學習相對位置信息。
這部分內容詳細闡述了Transformer模型的各個組成部分以及它們是如何協同工作的,從而為讀者提供了對模型架構的深入理解。
4. 自注意力的優勢 (Why Self-Attention)
在第四部分 Why Self-Attention(自注意力的優勢)中,論文主要闡述了自注意力機制相對于傳統序列處理方法(如循環神經網絡RNN和卷積神經網絡CNN)的幾個關鍵優勢:
-
計算復雜性(Computational Complexity):
- 自注意力層的計算復雜度為O(n2·d),其中n是序列長度,d是表示維度。這使得自注意力層在處理長序列時比RNN和CNN更高效,尤其是當序列長度n小于表示維度d時。
-
并行化能力(Parallelization):
- 自注意力層可以在常數時間內處理整個序列,而RNN層需要按順序逐步處理,這限制了其并行化能力。自注意力層的這種特性使得模型能夠更快速地訓練,特別是在現代硬件上。
-
長距離依賴(Long-Range Dependencies):
- 自注意力層通過減少學習長距離依賴所需的路徑長度,提高了模型學習這些依賴的能力。在自注意力網絡中,任意兩個位置之間的路徑長度是恒定的,而在RNN中這個長度是線性的,CNN則取決于卷積核的大小或擴張率。
-
最大路徑長度(Maximum Path Length):
- 論文中還討論了不同層類型的最大路徑長度,自注意力層提供了所有位置之間的最短路徑。
-
可解釋性(Interpretability):
- 自注意力層可能產生更可解釋的模型。通過分析注意力分布,可以觀察到模型如何關注輸入序列的不同部分,這有助于理解模型的決策過程。
-
限制自注意力的范圍(Restricted Self-Attention):
- 論文提出,為了處理更長的序列,可以限制自注意力的范圍,只考慮輸入序列中與當前輸出位置鄰近的一小部分位置。這將增加最大路徑長度,但減少計算量。
-
效率和性能(Efficiency and Performance):
- 自注意力機制不僅提高了計算效率,還有助于提升模型性能,尤其是在處理具有復雜結構的序列數據時。
這部分內容強調了自注意力機制在Transformer模型中的核心作用,以及它如何克服傳統序列模型的一些限制,從而在各種序列轉換任務中取得更好的性能。
5. 訓練 (Training)
根據論文的第五部分 訓練 (Training),以下是按照章節的詳細解讀:
5.1 訓練數據和批處理 (Training Data and Batching)
- 論文指出了用于訓練的數據集是標準的WMT 2014英德和英法數據集,這些數據集包含了數百萬的句子對。
- 數據經過字節對編碼(BPE)處理,以減少詞匯量并提高模型的泛化能力。
- 批處理是按照源序列和目標序列的大致相同長度進行的,每個批次包含了大約25000個源標記和25000個目標標記。
5.2 硬件和調度 (Hardware and Schedule)
- 訓練使用的硬件是配備了8個NVIDIA P100 GPU的機器。
- 基礎模型訓練了100,000步或大約12小時,而大型模型訓練了300,000步,大約3.5天。
5.3 優化器 (Optimizer)
- 論文中選用了Adam優化器,這是一種常用于深度學習的標準優化算法。
- 優化器的參數包括β1=0.9,β2=0.98和?=10^-9,這些參數有助于優化訓練過程。
5.4 正則化 (Regularization)
- 論文采用了三種正則化方法:
- 殘差dropout:在每個子層的輸出上應用dropout,以減少過擬合。
- 標簽平滑:在訓練期間使用標簽平滑,使模型學習更加不確定,有助于提高模型的泛化能力。
- 權重衰減:對模型參數進行L2正則化,以進一步防止過擬合。
這些正則化技術共同作用于模型,以提高其在看不見的數據上的魯棒性。
6. 結果 (Results)
根據論文的第6部分 結果 (Results),以下是按照章節的詳細解讀:
6.1 機器翻譯 (Machine Translation)
- 性能比較: 論文報告了Transformer模型在WMT 2014英德和英法翻譯任務上的性能。在英德翻譯任務上,大型Transformer模型(Transformer (big))以28.4 BLEU分數超越了之前所有報道的模型,包括集成模型。在英法翻譯任務上,該模型也取得了41.0 BLEU分數,超越了所有之前發布的單一模型。
- 訓練成本: 論文強調Transformer模型的訓練成本遠低于競爭模型。例如,在英德翻譯任務上,基礎模型在訓練成本上僅為其他競爭模型的一小部分。
- 模型配置: 論文列出了取得最佳結果的模型配置,包括層數、隱藏層維度、注意力頭數等。
6.2 模型變體 (Model Variations)
- 注意力頭數和維度: 論文探討了改變注意力頭數和每個頭的維度對模型性能的影響。發現單頭注意力的性能低于最佳設置,而太多的頭也會導致性能下降。
- 注意力鍵大小: 減少注意力鍵的維度會損害模型質量,表明確定兼容性不是一件容易的事情,可能需要比點積更復雜的兼容性函數。
- 模型大小和dropout: 更大的模型通常表現更好,dropout對于避免過擬合非常有幫助。
- 位置編碼: 使用學習到的位置嵌入代替正弦波位置編碼,結果與基礎模型幾乎相同。
6.3 英語成分句法分析 (English Constituency Parsing)
- 泛化能力: 為了評估Transformer模型是否能夠泛化到其他任務,作者在英語成分句法分析任務上進行了實驗。盡管這個任務的輸出受到強結構約束,并且輸出比輸入長得多,但Transformer模型仍然表現出色。
- WSJ數據集: 在Penn Treebank的WSJ部分上訓練了一個4層Transformer模型,大約有40K訓練句子。還在半監督設置下使用更大的數據集進行了訓練。
- 性能: Transformer模型在成分句法分析任務上的表現優于所有先前報道的模型,除了Recurrent Neural Network Grammar。
第6部分的結果展示了Transformer模型在多個自然語言處理任務上的有效性和優越性,不僅在機器翻譯領域取得了突破性的性能,還在句法分析等其他任務上展現了良好的泛化能力。
7. 結論 (Conclusion)
-
創新性: 論文首先強調了Transformer模型的創新之處,即它是第一個完全基于注意力機制的序列轉換模型,用多頭自注意力替代了編碼器-解碼器架構中常用的循環層。
-
性能提升: 作者指出,在WMT 2014英德和英法翻譯任務上,Transformer模型不僅達到了新的最佳性能,而且在某些情況下,甚至超越了之前所有報道的集成模型。
-
訓練效率: 論文突出了Transformer模型的訓練效率,與傳統的基于RNN或CNN的架構相比,它可以顯著更快地訓練,這在資源和時間有限的研究和應用環境中尤為重要。
-
未來工作: 作者表達了對基于注意力模型的未來發展的興奮,并提出了幾個未來的研究方向:
- 將Transformer模型擴展到除文本之外的其他輸入和輸出模態,如圖像、音頻和視頻。
- 探索局部、受限的注意力機制,以高效處理大型輸入和輸出。
- 研究如何使生成過程更少依賴序列化,這可能涉及到開發新的模型結構或訓練策略。
結論部分為整篇論文畫上了句號,總結了Transformer模型的主要貢獻,并展望了基于注意力機制的模型在未來的發展潛力和應用前景。通過強調模型的創新性和效率,以及對未來研究方向的規劃,論文為讀者提供了對Transformer模型深遠影響的認識。
附錄和致謝 (Appendix and Acknowledgements)
- 論文提供了注意力分布的可視化分析,展示了模型是如何關注句子中不同部分的。
- 作者對提供有益評論、更正和靈感的同事表示感謝。
參考文獻 (References)
- 論文列出了相關工作的參考文獻,為進一步研究提供了資源。
這個解讀基于提供的PDF文件內容,涵蓋了論文的主要章節和關鍵點。


申請的字典的類型是什么?)


:事件、文件)



:JVM虛擬機運行時棧幀結構)




存在被濫用的風險)
:循環語句)



