論文“”https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_DUSt3R_Geometric_3D_Vision_Made_Easy_CVPR_2024_paper.pdf?
代碼:GitHub - naver/dust3r: DUSt3R: Geometric 3D Vision Made Easy
????????? ? DUSt3R是一種旨在簡化幾何3D視覺任務的新框架。作者著重于使3D重建過程更加易于使用和高效。該框架利用深度學習和幾何處理的最新進展,提高了準確性并降低了計算復雜性。?
1 摘要
????????本文提出了DUSt3R,一種無需相機校準或視點位置信息即可處理任意圖像集合的密集、無約束立體3D重建的全新范式。我們將成對重建問題視為點圖的回歸,放寬了傳統投影相機模型的硬約束。這種方法統一了單目和雙目重建案例。
????????在提供多于兩張圖像的情況下,我們進一步提出了一種簡單但有效的全局對齊策略,將所有成對點圖表達在一個共同的參考框架中。我們基于標準Transformer編碼器和解碼器的網絡架構,利用強大的預訓練模型。???????
????????我們的方法直接提供了場景的3D模型以及深度信息,并且可以從中無縫地恢復像素匹配、焦距、相對和絕對相機參數。在單目和多視圖深度估計以及相對姿態估計方面的廣泛實驗展示了DUSt3R如何有效地統一各種3D視覺任務,創造新的性能記錄。總而言之,DUSt3R使許多幾何3D視覺任務變得簡單。
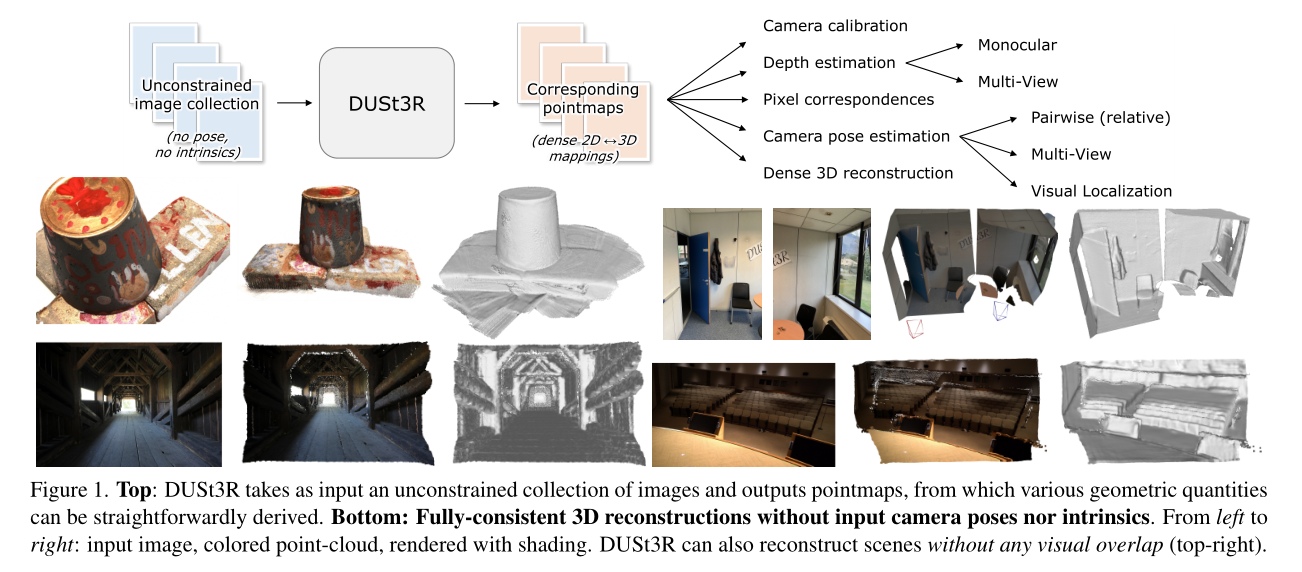
圖1展示了DUSt3R的工作流程和重建效果。
上半部分:DUSt3R以一組不受約束的圖像為輸入,輸出點圖(pointmaps),從這些點圖可以直接推導出各種幾何量。
下半部分:展示了DUSt3R在沒有輸入相機位姿或內參的情況下進行的一致3D重建。從左到右依次是輸入圖像、彩色點云、帶有陰影的渲染。右上角的圖示例展示了DUSt3R在沒有視覺重疊的情況下也能進行場景重建。
2 主要貢獻
- 簡化的流程:DUSt3R將傳統的多步驟3D視覺流程簡化為一個更直接的過程。這種簡化有助于減少錯誤并提高可用性。
- 魯棒性:該框架在各種數據集和場景中表現出魯棒性,包括不同的光照條件和遮擋情況。
- 高效性:通過優化算法組件和實現方式,DUSt3R在不犧牲準確性的情況下,實現了顯著的計算效率提升。
3 核心算法:?

?????????DUSt3R算法結合了現代深度學習技術和傳統幾何方法,通過高效的點云生成和三維重建技術,提供高精度和高魯棒性的三維重建結果。?
4? DUSt3R網絡的架構及其主要組件
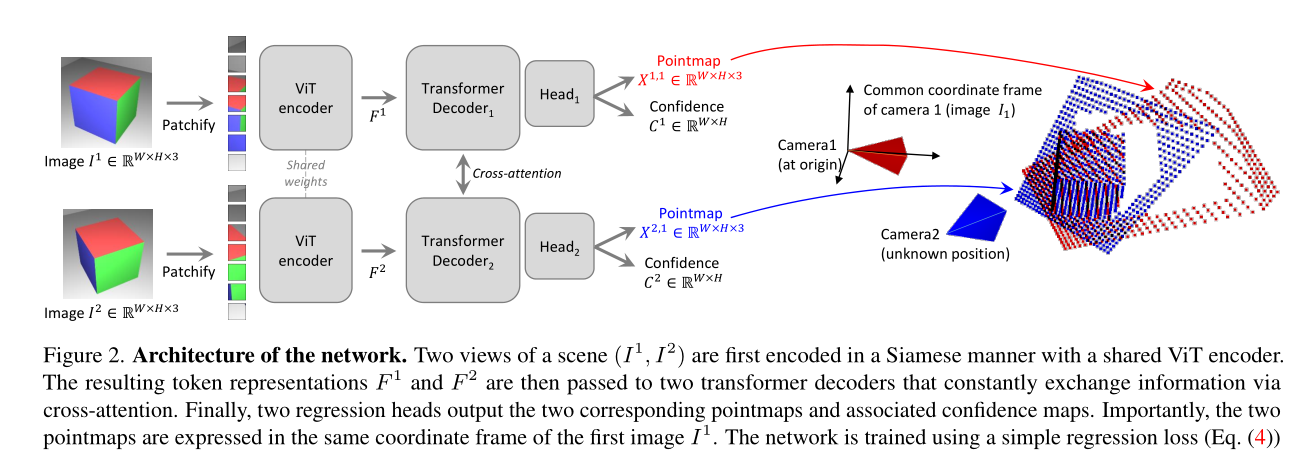
圖2展示了DUSt3R網絡的架構及其主要組件。這張圖形象地說明了網絡如何處理輸入的兩張RGB圖像(I1和I2),并生成對應的點云圖(Pointmap)和置信度圖(Confidence Map)。
網絡架構
-
輸入圖像
輸入是兩張RGB圖像,分別表示為I1和I2。I1表示由第一個相機拍攝的圖像,I2表示由第二個相機拍攝的圖像。
-
ViT編碼器(ViT Encoder)
輸入圖像I1和I2首先經過一個共享權重的ViT編碼器進行特征提取。ViT編碼器是一種基于視覺Transformer(ViT)的模型,用于將圖像轉化為Token表示(Token Representation)。編碼后的特征表示分別為F1和F2。
-
Patchify
編碼器輸出的Token表示F1和F2會被劃分成小塊(Patchify),每個塊表示圖像的一部分。
-
Transformer解碼器(Transformer Decoder)
經過Patchify處理后的特征表示F1和F2分別輸入到兩個Transformer解碼器中,這兩個解碼器通過交叉注意力機制不斷交換信息。交叉注意力機制允許解碼器在解碼過程中綜合兩張圖像的信息,從而提高點云圖的精度。
-
回歸頭(Regression Head)
Transformer解碼器的輸出結果傳遞給兩個回歸頭,分別對應輸入的兩張圖像。回歸頭負責生成最終的點云圖(X1,1和X2,1)和置信度圖(C1,1和C2,1)。
-
輸出
最終輸出的點云圖(X1,1和X2,1)和置信度圖(C1,1和C2,1)都以第一張圖像(I1)的坐標系為基準。這種設計簡化了后續的處理步驟,使得點云圖可以直接在同一坐標系下進行操作和分析。
訓練過程
- 損失函數
- 網絡使用簡單的回歸損失函數(公式4)進行訓練。損失函數基于預測的點云圖和真實點云圖之間的歐幾里得距離進行計算。
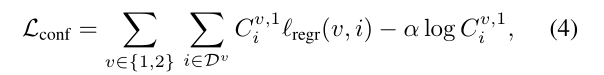
- 為了應對尺度模糊性,網絡對預測和真實的點云圖進行歸一化處理,通過計算所有有效點到原點的平均距離來確定縮放因子。
- 網絡還會學習為每個像素預測一個置信度分數,這個置信度分數表示網絡對該像素預測的可靠程度。最終的訓練目標是置信度加權的回歸損失。
5 實驗評估
5.1 無地圖視覺定位
????????數據集:使用了Map-free relocalization benchmark,這是一項非常具有挑戰性的測試,其中目標是在沒有地圖的情況下,僅憑一張參考圖像確定相機在公制空間中的位置。測試集包括65個驗證場景和130個測試場景。每個場景中,每幀視頻剪輯的姿勢必須相對于單個參考圖像獨立估計。
????????協議:評價標準包括絕對相機姿態準確性(以5°和25厘米為閾值)和虛擬對應重投影誤差(VCRE),后者測量虛擬3D點根據真實和估計相機姿態重投影誤差的平均歐氏距離。
結果:DUSt3R在測試集上的表現優于所有現有方法,有時優勢顯著,定位誤差小于1米。
5.2 恢復未知相機內參
????????數據集:使用了BLUBB數據集來評估DUSt3R在沒有內參信息的情況下恢復相機內參的能力。數據集提供了一系列場景,每個場景都具有已知的地面真實相機內參和3D點云。
????????協議:評價標準包括相機內參的準確性和重建的3D點云的完整性。DUSt3R通過估計場景的相對姿態和尺度,結合已知的地面真實3D點云來恢復內參。
????????結果:在沒有先驗相機信息的情況下,DUSt3R達到了平均2.7毫米的準確性,0.8毫米的完整性,總體平均距離為1.7毫米。這個精度水平在實際應用中非常有用,考慮到其即插即用的特性。
5.3 總結
????????DUSt3R在多個3D視覺任務中展示了其卓越的性能,無需對特定下游任務進行微調。該模型在零樣本設置下取得了令人印象深刻的結果,特別是在無地圖視覺定位和未知相機內參恢復任務中表現出色。實驗結果表明,DUSt3R不僅適用于3D重建任務,還能有效處理各種3D視覺任務,展示了其廣泛的應用潛力和實際使用價值。
5.4 可視化
????????論文包含了大量可視化內容,有助于理解概念和結果。這些包括流程圖、架構細節和重建3D模型的視覺比較。

圖3展示了兩個場景的重建例子,這兩個場景在訓練期間從未見過。圖像從左到右依次是:RGB圖像、深度圖、置信度圖和重建結果。以下是對每部分的詳細解析:
RGB圖像:
- 這是輸入的彩色圖像,為網絡提供了豐富的紋理和顏色信息,幫助進行3D重建。
深度圖:
- 這是網絡預測的深度圖,表示場景中每個像素到相機的距離。深度值越大,像素點離相機越遠。深度圖為重建提供了基礎的幾何信息。
置信度圖:
- 置信度圖表示網絡對每個像素深度預測的信心。高置信度區域通常表示預測較為準確的區域,而低置信度區域可能包含難以預測的部分,如天空、透明物體或反光表面。
重建結果:
- 左邊的場景顯示了直接從網絡f(I1, I2)輸出的原始結果。可以看到,網絡已經能夠較為準確地重建場景的3D形狀。
- 右邊的場景顯示了經過全局對齊(第3.4節)的結果。全局對齊步驟進一步優化了重建結果,使其更加精確和一致。
通過展示這些結果,圖3強調了DUSt3R方法在不同場景中的魯棒性和有效性,尤其是其在未見過的場景中的表現。此外,置信度圖的引入使得網絡能夠在不確定區域進行自適應調整,提高了重建的整體質量。
結論
????????DUSt3R在幾何3D視覺領域提供了顯著的進步。其簡化流程、結合魯棒性和高效性,使其成為計算機視覺研究人員和從業者的寶貴工具。詳細的實驗評估和全面的可視化進一步加強了論文的貢獻。



















服務器)