????????pandas使用Numpy的np.nan代表缺失數據,顯示為NaN。NaN是浮點數標準中地Not-a-Number。對于時間戳,則使用pd.NaT,而文本使用的是None。
首先構造一組數據:
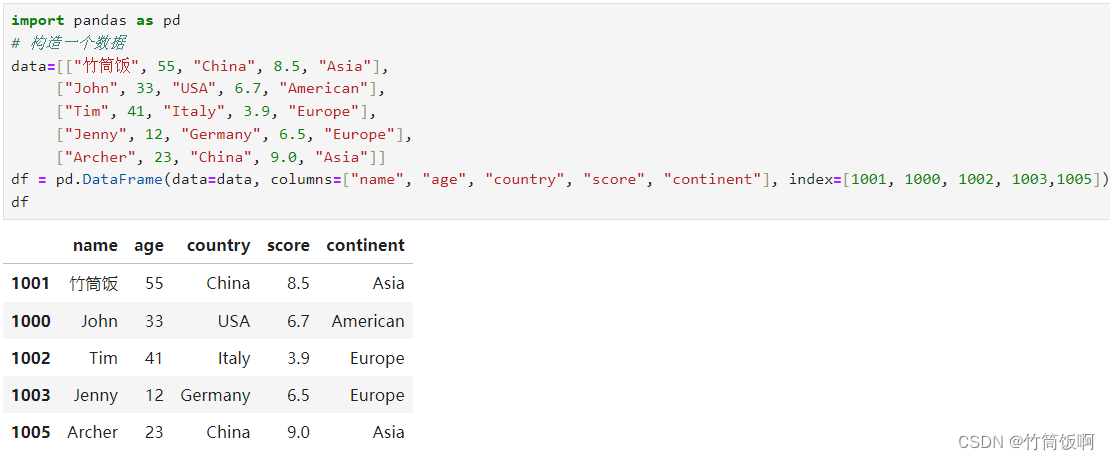
?使用None或者np.nan來表示缺失的值:

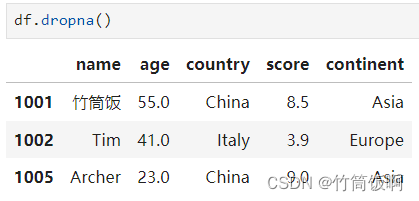
清理DataFrame時,如果要移除所有包含缺失數據的行:
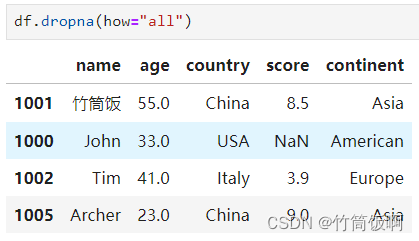
如果只想移除所有的值都缺失的行,可以使用how參數:
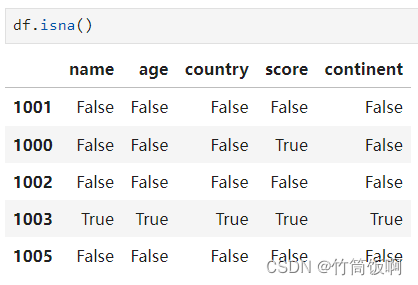
要想獲得一個反映對應位置上是否是NaN的布爾DataFrame或Series,可以使用isna方法:
還可以使用fillna來填補缺失的值,例如將score列中的NaN替換為平均值:
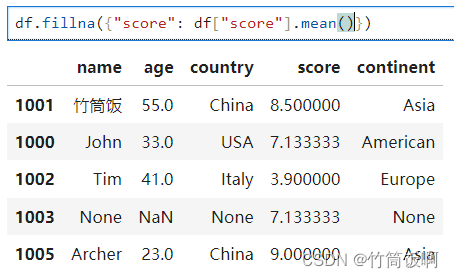
????????和缺失數據一樣,重復數據也會對數據分析的可靠性造成負面影響。可以使用drop_duplicates方法清理重復的行。也可以提供列的子集作為參數:
執行drop_duplicates("country", "continent"),如果某些行的country和continent都一樣,則保留第一行,刪除后續和它一樣的行。
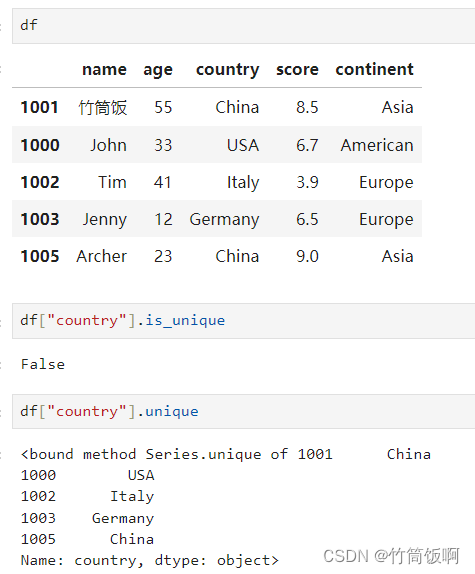
is_unique用于確認某一列是否包含重復的數據,unique則可以獲得去重后的值。
?
????????duplicated方法可以知道哪些行是重復的,它的返回值是一個布爾Series。keep參數默認值是first,意思是會保留第一次出現的數據,只將重復數據標記為True。將keep參數設置為False時,所有重復數據(包含第一次出現的數據)都會被標記為True。

?
?

——抽象工廠模式)






 、折射率(ior))




)



 葉子游戲新聞)

