一、容器內存概述
容器本質上還是一個進程,是一個被隔離和限制的進程。因此容器內存和進程內存在表現形式上其實是一樣的,這塊主要涉及三部分內容:RSS,page cache和swap這三部分,容器基于memory Cgroup對內存進行限制,但是具體限制的什么呢?又有哪些參數可以對其進行控制呢?
二、容器進程被莫名kill掉
在linux中當一個進程使用malloc申請分配內存的時候,操作系統并不會立即給該進程分配真實的物理存,此時分配的其實是虛擬內存。因此進程是可以申請超過物理內存上限的內存。為啥要這么設計呢?因為空閑內存空間是不斷變化的,有進程申請必然有進程歸還,此時申請的時候不夠,誰能保證下一個時刻還不夠呢?因此才有這個overcommit機制。
但是當一個進程在不斷向內存中寫數據的時候,如果內存還是不夠用,此時就會OOM,被操作系統kill掉,畢竟不能把數據寫到別的進程的內存空間中去,也算是一種保護機制。
當然kill掉是容器的默認行為,具體的這個行為是可以通過參數設置的。
其中43fxxxxxx 是容器的id,也就是每個容器都可以對其進行控制

還有幾個比較重要的參數

從文件名稱也可以看出來分別是最大限制,和當前使用。
每個運行的容器下面都有這些文件,可以自定義合適的參數值。
三、容器與page cache
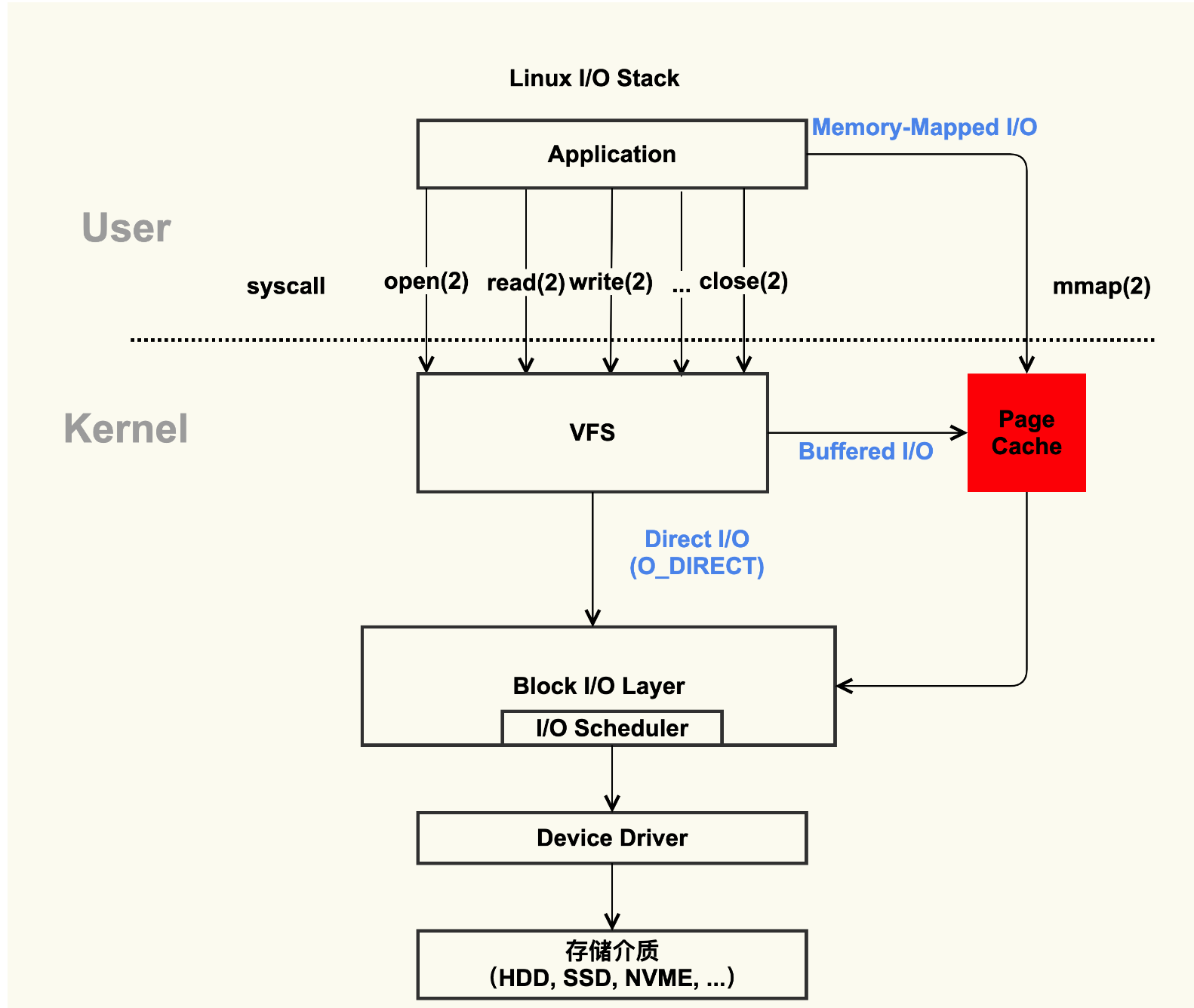
進程除了有自己獨立的RSS內存,如果涉及到文件的讀寫,linux還會為進程分配page cache,什么是page cache呢,page cache是操作系統在讀寫磁盤上的文件的時候,操作系統為了提升性能會預加載一部分內容到空閑的內存中來,而這部分空閑的內存則稱為page cache。
但是如果沒有空閑內存,而進程由要申請新的內存,則會回收page cache。保證內存供進程使用。
而上面提到的memory.usage.in_bytes = RSS + page cache
因此在某些情況下,memory.usage.in_bytes 是大于memory_limit_in_bytes的,但是不用擔心,因為page cache是自動回收的。
因此查看容器的真實的內存占用,查看memory.usage.in_bytes 是不準的,需要看:
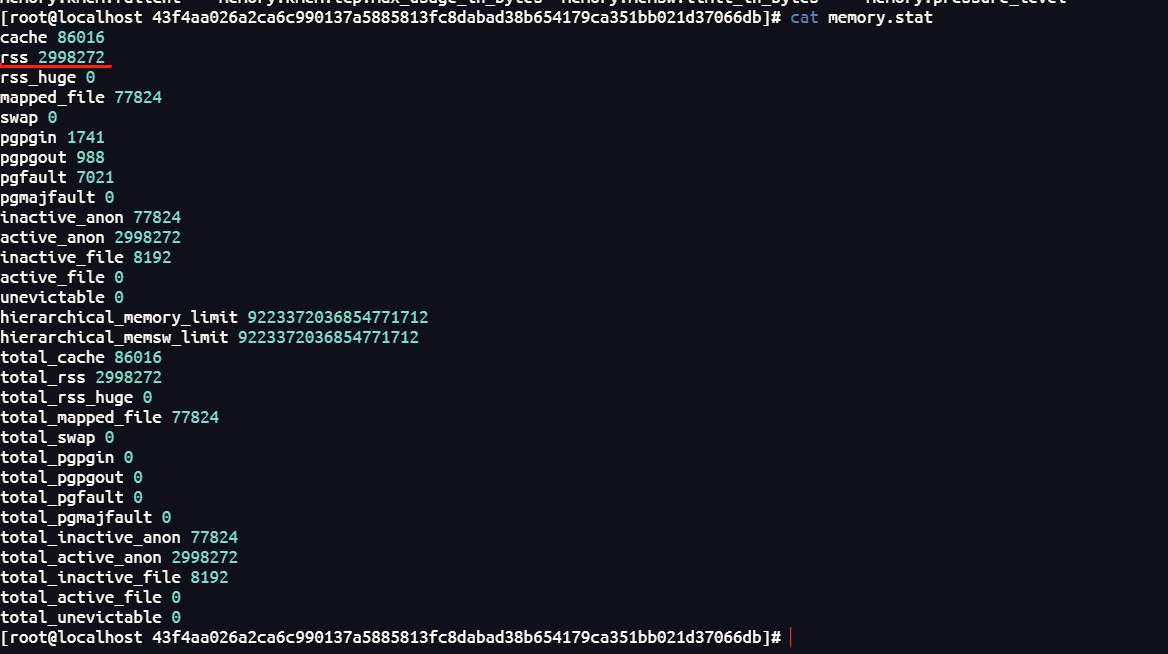
page cache不屬于傳統的內存限制范疇,是操作系統用來緩存文件的,不屬于用戶,屬于操作系統內核,每個容器都可以使用page cache。
紅色的部分就是page cache。
在關注容器的內存占用的時候,主要關注RSS。
四、容器和swap
swap其實并不是一塊內存空間,而是一塊磁盤空間,不過操作系統有時會將這塊磁盤空間當作內存使用而已。當內存寫滿的時候,操作系統可以將一部分不用的數據暫時存放到swap空間上,待需要的時候再從swap中加載進來。
那么當內存緊張的時候,操作系統是會選擇先釋放page cache呢還是先把冷數據放到swap中去呢?
這個可以針對每一個容器進行定制化,具體修改下面這個配置文件:

swappiness的取值范圍在0到100之間,
- 值為100的時候, 釋放Page Cache和寫冷數據到swap是同等優先級的。
- 值為60,這是大多數Linux系統的缺省值,這時候Page Cache的釋放優先級高于寫冷數據到swap。
- 值為0的時候,會限制該容器中的進程使用swap空間,僅對該容器生效
容器級別的swappiness會覆蓋操作系統級別的。
因此swap也不屬于傳統內存的限制范疇,每個容器都可以使用。
五、總結
memory cgroup 限制的是容器真正使用到的內存,對于swap和page cache 都是內核級別的,是由操作系統進行管理的,是所有進程共享的,是不能被memory cgroup所限制的。
)








路由v5.x(10)源碼(2)- history)

)






算法效率順序表)
