目????錄
摘??要
Abstract
第1章??前??言
1.1 ?項目的背景和意義
1.2 ?研究現狀
1.3 ?項目的目標和范圍
1.4 ?論文結構簡介
第2章??技術與原理
2.1 ?開發原理
2.2 ?開發工具
2.3 ?關鍵技術
第3章??需求建模
3.1 ?系統可行性分析
3.2 ?功能需求分析
3.3 ?非功能性需求
第4章??系統總體設計
4.1 ?系統總體目標
4.2 ?系統架構設計
4.3 ?數據庫設計
第5章??系統詳細設計與實現
5.1 實現系統功能所采用技術
5.2 用戶模塊設計
5.3 自媒體人模塊設計
5.4 后臺管理員模塊設計
第6章??系統測試與部署
6.1 測試內容
6.2 測試報告
6.3 系統運行
第7章??結論
7.1 ?總結
7.2 ?展望
參考文獻
致??謝
?股票分析與推薦系統設計與實現
摘 ?要
推動大數據技術在金融領域的應用:隨著大數據技術的發展,基于Hadoop和Spark的大數據平臺在各個行業得到了廣泛應用。然而,在金融領域,特別是在股票市場,這些技術的應用還相對較少[1]。通過本課題的研究,可以進一步推動大數據技術在金融領域的應用,提高股票市場的效率和準確性。
構建高效的股票分析與推薦系統:傳統的股票分析方法主要依賴于人工分析和專家的經驗。這種方法在處理大量數據時往往效率低下,且容易受到人為因素的影響。通過本課題的研究,可以構建高效的股票分析與推薦系統,提高股票分析的效率和準確性,同時降低人為因素的影響[2]。
擴展機器學習和深度學習在金融領域的應用:機器學習和深度學習是當前人工智能領域的重要分支,其在金融領域的應用也得到了廣泛的關注[3]。本課題將探討如何利用機器學習和深度學習技術對股票數據進行挖掘和分析,進一步擴展這些技術在金融領域的應用。
促進混合計算模型的研究與發展:本課題將研究如何將Hadoop和Spark兩種不同的計算模型進行有效的結合,以實現優勢互補。這將為混合計算模型在金融領域的應用提供新的思路和方法,同時也將促進混合計算模型的研究與發展。
本系統采用了Pandas+numpy、Hadoop+Mapreduce、Hive_sql、Springboot+Vue.js、MySQl等技術棧進行開發構建,具有良好的擴展性和并發性。同時,系統還使用了Sqoop將分析結果導入MySQL數據庫,使用Flask+echarts搭建可視化大屏界面,用Springboot+vue.js搭建web系統,實現智能推薦、股票預測、情感分析、知識圖譜等業務功能。
關鍵詞:股票分析與推薦系統;大數據;Pandas+numpy;Hadoop+Mapreduce;Springboot+Vue.js;;MySQL;
Stock analysis and recommendation system design and implementation
Abstract
Promoting the application of big data technology in the financial field: With the development of big data technology, big data platforms based on Hadoop and Spark have been widely used in various industries. However, in the financial field, especially in the stock market, these technologies are relatively small. Through the research of this project, the application of big data technology in the financial field can be further promoted, and the efficiency and accuracy of the stock market can be improved.
Establish an efficient stock analysis and recommendation system: Traditional stock analysis methods mainly depend on artificial analysis and expert experience. This method is often inefficient when processing a large amount of data and is easily affected by human factors. Through the research of this project, you can build an efficient stock analysis and recommendation system, improve the efficiency and accuracy of stock analysis, and reduce the impact of human factors.
The application of extended machine learning and deep learning in the financial field: Machine learning and deep learning are important branches in the current field of artificial intelligence, and their applications in the financial field have also received widespread attention. This topic will explore how to use machine learning and deep learning technology to dig and analyze stock data, and further expand the application of these technologies in the financial field.
第1章 ?前 ?言
1.1 ?項目的背景和意義
隨著信息技術的飛速發展和全球金融市場的日益繁榮,股票投資已成為廣大投資者的重要選擇之一。然而,股票市場的復雜性和不確定性使得投資者在做出投資決策時面臨巨大的挑戰。傳統的股票分析方法往往依賴于人工收集、整理和分析大量的市場數據,這不僅效率低下,而且難以準確捕捉市場的細微變化。因此,利用大數據技術構建一個高效、準確的股票分析與推薦系統,對于提高投資者的投資效率、降低投資風險具有重要意義。
近年來,大數據技術的快速發展為股票分析與推薦系統的構建提供了強有力的技術支持。通過收集、整合和分析來自多個渠道的股票市場數據,大數據技術可以揭示市場的內在規律和趨勢,為投資者提供有價值的投資參考。同時,隨著人工智能、機器學習等技術的不斷進步,股票分析與推薦系統的智能化水平也在不斷提高,能夠更準確地預測市場走勢,為投資者提供更加精準的投資建議。
項目可以提高投資效率:股票分析與推薦大數據系統能夠自動收集、整理和分析市場數據,為投資者提供實時的股票信息和分析報告。投資者可以通過系統快速了解市場動態、公司財務狀況等信息,從而更加高效地做出投資決策。降低投資風險:系統利用大數據技術和人工智能算法對市場進行深度分析,能夠揭示市場的內在規律和趨勢,為投資者提供準確的投資建議。這有助于投資者規避潛在的風險因素,降低投資風險。推動金融科技發展:股票分析與推薦大數據系統的構建需要綜合運用大數據、人工智能、機器學習等多種技術手段。該項目的實施將推動金融科技領域的創新和發展,為金融行業的數字化轉型提供有力支持。促進經濟發展:股票市場的穩定健康發展對于國家經濟的繁榮具有重要意義。股票分析與推薦大數據系統能夠為投資者提供更加精準的投資建議,有助于提高投資者的投資效率和信心,從而促進股票市場的穩定健康發展,為經濟發展注入強勁動力。
1.2??研究現狀
在數據采集方面,現代股票分析與推薦大數據系統能夠自動從多個渠道獲取包括歷史交易數據、新聞報道、公司財務報告等在內的海量信息。這些數據的準確性和完整性對于后續的分析和推薦至關重要。在數據處理方面,系統運用數據清洗、標準化和特征提取等技術,將原始數據轉換為可用于模型訓練的數值型向量。
在分析與推薦算法方面,股票分析與推薦大數據系統主要采用了機器學習、深度學習等先進技術。這些算法通過對歷史數據的學習和訓練,能夠揭示市場的內在規律和趨勢,為投資者提供有價值的投資建議。具體來說,系統可以采用基于監督學習的分類和回歸算法,預測股票價格的漲跌趨勢和具體數值;采用基于無監督學習的聚類算法,發現具有相似特征的股票群體;采用深度學習算法,自動提取市場數據中的關鍵特征,提高分析和推薦的準確性。
1.3 ?項目的目標和范圍
本項目旨在構建一個高效、準確、智能的股票分析和推薦大數據系統,以滿足投資者在股票投資過程中的多元化需求。具體目標包括:
(1)提供全面數據支持:系統能夠收集、整合來自多個渠道的股票市場數據,包括歷史交易數據、新聞資訊、公司財務報告等,為投資者提供全面、豐富的信息支持。
(2)實現智能分析:通過運用先進的數據挖掘和機器學習算法,系統能夠自動分析市場數據,揭示市場的內在規律和趨勢,為投資者提供有價值的投資參考。基于投資者的風險偏好、投資目標和歷史投資行為,系統能夠生成個性化的股票推薦列表,幫助投資者快速篩選出符合其需求的投資標的。
(3)提高投資效率:通過自動化和智能化的分析與推薦流程,系統能夠大大縮短投資者的投資決策時間,提高投資效率。通過為投資者提供準確、及時的投資建議,系統有助于引導市場資金的合理流動,促進股票市場的穩定健康發展。
本項目的范圍涵蓋了從數據收集、處理、分析到推薦的全過程,具體包括以下幾個方面:
(1)據源管理:系統需要定義和管理從多個渠道獲取的數據源,包括證券交易所、財經媒體、公司官方網站等,確保數據的準確性和完整性。
(2)數據處理:系統需要對原始數據進行清洗、標準化和特征提取等處理,以提高數據的質量和可用性。同時,系統還需要支持流式處理,實現對市場數據的實時更新和分析。
(3)分析與推薦算法:系統需要實現多種先進的股票分析和推薦算法,包括基于監督學習的分類和回歸算法、基于無監督學習的聚類算法以及深度學習算法等。這些算法需要能夠準確地預測股票價格的漲跌趨勢和具體數值,并為投資者提供個性化的投資建議。
(4)用戶界面設計:系統需要設計直觀、易用的用戶界面,方便投資者查看市場數據、分析結果和推薦列表。同時,系統還需要支持多種終端設備的訪問,如電腦、手機和平板電腦等。
(5)系統測試與維護:在項目開發過程中,需要進行全面的系統測試,確保系統的穩定性和可靠性。在項目上線后,還需要進行持續的維護和更新,以適應市場變化和投資者需求的變化。
1.4 ?論文結構簡介
本論文主要研究校園新聞發布系統的架構設計與具體實現問題,主要包含前沿、技術與原理、需求建模、系統總體設計、系統詳細設計與實現、系統測試與部署和總結和展望這幾個部分。通過從零到一,從無到有,從底層到具體實現,描述項目的構建過程。
第2章 ?技術與原理
2.1 ?開發原理
本系統利用Hadoop和Hive對股票數據進行深入分析和可視化,為投資者提供更加準確、全面的決策支持。本研究的成果將有助于提高投資者的決策效率和準確性,同時為金融領域的大數據應用提供新的思路和方法。本研究將采用以下步驟進行:
1、數據采集:收集股票市場的歷史數據和實時數據,包括股票價格、成交量、財務指標等。
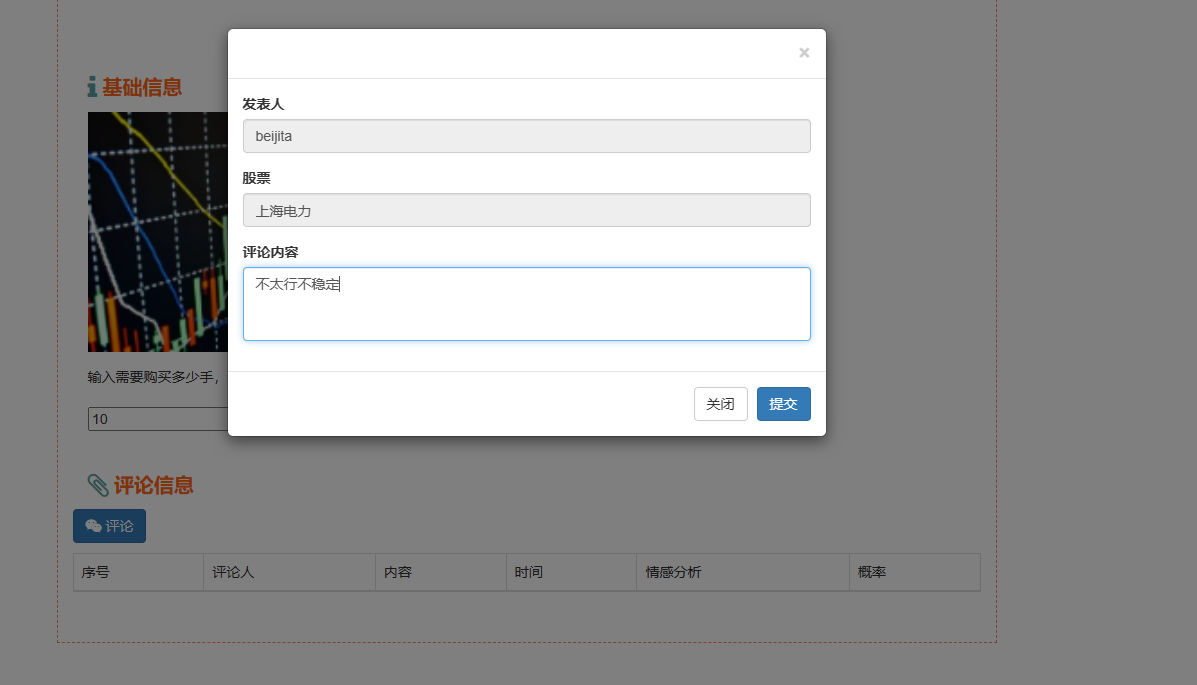
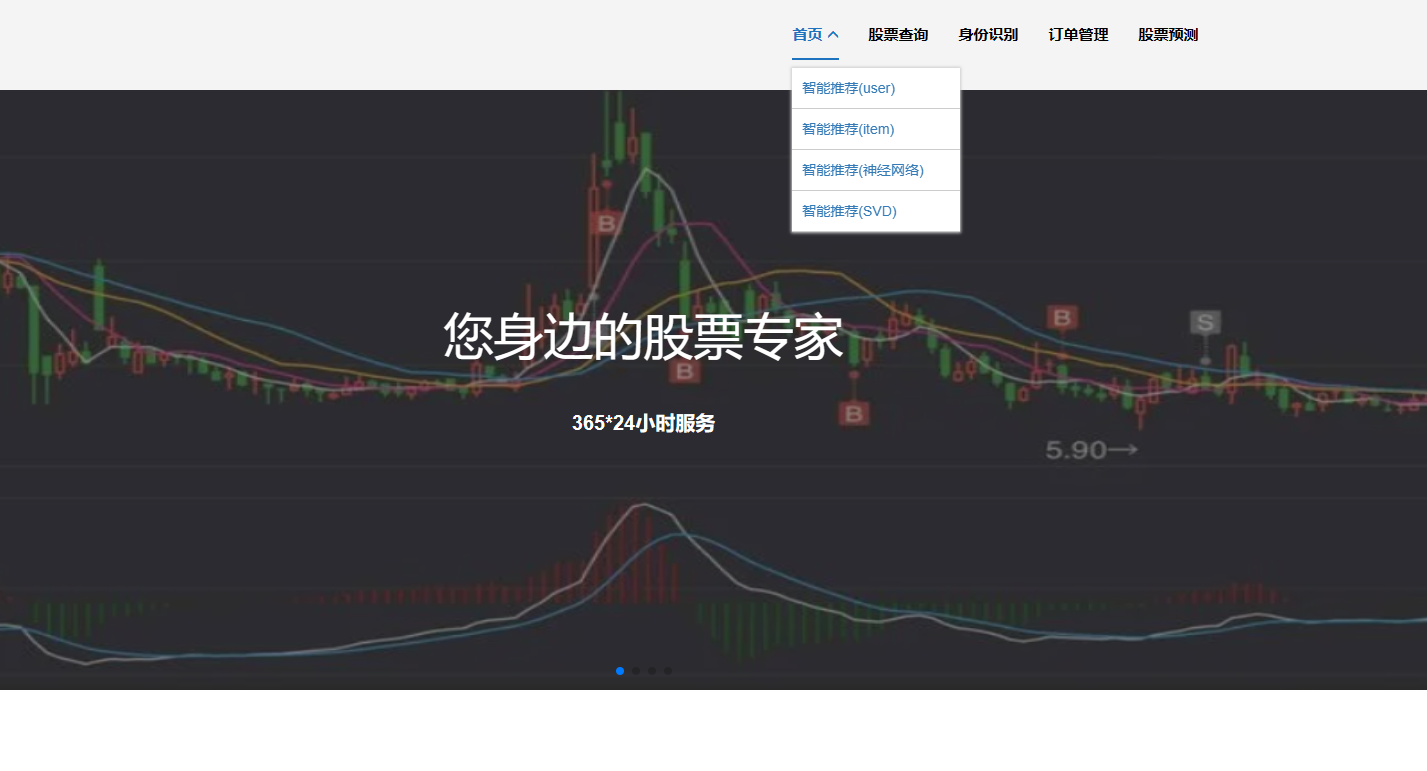
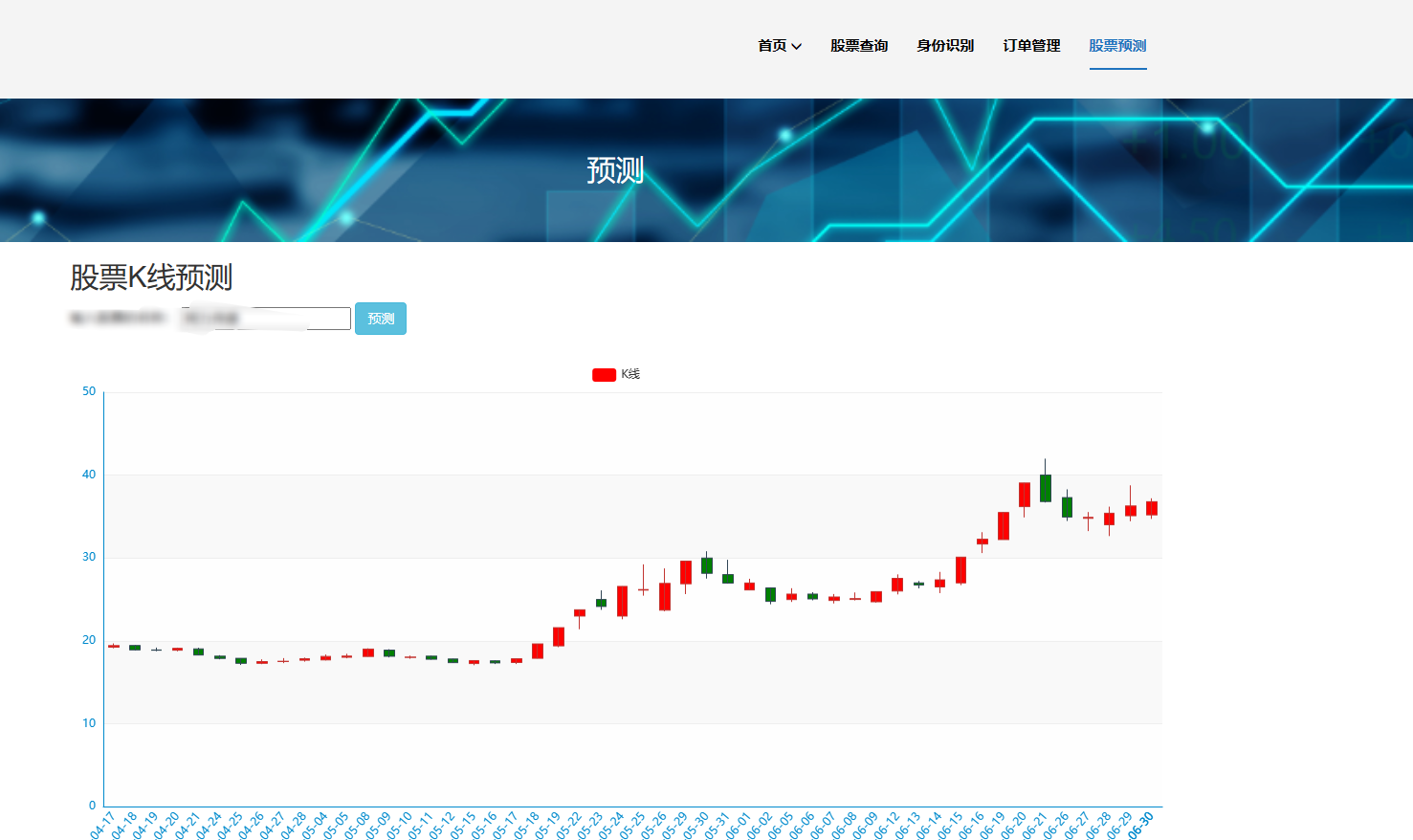
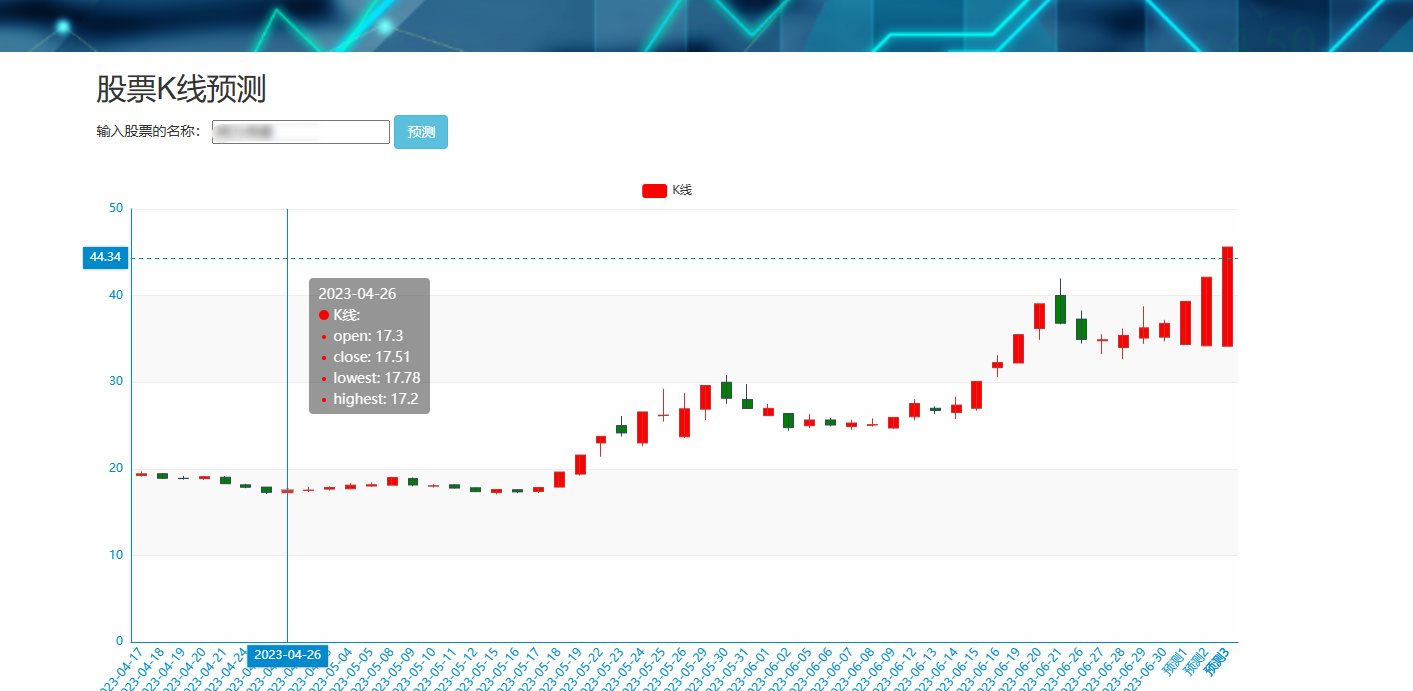
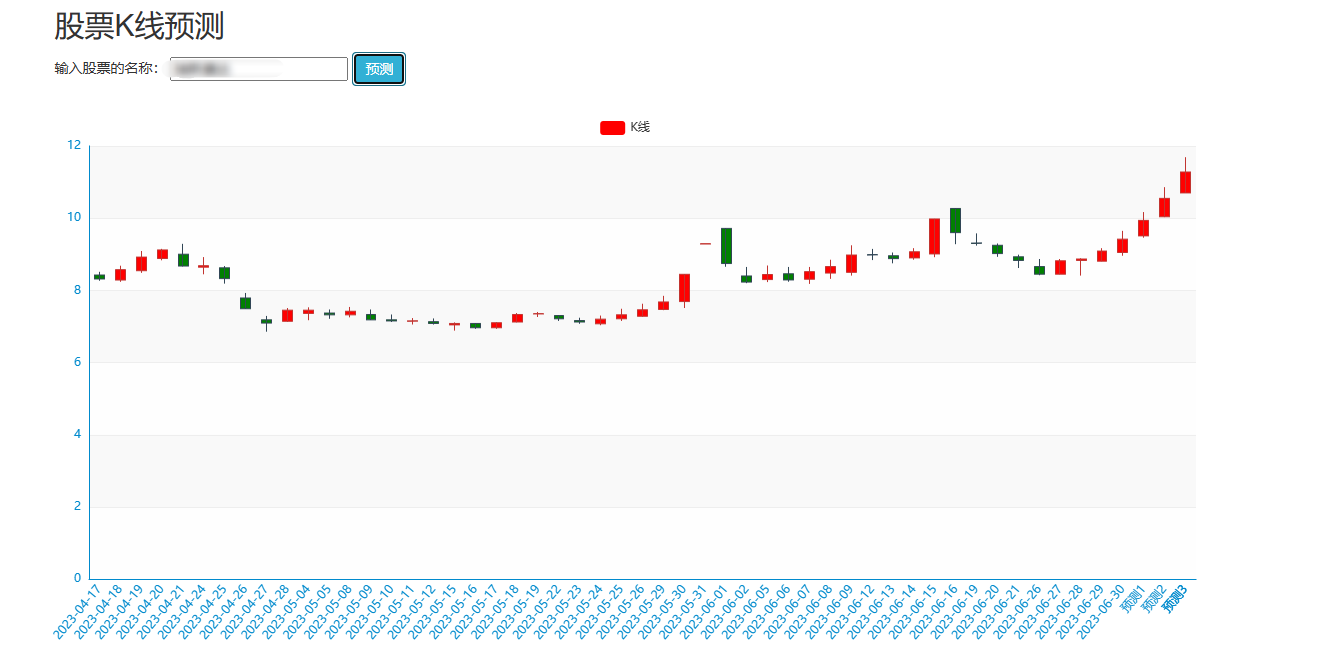
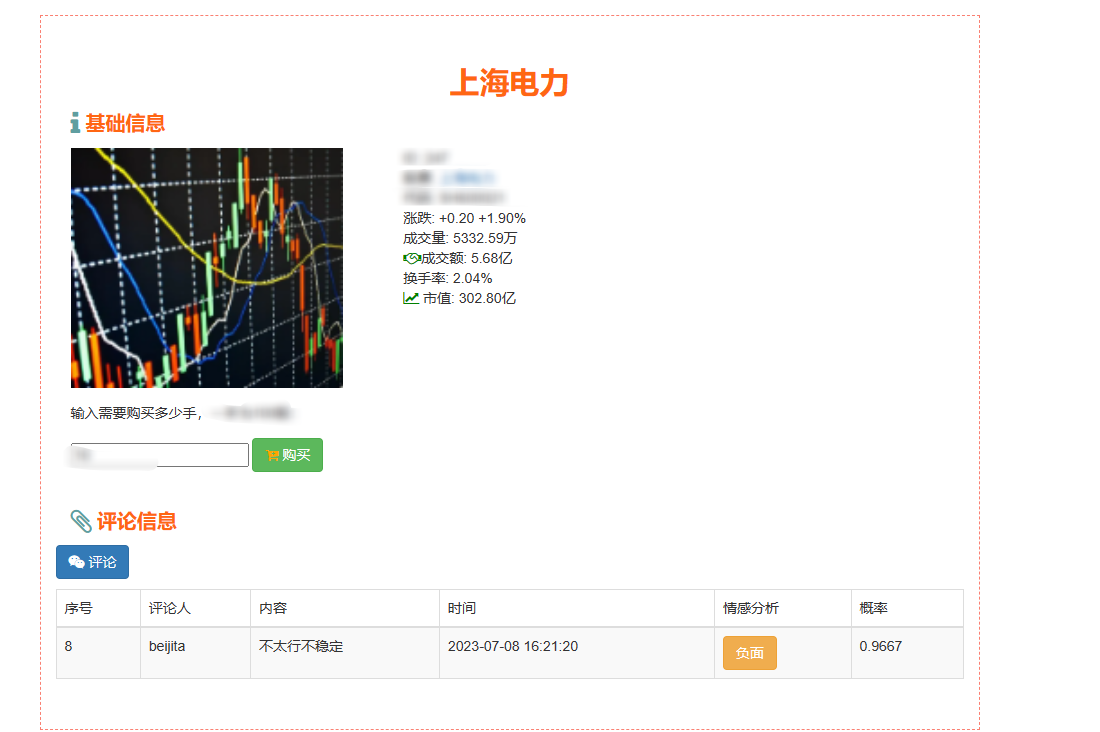
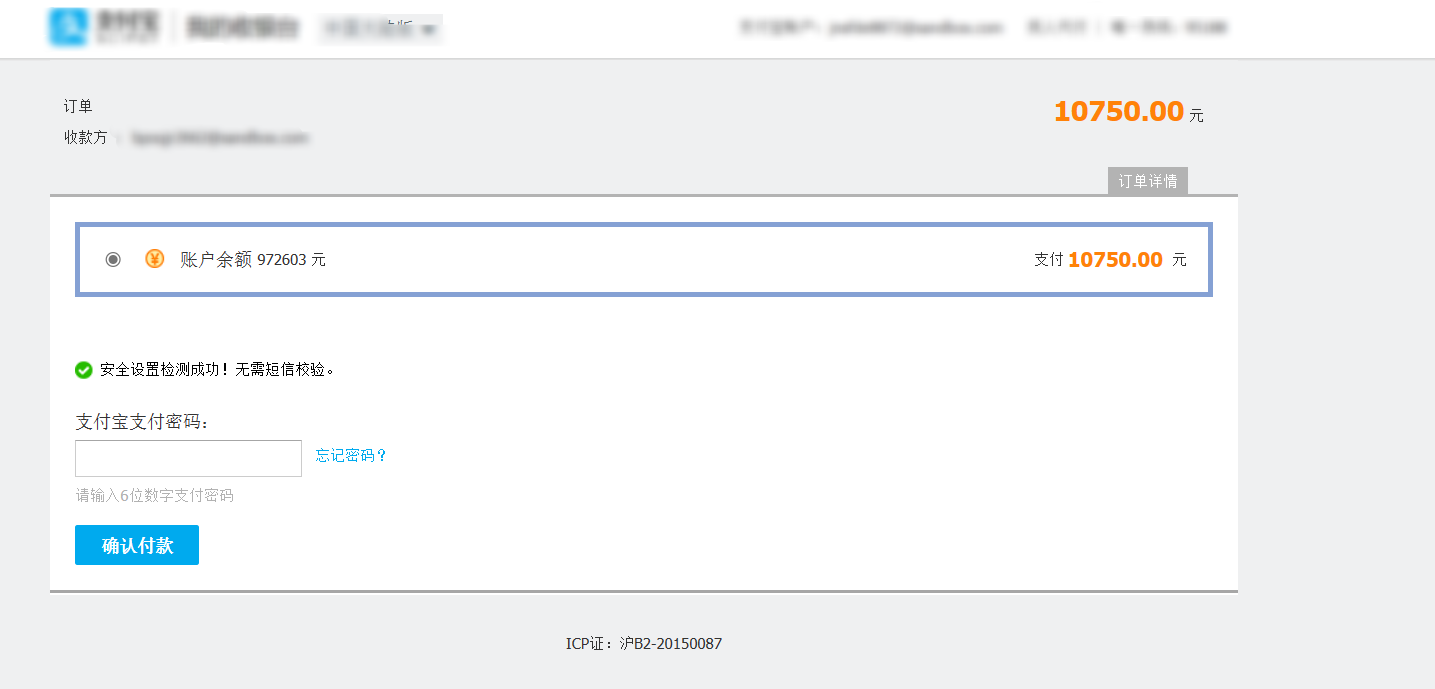
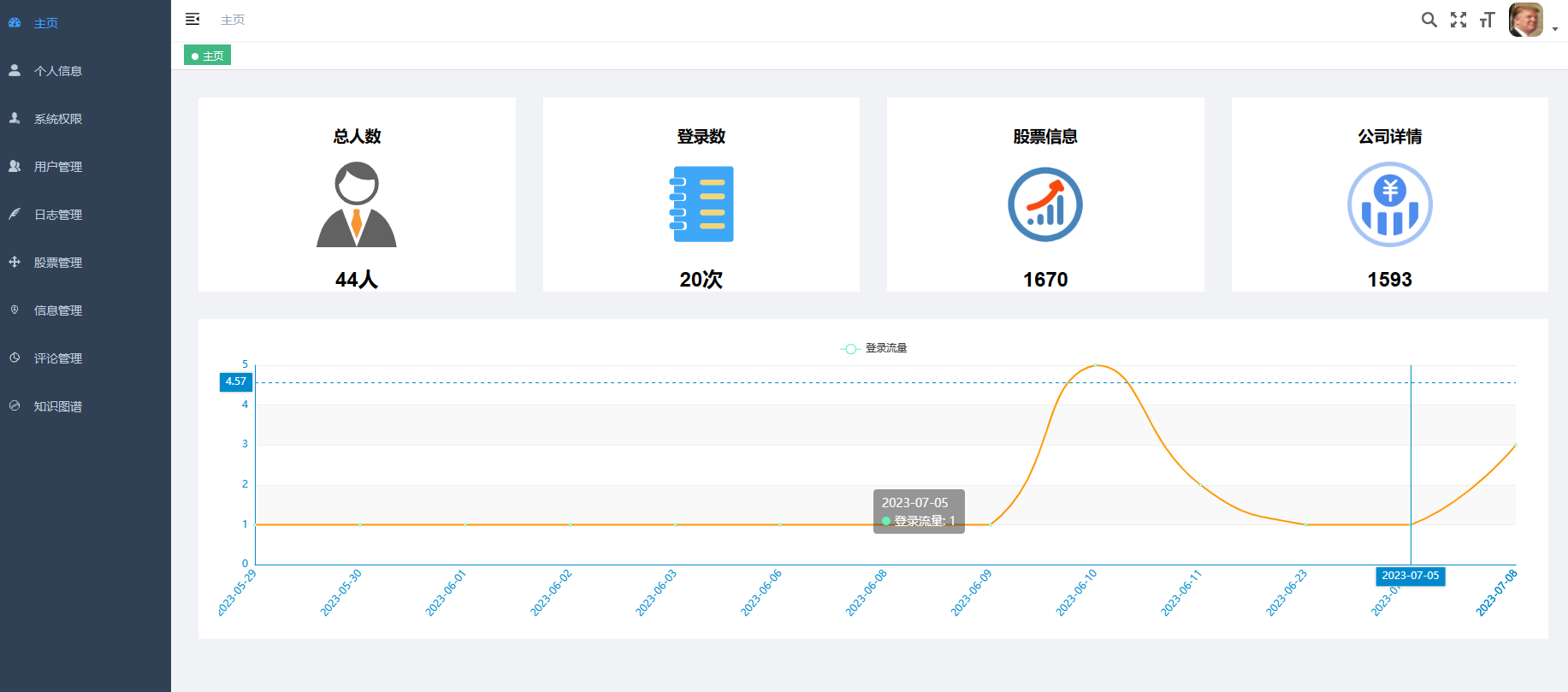
2、門戶系統:首頁股票信息展示;股票推薦(根據協同過濾基于用戶、物品、SVD神經網絡、MLP模型);股票K線預測(CNN卷積神經預測 );股票信息詳情(股票代碼,漲跌幅度,成交量,成交額,換手率,股票市值); 支付寶購買股票;訂單管理;股票信息評論(lstm情感分析模型)。
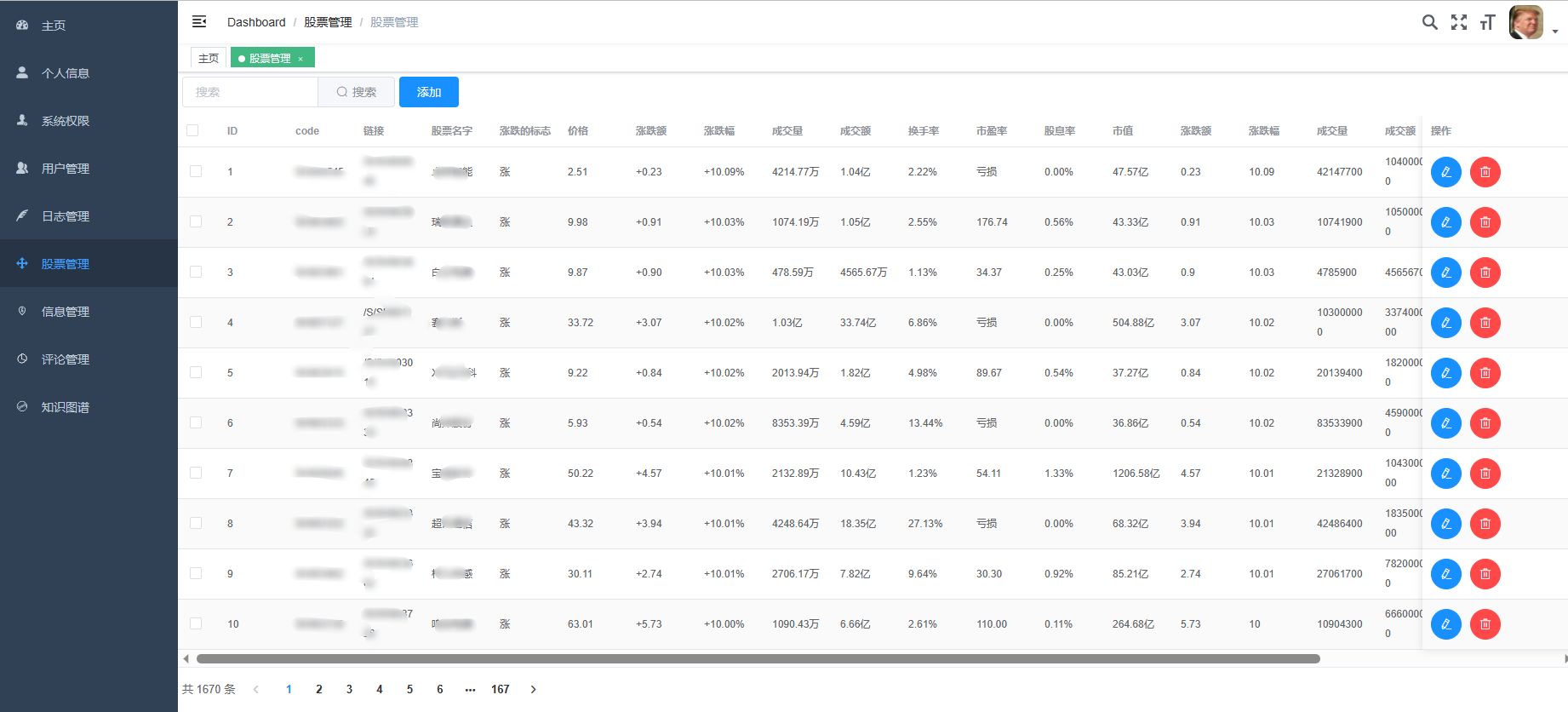
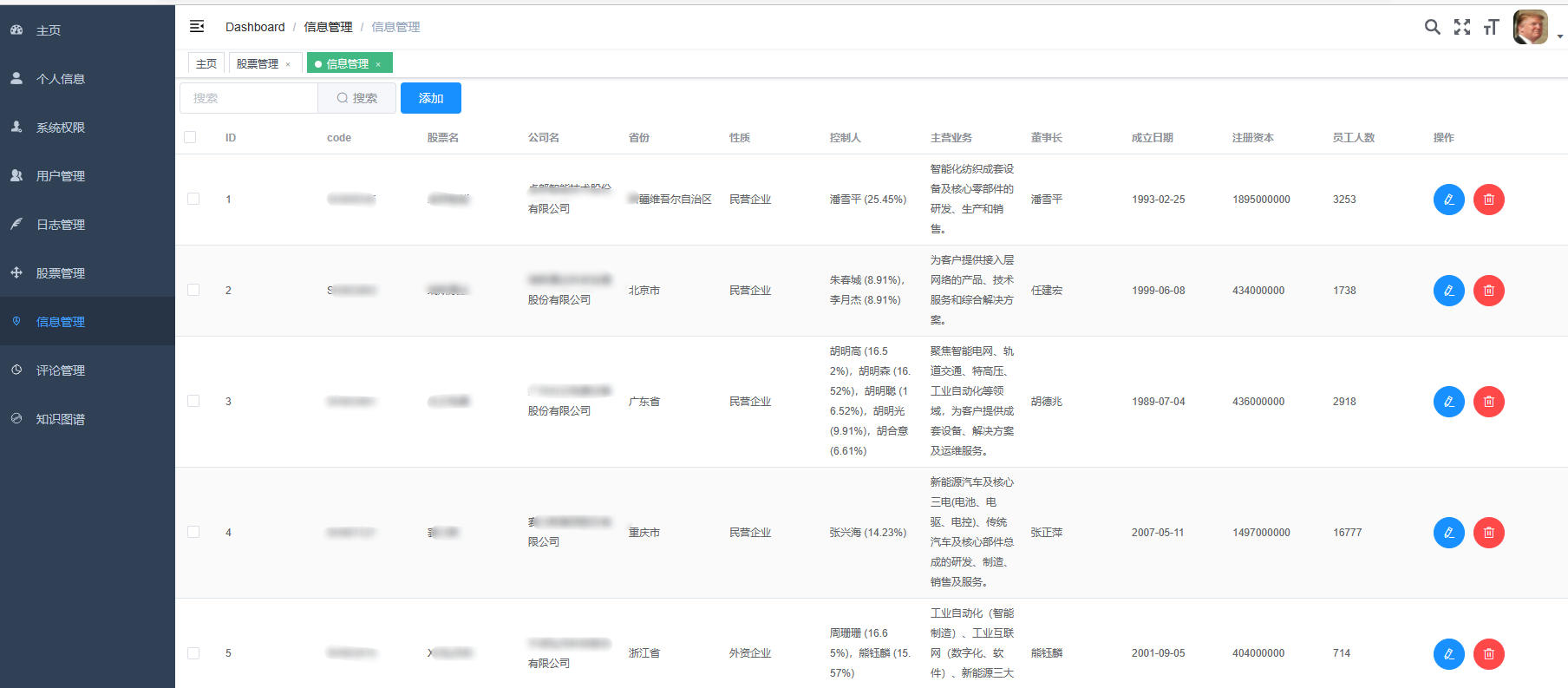
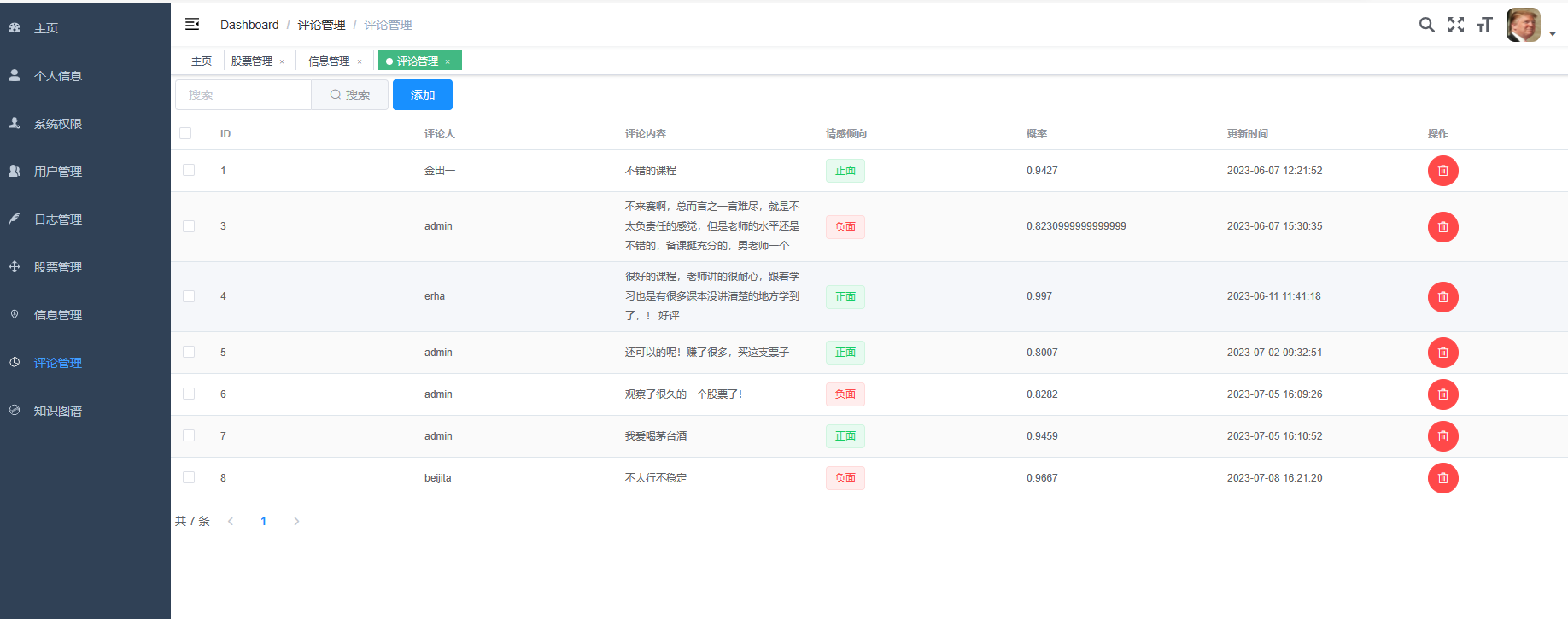
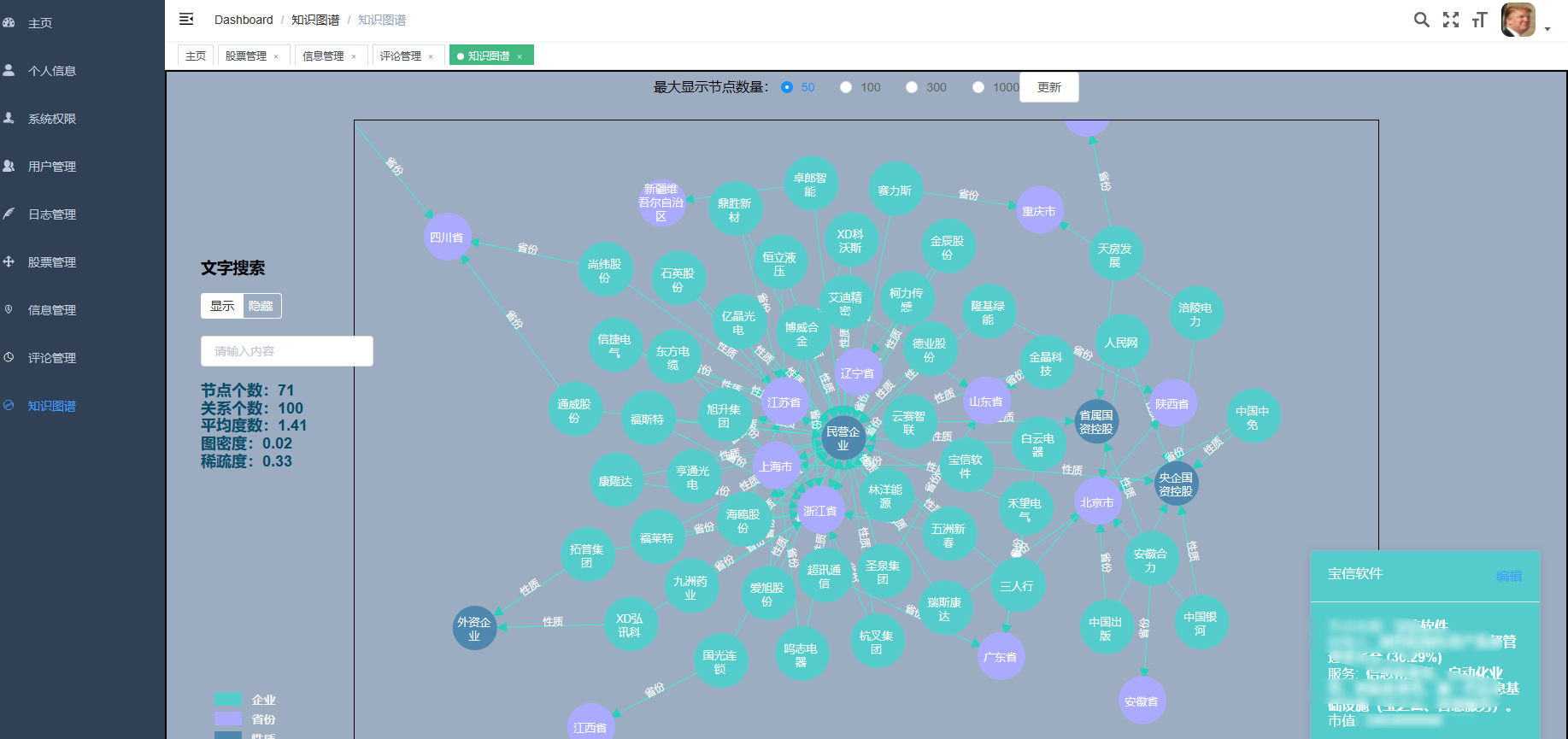
3、后臺管理系統:個人信息管理;系統管理;用戶管理;股票信息管理;評論信息管理;知識圖譜。
2.2 ?開發工具
2.2.1 ?Pandas
Pandas是Python語言的一個擴展程序庫,主要用于數據分析。它最初由AQR Capital Management于2008年4月開發,并在2009年底作為開源項目發布,之后由PyData開發團隊繼續開發和維護。Pandas的名稱來源于“panel data”(面板數據)和“Python data analysis”(Python數據分析),這體現了其作為數據分析工具的核心價值。
Pandas提供了高性能、易于使用的數據結構和數據分析工具,這些工具基于高性能數學運算庫Numpy,能夠支持從各種文件格式如CSV、JSON、SQL和Excel等導入數據。Pandas的主要特點包括功能強大、兼容性強和處理速度快。
Pandas的一些常見使用場景包括:
數據整理和清洗:Pandas可以將不同的數據源整理成一張表格,方便數據的整合和清洗。它支持缺失值的處理、數據類型的轉換、重復數據的刪除、不一致數據的糾正等。
數據探索性分析:Pandas可以用于數據的探索性分析,它可以給出數據的一些基本統計信息,如平均數、中位數、標準差、最大值、最小值等。同時,Pandas還可以繪制數據的各種圖表,如直方圖、散點圖、折線圖等,方便數據可視化。
數據建模和分析:Pandas可以用于數據建模和分析,它可以將數據集中的一些變量作為自變量,另一些變量作為因變量,進行各種建模和分析。Pandas支持線性回歸、邏輯回歸、決策樹、聚類等各種模型。
2.2.2 ?Numpy
NumPy(Numerical Python)是Python的一個開源數值計算擴展庫,也是Python科學計算的基礎軟件包。它提供了強大的N維數組對象、精密的廣播功能函數、線性代數、傅里葉變換和隨機數生成等功能。NumPy的主要特點包括:
多維數組對象:NumPy引入了多維數組對象(稱為numpy.ndarray或簡稱為數組),允許在單個數據結構中存儲和操作多維數據,如向量、矩陣和張量。這使得NumPy在處理大型矩陣和進行復雜數學運算時非常高效。
高效的數值運算:NumPy的底層實現是用C語言編寫的,因此它能夠執行高效的數值計算。此外,由于ndarray中的所有元素類型相同,數據在內存中是連續存儲的,這進一步提高了批量操作數組元素的速度。
豐富的數學函數庫:NumPy包含了大量的數學函數,用于執行各種數值計算,如三角函數、指數函數、對數函數等。此外,它還提供了線性代數操作的函數,如矩陣乘法、特征值分解、奇異值分解等,使其成為數值線性代數的強大工具。
強大的索引和切片功能:NumPy提供了豐富的索引和切片功能,允許用戶高效地訪問和操作數組的元素。這使得在處理大型數據集時能夠快速地提取所需信息。
互操作性:NumPy與其他常用的科學計算庫(如SciPy、pandas和Matplotlib)緊密集成,使得在不同庫之間傳遞數據變得非常容易。這使得NumPy在數據科學、機器學習、圖像處理等領域得到了廣泛應用。
NumPy的主要用途包括:
矩陣運算:NumPy提供了各種矩陣運算功能,如矩陣乘法、轉置和分解等,方便進行矩陣運算。
存儲和處理大型矩陣:NumPy可以用來存儲和處理大型矩陣,并能夠高效地進行矩陣運算。
數組操作:NumPy的核心功能是ndarray對象,它是一個多維數組,可以進行快速的數值計算和數組操作。
數值計算:NumPy提供了大量的數學函數,包括線性代數、傅里葉變換、隨機數生成等。
數據處理:NumPy可以方便地處理和操作多維數組,可以對數據進行排序、去重、篩選、統計等操作。
科學計算:NumPy廣泛應用于科學計算領域,如物理學、生物學、化學、地理學等。
2.2.2 ?Springboot
Spring Boot是一個基于Spring框架的開源框架,旨在簡化新Spring應用的初始搭建以及開發過程。
Pivotal團隊于2013年開始研發Spring Boot,并在2014年4月發布了全新開源的輕量級框架的第一個版本。Spring Boot通過自動化配置(Auto-configuration)的機制,根據項目中引入的依賴和約定,自動配置應用程序中的各種組件和功能。這減少了開發人員手動編寫大量XML或注解配置的工作量,降低了出錯的可能性。
Spring Boot提供了強大的插件體系和廣泛的集成,可以輕松地與其他技術棧集成,如Thymeleaf模板、JPA、MyBatis、Redis、MongoDB等,同時也支持對微服務的開發和管理.Spring Boot在項目中的主要用途包括快速開發、自動配置、內嵌服務器和監控與管理。它大大簡化了Spring應用程序的開發和部署過程,使開發人員可以更加專注于業務邏輯的實現。
2.2.2 ?虛擬機
VirtualBox:VirtualBox是一款由Oracle開發和維護的免費開源虛擬化軟件。它允許用戶在單個物理計算機上運行多個操作系統,如Windows、Linux、macOS等。VirtualBox提供了一個完整的虛擬化環境,包括虛擬機配置、啟動、關閉、快照、網絡設置等功能。
VMware Workstation/Fusion:VMware是全球最知名的虛擬化企業之一,其Workstation和Fusion產品分別針對PC和Mac用戶提供虛擬化解決方案。這些產品支持廣泛的操作系統,并提供強大的虛擬機管理功能,如虛擬機克隆、快照、網絡設置等。VMware Fusion還特別針對Mac用戶提供了Unity View模式,使得不同操作系統界面之間無縫銜接。
oVirt:oVirt是一款開源虛擬化管理平臺,專注于管理大規模虛擬化數據中心。它作為紅帽企業虛擬化(RHEV)的核心組件起步,現已發展成為一個獨立、功能齊全的虛擬化管理解決方案。oVirt強調可擴展性、穩定性和與其他開源工具的集成,為經濟高效且功能強大的虛擬化管理平臺提供了理想選擇。
QEMU:QEMU是一個快速、可移植的開源機器模擬器和虛擬化器。它可以模擬多種處理器架構,并在多種主機操作系統上運行。QEMU支持廣泛的設備模擬和操作系統,為用戶提供了強大的虛擬機模擬和虛擬化能力。
KVM(Kernel-based Virtual Machine):KVM是一種基于Linux內核的虛擬化技術。它將Linux內核轉換為虛擬機監控器(Hypervisor),使得用戶可以在Linux系統上直接運行虛擬機。KVM與QEMU結合使用,提供了強大的虛擬機管理和性能優化功能。
Parallels Desktop:Parallels Desktop是一款專為Mac用戶設計的虛擬化軟件。它允許用戶在Mac計算機上同時運行多個操作系統,如Windows、Linux等。Parallels Desktop提供了卓越的虛擬化技術,確保流暢穩定的運行,并支持多種特色功能,如共享打印、TouchID集成等。
2.3 ?關鍵技術
2.3.1 ?Hdoop+Mapreduce
HDFS(Hadoop Distributed File System):HDFS是Hadoop的分布式文件系統,用于存儲大數據集。它是Hadoop生態系統中的核心項目之一,是分布式計算中數據存儲管理的基礎。HDFS將數據分散存儲在一組計算機上,形成分布式存儲,具有高容錯性、高吞吐量的特點,適合存儲大規模數據集。
MapReduce:MapReduce是一種編程模型,用于處理大規模數據集(大于1TB)。MapReduce將復雜的運行于大規模集群上的并行計算過程高度地抽象為了兩個函數:Map和Reduce。Map階段將輸入數據劃分為多個數據塊,并對每個數據塊進行獨立處理,產生一系列中間結果;Reduce階段則將具有相同鍵的中間結果合并,得到最終結果。MapReduce提供了高效的數據處理框架,能夠自動處理數據的劃分、調度、執行和結果收集等過程。
YARN(Yet Another Resource Negotiator):YARN是Hadoop 2.0中的資源管理器,用于管理Hadoop集群中的計算資源。YARN的主要功能是跟蹤集群中的資源使用情況,協調和監控運行在集群上的應用程序。YARN將JobTracker的兩個主要功能(資源管理和作業調度/監控)分離成單獨的組件,從而提高了集群的可靠性和可擴展性。
HBase:HBase是一個分布式的、面向列的開源數據庫,可以認為是HDFS的封裝,本質是數據存儲、NoSQL數據庫。HBase適用于非結構化數據存儲的場合,在需要實時讀寫、隨機訪問超大規模數據集時,表現得尤為出色。
Sqoop:Sqoop是一款開源的數據導入導出工具,主要用于在Hadoop與傳統的數據庫間進行數據的轉化。Sqoop通過JDBC/ODBC連接數據庫,將數據庫中的數據導入到HDFS中,或將HDFS中的數據導出到數據庫中。
2.3.2 ?Hive
在大數據領域,Hive是一個非常重要的工具,它基于Hadoop構建,主要用于數據倉庫的存儲、查詢和分析。以下是Hive的主要特點和功能:
數據倉庫角色:Hive可以存儲和管理大規模的結構化和半結構化數據。它使用分布式文件系統(如HDFS)來存儲數據,并提供了對底層存儲系統的抽象,使得用戶可以快速查詢和分析存儲在Hadoop集群中的數據。
查詢引擎角色:Hive提供了類似于SQL的查詢語言(HiveQL),使得用戶可以用熟悉的SQL語法來查詢和分析數據。Hive將HiveQL查詢轉換為MapReduce作業來執行,利用Hadoop集群的并行處理能力進行高效的數據處理。通過這種方式,Hive使得用戶可以輕松地進行復雜的計算和分析操作。
數據存儲:Hive可以將大量結構化和半結構化數據存儲在Hadoop分布式文件系統中,以便后續查詢和分析。
數據查詢和分析:Hive支持類SQL語言的查詢操作,用戶可以使用HiveQL語言編寫查詢,并進行數據分析和統計。Hive可以對存儲在數據倉庫中的數據進行復雜的數據分析操作,如聚合、排序、連接等。
數據管理:Hive提供了數據倉庫的管理功能,包括數據表的創建、刪除、修改以及數據權限管理等功能。
數據導入導出:Hive支持將數據從其他數據源導入到數據倉庫中,也可以將數據從數據倉庫導出到其他系統中使用。
報表生成和可視化展示:Hive提供了豐富的報表生成功能,可以幫助企業快速生成各種報表以監控業務運行情況。同時,Hive還可以將數據分析結果進行可視化展示,如圖表、圖像等,以便用戶更好地理解和使用數據。
2.3.3 ?Flask
Flask是一個輕量級的Web開發框架,它使用Python編寫,具有簡潔、靈活和易于擴展的特點。這使得Flask成為開發小型到中型Web應用程序的理想選擇,特別是在大數據環境中,當需要快速構建和部署Web服務以支持數據處理、分析和可視化時。
Flask框架與各種數據可視化庫(如Plotly、Pyecharts等)結合使用,可以輕松地創建交互式圖表和可視化效果。通過Flask的后端處理,可以將數據轉換為可視化圖表,并通過Web界面展示給用戶。這使得大數據分析師和開發人員能夠更直觀地理解和分析數據。Flask也常用于開發RESTful API,這些API可以用于在Web應用程序、移動應用程序或其他客戶端之間傳輸數據。在大數據環境中,API可以用于從數據源獲取數據、處理數據并將結果返回給客戶端。Flask的輕量級和靈活性使其成為開發高效、可擴展的API的理想選擇。
在大數據項目中,Flask常用于實現前后端分離的開發模式。后端使用Flask框架處理數據請求和響應,而前端則使用JavaScript、HTML和CSS等技術構建用戶界面。這種開發模式可以提高開發效率,降低維護成本,并使得前后端開發人員可以獨立工作。Flask具有良好的可擴展性,支持第三方插件和擴展。這些插件和擴展可以擴展Flask的功能,滿足大數據項目中的各種需求。例如,可以使用Flask-SQLAlchemy擴展來簡化數據庫操作,使用Flask-Login擴展來實現用戶認證和授權等。
2.3.4 ?Echarts
ECharts在大數據中的作用主要體現在數據可視化方面。它是一個使用JavaScript編寫的開源可視化庫,可以在瀏覽器中生成高質量的圖表和圖形,幫助用戶更直觀地理解和分析大數據。
以下是ECharts在大數據中的一些主要作用:
ECharts支持多種圖表類型,包括折線圖、柱狀圖、餅圖、散點圖、地圖等,幾乎涵蓋了所有常見的數據可視化需求。這使得用戶可以根據數據的特點和需要選擇合適的圖表類型,以更直觀的方式展示數據。
ECharts支持多維數據的可視化,例如對于傳統的散點圖等,傳入的數據也可以是多個維度的。這使得用戶可以在同一圖表中展示多個維度的數據,更全面地了解數據的特征和關系。
ECharts提供了豐富的交互功能,用戶可以通過鼠標、鍵盤等設備與圖表進行交互,例如縮放、拖拽、選擇等。這些交互功能使得用戶可以更深入地探索和分析數據,發現其中的規律和趨勢。
ECharts允許用戶自定義圖表的樣式和行為,包括顏色、字體、標簽、動畫等。這使得用戶可以根據需要定制出符合自己品牌或主題的圖表,提高圖表的個性化和專業化程度。
ECharts可以在PC和移動設備上流暢運行,并且對移動端進行了優化,確保在不同設備上都有良好的展示效果。這使得用戶可以在各種設備上查看和分析數據,提高數據的可訪問性和便利性。
2.3.4 ?MySQL
MySQL是當下最受歡迎的持久化解決方案。其具有高性能:它的性能非常出色,可以支持高并發的訪問請求。可擴展性:它可以通過多種方式進行擴展,包括分庫分表、主從復制等方式。安全性:它提供了多種安全性措施,可以保護用戶的數據安全。簡單易用:經過一到兩天的學習基本就能掌握其語法。
第3章 ?需求建模
3.1??系統可行性分析
3.1.1?技術可行性
技術可行性主要關注項目所需的技術和資源是否具備。對于股票分析和推薦大數據系統,技術可行性包括數據采集、存儲、處理和分析的能力,以及系統架構的穩定性和可擴展性。目前,大數據技術和機器學習算法已經相對成熟,為項目的實施提供了堅實的技術基礎。同時,云計算和分布式存儲技術的發展也為系統提供了強大的計算和存儲能力。
3.1.2?經濟可行性
經濟可行性主要關注項目的投資回報和經濟效益。對于股票分析和推薦大數據系統,經濟可行性需要考慮項目的開發成本、運營成本以及潛在的市場收益。雖然系統的開發和運營需要一定的投入,但考慮到其能夠為投資者提供有價值的投資建議,從而增加其投資收益,因此項目具有良好的經濟效益和市場前景。
3.1.3?社會可行性
社會可行性主要關注項目對社會的影響和接受程度。股票分析和推薦大數據系統旨在提高投資者的投資效率和收益,對于推動金融市場的發展和穩定具有積極意義。同時,該系統也有助于提升大數據技術在金融領域的應用水平和普及程度,促進相關產業的發展。因此,項目在社會層面上是可行的。
3.1.4?操作可行性
操作可行性主要關注系統的易用性和可維護性。股票分析和推薦大數據系統需要面向廣大投資者,因此系統需要具備良好的用戶界面和交互體驗,以便用戶能夠輕松地使用系統并獲取所需的投資建議。同時,系統還需要具備可維護性,以便在出現問題時能夠迅速修復和升級。
3.2??功能需求分析
3.2.1 ?功能概述
1、數據采集與整合:系統能夠實時從多個數據源(如證券交易所、財經新聞網站、社交媒體等)采集股票相關的數據,包括股票價格、交易量、基本面數據、新聞事件等。能夠對采集到的數據進行清洗、去重、標準化等預處理操作,確保數據的質量和準確性。能夠將處理后的數據整合到統一的數據庫中,方便后續的分析和挖掘。
2、數據分析與挖掘:系統利用先進的數據分析技術和機器學習算法,對股票數據進行深入的分析和挖掘,識別出市場的趨勢、規律和異常現象。可以構建各種預測模型,如股票價格預測模型、市場走勢預測模型等,為投資者提供科學的投資建議。系統還能夠對投資者的投資組合進行風險評估和優化,幫助投資者實現資產的合理配置。
3、用戶登錄模塊:用戶身份驗證:用戶登錄模塊通過驗證用戶輸入的用戶名和密碼(或其他身份驗證方式,如指紋識別、面部識別等)來確認用戶的身份。只有經過驗證的用戶才能訪問系統。權限控制:用戶登錄模塊還可以與系統的權限管理系統集成,以根據用戶的角色和權限控制他們對系統功能和數據的訪問。這可以確保敏感數據和功能只能被授權用戶訪問。
4、個性化推薦:系統能夠根據投資者的投資偏好、風險承受能力等個性化因素,為投資者提供定制化的投資建議和推薦股票。投資者可以通過系統設定自己的投資目標和約束條件,系統會根據這些條件為投資者生成相應的投資策略和推薦股票列表。
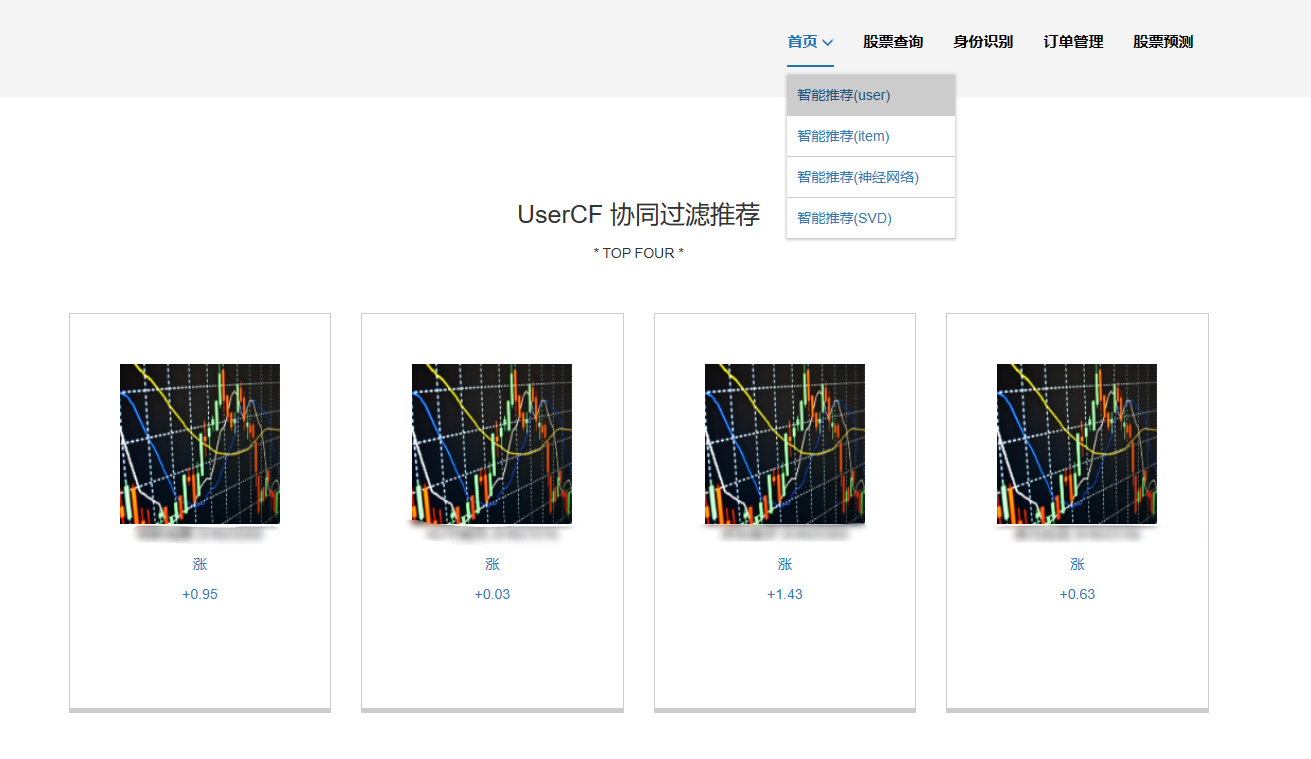
5、基于用戶的協同過濾推薦:使用了基于用戶的協同過濾算法(User-based Collaborative Filtering,簡稱UserCF):這種算法的核心思想是給用戶推薦和他興趣相似的其他用戶喜歡的產品。它首先找出與目標用戶興趣相似的其他用戶,然后根據這些相似用戶的喜好來為目標用戶推薦產品。
6、基于物品的協同過濾推薦:使用了基于物品的協同過濾算法(Item-based Collaborative Filtering,簡稱ItemCF):這種算法則是通過分析物品之間的相似性,來預測用戶評分行為并進行推薦。它首先找出與目標用戶之前喜歡的物品相似的其他物品,然后將這些相似物品推薦給目標用戶。
7、SVD混合神經網絡推薦模塊:SVD混合神經網絡推薦是一種結合了奇異值分解(SVD)和神經網絡技術的推薦系統方法。這種方法旨在通過SVD來降低數據的維度和復雜度,同時利用神經網絡的非線性處理能力來捕捉用戶與物品之間的復雜關系,從而提供更準確和個性化的推薦。
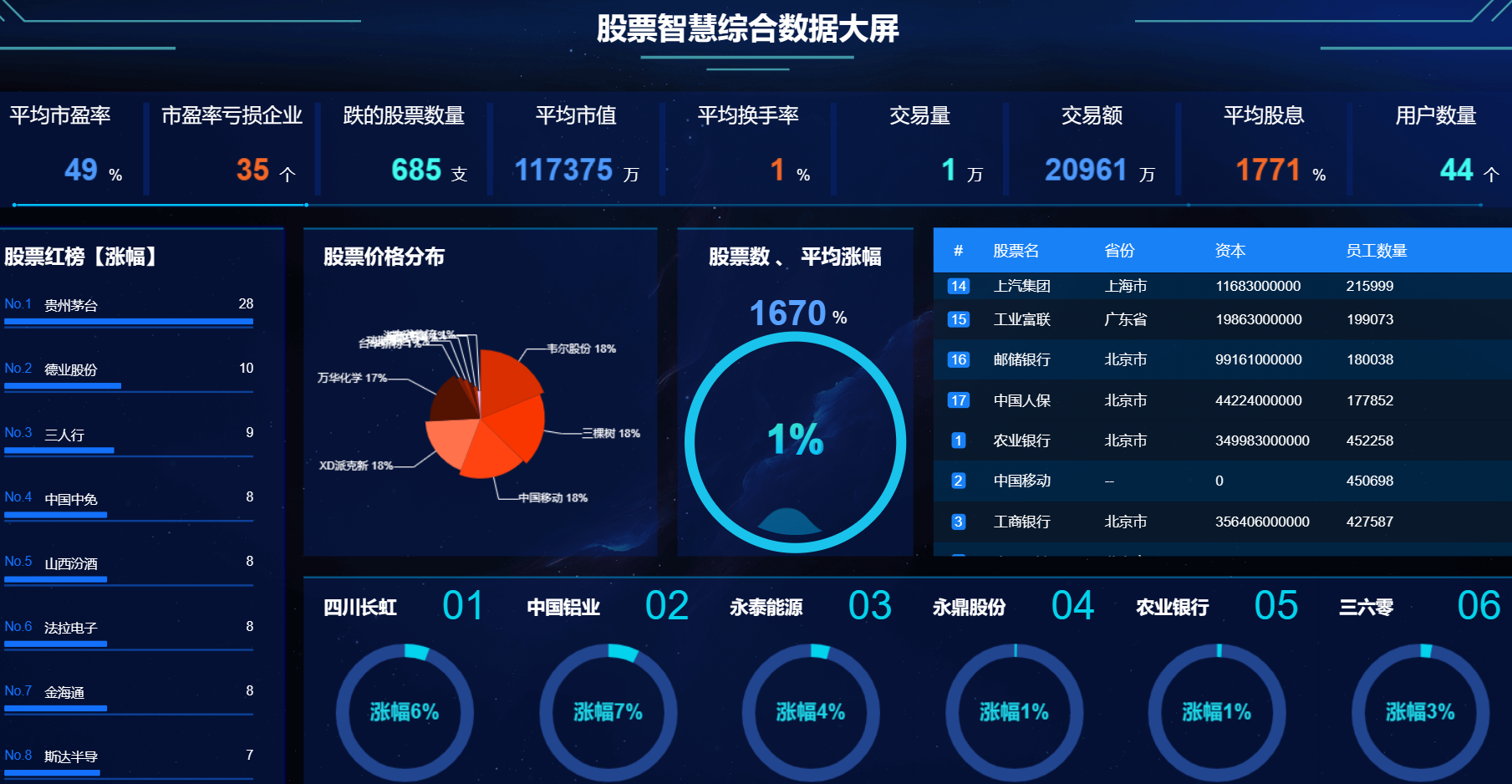
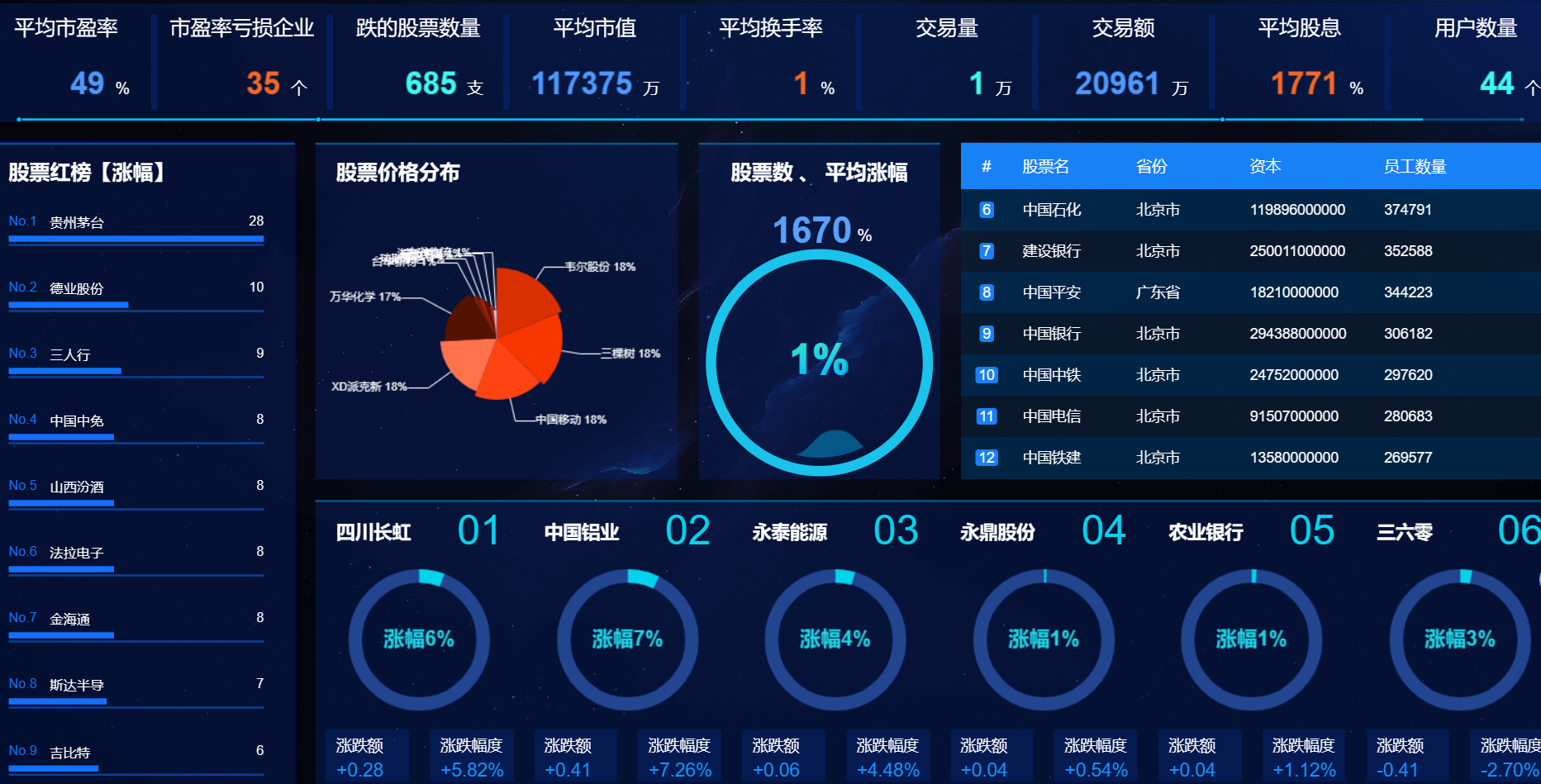
8、大屏數據實時可視化展示模塊:系統提供直觀、易懂的圖表和界面,將分析結果以可視化的形式展示給投資者,方便他們快速理解市場情況和投資建議。投資者可以通過系統查看股票的實時行情、歷史走勢、基本面數據等詳細信息,以便做出更明智的投資決策。
9.虛擬機模塊:虛擬機能夠在同一物理硬件上運行多個操作系統,實現了硬件資源的復用。每個虛擬機都是獨立的,相互之間完全隔離,這使得一個虛擬機的崩潰不會影響其他虛擬機或物理機。虛擬機提供硬件隔離、資源復用、節省成本、簡化管理、提高靈活性、增強安全性、支持多種操作系統和應用以及快速恢復和災難恢復


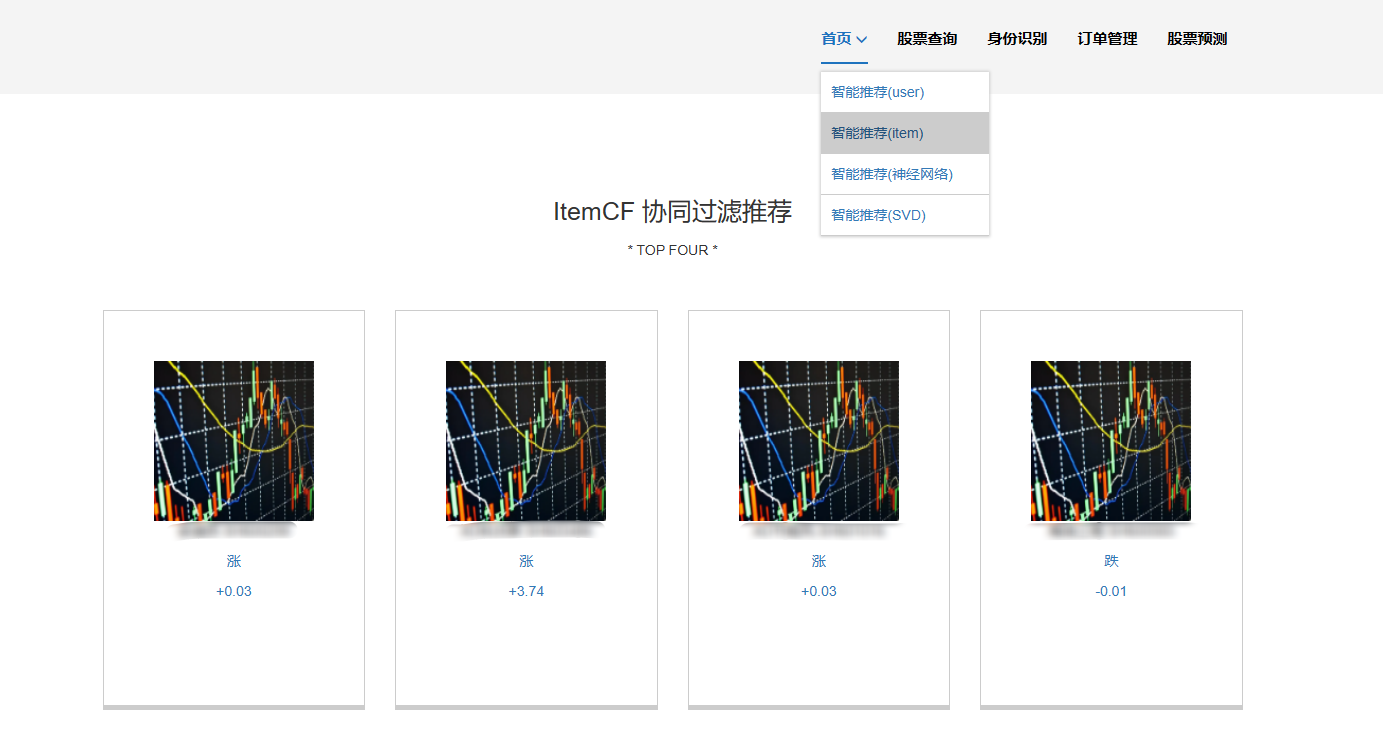
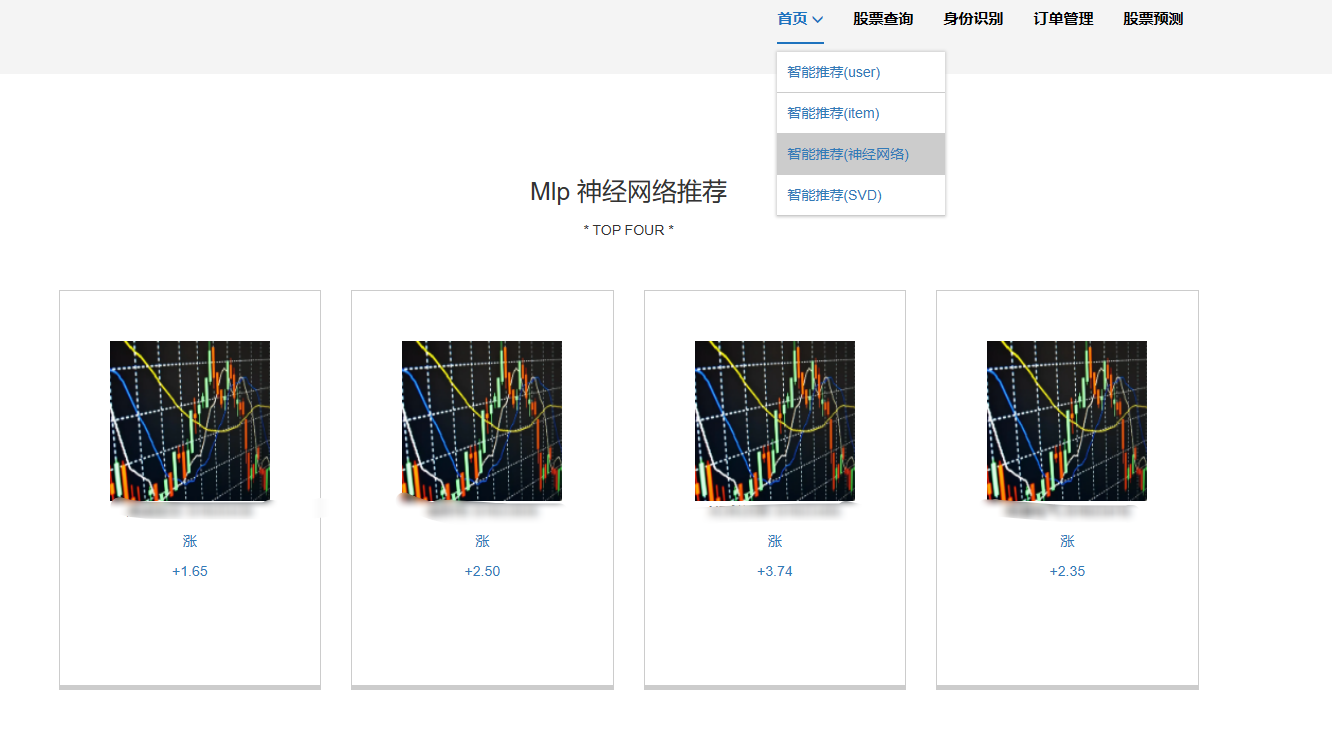
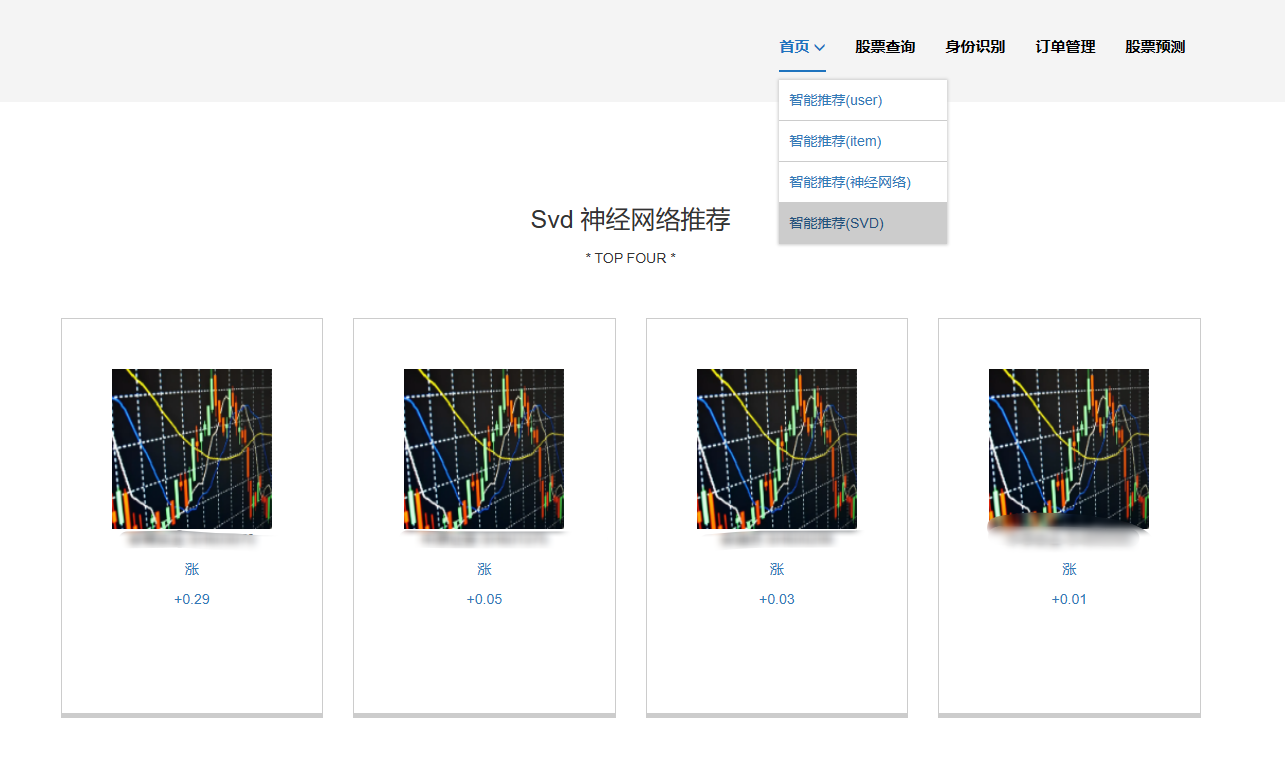




核心算法代碼分享如下:
# coding=utf-8
# BILSTM 情感分析接口import sys
import paddlehub as hub# BiLstm 情感分析接口
if __name__ == '__main__':param1 = sys.argv[1]# param1 = '這個電影不錯的喲'# param1 = "1"senta = hub.Module(name="senta_bilstm")test_text= [param1]input_dict = {"text": test_text}results = senta.sentiment_classify(data=input_dict)print(results)
”)
![mst[講課留檔]](http://pic.xiahunao.cn/mst[講課留檔])







)








)