? ? ? 多模態大型語言模型(MLLMs)在過去幾年中取得了爆炸性的增長。利用大型語言模型(LLMs)中豐富的常識知識,MLLMs在處理和推理各種模態(如圖像、視頻和音頻)方面表現出色,涵蓋了識別、推理和問答等一系列任務,所有這些任務都使用語言作為中間表示。然而,現有的MLLMs在理解網頁截圖和生成表達其潛在狀態的HTML代碼方面出奇地差。
? ? ? 為了解決現有 MLLM 在網頁理解和代碼生成方面的局限性,本文提出了 Web2Code 基準。Web2Code 包含一個大規模的網頁到代碼數據集,用于指令微調和一個評估框架,用于測試 MLLM 的網頁理解和 HTML 代碼翻譯能力。
源代碼下載:https://github.com/MBZUAI-LLM/web2code
1 數據集的構建
數據集構建是Web2Code項目的核心部分,它涉及創建和優化網頁圖像與HTML代碼配對的數據,以及生成與網頁理解相關的問答對。
1.1 創建新的網頁圖像-代碼對數據 (DWCG)
- 使用 GPT-3.5 生成 60K 個 HTML 頁面,遵循 CodeAlpaca 提示。
- 使用 Selenium WebDriver 從生成的 HTML 代碼中創建網頁圖像截圖。
- 將網頁圖像-代碼對轉換為指令跟隨數據格式,類似于 LLaVA 數據格式,以便用于訓練 MLLM。
1.2 精煉現有的網頁代碼生成數據 (DWCGR)
- 利用 Pix2code 和 WebSight 數據集來增強模型在 HTML 代碼生成任務上的能力。
- 使用 GPT-4 將 Pix2code 數據集中的隨機字母替換為有意義文本,并將網頁精煉為包含產品著陸頁、個人作品集、博客等類別的多樣化網頁。
- 將所有數據轉換為 LLaVA 指令跟隨數據格式。
1.3 創建新的文本問答對數據 (DWU)
- 使用 GPT-4 生成基于網頁代碼的問答對數據,用于網頁理解任務。
- 為 24.35K 個網頁數據生成 10 個問答對,共計 243.5K 個數據點。
- 問答對涵蓋了網頁的結構、設計、內容等方面,以確保模型能夠全面理解網頁信息。
1.4 精煉現有的網頁理解數據 (DWUR)
- 將 WebSRC 數據集集成到訓練中,以提高模型在網頁理解任務上的能力。
- 對 WebSRC 數據集中的問答對進行篩選,確保其相關性和質量。
- 使用 GPT-4 評估和提升答案的質量,將數據集精煉為 51.5K 個高質量的指令數據。
1.5 數據集統計和分析
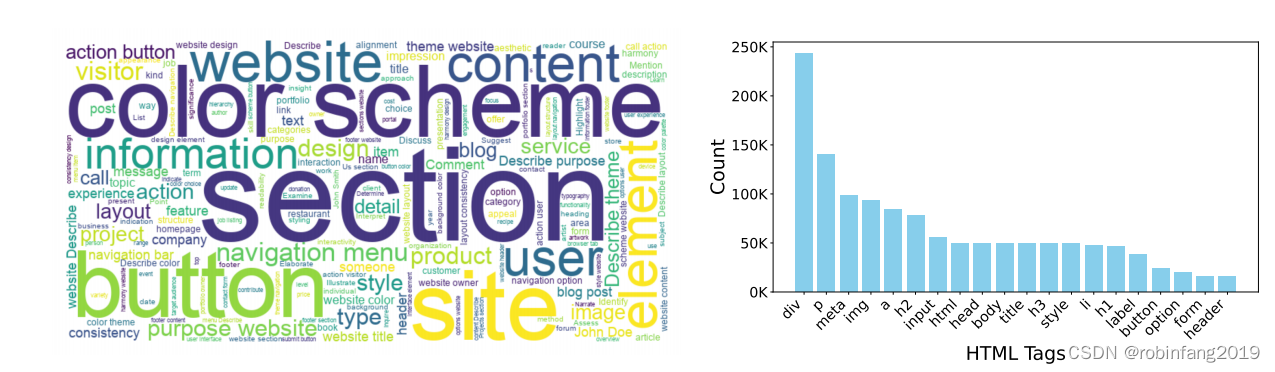
- 圖表展示了問答數據集中答案集的詞云,突出了數據中結構性和設計元素的重要性。
- 圖表展示了 GPT-3.5 生成 HTML 數據中最常見的 HTML 標簽分布,表明生成的頁面包含豐富的元素,結構完整。
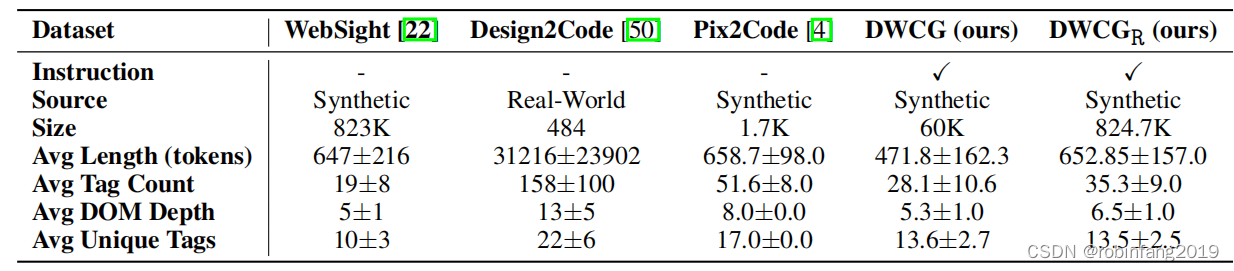
- 表格將 Web2Code 數據集與其他現有數據集進行了比較,例如 WebSight、Design2Code 和 Pix2Code,結果表明 Web2Code 數據集更大、更復雜、更具挑戰性。
1.6 數據集分布
- Web2Code 數據集包含 1179.7K 個指令數據點,包括 884.7K 個網站圖像-代碼對和 295K 個問答對。
- 問答對由 243.5K 個 GPT-4 基于問答對和 51.5K 個 WebSRC 圖像基于問答對組成。
- 評估數據集包含 1198 個網頁截圖圖像,來自 WebSight、Pix2Code、GPT-3.5 基于數據和人工作業。
- 此外,還使用了 5,990 個“是/否”問答對,使用 GPT-4 Vision API 生成,用于 WUB 基準測試。
2 評估框架
Web2Code 提出了一個包含兩個方案的評估框架,用于評估 MLLM 的網頁理解和代碼生成能力。

2.1 網頁理解基準 (WUB)
這是一個離線評估,使用“是/否”問題進行評估。
- 該基準包含 5,990 個高質量問答對,由 GPT-4 Vision API 生成,基于 1,198 個網頁截圖圖像。
- 每個問題的答案都是“是”或“否”。
- 將模型對問題的預測答案與真實答案進行比較,最終準確率作為評估指標。
2.2 網頁代碼生成基準 (WCGB)
這是一個在線評估,基于圖像相似度進行評估。
- 該基準評估 MLLM 從網頁圖像生成 HTML 代碼的能力。
- 將預測的 HTML 代碼轉換為圖像,并與真實圖像進行比較。
- 評估考慮了 10 個不同的方面,進一步分為四個評估矩陣,使用 GPT-4 Vision API 進行評分。
2.2.1 WCGB 評估的四個方面
- 視覺結構和對齊: 評估網頁元素的結構和布局、元素對齊、比例精度和視覺和諧。
- 顏色和美學設計: 評估顏色方案、美學相似性、整體美學吸引力。
- 文本和內容一致性: 評估字體特征、文本內容匹配、數字和特殊字符精度。
- 用戶界面和交互性: 評估用戶界面一致性、設計語言和 UI 元素的外觀。
2.3 評估指標
- WUB:準確率 (%)
- WCGB:視覺結構和對齊、顏色和美學設計、文本和內容一致性、用戶界面和交互性的分數 (0-10)
2.4 定量評估
表格展示了不同 LLM 核心和不同數據配置在 WCGB 和 WUB 基準測試上的性能。
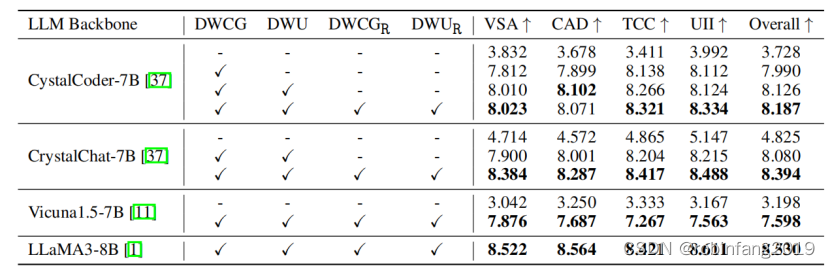
結果表明,Web2Code 數據集可以顯著提高 MLLM 的網頁理解和代碼生成能力,而現有數據集則導致性能下降。
2.5 定性評估
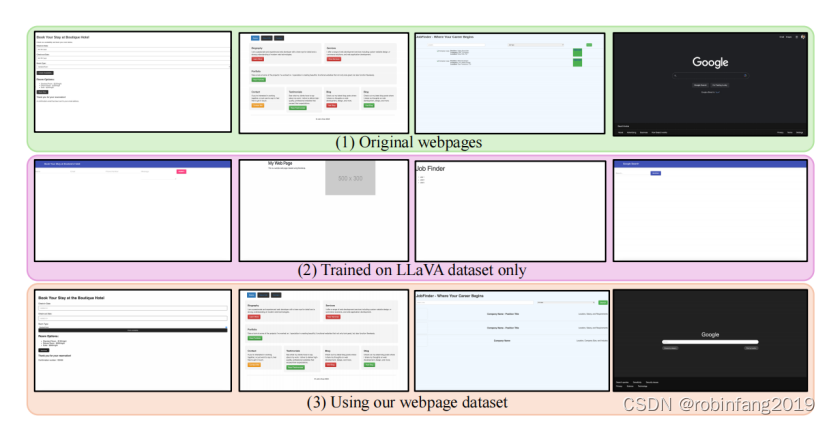
圖表展示了使用不同 LLM 核心生成的網頁圖像與真實圖像之間的比較。
結果表明,Web2Code 數據集可以提高模型生成網頁圖像的質量。
通過提出的評估框架,我們證明了Web2Code數據集在增強MLLMs的網頁理解和網頁到HTML翻譯能力方面是有效的,同時現有的數據集可能導致性能下降。















)



原則)