4-數據提取方法2(xpath和lxml)(6節課學會爬蟲)
- 1,Xpath語法:
- (1)選擇節點(標簽)
- (2)“//”:能從任意節點開始選擇
- (3)“@”符號的用途
- (4)獲取文本
- (5)點前
- 2,簡單使用
- (1)判斷某個標簽是否被選中
- (2)選擇當前頁面的任何一個節點(雙斜杠//)
- (3)選擇指定的標簽
- 3,Lxml(在代碼中使用xpath語法)
- (1)安裝
- (2)使用
- (3)爬取豆瓣電影
1,Xpath語法:
Xpath是一門從HTML中提取數據的一門語言
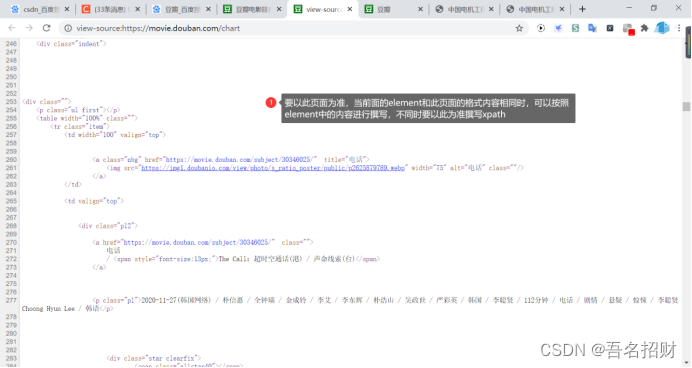
Xpath helper插件:幫助我們從element中定位數據
??爬蟲是爬不到element的內容的,這里使用插件只是讓其幫助我們學習xpath中的語法,從url地址中的響應中提取數據,只有response內容和element中內容相同時,才可以使用此工具提取數據,否則只能看response內容才能去提取,當然xpath語法簡單,看就能看到。
(1)選擇節點(標簽)
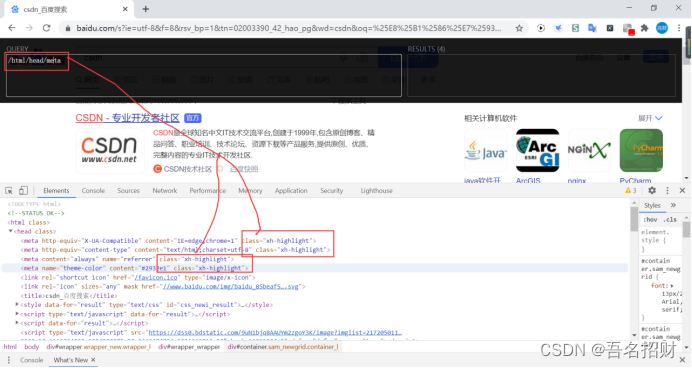
-- /html/head/meta:能夠選中html下的head下的所有的meta標簽
(2)“//”:能從任意節點開始選擇
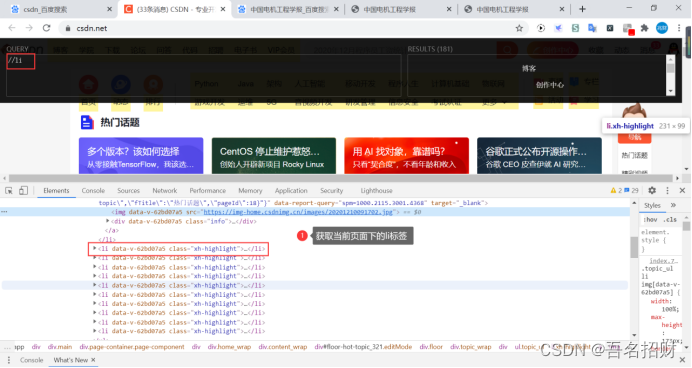
“//li”:當前頁面下的所有li標簽
“/html/head//link”:選擇head下的所有link標簽(head下的任意一級都會被選中)
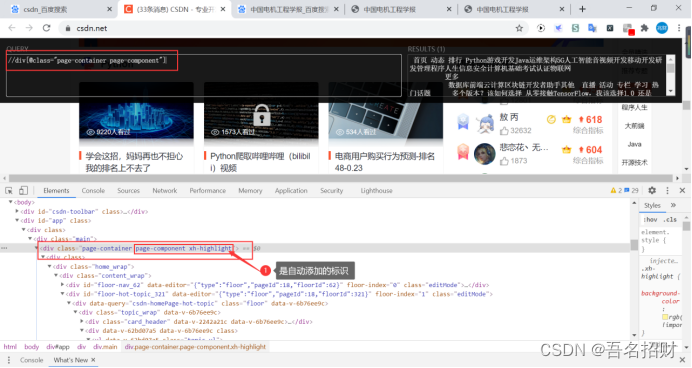
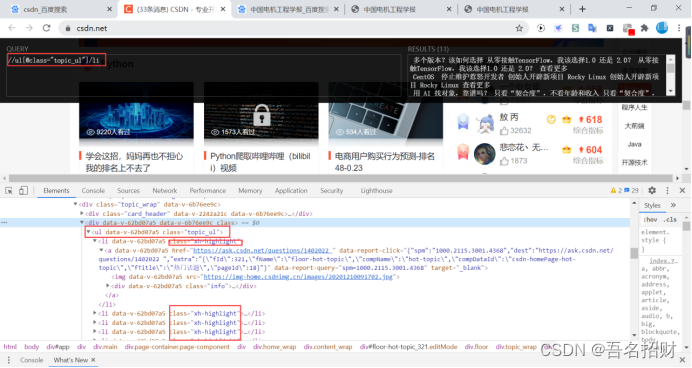
(3)“@”符號的用途
定位元素:“//ul[@class="topic_ul"]/li”
選擇class="topic_ul"的ul標簽下的li標簽
“/a/@href”: 選擇a標簽的href屬性值
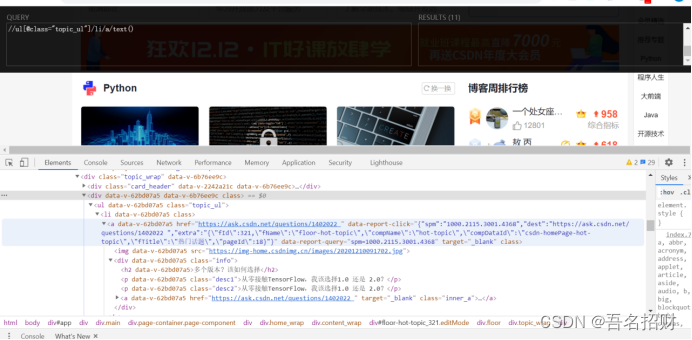
(4)獲取文本
“/a/text()”: 獲取文本(標簽a中包含的文本)
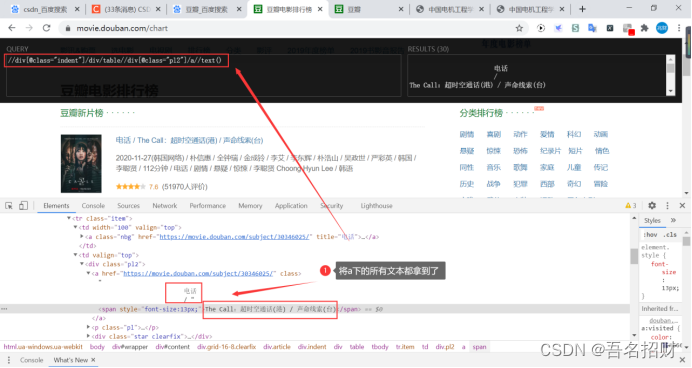
“/a//text()”: 獲取a標簽下的所有文本,即便a標簽下有其他標簽,所有的文本都會得到
(5)點前
“./a”:當前節點下的a標簽
相應方法可到w3cschool中查找,上面學到的已經能解決80%的問題了
@可以定位一個屬性,一個節點
選擇節點(標簽)
2,簡單使用
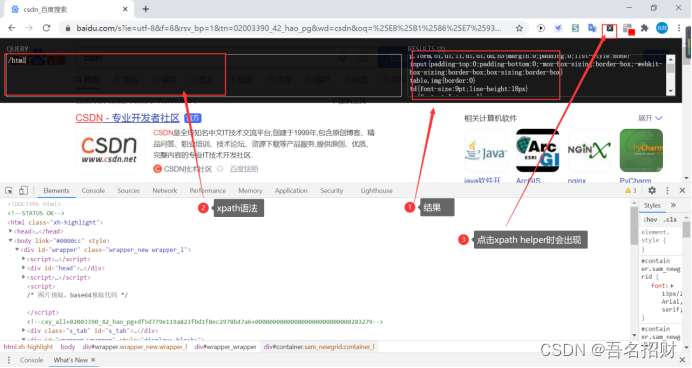
(1)判斷某個標簽是否被選中
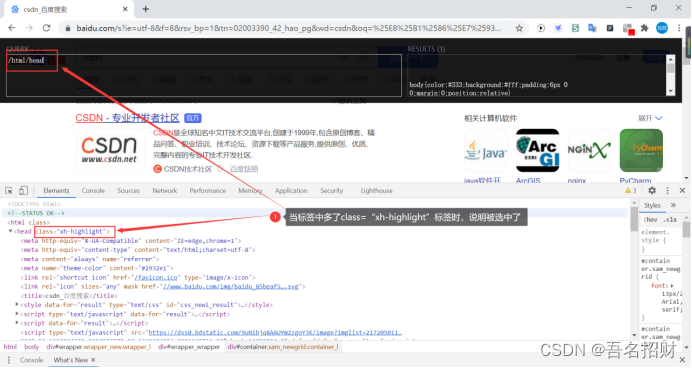
如下,選擇全部的meta都選擇上了
(2)選擇當前頁面的任何一個節點(雙斜杠//)
??我們如果從根路徑,一個一個的去找太麻煩了,而且使用鼠標找到某一標簽后,使用//可以得到當前頁面的任意節點。
??可以選擇整個頁面下的任何一個li標簽
(3)選擇指定的標簽
@符號能選擇指定屬性的值
[]能對選擇的標簽進行限定

3,Lxml(在代碼中使用xpath語法)
(1)安裝
pip install lxml
(2)使用
from lxml import etreeelement = etree.HTML("html字符串") #etree可以將HTML的字符串轉換成一個對象
element.xpath("/html/head/meta") #此時可以對此對象使用xpath語法了
(3)爬取豆瓣電影
下方式爬取豆瓣電影排行榜的某一頁的電影信息的爬蟲程序
#-*- codeing = utf-8 -*-
#@Time : 2020/12/10 14:50
#@Author : 招財進寶
#@File : 09_try_lxml.py
#@Software: PyCharmimport requests
from lxml import etreeurl="https://movie.douban.com/chart"headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}response = requests.get(url,headers=headers)
html_str = response.content.decode()
#print(html_str)#使用etree處理數據html = etree.HTML(html_str) #etree可以將HTML的字符串轉換成一個對象
print(html) #一個element對象,可以進行xpath撰寫#此時可以對此對象使用xpath語法了# #1.獲取所有的電影的url地址
# url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")
# print(url_list)
#
# #2.獲取所有的圖片的url地址
# img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")
# print(img_list)#3.需要把每部電影組成一個字典,字典中是電影的多重數據,如標題,url,圖片地址,評論數,評分
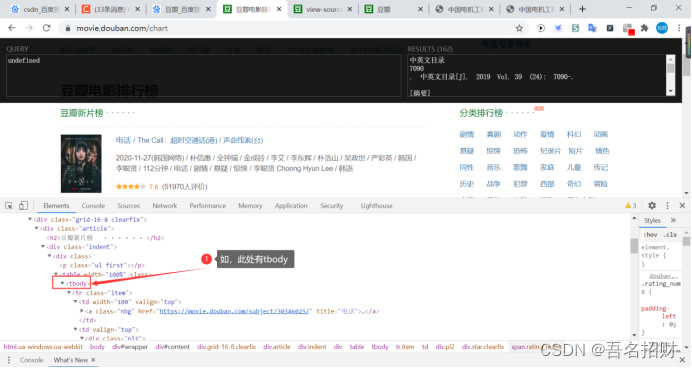
# 思路:#1.分組#2.每一組提取數據ret1 = html.xpath("//div[@class='indent']/div/table") #通過此中方式先對每個模塊進行分組
print(ret1) #[<Element table at 0x278cea01708>, <Element table at 0x278bed91708>,共10個table的對象for table in ret1:item = {}item["title"]=table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip() #此處只有中文的電影名#print(item["title"])item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0]item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0]item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0]item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0]print(item)
編輯 7 操作Blob字段)


















