TCP 三次握手與四次揮手面試題
任 TCP 虐我千百遍,我仍待 TCP 如初戀。
巨巨巨巨長的提綱,發車!發車!
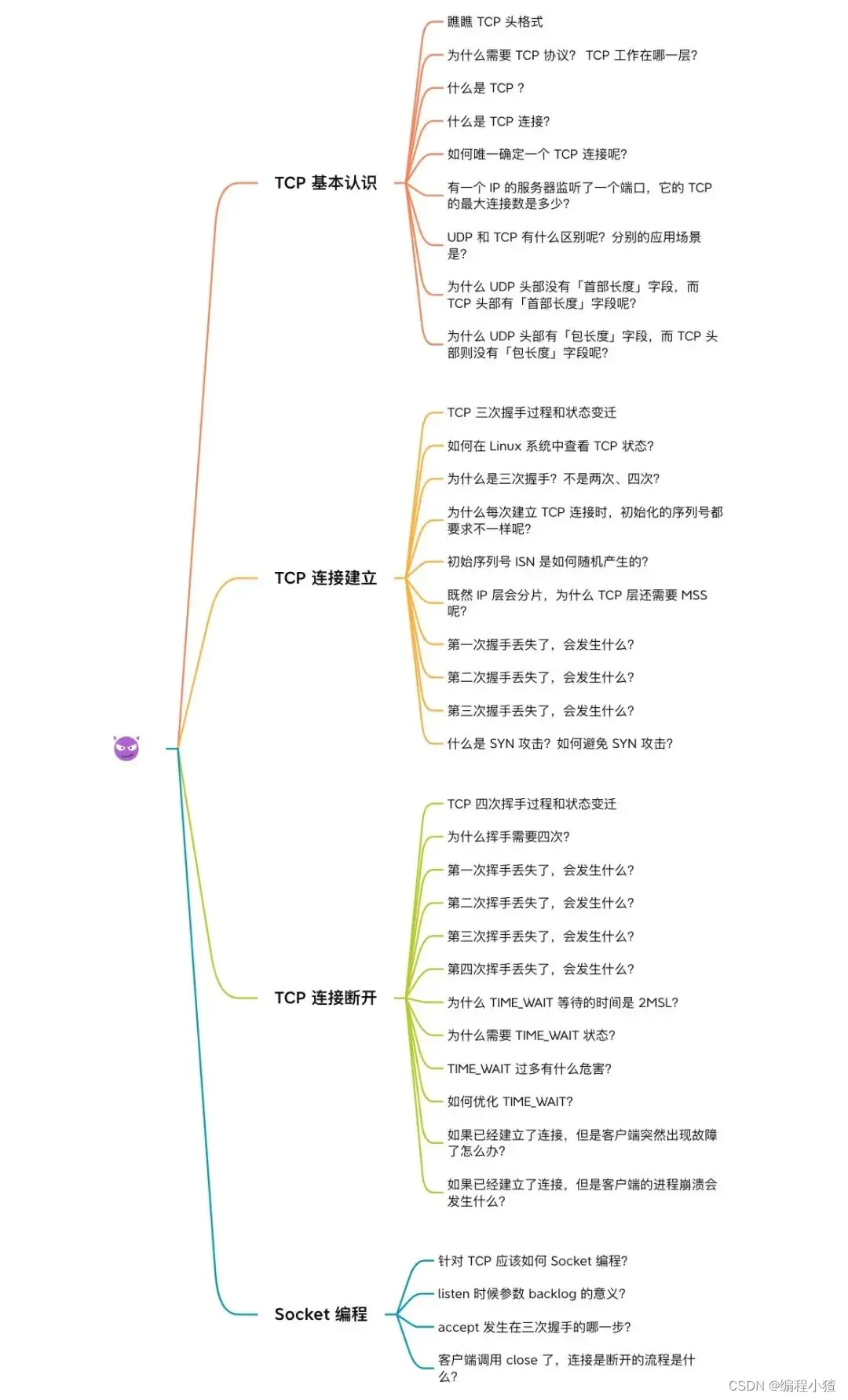
PS:本次文章不涉及 TCP 流量控制、擁塞控制、可靠性傳輸等方面知識,這些知識在這篇:
TCP 基本認識
TCP 頭格式有哪些?
我們先來看看 TCP 頭的格式,標注顏色的表示與本文關聯比較大的字段,其他字段不做詳細闡述。
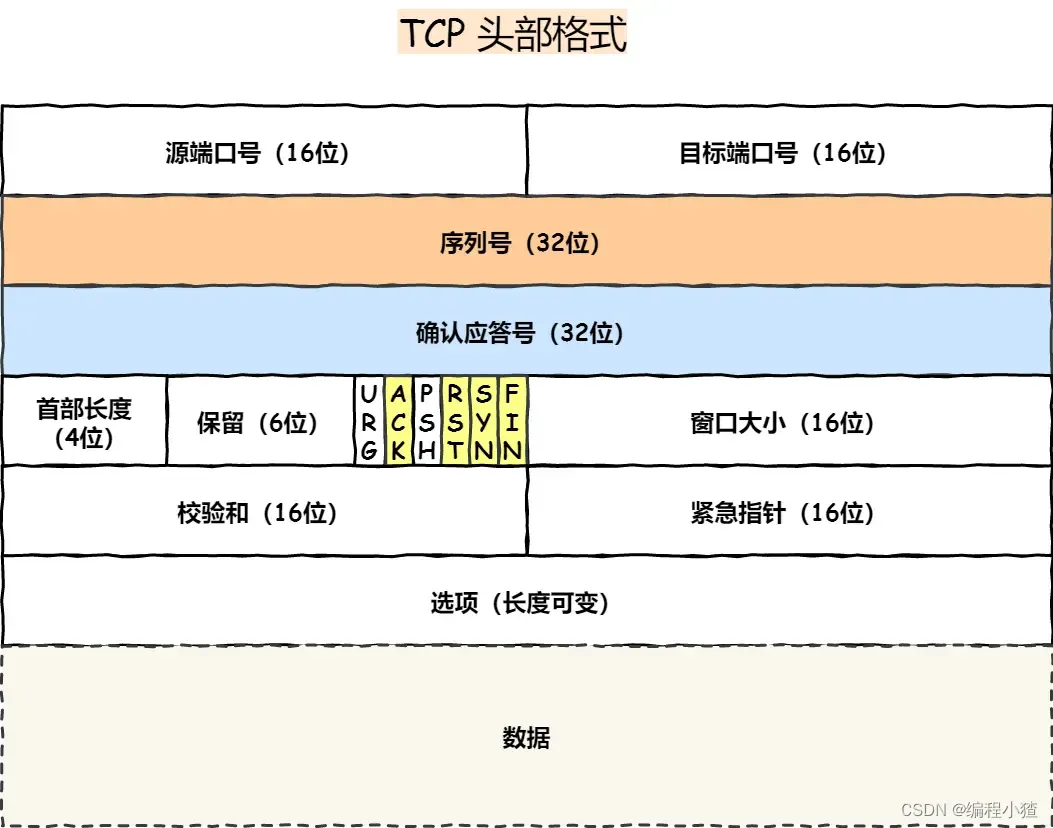
序列號:在建立連接時由計算機生成的隨機數作為其初始值,通過 SYN 包傳給接收端主機,每發送一次數據,就「累加」一次該「數據字節數」的大小。用來解決網絡包亂序問題。
確認應答號:指下一次「期望」收到的數據的序列號,發送端收到這個確認應答以后可以認為在這個序號以前的數據都已經被正常接收。用來解決丟包的問題。
控制位:
- ACK:該位為?
1?時,「確認應答」的字段變為有效,TCP 規定除了最初建立連接時的?SYN?包之外該位必須設置為?1?。 - RST:該位為?
1?時,表示 TCP 連接中出現異常必須強制斷開連接。 - SYN:該位為?
1?時,表示希望建立連接,并在其「序列號」的字段進行序列號初始值的設定。 - FIN:該位為?
1?時,表示今后不會再有數據發送,希望斷開連接。當通信結束希望斷開連接時,通信雙方的主機之間就可以相互交換?FIN?位為 1 的 TCP 段。
為什么需要 TCP 協議? TCP 工作在哪一層?
IP?層是「不可靠」的,它不保證網絡包的交付、不保證網絡包的按序交付、也不保證網絡包中的數據的完整性。
如果需要保障網絡數據包的可靠性,那么就需要由上層(傳輸層)的?TCP?協議來負責。
因為 TCP 是一個工作在傳輸層的可靠數據傳輸的服務,它能確保接收端接收的網絡包是無損壞、無間隔、非冗余和按序的。
什么是 TCP ?
TCP 是面向連接的、可靠的、基于字節流的傳輸層通信協議。

-
面向連接:一定是「一對一」才能連接,不能像 UDP 協議可以一個主機同時向多個主機發送消息,也就是一對多是無法做到的;
-
可靠的:無論的網絡鏈路中出現了怎樣的鏈路變化,TCP 都可以保證一個報文一定能夠到達接收端;
-
字節流:用戶消息通過 TCP 協議傳輸時,消息可能會被操作系統「分組」成多個的 TCP 報文,如果接收方的程序如果不知道「消息的邊界」,是無法讀出一個有效的用戶消息的。并且 TCP 報文是「有序的」,當「前一個」TCP 報文沒有收到的時候,即使它先收到了后面的 TCP 報文,那么也不能扔給應用層去處理,同時對「重復」的 TCP 報文會自動丟棄。
什么是 TCP 連接?
我們來看看 RFC 793 是如何定義「連接」的:
Connections: The reliability and flow control mechanisms described above require that TCPs initialize and maintain certain status information for each data stream. The combination of this information, including sockets, sequence numbers, and window sizes, is called a connection.
簡單來說就是,用于保證可靠性和流量控制維護的某些狀態信息,這些信息的組合,包括 Socket、序列號和窗口大小稱為連接。
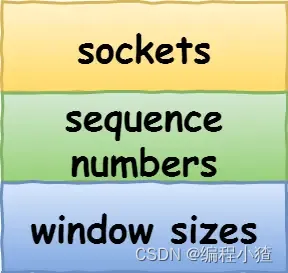
所以我們可以知道,建立一個 TCP 連接是需要客戶端與服務端達成上述三個信息的共識。
- Socket:由 IP 地址和端口號組成
- 序列號:用來解決亂序問題等
- 窗口大小:用來做流量控制
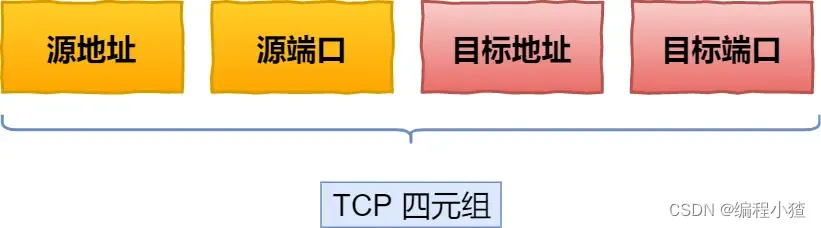
如何唯一確定一個 TCP 連接呢?
TCP 四元組可以唯一的確定一個連接,四元組包括如下:
- 源地址
- 源端口
- 目的地址
- 目的端口
 ?
?
源地址和目的地址的字段(32 位)是在 IP 頭部中,作用是通過 IP 協議發送報文給對方主機。
源端口和目的端口的字段(16 位)是在 TCP 頭部中,作用是告訴 TCP 協議應該把報文發給哪個進程。
有一個 IP 的服務端監聽了一個端口,它的 TCP 的最大連接數是多少?
服務端通常固定在某個本地端口上監聽,等待客戶端的連接請求。
因此,客戶端 IP 和端口是可變的,其理論值計算公式如下:
![]() ?
?
對 IPv4,客戶端的 IP 數最多為?2?的?32?次方,客戶端的端口數最多為?2?的?16?次方,也就是服務端單機最大 TCP 連接數,約為?2?的?48?次方。
當然,服務端最大并發 TCP 連接數遠不能達到理論上限,會受以下因素影響:
- 文件描述符限制,每個 TCP 連接都是一個文件,如果文件描述符被占滿了,會發生 Too many open files。Linux 對可打開的文件描述符的數量分別作了三個方面的限制:
- 系統級:當前系統可打開的最大數量,通過?
cat /proc/sys/fs/file-max?查看; - 用戶級:指定用戶可打開的最大數量,通過?
cat /etc/security/limits.conf?查看; - 進程級:單個進程可打開的最大數量,通過?
cat /proc/sys/fs/nr_open?查看;
- 系統級:當前系統可打開的最大數量,通過?
- 內存限制,每個 TCP 連接都要占用一定內存,操作系統的內存是有限的,如果內存資源被占滿后,會發生 OOM。
UDP 和 TCP 有什么區別呢?分別的應用場景是?
UDP 不提供復雜的控制機制,利用 IP 提供面向「無連接」的通信服務。
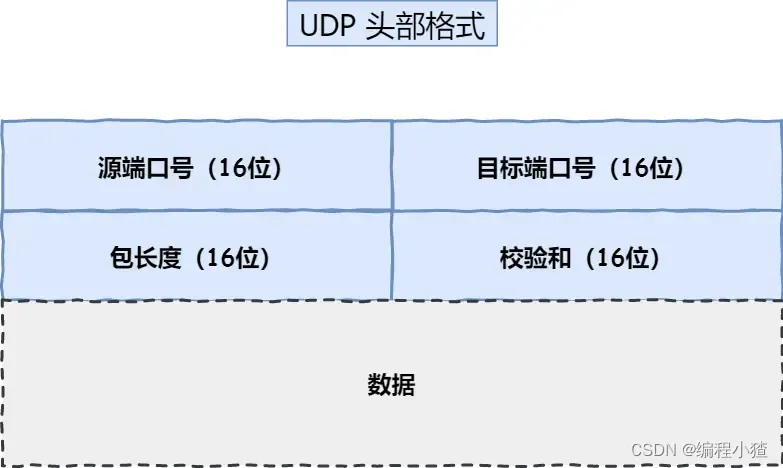
UDP 協議真的非常簡,頭部只有?8?個字節(64 位),UDP 的頭部格式如下:
 ?
?
- 目標和源端口:主要是告訴 UDP 協議應該把報文發給哪個進程。
- 包長度:該字段保存了 UDP 首部的長度跟數據的長度之和。
- 校驗和:校驗和是為了提供可靠的 UDP 首部和數據而設計,防止收到在網絡傳輸中受損的 UDP 包。
TCP 和 UDP 區別:
1. 連接
- TCP 是面向連接的傳輸層協議,傳輸數據前先要建立連接。
- UDP 是不需要連接,即刻傳輸數據。
2. 服務對象
- TCP 是一對一的兩點服務,即一條連接只有兩個端點。
- UDP 支持一對一、一對多、多對多的交互通信
3. 可靠性
- TCP 是可靠交付數據的,數據可以無差錯、不丟失、不重復、按序到達。
- UDP 是盡最大努力交付,不保證可靠交付數據。但是我們可以基于 UDP 傳輸協議實現一個可靠的傳輸協議,比如 QUIC 協議,具體可以參見這篇文章:如何基于 UDP 協議實現可靠傳輸?(opens new window)
4. 擁塞控制、流量控制
- TCP 有擁塞控制和流量控制機制,保證數據傳輸的安全性。
- UDP 則沒有,即使網絡非常擁堵了,也不會影響 UDP 的發送速率。
5. 首部開銷
- TCP 首部長度較長,會有一定的開銷,首部在沒有使用「選項」字段時是?
20?個字節,如果使用了「選項」字段則會變長的。 - UDP 首部只有 8 個字節,并且是固定不變的,開銷較小。
6. 傳輸方式
- TCP 是流式傳輸,沒有邊界,但保證順序和可靠。
- UDP 是一個包一個包的發送,是有邊界的,但可能會丟包和亂序。
7. 分片不同
- TCP 的數據大小如果大于 MSS 大小,則會在傳輸層進行分片,目標主機收到后,也同樣在傳輸層組裝 TCP 數據包,如果中途丟失了一個分片,只需要傳輸丟失的這個分片。
- UDP 的數據大小如果大于 MTU 大小,則會在 IP 層進行分片,目標主機收到后,在 IP 層組裝完數據,接著再傳給傳輸層。
TCP 和 UDP 應用場景:
由于 TCP 是面向連接,能保證數據的可靠性交付,因此經常用于:
FTP?文件傳輸;- HTTP / HTTPS;
由于 UDP 面向無連接,它可以隨時發送數據,再加上 UDP 本身的處理既簡單又高效,因此經常用于:
- 包總量較少的通信,如?
DNS?、SNMP?等; - 視頻、音頻等多媒體通信;
- 廣播通信;
為什么 UDP 頭部沒有「首部長度」字段,而 TCP 頭部有「首部長度」字段呢?
原因是 TCP 有可變長的「選項」字段,而 UDP 頭部長度則是不會變化的,無需多一個字段去記錄 UDP 的首部長度。
為什么 UDP 頭部有「包長度」字段,而 TCP 頭部則沒有「包長度」字段呢?
先說說 TCP 是如何計算負載數據長度:
 ?
?
其中 IP 總長度 和 IP 首部長度,在 IP 首部格式是已知的。TCP 首部長度,則是在 TCP 首部格式已知的,所以就可以求得 TCP 數據的長度。
大家這時就奇怪了問:“UDP 也是基于 IP 層的呀,那 UDP 的數據長度也可以通過這個公式計算呀? 為何還要有「包長度」呢?”
這么一問,確實感覺 UDP 的「包長度」是冗余的。
我查閱了很多資料,我覺得有兩個比較靠譜的說法:
- 第一種說法:因為為了網絡設備硬件設計和處理方便,首部長度需要是?
4?字節的整數倍。如果去掉 UDP 的「包長度」字段,那 UDP 首部長度就不是?4?字節的整數倍了,所以我覺得這可能是為了補全 UDP 首部長度是?4?字節的整數倍,才補充了「包長度」字段。 - 第二種說法:如今的 UDP 協議是基于 IP 協議發展的,而當年可能并非如此,依賴的可能是別的不提供自身報文長度或首部長度的網絡層協議,因此 UDP 報文首部需要有長度字段以供計算。
TCP 和 UDP 可以使用同一個端口嗎?
答案:可以的。
在數據鏈路層中,通過 MAC 地址來尋找局域網中的主機。在網際層中,通過 IP 地址來尋找網絡中互連的主機或路由器。在傳輸層中,需要通過端口進行尋址,來識別同一計算機中同時通信的不同應用程序。
所以,傳輸層的「端口號」的作用,是為了區分同一個主機上不同應用程序的數據包。
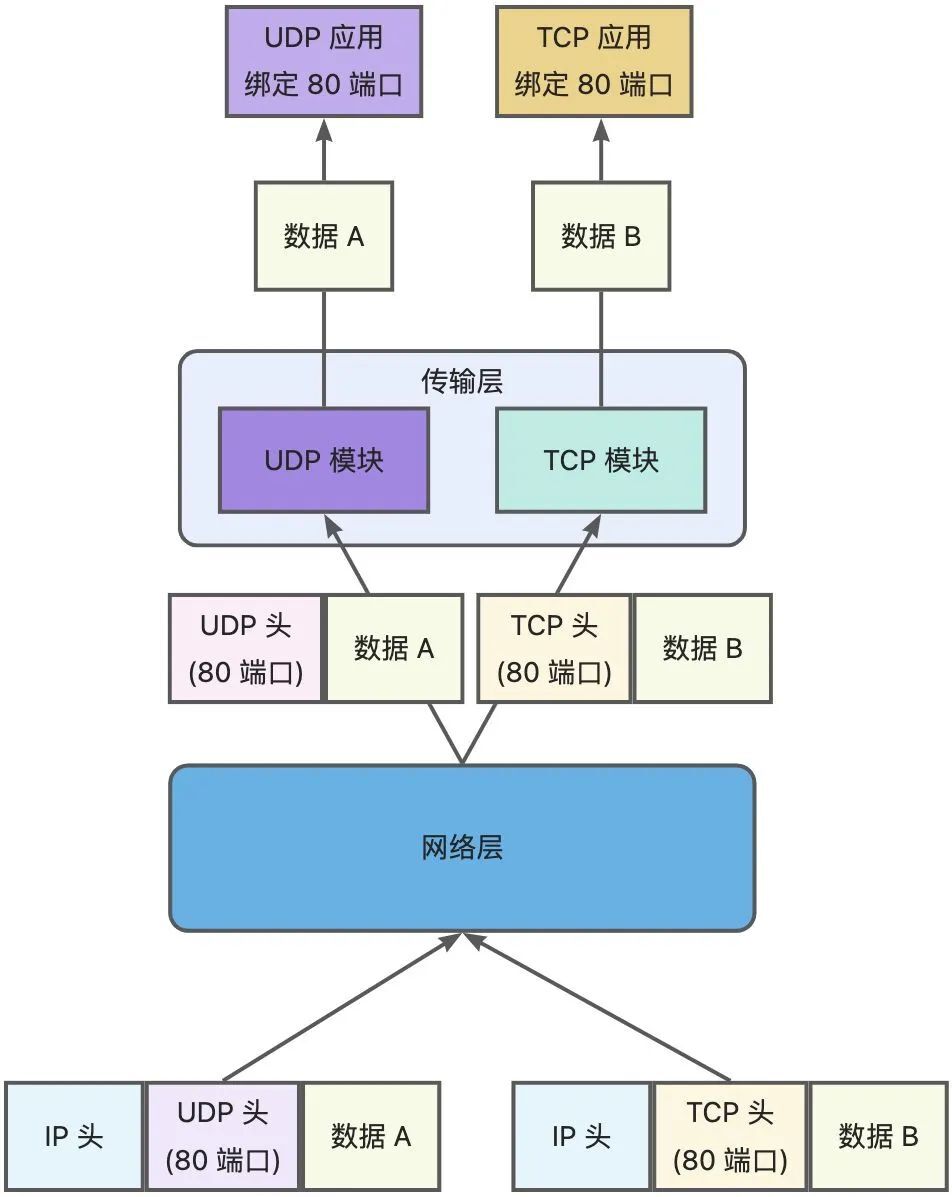
傳輸層有兩個傳輸協議分別是 TCP 和 UDP,在內核中是兩個完全獨立的軟件模塊。
當主機收到數據包后,可以在 IP 包頭的「協議號」字段知道該數據包是 TCP/UDP,所以可以根據這個信息確定送給哪個模塊(TCP/UDP)處理,送給 TCP/UDP 模塊的報文根據「端口號」確定送給哪個應用程序處理。
 ?
?
因此,TCP/UDP 各自的端口號也相互獨立,如 TCP 有一個 80 號端口,UDP 也可以有一個 80 號端口,二者并不沖突。
關于端口的知識點,還是挺多可以講的,比如還可以牽扯到這幾個問題:
- 多個 TCP 服務進程可以同時綁定同一個端口嗎?
- 重啟 TCP 服務進程時,為什么會出現“Address in use”的報錯信息?又該怎么避免?
- 客戶端的端口可以重復使用嗎?
- 客戶端 TCP 連接 TIME_WAIT 狀態過多,會導致端口資源耗盡而無法建立新的連接嗎?
上面這些問題,可以看這篇文章:TCP 和 UDP 可以使用同一個端口嗎?(opens new window)
TCP 連接建立
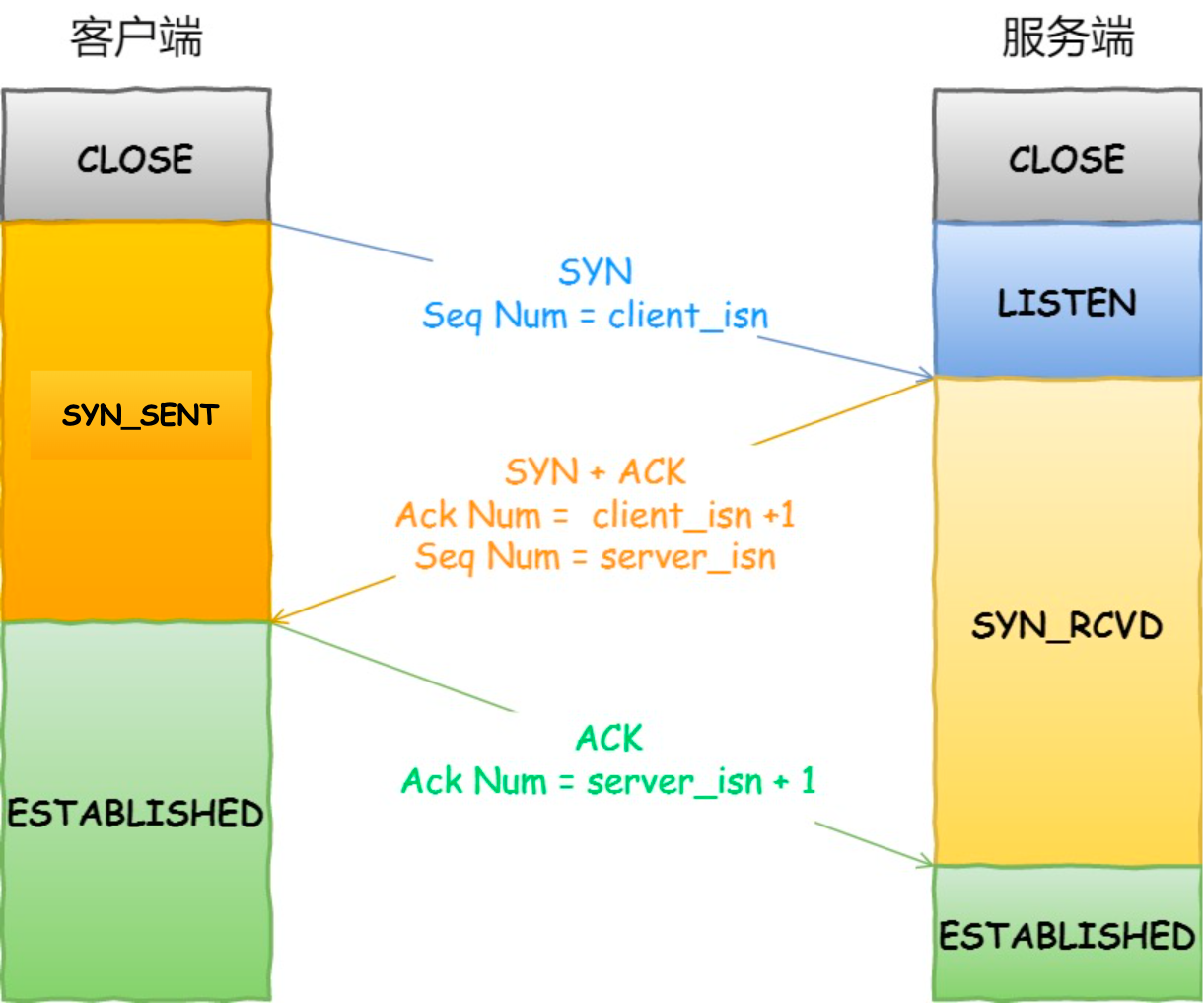
TCP 三次握手過程是怎樣的?
TCP 是面向連接的協議,所以使用 TCP 前必須先建立連接,而建立連接是通過三次握手來進行的。三次握手的過程如下圖:
 ?
?
- 一開始,客戶端和服務端都處于?
CLOSE?狀態。先是服務端主動監聽某個端口,處于?LISTEN?狀態
?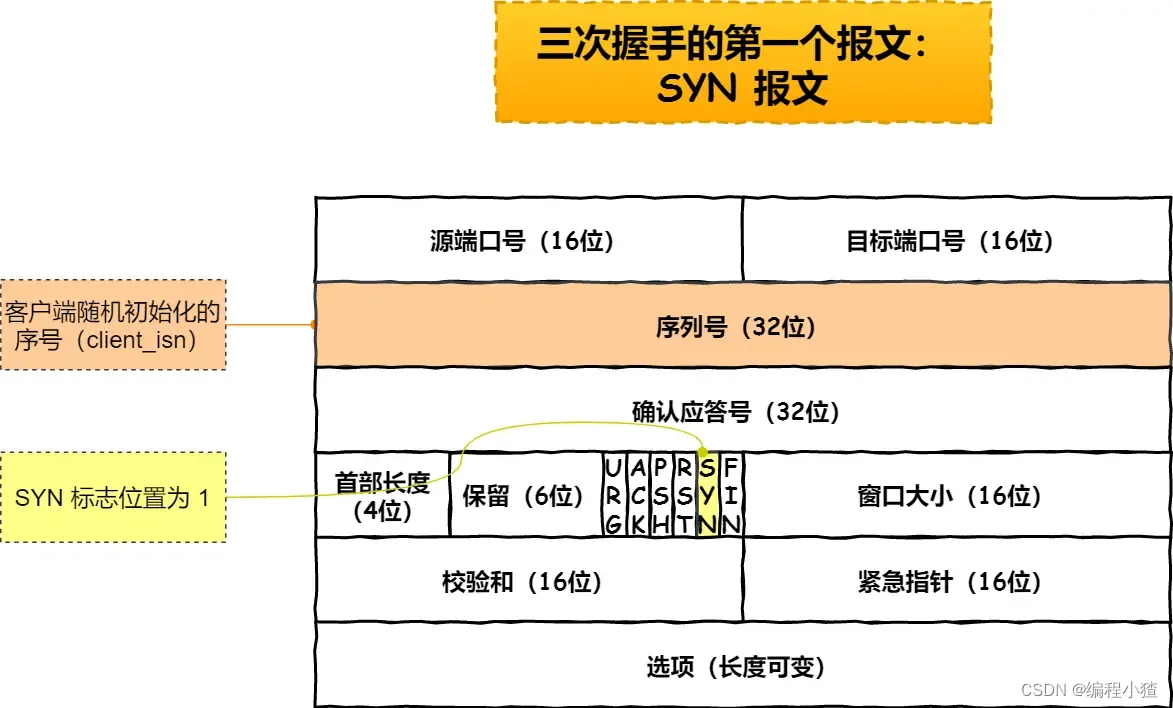
- 客戶端會隨機初始化序號(
client_isn),將此序號置于 TCP 首部的「序號」字段中,同時把?SYN?標志位置為?1,表示?SYN?報文。接著把第一個 SYN 報文發送給服務端,表示向服務端發起連接,該報文不包含應用層數據,之后客戶端處于?SYN-SENT?狀態。
?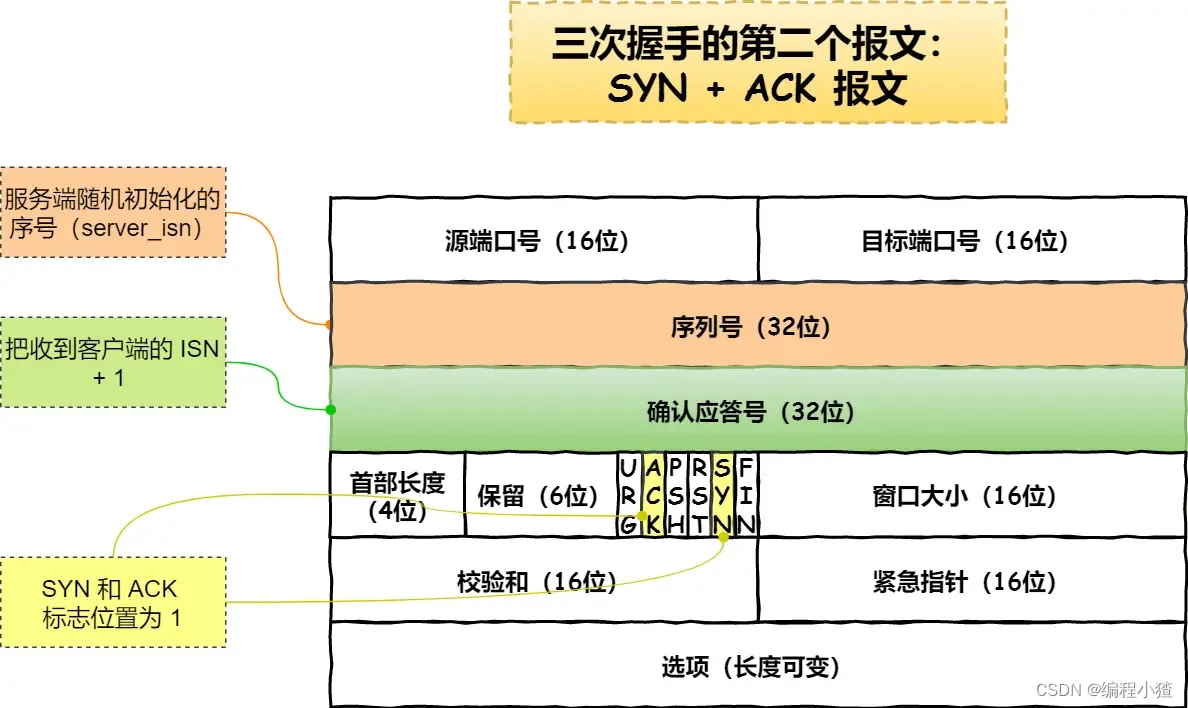
- 服務端收到客戶端的?
SYN?報文后,首先服務端也隨機初始化自己的序號(server_isn),將此序號填入 TCP 首部的「序號」字段中,其次把 TCP 首部的「確認應答號」字段填入?client_isn + 1, 接著把?SYN?和?ACK?標志位置為?1。最后把該報文發給客戶端,該報文也不包含應用層數據,之后服務端處于?SYN-RCVD?狀態。
?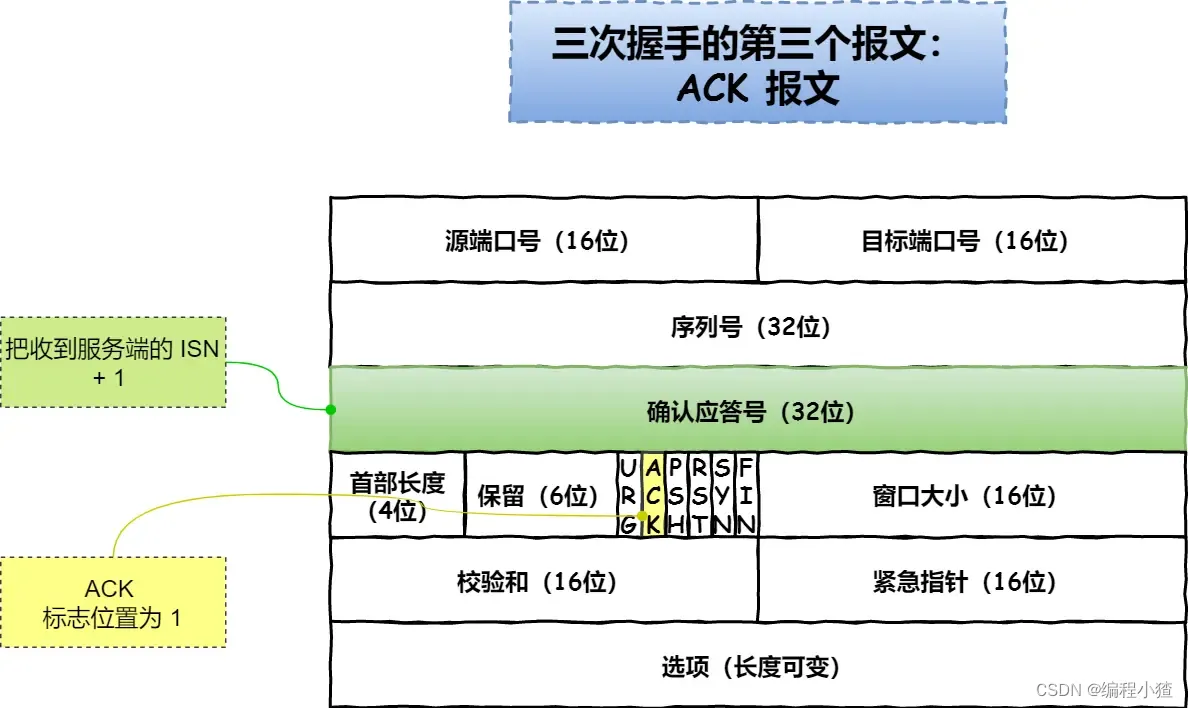
-
客戶端收到服務端報文后,還要向服務端回應最后一個應答報文,首先該應答報文 TCP 首部?
ACK?標志位置為?1?,其次「確認應答號」字段填入?server_isn + 1?,最后把報文發送給服務端,這次報文可以攜帶客戶到服務端的數據,之后客戶端處于?ESTABLISHED?狀態。 -
服務端收到客戶端的應答報文后,也進入?
ESTABLISHED?狀態。
從上面的過程可以發現第三次握手是可以攜帶數據的,前兩次握手是不可以攜帶數據的,這也是面試常問的題。
一旦完成三次握手,雙方都處于?ESTABLISHED?狀態,此時連接就已建立完成,客戶端和服務端就可以相互發送數據了。
如何在 Linux 系統中查看 TCP 狀態?
TCP 的連接狀態查看,在 Linux 可以通過?netstat -napt?命令查看。
?
為什么是三次握手?不是兩次、四次?
相信大家比較常回答的是:“因為三次握手才能保證雙方具有接收和發送的能力。”
這回答是沒問題,但這回答是片面的,并沒有說出主要的原因。
在前面我們知道了什么是?TCP 連接:
- 用于保證可靠性和流量控制維護的某些狀態信息,這些信息的組合,包括?Socket、序列號和窗口大小稱為連接。
所以,重要的是為什么三次握手才可以初始化 Socket、序列號和窗口大小并建立 TCP 連接。
接下來,以三個方面分析三次握手的原因:
- 三次握手才可以阻止重復歷史連接的初始化(主要原因)
- 三次握手才可以同步雙方的初始序列號
- 三次握手才可以避免資源浪費
原因一:避免歷史連接
我們來看看 RFC 793 指出的 TCP 連接使用三次握手的首要原因:
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
簡單來說,三次握手的首要原因是為了防止舊的重復連接初始化造成混亂。
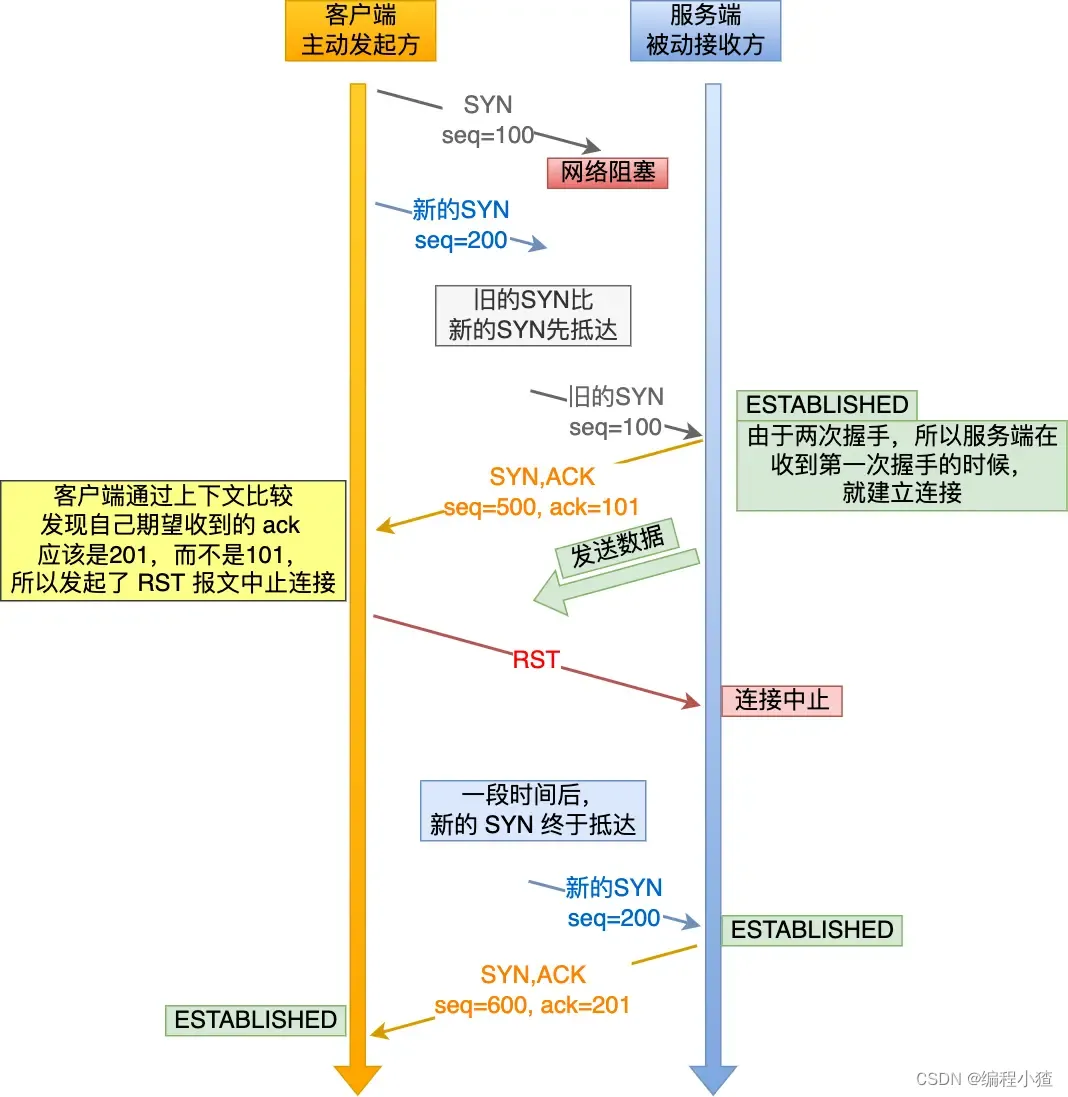
我們考慮一個場景,客戶端先發送了 SYN(seq = 90)報文,然后客戶端宕機了,而且這個 SYN 報文還被網絡阻塞了,服務端并沒有收到,接著客戶端重啟后,又重新向服務端建立連接,發送了 SYN(seq = 100)報文(注意!不是重傳 SYN,重傳的 SYN 的序列號是一樣的)。
看看三次握手是如何阻止歷史連接的:
?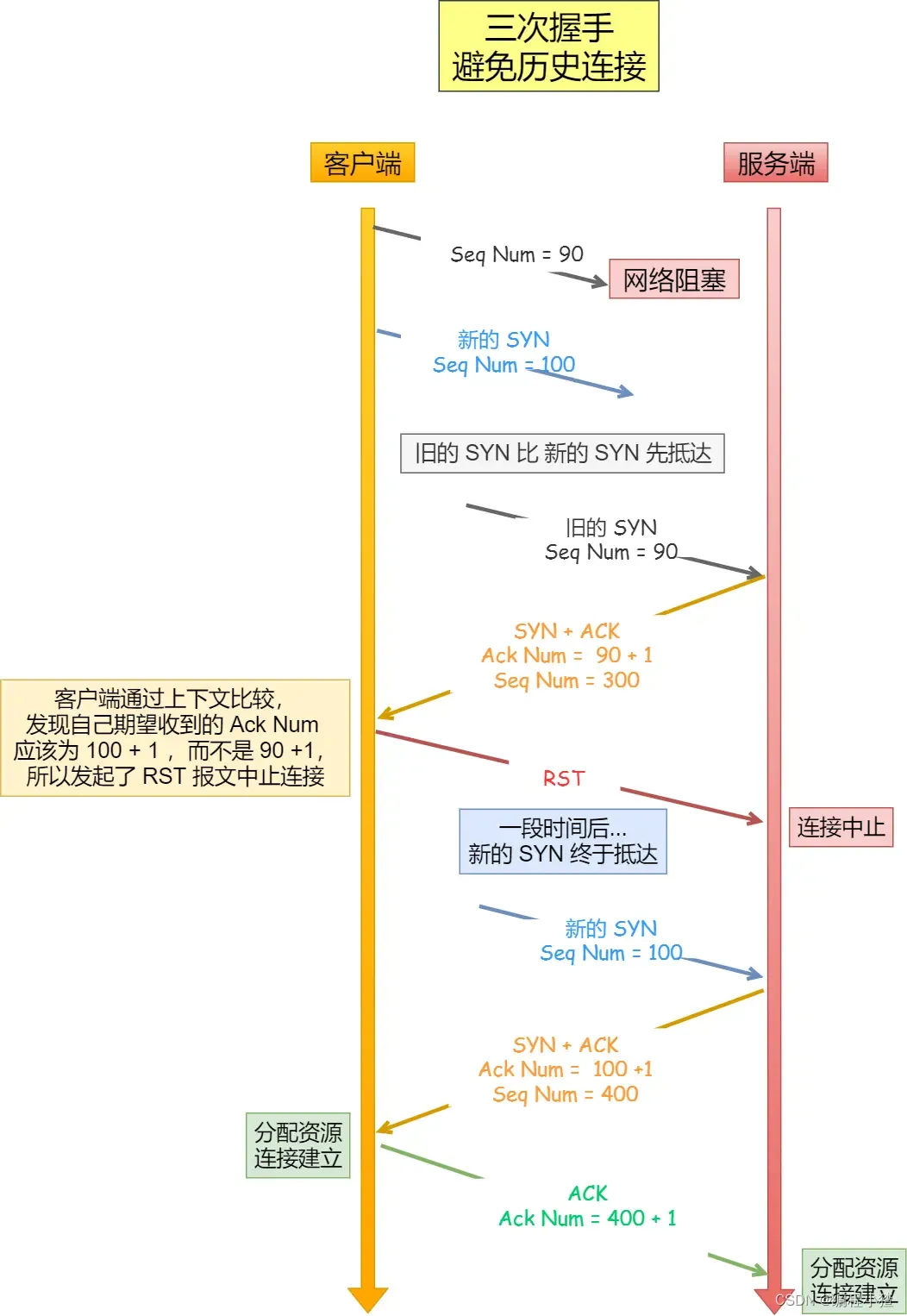
客戶端連續發送多次 SYN(都是同一個四元組)建立連接的報文,在網絡擁堵情況下:
- 一個「舊 SYN 報文」比「最新的 SYN」 報文早到達了服務端,那么此時服務端就會回一個?
SYN + ACK?報文給客戶端,此報文中的確認號是 91(90+1)。 - 客戶端收到后,發現自己期望收到的確認號應該是 100 + 1,而不是 90 + 1,于是就會回 RST 報文。
- 服務端收到 RST 報文后,就會釋放連接。
- 后續最新的 SYN 抵達了服務端后,客戶端與服務端就可以正常的完成三次握手了。
上述中的「舊 SYN 報文」稱為歷史連接,TCP 使用三次握手建立連接的最主要原因就是防止「歷史連接」初始化了連接。
TIP
有很多人問,如果服務端在收到 RST 報文之前,先收到了「新 SYN 報文」,也就是服務端收到客戶端報文的順序是:「舊 SYN 報文」->「新 SYN 報文」,此時會發生什么?
當服務端第一次收到 SYN 報文,也就是收到 「舊 SYN 報文」時,就會回復?SYN + ACK?報文給客戶端,此報文中的確認號是 91(90+1)。
然后這時再收到「新 SYN 報文」時,就會回?Challenge Ack?(opens new window)報文給客戶端,這個 ack 報文并不是確認收到「新 SYN 報文」的,而是上一次的 ack 確認號,也就是91(90+1)。所以客戶端收到此 ACK 報文時,發現自己期望收到的確認號應該是 101,而不是 91,于是就會回 RST 報文。
如果是兩次握手連接,就無法阻止歷史連接,那為什么 TCP 兩次握手為什么無法阻止歷史連接呢?
我先直接說結論,主要是因為在兩次握手的情況下,服務端沒有中間狀態給客戶端來阻止歷史連接,導致服務端可能建立一個歷史連接,造成資源浪費。
你想想,在兩次握手的情況下,服務端在收到 SYN 報文后,就進入 ESTABLISHED 狀態,意味著這時可以給對方發送數據,但是客戶端此時還沒有進入 ESTABLISHED 狀態,假設這次是歷史連接,客戶端判斷到此次連接為歷史連接,那么就會回 RST 報文來斷開連接,而服務端在第一次握手的時候就進入 ESTABLISHED 狀態,所以它可以發送數據的,但是它并不知道這個是歷史連接,它只有在收到 RST 報文后,才會斷開連接。
?
可以看到,如果采用兩次握手建立 TCP 連接的場景下,服務端在向客戶端發送數據前,并沒有阻止掉歷史連接,導致服務端建立了一個歷史連接,又白白發送了數據,妥妥地浪費了服務端的資源。
因此,要解決這種現象,最好就是在服務端發送數據前,也就是建立連接之前,要阻止掉歷史連接,這樣就不會造成資源浪費,而要實現這個功能,就需要三次握手。
所以,TCP 使用三次握手建立連接的最主要原因是防止「歷史連接」初始化了連接。
TIP
有人問:客戶端發送三次握手(ack 報文)后就可以發送數據了,而被動方此時還是 syn_received 狀態,如果 ack 丟了,那客戶端發的數據是不是也白白浪費了?
不是的,即使服務端還是在 syn_received 狀態,收到了客戶端發送的數據,還是可以建立連接的,并且還可以正常收到這個數據包。這是因為數據報文中是有 ack 標識位,也有確認號,這個確認號就是確認收到了第二次握手。如下圖:
 ?
?
所以,服務端收到這個數據報文,是可以正常建立連接的,然后就可以正常接收這個數據包了。
原因二:同步雙方初始序列號
TCP 協議的通信雙方, 都必須維護一個「序列號」, 序列號是可靠傳輸的一個關鍵因素,它的作用:
- 接收方可以去除重復的數據;
- 接收方可以根據數據包的序列號按序接收;
- 可以標識發送出去的數據包中, 哪些是已經被對方收到的(通過 ACK 報文中的序列號知道);
可見,序列號在 TCP 連接中占據著非常重要的作用,所以當客戶端發送攜帶「初始序列號」的?SYN?報文的時候,需要服務端回一個?ACK?應答報文,表示客戶端的 SYN 報文已被服務端成功接收,那當服務端發送「初始序列號」給客戶端的時候,依然也要得到客戶端的應答回應,這樣一來一回,才能確保雙方的初始序列號能被可靠的同步。
?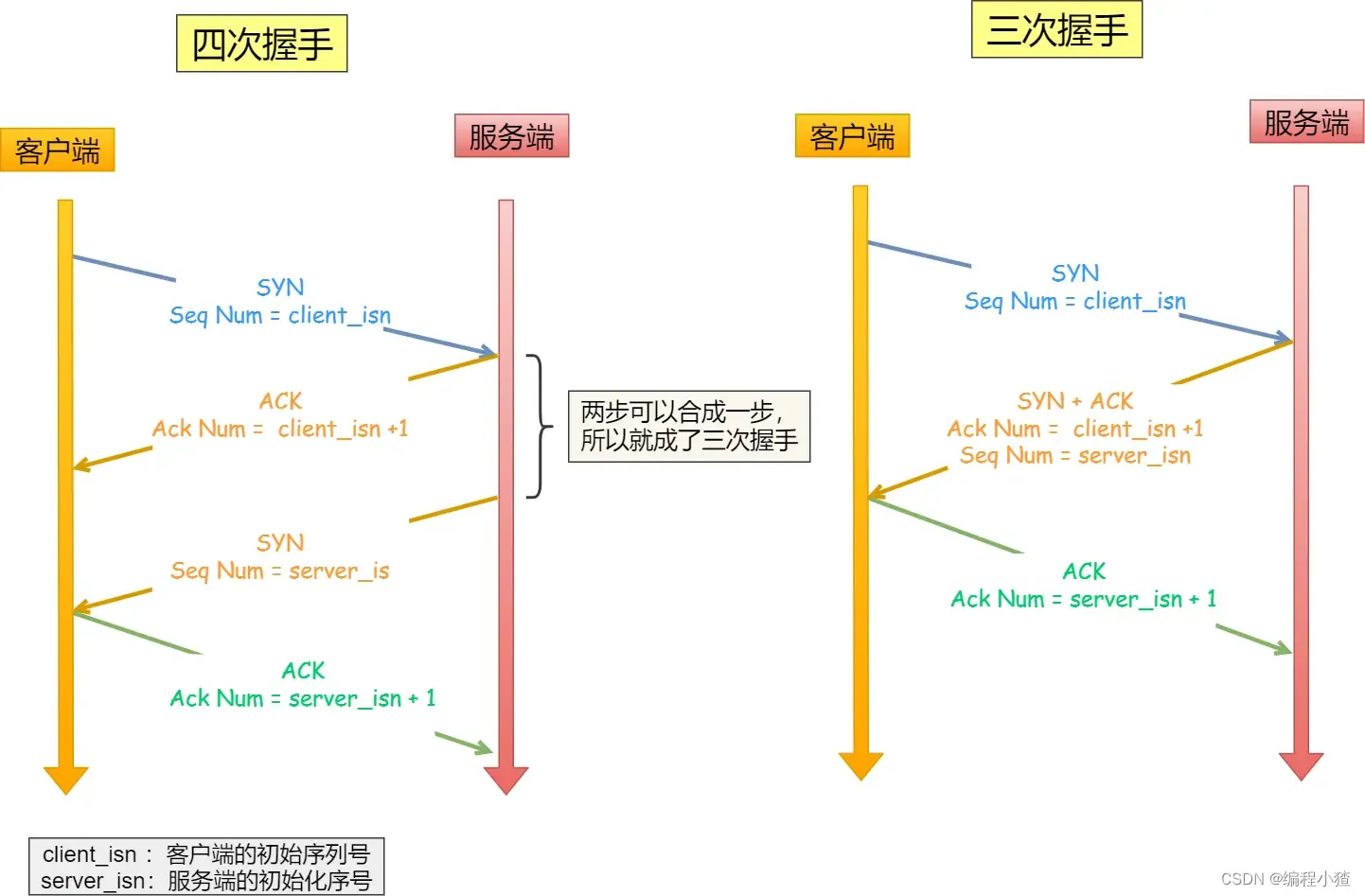
四次握手其實也能夠可靠的同步雙方的初始化序號,但由于第二步和第三步可以優化成一步,所以就成了「三次握手」。
而兩次握手只保證了一方的初始序列號能被對方成功接收,沒辦法保證雙方的初始序列號都能被確認接收。
原因三:避免資源浪費
如果只有「兩次握手」,當客戶端發生的?SYN?報文在網絡中阻塞,客戶端沒有接收到?ACK?報文,就會重新發送?SYN?,由于沒有第三次握手,服務端不清楚客戶端是否收到了自己回復的?ACK?報文,所以服務端每收到一個?SYN?就只能先主動建立一個連接,這會造成什么情況呢?
如果客戶端發送的?SYN?報文在網絡中阻塞了,重復發送多次?SYN?報文,那么服務端在收到請求后就會建立多個冗余的無效鏈接,造成不必要的資源浪費。
?
即兩次握手會造成消息滯留情況下,服務端重復接受無用的連接請求?SYN?報文,而造成重復分配資源。
TIP
很多人問,兩次握手不是也可以根據上下文信息丟棄 syn 歷史報文嗎?
我這里兩次握手是假設「由于沒有第三次握手,服務端不清楚客戶端是否收到了自己發送的建立連接的?
ACK?確認報文,所以每收到一個?SYN?就只能先主動建立一個連接」這個場景。當然你要實現成類似三次握手那樣,根據上下文丟棄 syn 歷史報文也是可以的,兩次握手沒有具體的實現,怎么假設都行。
小結
TCP 建立連接時,通過三次握手能防止歷史連接的建立,能減少雙方不必要的資源開銷,能幫助雙方同步初始化序列號。序列號能夠保證數據包不重復、不丟棄和按序傳輸。
不使用「兩次握手」和「四次握手」的原因:
- 「兩次握手」:無法防止歷史連接的建立,會造成雙方資源的浪費,也無法可靠的同步雙方序列號;
- 「四次握手」:三次握手就已經理論上最少可靠連接建立,所以不需要使用更多的通信次數。
為什么每次建立 TCP 連接時,初始化的序列號都要求不一樣呢?
主要原因有兩個方面:
- 為了防止歷史報文被下一個相同四元組的連接接收(主要方面);
- 為了安全性,防止黑客偽造的相同序列號的 TCP 報文被對方接收;
接下來,詳細說說第一點。
假設每次建立連接,客戶端和服務端的初始化序列號都是從 0 開始:
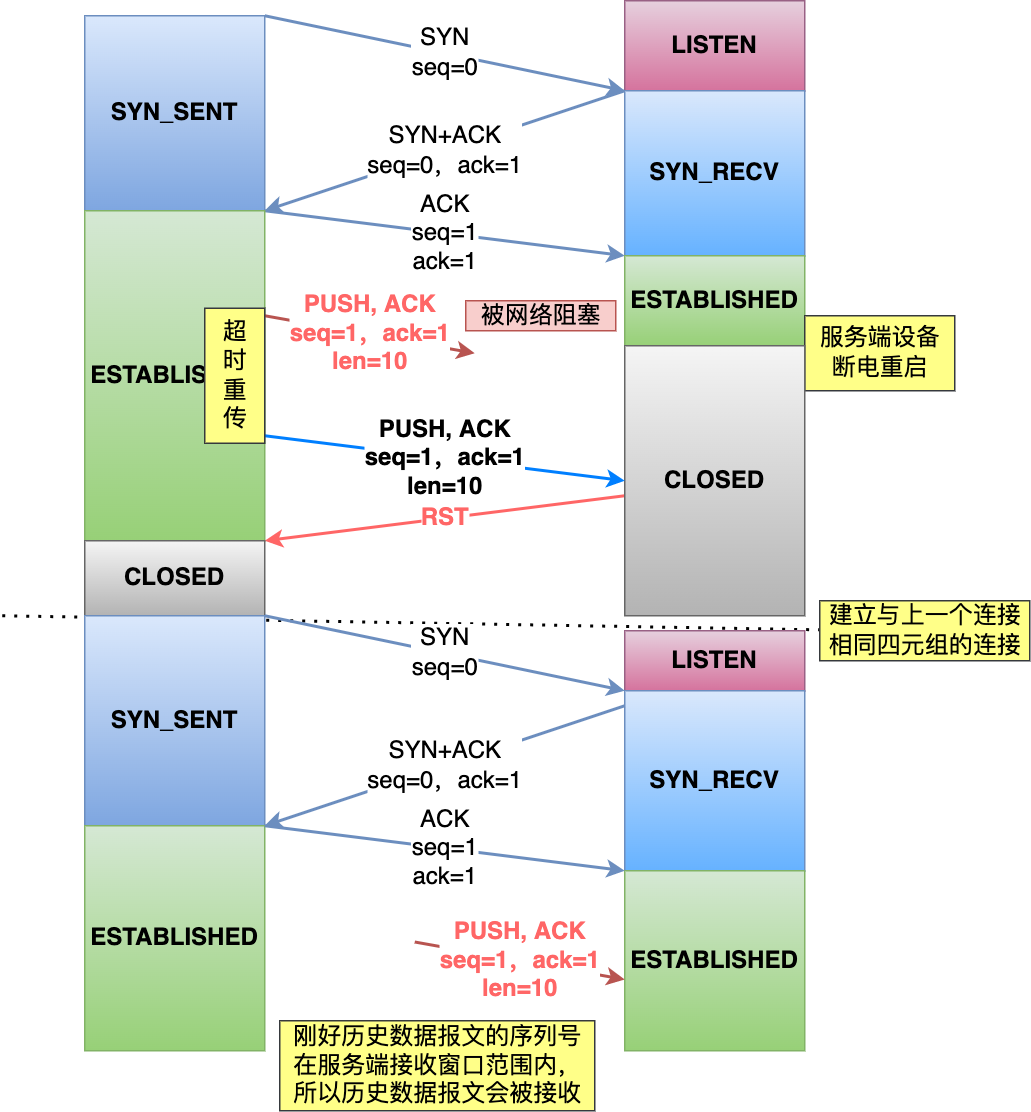 ?
?
過程如下:
- 客戶端和服務端建立一個 TCP 連接,在客戶端發送數據包被網絡阻塞了,然后超時重傳了這個數據包,而此時服務端設備斷電重啟了,之前與客戶端建立的連接就消失了,于是在收到客戶端的數據包的時候就會發送 RST 報文。
- 緊接著,客戶端又與服務端建立了與上一個連接相同四元組的連接;
- 在新連接建立完成后,上一個連接中被網絡阻塞的數據包正好抵達了服務端,剛好該數據包的序列號正好是在服務端的接收窗口內,所以該數據包會被服務端正常接收,就會造成數據錯亂。
可以看到,如果每次建立連接,客戶端和服務端的初始化序列號都是一樣的話,很容易出現歷史報文被下一個相同四元組的連接接收的問題。
如果每次建立連接客戶端和服務端的初始化序列號都「不一樣」,就有大概率因為歷史報文的序列號「不在」對方接收窗口,從而很大程度上避免了歷史報文,比如下圖:
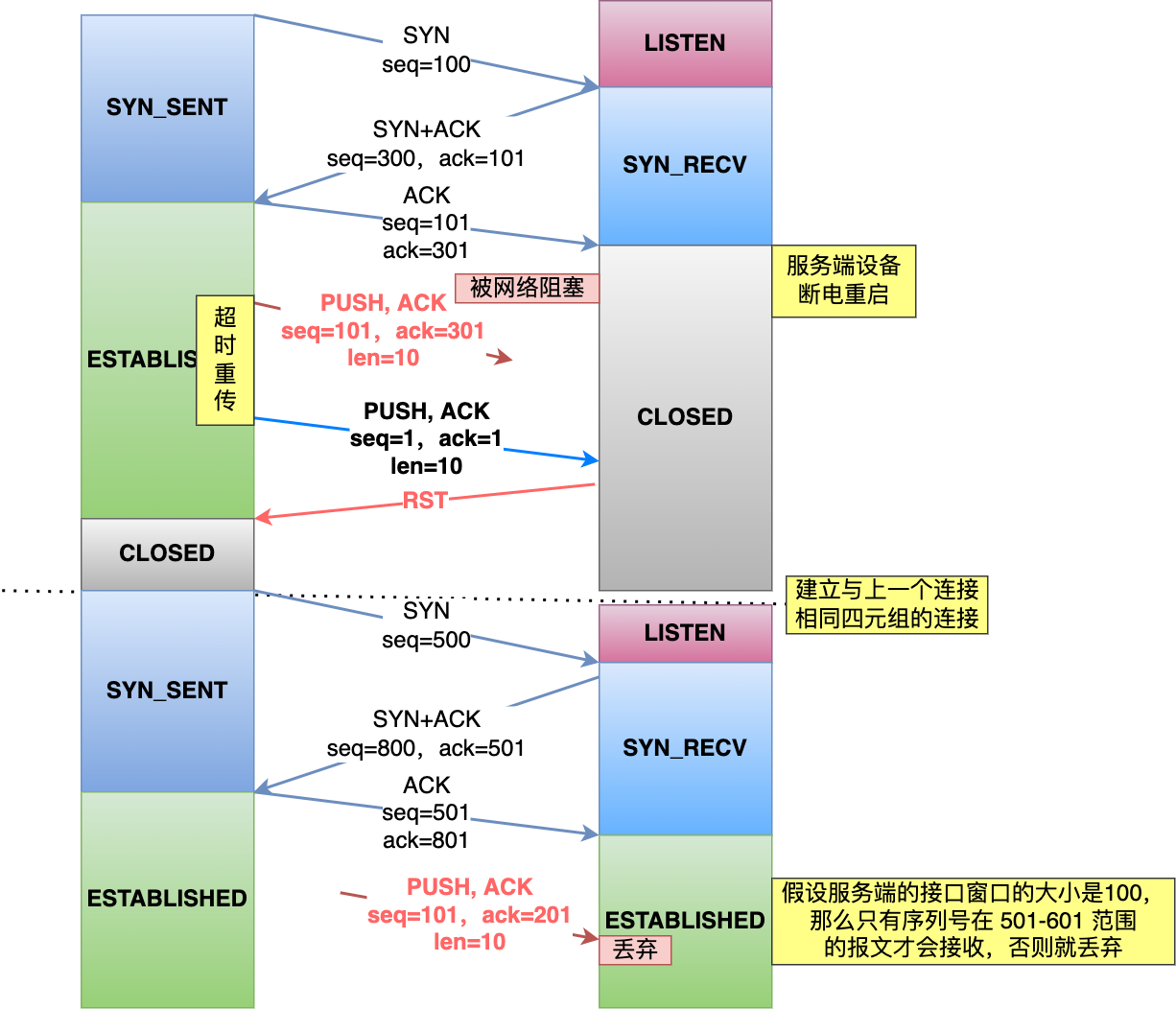 ?
?
相反,如果每次建立連接客戶端和服務端的初始化序列號都「一樣」,就有大概率遇到歷史報文的序列號剛「好在」對方的接收窗口內,從而導致歷史報文被新連接成功接收。
所以,每次初始化序列號不一樣很大程度上能夠避免歷史報文被下一個相同四元組的連接接收,注意是很大程度上,并不是完全避免了(因為序列號會有回繞的問題,所以需要用時間戳的機制來判斷歷史報文,詳細看篇:TCP 是如何避免歷史報文的??(opens new window))。
初始序列號 ISN 是如何隨機產生的?
起始?ISN?是基于時鐘的,每 4 微秒 + 1,轉一圈要 4.55 個小時。
RFC793 提到初始化序列號 ISN 隨機生成算法:ISN = M + F(localhost, localport, remotehost, remoteport)。
M?是一個計時器,這個計時器每隔 4 微秒加 1。F?是一個 Hash 算法,根據源 IP、目的 IP、源端口、目的端口生成一個隨機數值。要保證 Hash 算法不能被外部輕易推算得出,用 MD5 算法是一個比較好的選擇。
可以看到,隨機數是會基于時鐘計時器遞增的,基本不可能會隨機成一樣的初始化序列號。
既然 IP 層會分片,為什么 TCP 層還需要 MSS 呢?
我們先來認識下 MTU 和 MSS
?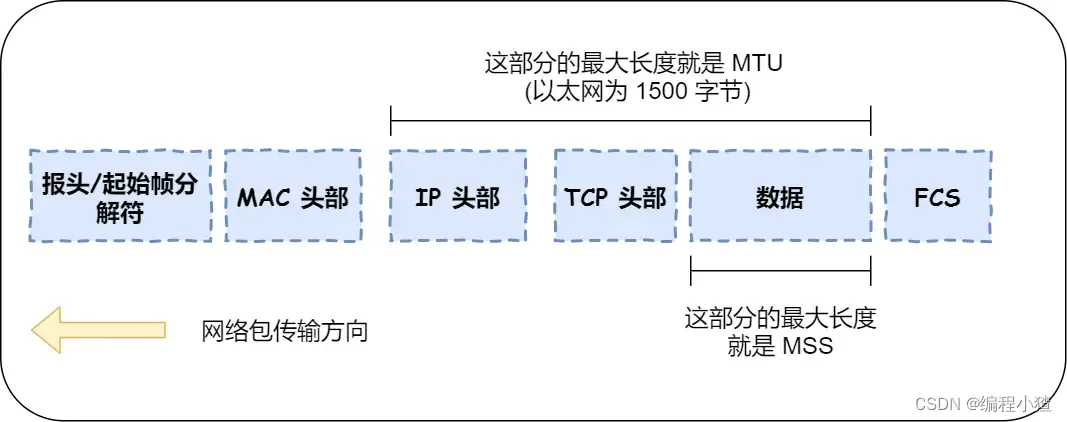
MTU:一個網絡包的最大長度,以太網中一般為?1500?字節;MSS:除去 IP 和 TCP 頭部之后,一個網絡包所能容納的 TCP 數據的最大長度;
如果在 TCP 的整個報文(頭部 + 數據)交給 IP 層進行分片,會有什么異常呢?
當 IP 層有一個超過?MTU?大小的數據(TCP 頭部 + TCP 數據)要發送,那么 IP 層就要進行分片,把數據分片成若干片,保證每一個分片都小于 MTU。把一份 IP 數據報進行分片以后,由目標主機的 IP 層來進行重新組裝后,再交給上一層 TCP 傳輸層。
這看起來井然有序,但這存在隱患的,那么當如果一個 IP 分片丟失,整個 IP 報文的所有分片都得重傳。
因為 IP 層本身沒有超時重傳機制,它由傳輸層的 TCP 來負責超時和重傳。
當某一個 IP 分片丟失后,接收方的 IP 層就無法組裝成一個完整的 TCP 報文(頭部 + 數據),也就無法將數據報文送到 TCP 層,所以接收方不會響應 ACK 給發送方,因為發送方遲遲收不到 ACK 確認報文,所以會觸發超時重傳,就會重發「整個 TCP 報文(頭部 + 數據)」。
因此,可以得知由 IP 層進行分片傳輸,是非常沒有效率的。
所以,為了達到最佳的傳輸效能 TCP 協議在建立連接的時候通常要協商雙方的 MSS 值,當 TCP 層發現數據超過 MSS 時,則就先會進行分片,當然由它形成的 IP 包的長度也就不會大于 MTU ,自然也就不用 IP 分片了。
?
經過 TCP 層分片后,如果一個 TCP 分片丟失后,進行重發時也是以 MSS 為單位,而不用重傳所有的分片,大大增加了重傳的效率。
第一次握手丟失了,會發生什么?
當客戶端想和服務端建立 TCP 連接的時候,首先第一個發的就是 SYN 報文,然后進入到?SYN_SENT?狀態。
在這之后,如果客戶端遲遲收不到服務端的 SYN-ACK 報文(第二次握手),就會觸發「超時重傳」機制,重傳 SYN 報文,而且重傳的 SYN 報文的序列號都是一樣的。
不同版本的操作系統可能超時時間不同,有的 1 秒的,也有 3 秒的,這個超時時間是寫死在內核里的,如果想要更改則需要重新編譯內核,比較麻煩。
當客戶端在 1 秒后沒收到服務端的 SYN-ACK 報文后,客戶端就會重發 SYN 報文,那到底重發幾次呢?
在 Linux 里,客戶端的 SYN 報文最大重傳次數由?tcp_syn_retries內核參數控制,這個參數是可以自定義的,默認值一般是 5。
# cat /proc/sys/net/ipv4/tcp_syn_retries
5
通常,第一次超時重傳是在 1 秒后,第二次超時重傳是在 2 秒,第三次超時重傳是在 4 秒后,第四次超時重傳是在 8 秒后,第五次是在超時重傳 16 秒后。沒錯,每次超時的時間是上一次的 2 倍。
當第五次超時重傳后,會繼續等待 32 秒,如果服務端仍然沒有回應 ACK,客戶端就不再發送 SYN 包,然后斷開 TCP 連接。
所以,總耗時是 1+2+4+8+16+32=63 秒,大約 1 分鐘左右。
舉個例子,假設 tcp_syn_retries 參數值為 3,那么當客戶端的 SYN 報文一直在網絡中丟失時,會發生下圖的過程:
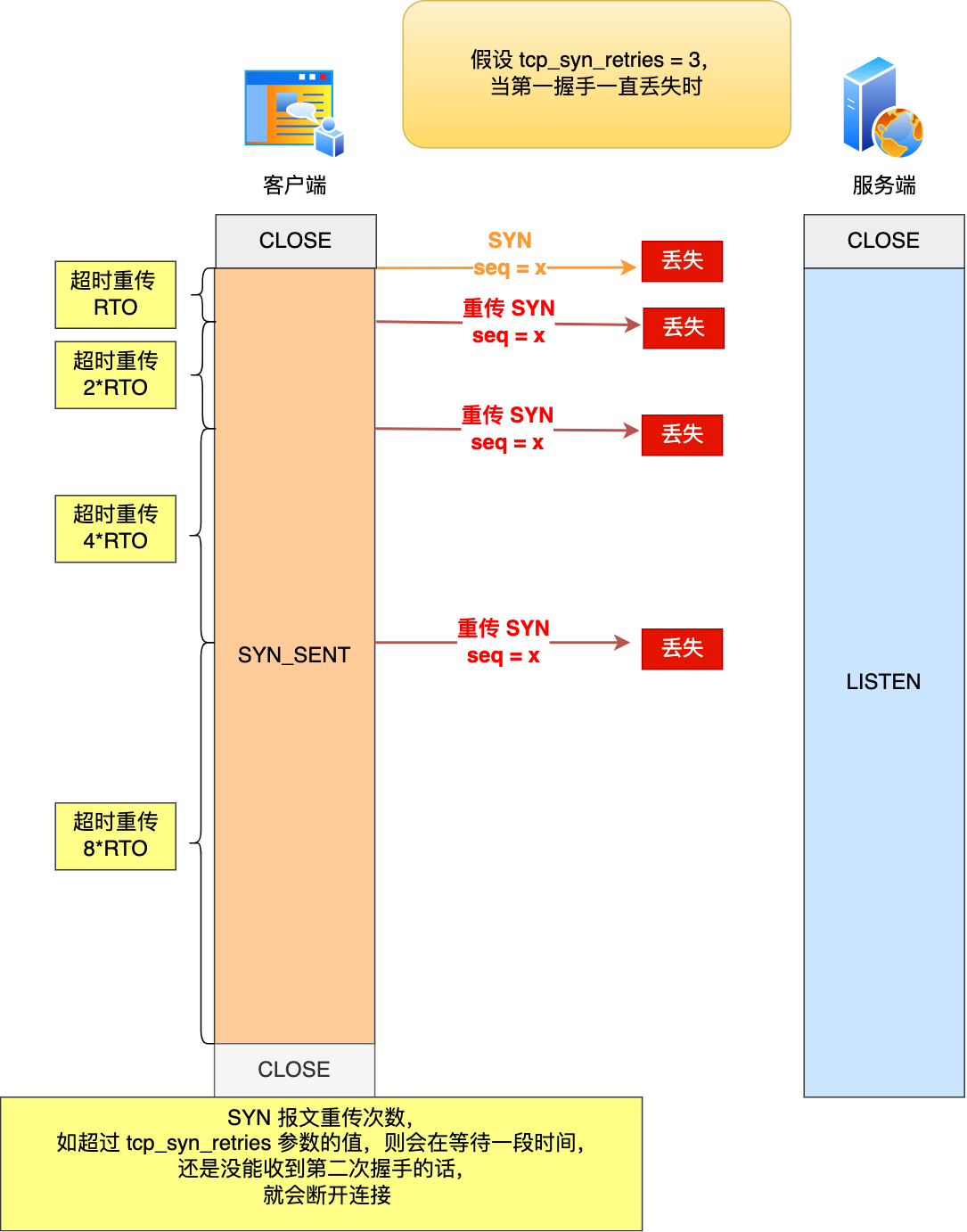 ?
?
具體過程:
- 當客戶端超時重傳 3 次 SYN 報文后,由于 tcp_syn_retries 為 3,已達到最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到服務端的第二次握手(SYN-ACK 報文),那么客戶端就會斷開連接。
第二次握手丟失了,會發生什么?
當服務端收到客戶端的第一次握手后,就會回 SYN-ACK 報文給客戶端,這個就是第二次握手,此時服務端會進入?SYN_RCVD?狀態。
第二次握手的?SYN-ACK?報文其實有兩個目的 :
- 第二次握手里的 ACK, 是對第一次握手的確認報文;
- 第二次握手里的 SYN,是服務端發起建立 TCP 連接的報文;
所以,如果第二次握手丟了,就會發生比較有意思的事情,具體會怎么樣呢?
因為第二次握手報文里是包含對客戶端的第一次握手的 ACK 確認報文,所以,如果客戶端遲遲沒有收到第二次握手,那么客戶端就覺得可能自己的 SYN 報文(第一次握手)丟失了,于是客戶端就會觸發超時重傳機制,重傳 SYN 報文。
然后,因為第二次握手中包含服務端的 SYN 報文,所以當客戶端收到后,需要給服務端發送 ACK 確認報文(第三次握手),服務端才會認為該 SYN 報文被客戶端收到了。
那么,如果第二次握手丟失了,服務端就收不到第三次握手,于是服務端這邊會觸發超時重傳機制,重傳 SYN-ACK 報文。
在 Linux 下,SYN-ACK 報文的最大重傳次數由?tcp_synack_retries內核參數決定,默認值是 5。
# cat /proc/sys/net/ipv4/tcp_synack_retries
5
因此,當第二次握手丟失了,客戶端和服務端都會重傳:
- 客戶端會重傳 SYN 報文,也就是第一次握手,最大重傳次數由?
tcp_syn_retries內核參數決定; - 服務端會重傳 SYN-ACK 報文,也就是第二次握手,最大重傳次數由?
tcp_synack_retries?內核參數決定。
舉個例子,假設 tcp_syn_retries 參數值為 1,tcp_synack_retries 參數值為 2,那么當第二次握手一直丟失時,發生的過程如下圖:
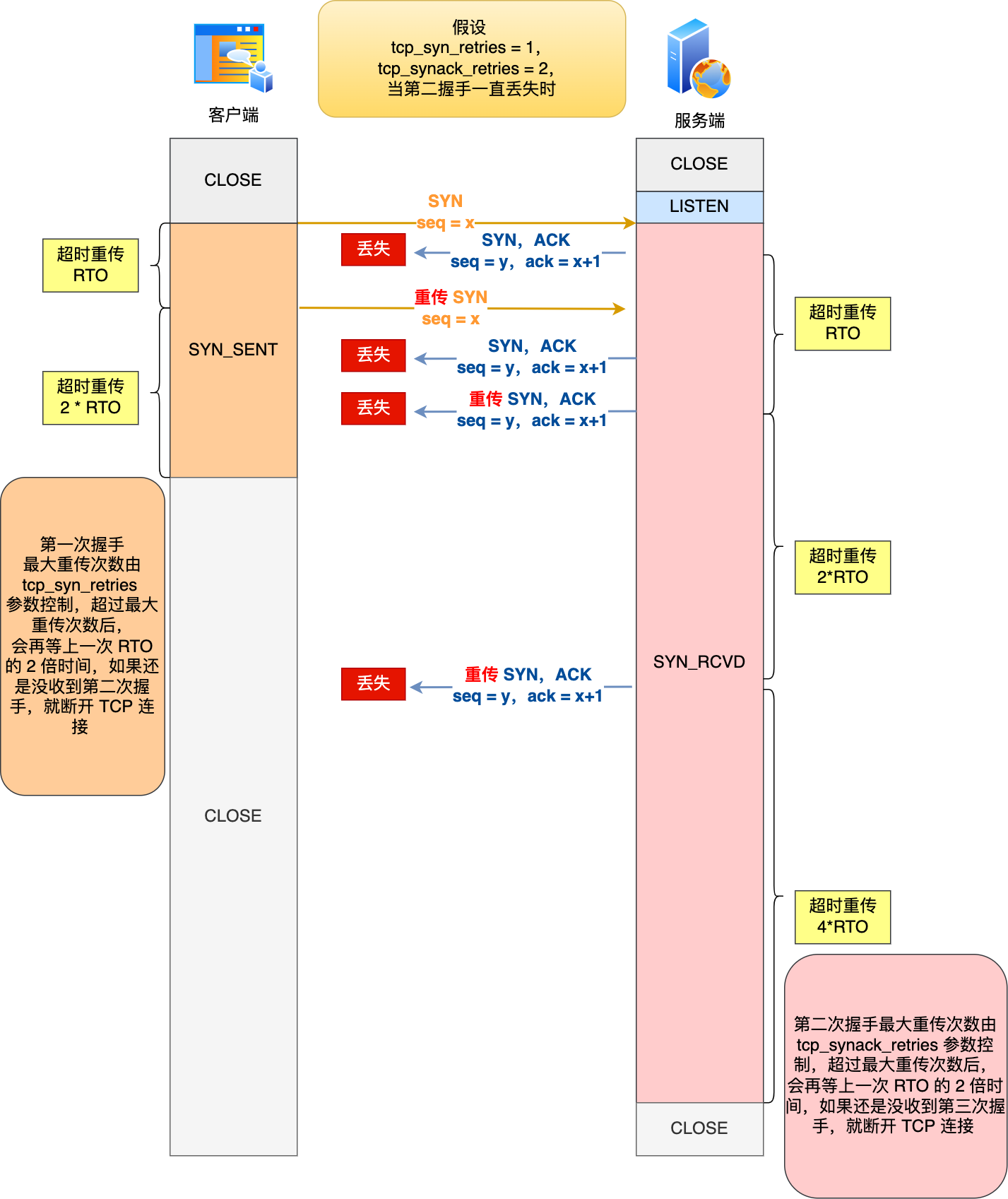 ?
?
具體過程:
- 當客戶端超時重傳 1 次 SYN 報文后,由于 tcp_syn_retries 為 1,已達到最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到服務端的第二次握手(SYN-ACK 報文),那么客戶端就會斷開連接。
- 當服務端超時重傳 2 次 SYN-ACK 報文后,由于 tcp_synack_retries 為 2,已達到最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到客戶端的第三次握手(ACK 報文),那么服務端就會斷開連接。
第三次握手丟失了,會發生什么?
客戶端收到服務端的 SYN-ACK 報文后,就會給服務端回一個 ACK 報文,也就是第三次握手,此時客戶端狀態進入到?ESTABLISH?狀態。
因為這個第三次握手的 ACK 是對第二次握手的 SYN 的確認報文,所以當第三次握手丟失了,如果服務端那一方遲遲收不到這個確認報文,就會觸發超時重傳機制,重傳 SYN-ACK 報文,直到收到第三次握手,或者達到最大重傳次數。
注意,ACK 報文是不會有重傳的,當 ACK 丟失了,就由對方重傳對應的報文。
舉個例子,假設 tcp_synack_retries 參數值為 2,那么當第三次握手一直丟失時,發生的過程如下圖:
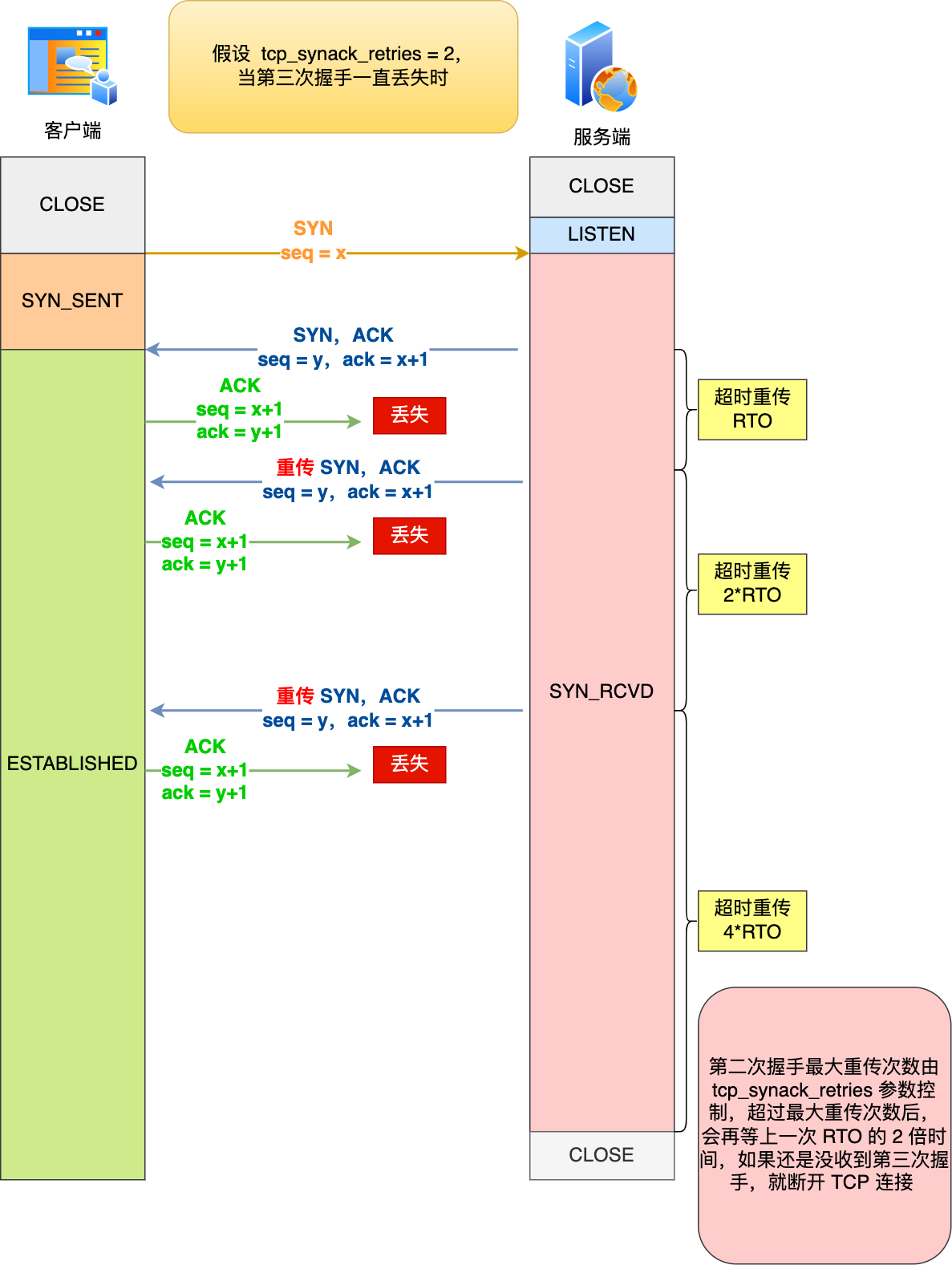 ?
?
具體過程:
- 當服務端超時重傳 2 次 SYN-ACK 報文后,由于 tcp_synack_retries 為 2,已達到最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到客戶端的第三次握手(ACK 報文),那么服務端就會斷開連接。
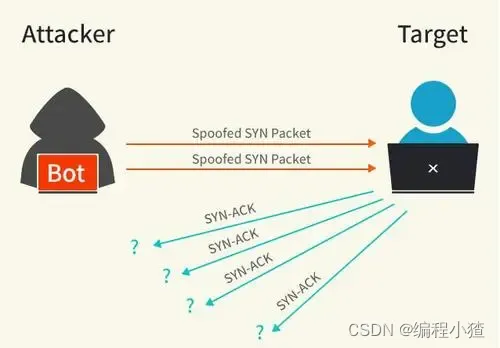
什么是 SYN 攻擊?如何避免 SYN 攻擊?
我們都知道 TCP 連接建立是需要三次握手,假設攻擊者短時間偽造不同 IP 地址的?SYN?報文,服務端每接收到一個?SYN?報文,就進入SYN_RCVD?狀態,但服務端發送出去的?ACK + SYN?報文,無法得到未知 IP 主機的?ACK?應答,久而久之就會占滿服務端的半連接隊列,使得服務端不能為正常用戶服務。
?
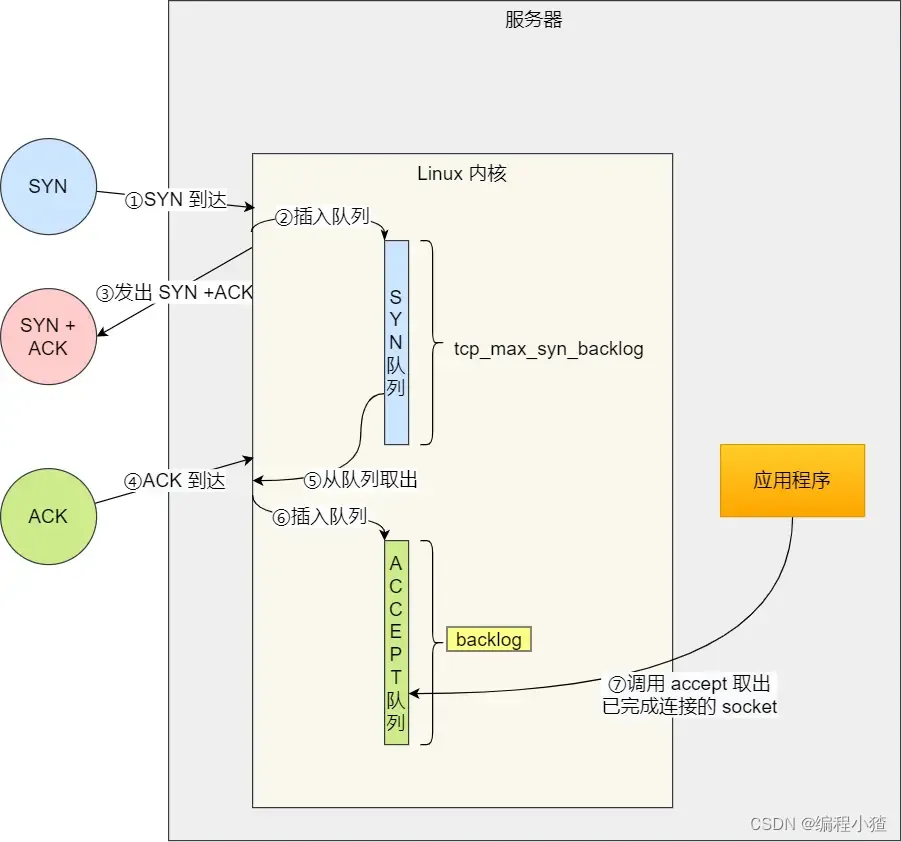
先跟大家說一下,什么是 TCP 半連接和全連接隊列。
在 TCP 三次握手的時候,Linux 內核會維護兩個隊列,分別是:
- 半連接隊列,也稱 SYN 隊列;
- 全連接隊列,也稱 accept 隊列;
我們先來看下 Linux 內核的?SYN?隊列(半連接隊列)與?Accpet?隊列(全連接隊列)是如何工作的?
 ?
?
正常流程:
- 當服務端接收到客戶端的 SYN 報文時,會創建一個半連接的對象,然后將其加入到內核的「 SYN 隊列」;
- 接著發送 SYN + ACK 給客戶端,等待客戶端回應 ACK 報文;
- 服務端接收到 ACK 報文后,從「 SYN 隊列」取出一個半連接對象,然后創建一個新的連接對象放入到「 Accept 隊列」;
- 應用通過調用?
accpet()?socket 接口,從「 Accept 隊列」取出連接對象。
不管是半連接隊列還是全連接隊列,都有最大長度限制,超過限制時,默認情況都會丟棄報文。
SYN 攻擊方式最直接的表現就會把 TCP 半連接隊列打滿,這樣當 TCP 半連接隊列滿了,后續再在收到 SYN 報文就會丟棄,導致客戶端無法和服務端建立連接。
避免 SYN 攻擊方式,可以有以下四種方法:
- 調大 netdev_max_backlog;
- 增大 TCP 半連接隊列;
- 開啟 tcp_syncookies;
- 減少 SYN+ACK 重傳次數
方式一:調大 netdev_max_backlog
當網卡接收數據包的速度大于內核處理的速度時,會有一個隊列保存這些數據包。控制該隊列的最大值如下參數,默認值是 1000,我們要適當調大該參數的值,比如設置為 10000:
net.core.netdev_max_backlog = 10000
方式二:增大 TCP 半連接隊列
增大 TCP 半連接隊列,要同時增大下面這三個參數:
- 增大 net.ipv4.tcp_max_syn_backlog
- 增大 listen() 函數中的 backlog
- 增大 net.core.somaxconn
具體為什么是三個參數決定 TCP 半連接隊列的大小,可以看這篇:可以看這篇:TCP 半連接隊列和全連接隊列滿了會發生什么?又該如何應對?(opens new window)
方式三:開啟 net.ipv4.tcp_syncookies
開啟 syncookies 功能就可以在不使用 SYN 半連接隊列的情況下成功建立連接,相當于繞過了 SYN 半連接來建立連接。
 ?
?
具體過程:
- 當 「 SYN 隊列」滿之后,后續服務端收到 SYN 包,不會丟棄,而是根據算法,計算出一個?
cookie?值; - 將 cookie 值放到第二次握手報文的「序列號」里,然后服務端回第二次握手給客戶端;
- 服務端接收到客戶端的應答報文時,服務端會檢查這個 ACK 包的合法性。如果合法,將該連接對象放入到「 Accept 隊列」。
- 最后應用程序通過調用?
accpet()?接口,從「 Accept 隊列」取出的連接。
可以看到,當開啟了 tcp_syncookies 了,即使受到 SYN 攻擊而導致 SYN 隊列滿時,也能保證正常的連接成功建立。
net.ipv4.tcp_syncookies 參數主要有以下三個值:
- 0 值,表示關閉該功能;
- 1 值,表示僅當 SYN 半連接隊列放不下時,再啟用它;
- 2 值,表示無條件開啟功能;
那么在應對 SYN 攻擊時,只需要設置為 1 即可。
$ echo 1 > /proc/sys/net/ipv4/tcp_syncookies
方式四:減少 SYN+ACK 重傳次數
當服務端受到 SYN 攻擊時,就會有大量處于 SYN_REVC 狀態的 TCP 連接,處于這個狀態的 TCP 會重傳 SYN+ACK ,當重傳超過次數達到上限后,就會斷開連接。
那么針對 SYN 攻擊的場景,我們可以減少 SYN-ACK 的重傳次數,以加快處于 SYN_REVC 狀態的 TCP 連接斷開。
SYN-ACK 報文的最大重傳次數由?tcp_synack_retries內核參數決定(默認值是 5 次),比如將 tcp_synack_retries 減少到 2 次:
$ echo 2 > /proc/sys/net/ipv4/tcp_synack_retries
TCP 連接斷開
TCP 四次揮手過程是怎樣的?
天下沒有不散的宴席,對于 TCP 連接也是這樣, TCP 斷開連接是通過四次揮手方式。
雙方都可以主動斷開連接,斷開連接后主機中的「資源」將被釋放,四次揮手的過程如下圖:
?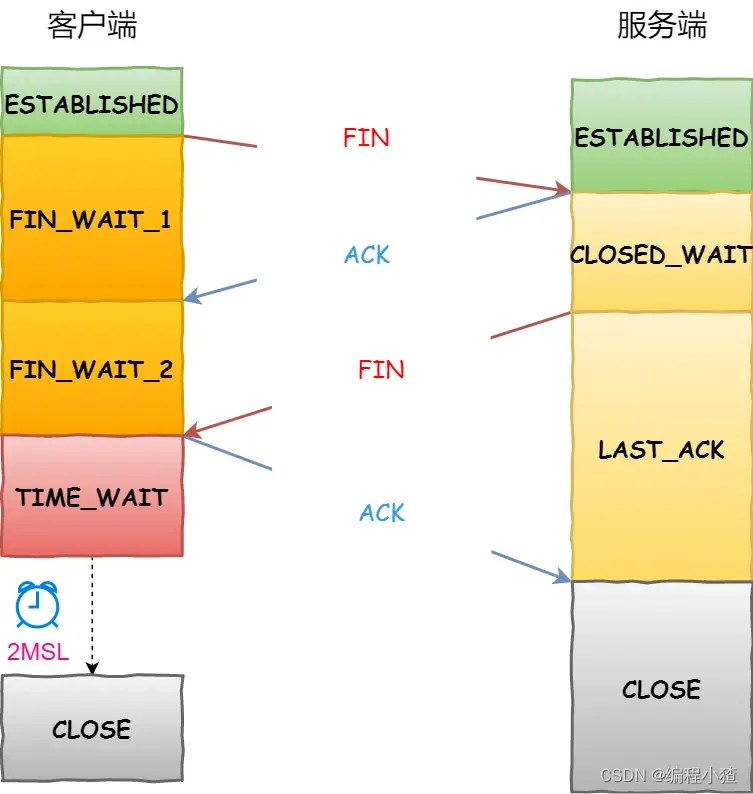
- 客戶端打算關閉連接,此時會發送一個 TCP 首部?
FIN?標志位被置為?1?的報文,也即?FIN?報文,之后客戶端進入?FIN_WAIT_1?狀態。 - 服務端收到該報文后,就向客戶端發送?
ACK?應答報文,接著服務端進入?CLOSE_WAIT?狀態。 - 客戶端收到服務端的?
ACK?應答報文后,之后進入?FIN_WAIT_2?狀態。 - 等待服務端處理完數據后,也向客戶端發送?
FIN?報文,之后服務端進入?LAST_ACK?狀態。 - 客戶端收到服務端的?
FIN?報文后,回一個?ACK?應答報文,之后進入?TIME_WAIT?狀態 - 服務端收到了?
ACK?應答報文后,就進入了?CLOSE?狀態,至此服務端已經完成連接的關閉。 - 客戶端在經過?
2MSL?一段時間后,自動進入?CLOSE?狀態,至此客戶端也完成連接的關閉。
你可以看到,每個方向都需要一個 FIN 和一個 ACK,因此通常被稱為四次揮手。
這里一點需要注意是:主動關閉連接的,才有 TIME_WAIT 狀態。
為什么揮手需要四次?
再來回顧下四次揮手雙方發?FIN?包的過程,就能理解為什么需要四次了。
- 關閉連接時,客戶端向服務端發送?
FIN?時,僅僅表示客戶端不再發送數據了但是還能接收數據。 - 服務端收到客戶端的?
FIN?報文時,先回一個?ACK?應答報文,而服務端可能還有數據需要處理和發送,等服務端不再發送數據時,才發送?FIN?報文給客戶端來表示同意現在關閉連接。
從上面過程可知,服務端通常需要等待完成數據的發送和處理,所以服務端的?ACK?和?FIN?一般都會分開發送,因此是需要四次揮手。
但是在特定情況下,四次揮手是可以變成三次揮手的,具體情況可以看這篇:TCP 四次揮手,可以變成三次嗎?(opens new window)
第一次揮手丟失了,會發生什么?
當客戶端(主動關閉方)調用 close 函數后,就會向服務端發送 FIN 報文,試圖與服務端斷開連接,此時客戶端的連接進入到?FIN_WAIT_1?狀態。
正常情況下,如果能及時收到服務端(被動關閉方)的 ACK,則會很快變為?FIN_WAIT2狀態。
如果第一次揮手丟失了,那么客戶端遲遲收不到被動方的 ACK 的話,也就會觸發超時重傳機制,重傳 FIN 報文,重發次數由?tcp_orphan_retries?參數控制。
當客戶端重傳 FIN 報文的次數超過?tcp_orphan_retries?后,就不再發送 FIN 報文,則會在等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到第二次揮手,那么直接進入到?close?狀態。
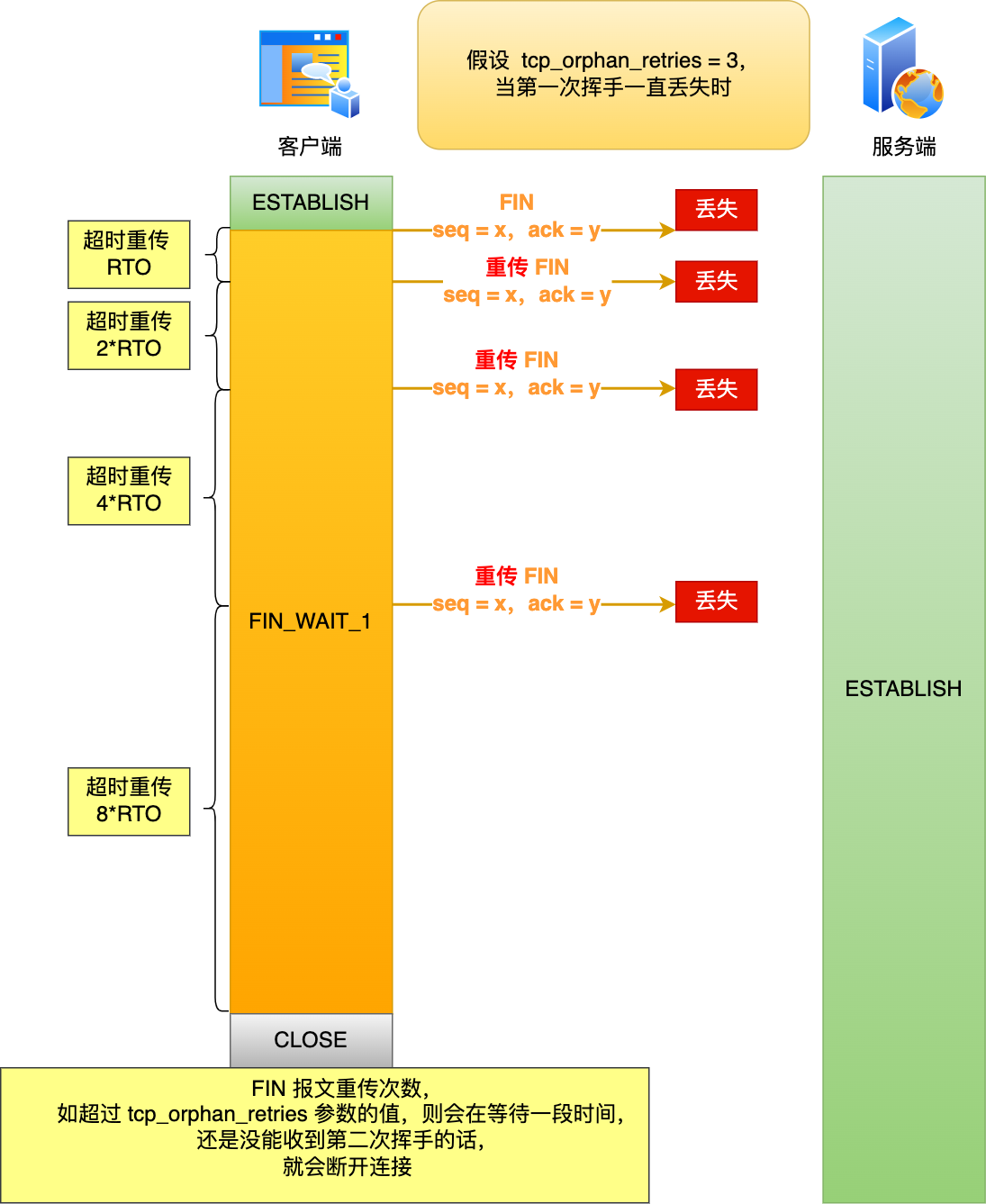
舉個例子,假設 tcp_orphan_retries 參數值為 3,當第一次揮手一直丟失時,發生的過程如下圖:
 ?
?
具體過程:
- 當客戶端超時重傳 3 次 FIN 報文后,由于 tcp_orphan_retries 為 3,已達到最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到服務端的第二次揮手(ACK報文),那么客戶端就會斷開連接。
第二次揮手丟失了,會發生什么?
當服務端收到客戶端的第一次揮手后,就會先回一個 ACK 確認報文,此時服務端的連接進入到?CLOSE_WAIT?狀態。
在前面我們也提了,ACK 報文是不會重傳的,所以如果服務端的第二次揮手丟失了,客戶端就會觸發超時重傳機制,重傳 FIN 報文,直到收到服務端的第二次揮手,或者達到最大的重傳次數。
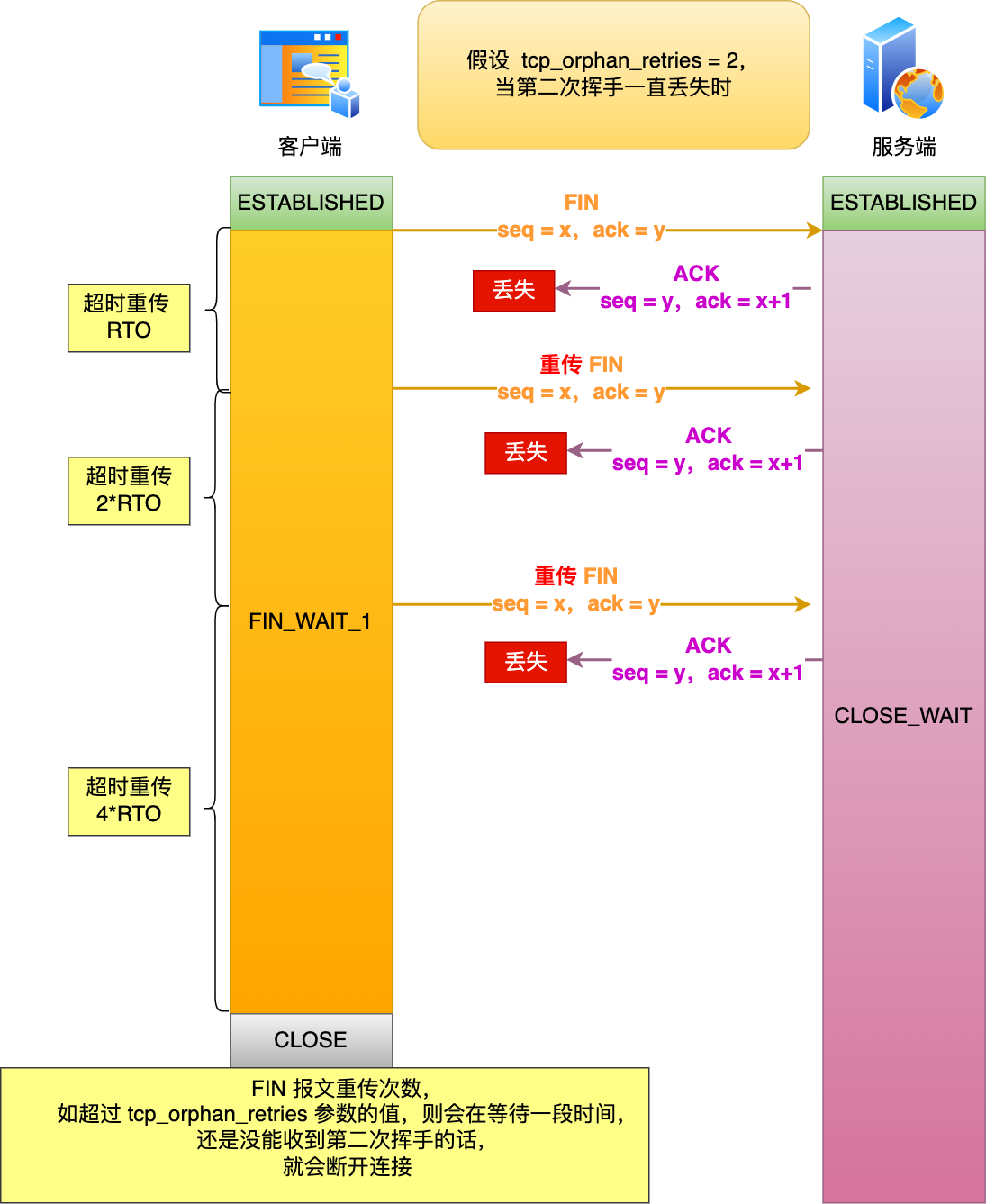
舉個例子,假設 tcp_orphan_retries 參數值為 2,當第二次揮手一直丟失時,發生的過程如下圖:
 ?
?
具體過程:
- 當客戶端超時重傳 2 次 FIN 報文后,由于 tcp_orphan_retries 為 2,已達到最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到服務端的第二次揮手(ACK 報文),那么客戶端就會斷開連接。
這里提一下,當客戶端收到第二次揮手,也就是收到服務端發送的 ACK 報文后,客戶端就會處于?FIN_WAIT2?狀態,在這個狀態需要等服務端發送第三次揮手,也就是服務端的 FIN 報文。
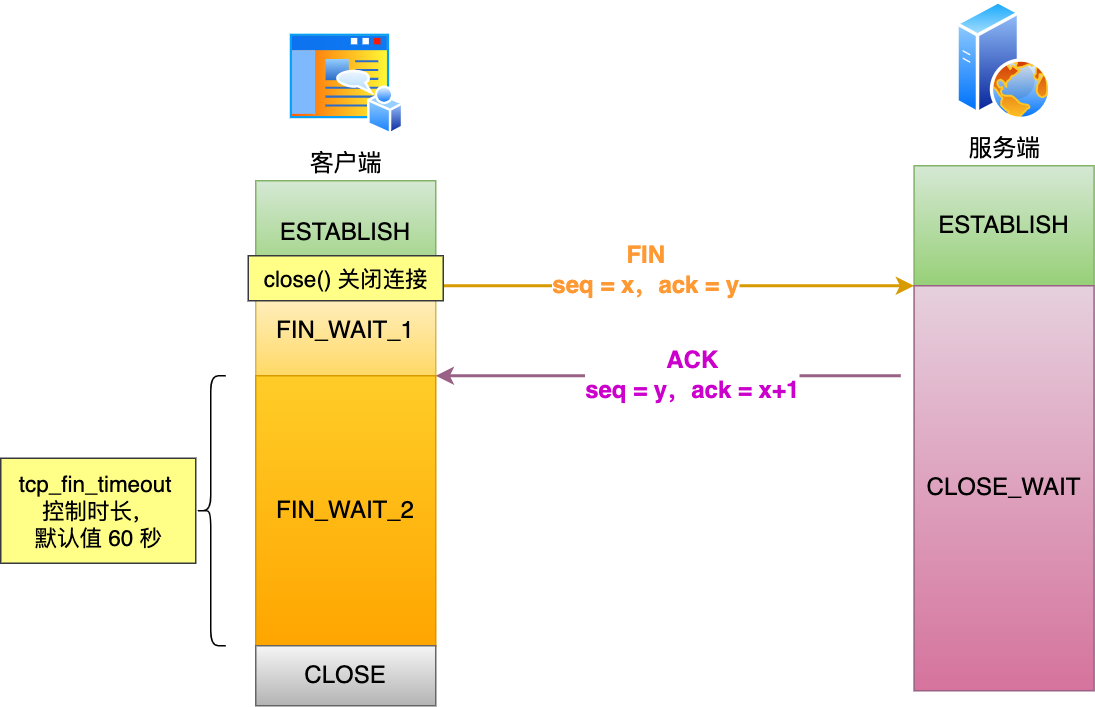
對于 close 函數關閉的連接,由于無法再發送和接收數據,所以FIN_WAIT2?狀態不可以持續太久,而?tcp_fin_timeout?控制了這個狀態下連接的持續時長,默認值是 60 秒。
這意味著對于調用 close 關閉的連接,如果在 60 秒后還沒有收到 FIN 報文,客戶端(主動關閉方)的連接就會直接關閉,如下圖:
 ?
?
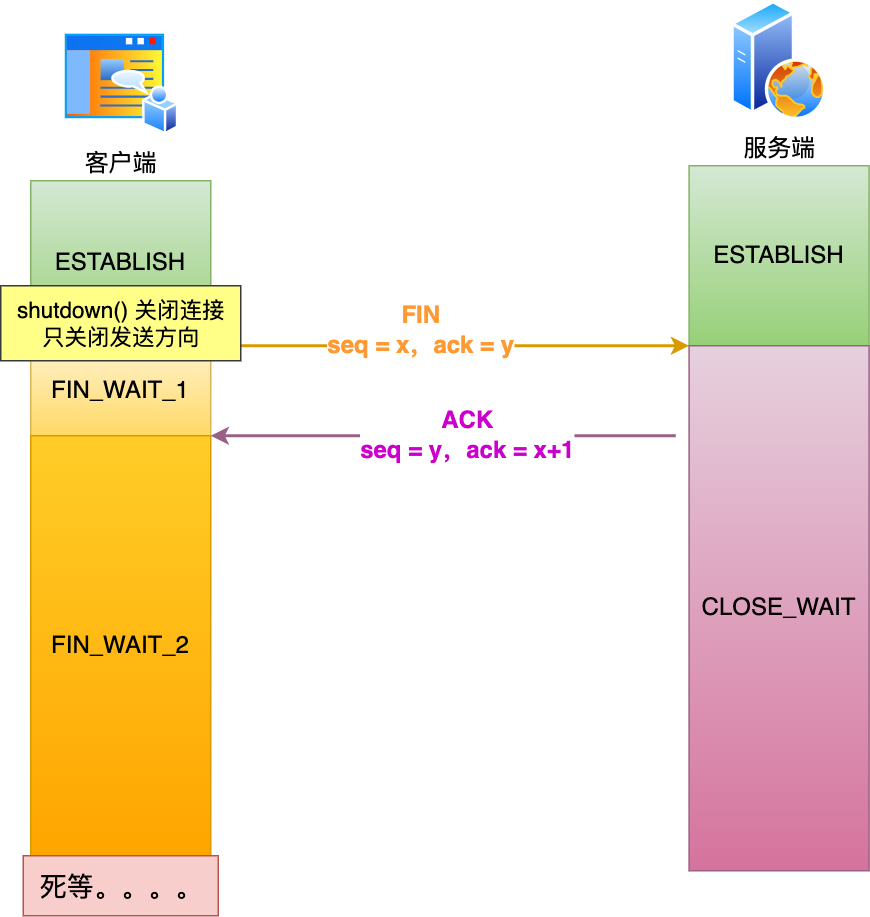
但是注意,如果主動關閉方使用 shutdown 函數關閉連接,指定了只關閉發送方向,而接收方向并沒有關閉,那么意味著主動關閉方還是可以接收數據的。
此時,如果主動關閉方一直沒收到第三次揮手,那么主動關閉方的連接將會一直處于?FIN_WAIT2?狀態(tcp_fin_timeout?無法控制 shutdown 關閉的連接)。如下圖:
 ?
?
第三次揮手丟失了,會發生什么?
當服務端(被動關閉方)收到客戶端(主動關閉方)的 FIN 報文后,內核會自動回復 ACK,同時連接處于?CLOSE_WAIT?狀態,顧名思義,它表示等待應用進程調用 close 函數關閉連接。
此時,內核是沒有權利替代進程關閉連接,必須由進程主動調用 close 函數來觸發服務端發送 FIN 報文。
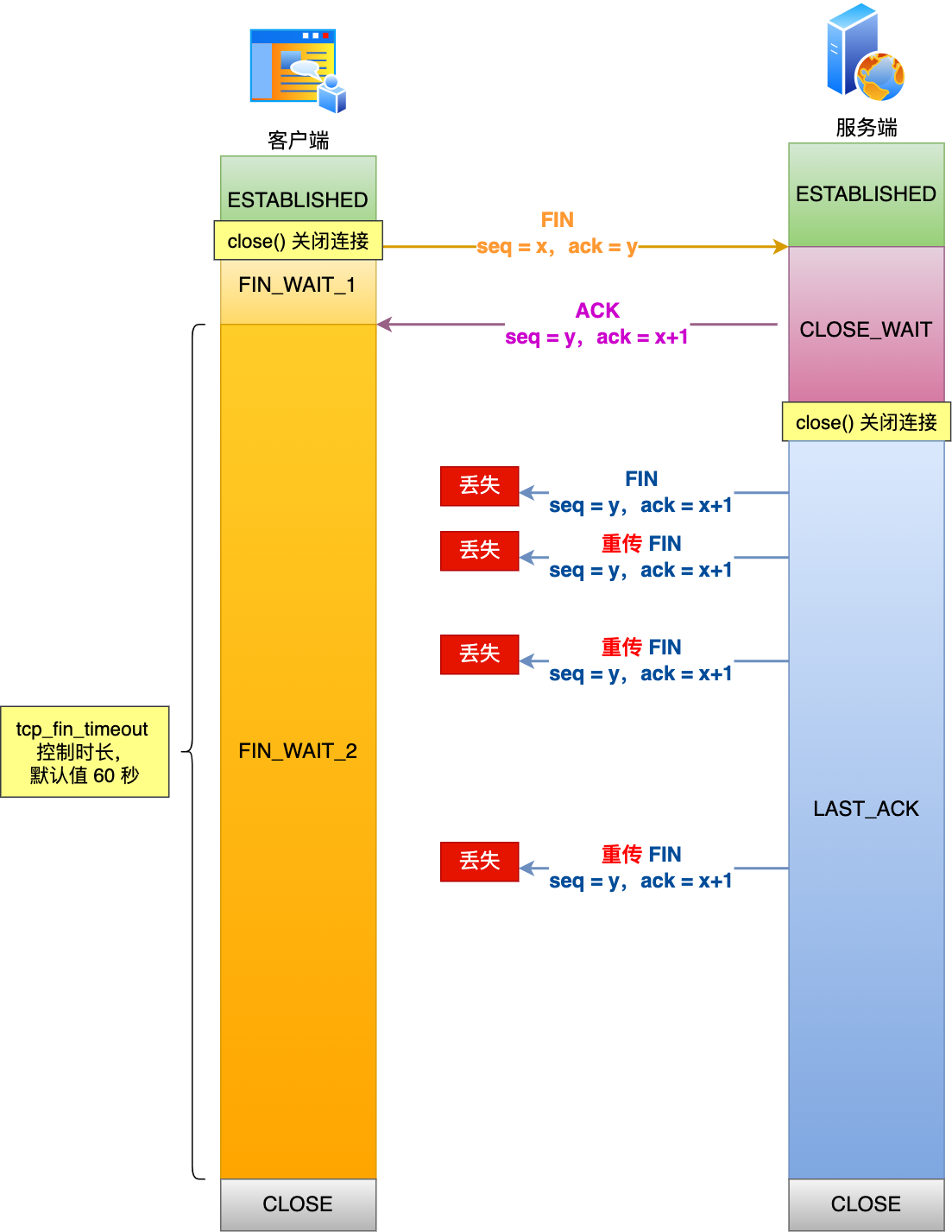
服務端處于 CLOSE_WAIT 狀態時,調用了 close 函數,內核就會發出 FIN 報文,同時連接進入 LAST_ACK 狀態,等待客戶端返回 ACK 來確認連接關閉。
如果遲遲收不到這個 ACK,服務端就會重發 FIN 報文,重發次數仍然由?tcp_orphan_retries 參數控制,這與客戶端重發 FIN 報文的重傳次數控制方式是一樣的。
舉個例子,假設?tcp_orphan_retries = 3,當第三次揮手一直丟失時,發生的過程如下圖:
 ?
?
具體過程:
- 當服務端重傳第三次揮手報文的次數達到了 3 次后,由于 tcp_orphan_retries 為 3,達到了重傳最大次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到客戶端的第四次揮手(ACK報文),那么服務端就會斷開連接。
- 客戶端因為是通過 close 函數關閉連接的,處于 FIN_WAIT_2 狀態是有時長限制的,如果 tcp_fin_timeout 時間內還是沒能收到服務端的第三次揮手(FIN 報文),那么客戶端就會斷開連接。
第四次揮手丟失了,會發生什么?
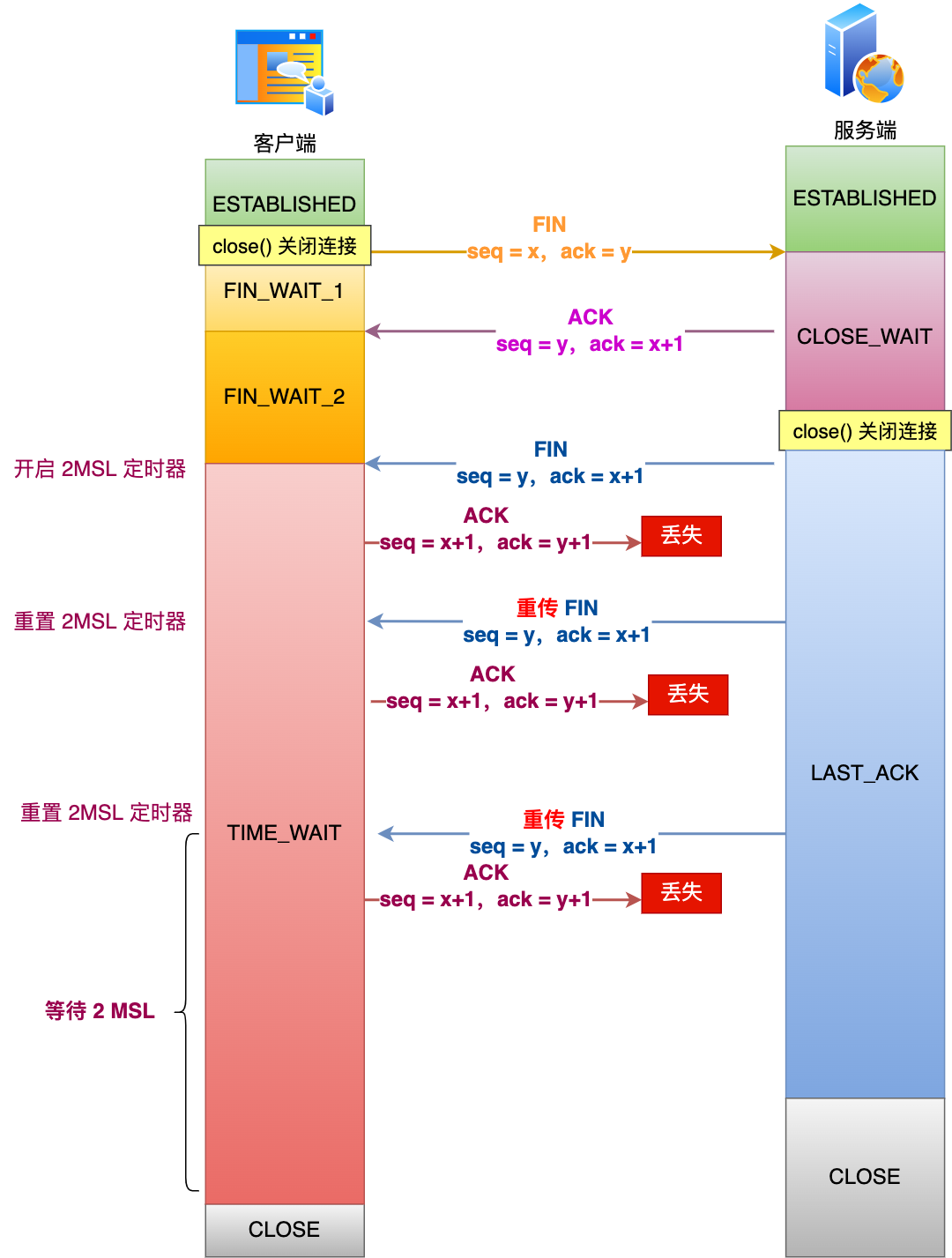
當客戶端收到服務端的第三次揮手的 FIN 報文后,就會回 ACK 報文,也就是第四次揮手,此時客戶端連接進入?TIME_WAIT?狀態。
在 Linux 系統,TIME_WAIT 狀態會持續 2MSL 后才會進入關閉狀態。
然后,服務端(被動關閉方)沒有收到 ACK 報文前,還是處于 LAST_ACK 狀態。
如果第四次揮手的 ACK 報文沒有到達服務端,服務端就會重發 FIN 報文,重發次數仍然由前面介紹過的?tcp_orphan_retries?參數控制。
舉個例子,假設 tcp_orphan_retries 為 2,當第四次揮手一直丟失時,發生的過程如下:
 ?
?
具體過程:
- 當服務端重傳第三次揮手報文達到 2 時,由于 tcp_orphan_retries 為 2, 達到了最大重傳次數,于是再等待一段時間(時間為上一次超時時間的 2 倍),如果還是沒能收到客戶端的第四次揮手(ACK 報文),那么服務端就會斷開連接。
- 客戶端在收到第三次揮手后,就會進入 TIME_WAIT 狀態,開啟時長為 2MSL 的定時器,如果途中再次收到第三次揮手(FIN 報文)后,就會重置定時器,當等待 2MSL 時長后,客戶端就會斷開連接。
為什么 TIME_WAIT 等待的時間是 2MSL?
MSL?是 Maximum Segment Lifetime,報文最大生存時間,它是任何報文在網絡上存在的最長時間,超過這個時間報文將被丟棄。因為 TCP 報文基于是 IP 協議的,而 IP 頭中有一個?TTL?字段,是 IP 數據報可以經過的最大路由數,每經過一個處理他的路由器此值就減 1,當此值為 0 則數據報將被丟棄,同時發送 ICMP 報文通知源主機。
MSL 與 TTL 的區別: MSL 的單位是時間,而 TTL 是經過路由跳數。所以?MSL 應該要大于等于 TTL 消耗為 0 的時間,以確保報文已被自然消亡。
TTL 的值一般是 64,Linux 將 MSL 設置為 30 秒,意味著 Linux 認為數據報文經過 64 個路由器的時間不會超過 30 秒,如果超過了,就認為報文已經消失在網絡中了。
TIME_WAIT 等待 2 倍的 MSL,比較合理的解釋是: 網絡中可能存在來自發送方的數據包,當這些發送方的數據包被接收方處理后又會向對方發送響應,所以一來一回需要等待 2 倍的時間。
比如,如果被動關閉方沒有收到斷開連接的最后的 ACK 報文,就會觸發超時重發?FIN?報文,另一方接收到 FIN 后,會重發 ACK 給被動關閉方, 一來一去正好 2 個 MSL。
可以看到?2MSL時長?這其實是相當于至少允許報文丟失一次。比如,若 ACK 在一個 MSL 內丟失,這樣被動方重發的 FIN 會在第 2 個 MSL 內到達,TIME_WAIT 狀態的連接可以應對。
為什么不是 4 或者 8 MSL 的時長呢?你可以想象一個丟包率達到百分之一的糟糕網絡,連續兩次丟包的概率只有萬分之一,這個概率實在是太小了,忽略它比解決它更具性價比。
2MSL?的時間是從客戶端接收到 FIN 后發送 ACK 開始計時的。如果在 TIME-WAIT 時間內,因為客戶端的 ACK 沒有傳輸到服務端,客戶端又接收到了服務端重發的 FIN 報文,那么?2MSL 時間將重新計時。
在 Linux 系統里?2MSL?默認是?60?秒,那么一個?MSL?也就是?30?秒。Linux 系統停留在 TIME_WAIT 的時間為固定的 60 秒。
其定義在 Linux 內核代碼里的名稱為 TCP_TIMEWAIT_LEN:
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT state, about 60 seconds */
如果要修改 TIME_WAIT 的時間長度,只能修改 Linux 內核代碼里 TCP_TIMEWAIT_LEN 的值,并重新編譯 Linux 內核。
為什么需要 TIME_WAIT 狀態?
主動發起關閉連接的一方,才會有?TIME-WAIT?狀態。
需要 TIME-WAIT 狀態,主要是兩個原因:
- 防止歷史連接中的數據,被后面相同四元組的連接錯誤的接收;
- 保證「被動關閉連接」的一方,能被正確的關閉;
原因一:防止歷史連接中的數據,被后面相同四元組的連接錯誤的接收
為了能更好的理解這個原因,我們先來了解序列號(SEQ)和初始序列號(ISN)。
- 序列號,是 TCP 一個頭部字段,標識了 TCP 發送端到 TCP 接收端的數據流的一個字節,因為 TCP 是面向字節流的可靠協議,為了保證消息的順序性和可靠性,TCP 為每個傳輸方向上的每個字節都賦予了一個編號,以便于傳輸成功后確認、丟失后重傳以及在接收端保證不會亂序。序列號是一個 32 位的無符號數,因此在到達 4G 之后再循環回到 0。
- 初始序列號,在 TCP 建立連接的時候,客戶端和服務端都會各自生成一個初始序列號,它是基于時鐘生成的一個隨機數,來保證每個連接都擁有不同的初始序列號。初始化序列號可被視為一個 32 位的計數器,該計數器的數值每 4 微秒加 1,循環一次需要 4.55 小時。
給大家抓了一個包,下圖中的 Seq 就是序列號,其中紅色框住的分別是客戶端和服務端各自生成的初始序列號。
?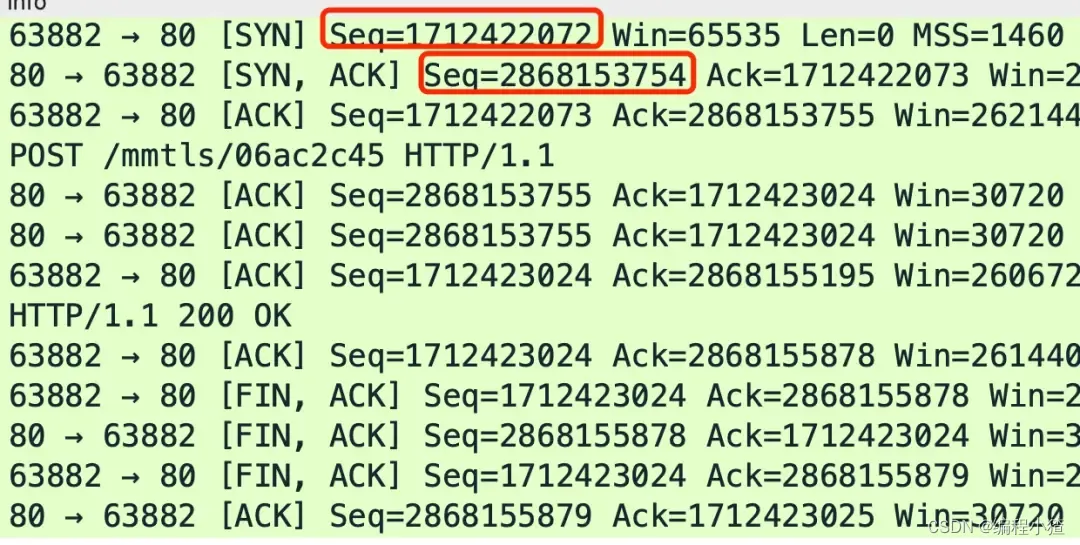
通過前面我們知道,序列號和初始化序列號并不是無限遞增的,會發生回繞為初始值的情況,這意味著無法根據序列號來判斷新老數據。
假設 TIME-WAIT 沒有等待時間或時間過短,被延遲的數據包抵達后會發生什么呢?
?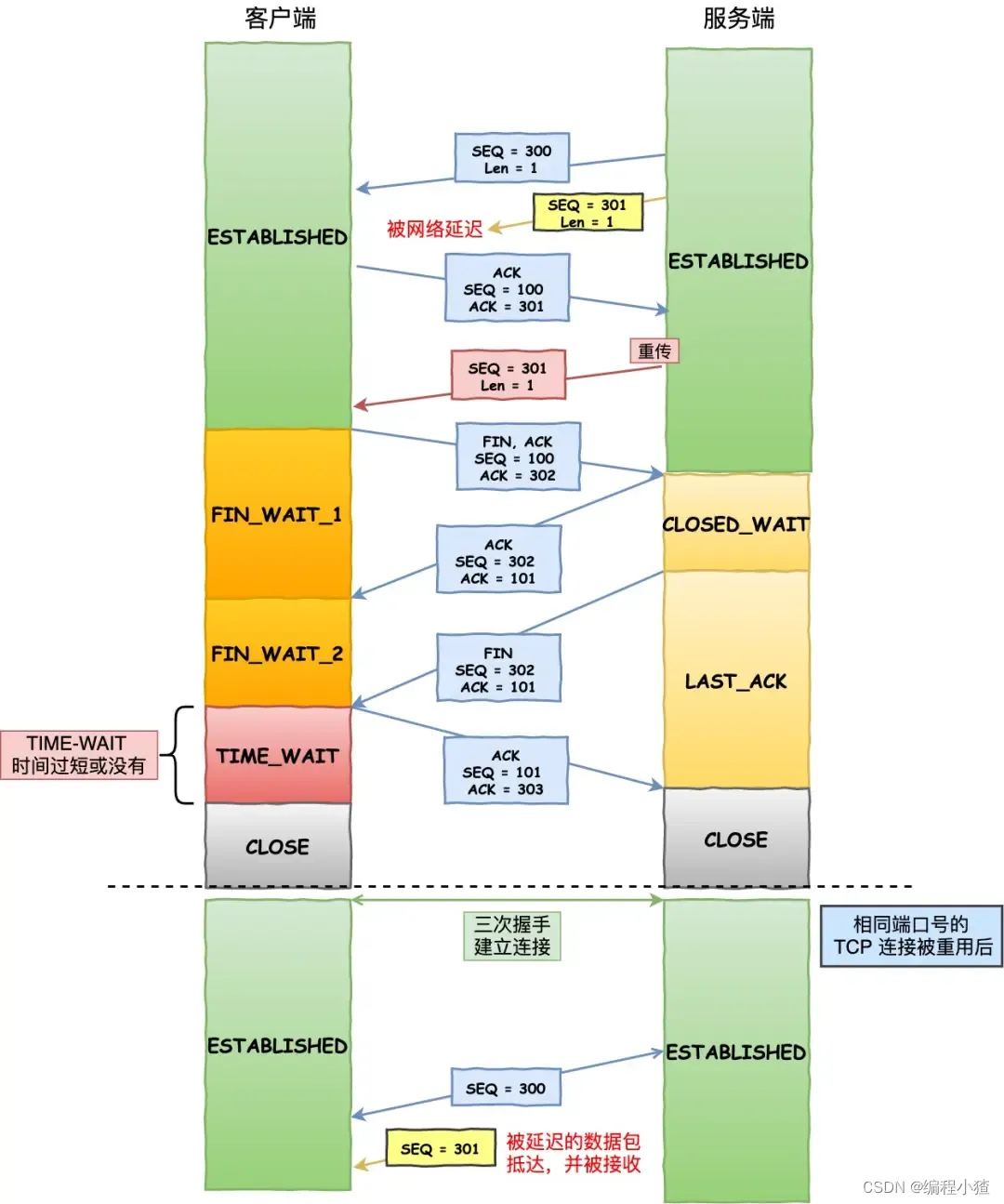
如上圖:
- 服務端在關閉連接之前發送的?
SEQ = 301?報文,被網絡延遲了。 - 接著,服務端以相同的四元組重新打開了新連接,前面被延遲的?
SEQ = 301?這時抵達了客戶端,而且該數據報文的序列號剛好在客戶端接收窗口內,因此客戶端會正常接收這個數據報文,但是這個數據報文是上一個連接殘留下來的,這樣就產生數據錯亂等嚴重的問題。
為了防止歷史連接中的數據,被后面相同四元組的連接錯誤的接收,因此 TCP 設計了 TIME_WAIT 狀態,狀態會持續?2MSL?時長,這個時間足以讓兩個方向上的數據包都被丟棄,使得原來連接的數據包在網絡中都自然消失,再出現的數據包一定都是新建立連接所產生的。
原因二:保證「被動關閉連接」的一方,能被正確的關閉
在 RFC 793 指出 TIME-WAIT 另一個重要的作用是:
TIME-WAIT - represents waiting for enough time to pass to be sure the remote TCP received the acknowledgment of its connection termination request.
也就是說,TIME-WAIT 作用是等待足夠的時間以確保最后的 ACK 能讓被動關閉方接收,從而幫助其正常關閉。
如果客戶端(主動關閉方)最后一次 ACK 報文(第四次揮手)在網絡中丟失了,那么按照 TCP 可靠性原則,服務端(被動關閉方)會重發 FIN 報文。
假設客戶端沒有 TIME_WAIT 狀態,而是在發完最后一次回 ACK 報文就直接進入 CLOSE 狀態,如果該 ACK 報文丟失了,服務端則重傳的 FIN 報文,而這時客戶端已經進入到關閉狀態了,在收到服務端重傳的 FIN 報文后,就會回 RST 報文。
?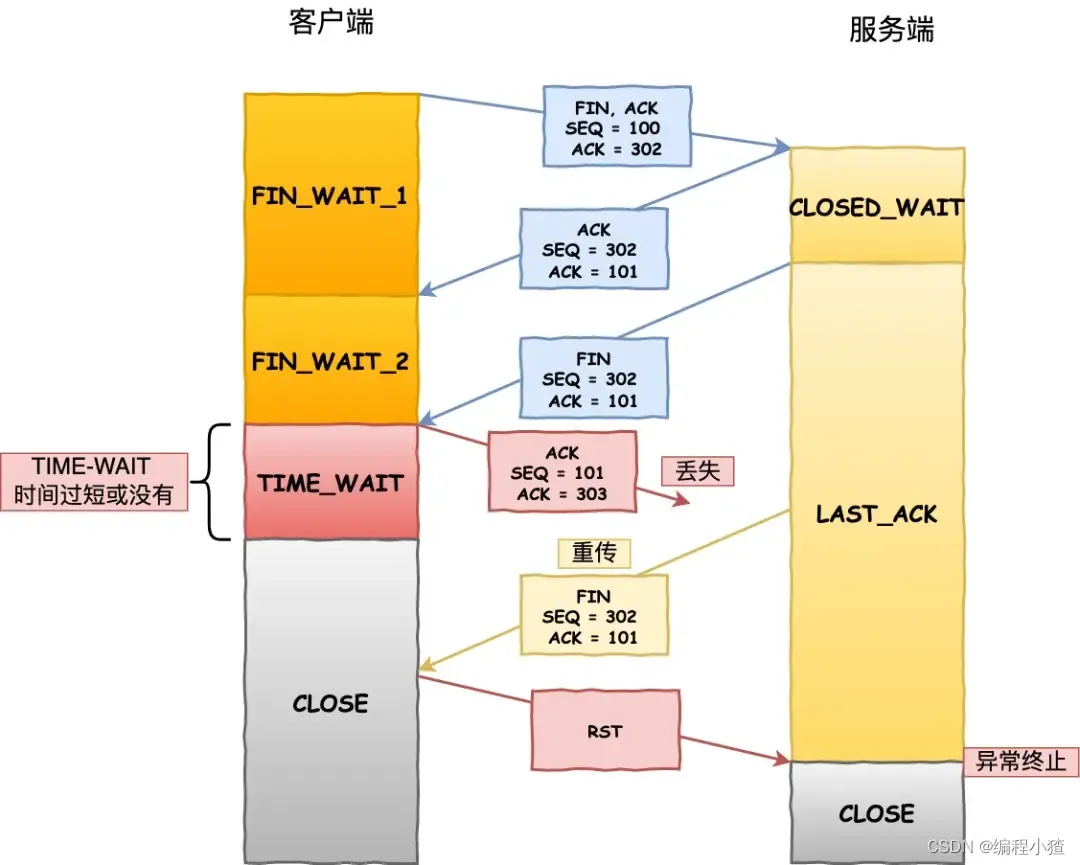
服務端收到這個 RST 并將其解釋為一個錯誤(Connection reset by peer),這對于一個可靠的協議來說不是一個優雅的終止方式。
為了防止這種情況出現,客戶端必須等待足夠長的時間,確保服務端能夠收到 ACK,如果服務端沒有收到 ACK,那么就會觸發 TCP 重傳機制,服務端會重新發送一個 FIN,這樣一去一來剛好兩個 MSL 的時間。
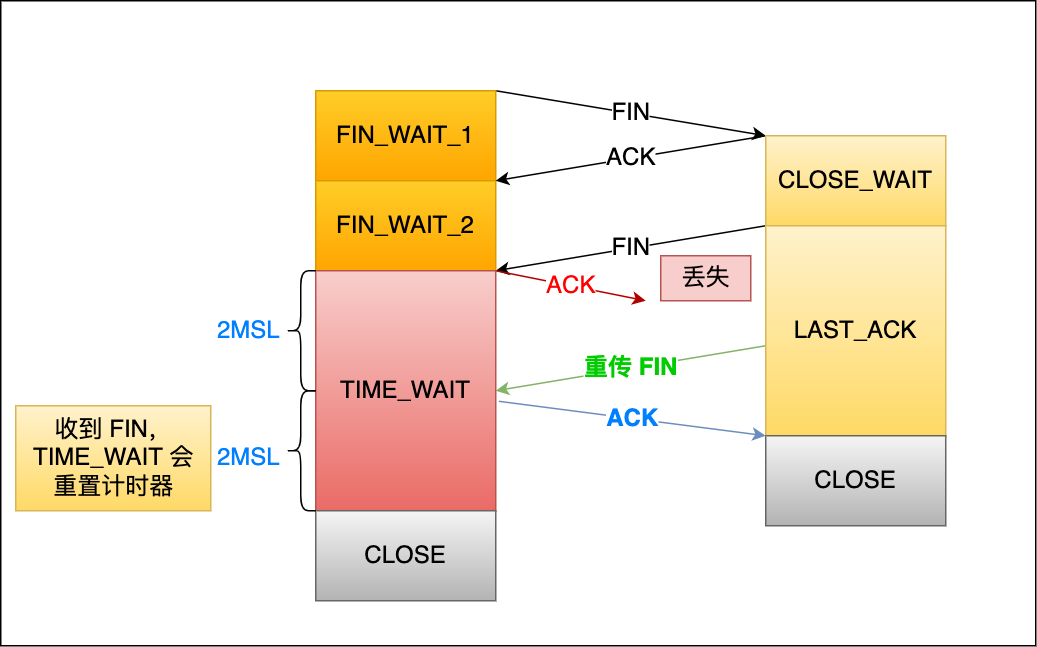 ?
?
客戶端在收到服務端重傳的 FIN 報文時,TIME_WAIT 狀態的等待時間,會重置回 2MSL。
TIME_WAIT 過多有什么危害?
過多的 TIME-WAIT 狀態主要的危害有兩種:
- 第一是占用系統資源,比如文件描述符、內存資源、CPU 資源、線程資源等;
- 第二是占用端口資源,端口資源也是有限的,一般可以開啟的端口為?
32768~61000,也可以通過?net.ipv4.ip_local_port_range參數指定范圍。
客戶端和服務端 TIME_WAIT 過多,造成的影響是不同的。
如果客戶端(主動發起關閉連接方)的 TIME_WAIT 狀態過多,占滿了所有端口資源,那么就無法對「目的 IP+ 目的 PORT」都一樣的服務端發起連接了,但是被使用的端口,還是可以繼續對另外一個服務端發起連接的。具體可以看我這篇文章:客戶端的端口可以重復使用嗎?(opens new window)
因此,客戶端(發起連接方)都是和「目的 IP+ 目的 PORT 」都一樣的服務端建立連接的話,當客戶端的 TIME_WAIT 狀態連接過多的話,就會受端口資源限制,如果占滿了所有端口資源,那么就無法再跟「目的 IP+ 目的 PORT」都一樣的服務端建立連接了。
不過,即使是在這種場景下,只要連接的是不同的服務端,端口是可以重復使用的,所以客戶端還是可以向其他服務端發起連接的,這是因為內核在定位一個連接的時候,是通過四元組(源IP、源端口、目的IP、目的端口)信息來定位的,并不會因為客戶端的端口一樣,而導致連接沖突。
如果服務端(主動發起關閉連接方)的 TIME_WAIT 狀態過多,并不會導致端口資源受限,因為服務端只監聽一個端口,而且由于一個四元組唯一確定一個 TCP 連接,因此理論上服務端可以建立很多連接,但是 TCP 連接過多,會占用系統資源,比如文件描述符、內存資源、CPU 資源、線程資源等。
如何優化 TIME_WAIT?
這里給出優化 TIME-WAIT 的幾個方式,都是有利有弊:
- 打開 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_timestamps 選項;
- net.ipv4.tcp_max_tw_buckets
- 程序中使用 SO_LINGER ,應用強制使用 RST 關閉。
方式一:net.ipv4.tcp_tw_reuse 和 tcp_timestamps
如下的 Linux 內核參數開啟后,則可以復用處于 TIME_WAIT 的 socket 為新的連接所用。
有一點需要注意的是,tcp_tw_reuse 功能只能用客戶端(連接發起方),因為開啟了該功能,在調用 connect() 函數時,內核會隨機找一個 time_wait 狀態超過 1 秒的連接給新的連接復用。
net.ipv4.tcp_tw_reuse = 1
使用這個選項,還有一個前提,需要打開對 TCP 時間戳的支持,即
net.ipv4.tcp_timestamps=1(默認即為 1)
這個時間戳的字段是在 TCP 頭部的「選項」里,它由一共 8 個字節表示時間戳,其中第一個 4 字節字段用來保存發送該數據包的時間,第二個 4 字節字段用來保存最近一次接收對方發送到達數據的時間。
由于引入了時間戳,我們在前面提到的?2MSL?問題就不復存在了,因為重復的數據包會因為時間戳過期被自然丟棄。
方式二:net.ipv4.tcp_max_tw_buckets
這個值默認為 18000,當系統中處于 TIME_WAIT 的連接一旦超過這個值時,系統就會將后面的 TIME_WAIT 連接狀態重置,這個方法比較暴力。
方式三:程序中使用 SO_LINGER
我們可以通過設置 socket 選項,來設置調用 close 關閉連接行為。
struct linger so_linger;
so_linger.l_onoff = 1;
so_linger.l_linger = 0;
setsockopt(s, SOL_SOCKET, SO_LINGER, &so_linger,sizeof(so_linger));
如果l_onoff為非 0, 且l_linger值為 0,那么調用close后,會立該發送一個RST標志給對端,該 TCP 連接將跳過四次揮手,也就跳過了TIME_WAIT狀態,直接關閉。
但這為跨越TIME_WAIT狀態提供了一個可能,不過是一個非常危險的行為,不值得提倡。
前面介紹的方法都是試圖越過?TIME_WAIT狀態的,這樣其實不太好。雖然 TIME_WAIT 狀態持續的時間是有一點長,顯得很不友好,但是它被設計來就是用來避免發生亂七八糟的事情。
《UNIX網絡編程》一書中卻說道:TIME_WAIT 是我們的朋友,它是有助于我們的,不要試圖避免這個狀態,而是應該弄清楚它。
如果服務端要避免過多的 TIME_WAIT 狀態的連接,就永遠不要主動斷開連接,讓客戶端去斷開,由分布在各處的客戶端去承受 TIME_WAIT。
服務器出現大量 TIME_WAIT 狀態的原因有哪些?
首先要知道 TIME_WAIT 狀態是主動關閉連接方才會出現的狀態,所以如果服務器出現大量的 TIME_WAIT 狀態的 TCP 連接,就是說明服務器主動斷開了很多 TCP 連接。
問題來了,什么場景下服務端會主動斷開連接呢?
- 第一個場景:HTTP 沒有使用長連接
- 第二個場景:HTTP 長連接超時
- 第三個場景:HTTP 長連接的請求數量達到上限
接下來,分別介紹下。
第一個場景:HTTP 沒有使用長連接
我們先來看看 HTTP 長連接(Keep-Alive)機制是怎么開啟的。
在 HTTP/1.0 中默認是關閉的,如果瀏覽器要開啟 Keep-Alive,它必須在請求的 header 中添加:
Connection: Keep-Alive
然后當服務器收到請求,作出回應的時候,它也被添加到響應中 header 里:
Connection: Keep-Alive
這樣做,TCP 連接就不會中斷,而是保持連接。當客戶端發送另一個請求時,它會使用同一個 TCP 連接。這一直繼續到客戶端或服務器端提出斷開連接。
從 HTTP/1.1 開始, 就默認是開啟了 Keep-Alive,現在大多數瀏覽器都默認是使用 HTTP/1.1,所以 Keep-Alive 都是默認打開的。一旦客戶端和服務端達成協議,那么長連接就建立好了。
如果要關閉 HTTP Keep-Alive,需要在 HTTP 請求或者響應的 header 里添加?Connection:close?信息,也就是說,只要客戶端和服務端任意一方的 HTTP header 中有?Connection:close?信息,那么就無法使用 HTTP 長連接的機制。
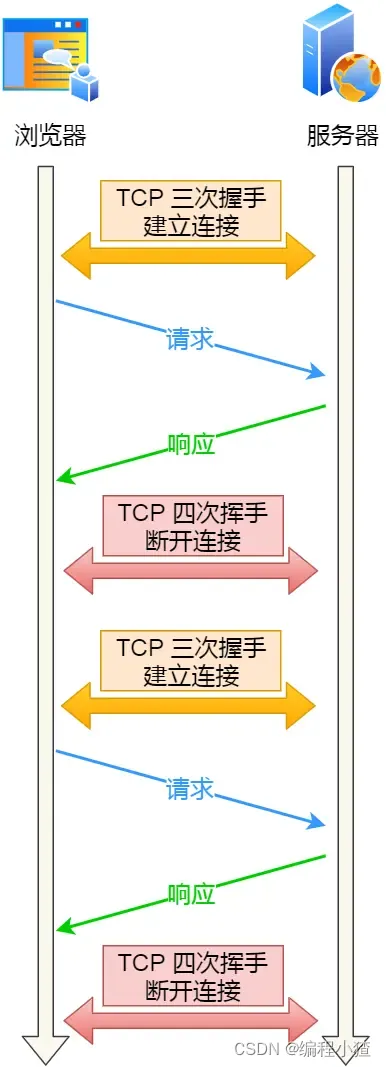
關閉 HTTP 長連接機制后,每次請求都要經歷這樣的過程:建立 TCP -> 請求資源 -> 響應資源 -> 釋放連接,那么此方式就是?HTTP 短連接,如下圖:
?
在前面我們知道,只要任意一方的 HTTP header 中有?Connection:close?信息,就無法使用 HTTP 長連接機制,這樣在完成一次 HTTP 請求/處理后,就會關閉連接。
問題來了,這時候是客戶端還是服務端主動關閉連接呢?
在 RFC 文檔中,并沒有明確由誰來關閉連接,請求和響應的雙方都可以主動關閉 TCP 連接。
不過,根據大多數 Web 服務的實現,不管哪一方禁用了 HTTP Keep-Alive,都是由服務端主動關閉連接,那么此時服務端上就會出現 TIME_WAIT 狀態的連接。
客戶端禁用了 HTTP Keep-Alive,服務端開啟 HTTP Keep-Alive,誰是主動關閉方?
當客戶端禁用了 HTTP Keep-Alive,這時候 HTTP 請求的 header 就會有?Connection:close?信息,這時服務端在發完 HTTP 響應后,就會主動關閉連接。
為什么要這么設計呢?HTTP 是請求-響應模型,發起方一直是客戶端,HTTP Keep-Alive 的初衷是為客戶端后續的請求重用連接,如果我們在某次 HTTP 請求-響應模型中,請求的 header 定義了?connection:close?信息,那不再重用這個連接的時機就只有在服務端了,所以我們在 HTTP 請求-響應這個周期的「末端」關閉連接是合理的。
客戶端開啟了 HTTP Keep-Alive,服務端禁用了 HTTP Keep-Alive,誰是主動關閉方?
當客戶端開啟了 HTTP Keep-Alive,而服務端禁用了 HTTP Keep-Alive,這時服務端在發完 HTTP 響應后,服務端也會主動關閉連接。
為什么要這么設計呢?在服務端主動關閉連接的情況下,只要調用一次 close() 就可以釋放連接,剩下的工作由內核 TCP 棧直接進行了處理,整個過程只有一次 syscall;如果是要求 客戶端關閉,則服務端在寫完最后一個 response 之后需要把這個 socket 放入 readable 隊列,調用 select / epoll 去等待事件;然后調用一次 read() 才能知道連接已經被關閉,這其中是兩次 syscall,多一次用戶態程序被激活執行,而且 socket 保持時間也會更長。
因此,當服務端出現大量的 TIME_WAIT 狀態連接的時候,可以排查下是否客戶端和服務端都開啟了 HTTP Keep-Alive,因為任意一方沒有開啟 HTTP Keep-Alive,都會導致服務端在處理完一個 HTTP 請求后,就主動關閉連接,此時服務端上就會出現大量的 TIME_WAIT 狀態的連接。
針對這個場景下,解決的方式也很簡單,讓客戶端和服務端都開啟 HTTP Keep-Alive 機制。
第二個場景:HTTP 長連接超時
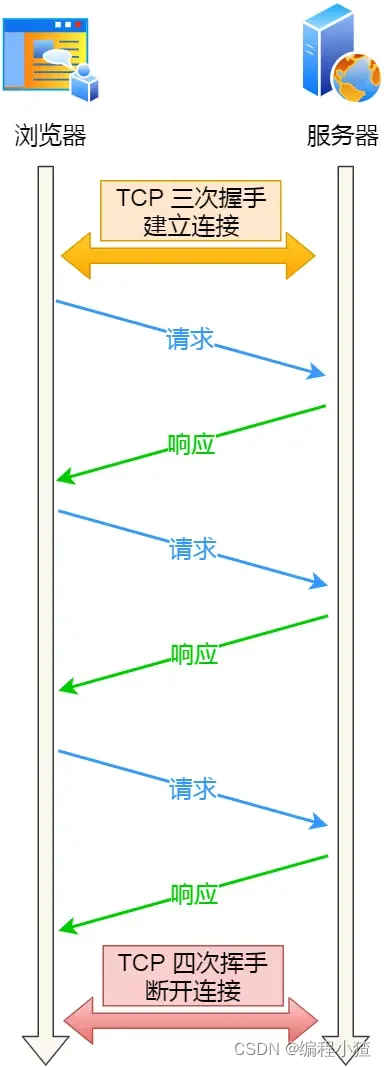
HTTP 長連接的特點是,只要任意一端沒有明確提出斷開連接,則保持 TCP 連接狀態。
HTTP 長連接可以在同一個 TCP 連接上接收和發送多個 HTTP 請求/應答,避免了連接建立和釋放的開銷。
?
可能有的同學會問,如果使用了 HTTP 長連接,如果客戶端完成一個 HTTP 請求后,就不再發起新的請求,此時這個 TCP 連接一直占用著不是挺浪費資源的嗎?
對沒錯,所以為了避免資源浪費的情況,web 服務軟件一般都會提供一個參數,用來指定 HTTP 長連接的超時時間,比如 nginx 提供的 keepalive_timeout 參數。
假設設置了 HTTP 長連接的超時時間是 60 秒,nginx 就會啟動一個「定時器」,如果客戶端在完后一個 HTTP 請求后,在 60 秒內都沒有再發起新的請求,定時器的時間一到,nginx 就會觸發回調函數來關閉該連接,那么此時服務端上就會出現 TIME_WAIT 狀態的連接。
?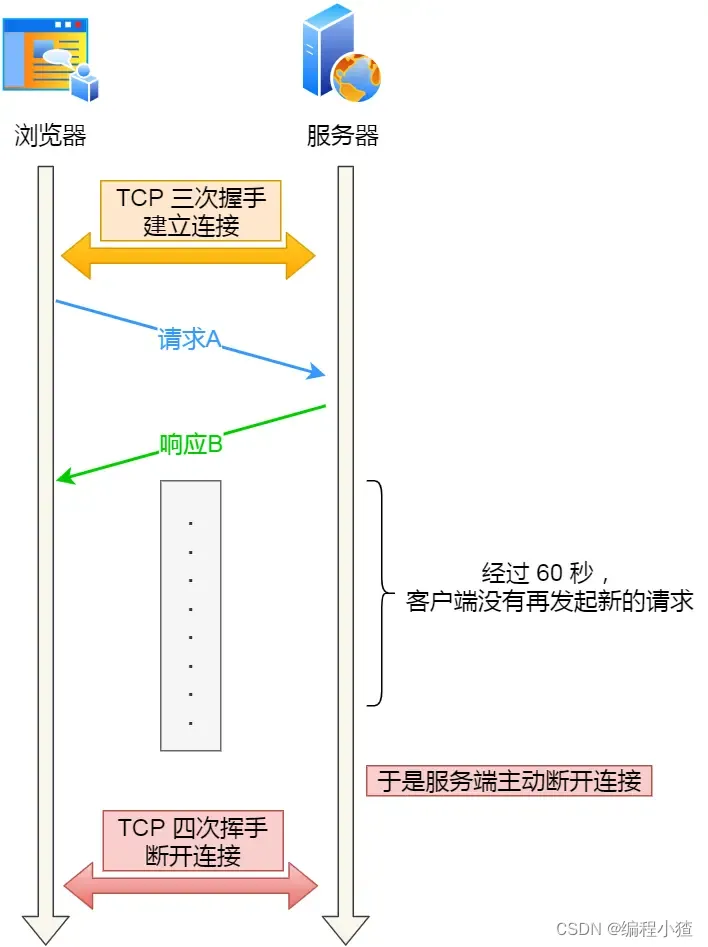
當服務端出現大量 TIME_WAIT 狀態的連接時,如果現象是有大量的客戶端建立完 TCP 連接后,很長一段時間沒有發送數據,那么大概率就是因為 HTTP 長連接超時,導致服務端主動關閉連接,產生大量處于 TIME_WAIT 狀態的連接。
可以往網絡問題的方向排查,比如是否是因為網絡問題,導致客戶端發送的數據一直沒有被服務端接收到,以至于 HTTP 長連接超時。
第三個場景:HTTP 長連接的請求數量達到上限
Web 服務端通常會有個參數,來定義一條 HTTP 長連接上最大能處理的請求數量,當超過最大限制時,就會主動關閉連接。
比如 nginx 的 keepalive_requests 這個參數,這個參數是指一個 HTTP 長連接建立之后,nginx 就會為這個連接設置一個計數器,記錄這個 HTTP 長連接上已經接收并處理的客戶端請求的數量。如果達到這個參數設置的最大值時,則 nginx 會主動關閉這個長連接,那么此時服務端上就會出現 TIME_WAIT 狀態的連接。
keepalive_requests 參數的默認值是 100 ,意味著每個 HTTP 長連接最多只能跑 100 次請求,這個參數往往被大多數人忽略,因為當 QPS (每秒請求數) 不是很高時,默認值 100 湊合夠用。
但是,對于一些 QPS 比較高的場景,比如超過 10000 QPS,甚至達到 30000 , 50000 甚至更高,如果 keepalive_requests 參數值是 100,這時候就 nginx 就會很頻繁地關閉連接,那么此時服務端上就會出大量的 TIME_WAIT 狀態。
針對這個場景下,解決的方式也很簡單,調大 nginx 的 keepalive_requests 參數就行。
服務器出現大量 CLOSE_WAIT 狀態的原因有哪些?
CLOSE_WAIT 狀態是「被動關閉方」才會有的狀態,而且如果「被動關閉方」沒有調用 close 函數關閉連接,那么就無法發出 FIN 報文,從而無法使得 CLOSE_WAIT 狀態的連接轉變為 LAST_ACK 狀態。
所以,當服務端出現大量 CLOSE_WAIT 狀態的連接的時候,說明服務端的程序沒有調用 close 函數關閉連接。
那什么情況會導致服務端的程序沒有調用 close 函數關閉連接?這時候通常需要排查代碼。
我們先來分析一個普通的 TCP 服務端的流程:
- 創建服務端 socket,bind 綁定端口、listen 監聽端口
- 將服務端 socket 注冊到 epoll
- epoll_wait 等待連接到來,連接到來時,調用 accpet 獲取已連接的 socket
- 將已連接的 socket 注冊到 epoll
- epoll_wait 等待事件發生
- 對方連接關閉時,我方調用 close
可能導致服務端沒有調用 close 函數的原因,如下。
第一個原因:第 2 步沒有做,沒有將服務端 socket 注冊到 epoll,這樣有新連接到來時,服務端沒辦法感知這個事件,也就無法獲取到已連接的 socket,那服務端自然就沒機會對 socket 調用 close 函數了。
不過這種原因發生的概率比較小,這種屬于明顯的代碼邏輯 bug,在前期 read view 階段就能發現的了。
第二個原因: 第 3 步沒有做,有新連接到來時沒有調用 accpet 獲取該連接的 socket,導致當有大量的客戶端主動斷開了連接,而服務端沒機會對這些 socket 調用 close 函數,從而導致服務端出現大量 CLOSE_WAIT 狀態的連接。
發生這種情況可能是因為服務端在執行 accpet 函數之前,代碼卡在某一個邏輯或者提前拋出了異常。
第三個原因:第 4 步沒有做,通過 accpet 獲取已連接的 socket 后,沒有將其注冊到 epoll,導致后續收到 FIN 報文的時候,服務端沒辦法感知這個事件,那服務端就沒機會調用 close 函數了。
發生這種情況可能是因為服務端在將已連接的 socket 注冊到 epoll 之前,代碼卡在某一個邏輯或者提前拋出了異常。之前看到過別人解決 close_wait 問題的實踐文章,感興趣的可以看看:一次 Netty 代碼不健壯導致的大量 CLOSE_WAIT 連接原因分析(opens new window)
第四個原因:第 6 步沒有做,當發現客戶端關閉連接后,服務端沒有執行 close 函數,可能是因為代碼漏處理,或者是在執行 close 函數之前,代碼卡在某一個邏輯,比如發生死鎖等等。
可以發現,當服務端出現大量 CLOSE_WAIT 狀態的連接的時候,通常都是代碼的問題,這時候我們需要針對具體的代碼一步一步的進行排查和定位,主要分析的方向就是服務端為什么沒有調用 close。
如果已經建立了連接,但是客戶端突然出現故障了怎么辦?
客戶端出現故障指的是客戶端的主機發生了宕機,或者斷電的場景。發生這種情況的時候,如果服務端一直不會發送數據給客戶端,那么服務端是永遠無法感知到客戶端宕機這個事件的,也就是服務端的 TCP 連接將一直處于?ESTABLISH?狀態,占用著系統資源。
為了避免這種情況,TCP 搞了個保活機制。這個機制的原理是這樣的:
定義一個時間段,在這個時間段內,如果沒有任何連接相關的活動,TCP 保活機制會開始作用,每隔一個時間間隔,發送一個探測報文,該探測報文包含的數據非常少,如果連續幾個探測報文都沒有得到響應,則認為當前的 TCP 連接已經死亡,系統內核將錯誤信息通知給上層應用程序。
在 Linux 內核可以有對應的參數可以設置保活時間、保活探測的次數、保活探測的時間間隔,以下都為默認值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
- tcp_keepalive_time=7200:表示保活時間是 7200 秒(2小時),也就 2 小時內如果沒有任何連接相關的活動,則會啟動保活機制
- tcp_keepalive_intvl=75:表示每次檢測間隔 75 秒;
- tcp_keepalive_probes=9:表示檢測 9 次無響應,認為對方是不可達的,從而中斷本次的連接。
也就是說在 Linux 系統中,最少需要經過 2 小時 11 分 15 秒才可以發現一個「死亡」連接。
?
注意,應用程序若想使用 TCP 保活機制需要通過 socket 接口設置?SO_KEEPALIVE?選項才能夠生效,如果沒有設置,那么就無法使用 TCP 保活機制。
如果開啟了 TCP 保活,需要考慮以下幾種情況:
-
第一種,對端程序是正常工作的。當 TCP 保活的探測報文發送給對端, 對端會正常響應,這樣?TCP 保活時間會被重置,等待下一個 TCP 保活時間的到來。
-
第二種,對端主機宕機并重啟。當 TCP 保活的探測報文發送給對端后,對端是可以響應的,但由于沒有該連接的有效信息,會產生一個 RST 報文,這樣很快就會發現 TCP 連接已經被重置。
-
第三種,是對端主機宕機(注意不是進程崩潰,進程崩潰后操作系統在回收進程資源的時候,會發送 FIN 報文,而主機宕機則是無法感知的,所以需要 TCP 保活機制來探測對方是不是發生了主機宕機),或對端由于其他原因導致報文不可達。當 TCP 保活的探測報文發送給對端后,石沉大海,沒有響應,連續幾次,達到保活探測次數后,TCP 會報告該 TCP 連接已經死亡。
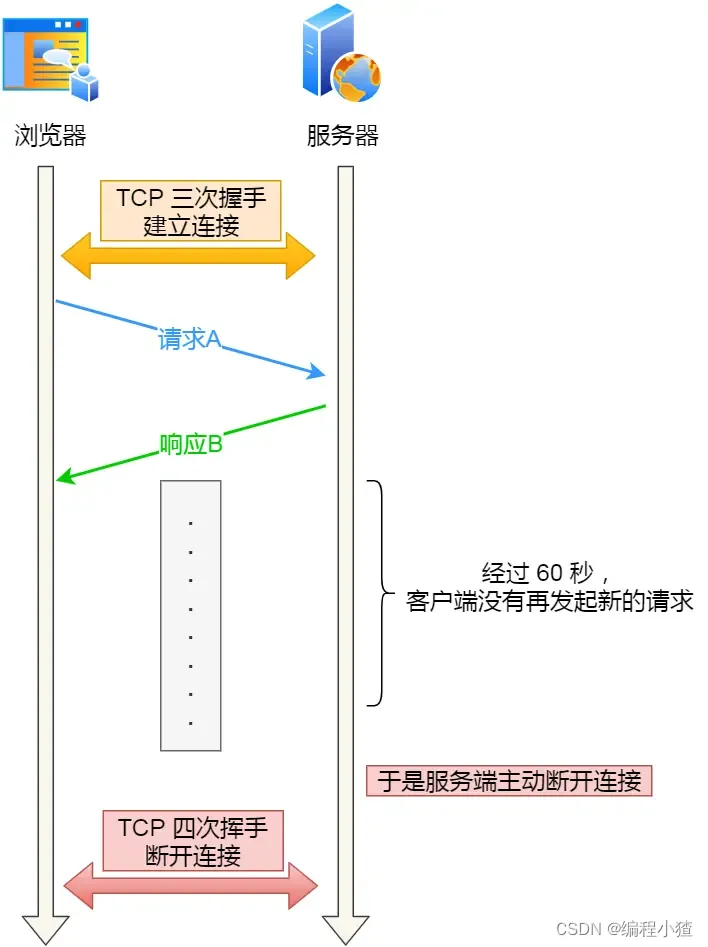
TCP 保活的這個機制檢測的時間是有點長,我們可以自己在應用層實現一個心跳機制。
比如,web 服務軟件一般都會提供?keepalive_timeout?參數,用來指定 HTTP 長連接的超時時間。如果設置了 HTTP 長連接的超時時間是 60 秒,web 服務軟件就會啟動一個定時器,如果客戶端在完成一個 HTTP 請求后,在 60 秒內都沒有再發起新的請求,定時器的時間一到,就會觸發回調函數來釋放該連接。
?
如果已經建立了連接,但是服務端的進程崩潰會發生什么?
TCP 的連接信息是由內核維護的,所以當服務端的進程崩潰后,內核需要回收該進程的所有 TCP 連接資源,于是內核會發送第一次揮手 FIN 報文,后續的揮手過程也都是在內核完成,并不需要進程的參與,所以即使服務端的進程退出了,還是能與客戶端完成 TCP 四次揮手的過程。
我自己做了個實驗,使用 kill -9 來模擬進程崩潰的情況,發現在 kill 掉進程后,服務端會發送 FIN 報文,與客戶端進行四次揮手。
TIP
關于進程崩潰和主機宕機的區別,可以參考這篇:TCP 連接,一端斷電和進程崩潰有什么區別?(opens new window)
還有一個類似的問題:「拔掉網線后, 原本的 TCP 連接還存在嗎?」,具體可以看這篇:拔掉網線后, 原本的 TCP 連接還存在嗎?(opens new window)
Socket 編程
針對 TCP 應該如何 Socket 編程?
?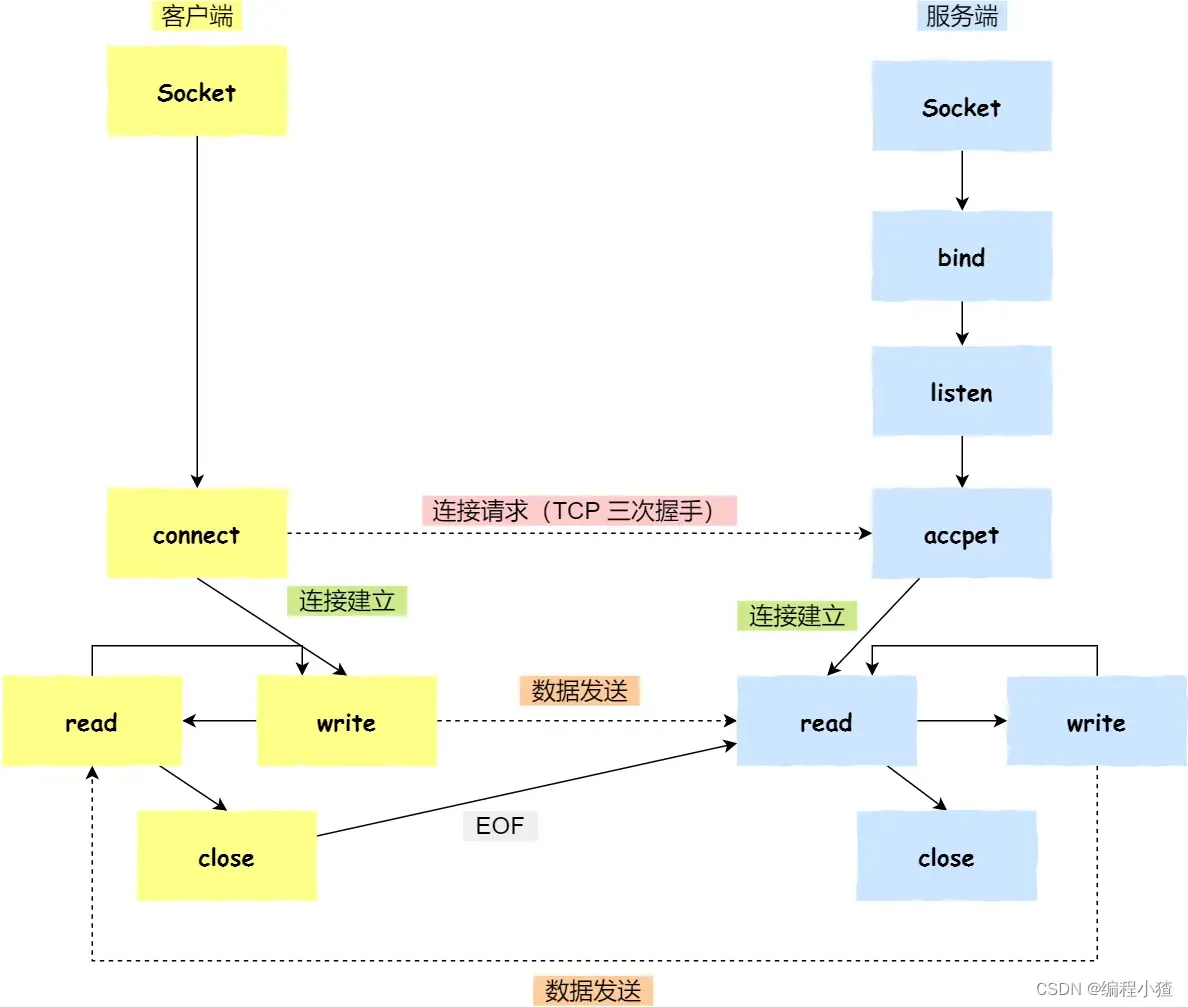
- 服務端和客戶端初始化?
socket,得到文件描述符; - 服務端調用?
bind,將 socket 綁定在指定的 IP 地址和端口; - 服務端調用?
listen,進行監聽; - 服務端調用?
accept,等待客戶端連接; - 客戶端調用?
connect,向服務端的地址和端口發起連接請求; - 服務端?
accept?返回用于傳輸的?socket?的文件描述符; - 客戶端調用?
write?寫入數據;服務端調用?read?讀取數據; - 客戶端斷開連接時,會調用?
close,那么服務端?read?讀取數據的時候,就會讀取到了?EOF,待處理完數據后,服務端調用?close,表示連接關閉。
這里需要注意的是,服務端調用?accept?時,連接成功了會返回一個已完成連接的 socket,后續用來傳輸數據。
所以,監聽的 socket 和真正用來傳送數據的 socket,是「兩個」 socket,一個叫作監聽 socket,一個叫作已完成連接 socket。
成功連接建立之后,雙方開始通過 read 和 write 函數來讀寫數據,就像往一個文件流里面寫東西一樣。
listen 時候參數 backlog 的意義?
Linux內核中會維護兩個隊列:
- 半連接隊列(SYN 隊列):接收到一個 SYN 建立連接請求,處于 SYN_RCVD 狀態;
- 全連接隊列(Accpet 隊列):已完成 TCP 三次握手過程,處于 ESTABLISHED 狀態;
?
int listen (int socketfd, int backlog)
- 參數一 socketfd 為 socketfd 文件描述符
- 參數二 backlog,這參數在歷史版本有一定的變化
在早期 Linux 內核 backlog 是 SYN 隊列大小,也就是未完成的隊列大小。
在 Linux 內核 2.2 之后,backlog 變成 accept 隊列,也就是已完成連接建立的隊列長度,所以現在通常認為 backlog 是 accept 隊列。
但是上限值是內核參數 somaxconn 的大小,也就說 accpet 隊列長度 = min(backlog, somaxconn)。
想詳細了解 TCP 半連接隊列和全連接隊列,可以看這篇:TCP 半連接隊列和全連接隊列滿了會發生什么?又該如何應對?(opens new window)
accept 發生在三次握手的哪一步?
我們先看看客戶端連接服務端時,發送了什么?
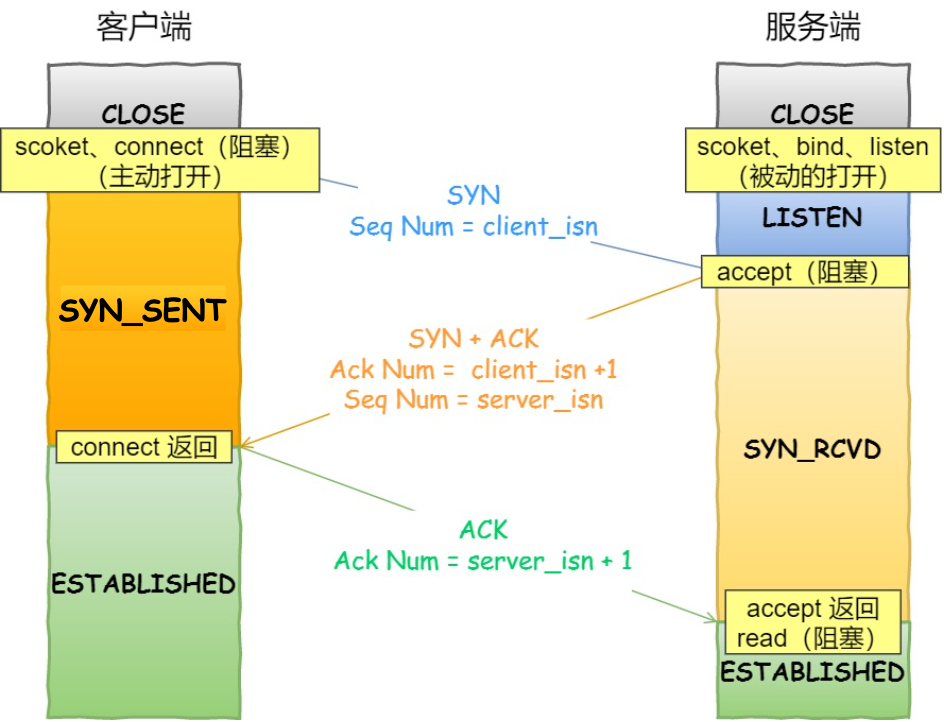 ?
?
- 客戶端的協議棧向服務端發送了 SYN 包,并告訴服務端當前發送序列號 client_isn,客戶端進入 SYN_SENT 狀態;
- 服務端的協議棧收到這個包之后,和客戶端進行 ACK 應答,應答的值為 client_isn+1,表示對 SYN 包 client_isn 的確認,同時服務端也發送一個 SYN 包,告訴客戶端當前我的發送序列號為 server_isn,服務端進入 SYN_RCVD 狀態;
- 客戶端協議棧收到 ACK 之后,使得應用程序從?
connect?調用返回,表示客戶端到服務端的單向連接建立成功,客戶端的狀態為 ESTABLISHED,同時客戶端協議棧也會對服務端的 SYN 包進行應答,應答數據為 server_isn+1; - ACK 應答包到達服務端后,服務端的 TCP 連接進入 ESTABLISHED 狀態,同時服務端協議棧使得?
accept?阻塞調用返回,這個時候服務端到客戶端的單向連接也建立成功。至此,客戶端與服務端兩個方向的連接都建立成功。
從上面的描述過程,我們可以得知客戶端 connect 成功返回是在第二次握手,服務端 accept 成功返回是在三次握手成功之后。
客戶端調用 close 了,連接是斷開的流程是什么?
我們看看客戶端主動調用了?close,會發生什么?
?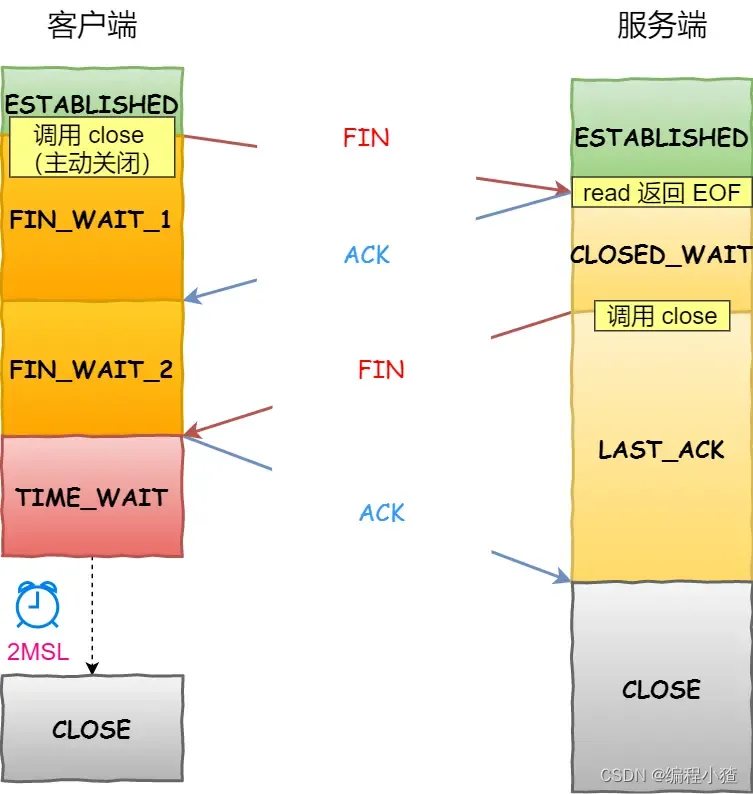
- 客戶端調用?
close,表明客戶端沒有數據需要發送了,則此時會向服務端發送 FIN 報文,進入 FIN_WAIT_1 狀態; - 服務端接收到了 FIN 報文,TCP 協議棧會為 FIN 包插入一個文件結束符?
EOF?到接收緩沖區中,應用程序可以通過?read?調用來感知這個 FIN 包。這個?EOF?會被放在已排隊等候的其他已接收的數據之后,這就意味著服務端需要處理這種異常情況,因為 EOF 表示在該連接上再無額外數據到達。此時,服務端進入 CLOSE_WAIT 狀態; - 接著,當處理完數據后,自然就會讀到?
EOF,于是也調用?close?關閉它的套接字,這會使得服務端發出一個 FIN 包,之后處于 LAST_ACK 狀態; - 客戶端接收到服務端的 FIN 包,并發送 ACK 確認包給服務端,此時客戶端將進入 TIME_WAIT 狀態;
- 服務端收到 ACK 確認包后,就進入了最后的 CLOSE 狀態;
- 客戶端經過?
2MSL?時間之后,也進入 CLOSE 狀態;
沒有 accept,能建立 TCP 連接嗎?
答案:可以的。
accpet 系統調用并不參與 TCP 三次握手過程,它只是負責從 TCP 全連接隊列取出一個已經建立連接的 socket,用戶層通過 accpet 系統調用拿到了已經建立連接的 socket,就可以對該 socket 進行讀寫操作了。
 ?
?
更想了解這個問題,可以參考這篇文章:沒有 accept,能建立 TCP 連接嗎?(opens new window)
沒有 listen,能建立 TCP 連接嗎?
答案:可以的。
客戶端是可以自己連自己的形成連接(TCP自連接),也可以兩個客戶端同時向對方發出請求建立連接(TCP同時打開),這兩個情況都有個共同點,就是沒有服務端參與,也就是沒有 listen,就能 TCP 建立連接。
更想了解這個問題,可以參考這篇文章:服務端沒有 listen,客戶端發起連接建立,會發生什么?



















