前言
為什么要學JVM?
首先:面試需要
了解JVM能幫助回答面試中的復雜問題。面試中涉及到的JVM相關問題層出不窮,難道每次面試都靠背幾百上千條面試八股?
其次:基礎知識決定上層建筑
自己寫的代碼都不知道是怎么回事,怎么可能寫出靠譜的系統?只有理解了JVM的工作機制,才能真正掌握Java這門語言,寫出高效、穩定的代碼。
然后:學習JVM也是進行JVM調優的基礎
寫的代碼放到線上要如何運行?要配多少內存?4G夠不夠?線上環境出問題,服務崩潰了,怎么快速定位?怎么解決問題?這些都離不開對JVM的深入理解。
學不學JVM,是能自主解決問題的一流程序員與跟著別人做CRUD的二流程序員的分水嶺!
二流程序員會覺得學JVM無關緊要,反正開發也用不上,做開發我只要學各種框架就行了。
而一流程序員都在盡自己能力把JVM每個底層邏輯整理成自己的知識體系,從而在實際工作中游刃有余,解決各種棘手的問題。
插播一條:真的免費,如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題
一、JVM要學什么?
一個Java文件,整體的執行過程整理如下圖:

這張圖就是整個JVM(JDK1.8)要學的所有東西,其中細節非常多,也很容易讓人學得枯燥,但是想要成為高手,就要忍受常人難以忍受的枯燥,不是嗎?
下面小北主要帶大家以實戰的方式整理一下這些核心模塊,讓大家學的沒那么枯燥。
二、Class文件規范
2.1 Class文件結構
首先,從上圖可以看到,JVM運行的第一步,是把一個xxxx.java文件編譯成為一個class文件,class文件本質上是一個二進制文件。
比如,對于一個ByCodeTest.class文件,使用UltraEdit工具打開,看到的內容部分是這樣的:
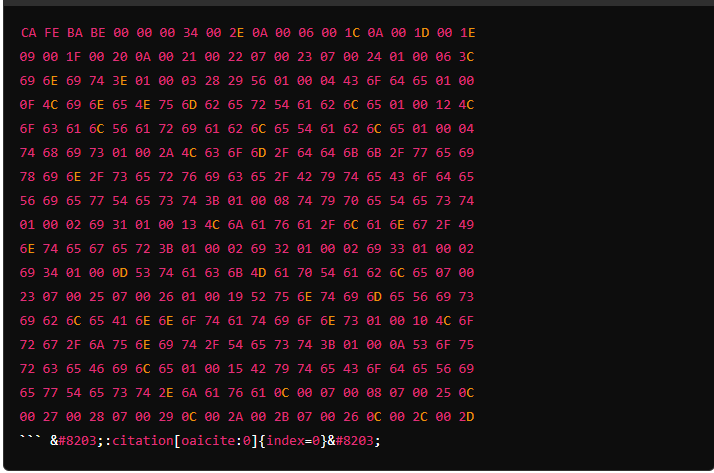
看到這很多小伙伴內心一萬頭草泥馬就奔騰而出了,這誰看得懂。
別慌,我們可以在IDEA中安裝一個ByteCodeView的插件來更直觀的查看一個ClassFile的內容,看到的大概內容是下面這樣的:
插件安裝及使用,這里就不多說了,相信對各位都是小菜一碟
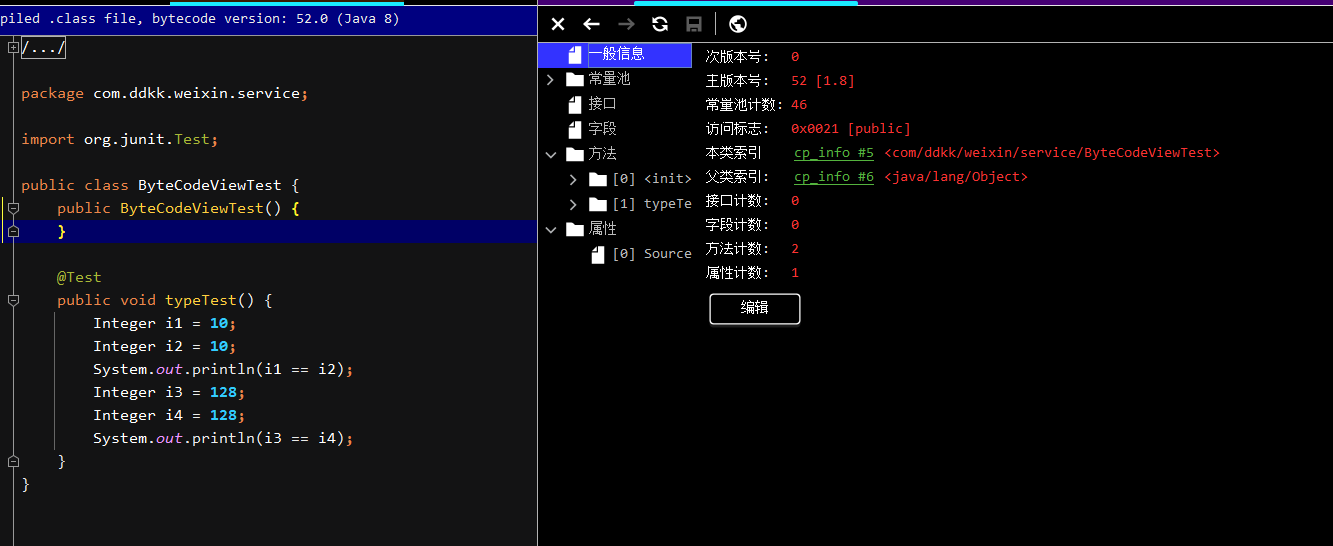
可以看到,一個class文件的大致組成部分。
然后再結合官方的文檔,或許能夠讓你開始對class文件有一個大致的感覺。

? 例如,前面u4表示四個字節是magic魔數,而這個魔數就是不講道理的 CAFEBABE 。
? 而后面的兩個u2,表示兩個字節的版本號。例如我們用 JDK8 看我們之前的class文件,minor_version就是 00 00,major_version就是 00 34。換成二進制就是 52。52.0 這就是 JVM 給 JDK8 分配的版本號。這兩個版本號就表示當前這個class文件是由JDK8編譯出來的。后續就只能用8以前版本的JVM執行。這就是JDK版本向前兼容的基礎。
例如,如果你嘗試用JDK8去引用Spring 6或者SpringBoot 3以后的新版本,就會報錯。就是因為Spring 6和SpringBoot 3發布出來的class文件,是用JDK17編譯的,版本號是61。JDK8是無法執行的。
2.2 理解字節碼指令
在上面的字節碼指令中,我們重點需要關注的是方法,也就是我們自己寫的代碼的部分。
例如在ByteCodeTest中的typeTest()這個方法,在Class文件中是這樣記錄的:
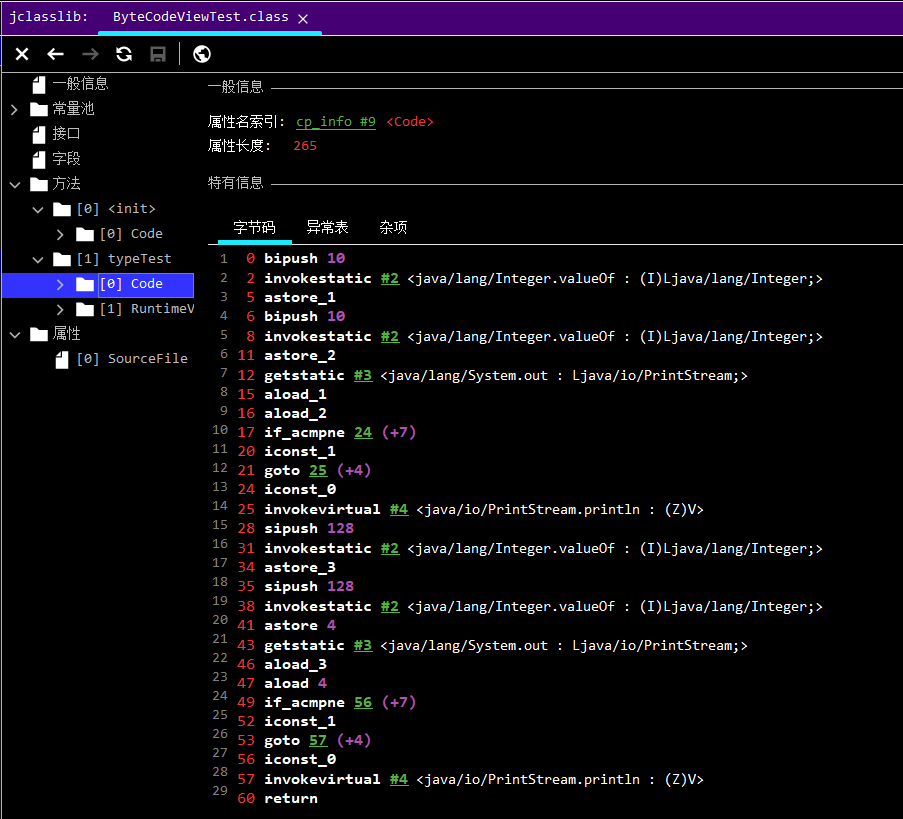
圖中 的每一行就是一個字節碼指令。
上述字節碼的含義,如果不考慮異常的話,那么JVM虛擬機執行的代碼邏輯應該是下面這樣的:
do{從程序計數器中讀取 PC 寄存器的值 + 1;根據 PC 寄存器指示的位置,從字節碼流中讀取一個字節的操作碼;if(字節碼存在操作數) 從字節碼流中讀取對應字節的操作數;執行操作碼所定義的操作;
}while(字節碼流長度>0)
這些字節碼指令你看不懂?沒關系,至少現在,你可以知道你寫的代碼在 Class 文件當中是怎么記錄的了😀
另外,如果你還想更仔細一點的分辨你的每一樣代碼都對應哪些指令,那么在這個工具中還提供了一個LineNumberTable,會告訴你這些指令與代碼的對應關系。
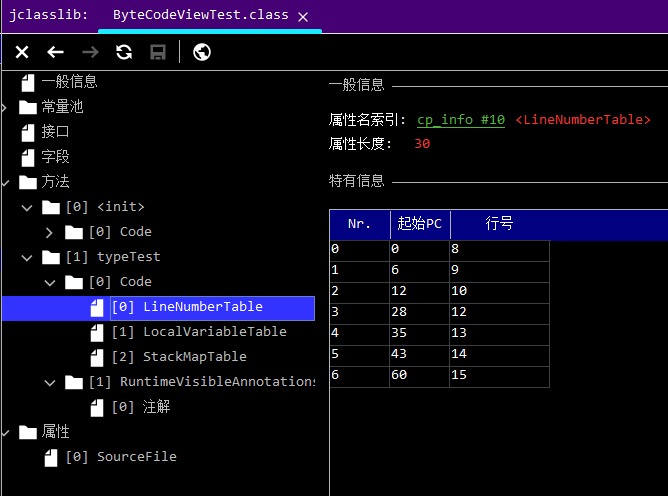
起始 PC 就是這些指令的字節碼指令的行數,行號則對應 Java 代碼中的行數。
實際上,Java 程序在遇到異常時給出的堆棧信息,就是通過這些數據來反饋報錯行數的。
2.3 字節碼指令解讀
在ByteCodeTest中,我們寫了一個typeTest方法:

初學者小白看到這里肯定不禁困惑:這些莫名其妙的true和false是怎么蹦出來的?
如果你之前恰巧刷到過這樣的面試題,或許你會記得這是因為JAVA的基礎類型裝箱機制引起的小誤會。
但是你知道產生這個問題的底層原因是什么嗎?
首先,我們可以從LineNumberTable 中獲取到這幾行代碼對應的字節碼指令:
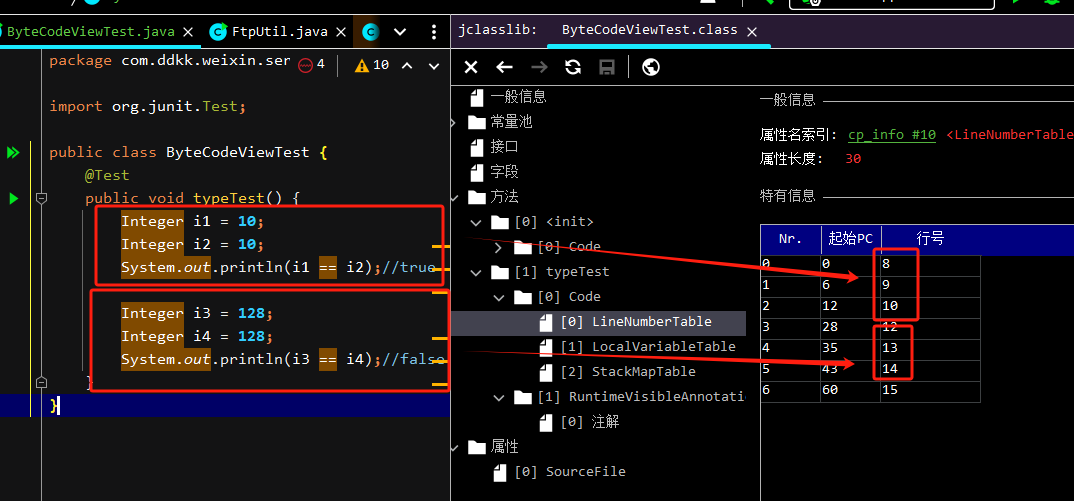
以前面三行為例,三行代碼對應的 PC 指令就是從 0 到 10 號這幾條指令。把指令摘抄下來是這樣的:
0 bipush 102 invokestatic #2 <java/lang/Integer.valueOf : (I)Ljava/lang/Integer;>5 astore_16 bipush 108 invokestatic #2 <java/lang/Integer.valueOf : (I)Ljava/lang/Integer;>
11 astore_2
12 getstatic #3 <java/lang/System.out : Ljava/io/PrintStream;>
可以看到,在執行astore指令往局部變量表中設置值之前,都調用了一次Integer.valueOf方法。
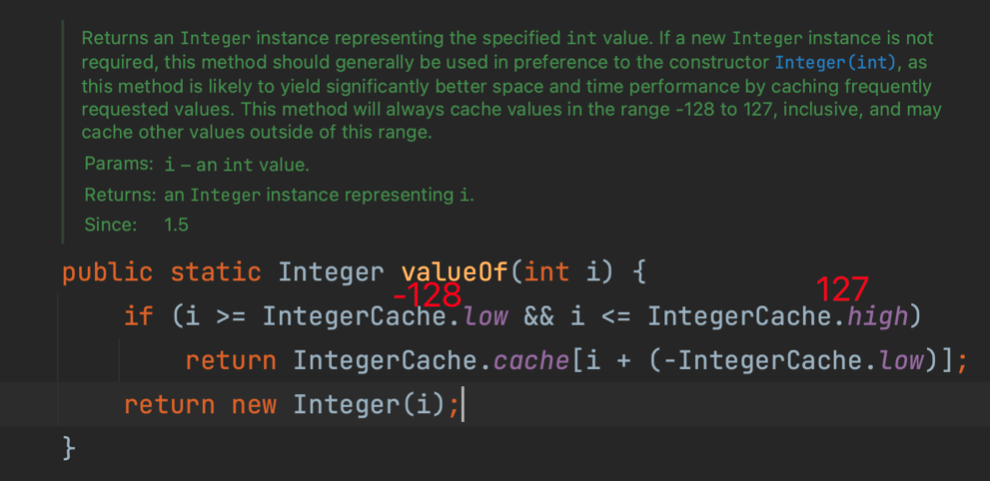
而在這個方法中,對于[-128,127]范圍內常用的數字,實際上是構建了緩存的。每次都從緩存中獲取一個相同的值,他們的內存地址當然就是相等的了。
這些初學者的夢魘,是不是在這個過程中找到了終極答案?
2.4 字節碼指令是如何工作的
要了解字節碼指令是如何工作的,就不得不先了解一下JVM中兩個重要的數據結構:局部變量表和操作數棧。
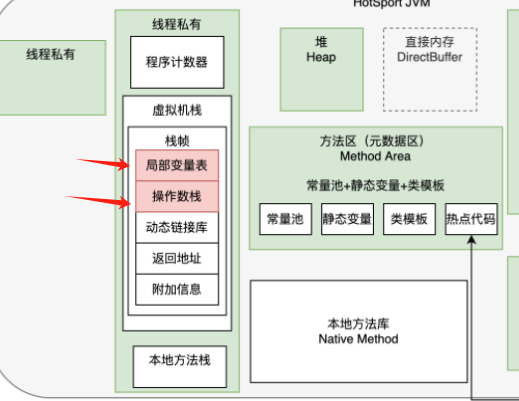
在 JVM 虛擬機中,會為每個線程構建一個線程私有的內存區域。
其中包含的最重要的數據就是程序計數器和虛擬機棧。
其中程序計數器主要是記錄各個指令的執行進度,用于在 CPU 進行切換時可以還原計算結果。
虛擬機棧中則包含了這個線程運行所需要的重要數據。
虛擬機棧是一個先進后出的棧結構,其中會為線程中每一個方法構建一個棧幀。而棧幀先進后出的特性也就對應了我們程序中每個方法的執行順序。每個棧幀中包含四個部分:
- 局部變量表
- 操作數棧
- 動態鏈接庫
- 返回地址。
操作數棧是一個先進后出的棧結構,主要負責存儲計算過程中的中間變量。
操作數棧中的每一個元素都可以是包括long型和double在內的任意 Java 數據類型。
局部變量表可以認為是一個數組結構,主要負責存儲計算結果。存放方法參數和方法內部定義的局部變量。以 Slot 為最小單位。
動態鏈接庫主要存儲一些指向運行時常量池的方法引用。每個棧幀中都會包含一個指向運行時常量池中該棧幀所屬方法的應用,持有這個引用是為了支持方法動態調用過程中的動態鏈接。
返回地址存放調用當前方法的指令地址。一個方法有兩種退出方式,一種是正常退出,一種是拋異常退出。如果方法正常退出,這個返回地址就記錄下一條指令的地址。如果是拋出異常退出,返回地址就會通過異常表來確定。
附加信息主要存放一些 HotSpot 虛擬機實現時需要填入的一些補充信息。這部分信息不在 JVM 規范要求之內,由各種虛擬機實現自行決定。
其中最為重要的就是操作數棧和局部變量表了
例如,對于初學者最頭疼的++操作,下面的 mathTest 方法
public int mathTest(){int i = 1 ;i = i++;return i;}
i 的返回結果是多少?
我們都知道 i 的返回結果是 1 ,但是++自增操作到底有沒有執行呢?就可以按照指令這樣進行解釋:
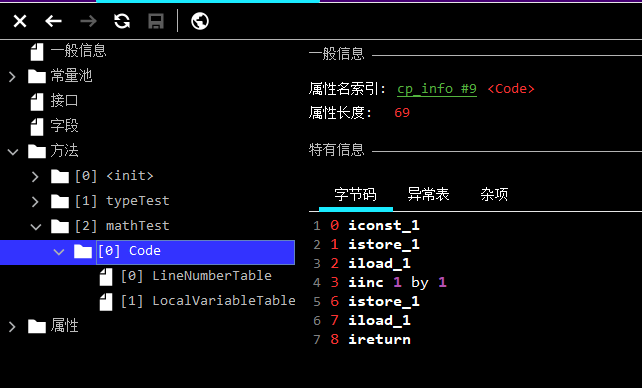
0 iconst_1 //往操作數棧中壓入一個常量1
1 istore_1 // 將 int 類型值從操作數棧中移出到局部變量表1 位置
2 iload_1 // 從局部變量表1 位置裝載int 類型的值到操作數棧中
3 iinc 1 by 1 // 將局部變量表 1 位置的數字增加 1
6 istore_1 // 將int類型值從操作數棧中移出到局部變量表1 位置
7 iload_1 // 從局部變量表1 位置裝載int 類型的值到操作數棧中
8 ireturn // 從操作數棧頂,返回 int 類型的值
這個過程中,k++是在局部變量表中對數字進行了自增,此時棧中還是 1。接下來執行=操作,就對應一個istore指令,從棧中將數字裝載到局部變量表中。局部變量表中的k的值(對應索引 1 位置),就還是還原成了 1。
那么接下來,你是不是可以自行理解一下 k=++k,是怎么執行的呢?
2.5 補充知識點:大廠面試題
如何確定一個方法需要多大的操作數棧和局部變量?
實際上,每個方法在執行前都需要申請對應的資源,主要是內存。如果內存空間不夠,就要在執行前直接拋出異常,而不能等到執行過程中才發現要用的內存空間申請不下來。
有些面試時,是會給你一個具體的方法,讓你自己一下計算過程中需要幾個操作數棧和幾個局部變量。
這是對算法的基礎要求。但是在工作中,其實class文件當中就記錄了所需要的操作數棧深度和局部變量表的槽位數。
例如對于 mathTest方法,所需的資源在工具中的紀錄是這樣的:
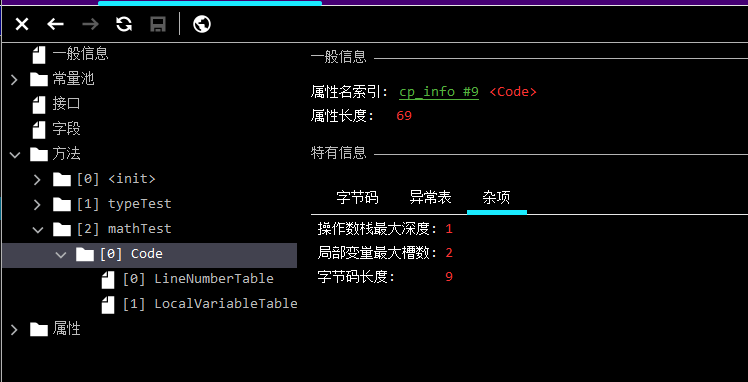
以后被領導問的時候可以直接通過這種方式告訴他就行了
這里會有一個小問題,如果你自己推演過剛才的計算過程,可以看到,局部變量表中,明明只用到了索引為 1 的一個位置而已,為什么局部變量表的最大槽數是 2 呢?
這是因為對于非靜態方法,JVM 默認都會在局部變量表的 0 號索引位置放入this變量,指向對象自身。所以我們可以在代碼中用this訪問自己的屬性。
一個槽可以存放 Java 虛擬機的基本數據類型,對象引用類型和returnAddress類型
插播一條:真的免費,如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題
三、類加載
Class文件中已經定義好了一個Java程序執行的全部過程,接下來就是要扔到JVM中執行。
既然要執行,就少不了類加載的模塊。而有趣的是,類加載模塊是少數幾個可以在Java代碼中擴展的JVM底層功能。
類加載模塊在JDK8之后,發生了非常重大的變化,本文主要以JDK8為例講解
3.1 JDK8的類加載體系
有了 Class 文件之后,接下來就需要通過類加載模塊將這些 Class 文件加載到 JVM 內存當中,這樣才能執行。而關于類加載模塊,最為重要的內容有以下三點:
- 每個類加載器對加載過的類保持一個緩存。
- 雙親委派機制,即向上委托查找,向下委托加載。
- 沙箱保護機制。
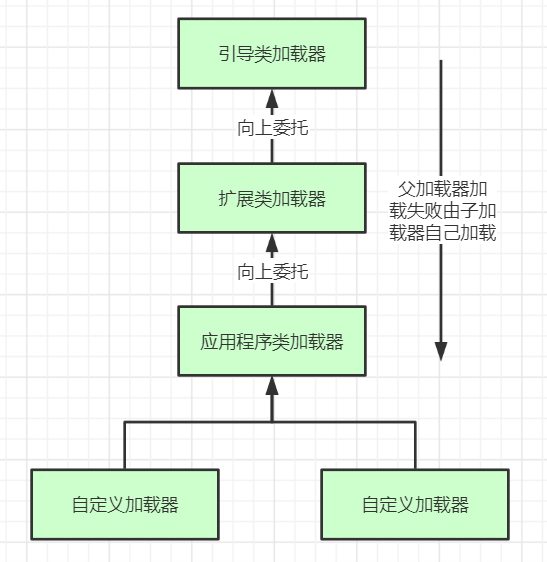
3.2 雙親委派機制
JDK8中的類加載器都繼承于一個統一的抽象類ClassLoader,類加載的核心也在這個父類中。
其中,加載類的核心流程如下:
核心代碼如下:
//類加載器的核心方法
protected Class<?> loadClass(String name, boolean resolve)throws ClassNotFoundException{synchronized (getClassLoadingLock(name)) {// 每個類加載起對他加載過的類都有一個緩存,先去緩存中查看有沒有加載過Class<?> c = findLoadedClass(name);if (c == null) {】//沒有加載過,就走雙親委派,找父類加載器進行加載。long t0 = System.nanoTime();try {if (parent != null) {c = parent.loadClass(name, false);} else {c = findBootstrapClassOrNull(name);}} catch (ClassNotFoundException e) {}if (c == null) {long t1 = System.nanoTime();// 父類加載起沒有加載過,就自行解析class文件加載。c = findClass(name);sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);sun.misc.PerfCounter.getFindClasses().increment();}}//這一段就是加載過程中的鏈接Linking部分,分為驗證、準備,解析三個部分。// 運行時加載類,默認是無法進行鏈接步驟的。if (resolve) {resolveClass(c);}return c;}}
這個方法里,就是最為核心的雙親委派機制。
雙親委派機制說簡單點就是,先找父親加載,不行再由兒子自己加載
并且,這個方法是protected聲明的,意味著,是可以被子類覆蓋的,所以,雙親委派機制也是可以被打破的。
而關于類加載機制的所有有趣的玩法,也都在這個核心方法里。比如class文件加密加載,熱加載等。
補充知識點(面試題:Tomcat為什么要打破雙親委派呢?)
3.3 沙箱保護機制
雙親委派機制有一個最大的作用就是要保護JDK內部的核心類不會被應用覆蓋。
而為了保護JDK內部的核心類,JAVA在雙親委派的基礎上,還加了一層保險。就是ClassLoader中的下面這個方法。
private ProtectionDomain preDefineClass(String name,ProtectionDomain pd){if (!checkName(name))throw new NoClassDefFoundError("IllegalName: " + name);// 不允許加載核心類if ((name != null) && name.startsWith("java.")) {throw new SecurityException("Prohibited package name: " +name.substring(0, name.lastIndexOf('.')));}if (pd == null) {pd = defaultDomain;}if (name != null) checkCerts(name, pd.getCodeSource());return pd;}
這個方法會用在JAVA在內部定義一個類之前。
這種簡單粗暴的處理方式,當然是有很多時代的因素。也因此在JDK中,你可以看到很多javax開頭的包。這個奇怪的包名也是跟這個沙箱保護機制有關系的。
四、執行引擎
之前已經看到過,在 Class 文件當中,已經明確的定義清楚了程序的完整執行邏輯。
而執行引擎就是將這些字節指令轉為機器指令去執行了。
這一塊更多的是跟操作系統打交道,對開發工作其實幫助就不是很大了。
所以,如果不是專門研究語言,執行引擎這一塊就沒有必要研究太深了。我們也直接跳過。
五、GC垃圾回收
執行引擎會將class文件扔到JVM的內存當中運行,在運行過程中,需要不斷的在內存當中創建并銷毀對象。
在傳統C/C++語言中,這些銷毀的對象需要手動進行內存回收,防止內存泄漏。而在Java當中,實現了影響深遠的GC垃圾回收機制。
GC 垃圾自動回收,這個可以說是 JVM 最為標志性的功能。
不管是做性能調優,還是工作面試,GC 都是 JVM 部分的重中之重。
而對于 JVM 本身,GC 也是不斷進行設計以及優化的核心。
幾乎 Java 提出的每個版本都對 GC 有或大或小的改動。
這里,我就用目前還是用得做多的 JDK8,帶大家快速梳理一下 GC 部分的主線。
插播一條:真的免費,如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題
5.1 垃圾回收器是干什么的?
在了解 JVM之前,給大家推薦一個工具,阿里開源的 Arthas
官網地址:https://arthas.aliyun.com/
這個工具功能非常強大,是對 Java進程進行性能調優的一個非常重要的工具,對于了解 JVM 底層幫助也非常大。
public class GCTest {public static void main(String[] args) throws InterruptedException {List l = new ArrayList<>();for(int i = 0 ; i < 100_0000 ; i ++){l.add(new String("dddddddddddd"));Thread.sleep(100);}}
}
運行后,使用Arthas 的dashboard指令,可以查看到這個 Java 程序的運行情況。
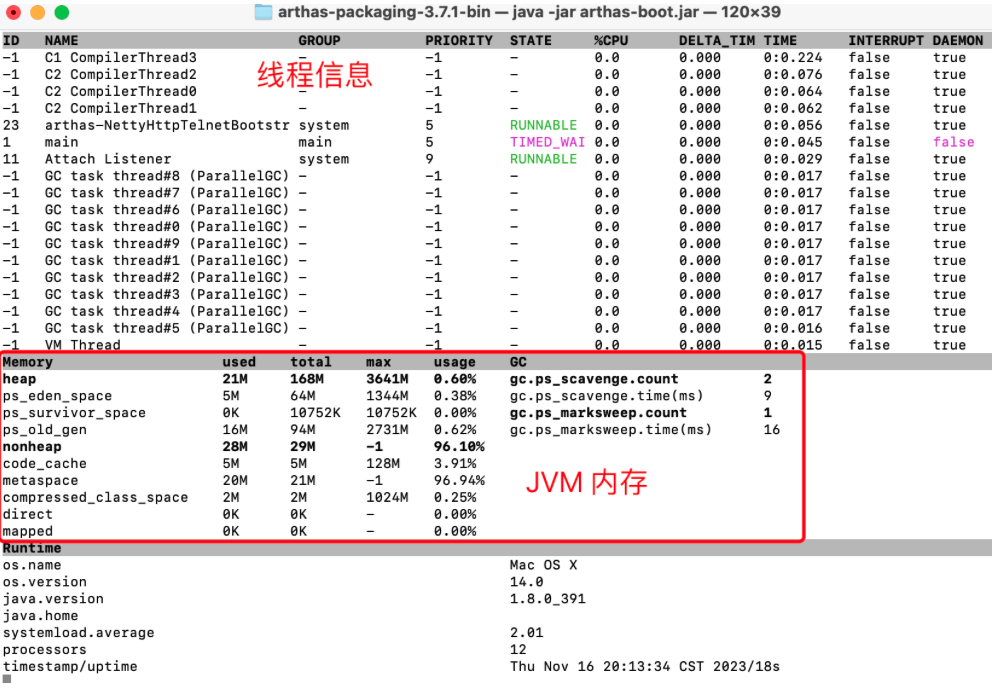
重點關注中間的 Memory 部分,這一部分就是記錄的 JVM 的內存使用情況
- ps_eden_space:伊甸園區
- ps_survivor_space:幸存區
- ps_old_gen:老年代
- nonheap:非堆內存
- code_cache:熱點指令緩存
- metaspace:元空間
- compressed_class_space:壓縮類空間
…
而后面的 GC 部分就是垃圾回收的執行情況。我
們就從這些能看到的部分作為入口,來理解一下一個 Java 進程是怎么管理他的內存的。
從 Memory 部分可以看到,一個 Java 進程會將他管理的內存分為heap堆區和nonheap非堆區兩個部分。其中非堆區的幾個核心部分像code_cache(熱點指令緩存),metaspace(元空間),compressed_class_space(壓縮類空間)。這一部分就相當于 Java 進程中的地下室,屬于不太活躍的部分。
而中間heap堆區就相當于客廳了,屬于Java 中最為核心的部分。
而這其中,又大體分為了eden_space,survivor_space和old_gen三個大的部分,這就是 JVM 內存的主體
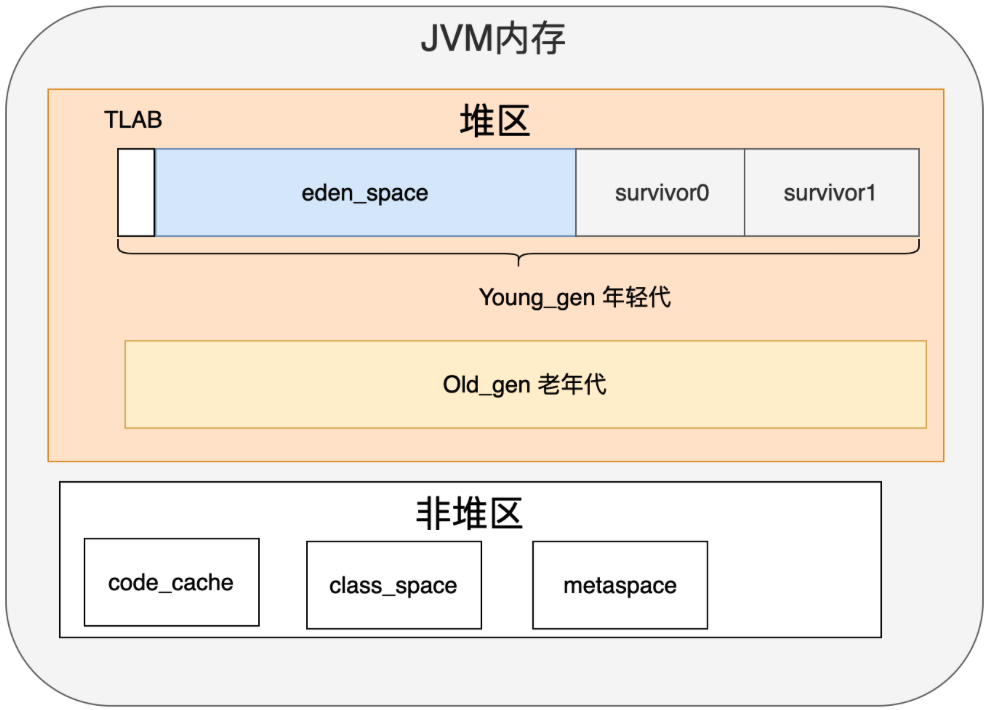
堆區是JVM用來存放對象的核心內存區域。
它的大小可以通過兩個參數來控制:-Xms(初始堆內存大小)和 -Xmx(最大堆內存大小)。
通過這兩個參數可以看出,堆內存是可以擴展的。如果初始內存不夠用,JVM會自動擴大堆內存。
但是,如果堆內存擴展到了最大值還不夠用,就沒法繼續擴展了,這時候就會拋出OOM(Out of Memory)異常。
在生產環境中,建議把 -Xms 和 -Xmx 設置成一樣的大小,這樣可以減少內存擴展時的性能消耗。
GC垃圾回收器的任務就是及時回收這些內存空間,讓內存可以重復利用,從而提升系統的性能和穩定性。
5.2 分代收集模型
不同GC,對內存的管理和回收的方式都是不同的。但是這其中面試最喜歡問的,就是關于垃圾分代收集模型。
在Memor部分還可以看到多次出現了 ps_ 這樣的字樣。這其實就代表JDK8默認的垃圾回收器Parallel Scavenge。
其整體的工作機制如下圖:

你知道嗎?Java做過統計,80%的對象都是“朝生夕死”,換句話說,這些對象創建快,消亡也快。
這些短命的對象被放在一個比較小的內存區域,這塊地方叫“年輕代”。
在年輕代,垃圾回收特別頻繁,叫做YoungGC。年輕代又被進一步分成三個區域:一個叫eden區,兩個叫survivor區。
默認情況下,這三個區域的大小比例是8:1:1。
那剩下的20%長壽對象去哪了?
它們被放到另一塊內存區域,這地方叫“老年代”。
老年代的對象競爭沒那么激烈,所以垃圾回收的頻率也低,只有空間不夠用時才進行,叫OldGC。
年輕代和老年代的默認大小比例是1:2。
在常見的分代收集模型中,對象會首先在eden區創建,經過一次YoungGC后,如果對象沒有被回收,就會被移動到一個survivor區。
下一次YoungGC時,這些幸存的對象又會被移動到另一個survivor區。每次移動,都會記錄一個分代年齡。一直到分代年齡達到閾值(默認是16),這些對象就會被移到老年代。到了老年代后,就不再記錄分代年齡了,安安靜靜地待著,直到“退休”。
這就是JDK最有代表性的分代收集機制。通過這個機制,JVM可以對不同的對象采取不同的回收策略,從而大大提高垃圾回收的效率。
5.3 JVM中有哪些垃圾回收器?
java 從誕生到現在最新的 JDK21 版本,總共就產生了以下十個垃圾回收器
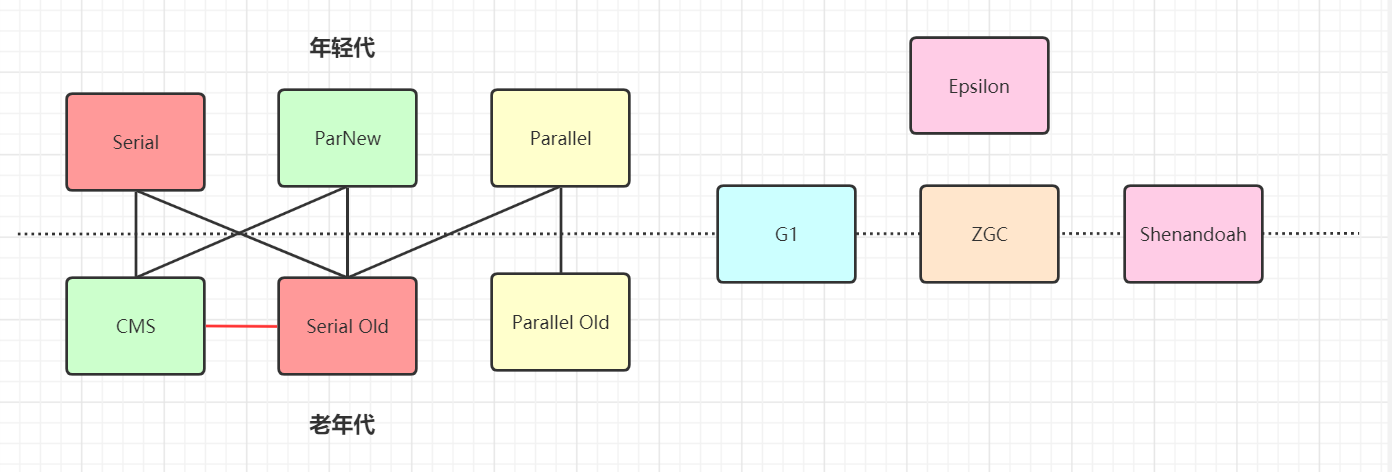
其中,左邊的都是分代算法。也就是將內存劃分為年輕代和老年代進行管理。
而有虛線的部分表示可以協同進行工作。
JDK8默認就是使用的Parallel Scavenge和Parallel Old的組合。也就是在arthas的dashboard中看到的ps。
右側的是不分代算法。也就是不再將內存嚴格劃分位年輕代和老年代。
JDK9 開始默認使用 G1。而 ZGC是目前最先進的垃圾回收器。
shennandoah則是OpenJDK 中引入的新一代垃圾回收器,與 ZGC 是競品關系。Epsilon是一個測試用的垃圾回收器,根本不干活。
六、GC 情況分析實例
GC可以說是決定JAVA程序運行效率的關鍵。因此我們一定要學會定制GC參數,以及分析GC日志,從而達到調優的目的
6.1 如何定制GC運行參數
現在,不同的GC垃圾回收器適用于不同的場景,所以我們得根據業務場景來定制合理的GC運行參數。
在Java程序運行過程中,會遇到各種問題:
有時CPU飆高
有時FullGC頻繁
有時OOM異常等等
這些問題大多需要憑經驗深入分析,才能對癥下藥。
那我們該怎么定制JVM運行參數呢?
首先得知道有哪些參數可以選擇。
JVM的參數主要有三類:
-
標準參數:以-開頭,所有HotSpot都支持。例如java -version。可以用java -help或java -?查看所有標準參數。
-
非標準參數:以-X開頭,是特定HotSpot版本支持的指令。例如java -Xms200M -Xmx200M。可以用java -X查看所有非標準參數。
-
不穩定參數:以-XX開頭,這些參數與特定HotSpot版本對應,可能換個版本就沒有了,文檔資料也特別少。以下是JDK8中的幾個有用指令:
java -XX:+PrintFlagsFinal:打印所有最終生效的不穩定指令。
java -XX:+PrintFlagsInitial:打印默認的不穩定指令。
java -XX:+PrintCommandLineFlags:打印當前命令的不穩定指令,可以看到使用了哪種GC。JDK1.8默認用的是ParallelGC。
例如下面一個簡單的示例代碼:
public static void main(String[] args) {ArrayList<byte[]> list = new ArrayList<>();for (int i = 0; i < 500; i++) {byte[] arr = new byte[1024 * 100];//100KBlist.add(arr);try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}}
然后在執行這個方法時,添加以下 JVM 參數:
-Xms60m -Xmx60m -XX:SurvivorRatio=8 -XX:+PrintGCDetails
執行后,可以看到下面輸出內容
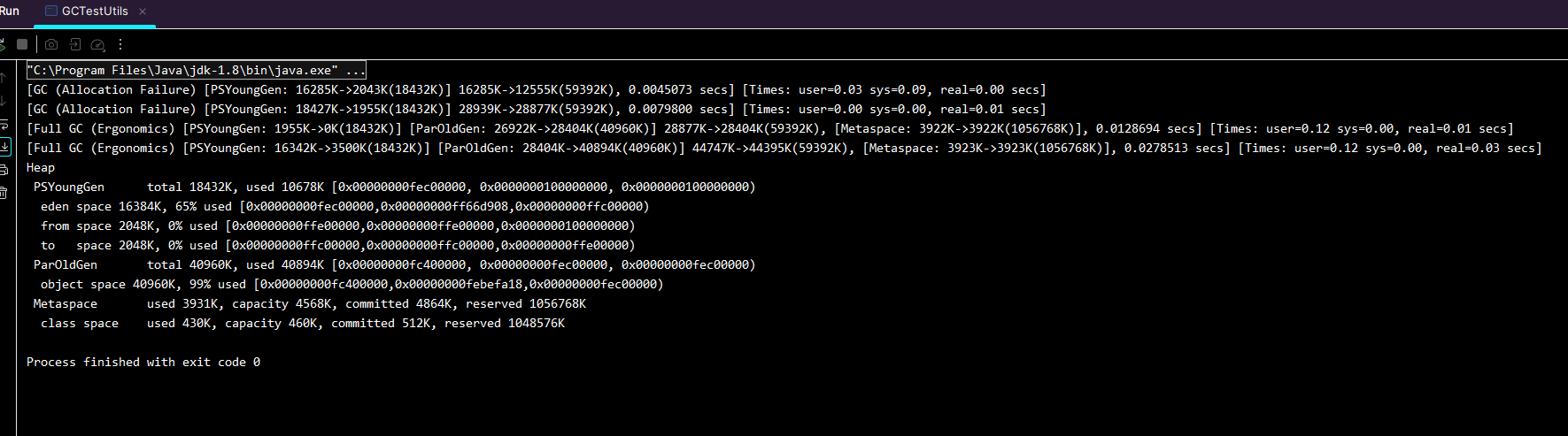
這里面就記錄了兩次 MinorGC 和兩次 FullGC 的執行效果。
當然,目前這些日志信息只是打印在控制臺,你只能憑經驗自己強行去看。
接下來,就可以添加-Xloggc參數,將日志打印到文件里。然后拿日志文件進行整體分析。
6.3 GC日志分析
這些GC日志隱藏了項目運行非常多隱蔽的問題
要如何發現其中的這些潛在的問題呢?
肉眼去看肯定是不現實的,這時候就要使用工具了。
這里推薦一個開源網站 https://www.gceasy.io/ 這是國外一個開源的GC 日志分析網站。
你可以把 GC 日志文件直接上傳到這個網站上,他就會分析出日志文件中的詳細情況。
這是個收費網站,但是有免費使用的額度
例如,在我們之前的示例中,添加一個參數 -Xloggc:./gc.log ,就可以將GC日志打印到文件當中。
接下來就可以將日志文件直接上傳到這個網站上。網站就會幫我們對GC情況進行分析。示例文件得到的報告是這樣的:

通過這份報告,你能迅速識別項目運行中潛藏的問題。報告不僅提供了具體的修改建議,還包含詳盡的指標分析。如果你覺得這些建議還不夠詳細,可以利用這些指標做進一步的分析,找到更多改進的方向。
如果是你們自己開發的項目,那接下來就可以根據這些建議和數據,深入分析,調整參數,優化配置。到了這一步,恭喜你,已經成功入門架構師的核心技能——JVM調優了。
總結
聊到這里,你對JVM是不是有點感覺了?
在這個過程中,你是不是還有很多細節上的疑問?
保持這些疑問,它們會成為你后續深入學習那些晦澀枯燥的底層理論的動力。這不會是一個容易的過程,但正是因為有挑戰,才更有價值,不是嗎?
踏上這條學習JVM的路,你會發現其中的復雜與精彩。而那些疑問和挑戰,正是推動你不斷前行的力量。保持好奇心和耐心,你才能一步步掌握這門技術,成為真正的Java架構師!
最后說一句(求關注,求贊,別白嫖我)
最近無意間獲得一份阿里大佬寫的刷題筆記,一下子打通了我的任督二脈,進大廠原來沒那么難。
這是大佬寫的, 7701頁的BAT大佬寫的刷題筆記,讓我offer拿到手軟
本文,已收錄于,我的技術網站 cxykk.com:程序員編程資料站,有大廠完整面經,工作技術,架構師成長之路,等經驗分享
求一鍵三連:點贊、分享、收藏
點贊對我真的非常重要!在線求贊,加個關注我會非常感激!
真的免費,如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題












四千字好文)





)
)