目錄
- 1、Java的IO體系
- 2、IO的常用方法
- 3、Java中為什么要分為字節流和字符流
- 4、File和RandomAccessFile
- 5、Java對象的序列化和反序列化
- 6、緩沖流
- 7、Java 的IO流中涉及哪些設計模式
1、Java的IO體系
IO 即為 input 輸入 和 output輸出
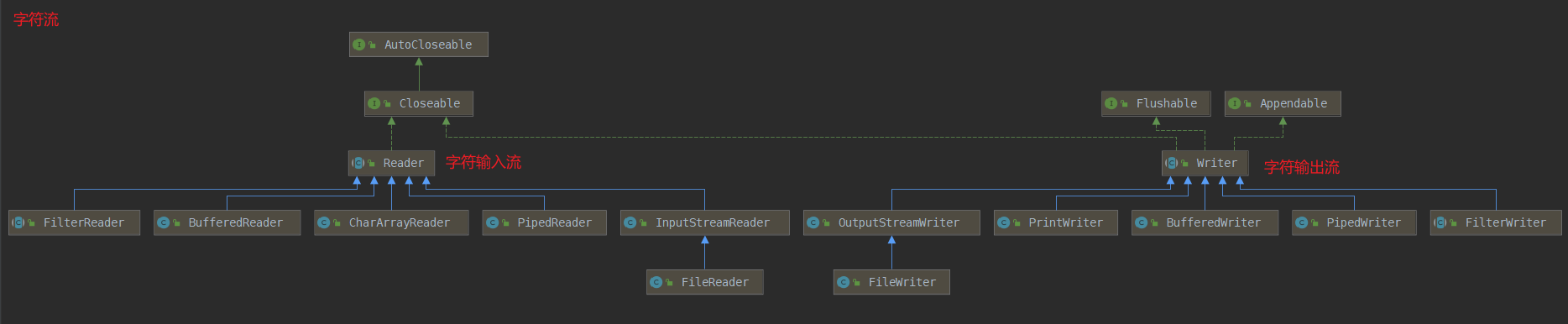
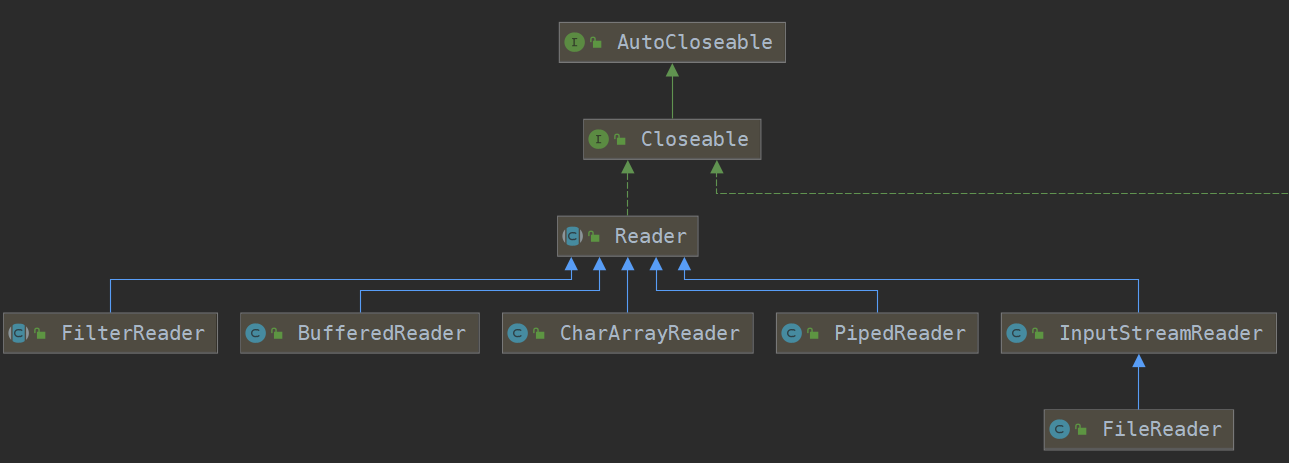
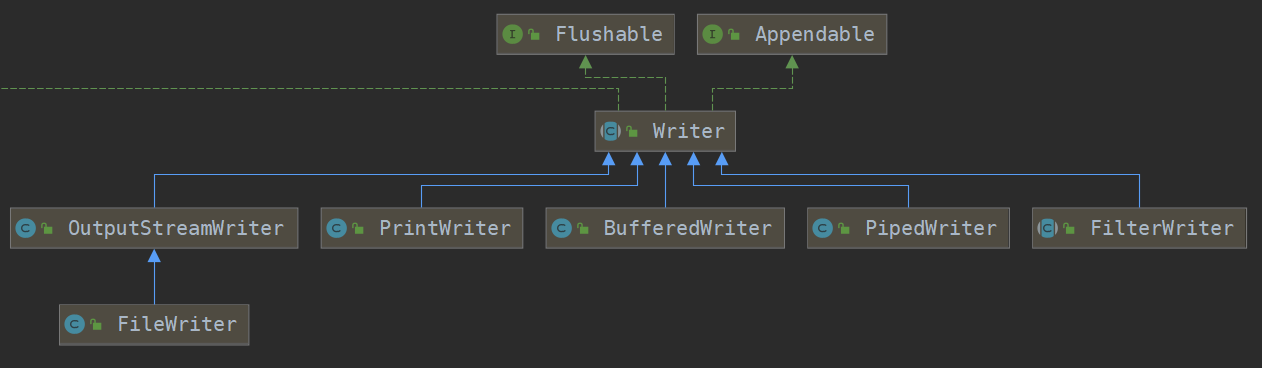
Java的IO體系主要分為字節流和字符流兩大類
字節流又分為
字節輸入流 InputStream 和 字節輸出流 OutputStream
都實現了java.lang.AutoCloseable接口 所以在使用這些流資源時 可以使用 try-with-resource結構 自動關閉流

放大點看:


字符流又分為
字符輸入流Writer 字符輸出流 Reader
放大點看:
2、IO的常用方法
掌握IO的 InputStream 、 OutputStream、Reader 、Writer中的方法
IO中 其他的幾十個類 都是基于 上面這四個類 設計的
InputStream抽象類中方法摘要

OutputStream抽象類中方法摘要

Reader 抽象類中方法摘要

Writer抽象類中方法摘要

3、Java中為什么要分為字節流和字符流
分為字節流和字符流的主要原因包括:
- 處理數據類型的不同:字節流以字節為單位進行讀寫操作,適用于處理二進制數據或者無需考慮字符編碼的數據(如圖像、音頻、視頻等文件),而字符流適用于處理文本數據。
- 字符編碼的考慮:字符流能夠處理字符編碼的轉換,從而能夠更好地處理不同編碼格式的文本數據。
- 文本處理的便捷性:使用字符流能夠更方便地處理文本數據,如按行讀取、字符緩沖等操作。
4、File和RandomAccessFile
在實際項目中我們使用流處理最多的就是文件
下面是File類的 字段和構造方法
一個 File 對象代表硬盤中實際存在的一個文件或者目錄。

代碼中建議使用 File.separator來表示 路徑分隔符 這樣程序會自動判斷當前運行環境 來生成符合當前運行環境的分隔符 比如Windows的 \
或者 Linux 的 /
File類常用方法:
get類的方法




判斷相關的方法



創建文件相關的方法

createNewFile 不存在則創建并且返回true 存在則不創建 返回false


mkdir 只創建一級目錄 如果父目錄不存在則創建失敗

文件或者目錄的遍歷


遍歷輸出一個文件夾下的全部文件
public class ListFiles{public static void main(String[] args) {//根據給定的路徑創建一個File對象File srcFile = new File("E:\\test");//調用方法getAllFilePath(srcFile);}//定義一個方法,用于獲取給定目錄下的所有內容,參數為第1步創建的File對象public static void getAllFilePath(File srcFile) {//獲取給定的File目錄下所有的文件或者目錄的File數組File[] fileArray = srcFile.listFiles();//遍歷該File數組,得到每一個File對象if(fileArray != null) {for(File file : fileArray) {//判斷該File對象是否是目錄if(file.isDirectory()) {//是:遞歸調用getAllFilePath(file);} else {//不是:獲取絕對路徑輸出在控制臺System.out.println(file.getAbsolutePath());}}}}
}
RandomAccessFile
RandomAccessFile 允許您跳轉到文件的任何位置,從那里開始讀取或寫入。適用于需要在文件中隨機訪問數據的場景。
比如在文檔的末位加幾個字,或者在文檔的開頭加幾個字等操作。

訪問模式 mode 的值可以是:
“r”:以只讀模式打開文件。調用結果對象的任何 write 方法都將導致 IOException。
“rw”:以讀寫模式打開文件。如果文件不存在,它將被創建。
"rws"模式:要求對內容或元數據的每個更新都被立即寫入到底層存儲設備。這意味著在使用"rws"模式打開文件時,不僅對文件內容的更新會被立即寫入,還包括文件的元數據,比如文件屬性、修改時間等。這種模式是同步的,可以確保在系統崩潰時不會丟失數據。
"rwd"模式:與“rws”類似,也是以讀寫模式打開文件,并且要求對文件內容的更新被立即寫入。不同的是,"rwd"模式只要求對文件內容的更新被立即寫入,而元數據可能會被延遲寫入,這意味著文件的屬性信息等可能不會立即更新到磁盤。
文件內容(File Content):
文件內容通常指的是文件中存儲的實際數據,即由應用程序創建的、用戶需要讀取或操作的數據。對文件內容的更新包括寫入新的數據,修改已有數據,或者刪除數據等操作。
元數據(Metadata):
元數據是指關于文件的描述性數據,例如文件的名稱、大小、創建時間、修改時間、權限信息等。在文件系統中,元數據通常是指文件的屬性信息、目錄結構、索引信息等。
如果需要確保對元數據的每次更新都被立即寫入到存儲設備,可以選擇"rws"模式;如果對元數據的實時性要求不高,可以選擇"rwd"模式以獲得更好的性能。
RandomAccessFile常用方法

舉個栗子:(使用 RandomAccessFile方法實現插入效果)
使用該類的write方法對文件寫入時,實際上是一種覆蓋效果,即寫入的內容會覆蓋相應位置處的原有內容。要實現插入效果
需要記錄插入位置的后續內容,插入內容后,再把后續內容寫入。
文件內容(來源于網絡上吐槽平均工資的一個段子)

我們利用RandomAccessFile 來 在 “兩個” 后面再插入點內容
public static void main(String[] args) {File file = new File("D:\\123.txt");try(RandomAccessFile randomAccessFile = new RandomAccessFile(file,"rws")) {// 指定插入位置randomAccessFile.seek(18);//獲取插入點后面的內容StringBuffer sb = new StringBuffer();byte[] b = new byte[100];int len;while( (len=randomAccessFile.read(b)) != -1 ) {sb.append( new String(b, 0, len) );}System.out.println(sb);randomAccessFile.seek(18); //重新設置插入位置randomAccessFile.write( "睪丸".getBytes() ); //插入指定內容randomAccessFile.write( sb.toString().getBytes() ); //恢復插入點后面的內容} catch (Exception e) {e.printStackTrace();}}
此時文件內容:

本質上想插入內容必須先定位到要插入的位置,然后保存此位置之后的內容,插入新內容后,再把保存的內容附加到新插入的內容之后。
使用RandomAccessFile 類的write方法對文件寫入時,實際上是一種覆蓋效果,即寫入的內容會覆蓋相應位置處的原有內容。
RandomAccessFile還有個比較重要的作用是實現大文件的斷點續傳功能
可以參考 https://blog.csdn.net/qq_37883866/article/details/137722103
5、Java對象的序列化和反序列化
基本概念:
序列化:將數據結構或對象轉換成二進制字節流的過程
反序列化:將在序列化過程中所生成的二進制字節流轉換成數據結構或者對象的過程
什么時候需要用到序列化
對象在進行網絡傳輸(比如遠程方法調用 RPC 的時候)之前需要先被序列化,接收到序列化的對象之后需要再進行反序列化。
例如通過Dubbo進行遠程通信的POJO類 都需要實現Serializable接口
將對象存儲到文件 也需要序列化 因為文件需要以字節流的形式傳輸
將對象存儲到Redis之前需要用到序列化,將對象從Redis中讀取出來需要反序列化;
比如:
@Bean("redisTemplate")public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);//設置value的序列化方式為JsonredisTemplate.setValueSerializer(jackson2JsonRedisSerializer);//設置key的序列化方式為StringredisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);redisTemplate.afterPropertiesSet();return redisTemplate;}
注意事項:
一個對象要想序列化,該類必須實現java.io.Serializable 接口,否則會拋出NotSerializableException 。
對于不想進行序列化的變量,需要使用 transient 關鍵字修飾 例如: public transient int name;
靜態變量不能被序列化 例如: public static int name;
transient 修飾的變量,在反序列化后變量值將會被置成類型的默認值。例如,如果是修飾 int 類型,那么反序列后結果就是 0。
實現Serializable接口的類 最好自定一個serialVersionUID
private static final long serialVersionUID = 1L;
在 Java 中,序列化 ID(SerialVersionUID)是序列化版本標識符,它是為了在進行對象序列化和反序列化時確保版本的兼容性而存在的。
序列化 ID 的作用主要包括以下幾個方面:
- 版本控制:當類的結構發生變化時(比如添加、刪除或修改字段、方法等),序列化 ID 可以確保在反序列化時能夠正確地恢復舊版本的對象。如果不指定序列化 ID,Java 編譯器會根據類的結構自動生成一個序列化 ID,但是這樣生成的序列化 ID 可能會受到類結構變化的影響,導致在反序列化時拋出版本不一致的異常。
- 兼容性:在分布式系統中,不同的 Java 虛擬機可能會使用不同的類版本。通過指定序列化 ID,可以確保不同版本的 Java 程序在進行對象序列化和反序列化時能夠正確地識別和處理對象版本,從而保證了系統的兼容性。
- 安全性:序列化 ID 可以防止惡意攻擊者通過修改類結構來篡改對象的字段值或方法行為,從而提高了系統的安全性。
Java 的序列化流(ObjectInputStream 和 ObjectOutputStream)可以將 Java 對象序列化和反序列化。
代碼示例:
class User implements Serializable {/** 版本控制:當類的結構發生變化時(比如添加、刪除或修改字段、方法等),序列化 ID 可以確保在反序列化時能夠正確地恢復舊版本的對象。* 如果不指定序列化 ID,Java 編譯器會根據類的結構自動生成一個序列化 ID,但是這樣生成的序列化 ID 可能會受到類結構變化的影響,* 導致在反序列化時拋出版本不一致的異常。** 兼容性:在分布式系統中,不同的 Java 虛擬機可能會使用不同的類版本。通過指定序列化 ID,* 可以確保不同版本的 Java 程序在進行對象序列化和反序列化時能夠正確地識別和處理對象版本,從而保證了系統的兼容性。** 安全性:序列化 ID 可以防止惡意攻擊者通過修改類結構來篡改對象的字段值或方法行為,從而提高了系統的安全性。** */private static final long serialVersionUID = 1L;private Integer age;private String name;public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "User{" +"age=" + age +", name='" + name + '\'' +'}';}}// 測試序列化 和 反序列化public static void main(String[] args) {User user = new User();user.setName("秀逗");user.setAge(10);// 序列化try (FileOutputStream fos = new FileOutputStream("D:\\user.dat");ObjectOutputStream oos = new ObjectOutputStream(fos);) {oos.writeObject(user);} catch (Exception e) {e.printStackTrace();}// 反序列化String filename = "D:\\user.dat";try (FileInputStream fileIn = new FileInputStream(filename);ObjectInputStream in = new ObjectInputStream(fileIn)) {// 從指定的文件輸入流中讀取對象并反序列化Object obj = in.readObject();// 將反序列化后的對象強制轉換為指定類型User user1 = (User) obj;// 打印反序列化后的對象信息System.out.println(user1);} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}}上面這種JDK自帶的序列化方式會有一些問題:
- 可移植性差:只能通過Java語言實現 ,無法跨語言進行序列化和反序列化。
- 性能差:序列化后的字節體積大,增加了傳輸/保存成本。
- 安全問題:輸入的反序列化的數據可被用戶控制,如果攻擊者惡意構造反序列化的數據,通Java的反序列化操作可能產生非預期對象,進而執行攻擊者構造的惡意代碼 造成嚴重后果
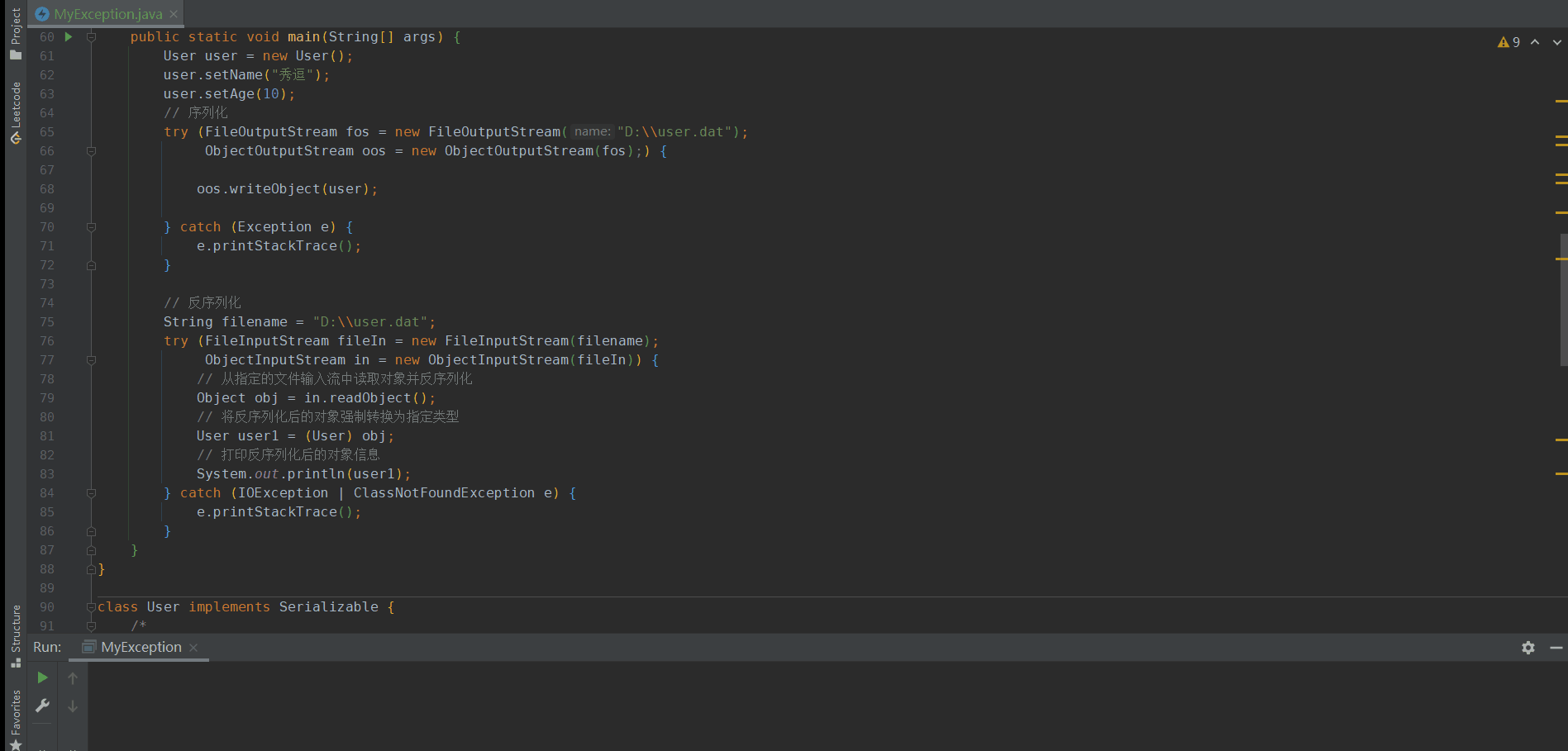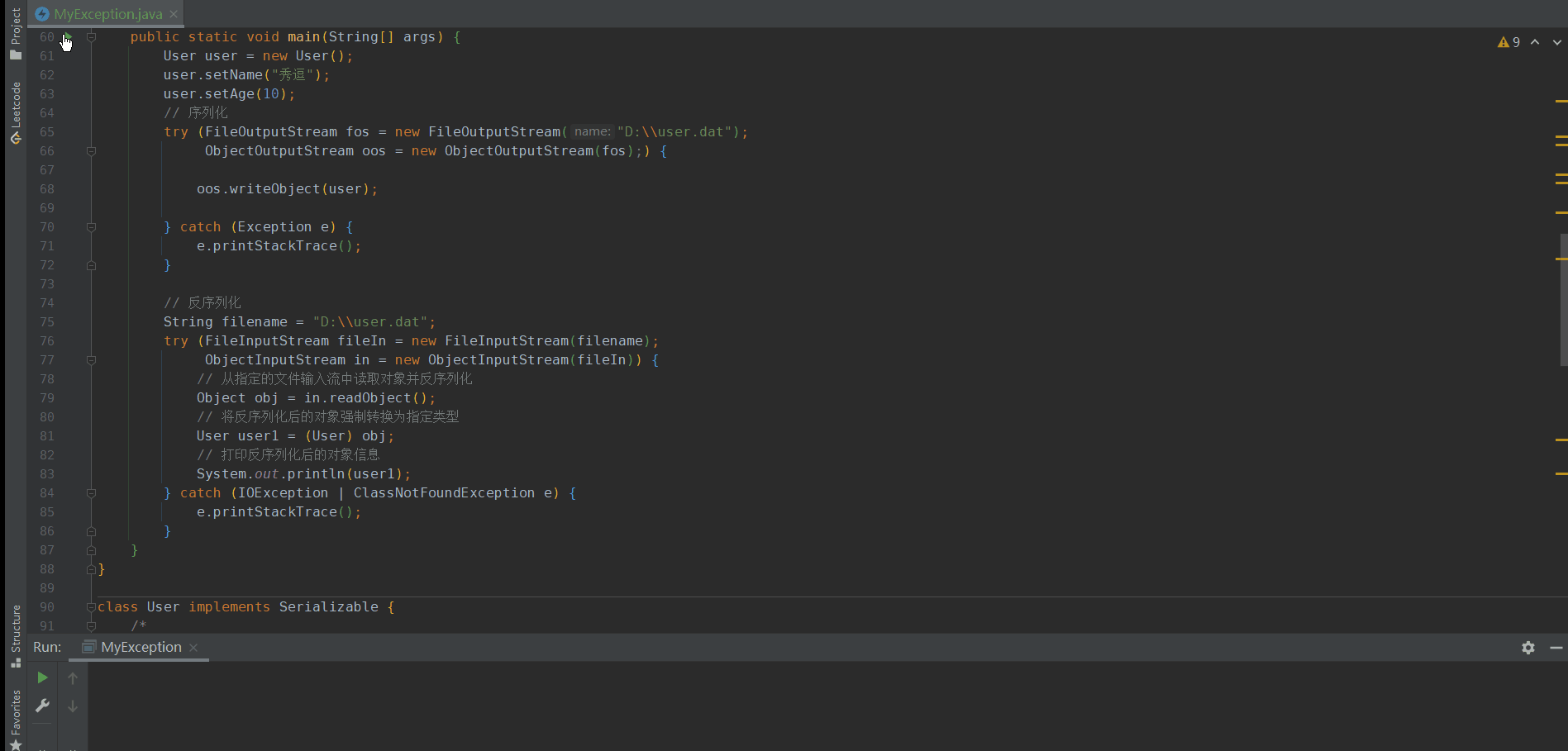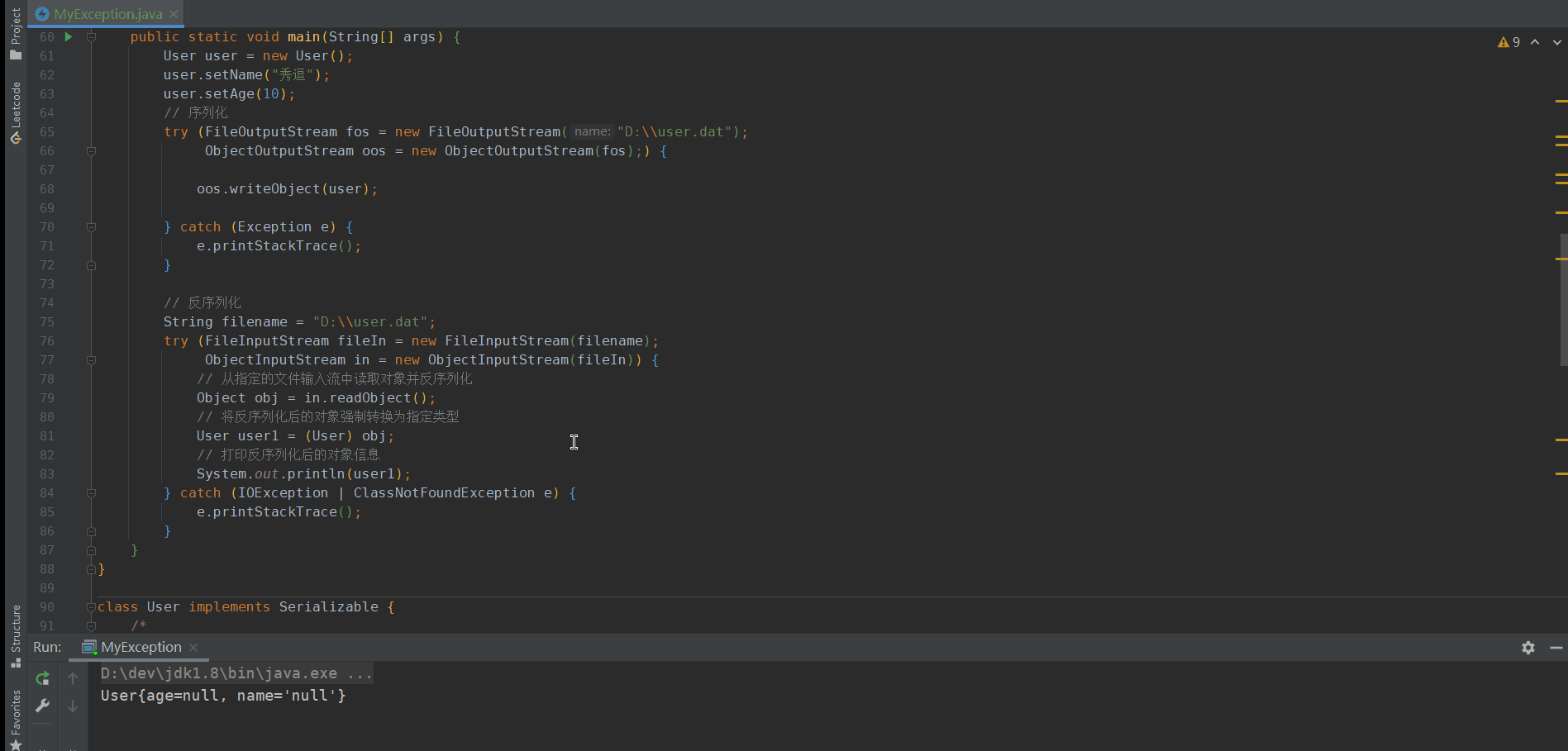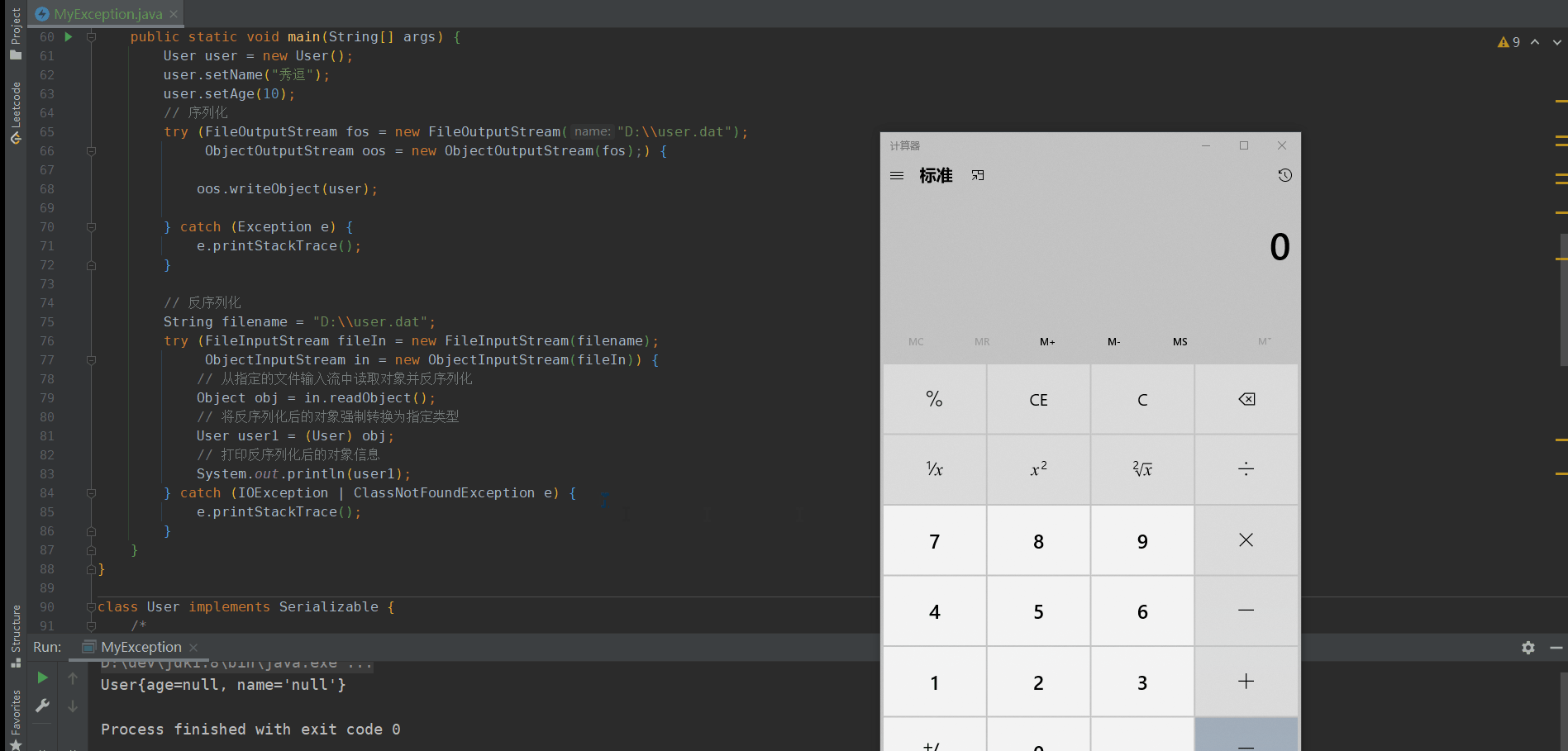
比如在序列化的對象中加下面一段代碼:
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException{ois.readObject();Runtime.getRuntime().exec("calc");}
就能打開window的計算器
因為Java 的序列化機制會通過反射在對象的反序列化過程中調用這個方法。這個方法的簽名必須是private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException。
這個機制提供了一個對象被反序列化時執行特定邏輯的機會,例如對特定字段進行初始化或進行額外的安全性檢查。然而,由于 readObject 方法可以執行自定義的邏輯,如果沒有嚴格的限制,惡意用戶就可能利用這一特性進行攻擊,因此需要謹慎使用。
第三方Java 序列化和反序列化庫
基于二進制的序列化協議
- Kryo
- Hessian
- Protobuf
- ProtoStuff
Kryo序列化舉例:
<!-- maven 引入 Kryo-->
<dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.4.0</version>
</dependency>
public static void main(String[] args) {Kryo kryo = new Kryo();kryo.register(User.class);User user = new User();user.setName("秀逗");user.setAge(10);try (Output output = new Output(new FileOutputStream("D:\\userKryo.dat"));){kryo.writeObject(output, user);} catch (FileNotFoundException e) {e.printStackTrace();}try (Input input = new Input(new FileInputStream("D:\\userKryo.dat"));){User user1 = kryo.readObject(input, User.class);System.out.println(user1);} catch (FileNotFoundException e) {e.printStackTrace();}}
比較下 相同對象 使用Java 的ObjectOutputStream 和使用Kryo 序列化后的文件大小
Kryo 比 ObjectOutputStream 小了20多倍

6、緩沖流
Java 的緩沖流是使用裝飾器模式 對字節流和字符流的一種封裝
目的是 使用緩沖區減少系統的 I/O 操作次數,從而提高系統的 I/O 效率
緩沖字節流:
對InputStream進行包裝 得到 BufferedInputStream (字節緩沖輸入流)
對OutputStream進行包裝 得到 BufferedOutputStream (字節緩沖輸出流)
緩沖字節流代碼示例:
public static void main(String[] args) throws IOException {try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("D:\\HRM_BETA.zip"));BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("D:\\HRM_BETA_COPY.zip"));){int b;while ((b = bufferedInputStream.read()) != -1) {bufferedOutputStream.write(b);}}catch (Exception e){throw e;}}
使用普通的字節流配合字節數組讀寫 速度也還可以 (當然緩沖字節流也可以使用數組讀寫):
public static void main(String[] args) throws IOException {try (InputStream inputStream = new FileInputStream("D:\\HRM_BETA.zip");OutputStream outputStream = new FileOutputStream("D:\\HRM_BETA_COPY.zip");){int len;byte[] bys = new byte[8*1024];while ((len = inputStream.read(bys)) != -1) {// 注意下后兩個參數 第一個是指數組bys的起始偏移量 第二個參數是指寫入數組bys的長度outputStream.write(bys,0,len);}}catch (Exception e){throw e;}}
緩沖字符流:
對Reader 進行包裝得到 BufferedReader (字符緩沖輸入流)
對Writer 進行包裝得到 BufferedWriter(字符緩沖輸出流)
緩沖字符流代碼示例:
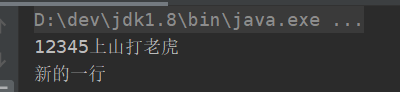
public static void main(String[] args) throws IOException {try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("D:\\123.txt"))){bufferedWriter.write("12345上山打老虎");bufferedWriter.newLine();bufferedWriter.write("新的一行");}catch (Exception e){throw e;}try (BufferedReader bufferedReader = new BufferedReader(new FileReader("D:\\123.txt"))){String line;while ((line = bufferedReader.readLine()) != null) {System.out.println(line);}}catch (Exception e){throw e;}}
運行結果:
7、Java 的IO流中涉及哪些設計模式
設計模式可以參考:https://blog.csdn.net/qq_37883866/article/details/115580862
**裝飾器模式:**動態地給一個對象添加一些額外的職責。提供了用子類擴展功能的一個靈活的替代,但比生成子類更為靈活。
在Java的IO體系中
FilterInputStream和FilterOutputStream 是兩個非常重要的裝飾器 他們分別繼承了抽象類 InputStream和OutputStream
我們可以利用 繼承 FilterInputStream或者FilterOutputStream 來動態地對輸入流或者輸出流添加一些功能 。比如添加緩沖、數據加密、計數等額外功能。
例如,BufferedInputStream 繼承 FilterInputStream ,它提供了緩沖功能,通過將原始輸入流包裝在 BufferedInputStream 中,可以提高讀取數據的性能。
我們也可以自定義一個流實現把輸入流內的大寫字母轉換為小寫字母:
public class LowerCaseInputStream extends FilterInputStream {protected LowerCaseInputStream(InputStream in) {super(in);}public int read() throws java.io.IOException {int c = super.read();return (c == -1 ? c : Character.toLowerCase((char)c));}public int read(byte[] b, int off, int len) throws java.io.IOException {int c = super.read(b, off, len);if (c != -1) {for (int i = off; i < off + c; i++) {b[i] = (byte)Character.toLowerCase((char)b[i]);}}return c;}
}// 測試方法
public static void main(String[] args) {String file = "C:\\Users\\Administrator\\Desktop\\123.txt";int c;try {InputStream in =new BufferedInputStream(new FileInputStream(file));while ((c = in.read()) >= 0) {System.out.print((char) c);}in.close();} catch (IOException e) {e.printStackTrace();}System.out.println();try {// 使用包裝類InputStream in =new LowerCaseInputStream(new BufferedInputStream(new FileInputStream(file)));while ((c = in.read()) >= 0) {System.out.print((char) c);}in.close();} catch (IOException e) {e.printStackTrace();}}
效果:
文件
輸出:

適配器模式:
將一個類的接口轉換成客戶希望的另外一個接口。使得原本不相容的接口可以協同工作。
InputStreamReader 和 OutputStreamWriter就是兩個適配器
分別用來適配 InputStream和OutputStream
通過適配器,我們可以將字節流對象適配成字符流對象,這樣我們可以直接通過字節流對象來讀取或者寫入字符數據。
InputStreamReader 和 OutputStreamWriter也就是常說的轉換流
其中InputStreamReader將字節輸入流轉為字符輸入流,繼承自Reader。
OutputStreamWriter是將字符輸出流轉為字節輸出流,繼承自Writer。(注意是 字符輸出流轉為字節輸出流)
字符編碼和字符集 這部分內容參考:https://blog.51cto.com/u_16213662/7427967
計算機中使用二進制數字 0 1 存儲數據,我們在電腦上看到的文字信息是通過將二進制轉換之后顯示的,兩者之間的轉換其實是編碼與解碼的過程。而編碼和解碼轉換之間是需要遵循規則的,即編碼和解碼都遵循同一種規則才能將文字信息正常顯示,如果編碼跟解碼使用了不同的規則,就會出現亂碼的情況。
轉換流,核心就是編碼和解碼過程:
編碼:字符 、字符串 ( 能看懂的 ) -----------> 字節(看不懂的)
解碼:字節( 看不懂的 ) -----------> 字符、字符串(能看懂的)
編碼與解碼的過程需要遵循的規則,其實就是不同的字符編碼。我們最早接觸的是ASCII碼,它主要是用來顯示英文和一些符號,到后面還有編碼規則中常用的有:gbk,utf-8等。它們分別屬于不同的編碼集。
encoding是charset encoding的簡寫,即字符集編碼,簡稱編碼。
charset是character set的簡寫,即字符集。
得出編碼是依賴于字符集的,一個字符集可以有多個編碼實現
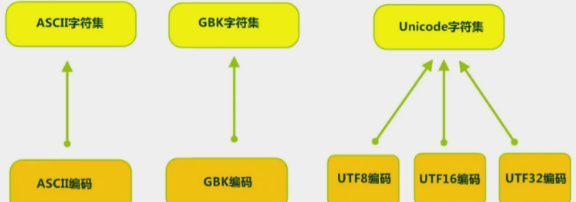
使用示例:
InputStreamReader(InputStream in):創建一個默認字符集字符輸入流。
InputStreamReader(InputStream in, String charsetName):創建一個指定字符集的字符流。
InputStreamReader isr1 = new InputStreamReader(new FileInputStream("D:\\utf-8.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("D:\\utf8.txt"),"UTF-8");OutputStreamWriter(OutputStream in): 創建一個使用默認字符集的字符流。
OutputStreamWriter(OutputStream in, String charsetName): 創建一個指定字符集的字符流。
OutputStreamWriter isr1 = new OutputStreamWriter(new FileOutputStream("gbk.txt""));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("gbk1.txt") , "GBK");
如果沒有指定字符集,則默認會使用平臺默認的字符編碼。
在不同的操作系統上,平臺默認的字符編碼可能不同。在大多數情況下,Windows 系統上的默認字符編碼是 Windows 系統默認的代碼頁(如GBK或Windows-1252),而在類 Unix 系統上通常是 UTF-8。
推薦指定字符集為 StandardCharsets.UTF_8
public static void main(String[] args) {try (OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("123.txt"), StandardCharsets.UTF_8);){osw.write("中國");} catch (IOException e) {e.printStackTrace();}try (InputStreamReader isr = new InputStreamReader(new FileInputStream("123.txt"), StandardCharsets.UTF_8);){//一次讀取一個字符數據int ch;while ((ch = isr.read()) != -1) {System.out.print((char) ch);}} catch (Exception e) {e.printStackTrace();}}





spi設備使用)
——Python編程基礎)











GTM常見配置問題總結)
