文章目錄
- 前言
- 一.冒泡排序
- 二.選擇排序
- 三.插入排序
- 四.希爾排序
- 五.堆排序
- 六.快速排序
- hoare
- 挖坑法
- 前后指針
- 快排遞歸實現:
- 快排非遞歸實現:
- 七、歸并排序
- 歸并遞歸實現:
- 歸并非遞歸實現:
- 八、各個排序的對比圖
前言
- 排序:所謂排序,就是使一串記錄,按照其中的某個或某些關鍵字的大小, 遞增或遞減的排列起來的操作。
- 穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序算法是穩定的;否則稱為不穩定的。
- 內部排序:數據元素全部放在內存中的排序。
- 外部排序:數據元素太多不能同時放在內存中,根據排序過程的要求不能在內外存之間移動數據的排序
接下來會涉及到的排序

這里寫了一個測試排序性能的代碼,方便我們觀察各個排序的好壞
//測試排序的性能
void TestOP()
{srand((unsigned)time(NULL));//N的數值手動改變,以判斷性能的好壞const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand() + i;a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("MergeSort:%d\n", end6 - begin6);printf("BubbleSort:%d\n", end7 - begin7);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);
}
還有交換函數
//交換函數
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
以下排序默認是升序,即從小到大的順序
一.冒泡排序
冒泡的時間復雜度是O(N^2),空間復雜度是O(1),具有穩定性

從圖中我們可以看出,冒泡排序其實就是一種選擇排序,即走一次,找到最大的數放在最右邊,接下來要排序的數據就少了一個,再走一次,找到此時最大的數放在此時的最右邊,接下來不斷重復此步驟,數據就有序了
//冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int flag = 0;for (int j = 0; j < n - 1 - i; j++){if (a[j] > a[j + 1]){Swap(&a[j], &a[j + 1]);flag = 1;}}if (flag == 0){return;}}
}
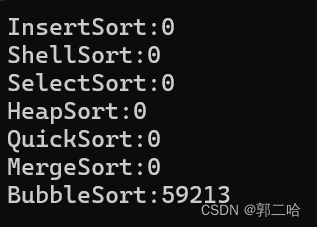
雖然我們使用了flag進行了優化,使冒泡排序在最好的情況下的時間復雜度位O(N),但是實際上冒泡排序只有教學意義,沒有實踐意義,效率非常低
在十萬個數據下面,冒泡走了5s,而在一百萬數據下面,走了接近1min了,可見效率是如此的低下

二.選擇排序
選擇排序的時間復雜度是O(N^2),空間復雜度是O(1),具有不穩定性

從圖中我們可以清楚的看到,選擇排序每走一次,找到最大或者最小的數據放在最右邊或者最左邊,然后減少排序的個數,以此類推完成排序
這個排序方法可以優化一下,即走一次找到最小的同時找到最大的
//選擇排序
void SelectSort(int* a, int n)
{int begin = 0;int end = n - 1;while (begin < end){int mini = begin;int maxi = begin;for (int i = begin + 1; i <= end; i++){if (a[i] < a[mini]){mini = i;}if (a[i] > a[maxi]){maxi = i;}}Swap(&a[begin], &a[mini]);if (maxi == begin){maxi = mini;}Swap(&a[end], &a[maxi]);begin++;end--;}
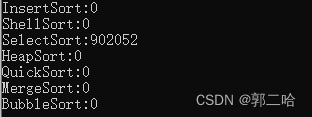
} 選擇排序即沒有實際意義,也沒有教學意義,效率低下
在十萬個數據下面,選擇走了8s,而在一百萬數據下面,走了接近15min了,效率不行

三.插入排序
插入排序的時間復雜度是O(N^2),空間復雜度是O(1),具有穩定性

插入排序的思路就是假設在[0,end]是有序的數據,在end+1的位置上插入一個新的數據,用tmp保存插入的數據。
如果end位置上的值大于tmp,end就減1,比較此時end位置上的值與tmp的大小
如果end位置上的值小于tmp,退出循環,將tmp賦給end + 1 位置上的值
//插入排序
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;//[0,end]是有序的,插入[end+1]數據int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
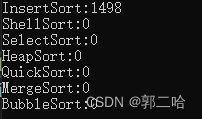
雖然插入排序的時間復雜度是O(N^2),但是它具有實踐意義
在十萬個數據下面,走了1s,在一百萬數據下面,走了16s了,可見效率是還可以
四.希爾排序
希爾排序的時間復雜度是O(N^1.3),空間復雜度是O(1),不具有穩定性

希爾排序(Shell Sort)是插入排序的一種。也稱縮小增量排序,是直接插入排序算法的一種更高效的改進版本。
希爾排序的思想:
- 預排序:先分gap,在各自的組內進行插入排序
- 插入排序:排好序后,減小gap的值,再次進行預排序,直到gap = 1,進行插入排序,這樣數據就有序了
假設gap = 3,將原數據分成3組,那么第一趟預排序的結果為下圖
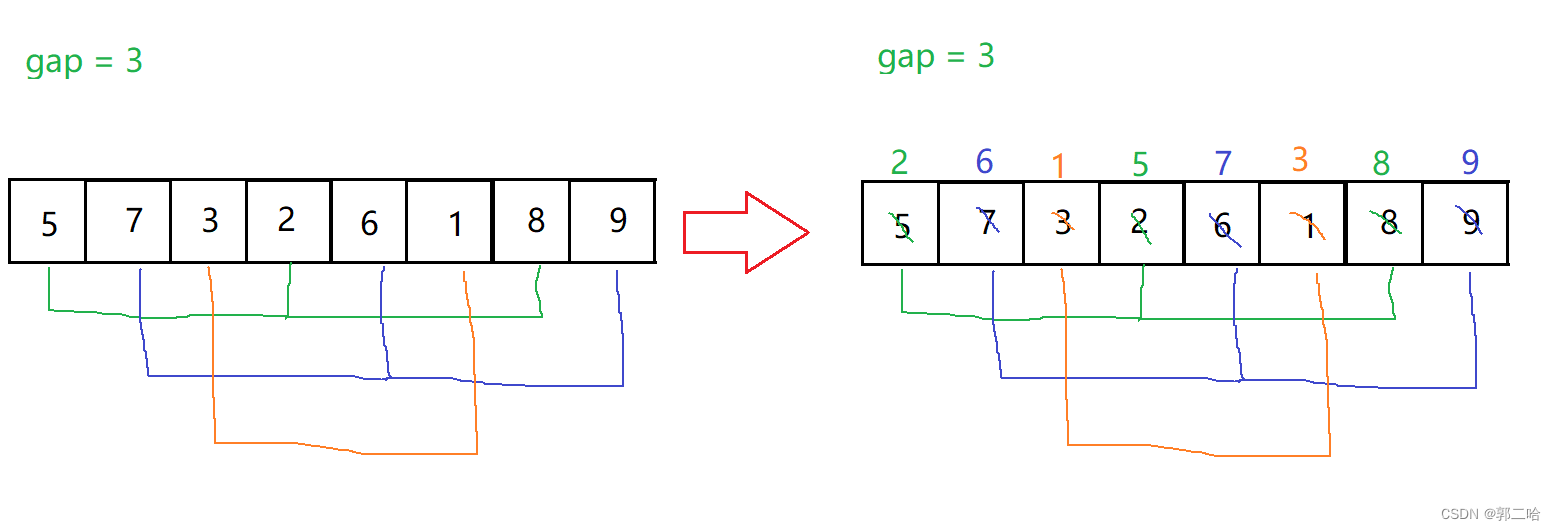
可以看到在走了一趟后的數據,比原始數據接近有序,這就是希爾排序的優點
//希爾排序
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//多組一起走for (int i = 0; i < n-gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
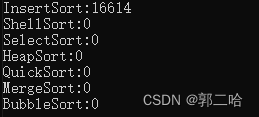
在十萬個數據下面,希爾走了31ms,在一百萬數據下面,走了264ms,可見效率還是很快的


五.堆排序
堆排序的時間復雜度是O(NlogN),空間復雜度是O(1),不具有穩定性

堆排序(Heap Sort)是指利用堆這種數據結構所設計的一種排序算法。堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點。
堆排序的基本思想是:
- 將待排序序列構造成一個大頂堆,此時,整個序列的最大值就是堆頂的根節點。
- 將其與末尾元素進行交換,此時末尾就為最大值。
- 然后將剩余n-1 個元素重新構造成一個堆,這樣會得到 n 個元素的次小值。 如此反復執行,便能得到一個有序序列了。
//向下調整法
void AdjustDown(int* a, int n, int parent)
{int child = 2 * parent + 1;while (child < n){if (child + 1 < n && a[child + 1] > a[child]){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}//堆排序
void HeapSort(int* a, int n)
{//創建堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}//排序int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}
在十萬個數據下面,堆排走了45ms,在一百萬數據下面,走了473ms,效率還可以


六.快速排序
快速排序的平均時間復雜度是O(NlogN),但是在最壞情況下有可能是O(N^2),空間復雜度是O(logN)~O(N),不具有穩定性

快速排序(Quick Sort)是一種常用的排序算法。快速排序的基本思想是通過選擇一個基準元素,將數組分為兩部分,使得左邊的元素都小于等于基準元素,右邊的元素都大于等于基準元素。然后,對左右兩部分分別進行快速排序,直到整個數組有序。
但是當數組已經有序時是最壞情況,快速排序的時間復雜度可能會達到O(N^2)。但是,在大多數情況下,快速排序的時間復雜度都非常接近O (NlogN)
快速排序優化的方法:
1.三數取中
可以看到假定最左邊的數作為基準元素,會不準確,因為有可能是最大的數也有可能是最小的數,影響效率,我們可以選擇三個數中間的數來作為基準元素
//三數取中法 left midi right
int GetMidi(int* a,int left,int right)
{int midi = (left + right) / 2;if (a[left] > a[midi]){if (a[midi] >= a[right]){return midi;}else if (a[left] < a[right]){return left;}else{return right;}}else{if (a[midi] <= a[right]){return midi;}else if (a[left] > a[right]){return left;}else{return right;}}
}
2.小區間優化
由于快速排序要遞歸數據區間,只要遞歸就要消耗空間,那么當數據區間比較小時,可以用插入排序,不用在遞歸了
//小區間排序 -> 插入排序
if ((right - left + 1) < 10)
{//注意數組取的位置和數組的長度InsertSort(a+left, right - left + 1);
}
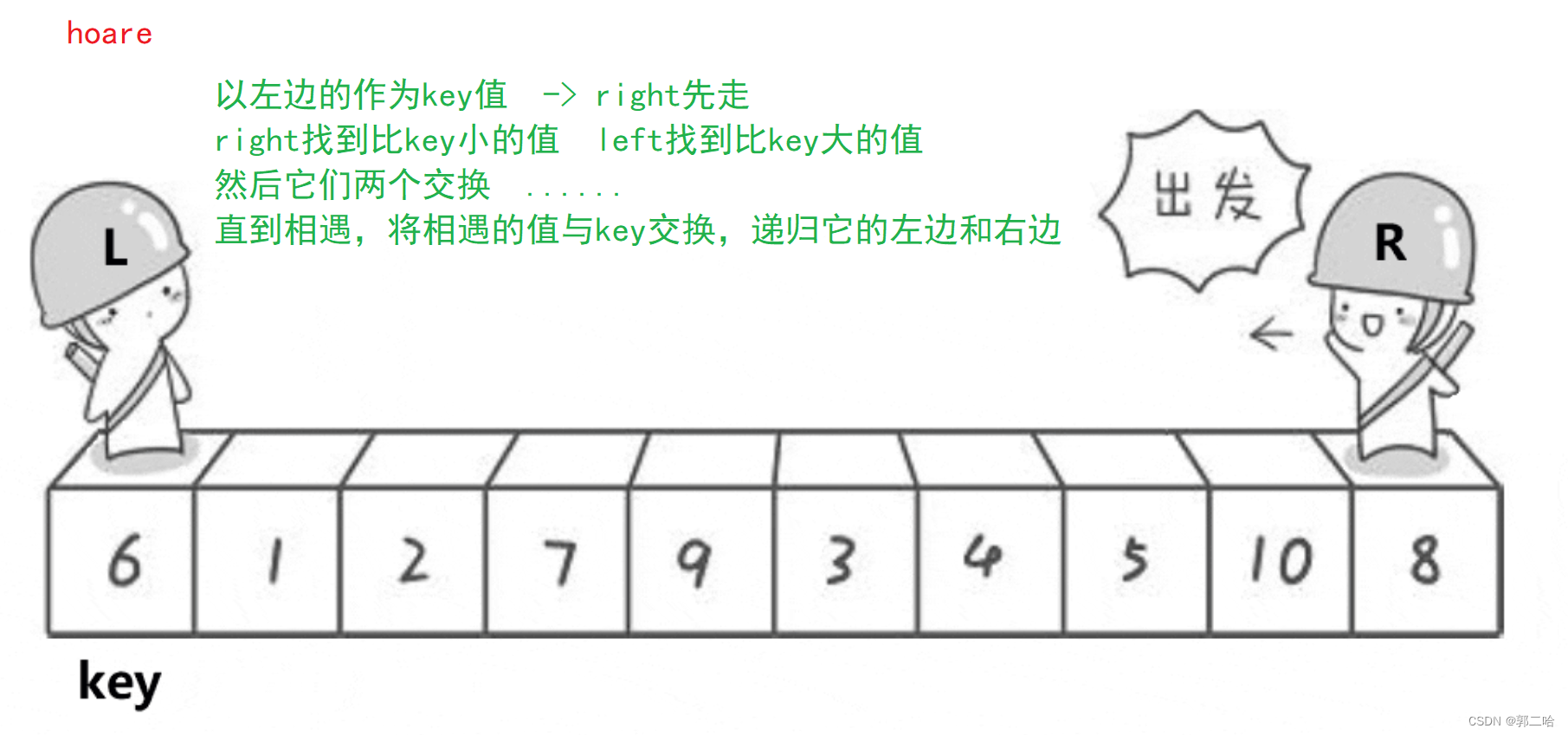
快速排序有三種排序方法:
hoare

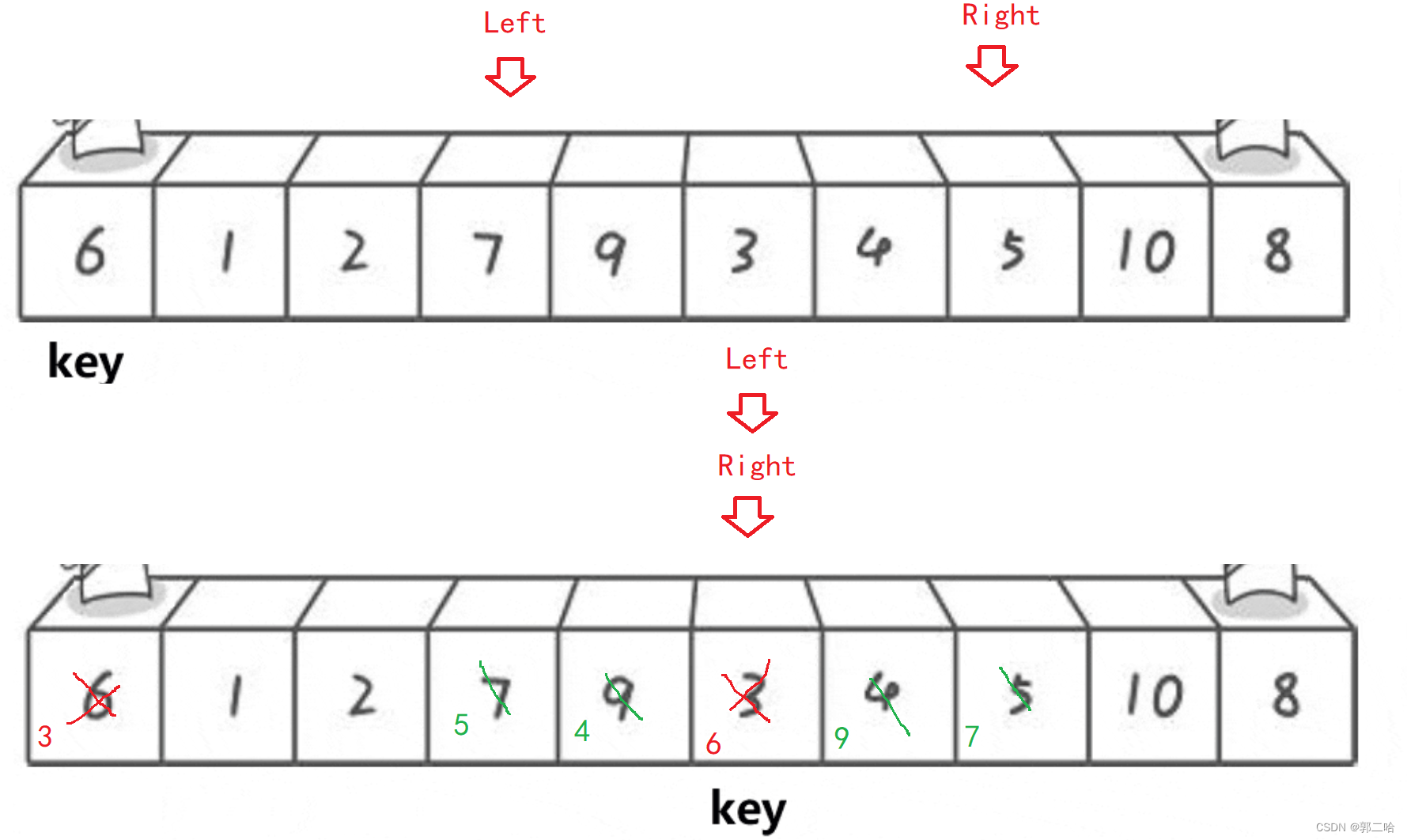
此時,數據6已經排好了,只需要遞歸它的左邊與右邊進行排序即可
// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{//三數取中int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int begin = left;int end = right;while (begin < end){while (begin < end && a[end] >= a[keyi]){end--;}while (begin < end && a[begin] <= a[keyi]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);return begin;
}
挖坑法

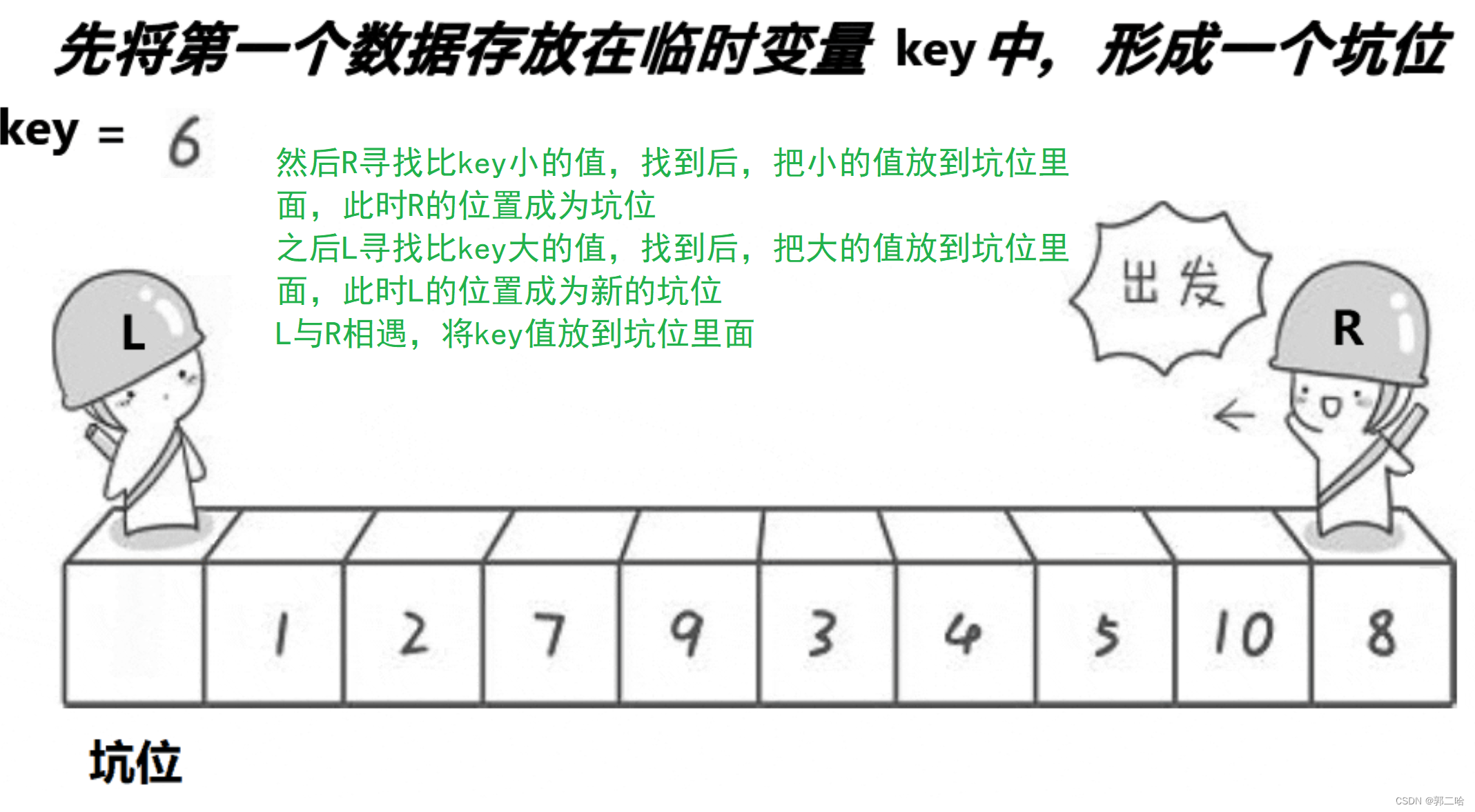
// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{//三數取中int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int key = a[left];int begin = left;int end = right;while (begin < end){while (begin < end && a[end] >= key){end--;}a[begin] = a[end];while (begin < end && a[begin] <= key){begin++;}a[end] = a[begin];}a[begin] = key;return begin;
}
前后指針


// 快速排序前后指針法
int PartSort3(int* a, int left, int right)
{//三數取中int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[keyi]);return prev;
}
快排遞歸實現:
以上三種方法針對的是每一次排序,我們還需要遞歸剩下的區間來完成數據的有效
void QuickSort(int* a, int left, int right)
{//[left,right]是閉區間if (left >= right){return;}//小區間排序 -> 插入排序if ((right - left + 1) < 10){//注意數組取的位置和數組的長度InsertSort(a+left, right - left + 1);}else{//隨便選擇一種排序方法即可int keyi = PartSort3(a,left,right);//[left,keyi-1] keyi [keyi+1,right]//遞歸左邊與右邊QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}
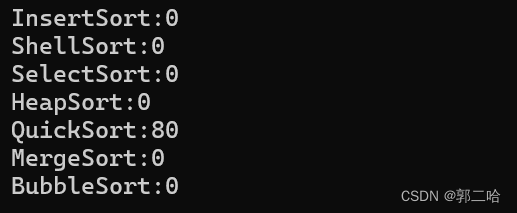
在十萬個數據下面,快速排序遞歸方法走了7ms,在一百萬數據下面,走了80ms,可見效率非常快

快排非遞歸實現:
眾所周知,遞歸會在棧上開辟空間,當遞歸的深度很大時,會導致棧溢出,這時我們可以把快速排序改成用非遞歸的形式實現
遞歸改為非遞歸的方法有兩種:
- 用循環實現
- 利用棧來實現
現在我們利用棧來實現,這里的棧是數據結構里面的棧。因為內存的棧的空間很小,而堆的空間很大,數據結構的棧就是在堆上開辟的
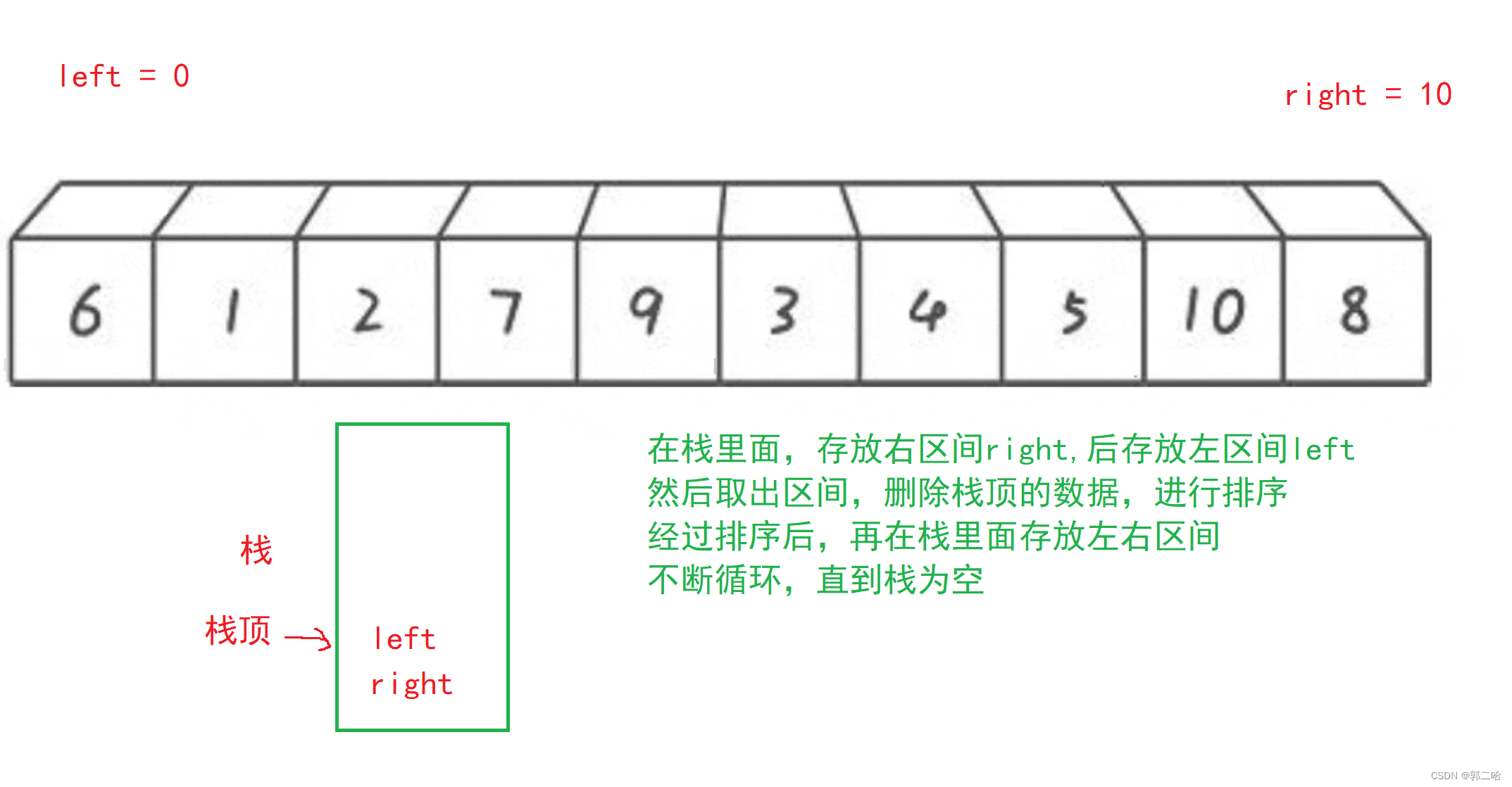
// 快速排序 非遞歸實現
//利用棧來實現
void QuickSortNonR(int* a, int left, int right)
{ST st;STInit(&st);STPush(&st, right);STPush(&st, left);while (!STEmpty(&st)){int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);int keyi = PartSort3(a, begin, end);//[begin,keyi-1] keyi [keyi+1,end]if (keyi + 1 < end){STPush(&st, end);STPush(&st, keyi + 1);}if (begin < keyi - 1){STPush(&st, keyi - 1);STPush(&st, begin);}}STDestroy(&st);
}
在十萬個數據下面,快速排序非遞歸方法走了19ms,在一百萬數據下面,走了283ms,可見效率與遞歸方法的差不多


七、歸并排序
歸并排序的時間復雜度是O(NlongN),空間復雜度是O(N),具有穩定性

歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序算法,該算法是采用分治法(Divide
andConquer)的一個非常典型的應用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為二路歸并。
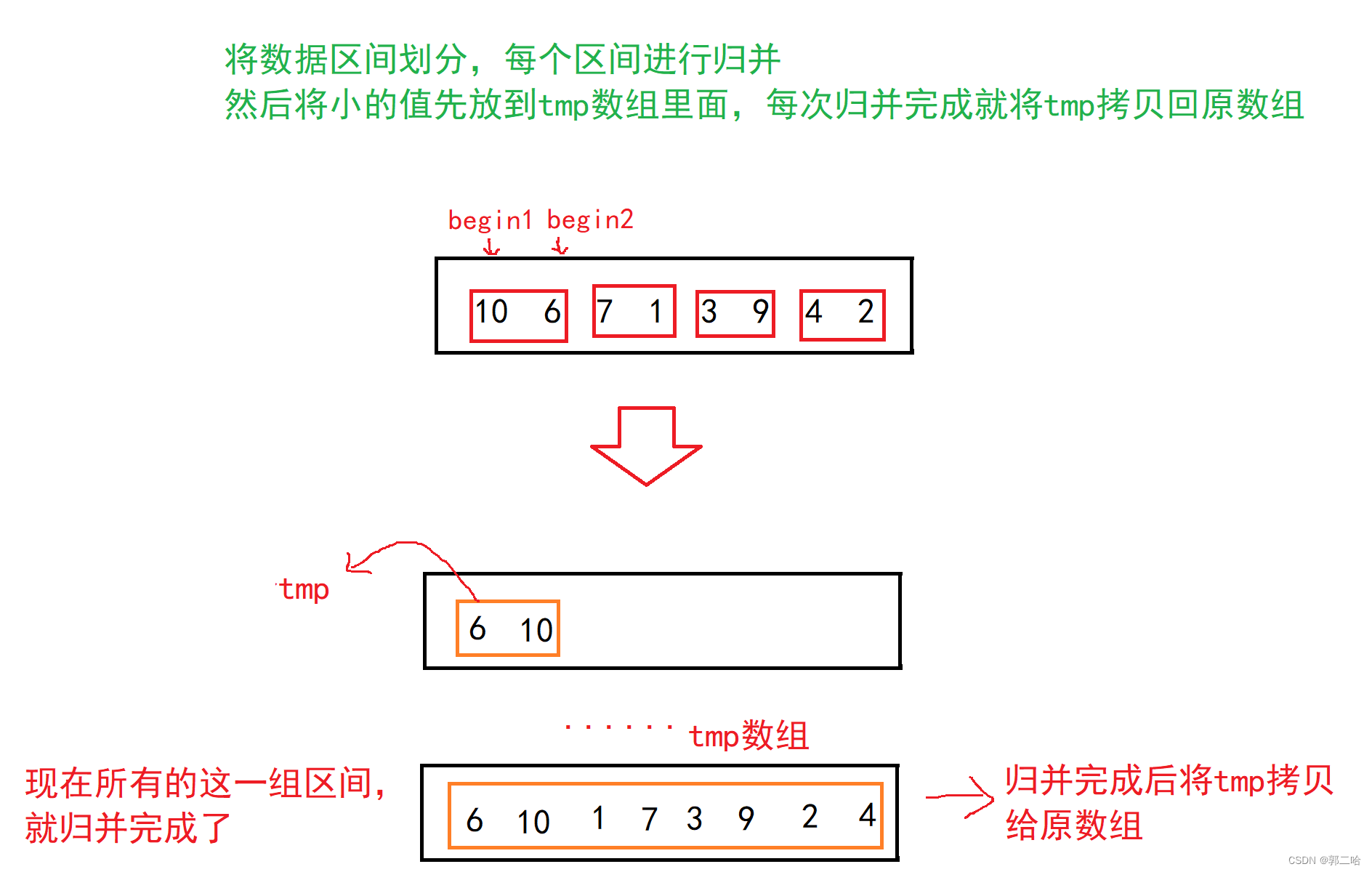
歸并排序核心步驟:
將數據劃分區間,區間大小從小到大,每個區間進行歸并,歸并完成后就要拷貝回去
歸并遞歸實現:
void _MergeSort(int* a, int* tmp, int left,int right)
{//遞歸if (left >= right){return;}int mid = (left + right) / 2;//[left,mid][mid+1,right]_MergeSort(a, tmp, left, mid);_MergeSort(a, tmp, mid+1, right);//歸并int begin1 = left;int end1 = mid;int begin2 = mid + 1;int end2 = right;int i = left;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//拷貝memcpy(a + left, tmp + left, (right - left + 1) * sizeof(int));
}//歸并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(n * sizeof(int));if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);tmp = NULL;
}
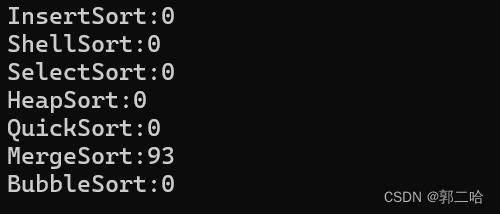
在十萬個數據下面,歸并排序遞歸方法走了9ms,在一百萬數據下面,走了93ms,可見效率非常快

歸并非遞歸實現:
上面我們提到遞歸會有棧溢出的問題,所有我們可以嘗試一下歸并的非遞歸的實現方法
遞歸改為非遞歸的方法有兩種:
- 用循環實現
- 利用棧來實現
這次我們使用循環來實現,歸并的核心就是分區間進行排序,既然如此, 我們可以設置分組gap的初始值為1,然后歸并一次,歸并完成后gap乘以2,來進行下一次的歸并區間,不斷重復此步驟直到gap 大于等于 數組長度時退出循環
//歸并排序 非遞歸實現
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}//分組排序 每次兩個gap組進行歸并排序int gap = 1;while (gap < n){for (int i = 0; i < n; i+=2*gap){int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;int j = i;//printf("[%d,%d],[%d,%d]", begin1, end1, begin2, end2);//如果begin2越界了,就不歸并if (begin2 >= n){break;}//如果end2越界了,就修正if (end2 >= n){end2 = n - 1;}//歸并排序while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}//拷貝memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}
在十萬個數據下面,歸并排序非遞歸方法走了9ms,在一百萬數據下面,走了87ms,可見效率非常快


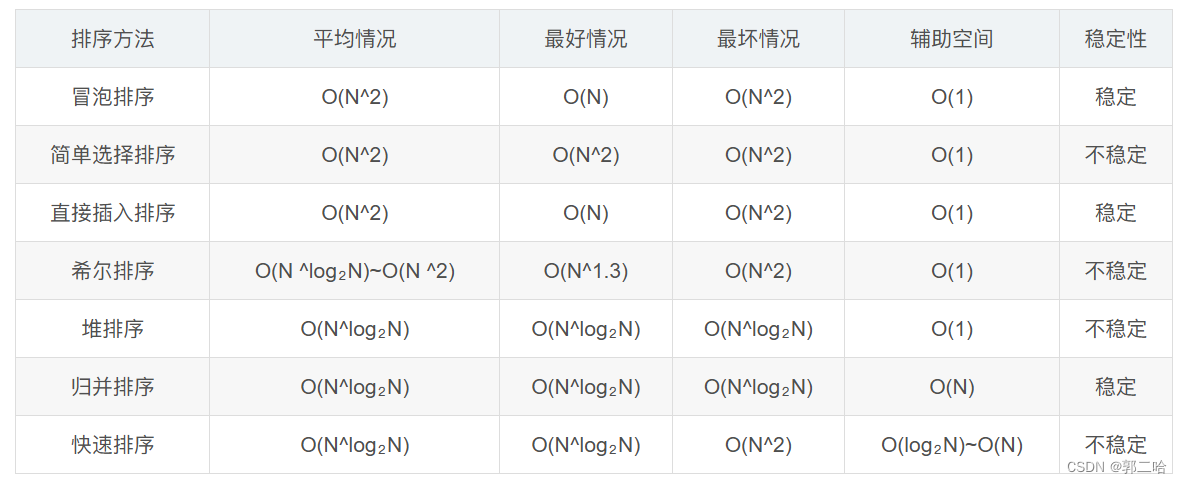
八、各個排序的對比圖


代碼實踐 -計算機視覺-45多尺度目標檢測)


安裝多個jdk,Mac卸載jdk)













