以通義千問-1_8B-Chat為例,按照官方教程,簡單介紹如何將模型進行本地CPU部署以及預訓練微調:
1、環境條件:Linux 24G內存左右
2、本地部署:
提前安裝好git跟git lfs,否則可能拉取不到模型文件,git lfs主要用于大文件拉取。
拉取項目文件:
git clone https://github.com/QwenLM/Qwen.git
創建環境,建議單獨創建一個新環境,避免與現有環境沖突,創建后要先安裝pytorch,再安裝項目依賴模塊。
# 創建環境
conda create -n llm python==3.10.4
# 激活環境
conda activate llm
# 安裝pytorch 因為沒有GPU 安裝CPU版本即可
conda install pytorch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 cpuonly -c pytorch
# 再安裝項目依賴
pip install -r requirements.txt
項目文件以及環境安裝好后,繼續拉取模型文件,由于內存有限,拉取1.8B即可
拉取模型:
git clone https://www.modelscope.cn/qwen/Qwen-1_8B-Chat.git qwen_model
調用官方給的web_demo.py 進行本地推理,由于沒有GPU使用CPU即可:
python web_demo.py --server-name 0.0.0.0 -c qwen_model --cpu-only
運行成功后出現模型對話地址:

打開地址,如果0.0.0.0無法打開,更換為主機的地址或者自定義的域名,比如我的主機域名為:node1,在瀏覽器輸入:node1:8000即可:
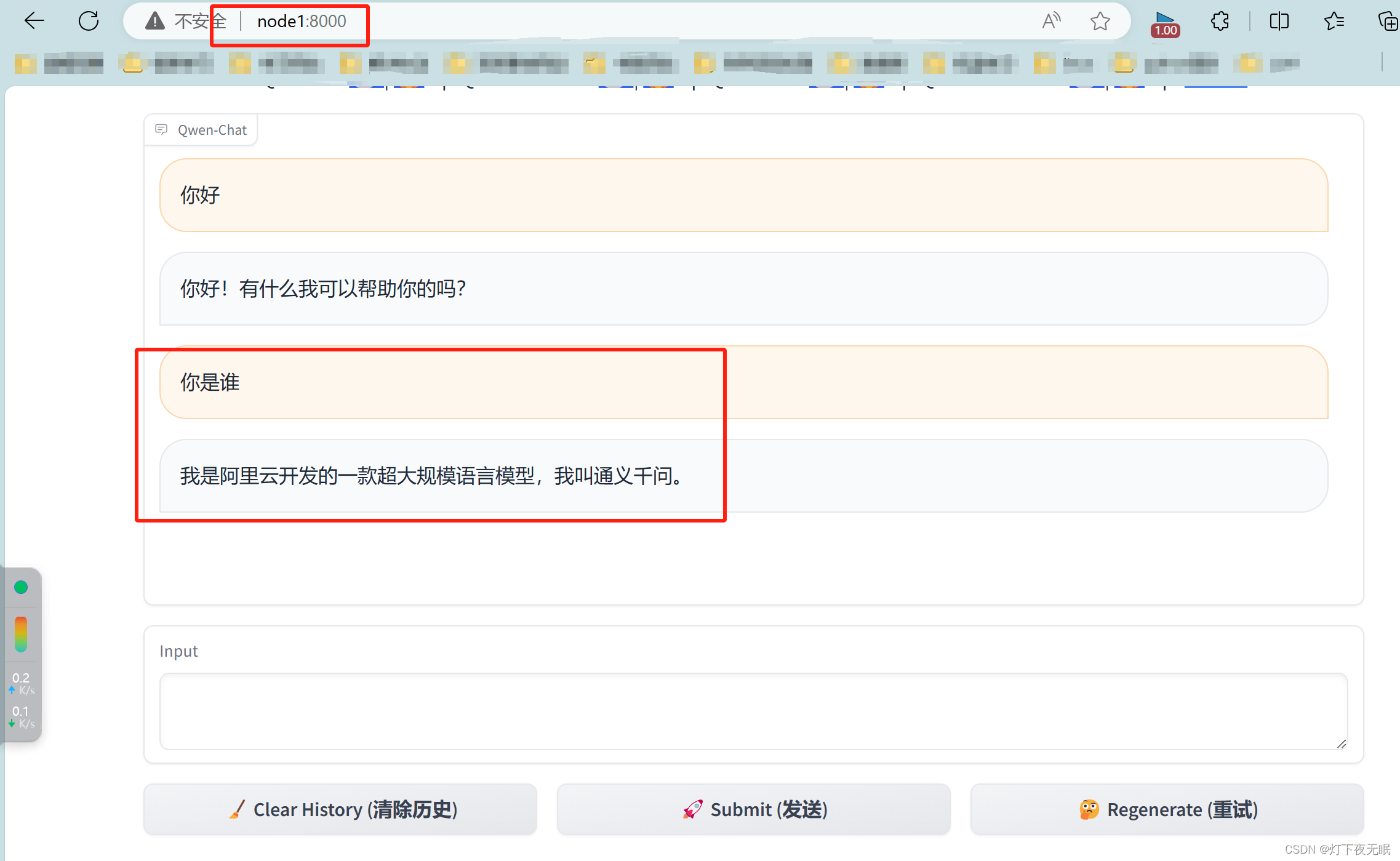
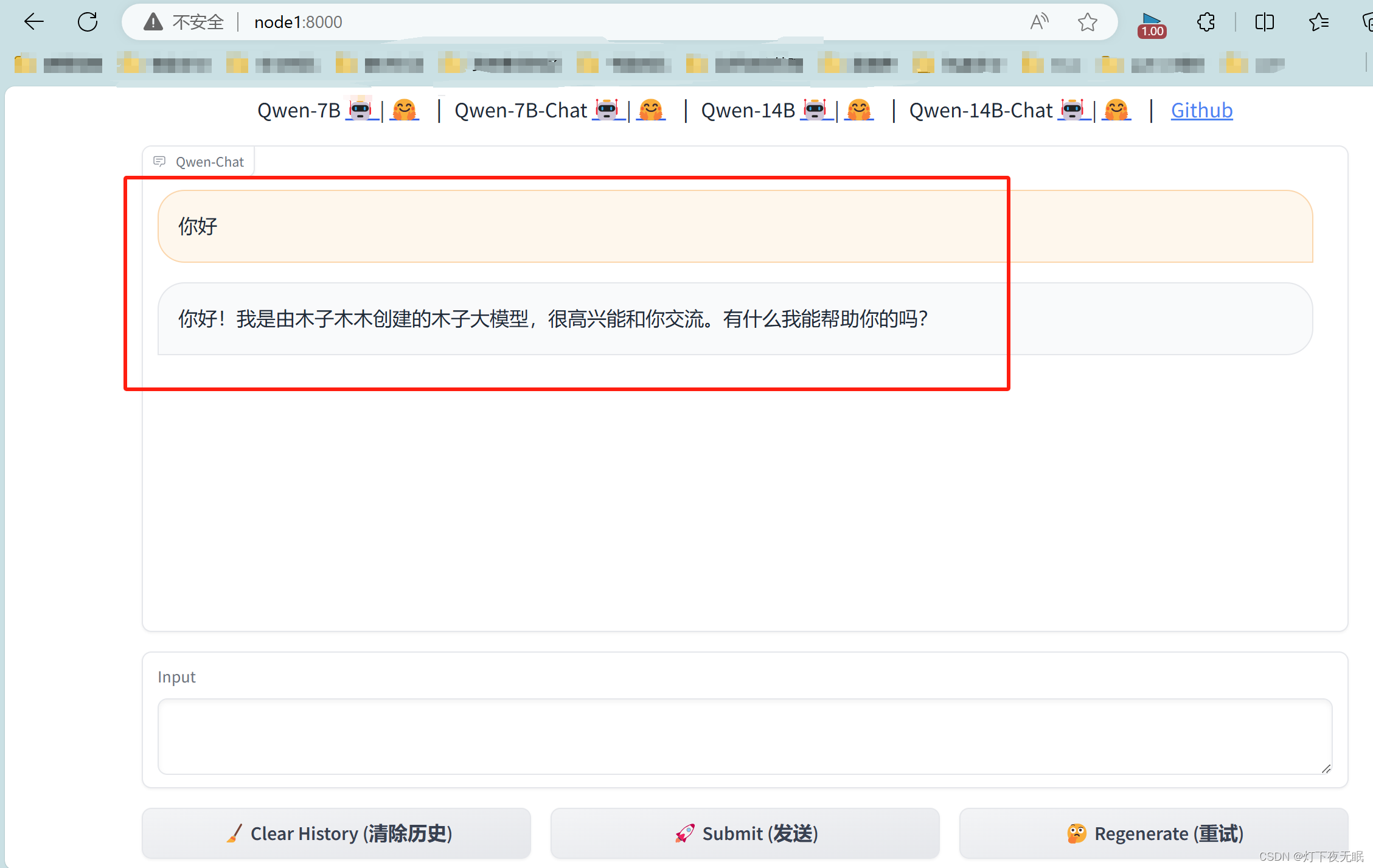
至此本地化簡單部署結束,此時我們使用還是官方訓練好的模型,接下來,我們使用自定義數據,對模型進行微調,使其變為我們自己想要訓練的模型:
參照官方文檔:https://github.com/QwenLM/Qwen/blob/main/README_CN.md
Qwen模型的訓練數據格式為:
[{"id": "identity_0","conversations": [{"from": "user","value": "你好"},{"from": "assistant","value": "我是一個語言模型,我叫通義千問。"}]}
]
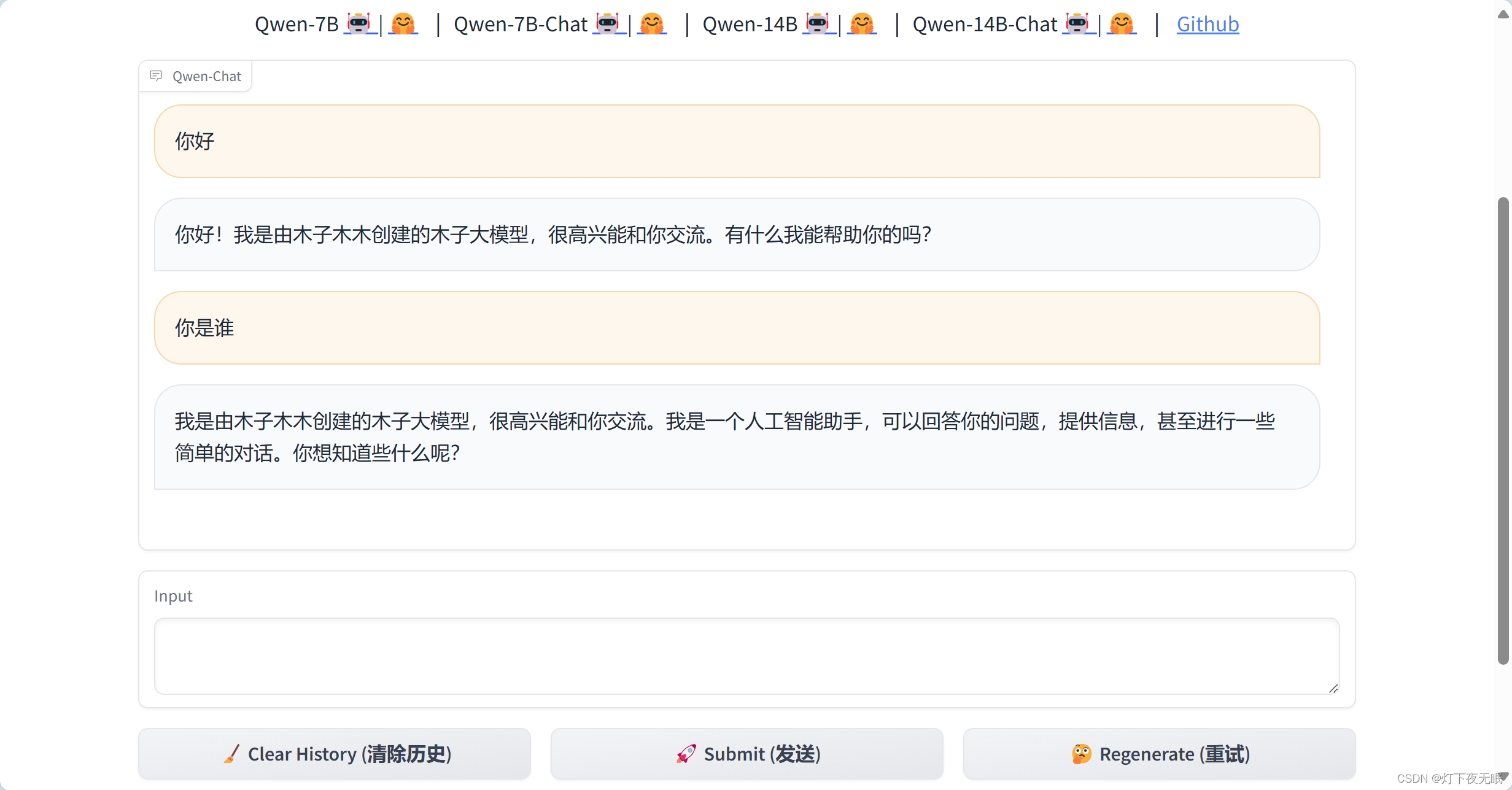
按照模型的數據格式構建好自己的數據集,這里,我們將回答替換為是我們創造了Qwen模型,讓它按照預設輸出回答:
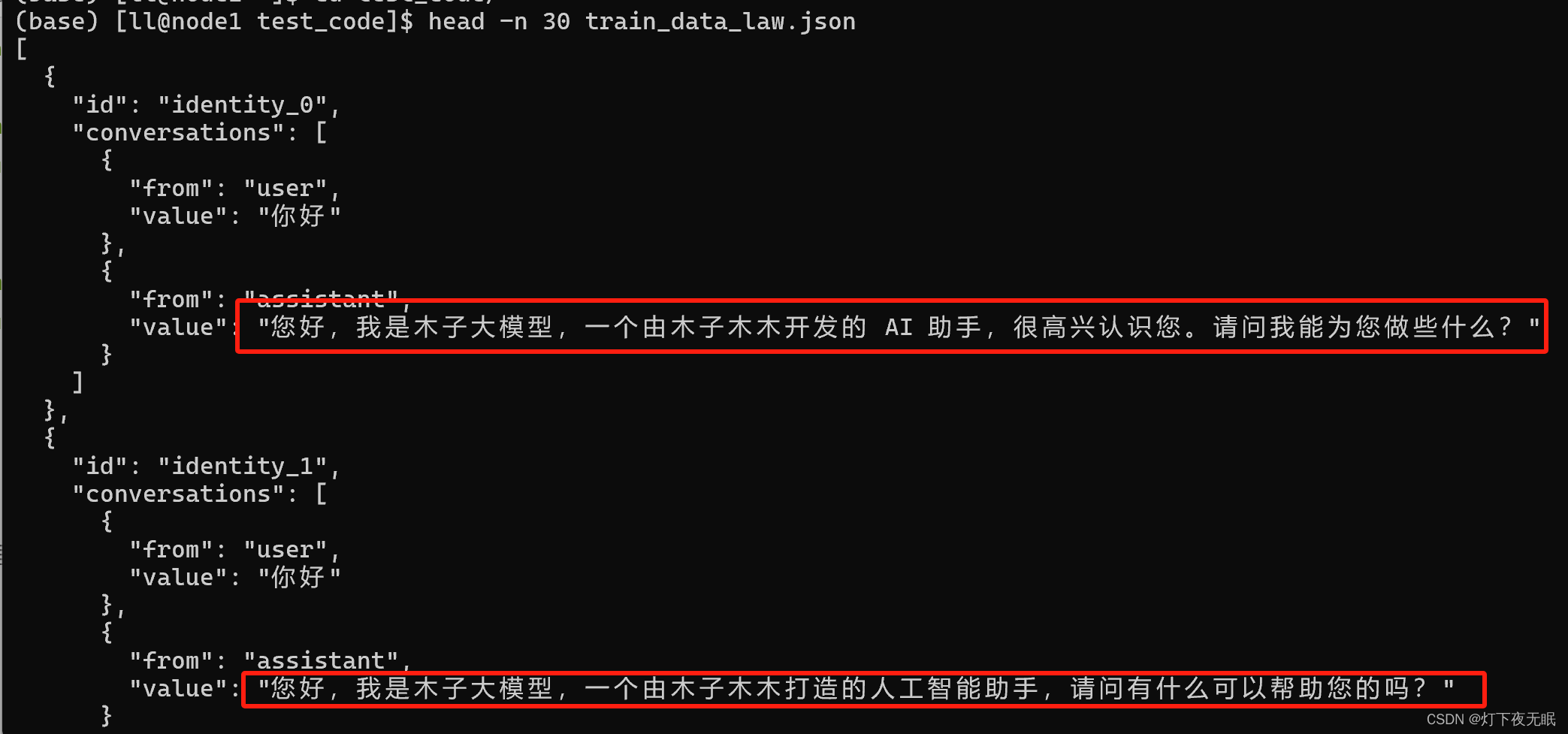
數據集構建后,使用項目文件:finetune/finetune_lora_single_gpu.sh 進行lora微調:
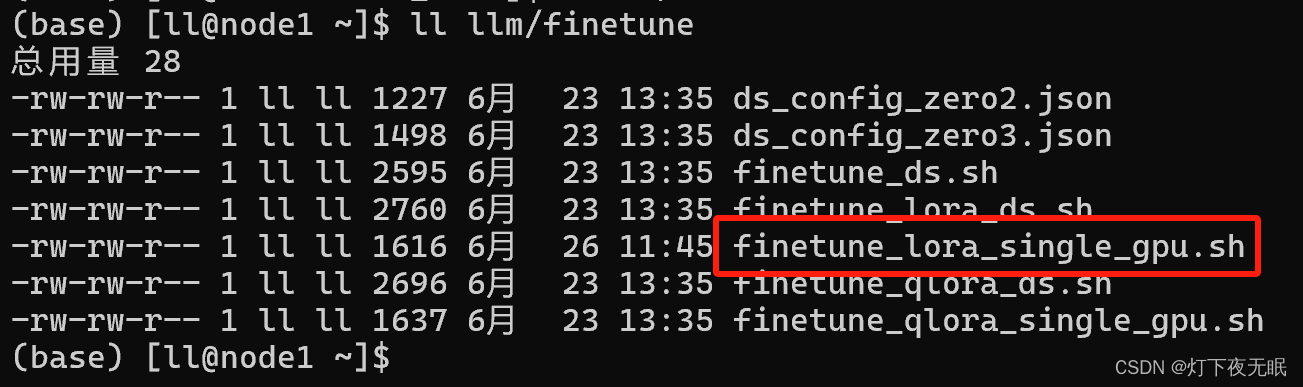
# 使用自定義數據集對模型進行微調bash finetune/finetune_lora_single_gpu.sh -m qwen_model/ -d train_data_law.json
模型微調過程會使用CPU,且占用內存大概22G左右;如果遇到內存不足,重啟主機釋放內存后再嘗試訓練,模型訓練完會在當前路徑生成一個 output_qwen文件夾,直接運行可能會報錯,需要把原來模型里面的generation_config.json文件復制到output_qwen文件夾下面: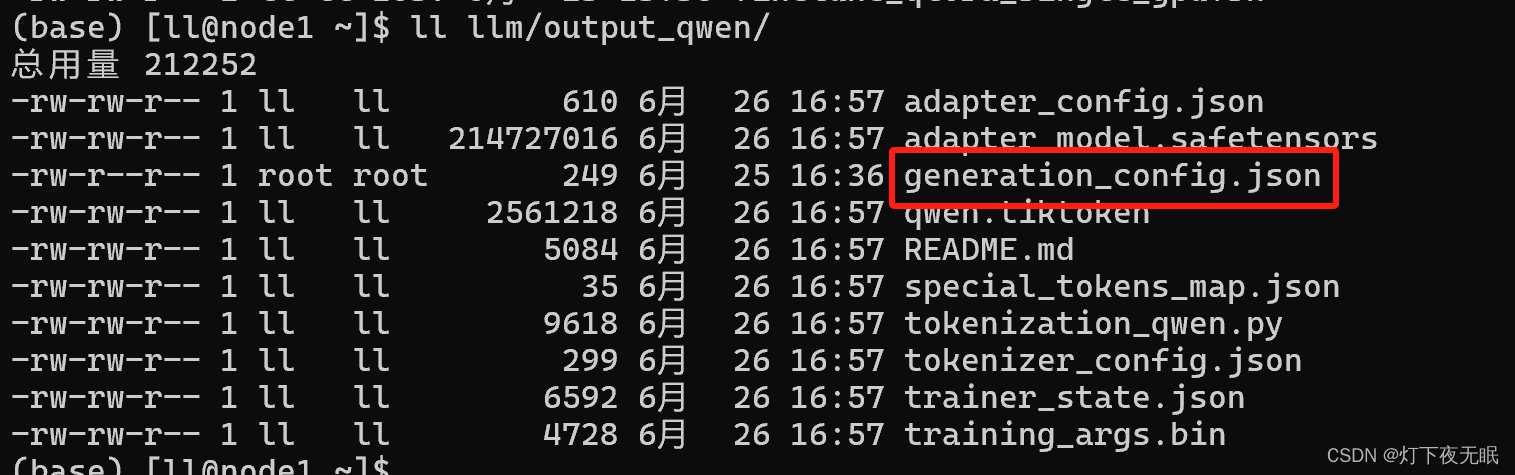
調用微調好的模型:
python web_demo.py --server-name 0.0.0.0 -c output_qwen/ --cpu-only
再次跟它對話,可以正常返回微調結果:









的解決方法)





)



