正則表達式雖然可以處理包含了諸如 HTML 或 XML 內容的字符串,但只能根據文本的
特征匹配字符串,而忽略字符串所包含的內容的真實格式。為了解決這個問題,Python 引入
XPath 以及支持 XPath 的第三方庫 lxml,專門對 XML 或 HTML 格式的數據進行解析。接下來,
本節將針對 XPath 和 lxml 的相關內容進行詳細介紹。
一、XPath 簡介
XPath 即 XML 路徑查詢語言(XML Path Language),是一種用于確定 XML 文檔中部分
節點位置的語言。它起初只支持搜索 XML 文檔,更新后能支持搜索 HTML 文檔。截至完稿
時,XPath 的最新版本為 XPath3.1。
那么 XPath 是如何搜索 XML 或 HTML 文檔呢?其實 XPath 基于 XML 或 HTML 的節點
樹,沿著節點樹的節點關系定位到目標節點所在的位置,并選取節點或節點集。為了形象地
描述出搜索節點的路徑,XPath 提供了簡潔明了的路徑表達式,通過路徑表達式可以快速地定
位與選取 XML 或 HTML 文檔中的一個節點或者一組節點集。
與正則表達式相比,路徑表達式的搜索方式大不相同。在這里,我們借用一個形象的例
子進行比較。假如我們把選取目標節點比作找金燕龍辦公樓。如果我們通過正則表達式查找,
則正則表達式會告訴我們辦公樓有哪些特征,辦公樓的左邊有哪些建筑、右邊有哪些建筑。
這樣的描述限定的查找范圍比較寬泛,查找起來比較煩瑣。如果我們通過路徑表達式查找,
則路徑表達式會直接告訴我們辦公樓的具體位置,即中國北京市昌平區建材城西路金燕龍辦
公樓。這樣的描述更加精準、更易查找。
路徑表達式描述了從一個節點到另一個節點或一組節點的路徑。這些路徑與在常規的計算
機文件系統中見到的路徑非常相似。例如,“/學生名單/班級/學生/籍貫”就是一個路徑表達式,
該路徑表達式也是用“/”字符進行分隔的,只不過它分隔的是節點,而不是目錄。接下來,通
過一張示意圖來描述 XML 文檔、XML 節點樹與路徑表達式的關系,具體如圖 4-1 所示。
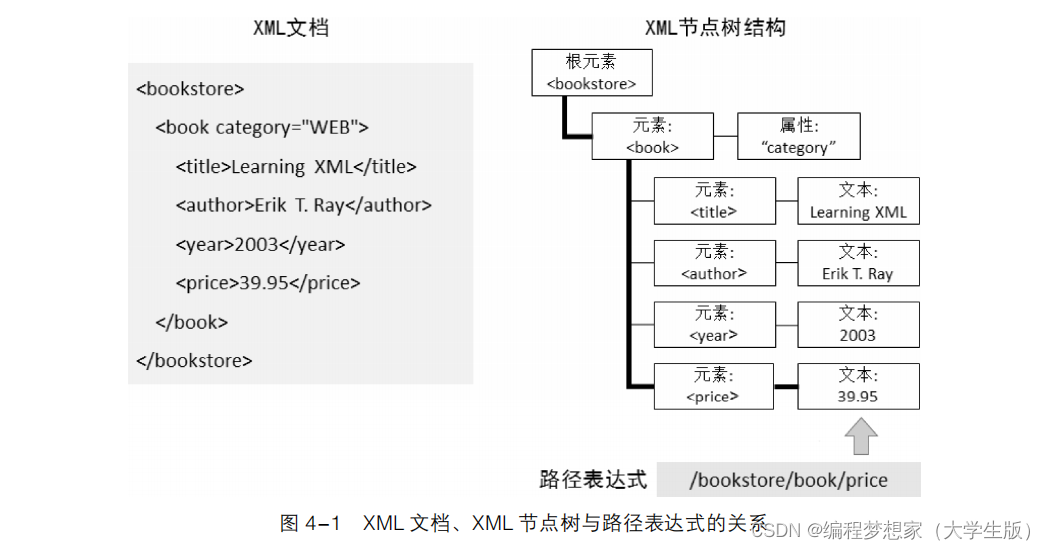
在圖 4-1 中,從左到右、從上到下依次為 XML 文檔、XML 節點樹和路徑表達式。其中,
路徑表達式為“/bookstore/book/price”,它對應的路徑為 XML 節點樹中加粗的線條,用于選
取節點<price>對應的文本 39.95。
二、XPath 語法
我們如果要編寫一個路徑表達式,則要先了解 XPath 的語法,如此才能使用路徑表達式
正確地選取節點。路徑表達式會從某個節點開始沿著節點樹查找節點,直至找到目標節點。
由于節點的多樣性,為了幫助開發人員快速選取目標節點,XPath 提供了一套語法規則。下面
從選取節點、謂語、選取未知節點、選取若干路徑這 4 個方面介紹 XPath 的語法。
1.選取節點
選取節點是最基礎的操作之一。節點所在的路徑既可以從根節點開始,也可以從任意位
置開始。選取節點的表達式如表 4-3 所示。

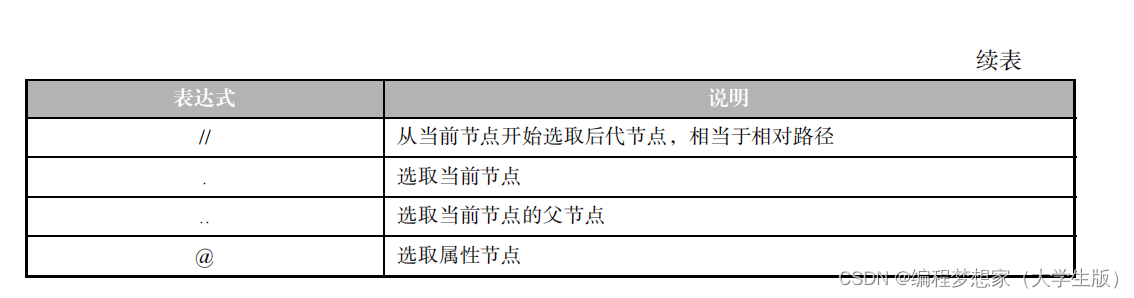
接下來,以 XML 文檔 bookstore.xml 為例,為大家演示如何使用表 4-3 中的表達式選取
XML 文檔中的節點。bookstore.xml 的具體內容如下。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book>
</bookstore>????????選取節點的示例代碼如下。
1 bookstore # 選取 bookstore 的所有子節點2 /bookstore # 選取根節點 bookstore 3 bookstore/book # 從根節點 bookstore 開始,向下選取名為 book 的所有子節點4 //book # 從任意節點開始,選取名為 book 的所有子節點5 bookstore//book # 從 bookstore 的后代節點中,選取名為 book 的所有子節點6 //@lang # 選取所有名為 lang 的屬性節點在上述代碼中,第 3 行、第 4 行的路徑表達式具有相同的功能,都可以選取節點 book 的所
有子節點。前者是從根節點開始沿著路徑向下選取的,后者是從節點樹的任意位置開始選取的。
2.謂語
謂語是為路徑表達式附加的條件,主要用于篩選當前被處理的節點集,選取出滿足某個
特定條件的節點,或者包含了指定屬性或值的節點。謂語會嵌入方括號中,位于要補充說明
的節點后面。帶謂語的路徑表達式的語法格式如下:
節點[謂語]
在上述格式中,方括號中的謂語可以是整數、屬性、函數,也可以是整數、屬性、函數
與運算符組合的表達式。如果謂語是整數(從 1 開始),則這個數值將作為位置,用于從節點
集中選取與該位置對應的節點;如果是屬性,則會從節點集中選取包含該屬性的節點;如果
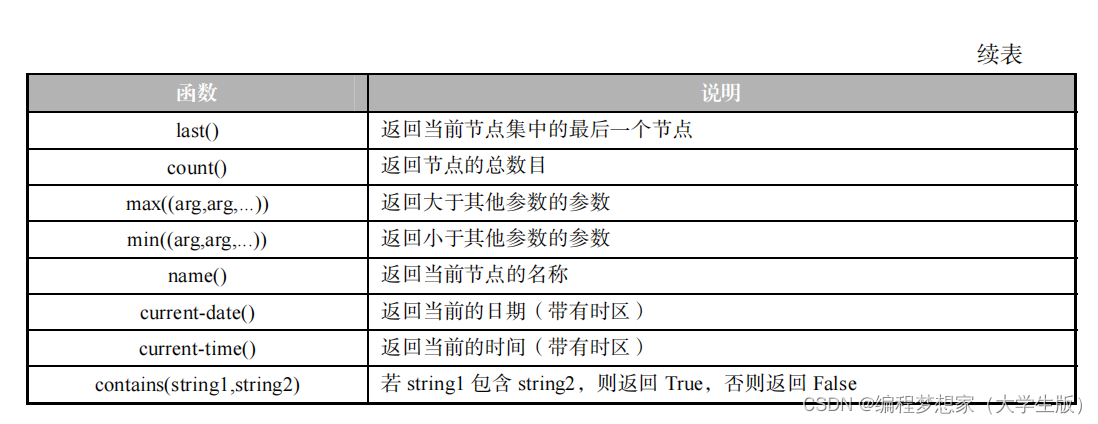
是函數,則會將該函數的返回值作為條件,從節點集中選取滿足條件的節點。常用的 XPath
函數如表 4-4 所示。

接下來,以前面的 bookstore.xml 為例,為大家演示帶謂語的路徑表達式的用法,具體代
碼如下。
/bookstore/book[1] # 選取屬于 bookstore 子節點的第 1 個 book 節點
/bookstore/book[last()] # 選取屬于 bookstore 子節點的最后一個 book 節點
/bookstore/book[last()-1] # 選取屬于 bookstore 子節點的倒數第 2 個 book 節點
/bookstore/book[position()<3] # 選取屬于 bookstore 子節點的前兩個 book 節點
//title[@lang] # 選取所有的屬性名稱為 lang 的 title 節點
//title[@lang= 'eng'] # 選取所有的屬性名稱為 lang 且屬性值為 eng 的 title 節點
# 選取子節點 price 的值大于 35.00,且父節點為 bookstore 的所有 book 節點
/bookstore/book[price>35.00]
# 選取屬于 book 的所有子節點 title,且節點 book 的子節點 price 的值必須大于 35.00
/bookstore/book[price>35.00]/title3.選取未知節點
| 通配符/函數 | 說明 |
| * | 匹配任何元素節點 |
| @* | 匹配任何屬性節點 |
| node() | 匹配任何類型的節點 |
????????XPath 提供了選取未知節點的通配符和函數,關于它們的說明如表 4-5 所示。
????????以前面的 XML 文檔為例,演示表 4-5 中通配符和函數的用法,具體代碼如下。
/bookstore/* # 選取屬于 bookstore 的所有子節點
//* # 選取文檔中的所有節點
//title[@*] # 選取所有帶有屬性的節點 title4.選取若干路徑
在 XPath 中,我們可以使用“|”運算符連接多個路徑表達式,根據多個路徑選取對應的
節點。以前面的 XML 文檔為例,演示“|”運算符的用法,具體代碼如下。
//book/title | //book/price # 選取屬于 book 的子節點 title 和 price
//title | //price # 選取所有 title 節點和 price 節點
# 選取屬于/bookstore/book/的所有 title 節點和文檔中的所有 price 節點
/bookstore/book/title | //price?
?
?
?
?
?
?
?
?
?
?


)















)
