目錄
- gcc/g++的使用
- gcc/g++是如何生成可執行文件的
- 預處理
- 編譯
- 匯編
- 鏈接
- 庫
- .o文件是如何與庫鏈接的?
- debug版本和release版本
gcc/g++的使用
在windows中,我們在VS中編寫好了代碼之后就可以直接在VS中對源碼進行編譯等操作后運行
而在Linux下,我們可以使用gcc/g++編譯器
gcc只能處理C語言代碼
g++可以處理C++代碼,也兼容C語言
對于一些指令和選項,在gcc和g++中是一樣的,所以本文只介紹gcc的用法
假如現在,我們已經寫好了一個C語言代碼mycode.c,那么怎么將這個代碼進行一些列處理,最后去運行它呢?
下面一條指令就可以:
gcc mycode.c
這條指令會默認讓其可執行文件命名為a.out
如果想要自定義可執行程序,可以使用選項-o
gcc mycode.c -o mycode
這樣,生成的可執行文件就叫做mycode了,并且這個寫法是最推薦的寫法
gcc -o mycode mycode.c這樣的寫法也可,記住-o選項后面永遠跟著重命名的可執行程序名
接下來想要執行這個文件,執行指令:./mycode
gcc/g++是如何生成可執行文件的
從源碼開始,經過預處理,編譯,匯編,鏈接四個步驟后,才能生成可執行程序
在gcc中,也有相應的選項去對文件進行只預處理,只編譯,只匯編,只鏈接
下面介紹一下每個步驟的主要功能以及在gcc中相應操作
我們使用的源碼很簡單:
#include<stdio.h>#define N 10
//主函數
int main()
{for(int i = 0;i<N;i++){printf("%d ",i); }return 0;
}
預處理
在預處理階段,主要功能包括:展開頭文件,宏替換,去注釋,條件編譯
gcc中的選項為-E
-E選項告訴gcc,從現在開始進行程序的翻譯,將預處理做完就停下來,不再往后走
我們常將預處理后的文件命名為以.i后綴結尾的文件
gcc -E mycode.c -o mycode.i
其實,預處理后的文件還是c語言的代碼,只是將頭文件展開,宏替換,去注釋,條件編譯
我們可以用vim查看mycode.i文件
我們可以發現,mycode.i的代碼有800多行,原因就是將頭文件stdio.h進行了展開
查看最后面,我們可以看見自己寫的代碼,可以發現我們寫的注釋消失了,并且宏N也被替換成了10,說明也發生了去注釋和宏替換
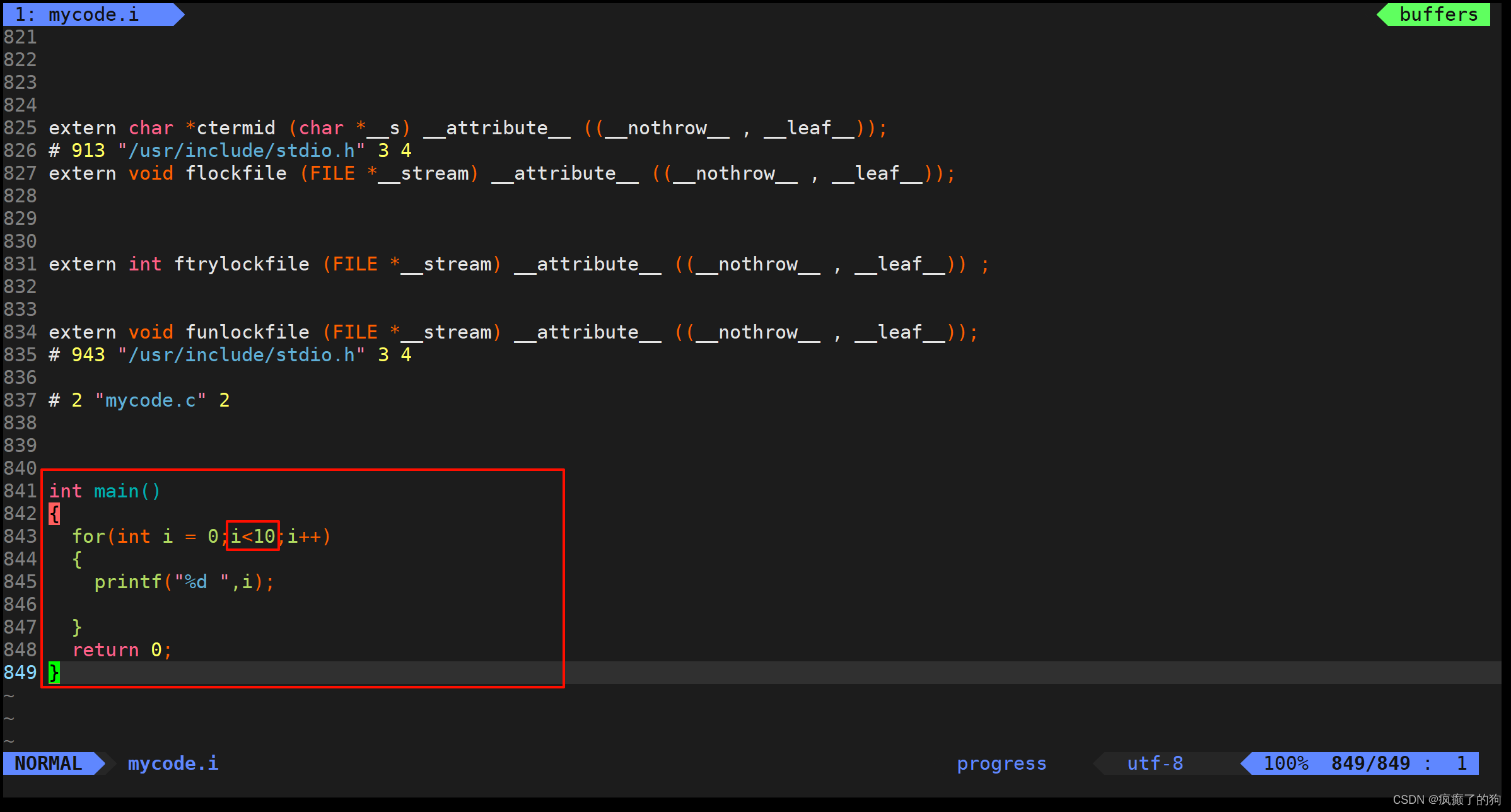
因為文中的代碼沒有涉及條件編譯,所以這里顯現不出條件編譯的結果
在這一階段,我們還可以使用-D選項進行添加宏
gcc -E mycode.c -o mycode.i -D DEBUG #添加宏DEBUG
編譯
在這個階段,gcc首先要檢查代碼的規范性,是否有語法的錯誤,以確定代碼的實際要做的工作,在檢查無誤后,gcc把代碼翻譯成匯編語言
gcc中,選項- S,告訴gcc,從現在開始進行程序的翻譯,將編譯工作做完就停下來,不要往后走了
我們通常將編譯后的匯編語言文件命名為.s后綴的文件
下面將mycode.i進行編譯:
gcc -S mycode.i -o mycode.s#從mycode.c還是也可以
gcc -S mycode.c -o mycode.s
進入mycode.s查看,可以看出里面是匯編代碼
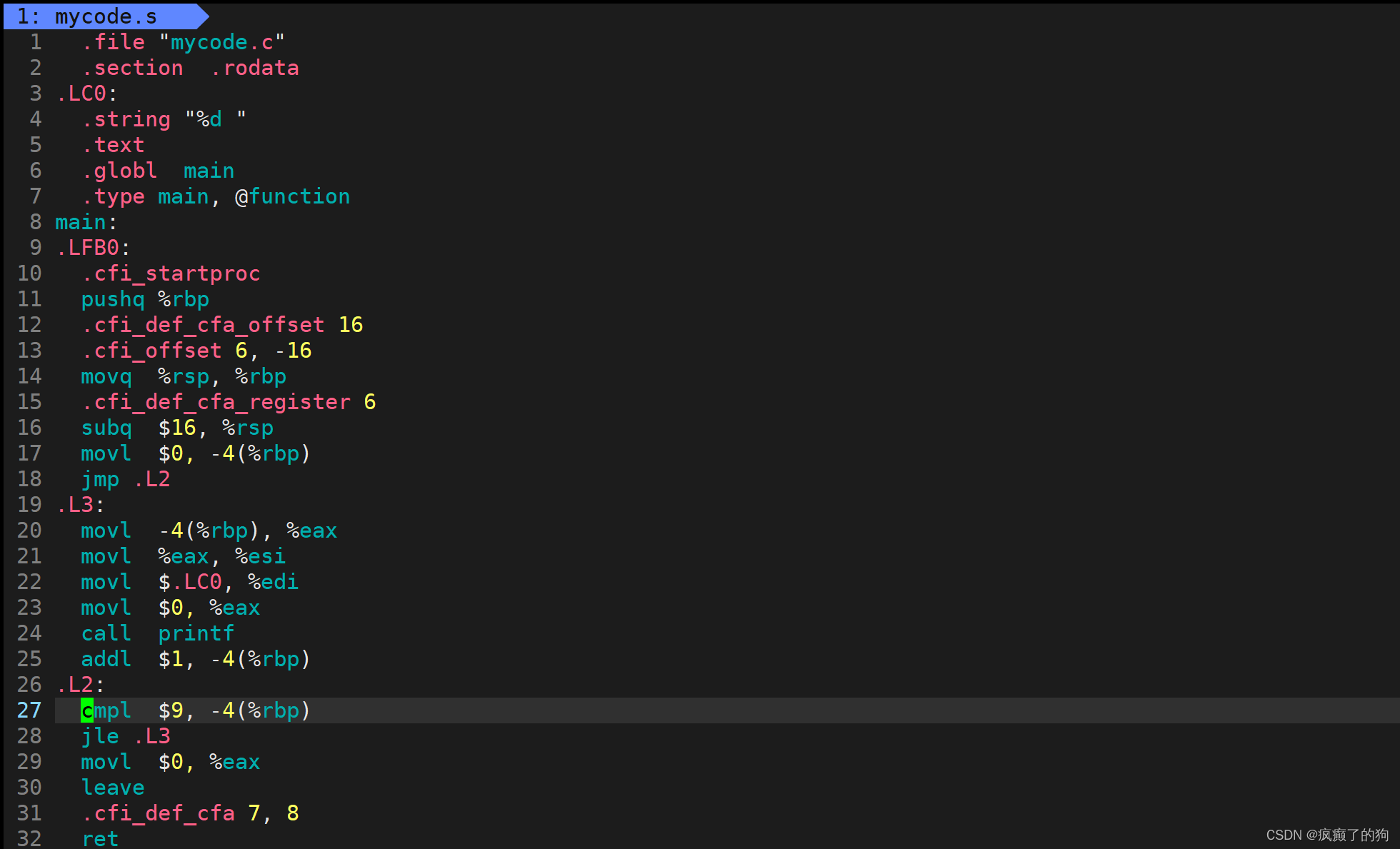
匯編
匯編階段就是把匯編代碼轉化成機器可以識別的二進制代碼
gcc中,選項-c,告訴gcc,從現在開始進行程序的翻譯,將匯編工作做完就停下來,不要往后走了
我們通常將編譯后的二進制機器碼文件命名為.o后綴的文件
.o文件也叫做可重定位目標二進制文件,簡稱目標文件,即windows下的.obj文件,雖然是二進制,但還不可以獨立執行,需要鏈接
gcc -c mycode.s -o mycode.o
用vim查看mycode.o文件,發現全是亂碼

其實這是正確的現象,因為匯編之后文件中全是二進制的代碼,而我們用的vim是文本編輯器,它將文件以文本的形式打開,所以會將二進制代碼識別為對應的字符或符號
所以許多二進制轉化為字符或符號后,它們就會組成一篇亂碼,正如圖片所示
鏈接
這個步驟,是將可重定位二進制文件與庫進行連接成可執行文件
gcc中,連接沒有選項
gcc mycode.o -o mycode
此時,預處理,編譯,匯編,鏈接就都完成了,成功生成了可執行文件
readelf -S指令可以讀取可執行文件對應二進制構成
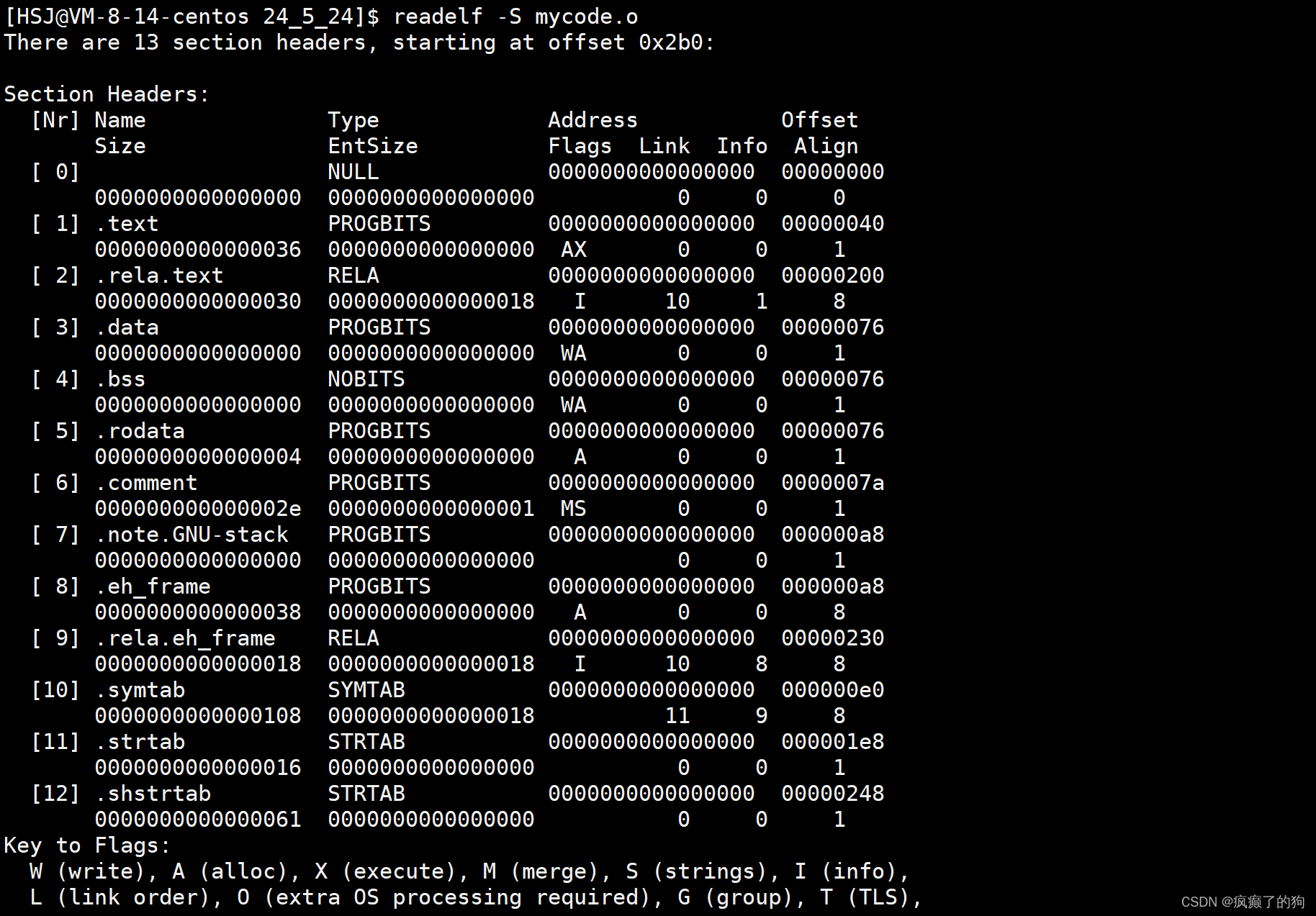
最后,總結一下:
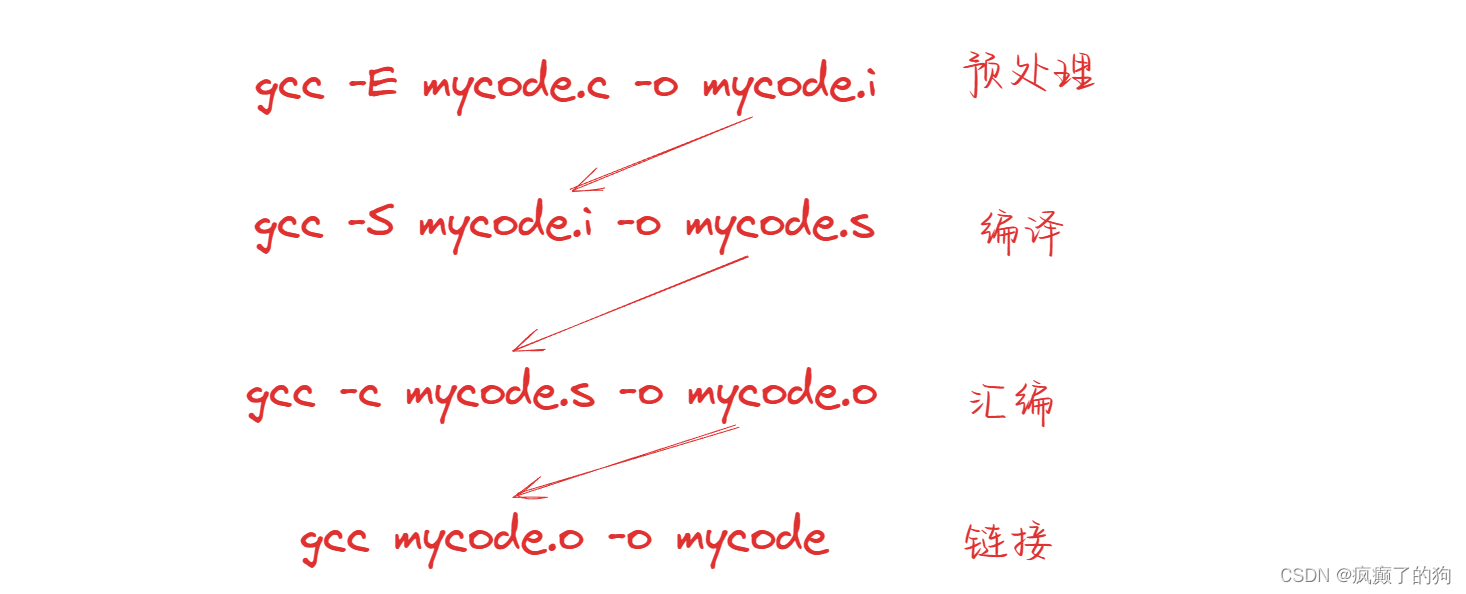
庫
前面講鏈接的時候提到了庫。什么是庫呢?
在C程序中,我們時常使用一些庫函數,實際上,我們使用庫函數只是在調用函數,這些庫函數的聲明在頭文件中,而庫函數的實現就是在庫中
Linux中,存放庫的目錄為/usr/lib64下
C語言的標準庫:/usr/lib64/libc.so
其實庫的本質就是一個文件
在Linux中,動態庫以.so為結尾,靜態庫以.ac結尾
在Windows中,動態庫以.dll為結尾,靜態庫以.lib結尾
在Linux中,庫是有自己的命名規則的,拿動態庫為例:libname.so.xxx
而在Linux中,默認只有動態庫,靜態庫是沒有安裝的
安裝靜態庫:
yum install -y glibc-static
yum install -y libstdc++-static
為什么在下載完VS IDE后就可以寫程序了呢?
原因是,編譯型語言,安裝開發包,必定下載對應的頭文件和庫文件,所以可以直接進行編寫代碼
而庫就是把源文件,經過一定的翻譯,然后打包成庫,這樣就可以提供一個庫文件,不用提供太多的源文件,同時也達到了隱藏源文件的目的
頭文件提供方法的聲明,庫文件提供方法的實現+自己的代碼 = 自己的程序
庫的最主要功能就是避免重復工作,將已經實現的功能進行打包,供別人調用使用
.o文件是如何與庫鏈接的?
有2中鏈接方式:1.動態鏈接 2.靜態鏈接
動態鏈接:
動態鏈接就是所有的代碼都共用一個動態庫,所以動態庫也叫做共享庫
動態鏈接將動態庫所處的位置拷貝到可執行文件中,在運行程序時到調用庫函數的時候,會跳轉到庫中執行,執行完畢后,再跳會代碼的調用處,繼續向下執行
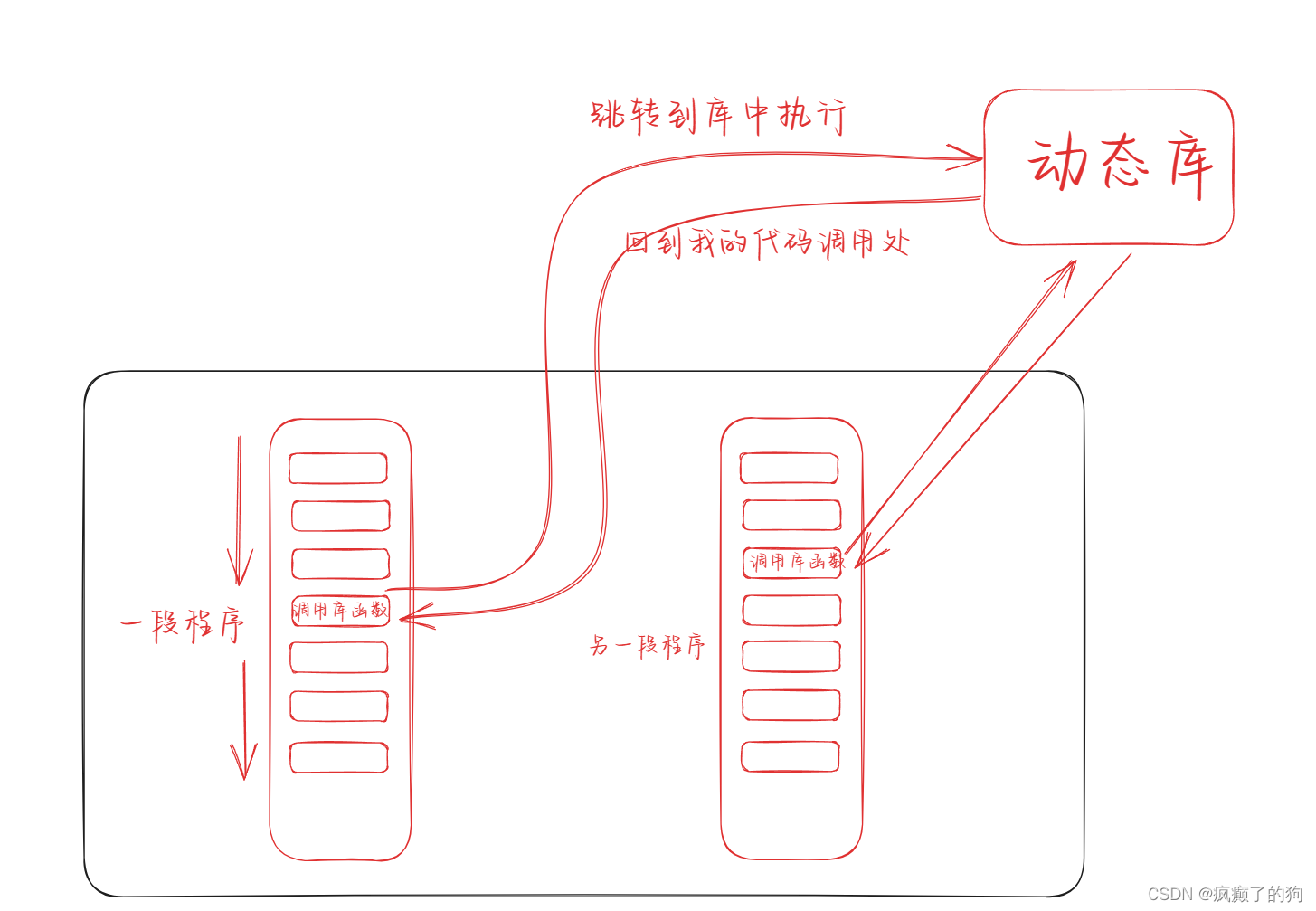
動態庫不能缺失,一旦動態庫缺失,影響的不止是一個程序,會導致許多程序無法正常運行
在Linux中,更不能隨意刪除動態庫,因為Linux和Unix本身就是用C/C++編寫的,其中許多的命令都會調用庫函數,如果刪除了動態庫,不僅我們自己的代碼會無法運行,就連內置的命令都無法運行,此時的Linux就可以算是廢了
用指令
ldd可以查看可執行程序依賴的動態庫

靜態鏈接:
在編譯器使用靜態庫進行靜態鏈接時,會將自己的方法拷貝到目標程序中,使程序不再依賴靜態庫
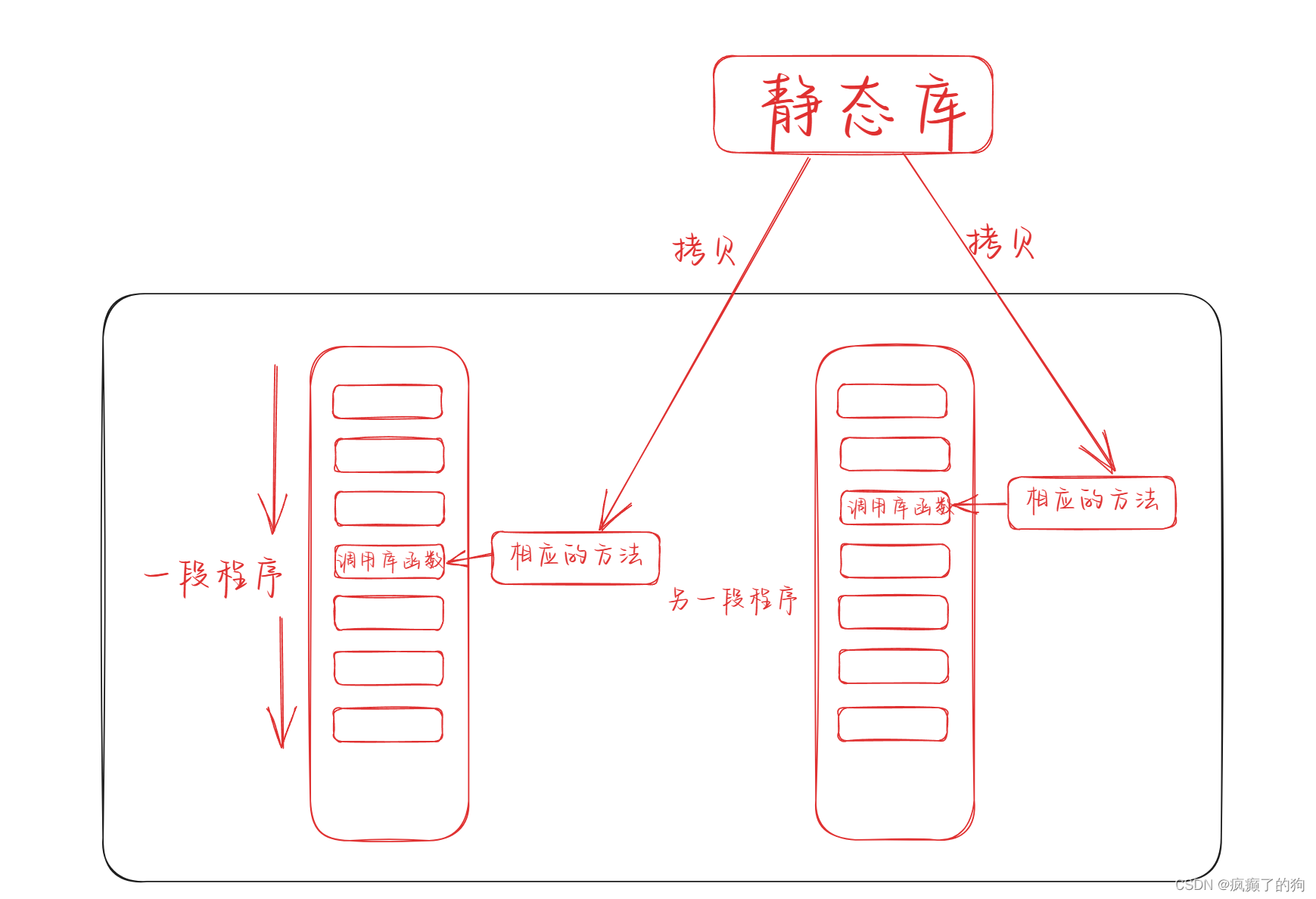
總結一下動態鏈接/庫 和 靜態鏈接/庫
- 不論是動態庫還是靜態庫,本質上就是2個文件,里面包含了各種的源碼
- 靜態鏈接:鏈接時,把庫中代碼拷貝自己的可執行程序里
- 動態鏈接:在可執行程序中不拷貝實現,只是把實現所在的位置拷貝到可執行文件中
- 靜態鏈接后,程序不再依賴靜態庫
- 動態鏈接后,程序仍依賴動態庫
Linux中,編譯行程可執行代碼,默認采用動態鏈接
通過ldd指令可以看出,我們前面生成的可執行程序mycode依賴的是動態庫

在Linux中,如果要使用靜態鏈接,要手動添加-static,并且同時系統中要有靜態庫,因為靜態庫不是系統默認提供的
下面我們將mycode.o進行靜態鏈接
gcc mycode.o -o mycode_static -static
用ldd查看,可以看出它使用靜態鏈接

同時,應為與動態鏈接相比,靜態鏈接是將靜態庫中的方法實現拷貝到了可執行文件中,所以采用靜態鏈接的可執行文件的大小一定大于采用動態鏈接的可執行文件大小
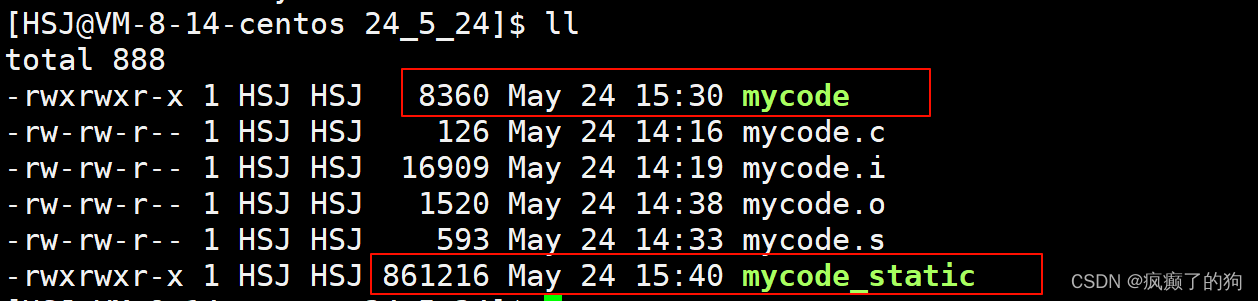
因為采取靜態鏈接會使可執行文件大小大很多,對于傳輸和下載這個文件會消耗許多時間和網絡,所以動態鏈接并不常用
用file指令可以查看一個可執行程序是動態鏈接的還是靜態鏈接的

有幾點需要注意:
- 如果沒有靜態庫,還添加
-static,是不行的 - 如果沒有如果沒有動態庫,只有動態庫,并且
gcc能找到,不添加-static是可以的,因為gcc默認優先動態鏈接,沒有動態庫,就使用靜態鏈接,而添加-static本質上是改變優先級 - 一個可執行程序不一定全部是動態鏈接或靜態鏈接,也可以是混合的,因為我們的程序可能依賴各種的庫,有的庫提供了動態庫,可能有的庫沒有提供,所以可以混合使用。如果加了
-static,則是讓所有鏈接都變為動態鏈接,如果庫不存在,則會報錯
動態鏈接和靜態鏈接比較:
動態鏈接的優點:動態庫是共享的,可以有效地節省資源(硬盤空間,內存空間,網絡空間等)
動態鏈接的缺點:動態庫一旦缺失,程序將無法正常運行
靜態鏈接的優點:不依賴庫,一旦形成可執行文件,可以獨立運行,可以在同平臺環境下隨便運行
靜態鏈接的缺點:體積大,占空間
debug版本和release版本
gcc默認以release模式生成可執行文件
要以debug版本生成可執行文件:
gcc mycode.c -o mycode_debug -g
mycode_debug文件占的空間會比release版本大,因為debug可以被追蹤、調試,生成可執行文件時,向里面添加了debug信息






新增節-添加代碼作業)



python實現)








