
【摘要】大型語言模型(LLM)的不斷進步使人們越來越關注開發公平可靠的方法來評估其性能的關鍵問題。特別是測試集泄漏、提示格式過擬合等主觀或非主觀作弊現象的出現,給法學碩士的可靠評估帶來了重大挑戰。由于評估框架通常利用正則表達式 (RegEx) 進行答案提取,因此某些模型可能會調整其響應以符合 RegEx 可以輕松提取的特定格式。然而,基于正則表達式的關鍵答案提取模塊經常出現提取錯誤。本文對整個LLM評估鏈進行了全面分析,證明優化關鍵答案提取模塊可以提高提取準確性,減少LLM對特定答案格式的依賴,增強LLM評估的可靠性。為了解決這些問題,我們提出了 xFinder,一個專門為關鍵答案提取而設計的模型。作為此過程的一部分,我們創建了一個專門的數據集,即關鍵答案查找器 (KAF) 數據集,以確保有效的模型訓練和評估。通過真實場景的泛化測試和評估,結果表明,只有 5 億個參數的最小 xFinder 模型的平均答案提取準確率達到 93.42%。相比之下,最佳評估框架中的 RegEx 準確率為 74.38%。與現有評估框架相比,xFinder 表現出更強的魯棒性和更高的準確性。
原文:xFinder: Robust and Pinpoint Answer Extraction for Large Language Models
地址:https://arxiv.org/abs/2405.11874v1
代碼:https://github.com/IAAR-Shanghai/xFinder
出版:未知
機構: Institute for Advanced Algorithms Research, Shanghai; Renmin University of China解析人:公眾號“碼農的科研筆記”
1 研究問題
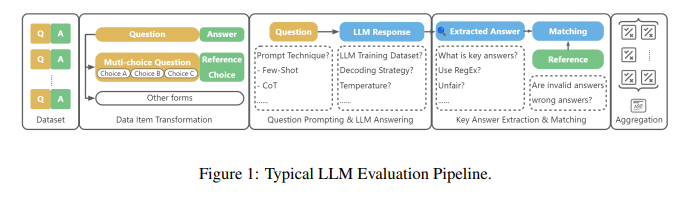
本文研究的核心問題是: 如何設計一種精準、魯棒的大語言模型(LLMs)生成內容中的關鍵答案抽取方法。
考慮這樣一個場景:現有多個LLMs如GPT-4、PaLM、Bard等,針對同一個問題生成了不同的回答。這些回答可能格式多樣,有的用自然語言直接給出答案,有的則先給出推理過程再得出結論。我們希望從這些回答中抽取出最終的關鍵答案,以便對不同LLM的表現進行評估和比較。然而現有的基于正則表達式的抽取方法往往無法應對LLM生成內容的多樣性,導致大量答案被漏抽或錯抽。
本文研究問題的特點和現有方法面臨的挑戰主要體現在以下幾個方面:
-
LLM生成的回答內容豐富多樣,很難用簡單的模板或規則進行匹配和抽取。比如有的回答會先給出推理過程,再在最后給出結論;有的回答會在中間某處給出答案,然后進行補充說明。
-
不同LLM對于同一個問題的理解和表述方式差異很大。比如針對"人工智能會取代人類嗎"這個問題,有的LLM可能直接回答"不會",而有的LLM則可能從技術、倫理、經濟等多個角度分析利弊,但最終也是得出"不會取代"的結論。
-
現有的基于正則表達式(RegEx)的抽取方法缺乏靈活性和泛化能力。它們通常依賴于特定的答案格式(如"The answer is ...")來定位和提取答案,一旦LLM生成的回答不符合預設格式,就很容易出錯。
-
缺乏高質量的答案抽取數據集。由于LLM回答的多樣性,人工標注答案抽取的數據成本很高。而直接將其他QA或MRC數據集轉化為答案抽取任務的數據質量較差。
針對這些挑戰,本文提出了一種預訓練+微調的"xFinder"方法:
xFinder的核心思想是先在大規模語料上預訓練一個語言模型,使其具備基本的語言理解和生成能力,然后在答案抽取數據集上進行微調,使其習得從LLM生成內容中定位和抽取關鍵答案的能力。 具體來說,xFinder采用的是基于Transformer的encoder-decoder結構。Encoder負責對LLM生成的文本進行編碼,生成each token的上下文表示。Decoder則根據question和answer range的embedding,在encoder的輸出表示中定位含有答案的句子和span。 為了訓練xFinder,本文構建了一個KB Answer Finder (KAF)數據集,包含由10個不同LLM在8個任務上生成的回答,以及對應的人工標注的關鍵答案。此外還有一個泛化測試集,包含另外8個LLM在11個新任務上的生成內容,用于評估xFinder的泛化能力。 實驗結果表明,xFinder相比傳統的RegEx方法,在答案抽取的精確度和魯棒性上都有大幅提升。在泛化測試集上,參數量只有5億的xFinder-qwen1505模型的平均抽取準確率達到了93.42%,而最好的RegEx方法只有74.38%。
2 研究方法
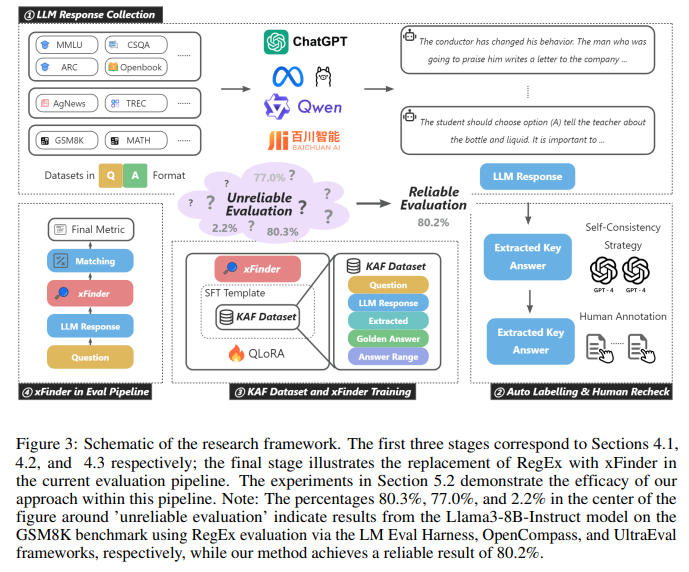
為了有效地微調xFinder模型,構建一個高質量的數據集至關重要。論文構建了一個專門用于關鍵答案提取的數據集KAF(Key Answer Finder)。本節將詳細介紹KAF數據集的構建過程以及xFinder模型的訓練方法。
2.1 KAF數據集構建
2.1.1 LLM回答生成
KAF數據集構建的第一步是利用不同的大型語言模型,針對多個評估任務生成問題-回答對。論文選取了18個典型的評估任務數據集,涵蓋了廣泛的知識領域。
為了引導LLM生成多樣化的回答,論文精心設計了8種提示詞配置,包括0-shot(-restrict)、0-shot-cot(-restrict)、5-shot(-restrict)和5-shot-cot(-restrict)。其中,-restrict表示在提示詞末尾添加一個標準化回答格式的要求。通過這些提示詞,可以得到LLM在不同few-shot設置和推理模式下的多樣化回答。
此外,考慮到不同系列和規模的LLM在面對同一個問題時可能給出不同的回答,論文選取了10個不同的LLM來生成回答,以進一步豐富數據的異質性。
2.1.2 半自動標注與人工復核
KAF數據集構建的關鍵是從LLM回答中提取出關鍵答案作為標簽。論文針對訓練集、測試集和泛化集采用了不同的標注策略:
-
對于訓練集,為了提高標注效率,論文采用了一種半自動化的方法。首先利用GPT-4生成兩組標注,然后應用自洽性策略,對兩輪標注結果不一致的樣本以及所有數學題進行人工復核。
-
對于測試集和泛化集,為確保標簽的準確性,全部采用兩輪人工標注的方式。
自洽性策略的核心思想是:對同一個樣本利用兩種不同形式的提示(常規形式和XML形式)生成兩組標注,若結果一致則認為標注可靠,否則交由人工復核。這種方法可以充分利用GPT-4的能力提高標注效率,同時通過人工復核保證關鍵樣本的標注質量。
2.1.3 KAF數據集概述
KAF數據集包含26,900個訓練樣本、4,961個測試樣本和4,482個泛化樣本。每個樣本包括一個問題、候選答案范圍、LLM對該問題的回答以及從回答中提取的關鍵答案標簽。
值得注意的是,訓練集和測試集中的問答對來自于10個LLM在8個評估任務上的回答,而泛化集的問答對則來自于8個LLM在另外11個全新評估任務上的回答。這種劃分方式有助于全面評估xFinder模型的泛化性能。
2.2 xFinder模型訓練
根據第3節中對關鍵答案提取任務的定義,xFinder的訓練目標是學會從LLM回答y中準確定位包含最終答案的關鍵句s,并從s中提取出與問題q對應的關鍵答案k。
xFinder的輸入包括問題q、LLM回答y、關鍵答案類型以及候選答案范圍,輸出為從y中提取的關鍵答案k。在訓練過程中,論文主要使用了XTuner工具包中的QLoRA方法進行微調,并精心設計了指令型提示詞來充分發揮xFinder的指令遵循能力。
此外,為了增強xFinder的泛化性,論文還對KAF訓練集進行了數據增強:
-
對50%的字母選項問題,通過增減選項數量來模擬LLM對此類問題的回答。
-
對含有外包裝關鍵句的樣本,隨機替換外包裝提示詞以豐富語言模式。
通過在高質量的KAF數據集上微調,并應用數據增強策略提升泛化性,xFinder可以在實際應用中準確地提取LLM回答中的關鍵信息,為后續的自動化評估打下堅實基礎。 第四步、實驗部分詳細撰寫:
5 實驗
5.1 實驗場景介紹
本論文提出了一個專門用于關鍵答案抽取的模型xFinder,實驗的目標是驗證xFinder在關鍵答案抽取任務上的有效性,以及在真實評估場景中替換主流框架的正則抽取模塊后對LLM排名的影響。
5.2 實驗設置
Datasets:
-
KAF(Key Answer Finder)數據集:包含訓練集26,900個樣本,測試集4,961個樣本,泛化集4,482個樣本。訓練和測試集的問答對由10個LLM在8個評估任務上生成,泛化集由8個LLM在11個新評估任務生成。
-
14個主流評估任務數據集
Baselines:
-
主流框架:OpenCompass、UltraEval、LM Eval Harness
-
GPT-4
-
Implementation details:
-
使用XTuner工具和QLoRA方法微調基礎模型,在8×A100 GPU上訓練
-
主要微調超參數:batch size為1,max length為2048,學習率2e-4,AdamW優化器
metric:關鍵答案抽取準確率
5.3 實驗結果
5.3.1 KAF測試集上xFinder vs. RegEx的抽取準確率對比
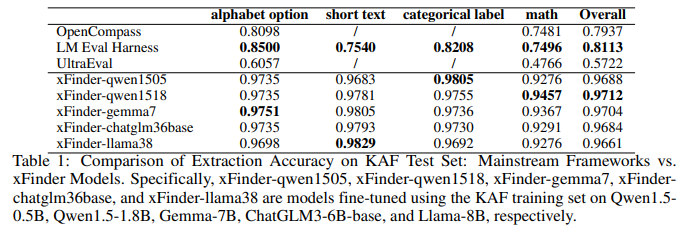
目的:評估使用KAF訓練集微調后的xFinder模型在KAF測試集上的關鍵答案抽取性能,與主流框架的RegEx方法進行對比
涉及圖表:表1
實驗細節概述:選取19個不同規模(0.5B~8B)的LLM,使用KAF訓練集進行微調,在KAF測試集上評估抽取準確率,與OpenCompass、UltraEval和LM Eval Harness的RegEx方法進行對比
結果:
-
使用KAF訓練集微調的xFinder模型具有很高的有效性,盡管模型參數規模差異16倍,但抽取準確率差異不超過0.5%,說明KAF數據集質量高
-
xFinder模型在各類型問題上的準確率均顯著高于主流框架的RegEx方法
5.3.2 KAF泛化集上xFinder vs. 其他模型的抽取準確率對比
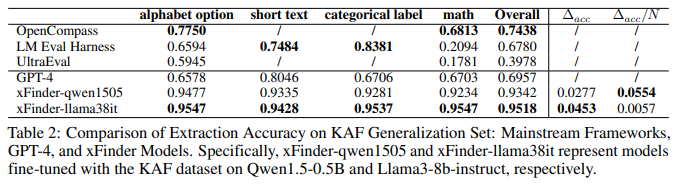
目的:評估xFinder在未見過的任務上的抽取能力
涉及圖表:表2
實驗細節概述:選取2個有代表性的xFinder模型,在KAF泛化集上評估抽取準確率,與GPT-4、OpenCompass、UltraEval和LM Eval Harness進行對比
結果:
-
xFinder在泛化集上保持了較高的抽取準確率,而主流框架的RegEx方法表現很差,尤其在抽取數學問題的關鍵答案時
-
即使是GPT-4也難以從復雜多變的LLM輸出中準確抽取關鍵答案
-
xFinder展現了很好的泛化能力
5.3.3 實驗三、在真實場景下使用xFinder和主流評估框架評估LLM性能
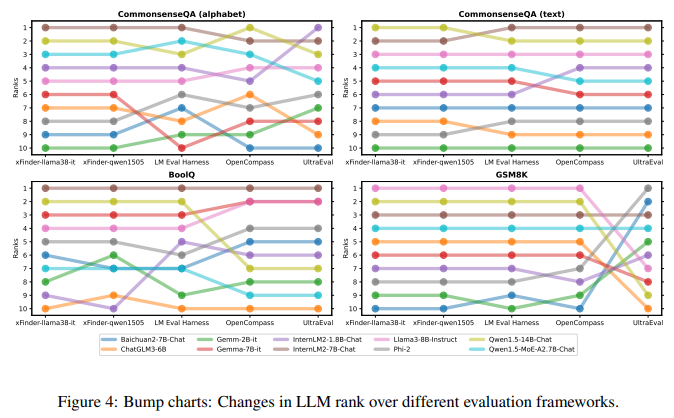
目的: 驗證在實際LLM評估任務中使用xFinder替代正則表達式抽取答案的有效性
涉及圖表: 圖4,表8-27
實驗細節概述:
-
選擇xFinder-qwen1505(?acc/N最高)和xFinder-llama38it(?acc最高)用于真實場景評估
-
在14個主流評估任務上,使用xFinder-qwen1505、xFinder-llama38it和主流評估框架評估10個LLM的性能,對比LLM排名差異
結果:
-
主流評估框架的LLM排名存在顯著差異,說明基于正則表達式的方法不可靠,可能影響模型評估和排名
-
使用不同基礎模型微調的xFinder在同一任務上對LLM的排名比較一致,表明xFinder更加穩定可靠
-
將評估任務設置為字母選項的可靠性值得懷疑,建議減少現有評估框架對字母選項格式的依賴
4 總結后記
本論文針對評估大語言模型(LLM)的關鍵答案提取問題,提出了一種名為xFinder的專用模型。通過構建高質量的KAF數據集并在此基礎上微調模型,實現了在多個評估任務上相比主流基于正則表達式的方法取得更高的提取準確率。實驗結果表明,所提xFinder模型具有更強的魯棒性和泛化能力,為提高LLM評估的可靠性提供了新的思路。
疑惑和想法:
-
除了微調方法,是否可以探索基于prompt engineering的方式來適配xFinder到新的任務?
可借鑒的方法點:
-
針對特定問題構建高質量數據集并微調模型的思路可以推廣到其他LLM評估任務,如事實性評估、對齊度評估等。
-
采用自洽性(self-consistency)策略生成高質量標注數據的方法可以應用到其他需要人工標注的場景,提高標注效率。
-
系統測試不同提示形式對LLM生成內容的影響,有助于設計出更加有效和公平的評估方案。
 方法之追蹤定位)
連接局域網)

)

)













