2024年中青杯數學建模競賽B題論文和代碼已完成,代碼為B題全部問題的代碼,論文包括摘要、問題重述、問題分析、模型假設、符號說明、模型的建立和求解(問題1模型的建立和求解、問題2模型的建立和求解、問題3模型的建立和求解)、模型的評價等等
2024中青杯數學建模競賽B題論文和代碼獲取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/xg2r5sf8m1s3hl5d
B 題:藥物屬性預測:
機器學習、深度學習、圖神經網絡
B 題:藥物屬性預測
近年來,隨著網絡技術的快速發展和大數據挖掘技術的成熟,人們的數據分析能力也在逐步提升,可以采集的數據規模越來越大。尤其是伴隨著電商和短視頻媒體的發展,產生了大量的圖結構數據。圖結構數據的研究非常有價值,由于圖結構數據的復雜性,使得這方面的研究工作十分具有挑戰性。
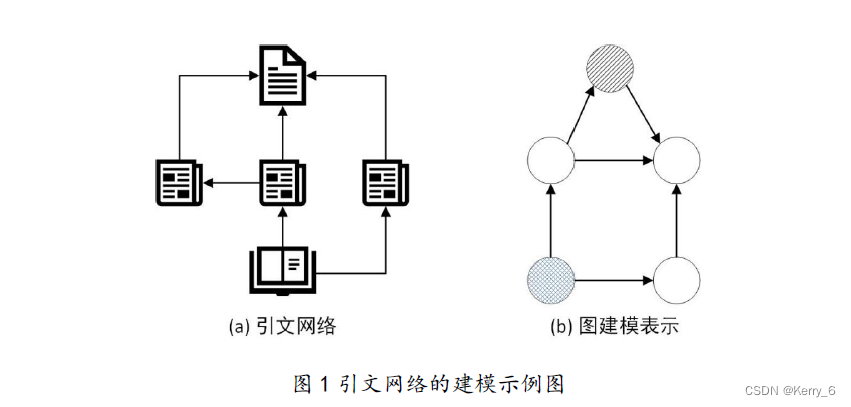
現實世界中有很多問題都可以使用圖來建模,圖數據是目前模式識別與機器學習領域重要的研究對象。例如,網上購物軟件采用基于圖深度學習的方法可以精準地向用戶推薦喜歡的商品,圖在推薦系統上的建模能力比較強;在生物醫療上,可以圖深度學習技術設計新藥物或者探究藥物間的相互作用;而在引文網絡中,論文通過引用關系被相互連接,并可通過分析這些關系將它們分組,正如圖1 所示。這些例子展示了基于圖的學習系統在不同領域的應用潛力和價值。圖是一種功能強大的結構,可以用來建模幾乎任何類型的數據。社交網絡、文本文檔、萬維網、化學化合物和蛋白質-蛋白質相互作用網絡,通常都是用圖表表示的數據的例子[2].由于圖形結構的豐富數據,圖上的機器學習最近成為一項非常重要的任務。近年來,越來越多的學者關注圖表示學習的研究工作,圖表示學習主要應用在圖分類、節點分類和鏈路預測等任務中。
附件是藥物分子的數據(圖數據),請您利用傳統方法建立藥物分子的分類模型,并給出分類精度及其結果分析。
傳統藥物分子分類方法依賴于復雜的化學屬性分析和生物實驗,不僅耗時耗力,而且難以處理大規模的分子數據。因此,發展一種高效、準確的分子分類方法成為了當前科研的一個熱點。與此同時,一些研究人員將神經網絡應用到藥物分子挖掘中,提出圖神經網絡,這種方法能夠端到端進行模型的優化學習,在圖分類準確度有較大提升。請您給出一種圖神經網絡模型對附件中的數據進行分類,并給出分類精度及其結果分析。
現有圖神經網絡模型在處理具有節點特征稀疏性和信息冗余的圖結構數據時面臨挑戰,這限制了模型在復雜網絡分析中的應用效果。請您嘗試給出一種新的藥物分子分類方法突破這種限制,給出試驗結果,并進行分析討論。
1.1 總體分析
下面是對2024中青杯B題的一個問題分析:
這個題目旨在利用機器學習和深度學習技術解決藥物分子分類的問題,探索利用圖結構數據對藥物進行高效、準確的分類。題目不僅要求使用傳統方法和現有的圖神經網絡模型,還需要提出創新性的方法來突破現有模型的局限。整體而言,這個問題貼近當前的科研前沿,具有一定的理論價值和實際應用意義。給定的數據集為模型訓練和驗證提供了基礎,題目設置合理,難度適中。
1.2 第一個子問題分析
題目要求使用傳統方法建立藥物分子分類模型,傳統方法通常指基于人工提取的特征和經典的機器學習算法,如決策樹、支持向量機等。這種方法的優點是可解釋性強,缺點是需要人工設計特征,難以捕捉數據中的復雜模式。
在具體實現時,需要對藥物分子數據進行預處理,提取與分類相關的化學結構特征,如分子量、極性、官能團等。然后使用這些特征訓練經典的機器學習模型,如邏輯回歸、隨機森林等,并在測試集上評估模型的性能。
傳統方法的分類結果需要進行全面分析,包括模型的準確率、精確率、召回率等指標,以及在不同類別上的表現。同時還需分析特征的重要性,探討哪些化學特征對分類更為關鍵。最后需總結傳統方法的優缺點,為下一步使用深度學習模型打下基礎。
1.3 第二個子問題分析:
題目要求使用圖神經網絡模型對藥物分子數據進行分類,圖神經網絡是一種processed結構化數據的新型深度學習模型,能夠直接處理圖結構數據,自動學習節點和邊的表示。與傳統方法相比,它不需要人工設計特征,能夠端到端地優化模型參數。
在實現時,需要先將藥物分子數據轉換為圖結構表示,每個節點代表一個原子,邊表示原子之間的化學鍵。然后設計合適的圖神經網絡模型,如圖卷積神經網絡(GCN)或圖注意力網絡(GAT)等,對節點和邊的表示進行編碼,最終得到整個圖的表示向量,用于分類。
在評估圖神經網絡模型時,需要對比其與傳統方法的準確率、泛化能力等,分析深度學習模型在藥物分類任務上的優勢所在。另外還需探討模型對數據噪聲和缺失值的魯棒性,以及在大規模數據集上的計算效率等實際應用考慮因素。
1.4 第三個子問題分析
現有圖神經網絡在處理節點特征稀疏和信息冗余的圖數據時仍有不足,這將影響模型在復雜網絡分析中的應用效果。節點特征稀疏意味著節點的屬性信息不完整,而信息冗余則表示圖中存在大量無用或重復的邊緣信息。
為突破這一限制,可以嘗試設計新的圖神經網絡架構,增強模型對稀疏特征的魯棒性,如引入注意力機制或外部知識;或者在模型輸入時加入降噪、去冗余的預處理步驟;亦可結合經典的圖理論方法,提出混合模型等。
實現新模型后,需要在給定數據集上進行全面的實驗評估,測試新模型在準確率、泛化能力、計算效率等方面的表現,與現有模型進行對比分析。最后需要總結新模型的創新之處,指出其在應對特殊類型圖數據時的優勢,并討論在其他領域中的潛在應用前景。
這個問題設置合理且具有一定的開放性,參賽者需要掌握機器學習、深度學習和圖論的基礎知識,并具備一定的建模能力和創新意識,才能很好地完成該題。
2024中青杯數學建模B題論文和代碼獲取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/xg2r5sf8m1s3hl5d




)

+vue影院售票商城 電影放映購物系統(附源碼+論文))
)



手撕基于向量檢索的 RAG)






