本系列用于Bert模型實踐實際場景,分別包括分類器、命名實體識別、選擇題、文本摘要等等。(關于Bert的結構和詳細這里就不做講解,但了解Bert的基本結構是做實踐的基礎,因此看本系列之前,最好了解一下transformers和Bert等)
本篇主要講解完形填空應用場景。本系列代碼和數據集都上傳到GitHub上:https://github.com/forever1986/bert_task
1 環境說明
1)本次實踐的框架采用torch-2.1+transformer-4.37
2)另外還采用或依賴其它一些庫,如:evaluate、pandas、datasets、accelerate等
2 前期準備
Bert模型是一個只包含transformer的encoder部分,并采用雙向上下文和預測下一句訓練而成的預訓練模型。可以基于該模型做很多下游任務。
2.1 了解Bert的輸入輸出
Bert的輸入:input_ids(使用tokenizer將句子向量化),attention_mask,token_type_ids(句子序號)、labels(結果)
Bert的輸出:
last_hidden_state:最后一層encoder的輸出;大小是(batch_size, sequence_length, hidden_size)(注意:這是關鍵輸出,本次任務就需要獲取該值,可以取出那個被mask掉的token,獲取其前幾個,取score最高的(當然也可以使用top_k或者top_p方式獲取一定隨機性))
pooler_output:這是序列的第一個token(classification token)的最后一層的隱藏狀態,輸出的大小是(batch_size, hidden_size),它是由線性層和Tanh激活函數進一步處理的。(通常用于句子分類,至于是使用這個表示,還是使用整個輸入序列的隱藏狀態序列的平均化或池化,視情況而定)。
hidden_states: 這是輸出的一個可選項,如果輸出,需要指定config.output_hidden_states=True,它也是一個元組,它的第一個元素是embedding,其余元素是各層的輸出,每個元素的形狀是(batch_size, sequence_length, hidden_size)
attentions:這是輸出的一個可選項,如果輸出,需要指定config.output_attentions=True,它也是一個元組,它的元素是每一層的注意力權重,用于計算self-attention heads的加權平均值。
2.2 數據集與模型
1)數據集來自:ChnSentiCorp(該數據集本身是做情感分類,但是我們只需要取其text部分即可)
2)模型權重使用:bert-base-chinese
2.3 任務說明
完形填空其實就是在一段文字中mask掉幾個字,讓模型能夠自動填充字。這里本身就是bert模型做預訓練是所做的事情之一,因此就是讓數據給模型做訓練的過程。
2.4 實現關鍵
1)數據集結構是一個帶有text和label兩列的數據,我們只需要獲取到text部分即可。
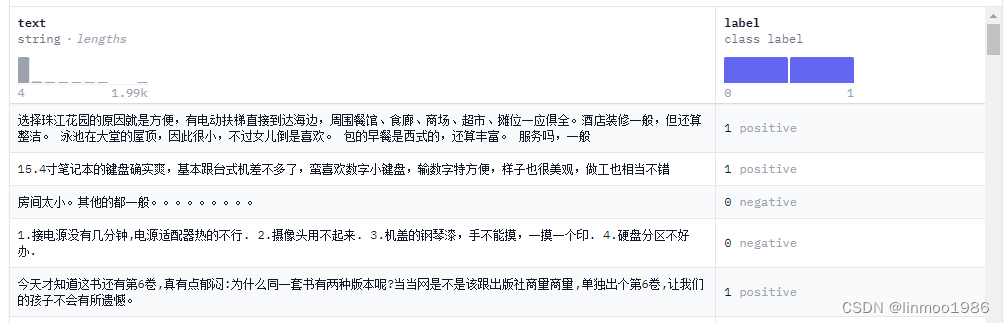
2)隨機mask掉部分數據,這個本身也是bert的訓練過程,因此在transforms框架中DataCollatorForLanguageModeling已經實現了,你也可以自己實現隨機mask掉你的數據進行訓練
3 關鍵代碼
3.1 數據集處理
數據集不需要做過多處理,只需要將text部分進行tokenizer,并制定max_length和truncation即可
def process_function(datas):tokenized_datas = tokenizer(datas["text"], max_length=256, truncation=True)return tokenized_datas
new_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
3.2 模型加載
model = BertForMaskedLM.from_pretrained(model_path)
注意:這里使用的是transformers中的BertForMaskedLM,該類對bert模型進行封裝。如果我們不使用該類,需要自己定義一個model,繼承bert,增加分類線性層。另外使用AutoModelForMaskedLM也可以,其實AutoModel最終返回的也是BertForMaskedLM,它是根據你config中的model_type去匹配的。
這里列一下BertForMaskedLM的關鍵源代碼說明一下transformers幫我們做了哪些關鍵事情
# 在__init__方法中增加增加了BertOnlyMLMHead,BertOnlyMLMHead其實就是一個二層神經網絡,一層是BertPredictionHeadTransform(包括linear+geluAct+ln),一層是decoder(hidden_size*vocab_size大小的linear)。
self.bert = BertModel(config, add_pooling_layer=False)
self.cls = BertOnlyMLMHead(config)
# 將輸出結果outputs取第一個返回值,也就是last_hidden_state
sequence_output = outputs[0]
# 將last_hidden_state輸入到cls層中,獲得最終結果(預測的score和詞)
prediction_scores = self.cls(sequence_output)
3.3 自動并隨機mask數據
關鍵代碼在于DataCollatorForLanguageModeling,該類會實現自動mask。參考torch_mask_tokens方法。
trainer = Trainer(model=model,args=train_args,train_dataset=new_datasets["train"],data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15),)
4 整體代碼
"""
基于BERT做完形填空
1)數據集來自:ChnSentiCorp
2)模型權重使用:bert-base-chinese
"""
# step 1 引入數據庫
from datasets import DatasetDict
from transformers import TrainingArguments, Trainer, BertTokenizerFast, BertForMaskedLM, DataCollatorForLanguageModeling, pipelinemodel_path = "./model/tiansz/bert-base-chinese"
data_path = "./data/ChnSentiCorp"# step 2 數據集處理
datasets = DatasetDict.load_from_disk(data_path)
tokenizer = BertTokenizerFast.from_pretrained(model_path)def process_function(datas):tokenized_datas = tokenizer(datas["text"], max_length=256, truncation=True)return tokenized_datasnew_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)# step 3 加載模型
model = BertForMaskedLM.from_pretrained(model_path)# step 4 創建TrainingArguments
# 原先train是9600條數據,batch_size=32,因此每個epoch的step=300
train_args = TrainingArguments(output_dir="./checkpoints", # 輸出文件夾per_device_train_batch_size=32, # 訓練時的batch_sizenum_train_epochs=1, # 訓練輪數logging_steps=30, # log 打印的頻率)# step 5 創建Trainer
trainer = Trainer(model=model,args=train_args,train_dataset=new_datasets["train"],# 自動MASK關鍵所在,通過DataCollatorForLanguageModeling實現自動MASK數據data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15),)# Step 6 模型訓練
trainer.train()# step 7 模型評估
pipe = pipeline("fill-mask", model=model, tokenizer=tokenizer, device=0)
str = datasets["test"][3]["text"]
str = str.replace("方便","[MASK][MASK]")
results = pipe(str)
# results[0][0]["token_str"]
print(results[0][0]["token_str"]+results[1][0]["token_str"])
5 運行效果

注:本文參考來自大神:https://github.com/zyds/transformers-code

)



2-1點亮一個LED)


 —— Collection)










