文章目錄
- 高并發場景下CAS效率的優化
- 1.空間換時間(LongAdder)
- 2.對比LongAdder和AtomicLong執行效率
- 2.1.AtmoictLong
- 2.2.LongAdder
- 2.3.比對
- 3.LongAdder原理
- 3.1.基類Striped64內部的三個重要成員
- 3.2.LongAdder.add()方法
- 3.3.LongAdder中longAccumulate()方法
- 3.4.LongAdder.casCellsBusy()方法
高并發場景下CAS效率的優化
在高并發情況下,CAS操作的自旋重試會導致系統開銷的增加,甚至有些線程可能進入一個無線重復的循環中。
除了存在CAS空自旋外,在SMP機構的CPU平臺上,大量的CAS操作還可能導致
"總線風暴"總線風暴是指在計算機系統中,由于大量的處理器或設備同時請求總線而導致的總線利用率驟增的現象。在多處理器系統或者高性能計算機中,當大量的處理器或者設備同時嘗試訪問系統總線時,可能會出現總線的瓶頸,導致系統性能下降或者崩潰。
總線風暴通常發生在以下情況下:
- 大量處理器競爭總線資源: 在多處理器系統中,如果大量的處理器同時競爭總線資源,比如同時發送讀寫請求或者數據傳輸請求,就會導致總線的繁忙,進而引發總線風暴。
- 外設訪問頻繁: 除了處理器外,系統中的其他外設,如存儲設備、網絡接口等,如果頻繁地訪問總線,也可能造成總線風暴。
總線風暴會帶來嚴重的系統性能問題,包括但不限于:
- 性能下降: 總線風暴會導致總線資源的過度利用,從而降低了其他設備和處理器對總線的訪問效率,系統的整體性能會因此下降。
- 數據丟失和沖突: 當多個設備同時請求總線時,可能會導致數據的丟失和沖突,影響數據的正確傳輸和處理。
- 系統穩定性問題: 如果總線風暴持續時間較長或者嚴重程度較高,可能會導致系統崩潰或者死鎖等嚴重的穩定性問題。
主要影響的有一下幾方面:
-
競爭激烈導致自旋時間延長: 當有多個線程同時競爭同一份資源時,只有一個線程能夠成功執行CAS操作,其他線程將會不斷進行自旋重試。如果競爭激烈,那么自旋時間會變得非常長,因為每個線程都需要等待前一個線程釋放資源,才能嘗試進行CAS操作。這樣一來,自旋的時間延長會增加系統的開銷,降低系統的性能。
-
上下文切換開銷增加: 自旋重試過程中,如果一個線程在自旋過程中被搶占,需要進行上下文切換到其他線程,再切回來時會帶來額外的開銷。在高并發情況下,頻繁的上下文切換會導致系統資源的浪費,降低系統的整體性能。
-
緩存競爭增加: 當多個線程同時競爭同一份資源時,由于緩存一致性協議的存在,會導致緩存行的競爭和緩存行的無效化。這會增加緩存訪問的延遲和內存總線的壓力,進而影響系統的性能。
-
對系統負載的影響: 隨著自旋重試次數的增加,系統的負載也會增加。這會影響系統的響應速度和吞吐量,導致系統的整體性能下降。
1.空間換時間(LongAdder)
JDK8,提供了一個新的類,LongAdder,以空間換時間的方式提升高并發場景下CAS的操作性能。
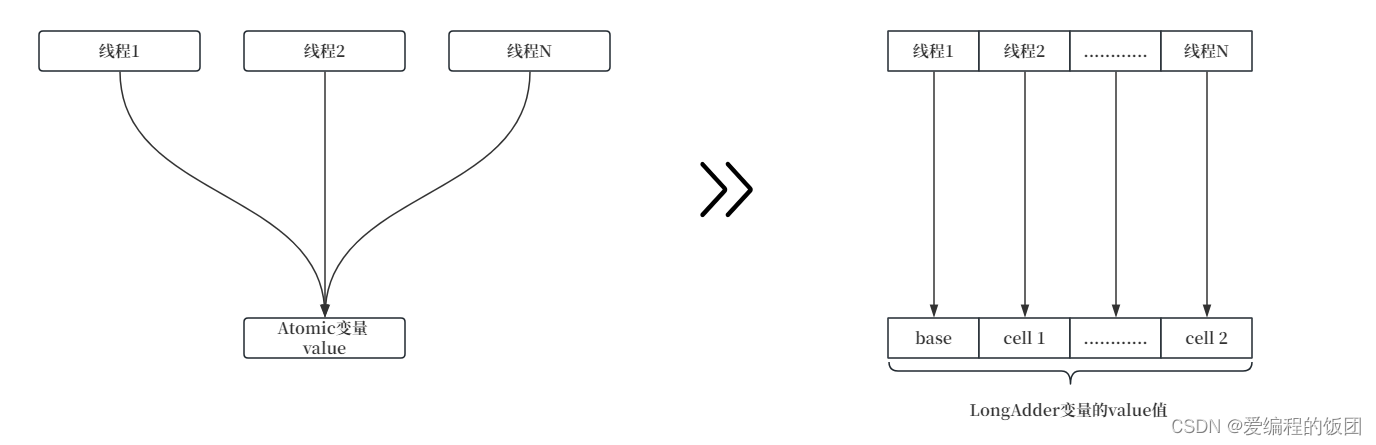
LongAdder是Java并發包(java.util.concurrent)中提供的一種用于高并發環境下的原子累加器類型。它主要解決了在高并發情況下使用AtomicLong時可能出現的性能瓶頸問題。核心思想就是:熱點分離
LongAdder的主要特點和優勢包括:
-
分段累加: LongAdder內部采用了分段的方式來進行累加操作。它將累加器的值分成多個段,每個段有一個獨立的累加器變量,稱為"cell"。這樣,在高并發情況下,不同線程可以同時對不同段的累加器進行操作,減少了線程競爭,提高了并發性能。(將value值分割成一個數組,當多線程訪問時,通過Hash算法將線程映射到一個元素進行操作,從而獲取value的結果,最終將數組的元素求和)
-
無鎖操作: LongAdder的每個段都是獨立的,因此在對各個段進行累加操作時,并不需要加鎖。它使用了一種類似于CAS(Compare And Swap)的樂觀鎖機制,避免了使用全局鎖帶來的性能損耗。
-
高并發性能: 在高并發環境下,LongAdder的性能明顯優于AtomicLong。由于采用了分段累加和無鎖操作,LongAdder能夠更好地應對大量線程同時對累加器進行操作的情況,從而提高了系統的并發性能。
-
自動擴容: 如果當前的線程數量超過了初始分段的數量,LongAdder會自動擴容,增加更多的段來適應更大的并發量,從而保持較高的性能。
-
統計匯總: LongAdder提供了
sum()方法來獲取所有段的累加器值的總和,方便對累加結果進行統計和匯總。
2.對比LongAdder和AtomicLong執行效率
下面我們做個小實驗,通過代碼來觀察一下 LongAdder和AtomicLong執行的一個效率,我們使用10個線程,每個線程累計累加1000次管家一下執行時間
2.1.AtmoictLong
private static final Logger log = LoggerFactory.getLogger(LongAdderTest.class);@Test@DisplayName("測試AtmoictLong的執行效率")public void testLongAdder() {long start = System.currentTimeMillis();CountDownLatch latch = new CountDownLatch(10);AtomicLong longAdder = new AtomicLong();ArrayList<Thread> threads = new ArrayList<>();for (int j = 0; j <10; j++) {threads.add(new Thread(()->{for (int i = 0; i < 1000000000; i++) {longAdder.incrementAndGet();}latch.countDown();}));}// 啟動全部線程threads.forEach(Thread::start);// 等待全部線程執行完畢try {latch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}long end = System.currentTimeMillis();log.error("執行結果:{}",longAdder.longValue());log.error("執行耗時:{}ms",end-start);}
2.2.LongAdder
@Test@DisplayName("測試LongAdder的執行效率")public void testLongAdder() {long start = System.currentTimeMillis();CountDownLatch latch = new CountDownLatch(10);LongAdder longAdder = new LongAdder();ArrayList<Thread> threads = new ArrayList<>();for (int j = 0; j <10; j++) {threads.add(new Thread(()->{for (int i = 0; i < 1000000000; i++) {longAdder.add(1);}latch.countDown();}));}// 啟動全部線程threads.forEach(Thread::start);// 等待全部線程執行完畢try {latch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}long end = System.currentTimeMillis();log.error("執行結果:{}",longAdder.longValue());log.error("執行耗時:{}ms",end-start);}

2.3.比對
但是LongAdder 也不是任意場景下都比 Atomic塊,如果數量量小的情況下,AtomicLong的速度要更快一些的
AtomicLong 是一種基于 CAS(Compare And Swap)的方式實現的原子操作類,適用于并發量比較小的場景。它在單個變量上執行原子操作,適用于高并發但并發量不是特別大的情況。因為它的實現比較輕量級,適合于競爭激烈但線程數量不是特別多的情況。
LongAdder 則是針對高并發場景做了優化的一種方式。它將變量分散到多個單元中,并行地執行更新操作,然后在需要獲取當前值的時候將這些單元的值合并起來。這種方式在高并發的情況下能夠減小競爭,從而提高性能。但是在并發量比較小的情況下,這種分散和合并的操作會帶來額外的開銷,使得 LongAdder 的性能略遜于 AtomicLong。
選擇使用 LongAdder 還是 AtomicLong 取決于具體場景和需求。
3.LongAdder原理
AtomicLong使用內部變量value保存的實際的long值,所有的操作都是針對該value變量進行,在高并發的環境下面,value變量其實就是一個熱點,也就是N個線程競爭一個熱點。重新線程越多,也就意味著CAS失敗的概率越高,從而進入惡性的CAS自旋狀態
LongAdder的基本思路就是分散熱點,將value值分散到一個數組中,不同線程會命中不同槽中的元素,每個線程只能對自己槽中的那個值進行CAS操作,這樣熱點就被分散了,沖突的概率就小很多了
LongAdder的實現思路其實和CurrentHashMap中分段使用的原理非常相似,本質上都是不同的線程,在不同的單元上進行操作,減少了線程的競爭,提高了并發的效率。
LongAdder的內部成員包含一個base值 和 一個cells數組,在最初無競爭的時候,只能操作base的值。只有當線程執行CAS失敗后,才會初始cells數組,并為線程分配所對應的元素。
LongAdder的設計目的是為了在高并發情況下提供更好的性能,相比于傳統的原子操作類(比如 AtomicLong),在高并發下可以減少競爭。
- LongAdder 的核心思想是將一個 long 類型的值分解成多個單元(cell),每個單元都是獨立的,每個單元保存一部分的累加值。
- 當多個線程同時對 LongAdder 進行累加操作時,LongAdder 會根據線程的哈希值選擇不同的單元進行累加操作,這樣可以減小競爭。如果發生了哈希沖突,會采用 CAS 操作嘗試更新單元的值。
- 當需要獲取當前值時,LongAdder 會將所有單元的值累加起來,得到最終的結果。由于每個單元都是獨立的,所以在獲取值的時候不需要加鎖,可以并行地進行。這樣就減小了獲取值時的開銷,提高了性能。
核心優勢
- 減小競爭:通過分段累加和并行更新,減小了多線程下的競爭,提高了性能。
- 并行計算:在獲取值時,可以并行地將所有單元的值累加起來,減小了獲取值時的開銷。
總的來說,LongAdder 的設計思路清晰,將累加操作分解成多個獨立的單元,通過分段累加和并行計算提高了在高并發情況下的性能表現。
3.1.基類Striped64內部的三個重要成員
LongAdder繼承 Striped64類,base值和cells數組都在Striped64類中定義,其中比較重要的幾個成員有
/*** Table of cells. When non-null, size is a power of 2.*/ transient volatile Cell[] cells;/*** Base value, used mainly when there is no contention, but also as* a fallback during table initialization races. Updated via CAS.*/ transient volatile long base;/*** Spinlock (locked via CAS) used when resizing and/or creating Cells.*/ transient volatile int cellsBusy;
1. cells
- 描述:
cells是一個volatile Cell[]類型的數組,用于存儲多個單元(Cell)。存放cell的哈希表,大小為2的冪 - 作用:每個單元(
Cell)都包含一個volatile long類型的變量,用于存儲一部分累加值。cells數組的每個元素都可以被多個線程同時訪問和修改,用于存儲累加值的其他部分。
2. base
- 描述:
base是一個volatile long類型的變量,用于存儲一部分累加值。 - 作用:
base可以被多個線程同時訪問和修改,用于存儲累加值的一部分。
3. cellsBusy
- 描述:
cellsBusy是一個volatile int類型的變量,用作自旋鎖。 - 作用:在進行數組擴容或者創建新的
Cell單元時,通過 CAS 操作來獲取鎖,以保證只有一個線程進行擴容或者創建操作。
Striped64的整體值value獲取如下
// LongAdder中
/*** 獲取當前累加器的值(long類型)。* @return 當前累加器的值*/
public long longValue() {return sum();
}/*** 計算累加器中所有單元值的總和。** @return 累加器中所有單元值的總和*/
public long sum() {// 獲取單元數組的引用Cell[] cs = cells;// 初始化總和為基本值long sum = base;// 如果單元數組不為null,則遍歷每個單元并累加值到總和if (cs != null) {for (Cell c : cs)if (c != null)sum += c.value;}return sum; // 返回總和
}
sum()方法首先獲取了當前累加器中的單元數組cells的引用,并將基本值base賦值給sum變量,作為初始總和。- 然后,如果單元數組
cells不為 null,就遍歷每個單元,將單元中的值累加到總和sum中。 - 最后返回總和
sum,即為累加器中所有單元值的總和。
3.2.LongAdder.add()方法
作為示例這里分析一下LongAdder的add方法
/*** 將給定的值添加到累加器中。** @param x 要添加的值*/
public void add(long x) {Cell[] cs; // 單元數組long b, v; // 基本值和單元值int m; // 單元數組長度減一Cell c; // 單元對象// 如果單元數組不為null,或者通過CAS操作將基本值更新為原基本值加上x成功if ((cs = cells) != null || !casBase(b = base, b + x)) {// 獲取當前線程的哈希值int index = getProbe();// 默認情況下,當前線程沒有爭用(即不與其他線程競爭)boolean uncontended = true;// 如果單元數組為空,或者單元數組長度減一小于0,或者單元數組中的單元為空,或者單元中的值通過CAS操作更新失敗if (cs == null || (m = cs.length - 1) < 0 ||(c = cs[index & m]) == null ||!(uncontended = c.cas(v = c.value, v + x)))// 調用longAccumulate方法進行累加操作longAccumulate(x, null, uncontended, index);}
}/*** 通過CAS操作來更新基本值。** @param cmp 期望值* @param val 新值* @return 如果更新成功返回true,否則返回false*/
final boolean casBase(long cmp, long val) {// 調用 BASE 中的 weakCompareAndSetRelease 方法,嘗試使用 CAS 操作更新基本值return BASE.weakCompareAndSetRelease(this, cmp, val);
}add方法首先嘗試通過 CAS 操作將給定的值累加到基本值base上。如果成功,方法結束。- 如果 CAS 操作失敗,說明存在競爭或者
cells數組不為 null,則獲取當前線程的哈希值,并嘗試更新對應的單元。 - 如果更新單元的過程中發生競爭或者單元數組為空,則調用
longAccumulate方法進行累加操作。 - 這種設計能夠有效地減少競爭,提高并發性能,尤其在高并發情況下,避免了多個線程同時更新同一個單元造成的性能下降。
3.3.LongAdder中longAccumulate()方法
longAccumulate()方法是Striped64中重要的方法,主要是實現不同線程更新各自Cell中的值,其邏輯類似于分段式鎖。
/*** 通過 CAS 操作來累加給定的值。** @param x 要累加的值* @param fn 用于累加的操作函數* @param wasUncontended 標志位,表示當前線程是否為無競爭狀態* @param index 當前線程的哈希碼*/
final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended, int index) {// 如果哈希碼為0,則重新計算哈希碼并標記為無競爭狀態if (index == 0) {ThreadLocalRandom.current(); // 強制初始化隨機數生成器index = getProbe(); // 獲取當前線程的哈希碼wasUncontended = true; // 標記為無競爭狀態}// 循環嘗試進行累加操作for (boolean collide = false;;) { // 標志位,表示上一次操作是否發生哈希沖突Cell[] cs; // 單元數組Cell c; // 單元對象int n; // 單元數組長度long v; // 單元值// 如果單元數組不為null且長度大于0if ((cs = cells) != null && (n = cs.length) > 0) {// 計算單元數組中的索引if ((c = cs[(n - 1) & index]) == null) {// 如果對應的單元為空if (cellsBusy == 0) { // 嘗試創建新的單元Cell r = new Cell(x); // 樂觀地創建單元if (cellsBusy == 0 && casCellsBusy()) { // 嘗試獲取單元數組更新鎖try { // 在鎖定狀態下重新檢查Cell[] rs; // 重新檢查后的單元數組int m, j; // 單元數組長度和索引if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & index] == null) {rs[j] = r; // 更新單元數組break; // 跳出循環}} finally {cellsBusy = 0; // 釋放單元數組更新鎖}continue; // 重新嘗試操作}}collide = false; // 未發生哈希沖突}else if (!wasUncontended) // 如果已知CAS操作失敗wasUncontended = true; // 繼續哈希沖突后的操作else if (c.cas(v = c.value,(fn == null) ? v + x : fn.applyAsLong(v, x)))break; // 累加操作成功,跳出循環else if (n >= NCPU || cells != cs)collide = false; // 達到最大大小或者單元數組失效else if (!collide)collide = true; // 發生哈希沖突else if (cellsBusy == 0 && casCellsBusy()) { // 嘗試獲取單元數組更新鎖try { // 在鎖定狀態下重新檢查if (cells == cs) // 如果單元數組未被其他線程修改cells = Arrays.copyOf(cs, n << 1); // 擴容單元數組} finally {cellsBusy = 0; // 釋放單元數組更新鎖}collide = false; // 未發生哈希沖突continue; // 重新嘗試操作}index = advanceProbe(index); // 更新哈希碼}else if (cellsBusy == 0 && cells == cs && casCellsBusy()) { // 嘗試獲取單元數組更新鎖try { // 在鎖定狀態下初始化單元數組if (cells == cs) { // 雙重檢查Cell[] rs = new Cell[2]; // 創建新的單元數組rs[index & 1] = new Cell(x); // 初始化單元cells = rs; // 更新單元數組break; // 跳出循環}} finally {cellsBusy = 0; // 釋放單元數組更新鎖}}else if (casBase(v = base,(fn == null) ? v + x : fn.applyAsLong(v, x))) // 使用基本值進行累加操作break; // 累加操作成功,跳出循環}
}這里主要分為 五個個部分,四個判斷(其實主要就是后三個判斷),一個自旋更新
- 第一個 if 分支:
- 當前線程的哈希碼為0時,重新計算哈希碼并標記為無競爭狀態。
- 通過
getProbe()方法獲取當前線程的哈希碼。 - 如果當前線程的哈希碼為0,強制初始化隨機數生成器,然后重新獲取哈希碼,并標記為無競爭狀態。
- 循環部分:
- 這是一個無限循環,直到累加操作成功并跳出循環。
- 有一個
collide變量用于標記上一次操作是否發生了哈希沖突。
- 第二個 if 分支:
- 如果
cells數組不為 null 且長度大于 0。 - 獲取
cells數組中對應的單元。 - 如果單元為空,則嘗試創建新的單元,如果成功則更新單元數組并跳出循環,否則繼續嘗試操作。
- 如果單元不為空,則嘗試進行 CAS 操作更新單元的值,如果成功則累加操作完成并跳出循環,否則繼續嘗試操作。
- 如果單元數組達到了最大大小或者單元數組失效,則標記為未發生哈希沖突。
- 如果發生了哈希沖突且沒有其他線程在擴容單元數組,則嘗試擴容單元數組并繼續操作。
- 如果
- 第三個 if 分支:
- 如果
cells數組為 null 且沒有其他線程在初始化單元數組,則嘗試初始化單元數組。 - 如果成功初始化單元數組,則在其中創建一個新的單元并跳出循環。
- 如果
- 最后一個 else 分支 :
- 如果無法避免競爭,則使用基本值進行累加操作。
- 如果成功,則累加操作完成并跳出循環。
3.4.LongAdder.casCellsBusy()方法
casCellsBusy 方法是 LongAdder 類中的一個私有方法,用于通過 CAS(比較并交換)操作嘗試獲取單元數組更新鎖。當 cellsBusy 的值為0時,表示鎖是空閑的,此時該方法會嘗試將 cellsBusy 的值從0更新為1,即獲取鎖。如果成功獲取鎖,則表示當前線程獲得了單元數組的更新權限,可以進行單元數組的更新操作;如果獲取鎖失敗,說明有其他線程已經持有了更新鎖,當前線程需要等待。
初始時,LongAdder 中的 cells 數組為 null,此時 casCellsBusy 的主要作用是在第一個線程進行累加操作時,嘗試初始化單元數組并獲取更新鎖。如果當前沒有其他線程持有更新鎖,那么第一個線程通過 casCellsBusy 方法可以成功獲取更新鎖,并在更新鎖的保護下進行單元數組的初始化。如果有其他線程在嘗試初始化單元數組,那么第一個線程就需要等待,直到其他線程釋放了更新鎖。
/*** 通過 CAS 操作來嘗試獲取單元數組更新鎖。** @return 如果成功獲取鎖則返回 true,否則返回 false*/
final boolean casCellsBusy() {// 使用 CELLSBUSY 的 compareAndSet 方法嘗試將單元數組更新鎖從0更新為1return CELLSBUSY.compareAndSet(this, 0, 1);
}
注意
當 cellsBusy 成員值為1時,表示 cells 數組正在被某個線程執行初始化或者擴容操作。在這種情況下,其他線程不能立即進行如下操作:
- 無法更新單元數組的值:由于可能存在單元數組的結構變化(例如初始化或者擴容),其他線程不能直接更新單元數組的值。因為這樣做可能會導致并發沖突或者數據丟失。
- 無法獲取單元數組的更新鎖:
casCellsBusy方法會失敗,因為單元數組的更新鎖已經被其他線程持有。這意味著其他線程不能立即獲取到單元數組的更新權限,需要等待當前的初始化或者擴容操作完成后才能嘗試獲取鎖并執行更新操作。 - 無法創建新的單元:當某個線程嘗試創建新的單元時,如果單元數組的某個位置為
null,那么這個線程也不能立即將新的單元放置到該位置。因為該位置可能在被其他線程進行初始化或者擴容操作,直接放置新的單元可能導致數據丟失或者覆蓋其他線程的操作。
因此,在 cellsBusy 成員值為1時,其他線程必須等待當前的初始化或者擴容操作完成后,才能安全地進行對 cells 數組的操作,以確保線程安全和數據一致性。












)




)

