目錄
前言
一、MyDataset文件
二、完整代碼:
三、結果展示:
四、添加accuracy值
- 🍨 本文為🔗365天深度學習訓練營?中的學習記錄博客
- 🍖 原作者:K同學啊 | 接輔導、項目定制
本周的學習內容是,使用pytorch實現車牌識別。
前言
????????之前的案例里面,我們大多是使用的是datasets.ImageFolder函數,直接導入已經分類好的數據集形成Dataset,然后使用DataLoader加載Dataset,但是如果對無法分類的數據集,我們應該如何導入呢。
????????這篇文章主要就是介紹通過自定義的一個MyDataset加載車牌數據集并完成車牌識別。
一、MyDataset文件
數據文件是這樣的,沒有進行分類的。

# 加載數據文件
class MyDataset(data.Dataset):def __init__(self, all_labels, data_paths_str, transform):self.img_labels = all_labels # 獲取標簽信息self.img_dir = data_paths_str # 圖像目錄路徑self.transform = transform # 目標轉換函數def __len__(self):return len(self.img_labels) # 返回數據集的長度,即標簽的數量def __getitem__(self, index):image = Image.open(self.img_dir[index]).convert('RGB') # 打開指定索引的圖像文件,并將其轉換為RGB模式label = self.img_labels[index] # 獲取圖像對應的標簽if self.transform:image = self.transform(image) # 如果設置了轉換函數,則對圖像進行轉換(如,裁剪、縮放、歸一化等)return image, label # 返回圖像和標簽二、完整代碼:
import pathlibimport matplotlib.pyplot as plt
import numpy as np
import torch
from PIL import Image
from torch import nn
from torch.utils import data
from torchvision import transforms
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib as mpl
mpl.use('Agg') # 在服務器上運行的時候,打開注釋device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)data_dir = './data'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classNames = [str(path).split('/')[1].split('_')[1].split('.')[0] for path in data_paths]
# print(classNames) # '滬G1CE81', '云G86LR6', '鄂U71R9F', '津G467JR'....data_paths_str = [str(path) for path in data_paths]# 數據可視化
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(14,5))
plt.suptitle('data show', fontsize=15)
for i in range(18):plt.subplot(3, 6, i+1)# 顯示圖片images = plt.imread(data_paths_str[i])plt.imshow(images)
plt.show()# 3、標簽數字化
char_enum = ["京","滬","津","渝","冀","晉","蒙","遼","吉","黑","蘇","浙","皖","閩","贛","魯","豫","鄂","湘","粵","桂","瓊","川","貴","云","藏","陜","甘","青","寧","新","軍","使"]number = [str(i) for i in range(0, 10)] # 0-9 的數字
alphabet = [chr(i) for i in range(65, 91)] # A到Z的字母
char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(classNames[0])# 將字符串數字化
def text2vec(text):vector = np.zeros([label_name_len, char_set_len])for i, c in enumerate(text):idx = char_set.index(c)vector[i][idx] = 1.0return vectorall_labels = [text2vec(i) for i in classNames]# 加載數據文件
class MyDataset(data.Dataset):def __init__(self, all_labels, data_paths_str, transform):self.img_labels = all_labels # 獲取標簽信息self.img_dir = data_paths_str # 圖像目錄路徑self.transform = transform # 目標轉換函數def __len__(self):return len(self.img_labels)def __getitem__(self, index):image = Image.open(self.img_dir[index]).convert('RGB')label = self.img_labels[index] # 獲取圖像對應的標簽if self.transform:image = self.transform(image)return image, label # 返回圖像和標簽total_datadir = './data/'
train_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])total_data = MyDataset(all_labels, data_paths_str, train_transforms)
# 劃分數據
train_size = int(0.8*len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data,[train_size, test_size])
print(train_size, test_size) # 10940 2735# 數據加載
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=16, shuffle=True)for X, y in test_loader:print('Shape of X [N,C,H,W]:',X.shape) # ([16, 3, 224, 224])print('Shape of y:', y.shape, y.dtype) # torch.Size([16, 7, 69]) torch.float64break# 搭建網絡模型
class Network_bn(nn.Module):def __init__(self):super(Network_bn, self).__init__()"""nn.Conv2d()函數:第一個參數(in_channels)是輸入的channel數量第二個參數(out_channels)是輸出的channel數量第三個參數(kernel_size)是卷積核大小第四個參數(stride)是步長,默認為1第五個參數(padding)是填充大小,默認為0"""self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn2 = nn.BatchNorm2d(12)self.pool = nn.MaxPool2d(2, 2)self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn4 = nn.BatchNorm2d(24)self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn5 = nn.BatchNorm2d(24)self.fc1 = nn.Linear(24 * 50 * 50, label_name_len * char_set_len)self.reshape = Reshape([label_name_len, char_set_len])def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.pool(x)x = F.relu(self.bn4(self.conv4(x)))x = F.relu(self.bn5(self.conv5(x)))x = self.pool(x)x = x.view(-1, 24 * 50 * 50)x = self.fc1(x)# 最終reshapex = self.reshape(x)return xclass Reshape(nn.Module):def __init__(self,shape):super(Reshape, self).__init__()self.shape = shapedef forward(self, x):return x.view(x.size(0), *self.shape)model = Network_bn().to(device)
print(model)# 優化器與損失函數
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=0.0001)
loss_model = nn.CrossEntropyLoss()def test(model, test_loader, loss_model):size = len(test_loader.dataset)num_batches = len(test_loader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in test_loader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_model(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchesprint(f'Avg loss: {test_loss:>8f}\n')return correct, test_lossdef train(model,train_loader, loss_model, optimizer):model = model.to(device)model.train()for i, (images, labels) in enumerate(train_loader, 0): # 0 是標起始位置的值images = Variable(images.to(device))labels = Variable(labels.to(device))optimizer.zero_grad()outputs = model(images)loss = loss_model(outputs, labels)loss.backward()optimizer.step()if i % 100 == 0:print('[%5d] loss: %.3f' % (i, loss))# 模型的訓練
test_acc_list = []
test_loss_list = []
epochs = 30
for t in range(epochs):print(f"Epoch {t+1}\n-----------------------")train(model,train_loader, loss_model,optimizer)test_acc,test_loss = test(model, test_loader, loss_model)test_acc_list.append(test_acc)test_loss_list.append(test_loss)print('Done!!!')# 結果分析
x = [i for i in range(1,31)]
plt.plot(x, test_loss_list, label="Loss", alpha = 0.8)
plt.xlabel('Epoch')
plt.ylabel('Loss')plt.legend()
plt.show()
plt.savefig("/data/jupyter/deep_demo/p10_car_number/resultImg.jpg") # 保存圖片在服務器的位置
plt.show()三、結果展示:



總結:從剛開始損失為0.077 到,訓練30輪后,損失到了0.026。
四、添加accuracy值
需求:對在上面的代碼中,對loss進行了統計更新,請補充acc統計更新部分,即獲取每一次測試的ACC值。
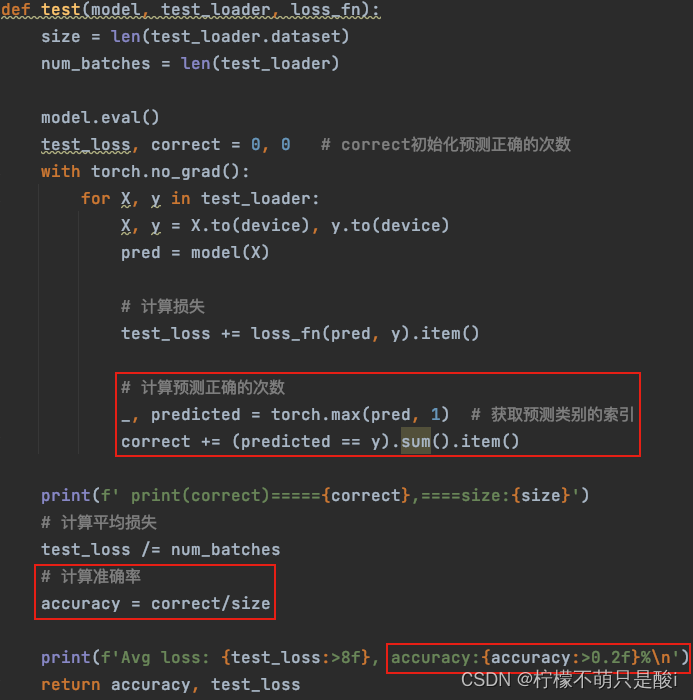
添加accuracy的運行過程:
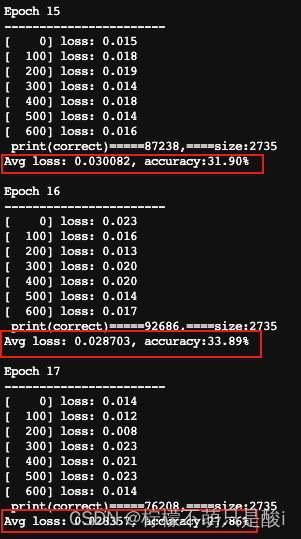 ?
?
)


















