一、場景描述
我們登陸HDFS的web端,上傳一個大文件。
二、流程圖
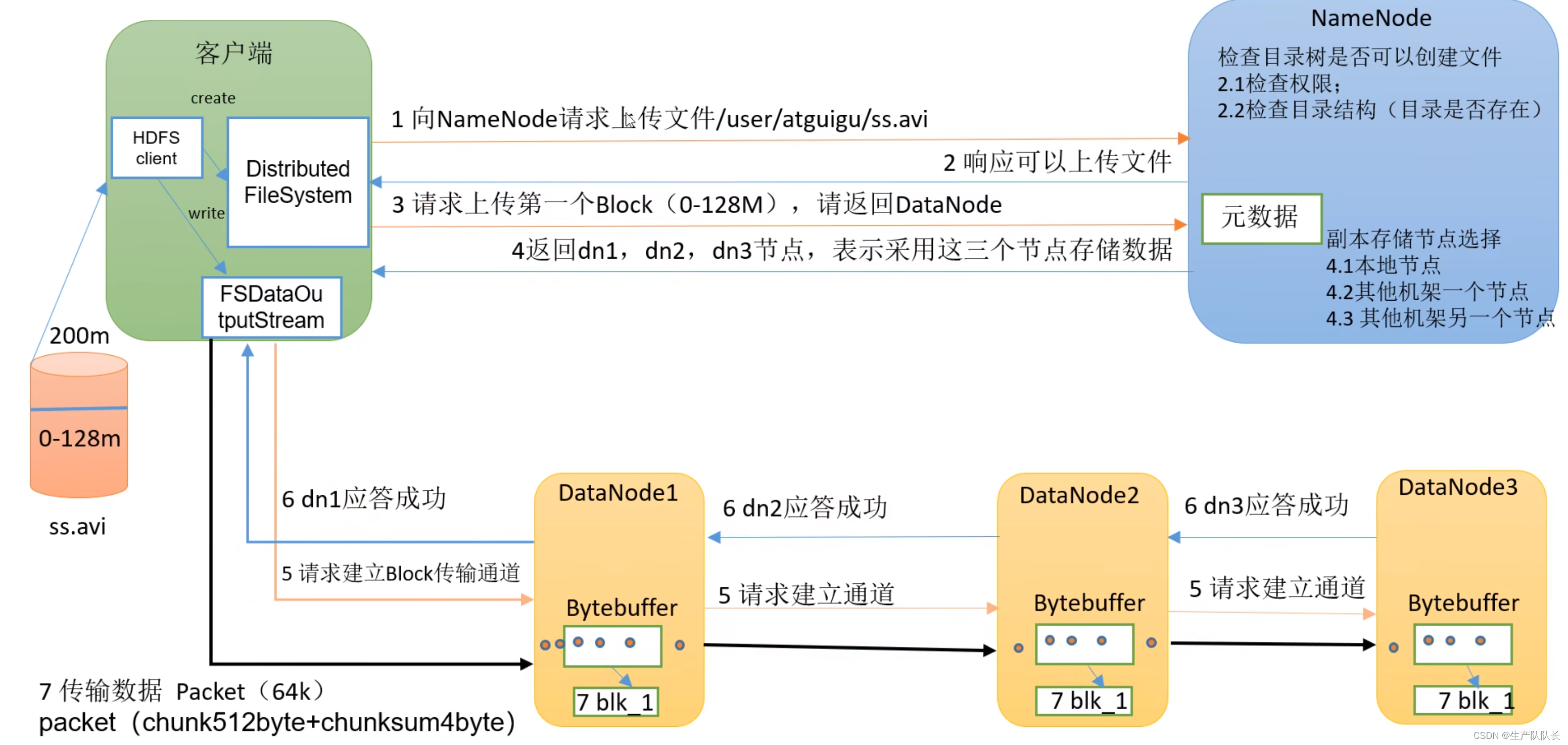
三、講解
流程1(Client與NameNode交互)
1、HDFS client創建DistributedFileSystem,通過dfs與NameNode進行2次(一來一回4次)對話(request和response),如圖所示。
2、第1次請求,NameNode會進行2.1和2.2的檢查工作。
3、第2次請求,上傳一個Block,NameNode選定的存儲數據的節點(DataNode),返回給client。
流程2(Client與DataNode交互)
4、HDFS client創建FSDataOutputStream(一種輸出流),通過它和集群中選定的存儲數據的DataNode交互
5、首先,和選定的DataNode打通數據流通道。
這里,client只需要和最近的節點直接交互,其他副本節點和該節點交互,無需和client交互。這里涉及到最近節點距離計算。
6、開始傳輸數據給最近節點,這里傳輸的時候,DataNode會先存一份在內存,同時,用內存的數據,寫入磁盤和傳輸到其他DataNode節點。就是圖中第7步。
7、所有節點存儲完成后,依次返回ack(了解消息隊列的,比如kafka,都知道ack是什么吧),告知存儲結果。最終由最近節點,反饋給client存儲結果。
8、當一個Block傳完之后,客戶端會再次請求NameNode,再次上傳一個Block。重復步驟3-8,直到,完整的文件傳輸完畢。



)

)





)

)


)


