目錄
概要
Motivation
整體架構流程
技術細節
小結
論文地址:基于改進YOLOv5算法的密集動態目標檢測方法 - 中國知網 (cnki.net)
概要
目的:提出一種基于 YOLOv5改進的檢測算法,解決密集動態目標檢測精度低及易漏檢的問題。
方法:在 YOLOv5的主干網絡中使用 QARepNeXt結構提高深度學習模型訓練速度;引入 S2-MLPv2注意力機制改善遮擋情況下檢測效果差的問題;將具有動態聚焦機制的邊界回歸損失函數 Wise-IoU 替代 原有損失函數提高收斂速度。
結果:通過在公開數據集上的實驗驗證,改進算法在密集行人檢測任務中表現出了更高的檢測精度、更低的漏檢率和更好的檢測效果。相較于原始YOLOv5s網絡模型,改進后的算法模型在復雜環境下展示了更強的魯棒性和泛化能力,能夠有效應用于密集動態目標檢測及其相關領域。
結論:通過引入QARepNeXt結構、S2-MLPv2注意力機制和Wise-IoU損失函數,優化了YOLOv5s網絡,提升了密集動態目標檢測的性能。這一改進算法在實際應用中具有重要的潛力,尤其在行人檢測等密集場景下表現出色,為相關領域的研究提供了新的思路和方法。
Motivation
- 密集動態目標檢測,遮擋導致的檢測精度低和漏檢率高。
- 于行人尺度較小,檢測難 度也增加。
整體架構流程
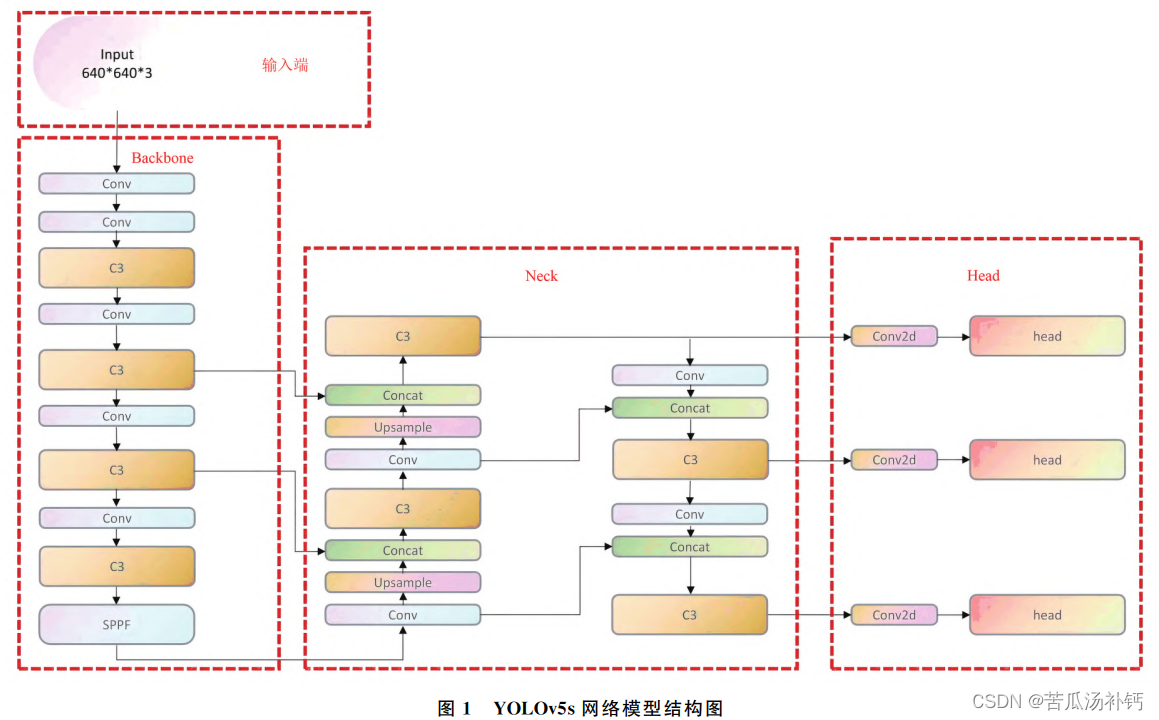
一種基于改進YOLOv5s算法的密集動態目標檢測方法。主要改進包括:
1. 主干網絡優化:引入QARepNeXt模塊,增強網絡特征提取和融合能力,提高檢測精度。
2. 特征融合階段改進:加入S2-MLPv2注意力機制,有效提取圖像關鍵信息,提高對遮擋目標的關注度。
3. 損失函數替換:采用Wise-IoU損失函數,提高模型的收斂能力和檢測精度。
技術細節
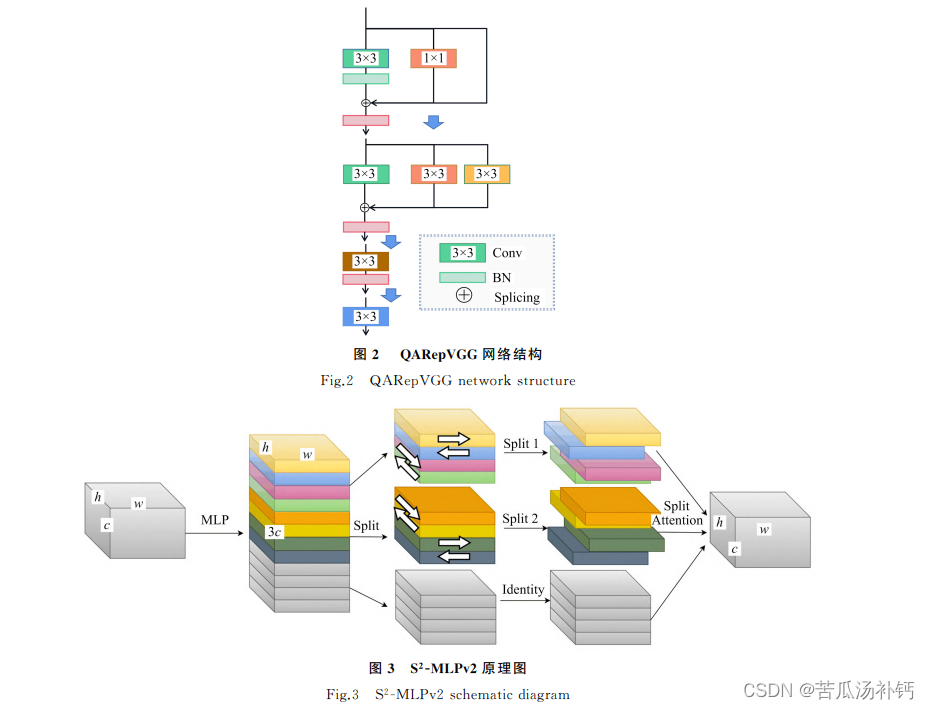
YOLOv5原始主干網絡采用3×3的卷積模塊,對非密集場景下的目標識別任務具有出色的能力,但在密集場景和被識別物有遮擋的情況下很難提取到有效特征信息,為此論文研究對傳統的 RepVGG 結構進行修改,引入更加友好的量化感知模塊 QARepNeXt。
為使網絡具有更好的量化性能,引用一種在 RepVGG 的基礎上改進的網絡結構 QARepVGG(Quantization-AwareRepVGG),不會在訓練過程中遭受量化崩潰,與 RepVGG 結構相比其量化性能得到很大程度的提升。
為提高特征信息的利用率,研究引入 S2-MLPv2注意力機制模塊。

在對畫面中的目標進行檢測時,由于視野內可能存在多個目標,算法會生成多個預測框。為了消除冗 余的預測框,通常需要采用非極大值抑制(Non-MaximumSuppression,NMS)方法。NMS算法會根據預 測框的置信度和重疊度進行篩選,保留置信度最高的預測框,并去除與其重疊度高的其他預測框,從而得 到最終的檢測結果。這樣可以有效地去除冗余的預測框,提高檢測的準確性和效率。
小結

針對密集動態目標檢測精度低及易漏檢的問題,本研究提出了一種基于 YOLOv5s 網絡改進的算法模型。改進的算法模型在以下幾個方面進行了優化:
1. 主干網絡優化:引入了量化性能更佳的 QARepNeXt 結構。QARepNeXt 結構通過優化網絡量化性能,提高了特征提取能力。相比原始 YOLOv5s 網絡模型,這種改進能夠更有效地捕捉并表征圖像中的重要特征。
2. 特征融合階段改進:在特征融合階段加入了 S2-MLPv2 注意力機制。S2-MLPv2 通過增強特征信息的利用率,提高了網絡對遮擋目標的關注度。這使得網絡在處理密集和動態目標時,能夠更準確地進行檢測,減少漏檢現象。
3. 損失函數替換:原有網絡的損失函數被替換為回歸性能更優秀的 Wise-IoU 損失函數。Wise-IoU 損失函數能夠更好地衡量預測框與真實框之間的重疊情況,提高檢測精度和回收率。
4. 實驗驗證:在公開數據集上進行了一系列實驗。實驗結果表明,優化后的算法在測量精確度、回收率和平均精度等方面都有顯著提升。相較于原始 YOLOv5s 網絡,改進模型表現出了更強的魯棒性和泛化能力。
綜上所述,通過在主干網絡、特征融合和損失函數等方面的改進,優化后的 YOLOv5s 算法模型有效提升了密集動態目標檢測的精度和可靠性,適用于密集動態目標檢測及其相關領域。

)

)

ADP5360ACBZ-1-R7 電量計 電池管理IC,ADP5072ACBZ 雙通道直流開關穩壓器,ADL5903ACPZN 射頻檢測器)










Vue)

)
