MHD、MQA、GQA注意力機制詳解
- 注意力機制詳解及代碼
- 前言:
- MHA
- MQA
- GQA
注意力機制詳解及代碼
前言:
自回歸解碼器推理是 Transformer 模型的 一個嚴重瓶頸,因為在每個解碼步驟中加 載解碼器權重以及所有注意鍵和值會產生 內存帶寬開銷
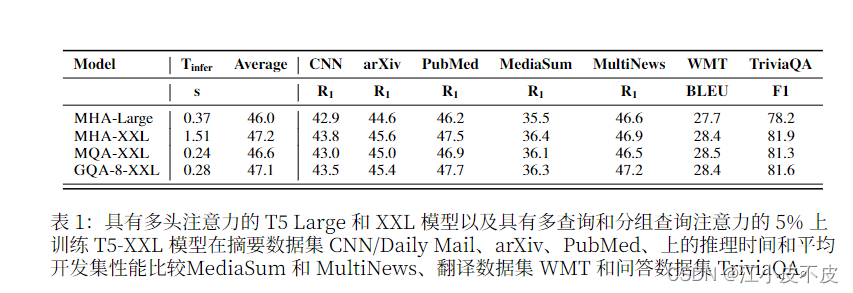
下圖為三種注意力機制的結構圖和實驗結果
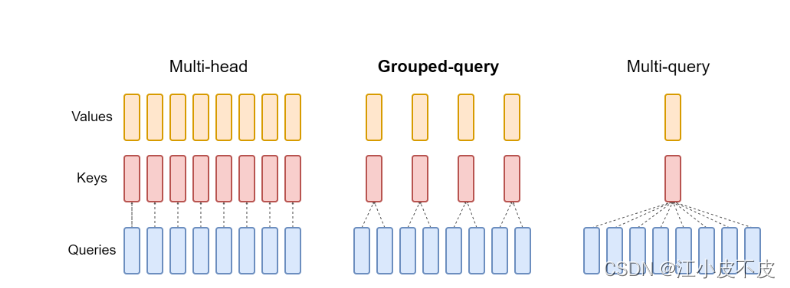
MHA
多頭注意力機制是Transformer模型中的核心組件。在其設計中,"多頭"意味著該機制并不只計算一種注意力權重,而是并行計算多種權重,每種權重都從不同的“視角”捕獲輸入的不同信息。
- hidden_state經過線性層得到q、k、v
- q、k、v經過split后增加一個維度:num_heads
- q、k計算注意力分數score
- softmax對注意力分數進行歸一化得到注意力權重attention_probs
- 使用注意力權重和值計算輸出:output
- 對注意力輸出進行拼接concat
import torch
from torch import nn
class MutiHeadAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(MutiHeadAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_heads## 初始化Q、K、V投影矩陣self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, hidden_size)self.v_linear = nn.Linear(hidden_size, hidden_size)## 輸出線性層self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key)value = self.split_head(value)## 計算注意力分數attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9## 對注意力分數進行歸一化attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)## 對注意力輸出進行拼接output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x):batch_size = x.size()[0]return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)
MQA
多查詢注意力(MQA)可能導致質量下降和訓練不穩定,并且訓練針對質量和推理優化的單獨模型可能不可行。此外,雖然一些語言模型已經使用了多查詢注意力,如PaLM但許多語言模型沒有,包括公開可用的語言模型,如T5和LLaM.
- hidden_state經過線性層得到q、k、v
- q、k、v經過split后增加一個維度:num_heads(q = num_heads,k=1,v=1)。相當于多個query,即多查詢。
- q、k計算注意力分數score
- softmax對注意力分數進行歸一化得到注意力權重attention_probs
- 使用注意力權重和值計算輸出:output
- 對注意力輸出進行拼接concat
## 多查詢注意力
import torch
from torch import nn
class MutiQueryAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(MutiQueryAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_heads## 初始化Q、K、V投影矩陣self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, self.head_dim) ###self.v_linear = nn.Linear(hidden_size, self.head_dim) ##### 輸出線性層self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key, 1)value = self.split_head(value, 1)## 計算注意力分數attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9## 對注意力分數進行歸一化attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x, head_num=None):batch_size = x.size()[0]if head_num == None:return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)else:return x.view(batch_size, -1, head_num, self.head_dim).transpose(1,2)GQA
- 使用 5% 的原始預訓練 計算將現有的多頭語言模型檢查點訓 練到具有 MQA 的模型中
- 引入分組查詢注意力 (GQA),這是多 頭語言模型的泛化。查詢注意力,它使用中間,多于一個,少于查詢頭數量的鍵值頭。
- 經過訓練的GQA 實現了接近多頭注意力 的質量,并且速度與 MQA 相當。
- hidden_state經過線性層得到q、k、v
- q、k、v經過split后增加一個維度:num_heads(q = num_heads,k=group_num,v=group_num)。相當于把多頭分組了,比如原先有10個頭,那就是10個query,分成5組,每組2個query,1個value,1個key。
- q、k計算注意力分數score
- softmax對注意力分數進行歸一化得到注意力權重attention_probs
- 使用注意力權重和值計算輸出:output
- 對注意力輸出進行拼接concat
## 分組注意力查詢
import torch
from torch import nn
class MutiGroupAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads, group_num):super(MutiGroupAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_headsself.group_num = group_num## 初始化Q、K、V投影矩陣self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)self.v_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)## 輸出線性層self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key, self.group_num)value = self.split_head(value, self.group_num)## 計算注意力分數attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9## 對注意力分數進行歸一化attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x, group_num=None):batch_size,seq_len = x.size()[:2]if group_num == None:return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)else:x = x.view(batch_size, -1, group_num, self.head_dim).transpose(1,2)x = x[:, :, None, :, :].expand(batch_size, group_num, self.num_heads // group_num, seq_len, self.head_dim).reshape(batch_size, self.num_heads // group_num * group_num, seq_len, self.head_dim)return x


















