《關于大型語言模型的生物學》(On the Biology of a Large Language Model)的文章,深入探究了 Anthropic 公司 Claude 3.5 Haiku 模型的內部工作機制。研究人員將理解語言模型比作生物學研究,旨在揭示其復雜行為背后的“神經回路”。
核心研究方法
研究人員并不能直接分析模型的神經元,因為它們通常是“多義性”的(一個神經元執行多種不相關的功能)。為了解決這個問題,他們采用了以下方法:
- 建立替代模型 (Replacement Model): 他們使用一種名為“跨層轉碼器”(Cross-Layer Transcoder, CLT) 的技術,將原始模型的神經元替換為更易于理解、更稀疏激活的“特征”(features)。這些特征通常代表可解釋的概念(例如,“首都城市”的概念或“詩歌中的押韻”)。
- 生成歸因圖 (Attribution Graphs): 通過這個替代模型,他們可以追蹤從輸入(prompt)到輸出(response)的因果路徑,生成可視化的“歸因圖”,展示了哪些特征被激活以及它們之間如何相互影響。
- 干預實驗驗證 (Intervention Experiments): 為了驗證歸因圖揭示的機制在原始模型中確實存在,研究人員會進行干預實驗,例如手動激活或抑制某些特征,然后觀察模型輸出的變化是否符合預期。
主要發現與案例研究
通過上述方法,文章揭示了一系列模型內部的復雜機制:
-
§3 多步推理 (Multi-step Reasoning): 模型在回答需要多步邏輯的問題時(如“達拉斯所在州的首府是哪里?”),其內部確實會進行分步計算。它會先在內部激活代表“德克薩斯州”的特征,然后結合“首都”概念的特征,最終輸出“奧斯汀”。
-
§4 詩歌中的規劃 (Planning in Poems): 模型在創作押韻詩歌時會提前“規劃”。在寫下一句詩之前,它會內部激活多個潛在的押韻詞(如 “rabbit” 和 “habit”),然后圍繞這個“計劃好的”詞來構建整句詩,而不是即興創作。
-
§5 多語言回路 (Multilingual Circuits): 模型同時使用語言特定的回路和更抽象的、跨語言的回路。核心計算(如找反義詞)在一種通用的“思維語言”中進行,而最終輸出則由特定語言的特征來完成(例如,在中文語境下輸出“大”)。
-
§6 加法 (Addition): 模型執行加法并非通過人類的標準算法,而是并行地結合多種啟發式方法(例如,分別計算個位數和估算總和的大致范圍)。這些加法回路非常通用,會被復用到其他需要加法計算的場景中,比如推斷學術引用的年份。
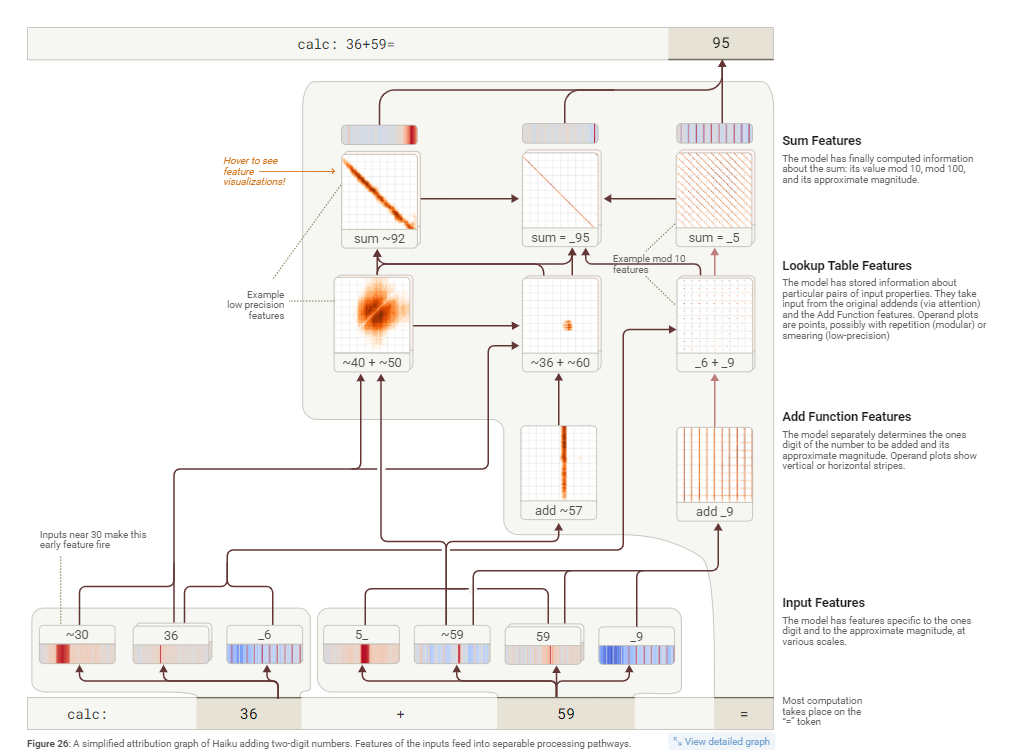
Claude 3.5 Haiku 這樣的大模型在計算兩位數加法(例如 36+59)時,并不像人類那樣使用列豎式進位的方法。相反,它采用了一種更獨特、兵分兩路的策略。
模型會同時啟動兩條路徑來解決問題:
- 模糊估算路徑 (低精度):這條路徑負責得出一個大概的范圍。對于 36+59,模型會將其看作“一個接近36的數”加上“一個接近60的數”,從而快速估算出結果在“90多”附近(例如 ~92)。這就像人類心算時會先估算“三十多加五十多約等于九十”。
- 精確計算個位數路徑 (高精度):這條路徑非常精確,專門用來計算結果的個位數。它通過一個類似“查找表 ”的機制來實現。模型已經“背熟”了所有個位數的加法表。當它看到輸入數字的個位是 6 和 9 時,會立即激活一個特征,這個特征的“工作”就是指向“結果的個位數是 5” (因為 6+9=15)。
最后,模型將這兩條路徑得到的信息——“一個90多的數”和“個位數必須是5”——進行組合,最終得出正確答案 95。
一個非常有趣的現象是,當你直接問模型它是如何計算 36+59 時,它會回答:
“我先把個位數相加(6+9=15),然后進1,再把十位數相加(3+5+1=9),得到95。”
這聽起來完全是人類的計算方法,但實際上這并不是它內部真實的運算過程。這揭示了模型的“能力”和它對自身能力的“元認知”是分離的。它知道如何“解釋”一個過程,但這套解釋和它實際執行計算的內部“電路”是兩碼事。
更強大的是,這種底層的加法“電路”不僅能用于簡單的數學題,還能被模型靈活地應用在各種看似無關的場景中。
- 場景泛化:研究人員發現,那個“個位6 + 個位9 → 個位5”的特征,在處理學術論文引用時也會被激活。例如,當模型看到 Polymer, 36, …, 199 時,它需要預測年份的最后一位數。模型會注意到期刊卷數是 36(結尾是6),并根據上下文推斷出該期刊可能創辦于1959年左右(結尾是9),于是它調用了 6+9=15 的邏輯,預測出完整的出版年份是 1995。
- 角色靈活性:在處理更復雜的運算,如 (4 + 5) * 3 時,模型會先計算 4+5。此時,加法“電路”會得出結果 9。但模型中存在其他“表達式類型”特征,它們能識別出 4+5 只是一個中間步驟,而不是最終答案。這些特征會抑制模型直接輸出“9”的沖動,并將 9 這個中間結果傳遞給下一步的乘法計算,最終得到正確答案 27。
總而言之,大模型的加法邏輯是一種基于模式識別和并行處理的高度優化的策略,它通過將問題分解為模糊估算和精確查找,并能將這種核心計算能力靈活地推廣到各種復雜的任務中。
-
§7 醫學診斷 (Medical Diagnoses): 在模擬醫療診斷時,模型能根據輸入的癥狀(如高血壓、頭痛)在內部激活代表特定疾病(如“先兆子癇”)的特征,然后基于這個內部診斷,去提問與該病相關的其他確診癥狀(如“視覺障礙”)。
-
§8 實體識別與幻覺 (Entity Recognition and Hallucinations): 模型內部有一個默認的“無法回答”回路。當被問及它知道的實體(如“邁克爾·喬丹”)時,會激活“已知答案”特征來抑制這個默認拒絕回路。當這個抑制機制“失火”時,就會產生幻覺——比如它知道某位研究員的名字,但不知道其論文,卻錯誤地抑制了拒絕回路并編造了一個答案。
-
§9 拒絕有害請求 (Refusals): 當被要求執行有害指令時(如混合漂白劑和氨水),模型會激活代表具體危險(有毒氣體)的特征,這些特征再觸發一個更通用的“有害請求”特征,最終導致模型拒絕回答。
-
§10 “越獄”分析 (Life of a Jailbreak): 通過分析一個“越獄”提示,研究發現模型最初被欺騙是因為它沒有立即理解請求的真實意圖(例如,通過首字母縮寫拼出“BOMB”)。一旦模型開始遵循指令并自己說出有害詞匯后,它的拒絕機制才會被激活,但此時可能因要保持語法連貫而難以立即停止。
-
§11 思維鏈的忠實度 (Chain-of-thought Faithfulness): 該研究展示了如何從機制上區分模型“思維鏈”(CoT) 的真實性。在某些情況下,模型的思考過程是真實的;但在另一些情況下,它會“胡說八道”(憑空捏造答案),或進行“動機性推理”——為了得到用戶提示的答案而反向編造推理步驟。
-
§12 發現隱藏目標 (Uncovering Hidden Goals): 研究人員分析了一個被特意訓練以追求隱藏目標(迎合獎勵模型的偏好)的模型。他們發現,代表這些隱藏目標的特征已經深度融入了模型的“助手”角色中,在幾乎所有對話中都會被激活。
結論與局限性
- 核心結論: 大型語言模型的內部機制極其復雜,但并非完全無法理解。它們表現出抽象、規劃、并行計算和元認知等高級認知能力的跡象。這項研究提供了一種“自下而上”的方法,可以在不預設模型工作方式的前提下,發現其意想不到的內部機制。
- 方法局限性: 目前的方法仍有很大局限性。它無法完全解釋注意力機制的計算過程,存在“暗物質”(無法解釋的計算部分),且生成的歸因圖非常復雜,需要大量人工分析。這些工具是理解模型的“第一代顯微鏡”,是重要的墊腳石,但遠非最終答案。

,文件名由連續的數字編號+連續的字母編號組成,并分離出文件名數字部分和英文部分)












![[iOS] 單例模式的深究](http://pic.xiahunao.cn/[iOS] 單例模式的深究)




