垃圾收集器是 JVM 內存管理的執行引擎,負責自動回收無用的對象內存。其設計核心是?權衡:主要是吞吐量和停頓時間之間的權衡。沒有“最好”的收集器,只有“最適合”特定場景的收集器。
一、核心基礎:分代收集模型
主流 HotSpot JVM 采用分代模型,將堆內存劃分為不同區域,基于對象存活周期的“弱分代假說”采用不同的收集策略:
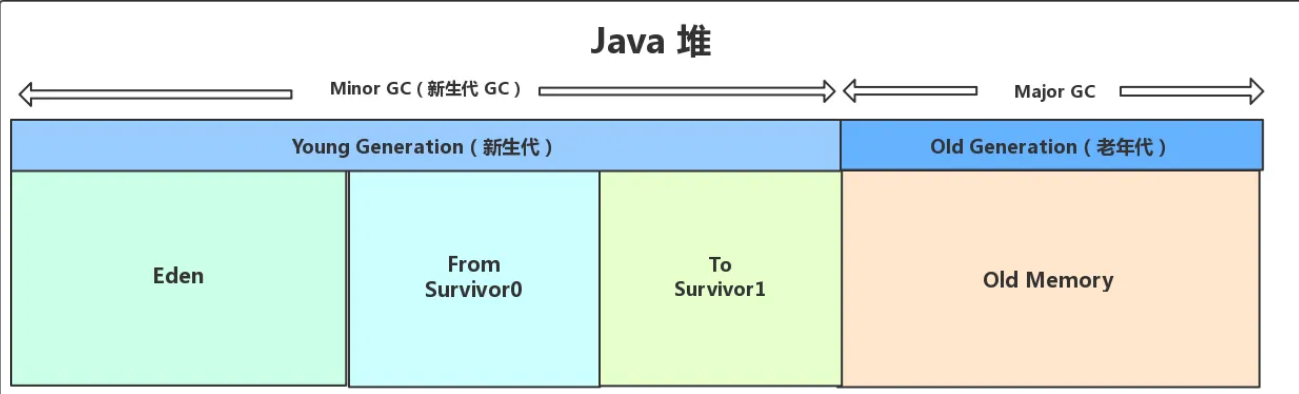
新生代:
存放新創建的對象。特點是區域小、對象存活率低、回收頻繁。
Eden區:對象誕生的地方。
Survivor幸存者區 :存放 Minor GC 后存活的對象。
老年代 :
存放經過多次 Young GC 后依然存活的對象。特點是區域大、對象存活率高。
元空間 :存放類元數據等,由本地內存提供,不屬堆內存。
垃圾收集類型:
Minor GC / Young GC:只收集年輕代的垃圾。
Major GC / Old GC:只收集老年代的垃圾。
Full GC:收集整個堆(新生代 + 老年代 + 方法區)的垃圾。
二、垃圾收集算法
分代收集理論:
目前主流JVM虛擬機中的垃圾收集器,都遵循分代收集理論:
弱分代:絕大多數對象都是朝生夕滅
強分代:經歷越多次垃圾收集過程的對象,越難以回收,難以消亡
按照分代收集理論設計的“分代垃圾收集器”,所采用的設計原則:收集器應該將Java堆劃分成不同的區域,然后將回收對象依據其年齡(年齡即對象經歷過垃圾收集過程的次數)分配到不同的區域存儲。
分代存儲:
- 如果一個區域中大多數對象都是朝生夕滅(新生代),難以熬過垃圾收集過程的話,把它們集中存儲在一起,每次回收時,只關注如何保留少量存活對象,而不是去標記大量將要回收的對象,就能以較低代價回收到大量的空間。
- 如果一個區域中大多數對象都是難以回收(老年代),那么把它們集中放在一起,JVM虛擬機就可以使用較低的頻率,來對這個區域進行回收。
這樣設計的好處是,兼顧垃圾收集的時間開銷和內存空間的有效利用。
分代收集:
堆區按照分代存儲的好處:
- 在Java堆區劃分成不同區域后,垃圾收集器才可以每次只回收其中某一個或者某些區域,所以才有MinorGC、MajorGC、FullGC等垃圾收集類型劃分。
- 在Java堆區劃分成不同區域后,垃圾收集器才可以針對不同的區域,安排與該區域存儲對象存亡特征相匹配的垃圾收集算法:標記-復制算法、標記-清除算法、標記-整理算法等。
垃圾收集算法:
垃圾收集算法主要解決三個問題:
如何判斷對象已死?(標記階段)
如何回收垃圾對象占用的內存?(清除階段)
如何避免內存碎片?(整理階段)
圍繞這些問題,衍生出了以下幾種基礎算法。
1. 基礎:如何判斷對象“已死”?
垃圾收集的前提是判斷對象是否存活。主要有兩種算法:
(1). 引用計數算法
機制:在對象中添加一個引用計數器。每當有一個地方引用它時,計數器值就加一;當引用失效時,計數器值就減一。任何時刻計數器為零的對象就是不可能再被使用的。
優點:原理簡單,判定效率高。
缺點:無法解決對象之間循環引用的問題(對象A引用B,對象B引用A,但再無第三方引用它們倆)。因此,主流Java虛擬機均不采用此算法。
(2). 可達性分析算法
機制:通過一系列稱為?“GC Roots”?的根對象作為起始節點集,從這些節點開始,根據引用關系向下搜索,搜索過程所走過的路徑稱為?“引用鏈”。如果某個對象到GC Roots間沒有任何引用鏈相連(即從GC Roots到這個對象不可達),則證明此對象是不可能再被使用的。
Java中可作為GC Roots的對象包括:
虛擬機棧(棧幀中的本地變量表)中引用的對象。
方法區中類靜態屬性引用的對象。
方法區中常量引用的對象。
本地方法棧中JNI(即通常說的Native方法)引用的對象。
Java虛擬機內部的引用(如基本數據類型對應的Class對象,常駐的異常對象等)。
所有被同步鎖(synchronized關鍵字)持有的對象。
這是目前主流Java虛擬機采用的判斷對象是否存活的算法。
2. 核心:垃圾收集算法
確定了哪些對象是垃圾之后,就需要進行回收。主要有三種基礎算法:
1. 標記-清除算法
過程:算法分為“標記”和“清除”兩個階段。
標記:首先通過可達性分析,標記出所有需要回收的對象。
清除:隨后,統一回收掉所有被標記的對象。
優點:是最基礎的收集算法,后續算法都是在其基礎上改進的。
缺點:
執行效率不穩定:如果堆中包含大量需要回收的對象,則標記和清除兩個過程的執行效率都會隨之降低。
內存碎片化:標記、清除之后會產生大量不連續的內存碎片。碎片太多可能導致以后在分配大對象時無法找到足夠的連續內存,從而不得不提前觸發另一次垃圾收集。
2. 復制算法
過程:它將可用內存按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊的內存用完了,就將還存活著的對象復制到另外一塊上面,然后再把已使用過的內存空間一次清理掉。
優點:
高效:只需要按順序分配內存,移動堆頂指針即可,分配新對象的速度極快。
無碎片:復制過程中會將存活對象緊湊地排列在另一塊內存,完全避免了碎片問題。
缺點:內存利用率低,可用內存縮小為了原來的一半。
應用:是HotSpot虛擬機中年輕代垃圾收集的核心算法。但商業虛擬機都對其進行了優化:并不按1:1的比例劃分內存,而是將內存分為一塊較大的Eden空間和兩塊較小的Survivor空間(通常是8:1:1)。每次分配只使用Eden和其中一塊Survivor。發生Minor GC時,將Eden和Survivor中仍然存活的對象一次性復制到另一塊Survivor空間上,然后直接清理掉Eden和已用過的那塊Survivor空間。這樣只有10%的內存會被“浪費”。
3. 標記-整理算法
過程:也分為“標記”和“整理”兩個階段。
標記:與“標記-清除”算法一樣,首先標記所有需要回收的對象。
整理:讓所有存活的對象都向內存空間的一端移動,然后直接清理掉邊界以外的內存。
優點:
無內存碎片:整理后內存是緊湊的。
內存利用率高:無需浪費一半的內存空間。
缺點:“整理”階段涉及大量對象的移動,并且需要更新所有引用這些對象的指針,是一種開銷較大的操作,而且移動對象時必須全程暫停用戶應用程序(Stop The World)。
應用:主要用于老年代的垃圾收集,如Serial Old和Parallel Old收集器。
4. 分代收集算法
本質:這并非一種新的算法思想,而是上述三種算法的實際應用范式。
思路:根據對象存活周期的不同,將Java堆劃分為年輕代和老年代。
在年輕代:對象“朝生夕死”,存活率低,回收頻繁。因此選用復制算法,只需要付出少量存活對象的復制成本就可以完成收集,且速度最快。
在老年代:對象存活率高,沒有額外的空間對它進行分配擔保。因此必須使用?“標記-清除”或“標記-整理”?算法來進行回收。
3. 垃圾收集算法總結:
| 算法 | 過程 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| 標記-清除 | 標記 → 清除 | 實現簡單 | 效率低、產生碎片 | 老年代 (CMS) |
| 復制 | 標記 → 復制到另一半 → 清空原空間 | 效率高、無碎片 | 浪費一半空間 | 年輕代 (幾乎所有收集器) |
| 標記-整理 | 標記 → 整理存活對象到一端 → 清理邊界 | 無碎片、空間利用率高 | 移動對象成本高 | 老年代 (Serial Old, Parallel Old) |
| 分代收集 | 根據代的特點選用上述算法 | 綜合優勢,揚長避短 | 實現復雜 | 現代JVM的實際實踐 |
三、經典垃圾收集器詳解
垃圾收集器是內存回收算法的具體實現。不同收集器適用于不同場景,核心目標是在?吞吐量?和?停頓時間?之間取得最佳平衡。
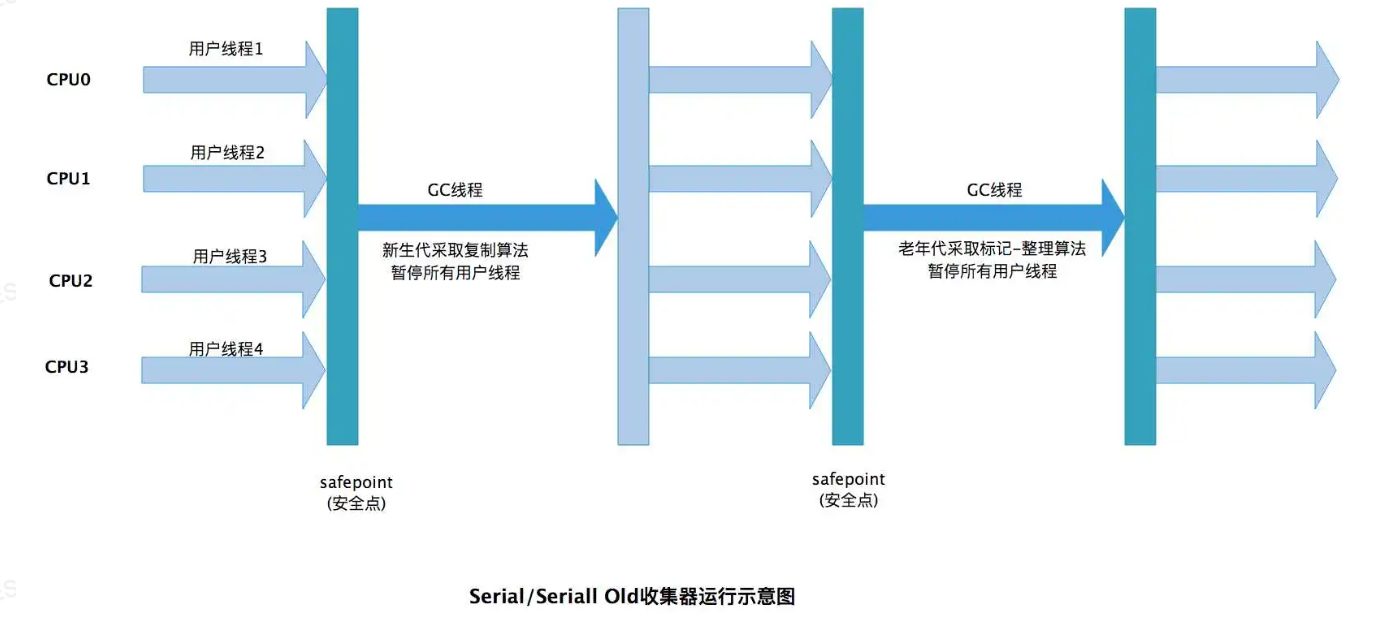
1. Serial 收集器(新生代)
特點:單線程工作的收集器。在進行垃圾收集時,必須暫停所有用戶工作線程("Stop The World"),直到收集結束。
算法:復制算法。
定位:是?Client 模式下的默認新生代收集器。簡單而高效,沒有線程交互開銷。適用于內存資源受限的客戶端應用或單核服務器環境。
2. Serial Old 收集器(老年代)
特點:Serial 收集器的老年代版本,同樣是一個單線程收集器。
算法:標記-整理算法。
定位:主要用于?Client 模式。在 Server 模式下,它主要作為?CMS 收集器失敗時的后備預案(Concurrent Mode Failure)。
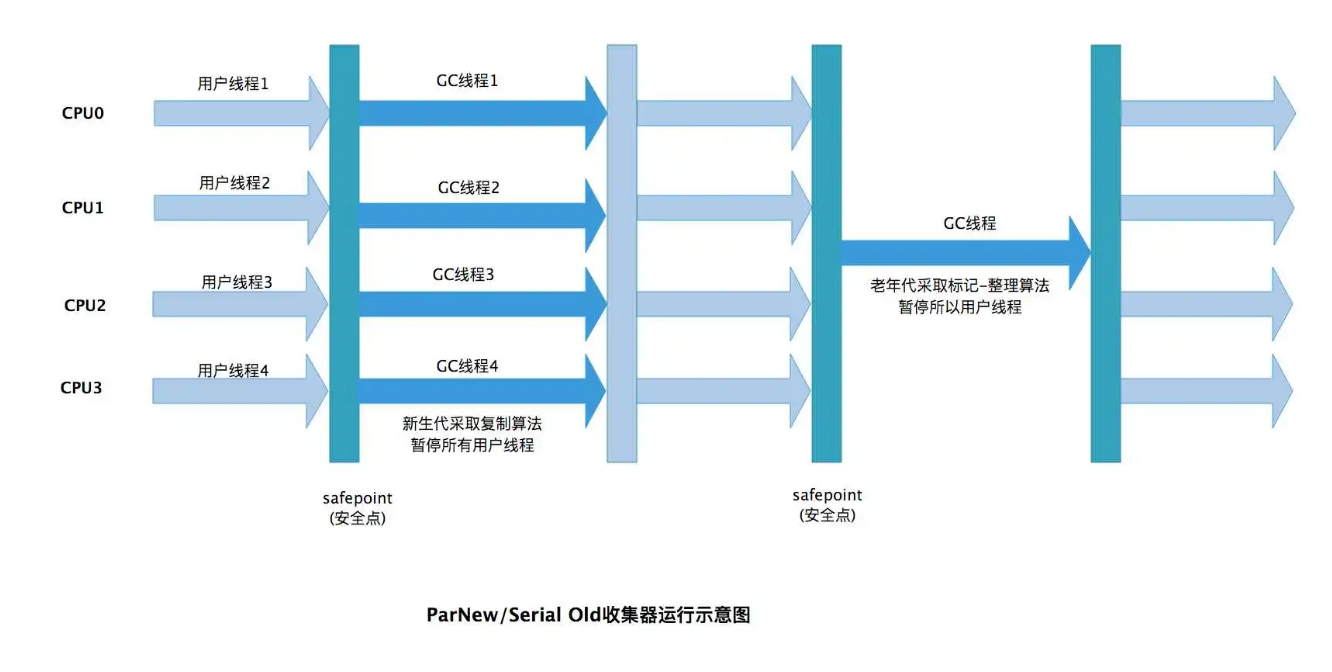
3. ParNew 收集器(新生代)
特點:本質上是?Serial 收集器的多線程并行版本。它使用多條線程進行垃圾收集,但在收集時同樣需要“Stop The World”。
算法:復制算法。
定位:在 JDK 7 之前,它是許多服務端應用的首選新生代收集器,因為它是?唯一能與 CMS 收集器配合工作?的新生代收集器。
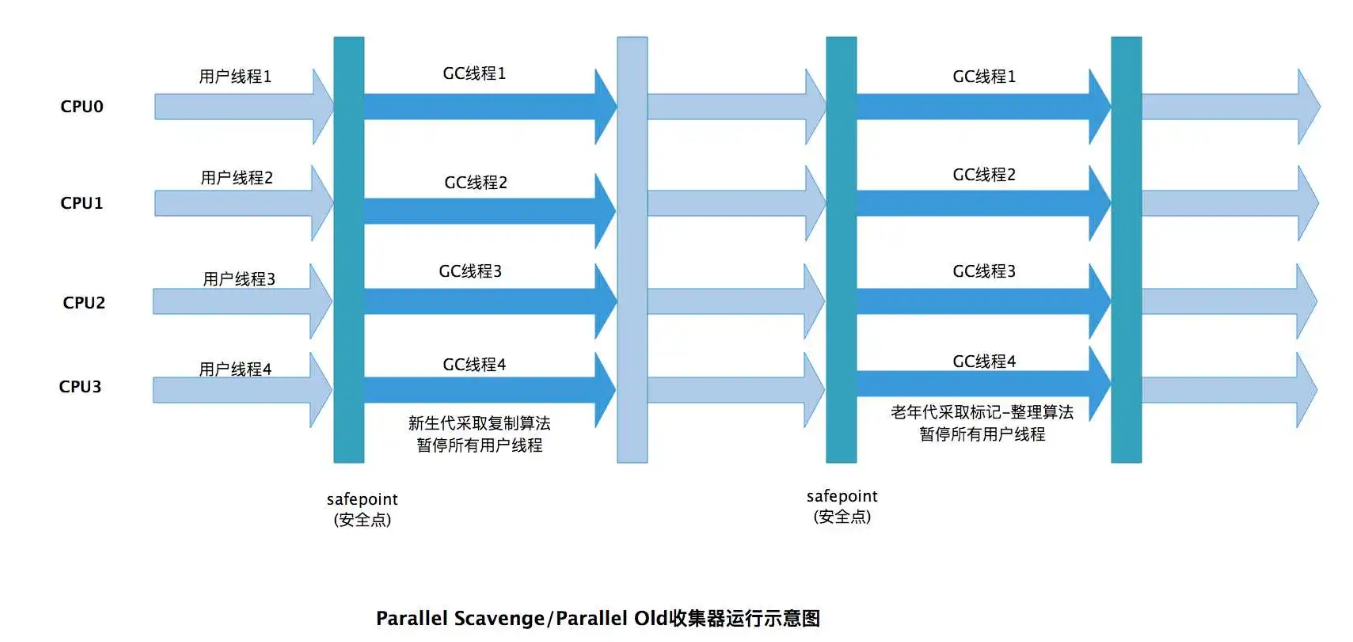
4. Parallel Scavenge 收集器(新生代)
特點:也稱為“吞吐量優先”收集器。它使用并行多線程進行收集,但其關注點是達到一個?可控制的吞吐量(吞吐量 = 運行用戶代碼時間 / (運行用戶代碼時間 + 垃圾收集時間))。
算法:復制算法。
定位:適合后臺運算、科學計算等?不需要低延遲,但需要高吞吐量?的任務。是?JDK 8 默認的新生代收集器。
5. Parallel Old 收集器(老年代)
特點:Parallel Scavenge 收集器的老年代版本,使用多線程進行收集。
算法:標記-整理算法。
定位:在 JDK 6 之后才開始提供。它的出現使得?Parallel Scavenge + Parallel Old?成為一套真正專注于?高吞吐量?的完整組合。
6. CMS 收集器(老年代)
目標:以?獲取最短回收停頓時間?為目標,注重用戶體驗。
過程:其核心過程有四步驟:
初始標記?(Stop The World):速度極快。
并發標記?(與用戶線程并發):耗時最長但無需停頓。
重新標記?(Stop The World):修正并發標記期間的變化。
并發清除?(與用戶線程并發)。
算法:標記-清除算法(會產生碎片)。
缺點:對CPU資源敏感、無法處理“浮動垃圾”、會產生內存碎片。
定位:適用于互聯網站、B/S系統的服務端,重視服務的響應速度。現已不推薦使用,被 G1 等收集器取代。
7. G1 收集器(老年代)
革新:放棄了傳統物理連續的分代模型,將堆劃分為多個大小相等的獨立區域(Region)。雖然保留分代概念,但年輕代和老年代是這些 Region 的動態集合。
目標:可預測的停頓時間模型。允許用戶指定期望的停頓時間。
工作機制:跟蹤各個 Region 的回收價值(空間大小及回收成本),優先回收價值最大的 Region。
算法:整體上看是標記-整理算法,局部(兩個Region之間)基于復制算法。
在不同的應用場景下,選擇合適的垃圾收集器至關重要。對于追求高吞吐量的后臺計算任務,Parallel Scavenge與Parallel Old的組合是最佳選擇;若需要低延遲的響應式服務,CMS或新一代的G1收集器更為合適;而對于內存敏感的單核環境,Serial收集器仍是最實用的選項。隨著技術發展,G1收集器憑借其平衡的吞吐量和延遲表現,已成為大多數現代應用的默認推薦。在選擇時,還需考慮JDK版本和具體的性能需求,才能做出最合適的決策。

—— 結合Tensorboard進行結果分析)
)



 的必會知識點匯總)
?? 詳解)

)







)
)
