一、項目背景
- 這個項目是為了學習和實現一個高性能、特別是高并發場景下的內存分配器。這個項目是基于谷歌開源項目tcmalloc(Thread-Caching Malloc)實現的。tcmalloc 的核心目標就是替代系統默認的
malloc/free,在多線程環境下提供更高效的內存管理。 - C/C++的malloc雖然通用,但在高并發環境下,頻繁申請和釋放內存會引起劇烈鎖競爭,進而造成性能瓶頸。
- 理解tcmalloc這個項目,不僅是深入 C++ 高性能編程、提升技術深度的絕佳途徑,也是鞏固C++學習的重要方式。
二、項目功能
項目介紹
采取三層結構:thread_cache-central_cache-page_cache。當一個線程需要申請內存時,先向thread cache進行申請,thread cache沒有內存,轉而向central cache進行申請,central cache沒有內存,轉而向page cache進行申請,page cache沒有內存,會直接在堆上進行開辟。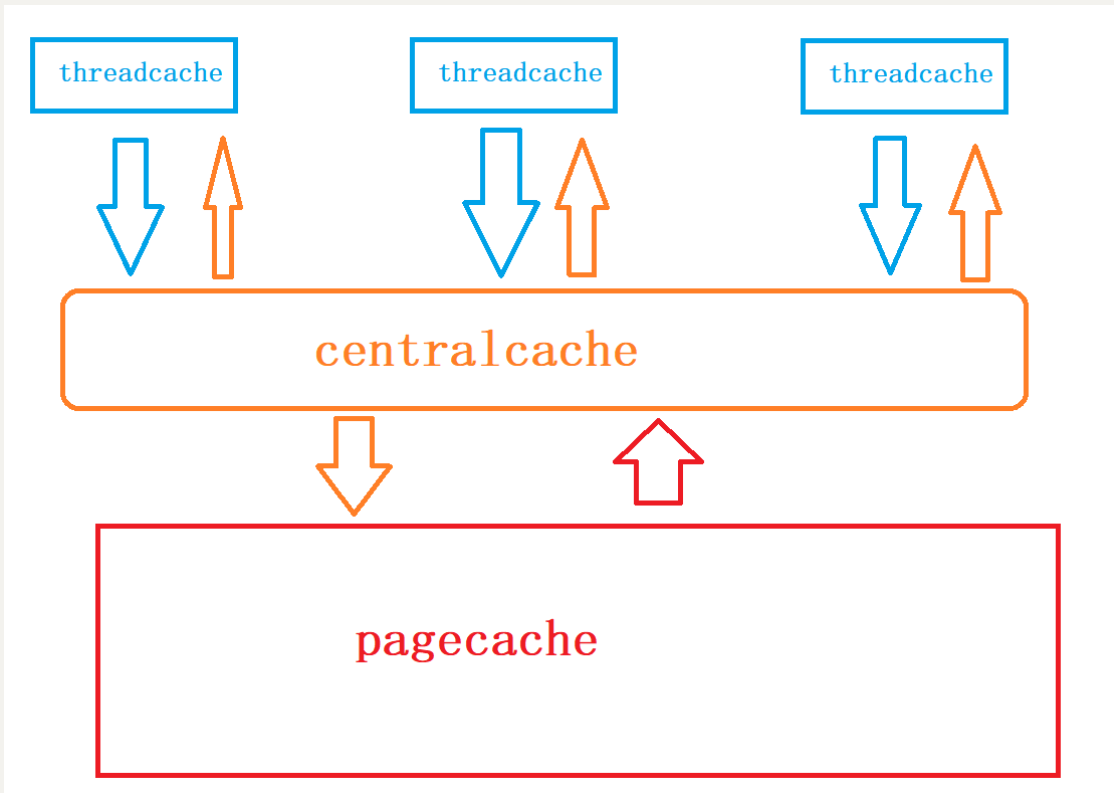
? 在進行歸還內存時,不會直接釋放掉,直接釋放掉下次申請還要再進行上面的流程。對thread cache增加自由鏈表的結構,每次用完釋放后,直接將其鏈入thread cache的自由鏈表中,待自由鏈表長度過長或占用內存過大,我們在統一進行回收合并,這樣也能解決外碎片問題。
? 這三層結構主要解決小于和等于256KB大小的內存申請和釋放問題,對于申請和釋放大于256KB的內存塊,直接向page cache進行申請和釋放。
? **thread cache:**對于小塊內存進行管理,這個是每個線程獨有的,這里不存在線程安全問題,不用進行加鎖,每個線程獨享一個cache。
? **central cache:**中心緩存,所有線程共享的,thread cache按需從里面申請內存,會在合適時候對thread cache進行回收,以達到內存調度。central cache這里會存在內存競爭的問題,所以需要加鎖。
? **page cache:**是以頁為單位進行存儲和分配的,central cache向其申請對象時,page cache會給出若干頁,進行切割定長內存小塊分配給central cache。當若干頁進行回收后,會進行合并,解決了內存碎片問題(外碎片)。
項目目標
- 高性能: 絕大多數小內存分配在 Thread Cache 無鎖完成,大幅提升并發性能。
- 低鎖競爭: 通過線程私有緩存和批量操作,將全局鎖競爭降到最低(主要在 Central Cache 的桶鎖)。
- 碎片控制: Page Cache 的合并機制有效緩解了外部碎片問題。
三、測試計劃
單元測試
**一般測試:**測試是否能正常工作
void Test_ConcurrentAlloc1()
{int* p1 = (int*)ConcurrentAlloc(6); //maxsize:2 allocnum:1 size:0int* p2 = (int*)ConcurrentAlloc(7); //3 2 1int* p3 = (int*)ConcurrentAlloc(8); //3 0int* p4 = (int*)ConcurrentAlloc(1); //4 3 2int* p5 = (int*)ConcurrentAlloc(1); //4 1int* p6 = (int*)ConcurrentAlloc(1); //4 0int* p7 = (int*)ConcurrentAlloc(1); //5 4 3*p1 = 10;*p2 = 20;*p3 = 30;*p4 = 40;cout << p1 << ": " << *p1 << endl;cout << p2 << ": " << *p2 << endl;cout << p3 << ": " << *p3 << endl;cout << p4 << ": " << *p4 << endl;ConcurrentFree(p1); //maxsize:5 size:4 span._usecount:10ConcurrentFree(p2); //5 0 5ConcurrentFree(p3); //5 1 5ConcurrentFree(p4); //5 2 5ConcurrentFree(p5); //5 3 5ConcurrentFree(p6); //5 4 5ConcurrentFree(p7); //5 0 0
}
運行結果:

特殊測試:是否可以分配大塊內存
void Test_BigAlloc()
{int *p1 = (int *)ConcurrentAlloc(MAX_BYTES + 100);int *p2 = (int *)ConcurrentAlloc(NPAGES << PAGE_SHIFT);*p1 = 10;*p2 = 20;cout << p1 << ": " << *p1 << endl;cout << p2 << ": " << *p2 << endl;ConcurrentFree(p1);ConcurrentFree(p2);
}
測試結果:

基準測試
// ntimes 一輪申請和釋放內存的次數
// rounds 輪次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(malloc(16));v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u個線程并發執行%u輪次,每輪次malloc %u次: 花費:%u ms\n",nworks, rounds, ntimes, (unsigned int)malloc_costtime);printf("%u個線程并發執行%u輪次,每輪次free %u次: 花費:%u ms\n",nworks, rounds, ntimes, (unsigned int)free_costtime);printf("%u個線程并發malloc&free %u次,總計花費:%u ms\n",nworks, nworks * rounds * ntimes, (unsigned int)malloc_costtime + free_costtime);
}// 單輪次申請釋放次數 線程數 輪次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(ConcurrentAlloc(16));v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u個線程并發執行%u輪次,每輪次concurrent alloc %u次: 花費:%u ms\n",nworks, rounds, ntimes, (unsigned int)malloc_costtime);printf("%u個線程并發執行%u輪次,每輪次concurrent dealloc %u次: 花費:%u ms\n",nworks, rounds, ntimes, (unsigned int)free_costtime);printf("%u個線程并發concurrent alloc&dealloc %u次,總計花費:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}int main()
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 10, 10);cout << endl << endl;BenchmarkMalloc(n, 10, 10);cout << "==========================================================" << endl;return 0;
}
測試結果:
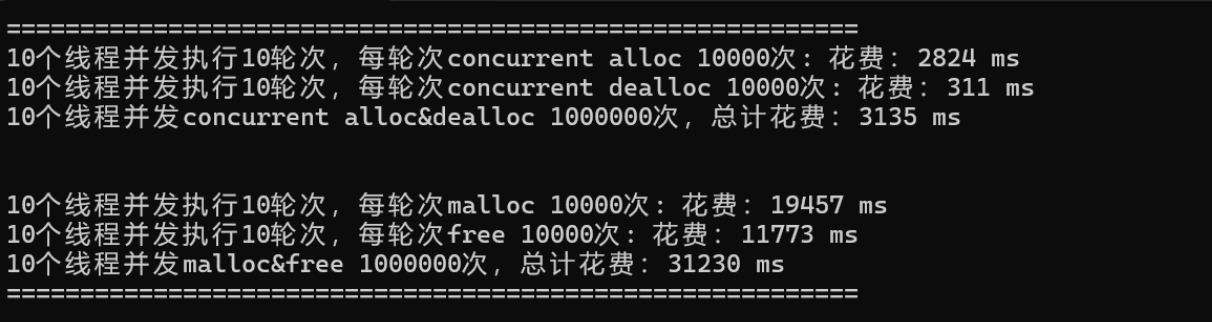
性能測試
多線程環境下的內存分配/釋放壓力測試:
void MultiThreadAlloc1()
{std::vector<void*> v;for (size_t i = 0; i < 7; ++i){void* ptr = ConcurrentAlloc(6);v.push_back(ptr);}for (auto e : v){ConcurrentFree(e);}
}
測試結果:
- ThreadCache 的批量分配和釋放機制
- 對象在ThreadCache和CentralCache間的流動
- 內存池的資源保留策略
- 整個生命周期沒有內存泄漏
內存碎片化測試:
void TestFragmentation() {const int BLOCK_COUNT = 500;std::vector<void*> mediumBlocks;std::vector<void*> smallBlocks;// 分配中型內存塊 (32KB)for (int i = 0; i < BLOCK_COUNT; ++i) {mediumBlocks.push_back(ConcurrentAlloc(32 * 1024));}// 釋放75%的中型塊(制造碎片)for (int i = 0; i < BLOCK_COUNT * 3/4; ++i) {ConcurrentFree(mediumBlocks[i]);}// 分配大量小內存塊 (128B)for (int i = 0; i < BLOCK_COUNT * 10; ++i) {smallBlocks.push_back(ConcurrentAlloc(128));}// 嘗試分配大內存塊void* bigBlock = ConcurrentAlloc(128 * 1024);assert(bigBlock != nullptr && "Fragmentation may be too high!");// 清理ConcurrentFree(bigBlock);for (auto p : smallBlocks) ConcurrentFree(p);for (int i = BLOCK_COUNT * 3/4; i < BLOCK_COUNT; ++i) {ConcurrentFree(mediumBlocks[i]);}std::cout << "Fragmentation Test: Passed\n";
}
測試結果:
- 在高度碎片化的環境中仍能分配大內存塊
- 自動合并相鄰空閑Span的能力
- 正確處理不同大小內存塊的混合分配
- 資源完全回收無泄漏





)




之生命周期管理詳解)








