一、Kafka 基礎與系統要求
1.1 核心概念
- Broker:Kafka 服務器節點,負責存儲消息和處理客戶端請求
- Topic:消息分類的邏輯容器,每條消息需指定發送到某個 Topic
- Partition:Topic 的物理分片,可分布式存儲在不同 Broker 上,實現水平擴展
- Producer:消息生產者,向 Kafka Topic 發送消息
- Consumer:消息消費者,從 Kafka Topic 訂閱并消費消息
- Consumer Group:多個 Consumer 組成的分組,同組內 Consumer 共同消費 Topic 消息(避免重復消費)
- ZooKeeper:Kafka 早期版本(2.8 前)依賴的分布式協調工具,用于管理集群元數據、選舉 Broker 控制器等(2.8+ 版本支持無 ZooKeeper 模式)
1.2 系統要求
- 基礎環境:Java 8 或 Java 11(推薦,Kafka 依賴 JVM 運行)
- 硬件配置:
-
- 單節點:至少 2GB 內存、20GB 磁盤空間(測試環境)
-
- 集群節點:建議 4GB+ 內存、100GB+ 磁盤(生產環境,優先 SSD 提升性能)
- 支持系統:Linux(Ubuntu/CentOS,推薦生產環境)、Windows(僅建議測試環境)、macOS
- 網絡要求:集群節點間網絡互通,開放默認端口(Broker 9092、ZooKeeper 2181)
二、Kafka 安裝(單節點,測試環境)
2.1 依賴環境準備(ZooKeeper 安裝)
Kafka 2.8 版本前需單獨部署 ZooKeeper,以下以 Kafka 2.13-3.5.1 版本(依賴 ZooKeeper) 為例:
2.1.1 Linux 系統(Ubuntu/CentOS 通用)
安裝流程圖解:
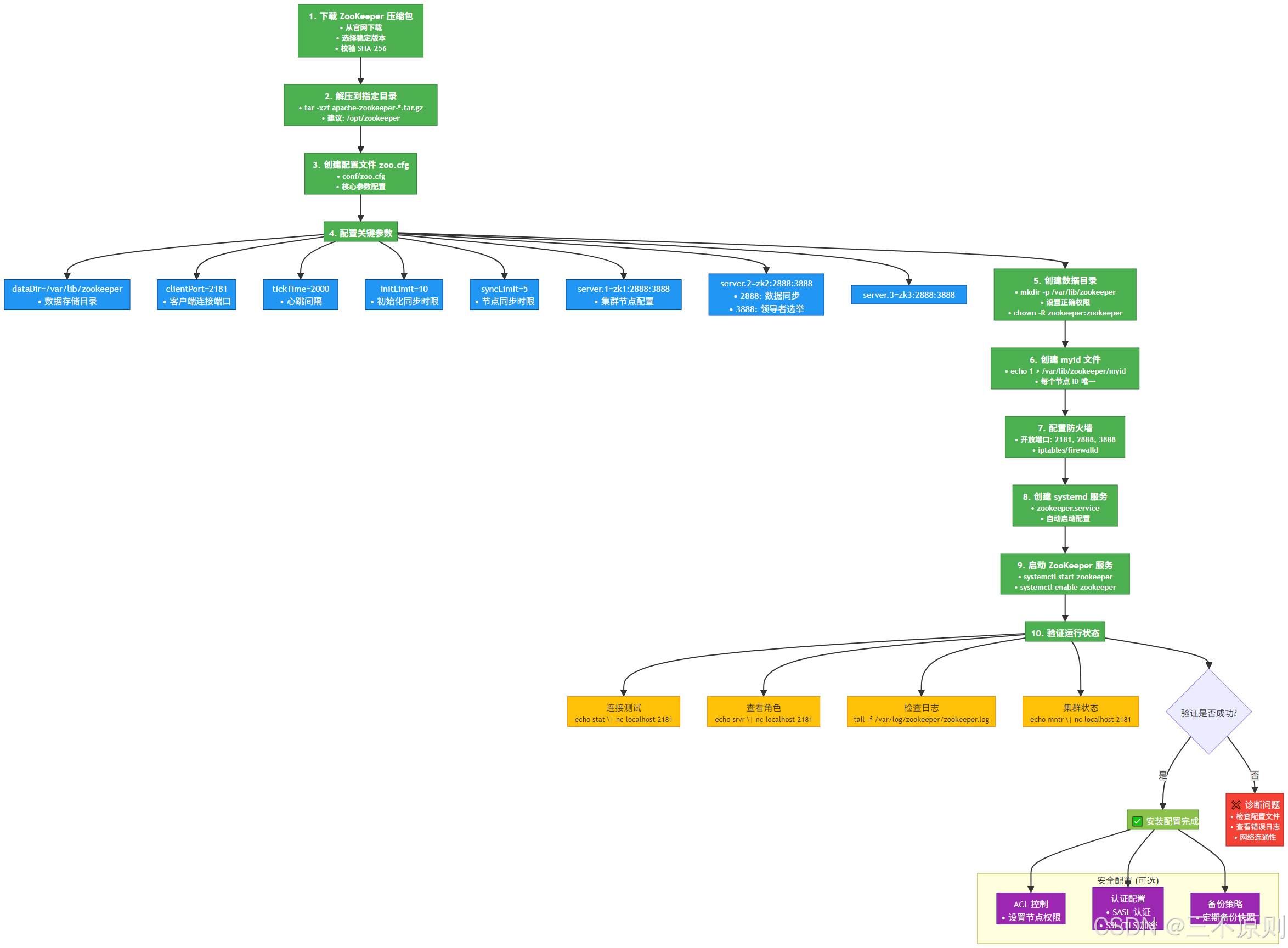
執行步驟:
? ? ? ? 1. 下載 ZooKeeper(推薦 3.8.x 版本):
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz? ? ? ? 2. 解壓到 /opt 目錄:
tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz -C /opt/
ln -s /opt/apache-zookeeper-3.8.4-bin /opt/zookeeper # 創建軟鏈接,方便后續操作? ? ? ? 3. 修改配置文件:
cd /opt/zookeeper/conf
cp zoo_sample.cfg zoo.cfg # 復制默認配置為正式配置
# 編輯配置,指定數據存儲目錄
sed -i 's/dataDir=\/tmp\/zookeeper/dataDir=\/opt/zookeeper/data/' zoo.cfg? ? ? ? 4. 創建數據目錄并啟動服務:
mkdir -p /opt/zookeeper/data
/opt/zookeeper/bin/zkServer.sh start # 啟動服務? ? ? ? 5. 驗證狀態(出現 Mode: standalone 即為單節點運行成功):
/opt/zookeeper/bin/zkServer.sh status2.1.2 Windows 系統
安裝流程圖解:
執行步驟:
? ? ? ? 1. 下載 ZooKeeper 壓縮包(同 Linux 步驟 1),解壓到 D:\zookeeper
? ? ? ? 2. 進入 D:\zookeeper\conf,復制 zoo_sample.cfg 并重命名為 zoo.cfg,修改數據目錄:
dataDir=D:\zookeeper\data # 手動創建 data 文件夾? ? ? ? 3. 配置環境變量:
-
- 系統變量新增 ZOOKEEPER_HOME,值為 D:\zookeeper
-
- 在 Path 變量中添加 %ZOOKEEPER_HOME%\bin
? ? ? ? 4. 啟動服務(以管理員身份打開 cmd):
zkServer.cmd # 啟動服務,保持窗口運行(關閉窗口則服務停止)? ? ? ? 5. 驗證服務:新打開 cmd 窗口,執行 zkCli.cmd,若能進入 [zk: localhost:2181(CONNECTED)] 則成功。
2.2 Kafka 安裝(Linux 系統為例)
2.2.1 安裝流程圖解
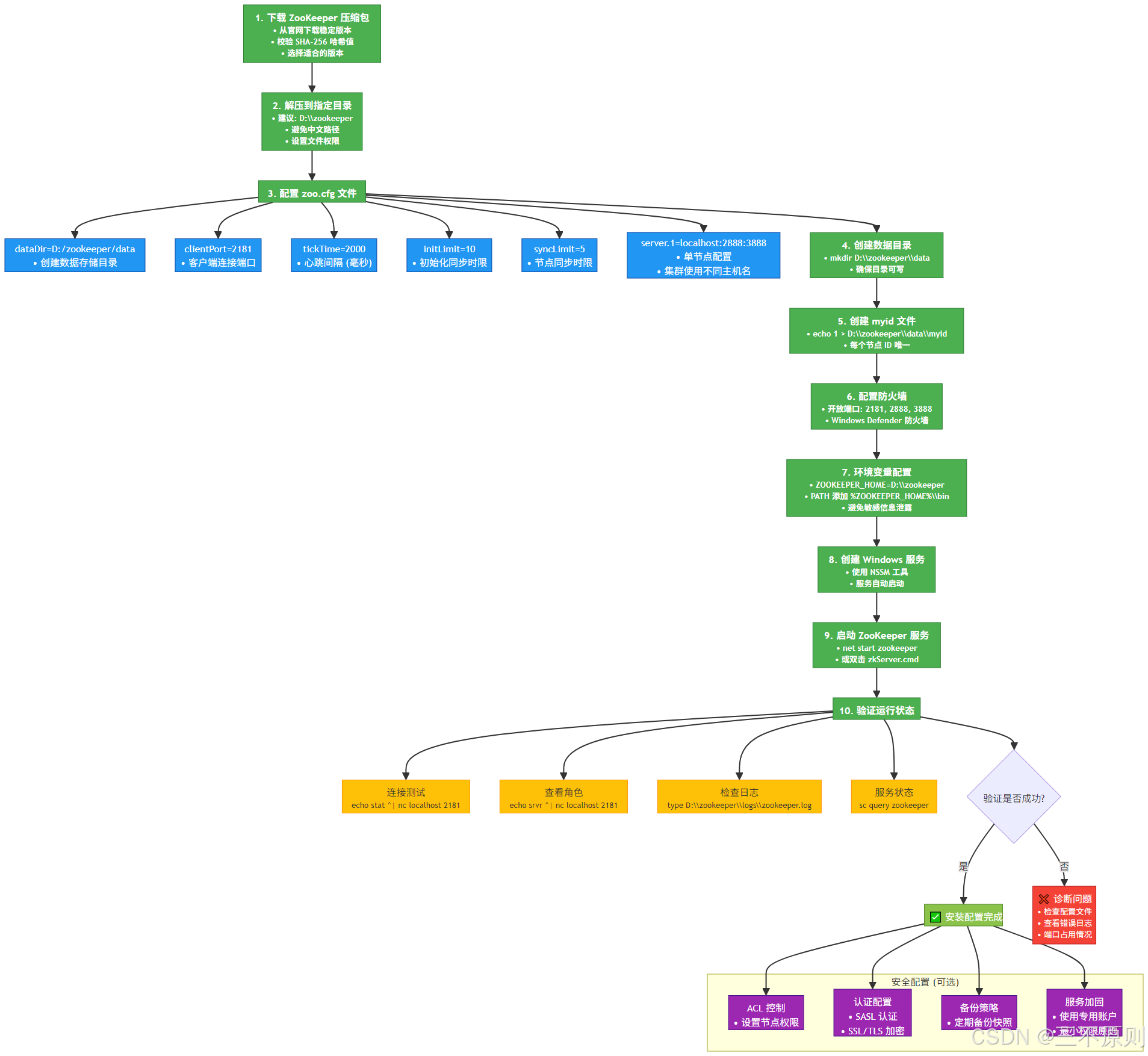
2.2.2 執行步驟
? ? ? ? 1. 下載 Kafka(選擇與 Scala 兼容的版本,如 2.13-3.5.1):
wget https://dlcdn.apache.org/kafka/3.5.1/kafka_2.13-3.5.1.tgz? ? ? ? 2. 解壓到 /opt 目錄并創建軟鏈接:
tar -zxvf kafka_2.13-3.5.1.tgz -C /opt/
ln -s /opt/kafka_2.13-3.5.1 /opt/kafka? ? ? ? 3. 修改核心配置文件 server.properties(關鍵配置項):
cd /opt/kafka/config
vi server.properties主要修改內容:
broker.id=0 # Broker 唯一標識,集群中需不同(如 0、1、2)
listeners=PLAINTEXT://:9092 # 監聽地址,默認 9092 端口(集群需指定節點 IP)
log.dirs=/opt/kafka/logs # 消息日志存儲目錄(手動創建 logs 文件夾)
zookeeper.connect=localhost:2181 # ZooKeeper 地址(集群需填寫所有 ZooKeeper 節點,如 zk1:2181,zk2:2181)
auto.create.topics.enable=false # 禁用自動創建 Topic,建議手動創建? ? ? ? 4. 啟動 Kafka Broker 服務(需先確保 ZooKeeper 已啟動):
# 前臺啟動(用于測試,關閉終端則服務停止)
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
# 后臺啟動(生產環境推薦,日志輸出到 logs/kafkaServer.out)
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties? ? ? ? 5. 驗證 Broker 狀態(查看 9092 端口是否被占用):
netstat -tuln | grep 9092 # 出現 LISTEN 狀態即為成功2.3 Windows 系統 Kafka 安裝
與 Linux 步驟類似,核心差異:
? ? ? ? 1. 下載 Kafka 壓縮包并解壓到 D:\kafka
? ? ? ? 2. 修改 D:\kafka\config\server.properties:
log.dirs=D:\kafka\logs # 手動創建 logs 文件夾
zookeeper.connect=localhost:2181? ? ? ? 3. 啟動 Broker(以管理員身份打開 cmd,進入 D:\kafka\bin\windows):
kafka-server-start.bat ../../config/server.properties # 前臺啟動? ? ? ? 4. 驗證:查看 9092 端口是否占用(cmd 執行 netstat -ano | findstr "9092")。
三、Kafka 核心配置(單節點與集群)
3.1 單節點關鍵配置(server.properties)
| 配置項 | 說明 | 推薦值(測試環境) |
| broker.id | Broker 唯一 ID(集群中不可重復) | 0 |
| listeners | 監聽地址格式:協議://IP:端口,PLAINTEXT 為明文協議 | PLAINTEXT://:9092 |
| log.dirs | 消息日志存儲目錄(建議獨立磁盤,避免與系統盤共用) | /opt/kafka/logs |
| zookeeper.connect | ZooKeeper 連接地址(集群格式:zk1:2181,zk2:2181,zk3:2181/kafka) | localhost:2181 |
| log.retention.hours | 消息保留時間(超過時間自動刪除) | 168(7 天) |
| log.segment.bytes | 單個日志片段大小(達到閾值后滾動生成新片段) | 1073741824(1GB) |
| num.partitions | 新建 Topic 的默認分區數(分區越多,吞吐越高,但資源消耗也越大) | 3 |
3.2 Kafka 集群部署(3 節點示例)
3.2.1 集群架構圖解
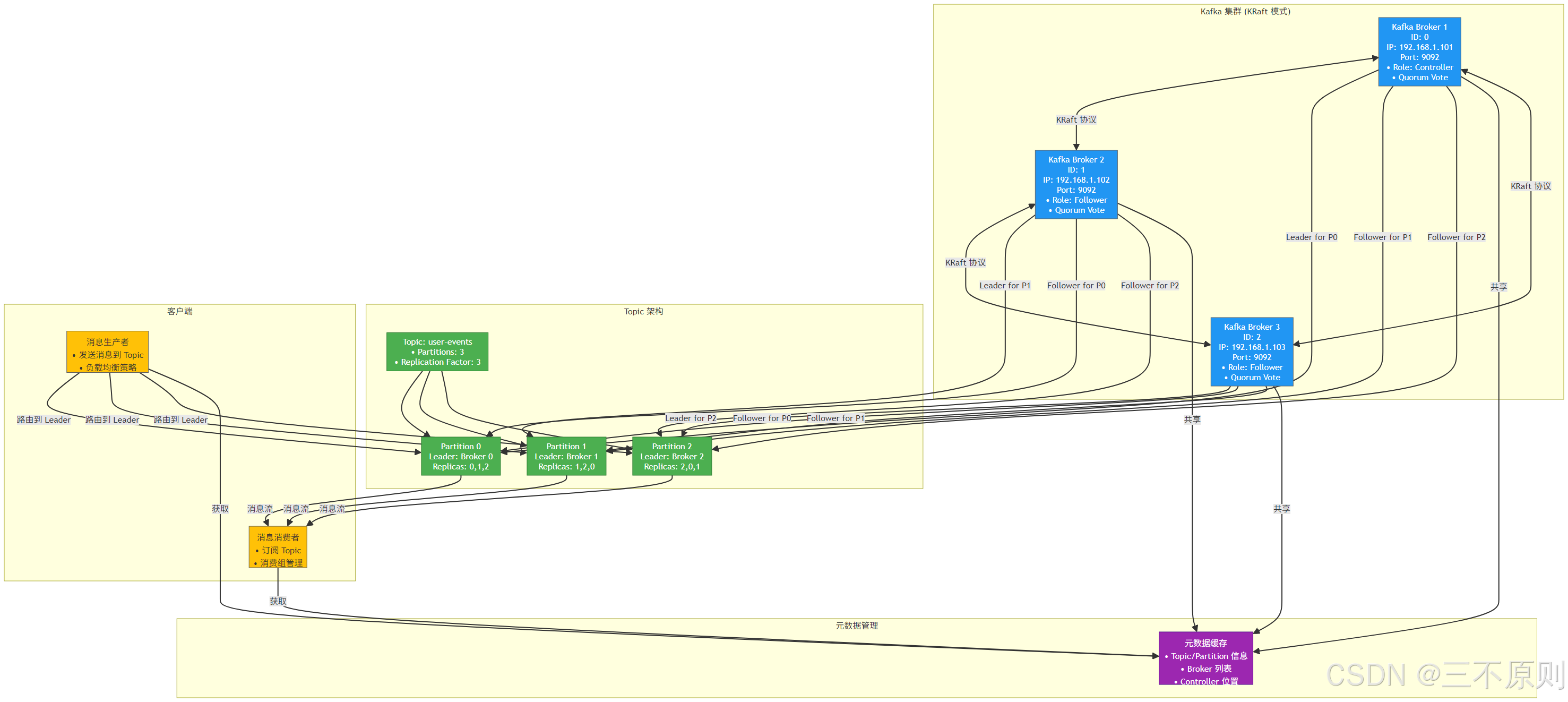
3.2.2 集群部署步驟(基于 Linux 系統)
- 準備 3 臺服務器,分別命名為 kafka1(192.168.1.101)、kafka2(192.168.1.102)、kafka3(192.168.1.103),確保節點間網絡互通,且已安裝 Java 環境。
- 部署 ZooKeeper 集群(3 節點):
-
- 每臺節點按 2.1.1 步驟安裝 ZooKeeper,修改 zoo.cfg 新增集群配置:
# 集群節點配置:server.節點ID=IP:通信端口:選舉端口
server.1=192.168.1.101:2888:3888
server.2=192.168.1.102:2888:3888
server.3=192.168.1.103:2888:3888-
- 每臺節點在 dataDir 目錄下創建 myid 文件,寫入對應節點 ID(如 kafka1 寫 1,kafka2 寫 2):
echo 1 > /opt/zookeeper/data/myid # kafka1 節點執行-
- 依次啟動 3 臺節點的 ZooKeeper 服務,驗證集群狀態(其中一臺為 Leader,其余為 Follower):
/opt/zookeeper/bin/zkServer.sh status? ? ? ?3. 部署 Kafka 集群:
-
- 每臺節點按 2.2 步驟安裝 Kafka,修改 server.properties 關鍵配置:
| 節點 | broker.id | listeners | zookeeper.connect |
| kafka1 | 0 | PLAINTEXT://192.168.1.101:9092 | 192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181 |
| kafka2 | 1 | PLAINTEXT://192.168.1.102:9092 | 同上 |
| kafka3 | 2 | PLAINTEXT://192.168.1.103:9092 | 同上 |
-
- 依次啟動 3 臺節點的 Kafka Broker 服務(后臺啟動):
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties-
- 驗證集群狀態(查看所有 Broker 是否在線):
# 列出集群中所有 Broker 節點
/opt/kafka/bin/kafka-broker-api-versions.sh --bootstrap-server 192.168.1.101:9092四、Kafka 基本操作(命令行工具)
4.1 Topic 管理
Kafka 提供命令行工具用于 Topic 的創建、查詢、修改和刪除,工具位于 /opt/kafka/bin 目錄(Windows 系統在 D:\kafka\bin\windows)。
4.1.1 創建 Topic
命令格式(Linux 系統):
# 創建 Topic(指定分區數 3、副本數 2,需集群環境支持副本)
/opt/kafka/bin/kafka-topics.sh \
--bootstrap-server 192.168.1.101:9092,192.168.1.102:9092 \
--create \
--topic user-behavior-topic \
--partitions 3 \
--replication-factor 2 \
--config retention.ms=604800000 # 消息保留時間(7天,可選)參數說明:
- --bootstrap-server:指定 Kafka 集群節點(單節點用 localhost:9092)
- --partitions:Topic 分區數(建議與 Broker 數量匹配,提升吞吐)
- --replication-factor:副本數(需 ≤ Broker 數量,確保數據冗余,生產環境建議 2-3)
Windows 系統命令:
kafka-topics.bat --bootstrap-server localhost:9092 --create --topic user-behavior-topic --partitions 3 --replication-factor 14.1.2 查詢 Topic 列表與詳情
# 查詢所有 Topic
/opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --list# 查詢指定 Topic 詳情(含分區、副本分布)
/opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic user-behavior-topic4.1.3 修改 Topic 配置(如分區數、保留時間)
# 增加分區數(注意:分區數僅能增加,不能減少)
/opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic user-behavior-topic --partitions 5# 修改消息保留時間(改為 3 天)
/opt/kafka/bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --topic user-behavior-topic --add-config retention.ms=2592000004.1.4 刪除 Topic
/opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic user-behavior-topic4.2 生產者與消費者測試(命令行)
4.2.1 啟動生產者發送消息
# Linux 系統
/opt/kafka/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic user-behavior-topic# Windows 系統
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic user-behavior-topic啟動后直接輸入消息(如 {"user_id": "1001", "behavior": "click", "timestamp": 1690000000}),按回車發送。
4.2.2 啟動消費者接收消息
新打開終端,執行以下命令(消費者需指定消費組,默認組為 console-consumer-xxx):
# 從頭消費 Topic 所有消息(--from-beginning 可選,默認消費新消息)
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic user-behavior-topic --from-beginning --group test-consumer-group此時生產者發送的消息會實時在消費者終端顯示,驗證消息收發正常。
五、Kafka 實際應用場景(代碼示例)
5.1 場景說明:用戶行為日志采集
假設需要采集用戶在電商平臺的點擊、下單、支付等行為日志,通過 Kafka 實現 “日志采集→消息存儲→實時消費” 流程,架構如下:
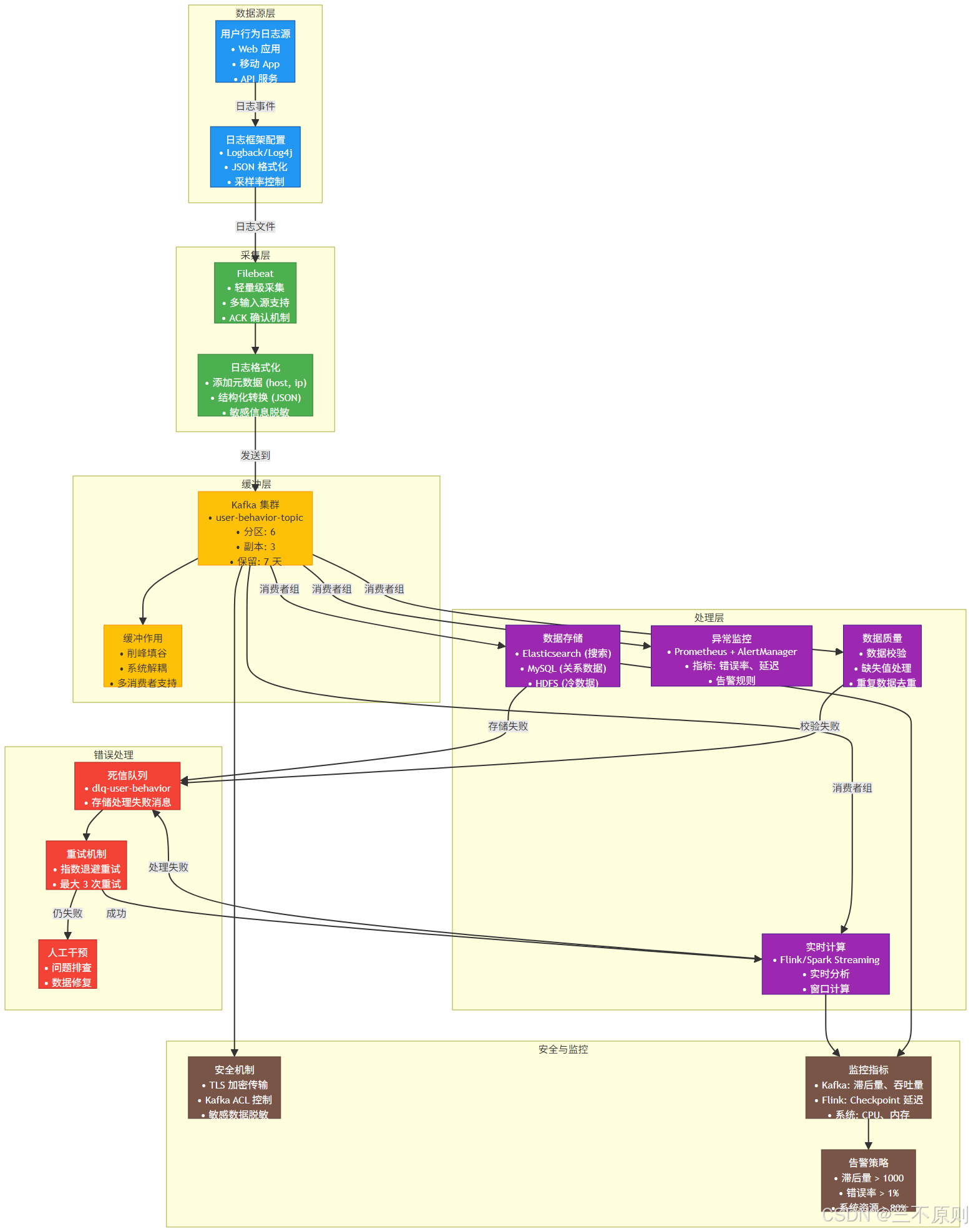
5.2 Java 生產者代碼示例(Spring Boot 集成)
5.2.1 引入依賴(pom.xml)
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.9.2</version> <!-- 與 Spring Boot 版本匹配 -->
</dependency>5.2.2 配置 Kafka 生產者(application.yml)
spring:kafka:bootstrap-servers: 192.168.1.101:9092,192.168.1.102:9092producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.springframework.kafka.support.serializer.JsonSerializeracks: 1 # 消息確認機制(1:Leader 接收成功即確認,平衡性能與可靠性)retries: 3 # 發送失敗重試次數batch-size: 16384 # 批量發送大小(16KB)linger-ms: 5 # 等待 5ms 批量發送(提升效率)5.2.3 生產者代碼(發送用戶行為日志)
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;@Component
public class UserBehaviorProducer {private final KafkaTemplate<String, UserBehaviorLog> kafkaTemplate;private static final String TOPIC = "user-behavior-topic";// 構造注入 KafkaTemplatepublic UserBehaviorProducer(KafkaTemplate<String, UserBehaviorLog> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}// 發送消息(key 為用戶 ID,用于分區路由,確保同一用戶消息進入同一分區)public void sendUserBehaviorLog(UserBehaviorLog log) {kafkaTemplate.send(TOPIC, log.getUserId(), log).addCallback(success -> System.out.println("消息發送成功:" + log),failure -> System.err.println("消息發送失敗:" + failure.getMessage()));}
}// 用戶行為日志實體類
class UserBehaviorLog {private String userId;private String behavior; // click, order, payprivate Long timestamp;// Getter、Setter 省略
}5.3 Java 消費者代碼示例(監聽 Topic)
5.3.1 配置 Kafka 消費者(application.yml)
spring:kafka:consumer:group-id: user-behavior-consumer-group # 消費組 IDkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.springframework.kafka.support.serializer.JsonDeserializerauto-offset-reset: earliest # 無偏移量時從頭消費(可選:latest 消費新消息)enable-auto-commit: false # 禁用自動提交偏移量,手動提交確保消息不丟失listener:ack-mode: manual-immediate # 手動立即提交偏移量5.3.2 消費者監聽代碼
import org.apache.kafka.clients.consumer.ConsumerAcknowledgment;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;@Component
public class UserBehaviorConsumer {// 監聽指定 Topic,手動提交偏移量@KafkaListener(topics = "user-behavior-topic", groupId = "user-behavior-consumer-group")public void consumeUserBehavior(ConsumerRecord<String, UserBehaviorLog> record, ConsumerAcknowledgment ack) {try {// 1. 獲取消息內容String userId = record.key();UserBehaviorLog log = record.value();System.out.println("接收用戶行為日志:" + userId + " - " + log.getBehavior());// 2. 業務處理(如存儲到 Elasticsearch、觸發實時計算)// elasticsearchTemplate.save(log);// 3. 手動提交偏移量(確保業務處理完成后提交,避免消息丟失)ack.acknowledge();} catch (Exception e) {System.err.println("消息處理失敗:" + e.getMessage());// 失敗時可重試或死信隊列處理}}
}六、Kafka 維護與優化
6.1 日志清理與磁盤管理
Kafka 消息默認存儲在 log.dirs 目錄,需定期監控磁盤空間,避免磁盤占滿導致服務異常:
6.1.1 配置日志清理策略(server.properties)
# 日志清理策略:delete(刪除過期日志)或 compact(按 key 壓縮,保留最新值)
log.cleanup.policy=delete# 單個日志片段大小(達到后滾動生成新片段,默認 1GB)
log.segment.bytes=1073741824# 日志片段保留時間(超過后觸發清理,默認 7 天)
log.retention.hours=168# 日志目錄磁盤使用率閾值(超過 85% 觸發清理,默認 85%)
log.dirs.config=log.retention.bytes=10737418240 # 可選:按磁盤大小限制(10GB)6.1.2 手動觸發日志清理(緊急情況)
# 查看 Topic 日志目錄
ls -l /opt/kafka/logs/user-behavior-topic-*# 手動刪除過期日志片段(需謹慎,建議先備份)
rm -rf /opt/kafka/logs/user-behavior-topic-0/00000000000000000000.log.16900000006.2 性能優化建議
6.2.1 Broker 優化(server.properties)
? ? ? ? 1. 內存配置:修改 Kafka 啟動腳本 bin/kafka-server-start.sh,調整 JVM 內存(生產環境建議 4-8GB):
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g" # 堆內存大小(避免超過物理內存 50%)? ? ? ? 2. 網絡優化:
# 每個 Broker 最大并發連接數(默認 2000)
num.network.threads=8
# 處理磁盤 I/O 的線程數(默認 8,建議與 CPU 核心數匹配)
num.io.threads=16
# 發送緩沖區大小(默認 128KB,高吞吐場景可調整為 256KB)
socket.send.buffer.bytes=262144
# 接收緩沖區大小(默認 128KB,同上)
socket.receive.buffer.bytes=2621446.2.2 生產者優化(application.yml)
spring:kafka:producer:batch-size: 32768 # 批量發送大小(32KB,提升吞吐)linger-ms: 10 # 等待 10ms 批量發送(平衡延遲與吞吐)compression-type: gzip # 消息壓縮(gzip/snappy,減少網絡傳輸)acks: 1 # 僅 Leader 確認(生產環境建議 1,兼顧可靠性與性能)6.2.3 消費者優化
spring:kafka:consumer:fetch.min.bytes: 16384 # 最小拉取字節數(16KB,避免頻繁拉取)fetch.max.wait.ms: 500 # 最大等待時間(500ms,超時即使未達閾值也拉取)listener:concurrency: 3 # 消費者并發數(建議等于 Topic 分區數,提升消費速度)6.3 數據備份與災難恢復
6.3.1 定期備份 Topic 數據
# 使用 kafka-dump-log 工具導出 Topic 數據到文件(示例:導出分區 0 的數據)
/opt/kafka/bin/kafka-dump-log.sh --files /opt/kafka/logs/user-behavior-topic-0/00000000000000000000.log --print-data-log > user-behavior-backup.log6.3.2 集群故障恢復(如 Broker 下線)
- 單個 Broker 下線:若配置了副本(replication-factor ≥2),下線 Broker 上的分區會自動切換到其他副本,無需手動干預,重啟下線 Broker 后會自動同步數據并加入集群。
- 數據丟失恢復:若未配置副本導致數據丟失,需從備份文件恢復,步驟如下:
# 1. 創建臨時 Topic
/opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic temp-topic --partitions 3 --replication-factor 1# 2. 使用生產者導入備份數據
/opt/kafka/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic temp-topic < user-behavior-backup.log# 3. 將臨時 Topic 數據遷移到原 Topic(需開發腳本或使用 Flink/Spark 同步)七、常見故障排查
7.1 Broker 啟動失敗
故障現象:執行啟動命令后,服務很快退出,查看日志報錯。
排查步驟:
? ? ? ? 1. 查看日志:日志路徑默認在 logs/server.log,執行:
tail -f /opt/kafka/logs/server.log? ? ? ? 2. 常見錯誤與解決:
-
- 錯誤 1:Address already in use(端口被占用)
解決:查看 9092 端口占用進程,殺死進程或修改 server.properties 中的 listeners 端口:
netstat -tuln | grep 9092 # 查看占用進程
kill -9 <進程ID> # 殺死進程-
- 錯誤 2:Connection refused to ZooKeeper(無法連接 ZooKeeper)
解決:檢查 ZooKeeper 服務是否啟動,或 zookeeper.connect 配置是否正確:
/opt/zookeeper/bin/zkServer.sh status # 檢查 ZooKeeper 狀態7.2 生產者發送消息失敗
故障現象:生產者發送消息后報錯 Leader not available。
排查步驟:
- 檢查 Topic 是否存在,執行 kafka-topics.sh --list 確認。
- 檢查集群 Broker 狀態,執行 kafka-broker-api-versions.sh 確認所有 Broker 在線。
- 若為集群環境,檢查 listeners 配置是否為節點 IP(而非 localhost),否則跨節點無法訪問。
7.3 消費者無法接收消息
故障現象:消費者啟動后,無消息接收,生產者發送正常。
排查步驟:
- 檢查消費組 group-id 是否正確,不同消費組可重復消費同一 Topic。
- 檢查 auto-offset-reset 配置:若為 latest,僅消費啟動后的新消息;改為 earliest 可從頭消費。
- 檢查 Topic 分區與消費組偏移量,執行以下命令查看偏移量:
/opt/kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group user-behavior-consumer-group若 Current offset 等于 Log end offset,說明已消費完所有消息,需生產者發送新消息。
八、總結
Kafka 作為高性能的分布式消息隊列,核心優勢在于高吞吐、低延遲和高可靠性,廣泛應用于日志采集、實時計算、消息通知等場景。通過本文的學習,讀者可掌握:
- 單節點與集群環境的安裝部署(含 ZooKeeper 配置);
- Topic、生產者、消費者的核心操作;
- 實際應用場景的代碼集成(Spring Boot 示例);
- 日常維護、性能優化與故障排查方法。
在生產環境中,需根據業務流量合理規劃分區數、副本數,結合監控工具(如 Prometheus + Grafana)實時監控集群狀態,確保 Kafka

出口商品類章金額數據庫)

)


)






)

MVCC、Redo Log 與 Undo Log)
)


