關注gongzhongaho【CVPR頂會精選】
多模態研究正處在爆發期,從圖文融合到視頻、語音、傳感器數據,模型能力邊界不斷擴展。頂會頂刊已將其視為具身智能與通用AI的核心方向。但寫論文時常遇到痛點:方法多、任務雜,缺乏統一框架,選題容易顯得“跟風”。未來趨勢是跨模態表示的高效對齊與可解釋融合,既能落地應用,也能凸顯創新性。
論文一:Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models
方法:
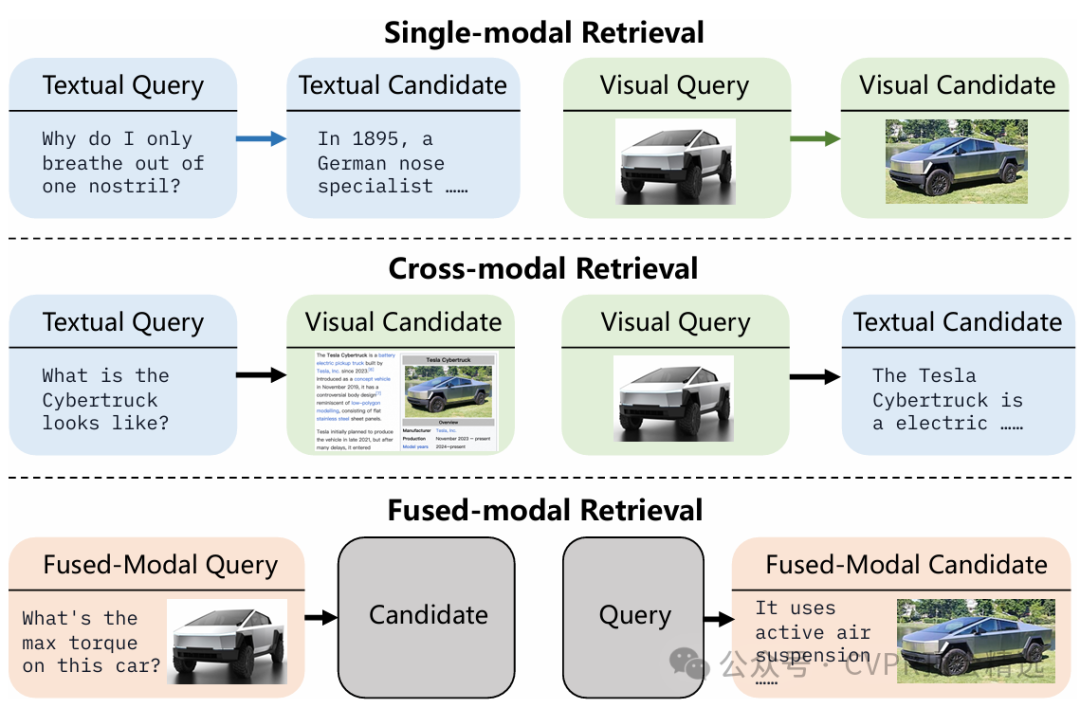
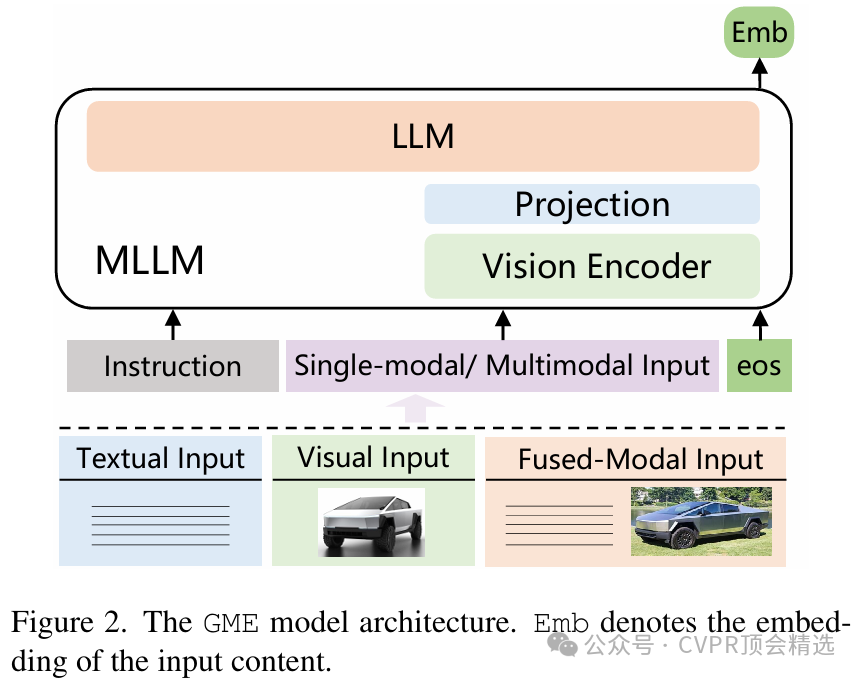
作者采用多模態大語言模型作為核心,統一對文本、圖像等模態進行編碼,并通過共享特征空間實現不同模態間的高效對齊。訓練過程中,模型在合成多模態數據集上進行端到端優化,通過對跨模態語義相關性的深度挖掘來增強檢索能力。推理時,無論輸入是什么模態,GME都能智能推斷最相關的目標模態內容,在多種公開基準上實現了跨模態檢索性能的新突破。
創新點:
利用多模態大語言模型統一建模多種模態,打破傳統檢索模型在模態轉換上的局限。
構建了高質量合成多模態數據集,有效提升模型的跨模態泛化能力和魯棒性。
提出端到端優化方案,使模型在文本-圖像、圖像-文本等檢索任務上均取得業界領先表現。
論文鏈接:
https://ieeexplore.ieee.org/abstract/document/11093150
圖靈學術科研輔導
論文二:Apollo: An Exploration of Video Understanding in Large Multimodal Models
方法:
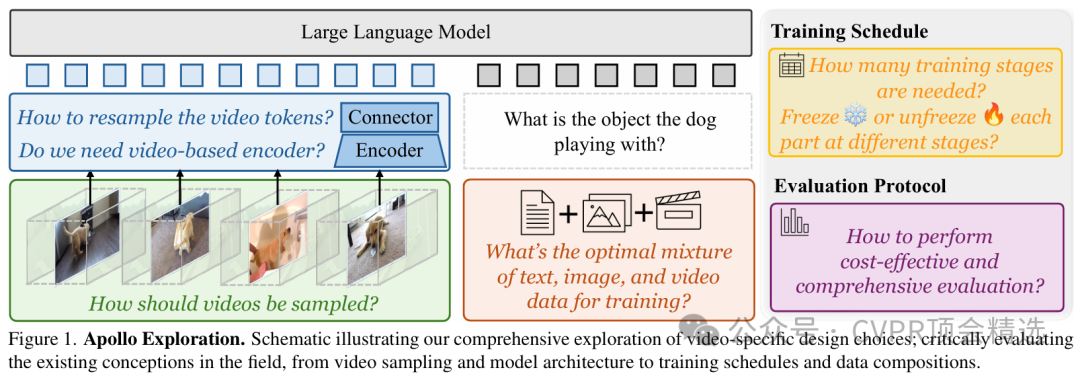
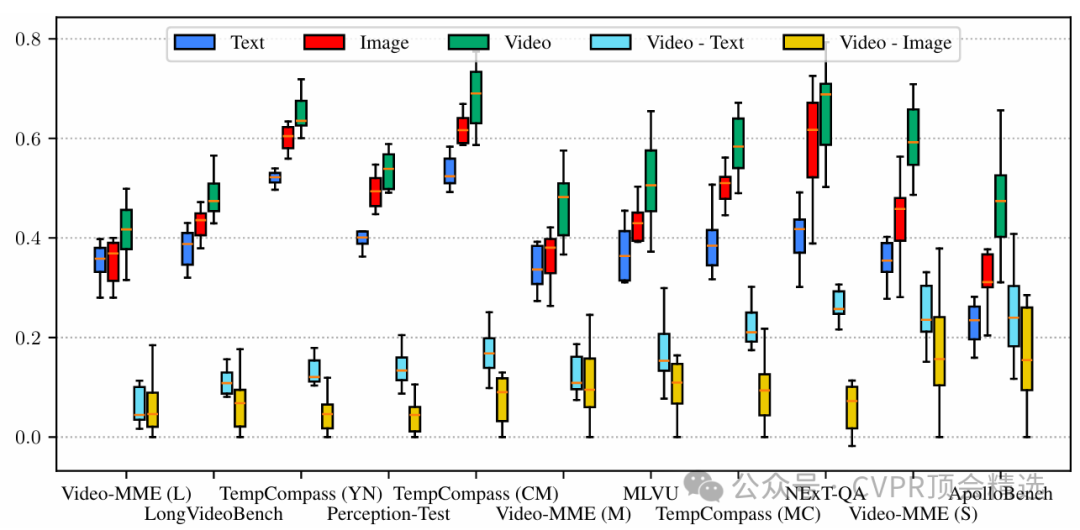
Apollo模型在架構上融合了先進的視頻幀編碼器與多模態特征對齊機制,能夠對視頻的時序信息和視覺細節進行深度捕捉和統一建模。訓練階段,模型利用大規模視頻-文本對進行端到端預訓練,通過多任務損失強化語義理解和跨模態推理能力。推理時,Apollo能夠高效地處理長視頻序列,將抽象的視覺動態轉化為精準的語義描述和任務輸出,在多項視頻理解基準上取得了領先成績。
創新點:
首次系統性地優化多模態大模型的視頻處理流程,實現端到端的視頻語義理解。
設計了高效的視頻特征提取與融合結構,顯著提升模型對復雜視頻場景的表征能力。
通過創新的訓練策略和大規模預訓練,顯著增強了模型在多領域視頻任務中的泛化能力與表現。
論文鏈接:
https://arxiv.org/abs/2412.10360
圖靈學術科研輔導
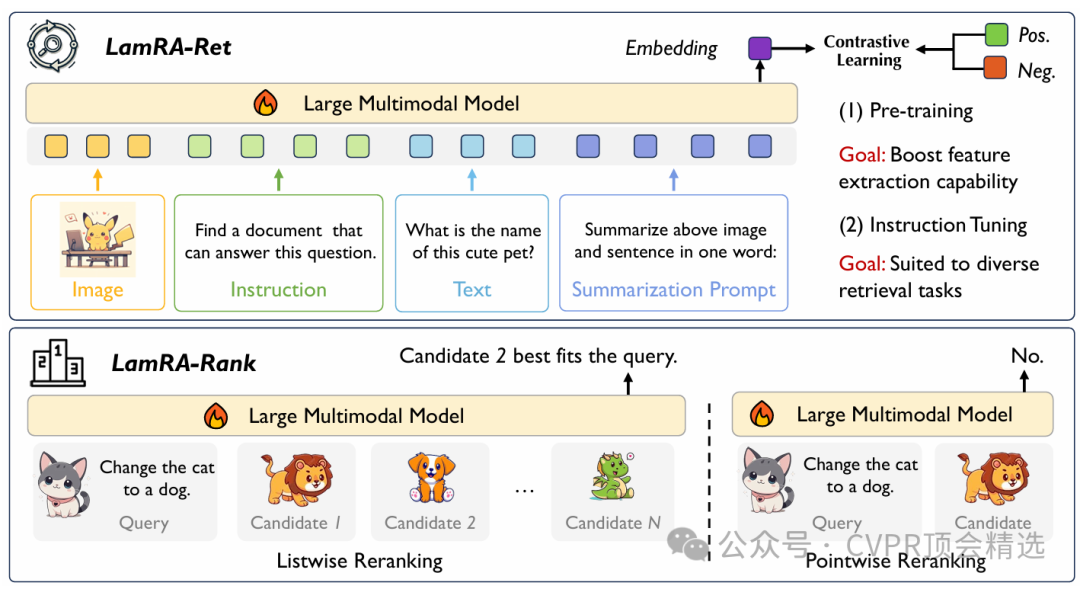
論文三:LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
方法:
作者的框架以多模態大模型為基礎,直接利用其強大的語義編碼能力對檢索候選進行理解和排序,無需針對特定任務進行微調。整個流程先通過高效的初步檢索篩選相關內容,再由大模型對候選進行語義重排序,最大化結果的準確性和多樣性。最終,LamRA能夠在多種實際檢索場景下展現出優異性能,兼容文本-文本、圖像-文本等多模態輸入,實現真正的“即插即用”智能檢索體驗。
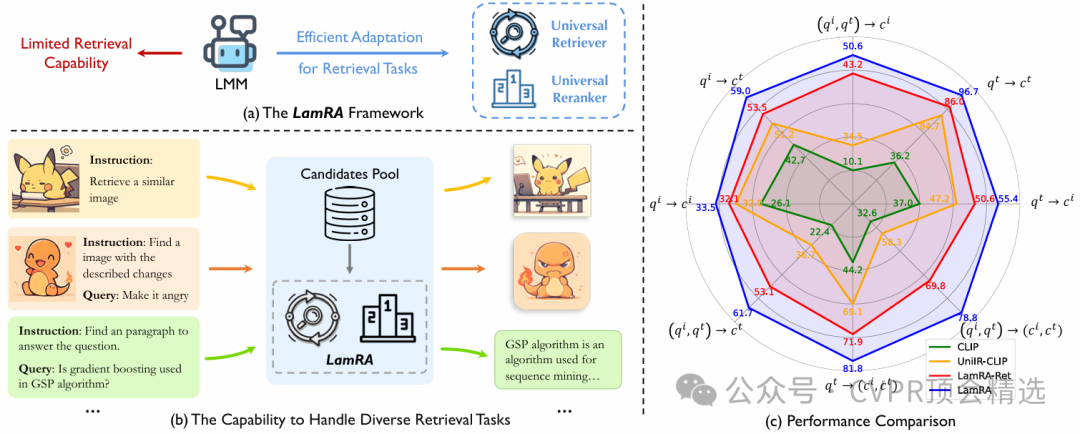
創新點:
首次系統性地優化多模態大模型的視頻處理流程,實現端到端的視頻語義理解。
設計了高效的視頻特征提取與融合結構,顯著提升模型對復雜視頻場景的表征能力。
?通過創新的訓練策略和大規模預訓練,顯著增強了模型在多領域視頻任務中的泛化能力與表現。
論文鏈接:
https://arxiv.org/abs/2412.01720
本文選自gongzhonghao【CVPR頂會精選】





)








詳細講解)




破除解版下載!IDM 下載器永久免費版!提升下載速度達5倍!安裝及使用)